شارك في التأليف مع ناريش و غوراف.
ستغطي هذه المقالة ماذا ولماذا وكيف يتم نقل التعلم.
- ابحث عن هو نقل التعلم
- لماذا يجب عليك استخدام نقل التعلم
- كيفية هل يمكنك استخدام نقل التعلم في مهمة تصنيف حقيقية؟
وعلى وجه التحديد، سنغطي الجوانب التالية لنقل التعلم.
- الدافع وراء فكرة نقل التعلم وفوائده.
- تطوير الحدس لاختيار النموذج الأساسي. (مفكرة)
- ناقش الخيارات المختلفة والمقايضات التي تمت على طول الطريق.
- تنفيذ مهمة تصنيف الصور باستخدام PyTorch. (مفكرة)
- مقارنة أداء النماذج الأساسية المختلفة.
- موارد لمعرفة المزيد حول نقل التعلم والوضع الحالي للفن
يعد نقل التعلم مجالًا كبيرًا ومتناميًا وتغطي هذه المقالة عددًا قليلاً من جوانبه. ومع ذلك، هناك العديد من مجتمعات التعلم العميق عبر الإنترنت التي تناقش نقل التعلم. على سبيل المثال، هنا مقالة جيدة حول كيفية الاستفادة من نقل التعلم للوصول إلى معايير أعلى من نماذج التدريب من الصفر.
الجمهور المستهدف والمتطلبات الأساسية
- أنت على دراية بمفاهيم التعلم الآلي الأساسية (ML)، مثل تحديد نماذج التصنيف والتدريب عليها
- أنت على دراية PyTorch و الشعلة
في القسم التالي، سنقدم رسميًا نقل التعلم ونشرحه بالأمثلة.
ما هو نقل التعلم؟
من هذه الصفحة,
"نقل التعلم هو أسلوب للتعلم الآلي حيث يتم إعادة استخدام النموذج الذي تم تطويره لمهمة ما كنقطة بداية لنموذج في مهمة ثانية."
نموذج التعلم العميق عبارة عن شبكة من الأوزان التي تم تحسين قيمها باستخدام دالة الخسارة أثناء تقدم التدريب. عادةً ما تتم تهيئة أوزان الشبكة بشكل عشوائي قبل بدء عملية التدريب. في نقل التعلم، نستخدم أ نموذج مدرب مسبقًا التي تم تدريبها على مهمة ذات صلة. وهذا يعطينا مجموعة من الأوزان الأولية التي من المحتمل أن تؤدي أداءً أفضل من الأوزان التي تمت تهيئتها بشكل عشوائي. نقوم بتحسين الأوزان المدربة مسبقًا بشكل أكبر لمهمتنا المحددة.
جيريمي هوارد (من fast.ai) يقول.
"حيثما أمكن، يجب أن تهدف إلى بدء التدريب على الشبكة العصبية الخاصة بك باستخدام نموذج مُدرب مسبقًا وضبطه. أنت حقًا لا تريد أن تبدأ بأوزان عشوائية، لأن هذا يعني أنك تبدأ بنموذج لا يعرف كيف يفعل أي شيء على الإطلاق! ومع التدريب المسبق، يمكنك استخدام بيانات أقل بمقدار 1000 مرة من البدء من الصفر.
أدناه، سنرى كيف يمكن للمرء أن يفكر في مفهوم نقل التعلم من حيث صلته بالبشر.
القياس البشري لنقل التعلم
- تدريب نموذجي: بعد ولادة الطفل، يستغرق الأمر بعض الوقت ليتعلم الوقوف والتوازن والمشي. خلال هذا الوقت، يمرون بمرحلة بناء العضلات الجسدية، ويتعلم دماغهم فهم واستيعاب مهارات الوقوف والتوازن والمشي. يمرون بعدة محاولات، بعضها ناجح وبعضها فاشل، للوصول إلى مرحلة يمكنهم فيها الوقوف والتوازن والمشي بشيء من الثبات. يشبه هذا تدريب نموذج التعلم العميق الذي يستغرق الكثير من الوقت (عصور التدريب) لتعلم مهمة عامة (مثل تصنيف صورة على أنها تنتمي إلى أحد فئات ImageNet الـ 1000) عندما يتم تدريبها على هذه المهمة.
- نقل التعلم: الطفل الذي تعلم المشي يجد أنه من الأسهل بكثير تعلم المهارات المتقدمة ذات الصلة مثل القفز والجري. يشبه نقل التعلم هذا الجانب من التعلم البشري حيث يتم الاستفادة من النموذج المُدرب مسبقًا والذي تعلم بالفعل مهارات عامة للتدريب بكفاءة على المهام الأخرى ذات الصلة.
الآن بعد أن قمنا ببناء فهم بديهي للتعلم النقلي وقياسه على التعلم البشري، دعنا نلقي نظرة على سبب استخدام التعلم النقلي لنماذج تعلم الآلة.
لماذا يجب علي استخدام نقل التعلم؟
تختلف العديد من مهام الذكاء الاصطناعي للرؤية، مثل تصنيف الصور أو تجزئة الصورة أو توطين الكائنات أو اكتشافها، فقط في الكائنات المحددة التي تقوم بتصنيفها أو تقسيمها أو اكتشافها. لقد تعلمت النماذج التي تم تدريبها على هذه المهام ميزات الكائنات الموجودة في مجموعة بيانات التدريب الخاصة بها. وبالتالي، يمكن تكييفها بسهولة مع المهام ذات الصلة. على سبيل المثال، يمكن ضبط النموذج الذي تم تدريبه للتعرف على وجود سيارة في الصورة بشكل دقيق للتعرف على قطة أو كلب.
الميزة الرئيسية لنقل التعلم هي القدرة على تمكينك من تحقيق دقة أفضل في مهامك. ويمكننا أن نقسم مزاياها على النحو التالي:
- كفاءة التدريب: عندما تبدأ بنموذج تم تدريبه مسبقًا وتعلم بالفعل الميزات العامة للبيانات، فلن تحتاج إلا إلى ذلك ضبط دقيق النموذج لمهمتك المحددة، والتي يمكن تنفيذها بسرعة أكبر (أي استخدام فترات تدريب أقل).
- دقة النموذج: استخدام نقل التعلم يمكن أن يمنحك تعزيز كبير للأداء مقارنة بتدريب نموذج من الصفر باستخدام نفس القدر من الموارد. من المهم أيضًا اختيار النموذج المناسب الذي تم تدريبه مسبقًا لنقل التعلم لمهمتك المحددة.
- حجم بيانات التدريب: نظرًا لأن النموذج الذي تم تدريبه مسبقًا قد تعلم بالفعل كيفية تحديد العديد من الميزات التي تتداخل مع الميزات الخاصة بمهمتك، فيمكنك تدريب النموذج الذي تم تدريبه مسبقًا باستخدام بيانات أقل خاصة بالمجال. يعد هذا مفيدًا إذا لم يكن لديك قدر كبير من البيانات المصنفة لمهمتك المحددة.
