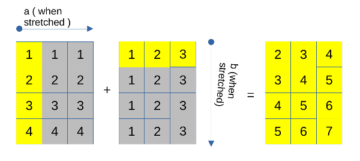
المُقدّمة
المربعات الصغرى العادية هي تقنية تحسين. OLS هي نفس التقنية المستخدمة بواسطة فئة scikit-Learn LinearRegression ووظيفة numpy.polyfit () خلف الكواليس. قبل أن ننتقل إلى تفاصيل تقنية OLS ، سيكون من المفيد الاطلاع على المقالة التي كتبتها دور تقنيات التحسين في التعلم الآلي والتعلم العميق. في نفس المقالة ، شرحت بإيجاز سبب وسياق وجود تقنية OLS (القسم 6). هذه المقالة هي إلى حد كبير استمرار للمقال نفسه ، ومن المتوقع أن يكون القراء على دراية بها.

المصدر: Pixbay
أهداف التعلم:
في هذه المقالة سوف تفعل
- تعرف على ماهية OLS وافهم معادلتها الرياضية
- احصل على نظرة عامة على OLS في شكل قشارة وعيوبه
- افهم OLS باستخدام مثال في الوقت الفعلي
جدول المحتويات
- ما هي مشاكل التحسين؟
- لماذا نحتاج OLS؟
- فهم الرياضيات وراء خوارزمية OLS
- حل OLS في شكل قشارة
- OLS في العمل باستخدام مثال حقيقي
- مشاكل في شكل Scaler لحل OLS
- وفي الختام
ما هي مشاكل التحسين؟
مشاكل التحسين هي مشاكل رياضية تتضمن إيجاد أفضل حل من مجموعة من الحلول الممكنة. تُصاغ هذه المشكلات عادةً على أنها مشاكل تعظيم أو تصغير ، حيث يكون الهدف إما تعظيم أو تقليل وظيفة موضوعية معينة. الوظيفة الهدف هي تعبير رياضي يصف الكمية المطلوب تحسينها ، وتحدد مجموعة من القيود مجموعة الحلول الممكنة.
تظهر مشاكل التحسين في مجالات مختلفة ، بما في ذلك الهندسة ، والتمويل ، والاقتصاد ، وبحوث العمليات. يتم استخدامها لنمذجة وحل المشكلات مثل تخصيص الموارد والجدولة وتحسين المحفظة. يعد التحسين مكونًا مهمًا في العديد من خوارزميات التعلم الآلي. في التعلم الآلي ، يتم استخدام التحسين للعثور على أفضل مجموعة من المعلمات لنموذج يقلل من الفرق بين تنبؤات النموذج والقيم الحقيقية. يعد التحسين مجالًا نشطًا للبحث في التعلم الآلي ، حيث يتم تطوير خوارزميات تحسين جديدة لتحسين سرعة ودقة نماذج التعلم الآلي للتدريب.
تتضمن بعض الأمثلة على استخدام التحسين في التعلم الآلي ما يلي:
- في التعلم الخاضع للإشراف، يتم استخدام التحسين للعثور على معلمات نموذج تقلل من الاختلاف بين تنبؤات النموذج والقيم الحقيقية لمجموعة بيانات تدريب معينة. على سبيل المثال ، يستخدم الانحدار الخطي والانحدار اللوجستي التحسين للعثور على أفضل قيم معاملات النموذج. بالإضافة إلى ذلك ، يتم إنشاء بعض النماذج مثل أشجار القرار والغابات العشوائية ونماذج تعزيز التدرج من خلال إضافة نماذج جديدة بشكل متكرر إلى المجموعة وتحسين معلمات النماذج الجديدة التي تقلل الخطأ في بيانات التدريب.
- في التعلم غير الخاضع للإشراف، يساعد التحسين في العثور على أفضل تكوين للمجموعات أو تعيين البيانات التي تمثل أفضل بنية أساسية في البيانات. في المجموعات، يتم استخدام التحسين للعثور على أفضل تكوين للمجموعات في البيانات. على سبيل المثال ، تستخدم خوارزمية K-Means تقنية تحسين تسمى خوارزمية Lloyd ، والتي تعيد تعيين نقاط البيانات بشكل متكرر إلى أقرب مركز للكتلة وتقوم بتحديث النقط المركزية العنقودية بناءً على النقاط المعينة حديثًا. وبالمثل ، فإن خوارزميات التجميع الأخرى مثل التجميع الهرمي ، والتجميع القائم على الكثافة ، ونماذج المزيج الغاوسي تستخدم أيضًا تقنيات التحسين للعثور على أفضل حل للتجميع. في تخفيض الأبعاد، يعثر التحسين على أفضل تعيين للبيانات من مساحة ذات أبعاد عالية إلى مساحة منخفضة الأبعاد. على سبيل المثال ، يستخدم تحليل المكونات الرئيسية (PCA) تحليل القيمة المفردة (SVD) ، وهي تقنية تحسين ، للعثور على أفضل تركيبة خطية من المتغيرات الأصلية التي تشرح معظم التباين في البيانات. بالإضافة إلى ذلك ، تستخدم تقنيات تقليل الأبعاد الأخرى مثل التحليل الخطي التمييزي (LDA) والتضمين العشوائي للجوار الموزع (t-SNE) أيضًا تقنيات التحسين للعثور على أفضل تمثيل للبيانات في مساحة ذات أبعاد أقل.