إذًا، كيف يمكننا أن نقوم بنقل التعلم عمليًا؟ يطبق القسم التالي نقل التعلم في PyTorch لمهمة تصنيف الزهور.
لإجراء نقل التعلم باستخدام PyTorch، نحتاج أولاً إلى تحديد مجموعة بيانات ونموذج رؤية مُدرب مسبقًا لتصنيف الصور. تركز هذه المقالة على استخدام torch-vision (مكتبة المجال المستخدمة مع PyTorch). دعونا نفهم أين يمكن العثور على مثل هذه النماذج ومجموعات البيانات المدربة مسبقًا.
أين يمكن العثور على نماذج رؤية مدربة مسبقًا لتصنيف الصور؟
هناك الكثير من مواقع الويب التي تقدم نماذج عالية الجودة لتصنيف الصور مدربة مسبقًا. على سبيل المثال:
ولأغراض هذه المقالة سوف نستخدم نماذج مدربة مسبقًا من torchvision. من المفيد أن نتعلم قليلاً عن كيفية تدريب هذه النماذج. دعونا نستكشف هذا السؤال بعد ذلك!
ما هي مجموعات البيانات التي تم تدريب نماذج torchvision عليها مسبقًا؟
بالنسبة للمهام المتعلقة بالرؤية التي تتضمن صورًا، عادةً ما يتم تدريب نماذج torchvision مسبقًا على مجموعة بيانات ImageNet. تحتوي مجموعة ImageNet الفرعية الأكثر شيوعًا التي يستخدمها الباحثون ولنماذج الرؤية النموذجية قبل التدريب على حوالي 1.2 مليون صورة عبر 1000 فئة. يتم استخدام تصنيف ImageNet كمهمة تدريب مسبق للأسباب التالية:
- إنه جاهز توفر إلى مجتمع البحث
- • سعة والصور المتنوعة التي يحتوي عليها
- استخدامه من قبل العديد من الباحثين - مما يجعله جذابًا لمقارنة النتائج باستخدام أ القاسم المشترك تصنيف Imagenet 1K
يمكنك قراءة المزيد عن تاريخ تحدي ImageNet والخلفية التاريخية والمعلومات حول مجموعة البيانات الكاملة في هذا الشأن صفحة ويكيبيديا.
الاعتبارات القانونية عند استخدام النماذج المدربة مسبقًا
تم إصدار ImageNet لأغراض بحثية غير تجارية فقط (https://image-net.org/download). ومن ثم، ليس من الواضح ما إذا كان يمكن قانونيًا استخدام الأوزان من نموذج تم تدريبه مسبقًا على ImageNet لأغراض تجارية. إذا كنت تخطط للقيام بذلك، يرجى طلب المشورة القانونية.
الآن بعد أن عرفنا أين يمكننا العثور على النماذج المدربة مسبقًا التي سنستخدمها لنقل التعلم، دعنا نلقي نظرة على المكان الذي يمكننا فيه شراء مجموعة البيانات التي نرغب في استخدامها لمهمة التصنيف المخصصة لدينا.
مجموعة البيانات: زهور أكسفورد 102
سنستخدم مجموعة بيانات Flowers 102 لتوضيح نقل التعلم باستخدام PyTorch. سوف نقوم بتدريب نموذج لتصنيف الصور في الزهور 102 مجموعة البيانات في واحدة من 102 فئة. هذه مشكلة تصنيف متعددة الفئات (ذات تسمية واحدة) تكون فيها الفئات المتوقعة متنافية. سنستفيد من Torchvision لهذه المهمة منذ ذلك الحين يوفر مجموعة البيانات هذه لكي نستخدمها.
تم الحصول على مجموعة بيانات Flowers 102 من مجموعة الهندسة البصرية في أكسفورد. يرجى الاطلاع على صفحة شروط الترخيص لاستخدام مجموعة البيانات.
بعد ذلك، دعونا نلقي نظرة على الخطوات رفيعة المستوى المتضمنة في هذه العملية.
كيف يعمل نقل التعلم؟
يمكن الاطلاع على نقل التعلم لمهام تصنيف الصور كسلسلة من ثلاث خطوات كما هو موضح في الشكل 1. هذه الخطوات هي كما يلي:
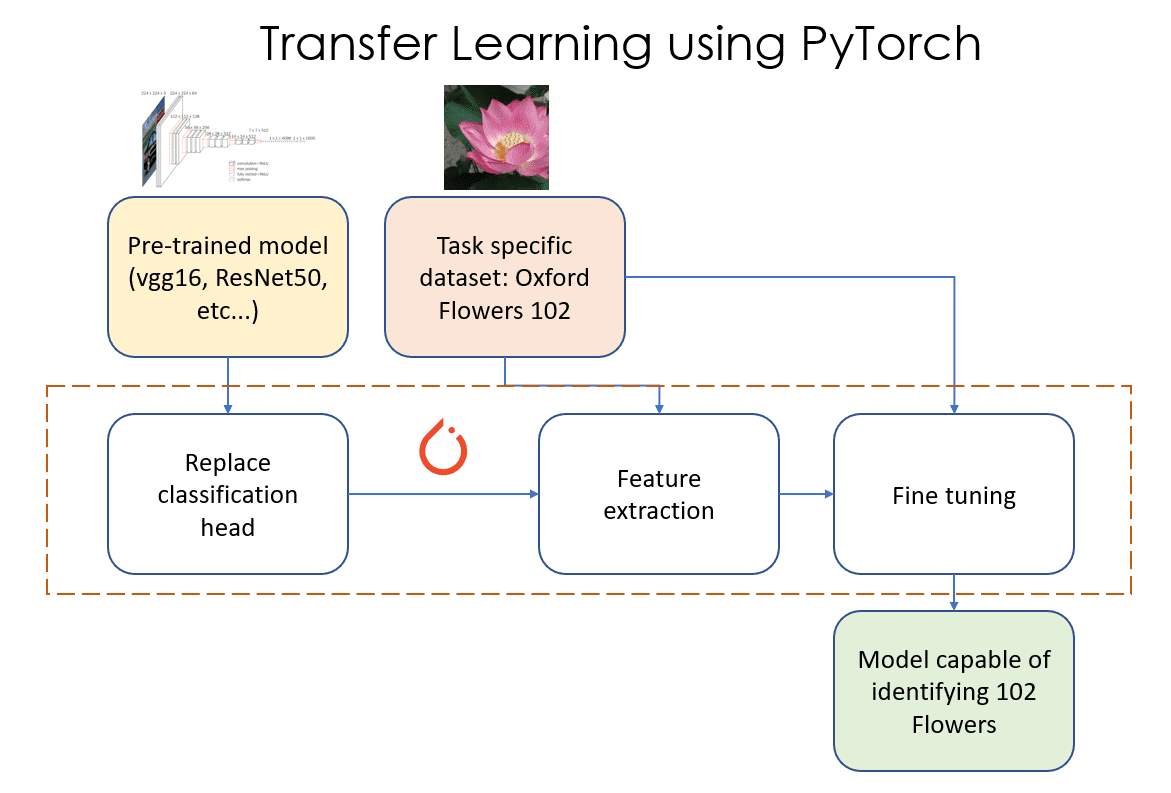
الشكل 1: نقل التعلم باستخدام PyTorch. المصدر: المؤلف (المؤلفون)
- استبدال طبقة المصنف: في هذه المرحلة نقوم بتحديد واستبدال الأخير “رئيس التصنيف" لنموذجنا المُدرب مسبقًا مع "رأس التصنيف" الخاص بنا والذي يحتوي على العدد الصحيح من ميزات الإخراج (102 في هذا المثال).
- ميزة استخراج: في هذه المرحلة، نقوم بتجميد (جعل تلك الطبقات غير قابلة للتدريب) جميع طبقات النموذج باستثناء طبقة التصنيف المضافة حديثًا، وندرب هذه الطبقة المضافة حديثًا فقط.
- ضبط دقيق: في هذه المرحلة، نقوم بإلغاء تجميد بعض المجموعات الفرعية من الطبقات في النموذج (إلغاء تجميد الطبقة يعني جعلها قابلة للتدريب). في هذه المقالة، سنقوم بإلغاء تجميد جميع طبقات النموذج وتدريبها كما نقوم بتدريب أي نموذج PyTorch للتعلم الآلي (ML).
تحتوي كل مرحلة من هذه المراحل على الكثير من التفاصيل الإضافية والفروق الدقيقة التي نحتاج إلى معرفتها والقلق بشأنها. وسندخل في تلك التفاصيل قريبا. في الوقت الحالي، دعونا نتعمق في مرحلتين أساسيتين، وهما استخراج الميزات والضبط الدقيق أدناه.
استخراج الميزة وضبطها
يمكنك العثور على مزيد من المعلومات حول استخراج الميزات وضبطها هنا.
توضح الرسوم البيانية أدناه استخراج الميزات والضبط الدقيق بصريًا.
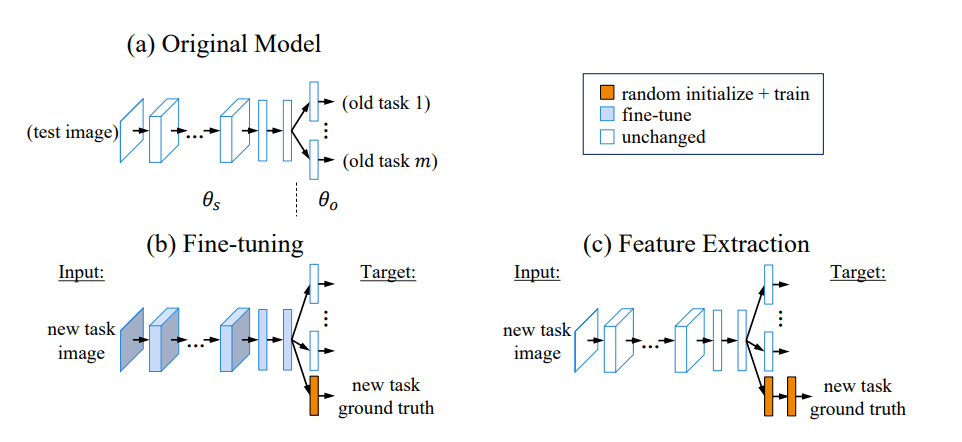
الشكل 2: شرح مرئي للضبط الدقيق (ب) واستخراج الميزات (ج). مصدر: التعلم دون نسيان
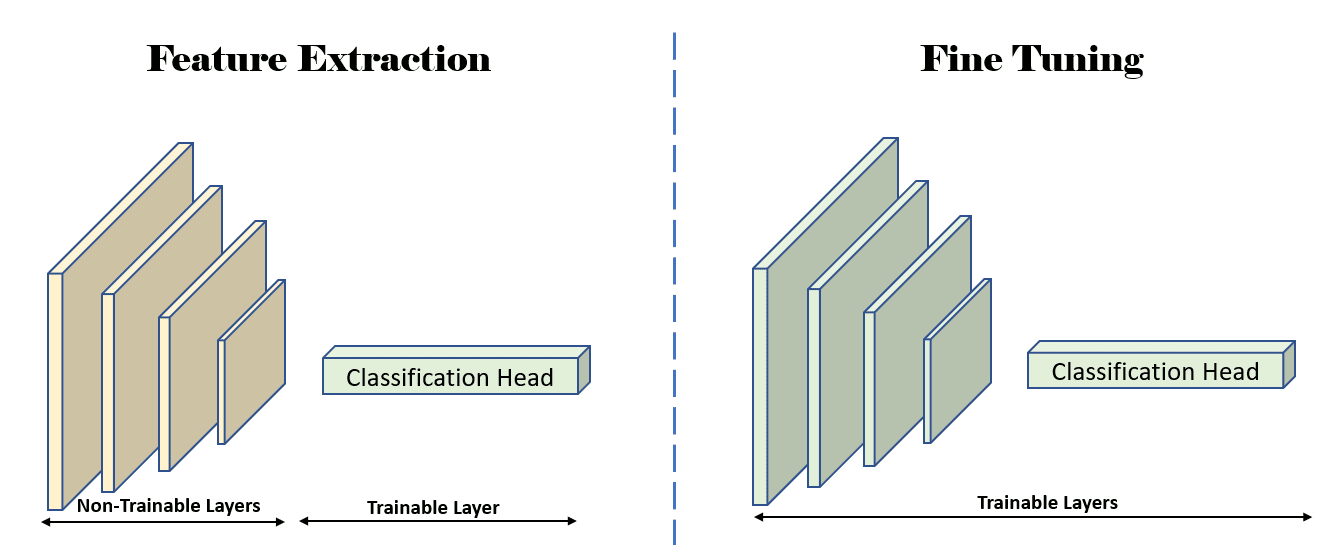
الشكل 3: رسم توضيحي يوضح الطبقات القابلة للتدريب (غير المجمدة) أثناء مراحل استخراج الميزات والضبط الدقيق. المصدر: المؤلف (المؤلفون)
الآن بعد أن طورنا فهمًا جيدًا لمهمة التصنيف المخصصة، والنموذج المُدرب مسبقًا الذي سنستخدمه لهذه المهمة، وكيفية عمل التعلم النقلي، دعونا نلقي نظرة على بعض التعليمات البرمجية الملموسة التي تنفذ التعلم النقلي.
ستتعلم في هذا القسم مفاهيم مثل التحليل الاستكشافي للنموذج، واختيار النموذج الأولي، وكيفية تحديد النموذج، وتنفيذ خطوات تعلم النقل (التي تمت مناقشتها أعلاه)، وكيفية منع التجهيز الزائد. سنناقش تقسيم التدريب/التقييم/الاختبار لمجموعة البيانات هذه وتفسير النتائج.
يمكن العثور على الكود الكامل لهذه التجربة هنا (تصنيف Flowers102 باستخدام نماذج مدربة مسبقًا). القسم الخاص بتحليل النموذج الاستكشافي موجود في أ دفتر منفصل.