- في التعلم العميق، يتم استخدام التحسين للعثور على أفضل مجموعة من المعلمات للشبكات العصبية ، والتي يتم إجراؤها عادةً باستخدام خوارزميات التحسين القائمة على التدرج مثل هبوط التدرج العشوائي (SGD) أو Adam / Adagrad / RMSProp ، إلخ.
لماذا نحتاج OLS؟
• المربعات الصغرى العادية خوارزمية (OLS) هي طريقة لتقدير معلمات نموذج الانحدار الخطي. تهدف خوارزمية OLS إلى العثور على قيم معلمات نموذج الانحدار الخطي (أي المعاملات) التي تقلل مجموع القيم التربيعية المتبقية. القيم المتبقية هي الاختلافات بين القيم المرصودة للمتغير التابع والقيم المتوقعة للمتغير التابع بالنظر إلى المتغيرات المستقلة. من المهم ملاحظة أن خوارزمية OLS تفترض أن الأخطاء يتم توزيعها بشكل طبيعي بمتوسط صفري وتباين ثابت وأنه لا توجد علاقة خطية متعددة (ارتباط عالٍ) بين المتغيرات المستقلة. يجب استخدام طرق أخرى ، مثل المربعات الصغرى المعممة أو المربعات الصغرى الموزونة ، في الحالات التي لا يتم فيها استيفاء هذه الافتراضات.
فهم الرياضيات وراء خوارزمية OLS
لشرح خوارزمية OLS ، اسمحوا لي أن آخذ أبسط مثال ممكن. ضع في اعتبارك نقاط البيانات الثلاثة التالية:
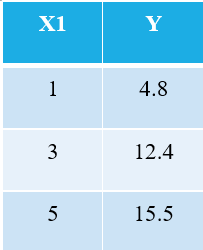
سوف يدرك كل شخص مطلع على التعلم الآلي على الفور أننا نشير إلى X1 باعتباره المتغير المستقل (ويسمى أيضًا "المميزات"أو "صفات")، و Y هو المتغير التابع (يشار إليه أيضًا باسم "استهداف" or "حصيلة"). ومن ثم ، فإن المهمة العامة لأي جهاز هي العثور على العلاقة بين X1 و Y. هذه العلاقة في الواقع "تعلمت" بواسطة الجهاز من البيانات. ومن ثم ، فإننا نطلق على مصطلح "التعلم الآلي". نحن البشر نتعلم من تجاربنا. وبالمثل ، يتم إدخال نفس التجربة في الجهاز مثل البيانات.
الآن ، لنفترض أننا نريد العثور على الخط الأنسب من خلال نقاط البيانات الثلاث المذكورة أعلاه. يوضح الرسم البياني التالي نقاط البيانات الثلاث هذه في دوائر زرقاء. يظهر أيضًا الخط الأحمر (مع المربعات) ، والذي ندعي أنه "أفضل خط مناسب"من خلال نقاط البيانات الثلاث هذه. أيضًا ، لقد أظهرت خطًا "غير ملائم" (الخط الأصفر) للمقارنة.
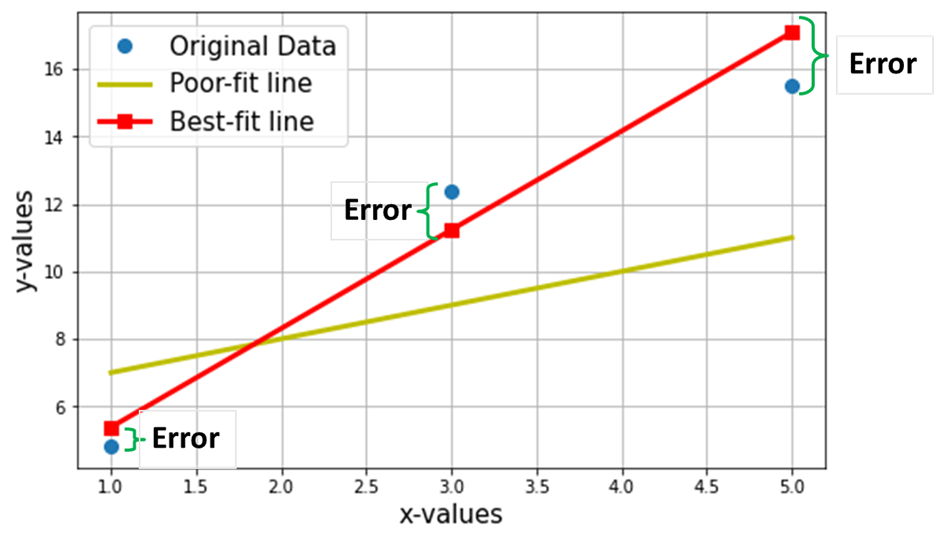
الهدف الصافي هو إيجاد معادلة أفضل خط مستقيم ملائم (من خلال هذه النقاط الثلاث المذكورة في الجدول أعلاه).