تحليل النموذج الاستكشافي
على غرار تحليل البيانات الاستكشافية في علم البيانات، فإن الخطوة الأولى في نقل التعلم هي تحليل النماذج الاستكشافية. في هذه الخطوة، نستكشف جميع النماذج المدربة مسبقًا والمتوفرة لمهام تصنيف الصور، ونحدد كيفية هيكلة كل منها.
بشكل عام، من الصعب معرفة النموذج الذي سيحقق أفضل أداء لمهمتنا، لذلك ليس من غير المألوف تجربة بعض النماذج التي تبدو واعدة أو قابلة للتطبيق في حالتنا. في هذا السيناريو الافتراضي، لنفترض أن حجم النموذج ليس مهمًا (لا نريد نشر هذه النماذج على الأجهزة المحمولة أو الأجهزة المتطورة). سنلقي نظرة أولاً على قائمة نماذج التصنيف المتاحة المدربة مسبقًا في torchvision.
classification_models = torchvision.models.list_models(module=torchvision.models) print(len(classification_models), "classification models:", classification_models)
سوف طباعة
80 classification models: ['alexnet', 'convnext_base', 'convnext_large', 'convnext_small', 'convnext_tiny', 'densenet121', 'densenet161', 'densenet169', 'densenet201', 'efficientnet_b0', 'efficientnet_b1', 'efficientnet_b2', 'efficientnet_b3', 'efficientnet_b4', 'efficientnet_b5', 'efficientnet_b6', 'efficientnet_b7', 'efficientnet_v2_l', 'efficientnet_v2_m', 'efficientnet_v2_s', 'googlenet', 'inception_v3', 'maxvit_t', 'mnasnet0_5', 'mnasnet0_75', 'mnasnet1_0', 'mnasnet1_3', 'mobilenet_v2', 'mobilenet_v3_large', 'mobilenet_v3_small', 'regnet_x_16gf', 'regnet_x_1_6gf', 'regnet_x_32gf', 'regnet_x_3_2gf', 'regnet_x_400mf', 'regnet_x_800mf', 'regnet_x_8gf', 'regnet_y_128gf', 'regnet_y_16gf', 'regnet_y_1_6gf', 'regnet_y_32gf', 'regnet_y_3_2gf', 'regnet_y_400mf', 'regnet_y_800mf', 'regnet_y_8gf', 'resnet101', 'resnet152', 'resnet18', 'resnet34', 'resnet50', 'resnext101_32x8d', 'resnext101_64x4d', 'resnext50_32x4d', 'shufflenet_v2_x0_5', 'shufflenet_v2_x1_0', 'shufflenet_v2_x1_5', 'shufflenet_v2_x2_0', 'squeezenet1_0', 'squeezenet1_1', 'swin_b', 'swin_s', 'swin_t', 'swin_v2_b', 'swin_v2_s', 'swin_v2_t', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'vit_b_16', 'vit_b_32', 'vit_h_14', 'vit_l_16', 'vit_l_32', 'wide_resnet101_2', 'wide_resnet50_2']
رائع! هذه قائمة كبيرة جدًا من النماذج للاختيار من بينها! إذا كنت تشعر بالارتباك، فلا تقلق - في القسم التالي، سنلقي نظرة على العوامل التي يجب مراعاتها عند اختيار المجموعة الأولية من النماذج لتنفيذ التعلم النقلي.
اختيار النموذج الأولي
والآن بعد أن أصبح لدينا قائمة تضم 80 نموذجًا مرشحًا للاختيار من بينها، نحتاج إلى تضييق نطاقها إلى عدد قليل من النماذج التي يمكننا إجراء التجارب عليها. يعد اختيار العمود الفقري للنموذج الذي تم تدريبه مسبقًا بمثابة معلمة مفرطة، ويمكننا (ويجب علينا) استكشاف خيارات متعددة عن طريق إجراء التجارب لمعرفة أي منها يعمل بشكل أفضل. يعد إجراء التجارب أمرًا مكلفًا ويستغرق وقتًا طويلاً، ومن غير المرجح أن نتمكن من تجربة جميع النماذج، ولهذا السبب نحاول تضييق القائمة إلى 3-4 نماذج في البداية.
قررنا أن نبدأ بالنماذج الأساسية التالية المدربة مسبقًا.
- Vgg16: 135 مليون معلمة
- ResNet50: 23 مليون معلمة
- ResNet152: 58 مليون معلمة
وإليك كيف/لماذا اخترنا هؤلاء الثلاثة في البداية.
- نحن لسنا مقيدين بحجم النموذج أو زمن الاستجابة الاستدلالي، لذلك لا نحتاج إلى العثور على النماذج فائقة الكفاءة. إذا كنت ترغب في دراسة مقارنة لنماذج الرؤية المختلفة للأجهزة المحمولة، يرجى قراءة الورقة التي تحمل عنوان "مقارنة وقياس نماذج وأطر الذكاء الاصطناعي على الأجهزة المحمولة".
- تحظى النماذج التي نختارها بشعبية كبيرة في مجتمع Vision ML وتميل إلى أن تكون اختيارات جيدة لمهام التصنيف. يمكنك استخدام عدد الاستشهادات للأبحاث المتعلقة بهذه النماذج كمؤشرات مناسبة لمدى فعالية هذه النماذج. ومع ذلك، يرجى الانتباه إلى التحيز المحتمل حيث أن الأوراق البحثية الخاصة بنماذج مثل AlexNet والتي كانت موجودة منذ فترة طويلة ستحتوي على عدد أكبر من الاستشهادات على الرغم من عدم استخدامها في أي مهمة تصنيف جدية كخيار افتراضي.
- حتى داخل بنيات النماذج، هناك العديد من النكهات أو الأحجام للنماذج. على سبيل المثال، يأتي EfficientNet في فئات تسمى B0 إلى B7. يرجى الرجوع إلى الأوراق الخاصة بالنماذج المحددة للحصول على تفاصيل حول ما تعنيه هذه الزخارف.
عدد الاستشهادات لمختلف الأوراق حول نماذج التصنيف المدربة مسبقًا والمتوفرة في torchvision.
- ريسنت: 165 ألف
- أليكس نت: 132 ألفًا
- Vgg16: 102 كيلو
- موبايل نت: 19 ألف
- محولات الرؤية: 16 كيلو
- شبكة فعالة: 12 كيلو
- شفل نت: 6 كيلو
إذا كنت ترغب في قراءة المزيد عن العوامل التي قد تؤثر على اختيارك للنموذج المُدرب مسبقًا، فيرجى قراءة المقالات التالية:
- 4 نماذج CNN مُدربة مسبقًا لاستخدامها في رؤية الكمبيوتر مع نقل التعلم
- كيف تختار أفضل نموذج تم تدريبه مسبقًا لشبكتك العصبية التلافيفية؟
- التحليل المعياري لبنيات الشبكات العصبية التمثيلية العميقة
دعونا نتحقق من رؤوس التصنيف لهذه النماذج.
vgg16 = torchvision.models.vgg16_bn(weights=None)
resnet50 = torchvision.models.resnet50(weights=None)
resnet152 = torchvision.models.resnet152(weights=None) print("vgg16n", vgg16.classifier)
print("resnet50n", resnet50.fc)
print("resnet152n", resnet152.fc)
vgg16 Sequential( (0): Linear(in_features=25088, out_features=4096, bias=True) (1): ReLU(inplace=True) (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU(inplace=True) (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=4096, out_features=1000, bias=True)
)
resnet50 Linear(in_features=2048, out_features=1000, bias=True)
resnet152 Linear(in_features=2048, out_features=1000, bias=True)
يمكنك العثور على دفتر الملاحظات الكامل ل تحليل النموذج الاستكشافي هنا.
نظرًا لأننا سنقوم بإجراء تجارب على 3 نماذج تم تدريبها مسبقًا وتنفيذ التعلم النقلي على كل منها على حدة، فلنحدد بعض التجريدات والفئات التي ستساعدنا في تشغيل هذه التجارب وتتبعها.
تحديد نموذج PyTorch لتغليف النماذج المدربة مسبقًا
للسماح بالاستكشاف السهل، سنقوم بتعريف نموذج PyTorch باسم Flowers102Classifier، واستخدامه خلال هذا التمرين. سنضيف وظائف تدريجية إلى هذه الفئة حتى نحقق هدفنا النهائي. دفتر الملاحظات الكامل ل يمكن العثور على نقل التعلم لتصنيف الزهور 102 هنا.
سوف تتعمق الأقسام أدناه في كل خطوة من الخطوات الميكانيكية اللازمة لتنفيذ التعلم النقلي.
استبدال رأس التصنيف القديم بآخر جديد
يحتوي رأس التصنيف الحالي لكل نموذج من هذه النماذج، والذي تم تدريبه مسبقًا على مهمة تصنيف ImageNet، على 1000 ميزة إخراج. تحتوي مهمتنا المخصصة لتصنيف الزهور على 102 ميزة إخراج. وبالتالي، نحن بحاجة إلى استبدال رأس التصنيف النهائي (الطبقة) بآخر جديد يحتوي على 102 ميزة إخراج.
سيتضمن مُنشئ فصلنا كودًا يقوم بتحميل النموذج المُدرب مسبقًا محل الاهتمام من torchvision باستخدام أوزان مدربة مسبقًا، وسيستبدل رأس التصنيف برأس تصنيف مخصص لـ 102 فئة.
def __init__(self, backbone, load_pretrained): super().__init__() assert backbone in backbones self.backbone = backbone self.pretrained_model = None self.classifier_layers = [] self.new_layers = [] if backbone == "resnet50": if load_pretrained: self.pretrained_model = torchvision.models.resnet50( weights=torchvision.models.ResNet50_Weights.IMAGENET1K_V2 ) else: self.pretrained_model = torchvision.models.resnet50(weights=None) # end if self.classifier_layers = [self.pretrained_model.fc] # Replace the final layer with a classifier for 102 classes for the Flowers 102 dataset. self.pretrained_model.fc = nn.Linear( in_features=2048, out_features=102, bias=True ) self.new_layers = [self.pretrained_model.fc] elif backbone == "resnet152": if load_pretrained: self.pretrained_model = torchvision.models.resnet152( weights=torchvision.models.ResNet152_Weights.IMAGENET1K_V2 ) else: self.pretrained_model = torchvision.models.resnet152(weights=None) # end if self.classifier_layers = [self.pretrained_model.fc] # Replace the final layer with a classifier for 102 classes for the Flowers 102 dataset. self.pretrained_model.fc = nn.Linear( in_features=2048, out_features=102, bias=True ) self.new_layers = [self.pretrained_model.fc] elif backbone == "vgg16": if load_pretrained: self.pretrained_model = torchvision.models.vgg16_bn( weights=torchvision.models.VGG16_BN_Weights.IMAGENET1K_V1 ) else: self.pretrained_model = torchvision.models.vgg16_bn(weights=None) # end if self.classifier_layers = [self.pretrained_model.classifier] # Replace the final layer with a classifier for 102 classes for the Flowers 102 dataset. self.pretrained_model.classifier[6] = nn.Linear( in_features=4096, out_features=102, bias=True ) self.new_layers = [self.pretrained_model.classifier[6]]
نظرًا لأننا سنقوم باستخراج الميزات متبوعًا بالضبط الدقيق، فسنحفظ الطبقات المضافة حديثًا في قائمة self.new_layers. سيساعدنا هذا في تحديد أوزان تلك الطبقات على أنها قابلة للتدريب أو غير قابلة للتدريب اعتمادًا على ما نقوم به.
الآن بعد أن استبدلنا رأس التصنيف الأقدم برأس تصنيف جديد يحتوي على أوزان مبدئية بشكل عشوائي، سنحتاج إلى تدريب تلك الأوزان حتى يتمكن النموذج من إجراء تنبؤات دقيقة. يتضمن ذلك استخراج الميزات والضبط الدقيق وسنلقي نظرة على ذلك بعد ذلك.
نقل التعلم (المعلمات القابلة للتدريب ومعدلات التعلم)
يتضمن نقل التعلم تشغيل استخراج الميزات والضبط الدقيق بهذا الترتيب المحدد. دعونا نلقي نظرة فاحصة على سبب الحاجة إلى تشغيلها بهذا الترتيب وكيف يمكننا التعامل مع المعلمات القابلة للتدريب لمختلف مراحل نقل التعلم.
ميزة استخراج: قمنا بتعيين require_grad على False للأوزان في جميع الطبقات في النموذج، وقمنا بتعيين require_grad على True للطبقات المضافة حديثًا فقط.
نقوم بتدريب الطبقة (الطبقات) الجديدة من أجل 16 حقب مع معدل التعلم 1e-3. يضمن ذلك أن الطبقة (الطبقات) الجديدة قادرة على ضبط وتكييف أوزانها مع الأوزان الموجودة في جزء مستخرج الميزات في الشبكة. من المهم تجميد بقية الطبقات في الشبكة وتدريب الطبقة (الطبقات) الجديدة فقط حتى لا نصدم الشبكة وننسى ما تعلمته بالفعل. إذا لم نقوم بتجميد الطبقات السابقة، فسينتهي الأمر بإعادة تدريبهم على الأوزان غير المرغوب فيها التي تمت تهيئتها بشكل عشوائي عندما أضفنا رأس التصنيف الجديد.