إنها معادلة الخط الأنسب (الخط الأحمر في الرسم أعلاه) ، أين w1 = منحدر الخط ؛ w0 = اعتراض الخط.
في التعلم الآلي ، يُطلق على أفضل ملاءمة اسم خطي تراجع (LR) ، و w0 و w1 تسمى أيضًا أوزان النموذج أو معاملات النموذج.
تمثل المربعات الحمراء في الرسم أعلاه القيم المتوقعة من نموذج الانحدار الخطي (Y ^). بالطبع ، القيم المتوقعة ليست هي نفسها القيم الفعلية لـ Y (الدوائر الزرقاء). يمثل الاختلاف الرأسي الخطأ في التنبؤ الذي قدمه (انظر الصورة أدناه) لأي نقطة بيانات.
![]()
الآن أنا أدعي أن هذا الخط المناسب سيكون به الحد الأدنى من الخطأ للتنبؤ (من بين جميع السطور العشوائية "غير الملائمة" الممكنة). يتم التعبير عن هذا الخطأ الإجمالي عبر جميع نقاط البيانات كـ دالة الخطأ التربيعي المتوسطة (MSE)، والذي سيكون الحد الأدنى للخط الأنسب.
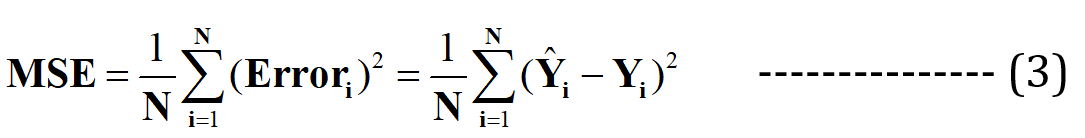
N = العدد الإجمالي. من نقاط البيانات في مجموعة البيانات (في الحالة الحالية ، تكون 3)
يشار إلى تقليل أو زيادة أي كمية إلى الحد الأقصى رياضيًا باسم مشكلة التحسين ، ومن ثم فإن الحل (النقطة التي يوجد فيها الحد الأدنى / الحد الأقصى) يشير إلى القيم المثلى للمتغيرات.

الانحدار الخطي مثال على التحسين غير المقيد، معطى بواسطة:
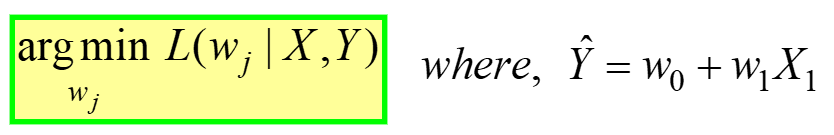 ---- (4)
---- (4)
يُقرأ هذا على أنه "Find the الأوزان المثلى (wj) من أجلها MSE دالة الخسارة (الواردة في المعادلة 3 أعلاه) لها القيمة الدنيا ، ل بيانات GIVEN X و Y" (راجع الجدول الأول في بداية المقال). لام (wj) يمثل خسارة MSE ، وهي دالة لأوزان النموذج ، وليس X أو Y. تذكر أن X & Y هي بياناتك ومن المفترض أن تكون ثابتة! يمثل الرمز "j" معامل / وزن النموذج j.
عند استبدال Y ^ = w0 + ث1X1 في مكافئ. 3 أعلاه ، النهائي وظيفة فقدان MSE (L) يشبه:
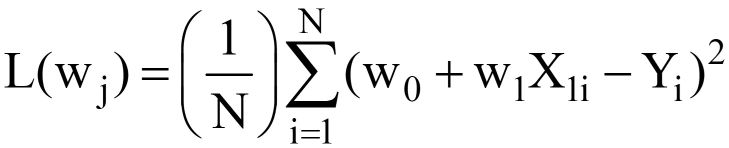 ---- (5)
---- (5)
من الواضح أن L دالة لأوزان النموذج (w0 & ث1) ، والتي يجب أن نجد قيمها المثلى عند تقليل L. يتم تمثيل القيم المثلى بواسطة (*) في الشكل أدناه.