الكون المثالى: قمنا بتعيين require_grad على True للأوزان في جميع طبقات النموذج. نحن ندرب الشبكة بأكملها من أجل 8 حقب. ومع ذلك، فإننا نعتمد استراتيجية معدل التعلم التفاضلي في هذه الحالة. نقوم بتخفيض معدل التعلم (LR) بحيث يتناقص LR أثناء تحركنا نحو طبقات الإدخال (بعيدًا عن رأس تصنيف المخرجات). نحن نخفض معدل التعلم أثناء تحركنا للأعلى في النموذج نحو الطبقات الأولية للنموذج لأن تلك الطبقات الأولية تعلمت الميزات الأساسية حول الصورة، والتي ستكون شائعة في معظم مهام الذكاء الاصطناعي للرؤية. ومن ثم، يتم تدريب الطبقات الأولية باستخدام LR منخفض جدًا لتجنب إزعاج ما تعلموه. بينما ننتقل إلى أسفل النموذج نحو رأس التصنيف، يتعلم النموذج شيئًا محددًا بمهمة معينة، لذلك فمن المنطقي تدريب تلك الطبقات اللاحقة باستخدام LR أعلى. يمكن للمرء أن يعتمد استراتيجيات مختلفة هنا، وفي حالتنا، نستخدم استراتيجيتين مختلفتين لتوضيح فعالية كل منهما.
- VGG16: بالنسبة لشبكة vgg16، نقوم بتحلل LR خطيا من LR=1e-4 إلى LR=1e-7 (1000x أقل من LR لطبقة التصنيف). نظرًا لوجود 44 طبقة في مرحلة استخراج المعالم، يتم تعيين LR لكل طبقة يكون (1e-7 - 1e-4)/44 = 2.3e-6 أقل من الطبقة السابقة.
- ريسنيت: بالنسبة لشبكة ResNet (50/152)، فإننا نتحلل LR بشكل كبير بدءًا من LR=1e-4. نقوم بتقليل LR بمقدار 3x لكل طبقة نتحرك للأعلى.
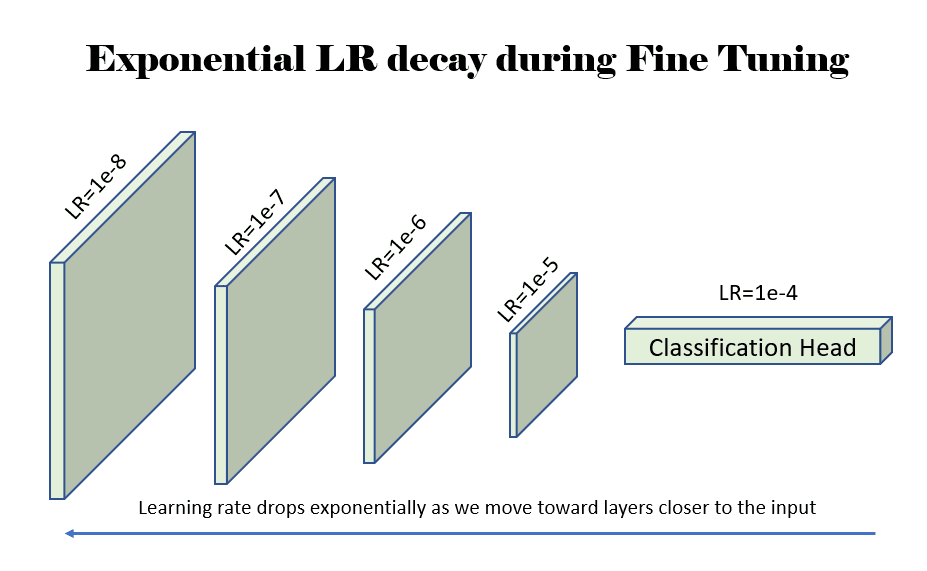
الشكل 4: مثال يوضح انخفاض معدل التعلم (LR) بشكل كبير بعامل 10 بينما نتحرك للأعلى نحو الطبقات الأقرب إلى مدخلات الشبكة. المصدر: المؤلف (المؤلفون).
يظهر رمز تجميد الطبقات لكل من استخراج الميزات بالإضافة إلى الضبط الدقيق في الوظيفة المسماة Fine_tune() أدناه.
def fine_tune(self, what: FineTuneType): # The requires_grad parameter controls whether this parameter is # trainable during model training. m = self.pretrained_model for p in m.parameters(): p.requires_grad = False if what is FineTuneType.NEW_LAYERS: for l in self.new_layers: for p in l.parameters(): p.requires_grad = True elif what is FineTuneType.CLASSIFIER: for l in self.classifier_layers: for p in l.parameters(): p.requires_grad = True else: for p in m.parameters(): p.requires_grad = True
مقتطف التعليمات البرمجية: تجميد المعلمات وإلغاء تجميدها باستخدام require_grad أثناء مرحلة استخراج الميزات (NEW_LAYERS) والضبط الدقيق (ALL).
في PyTorch، تتمثل طريقة تعيين LRs التفاضلية لكل طبقة في تحديد الأوزان التي تحتاج إلى LR للمُحسِّن الذي سيتم استخدامه أثناء نقل التعلم. في دفتر ملاحظاتنا، نستخدم مُحسِّن Adam. تحصل طريقة get_optimizer_params() أدناه على معلمات المُحسِّن لتمريرها إلى مُحسِّن Adam (أو غيره) الذي سنستخدمه.
def get_optimizer_params(self): """This method is used only during model fine-tuning when we need to set a linearly or exponentially decaying learning rate (LR) for the layers in the model. We exponentially decay the learning rate as we move away from the last output layer. """ options = [] if self.backbone == "vgg16": # For vgg16, we start with a learning rate of 1e-3 for the last layer, and # decay it to 1e-7 at the first conv layer. The intermediate rates are # decayed linearly. lr = 0.0001 options.append( { "params": self.pretrained_model.classifier.parameters(), "lr": lr, } ) final_lr = lr / 1000.0 diff_lr = final_lr - lr lr_step = diff_lr / 44.0 for i in range(43, -1, -1): options.append( { "params": self.pretrained_model.features[i].parameters(), "lr": lr + lr_step * (44 - i), } ) # end for elif self.backbone in ["resnet50", "resnet152"]: # For the resnet class of models, we decay the LR exponentially and reduce # it to a third of the previous value at each step. layers = ["conv1", "bn1", "layer1", "layer2", "layer3", "layer4", "fc"] lr = 0.0001 for layer_name in reversed(layers): options.append( { "params": getattr(self.pretrained_model, layer_name).parameters(), "lr": lr, } ) lr = lr / 3.0 # end for # end if return options # end def
مقتطف الكود: معدلات التعلم التفاضلية لكل طبقة عند ضبط النموذج.
بمجرد حصولنا على معلمات النموذج مع LRs الخاصة بها، يمكننا تمريرها إلى المحسن باستخدام سطر واحد من التعليمات البرمجية. يتم استخدام LR الافتراضي 1e-8 للمعلمات التي لم يتم تحديد أوزانها في القاموس الذي يتم إرجاعه بواسطة get_optimizer_params().
optimizer = torch.optim.Adam(fc.get_optimizer_params(), lr=1e-8)مقتطف التعليمات البرمجية: قم بتمرير المعلمات باستخدام LRs الخاصة بها إلى مُحسِّن Adam.
الآن بعد أن عرفنا كيفية تنفيذ التعلم النقلي، دعونا نلقي نظرة على الاعتبارات الأخرى التي نحتاج إلى وضعها في الاعتبار قبل ضبط نموذجنا. يتضمن ذلك الخطوات التي يتعين علينا اتخاذها لمنع التجهيز الزائد، واختيار تقسيم القطار/الفال/الاختبار المناسب.
منع التجهيز الزائد
لدينا في مفكرة، نحن نستخدم تقنيات زيادة البيانات التالية في بيانات التدريب لمنع التجهيز الزائد والسماح للنموذج بمعرفة الميزات حتى يتمكن من إجراء تنبؤات على البيانات غير المرئية.
- غضب اللون
- انعكاس أفقي
- تناوب
- قص
لا توجد زيادة في البيانات مطبقة على تقسيم التحقق من الصحة.
وينبغي للمرء أيضا استكشاف الوزن يتدهور، وهي تقنية تنظيم لمنع التجهيز الزائد عن طريق تقليل تعقيد النموذج.
قطار/فال/اختبار الانقسام
يوصي مؤلفو مجموعة بيانات Flowers 102 بتقسيم قطار/val/test بحجم 1020/1020/6149. العديد من المؤلفين يفعلون الأشياء بشكل مختلف. على سبيل المثال،
- في مجلة ResNet الضربات مرة أخرى ورقة، يستخدم المؤلفون تقسيم القطار + فال (2040 صورة) كمجموعة القطار، ومجموعة الاختبار كمجموعة الاختبار. ليس من الواضح ما إذا كان هناك تقسيم للتحقق من الصحة.
- في هذه المقالة على التصنيف على الزهور 102، يستخدم المؤلفون تقسيم الاختبار بالحجم 6149 كتقسيم القطار.
- في هذا مفكرة، يستخدم المؤلف تقسيم القطار/فال/الاختبار بالحجم 6552 و818 و819 على التوالي.
الطريقة الوحيدة لمعرفة المؤلف الذي يفعل ما هو قراءة الأوراق أو الكود.
في دفتر ملاحظاتنا (في هذه المقالة)، نستخدم تقسيم الحجم 6149 كتقسيم القطار وتقسيم الحجم 2040 كتقسيم التحقق من الصحة. نحن لا نستخدم تقسيم الاختبار، لأننا لا نحاول التنافس هنا حقًا.
في هذا الوقت، يجب أن تشعر بالقدرة على الزيارة هذا الكمبيوتر المحمول الذي ينفذ جميع الخطوات المذكورة أعلاه ويتم عرض نتائجها لك لعرضها. لا تتردد في استنساخ دفتر الملاحظات على Kaggle أو Google Colab وتشغيله بنفسك على وحدة معالجة الرسومات. إذا كنت تستخدم Google Colab، فستحتاج إلى إصلاح بعض المسارات حيث يتم تنزيل مجموعات البيانات والنماذج المدربة مسبقًا وحيث يتم تخزين أفضل الأوزان للنماذج المضبوطة بدقة.
أدناه، سنلقي نظرة على نتائج تجارب التعلم بالنقل!
النتائج
تحتوي النتائج على بعض المواضيع المشتركة التي سنستكشفها أدناه.
- بعد خطوة استخراج الميزة وحدها، تتمتع جميع الشبكات تقريبًا بدقة تتراوح بين 91% و94%
- تعمل جميع الشبكات تقريبًا بشكل جيد، حيث تحقق دقة تصل إلى 96+% بعد خطوة الضبط الدقيق. يوضح هذا أن خطوة الضبط الدقيق تساعد حقًا أثناء نقل التعلم.
هناك اختلاف كبير في عدد المعلمات في شبكتنا، حيث vgg16 عند 135 مليون معلمة، وResNet50 عند 23 مليون معلمة، وResNet152 عند 58 مليون معلمة. يشير هذا إلى أنه ربما يمكننا العثور على شبكة أصغر ذات دقة وأداء مماثلين.
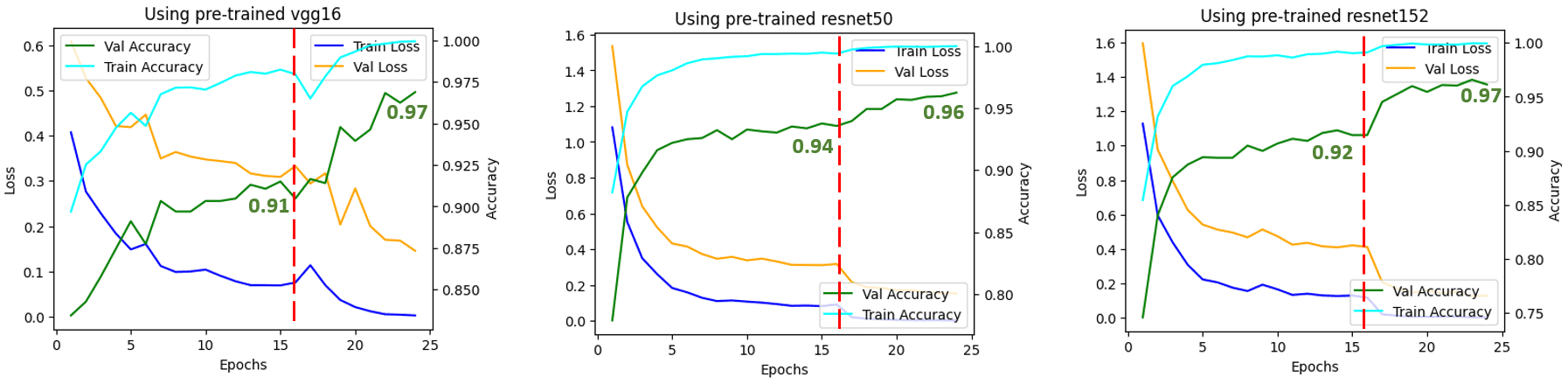
الشكل 5: خسارة التدريب/القيمة والدقة في عملية تعلم النقل. المصدر: المؤلف (المؤلفون).
يشير الخط الأحمر العمودي إلى العصر الذي تحولنا فيه من استخراج الميزات (16 حقبة) إلى الضبط الدقيق (8 حقب). يمكنك أن ترى أنه عندما تحولنا إلى الضبط الدقيق، أظهرت جميع الشبكات زيادة في الدقة. وهذا يدل على أن الضبط الدقيق بعد استخراج الميزة فعال للغاية.