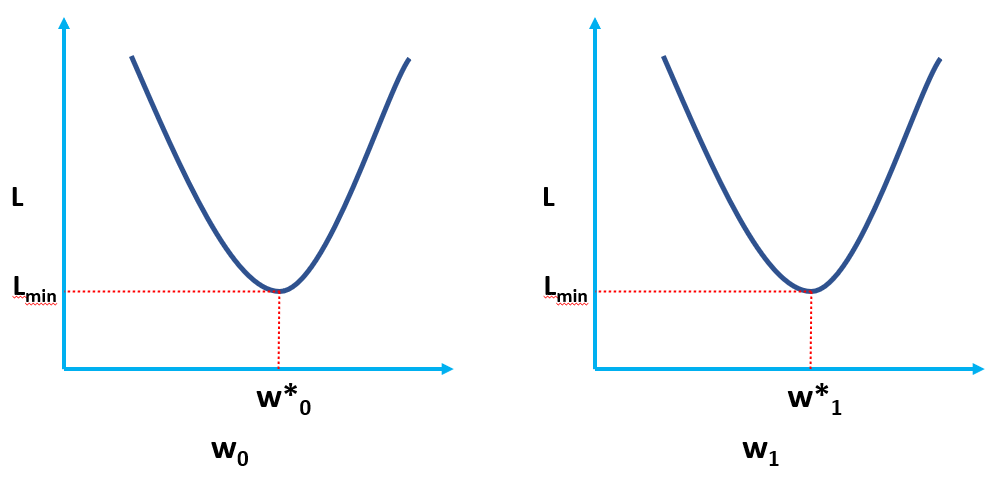
حل OLS في شكل قشارة
مكافئ. 5 الوارد أعلاه يمثل وظيفة خسارة OLS في شكل قشارة (حيث يمكننا رؤية تلخيص الأخطاء لكل نقطة بيانات. تعد خوارزمية OLS حلاً تحليليًا لمشكلة التحسين المعروضة في المعادلة. 4. يتكون هذا الحل التحليلي من الخطوات التالية:
خطوة 1

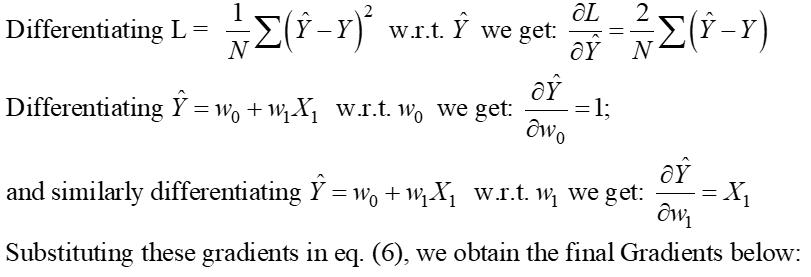

الخطوة 2: قم بمساواة هذه التدرجات بالصفر وحل القيم المثلى لمعاملات النموذج wj.
هذا يعني أساسًا أن ميل الظل (التفسير الهندسي للتدرجات) إلى دالة الخسارة في القيم المثلى (النقطة التي تكون فيها L هي الحد الأدنى) سيكون صفرًا ، كما هو موضح في الأشكال أعلاه.

من المعادلات أعلاه ، يمكننا تحويل "2" من LHS إلى RHS ؛ يبقى RHS كـ 0 (حيث أن 0/2 لا يزال 0).


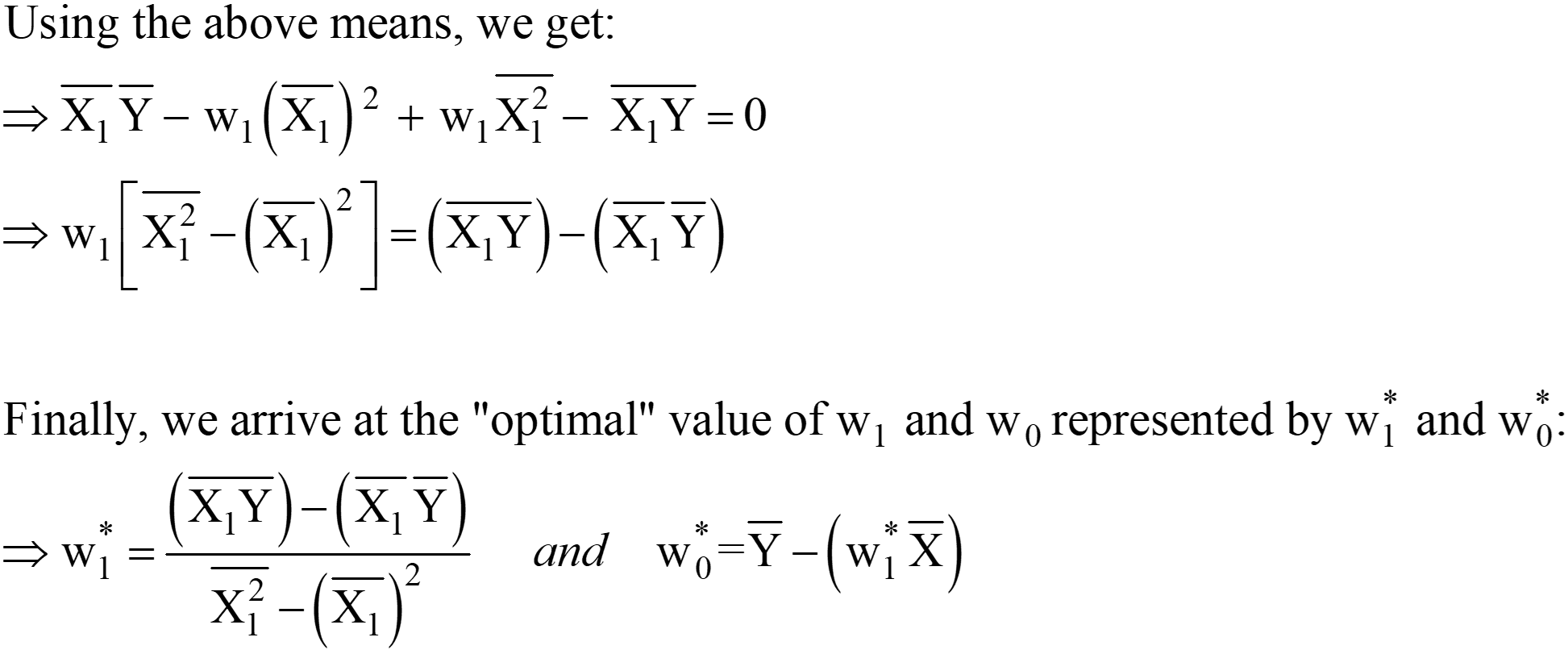
هذه التعبيرات الخاصة بـ w1 * و w0 * هي الحل التحليلي النهائي لـ OLS في شكل Scaler.
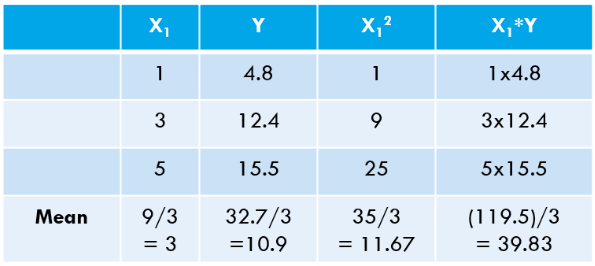
الخطوة 3: حساب الوسائل المذكورة أعلاه واستبدالها في التعبير عن w1 * & w0 *.
دعنا نحسب هذه القيم لمجموعة البيانات الخاصة بنا:
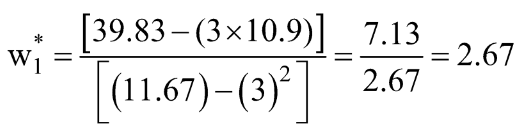
![]()
دعونا نحسب نفس الشيء باستخدام كود بايثون:
[الإخراج]: هذه هي معادلة الخط "الأنسب": 2.675 × + 2.875
يمكنك أن ترى قيمنا "المحسوبة يدويًا" تتطابق بشكل وثيق جدًا مع قيم الميل والاعتراض التي تم الحصول عليها باستخدام NumPy (يرجع الاختلاف الصغير إلى أخطاء التقريب في حساباتنا اليدوية). يمكننا أيضًا التحقق من أن نفس OLS "يعمل خلف الكواليس" لفئة LinearRegression من تعلم الحروف الحزمة ، كما هو موضح في الكود أدناه.
# استيراد فئة LinearRegression من حزمة scikit-Learn من sklearn.linear_model import LinearRegression LR = LinearRegression () # إنشاء مثيل لفئة LinearRegression # حدد X و Y كمصفوفات NumPy (متجهات العمود) X = np.array ([1,3,5 ، 1,1،4.8,12.4,15.5]). reshape (-1,1،0) Y = np.array ([XNUMX،XNUMX،XNUMX]). reshape (-XNUMX،XNUMX) LR.fit (X، Y) # حساب معاملات النموذج LR .intercept_ # التحيز أو مصطلح التقاطع (wXNUMX *)
[الإخراج]: صفيف ([2.875])
LR.coef_ # مصطلح المنحدر (w1 *) [الإخراج]: المصفوفة ([[2.675]])
OLS قيد التشغيل باستخدام مثال فعلي
أنا هنا أستخدم مجموعة بيانات Boston House Pricing ، وهي إحدى مجموعات البيانات الأكثر شيوعًا أثناء تعلم علوم البيانات. الهدف هو جعل نموذج الانحدار الخطي للتنبؤ بالقيمة المتوسطة لأسعار المنزل بناءً على 13 سمة / سمة مذكورة أدناه.
استيراد مجموعة البيانات واستكشافها.
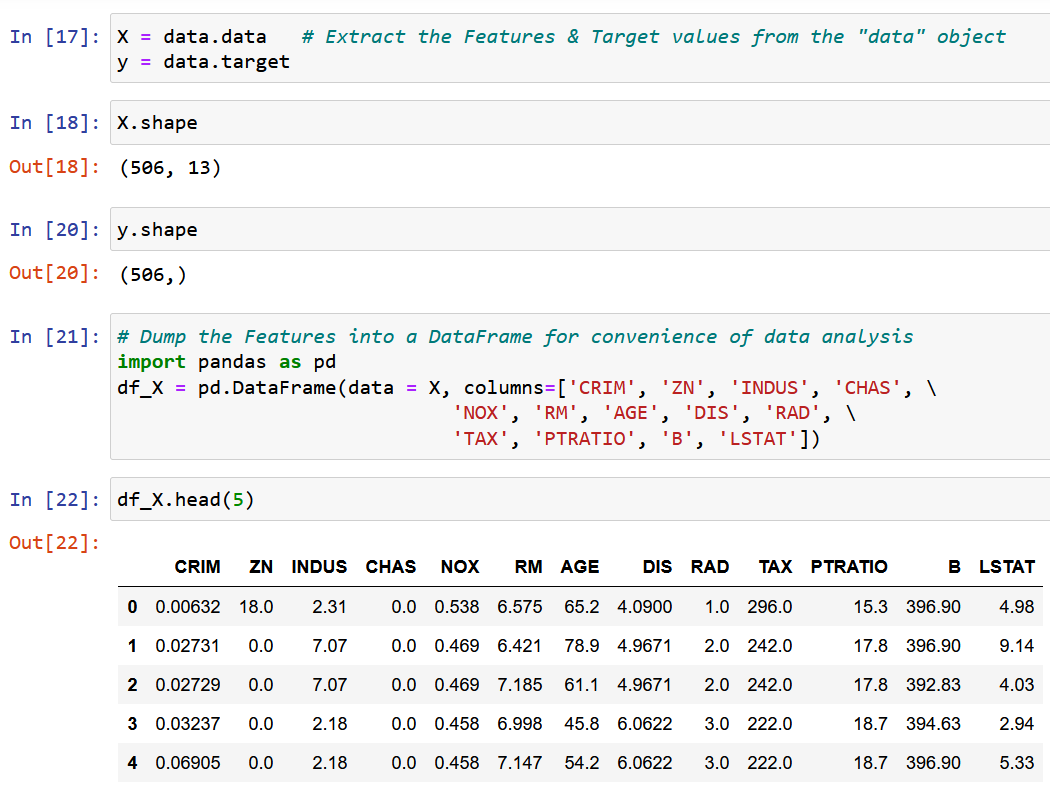
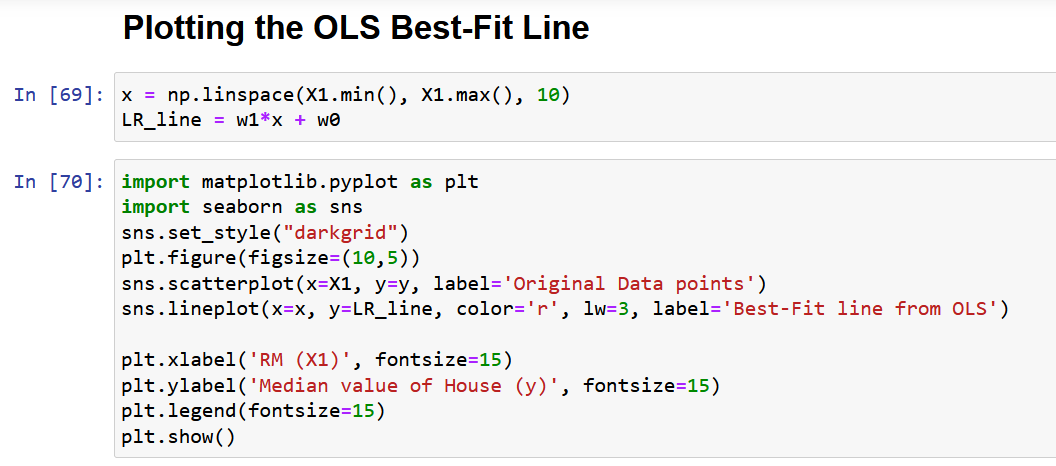
سنستخرج ميزة واحدة RM ، متوسط حجم الغرفة في المنطقة المحلية المحددة ، ونلائمها مع المتغير المستهدف y (القيمة المتوسطة لسعر المنزل).
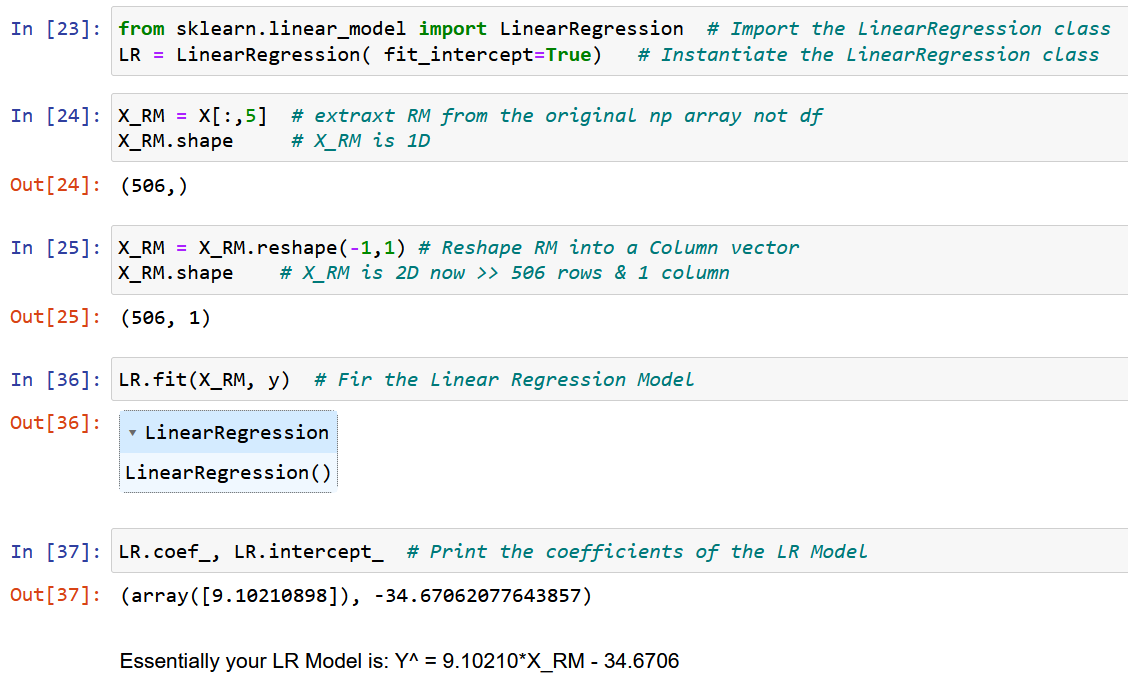
الآن ، دعنا نستخدم NumPy النقي ونحسب معاملات النموذج باستخدام التعبيرات المشتقة للقيم المثلى لمعاملات النموذج w0 & w1 أعلاه (نهاية الخطوة 2).
دعنا أخيرًا نرسم البيانات الأصلية مع أفضل خط مناسب ، كما هو موضح أدناه.

مشاكل مع شكل قشارة حل OLS
أخيرًا ، اسمحوا لي أن أناقش المشكلة الرئيسية في النهج أعلاه ، كما هو موضح في القسم 4. كما ترون من مجموعة البيانات المذكورة أعلاه ، فإن أي مجموعة بيانات حقيقية سيكون لها ميزات متعددة. السبب الرئيسي الذي جعلني أتخذ ميزة واحدة فقط لإثبات طريقة OLS في القسم أعلاه هو أنه مع زيادة عدد الميزات ، سيزداد عدد التدرجات أيضًا ، وبالتالي عدد المعادلات التي يجب حلها في وقت واحد!
على وجه الدقة ، بالنسبة لـ 13 ميزة (مجموعة بيانات بوسطن أعلاه) ، سيكون لدينا 13 معاملاً نموذجيًا ومصطلح اعتراض واحد ، مما يجعل العدد الإجمالي للمتغيرات التي سيتم تحسينها على النحو الأمثل إلى 14. ومن ثم ، سنحصل على 14 تدرجًا (المشتق الجزئي من دالة الخسارة فيما يتعلق بكل من هذه المتغيرات الأربعة عشر). وبالتالي ، نحتاج إلى حل 14 معادلة (بعد معادلة هذه المشتقات الجزئية الأربعة عشر بالصفر ، كما هو موضح في الخطوة 14). لقد أدركت بالفعل مدى تعقيد الحل التحليلي باستخدام متغيرين فقط. بصراحة ، لقد حاولت أن أقدم لكم الشرح الأكثر تفصيلاً لـ OLS المتاح على الإنترنت ، ومع ذلك ليس من السهل استيعاب الرياضيات.
ومن ثم ، وبكلمات بسيطة ، الحل التحليلي أعلاه غير قابل للتحجيم!
الحل لهذه المشكلة هو "النموذج المتجه لحل OLS" ، والذي سيتم مناقشته بالتفصيل في مقالة متابعة (الجزء 2 من هذه المقالة) ، مع القسمين 7 و 8.
وفي الختام
في الختام ، تعد طريقة OLS أداة قوية لتقدير معلمات نموذج الانحدار الخطي. يعتمد على مبدأ تقليل مجموع الفروق التربيعية بين القيم المتوقعة والفعلية.
فيما يلي بعض النقاط الرئيسية من المقال:
- يمكن تمثيل حل OLS في شكل قشارة ، مما يسهل تنفيذه وتفسيره.
- ناقشت المقالة مفهوم مشاكل التحسين والحاجة إلى OLS في تحليل الانحدار وقدمت صيغة رياضية ومثالًا على OLS في العمل.
- تسلط المقالة الضوء أيضًا على بعض القيود المفروضة على شكل قشارة حل OLS ، مثل قابلية التوسع وافتراضات الخطية والتباين الثابت. أتمنى أن تتعلم شيئًا جديدًا من هذه المقالة.
يرجى ترك تعليق لي إذا شعرت أن أي نقطة / معادلة في هذه المقالة تحتاج إلى شرح أو إذا كنت تريد مني أن أكتب عن أي خوارزمية أخرى لتعلم الآلة بمثل هذه التفاصيل.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/01/a-comprehensive-guide-to-ols-regression-part-1/
- 1
- 10
- 214
- 7
- a
- من نحن
- فوق
- مطلق
- دقة
- في
- اكشن
- نشط
- في الواقع
- إضافة
- وبالإضافة إلى ذلك
- بعد
- وتهدف
- خوارزمية
- خوارزميات
- الكل
- توزيع
- سابقا
- من بين
- تحليل
- تحليلية
- و
- نهج
- المنطقة
- البند
- تعيين
- متاح
- المتوسط
- على أساس
- في الأساس
- قبل
- وراء
- خلف الكواليس
- يجري
- أقل من
- أفضل
- ما بين
- انحياز
- الأزرق
- تعزيز
- بوسطن
- موجز
- يجلب
- بنيت
- دعوة
- تسمى
- حقيبة
- الحالات
- مركز
- معين
- الدوائر
- مطالبة
- فئة
- عن كثب
- كتلة
- المجموعات
- الكود
- عمود
- مجموعة
- التعليق
- عادة
- مقارنة
- تعقيد
- عنصر
- شامل
- إحصاء
- مفهوم
- اختتام
- الاعداد
- بناء على ذلك
- نظر
- ثابت
- القيود
- سياق الكلام
- استمرار
- ارتباط
- الدورة
- خلق
- حاسم
- حالياًّ
- غامق
- البيانات
- نقاط البيانات
- علم البيانات
- قواعد البيانات
- القرار
- عميق
- يعرف
- تظاهر
- التظاهر
- تابع
- المشتقات
- مستمد
- وصف
- التفاصيل
- تفاصيل
- المتقدمة
- فرق
- الخلافات
- بحث
- ناقش
- وزعت
- قطرة
- كل
- الاقتصاد - Economics
- إما
- توضيح
- الهندسة
- معادلات
- خطأ
- أخطاء
- إلخ
- الأثير (ETH)
- مثال
- أمثلة
- موجود
- متوقع
- الخبره في مجال الغطس
- خبرة
- شرح
- شرح
- ويوضح
- تفسير
- اكتشف
- أعربت
- التعبيرات
- استخراج
- مألوف
- الميزات
- المميزات
- بنك الاحتياطي الفيدرالي
- مجال
- الشكل
- الأرقام
- نهائي
- أخيرا
- تمويل
- العثور على
- ويرى
- الاسم الأول
- تناسب
- متابعيك
- متابعات
- النموذج المرفق
- تبدأ من
- وظيفة
- منح
- معطى
- هدف
- الذهاب
- التدرجات
- تجمع
- توجيه
- يساعد
- مرتفع
- ويبرز
- أمل
- منـزل
- HTTPS
- البشر
- صورة
- فورا
- تنفيذ
- استيراد
- أهمية
- تحسن
- in
- تتضمن
- بما فيه
- القيمة الاسمية
- مستقل
- مثل
- Internet
- ترجمة
- تنطوي
- IT
- القفل
- تعلم
- تعلم
- LG
- القيود
- خط
- خطوط
- تبدو
- خسارة
- آلة
- آلة التعلم
- الرئيسية
- جعل
- القيام ب
- كثير
- رسم الخرائط
- مباراة
- رياضي
- رياضيا
- الرياضيات
- ماكس العرض
- تعظيم
- يعني
- المذكورة
- طريقة
- طرق
- التقليل
- التقليل
- الحد الأدنى
- مزيج
- نموذج
- عارضات ازياء
- أكثر
- متعدد
- حاجة
- إحتياجات
- صاف
- الشبكات
- عصبي
- الشبكات العصبية
- جديد
- عادة
- عدد
- نمباي
- موضوعي
- أهداف
- تم الحصول عليها
- ONE
- عمليات
- الأمثل
- التحسين
- الأمثل
- الأمثل
- أصلي
- أخرى
- الكلي
- نظرة عامة
- صفقة
- المعلمات
- جزء
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- البوينت
- نقاط
- محفظة
- ممكن
- قوي
- تنبأ
- وتوقع
- تنبؤ
- تنبؤات
- قدم
- السعر
- الأسعار
- التسعير
- رئيسي
- مبدأ
- المشكلة
- مشاكل
- المقدمة
- بايثون
- كمية
- عشوائية
- عرض
- القراء
- في الوقت الحقيقي
- أدركت
- سبب
- الاعتراف
- أحمر
- يشار
- يشير
- تراجع
- صلة
- بقايا
- تذكر
- مثل
- التمثيل
- ممثلة
- يمثل
- بحث
- مورد
- النوع
- غرفة
- نفسه
- التدرجية
- مشاهد
- علوم
- تعلم الحروف
- القسم
- أقسام
- طقم
- SGD
- نقل
- ينبغي
- أظهرت
- يظهر
- وبالمثل
- الاشارات
- عزباء
- صيغة المفرد
- مقاس
- منحدر
- صغير
- حل
- الحلول
- حل
- بعض
- شيء
- الفضاء
- سرعة
- مربع
- المربعات
- بداية
- خطوة
- خطوات
- لا يزال
- مستقيم
- بناء
- هذه
- مفترض
- جدول
- أخذ
- الوجبات السريعة
- الهدف
- مهمة
- تقنيات
- •
- عبر
- إلى
- أداة
- الإجمالي
- قادة الإيمان
- الأشجار
- صحيح
- عادة
- التي تقوم عليها
- فهم
- آخر التحديثات
- us
- تستخدم
- قيمنا
- القيم
- مختلف
- تحقق من
- مرئي
- ابحث عن
- التي
- في حين
- سوف
- كلمات
- جدير بالاهتمام
- سوف
- اكتب
- مكتوب
- X
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت
- صفر