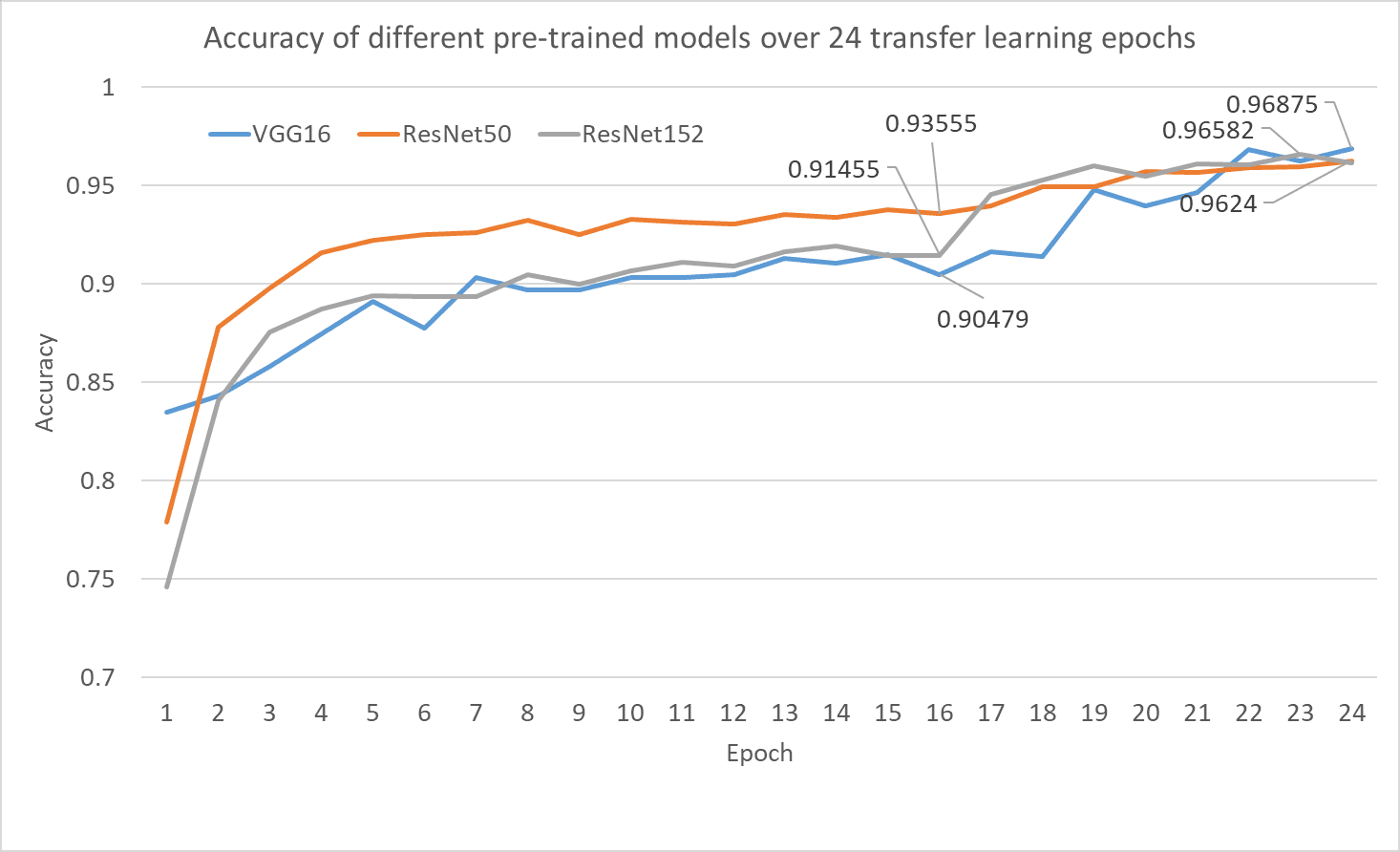
الشكل 6: دقة التحقق من صحة جميع النماذج الثلاثة المدربة مسبقًا بعد نقل التعلم في مهمة تصنيف الزهور. يتم عرض دقة التحقق من الصحة بعد استخراج الميزة في العصر 3 جنبًا إلى جنب مع أفضل دقة للتحقق من الصحة لكل نموذج أثناء مرحلة الضبط الدقيق. المصدر: المؤلف (المؤلفون).
- يعد نقل التعلم طريقة مقتصدة وفعالة لتدريب شبكتك من خلال البدء من شبكة مدربة مسبقًا في مهمة مماثلة ولكن غير ذات صلة
- توفر Torchvision العديد من النماذج التي تم تدريبها مسبقًا على ImageNet للباحثين لاستخدامها أثناء نقل التعلم
- كن حذرًا عند استخدام النماذج المدربة مسبقًا في الإنتاج للتأكد من عدم انتهاك أي تراخيص أو شروط استخدام لمجموعات البيانات التي تم تدريب النماذج عليها مسبقًا
- يشمل نقل التعلم استخراج الميزات والضبط الدقيق، والذي يجب تنفيذه بهذا الترتيب المحدد
الآن بعد أن عرفنا كيفية إجراء نقل التعلم لمهمة مخصصة بدءًا من نموذج تم تدريبه مسبقًا على مجموعة بيانات مختلفة، ألن يكون رائعًا إذا تمكنا من تجنب استخدام مجموعة بيانات منفصلة للتدريب المسبق (مهمة ذريعة) واستخدام مجموعة البيانات الخاصة بنا لهذا الغرض؟ وتبين أن هذا أصبح ممكنا!
في الآونة الأخيرة، تم استخدام الباحثين والممارسين التعلم تحت الإشراف الذاتي كوسيلة لأداء التدريب المسبق للنموذج (تعلم مهمة الذريعة) والتي لها فائدة تدريب النموذج على مجموعة بيانات بنفس التوزيع مثل مجموعة البيانات المستهدفة التي من المفترض أن يستهلكها النموذج في الإنتاج. إذا كنت مهتمًا بمعرفة المزيد عن التدريب المسبق الخاضع للإشراف الذاتي والتدريب المسبق الهرمي، فيرجى الاطلاع على هذه الورقة البحثية الصادرة في عام 2021 بعنوان يعمل التدريب المسبق الخاضع للإشراف الذاتي على تحسين التدريب المسبق الخاضع للإشراف الذاتي.
إذا كنت تمتلك البيانات الخاصة بمهمتك المحددة، فيمكنك استخدام التعلم الخاضع للإشراف الذاتي للتدريب المسبق لنموذجك ولا تقلق بشأن استخدام مجموعة بيانات ImageNet لخطوة ما قبل التدريب، وبالتالي البقاء في وضع واضح فيما يتعلق باستخدام ImageNet مجموعة البيانات المعنية.
- رأس التصنيف: في PyTorch، هذا هو ن.خطي طبقة تقوم بتعيين العديد من ميزات الإدخال لمجموعة من ميزات الإخراج
- تجميد الأوزان: جعل الأوزان غير قابلة للتدريب. في PyTorch، يتم ذلك عن طريق الإعداد require_grad=False
- قم بفك تجميد (أو ذوبان) الأوزان: جعل الأوزان قابلة للتدريب. في PyTorch، يتم ذلك عن طريق الإعداد require_grad=True
- التعلم بإشراف ذاتي: طريقة لتدريب نموذج تعلم الآلة بحيث يمكن تدريبه على البيانات دون أي تسميات من صنع الإنسان. يمكن أن يتم إنشاء التسميات تلقائيًا أو يتم إنشاؤها آليًا
دروف ماتاني هو من عشاق التعلم الآلي ويركز على PyTorch وCNNs وVision وSpeech وText AI. وهو خبير في الذكاء الاصطناعي على الأجهزة، وتحسين النماذج وتقديرها، وتعلم الآلة والبنية التحتية للبيانات. قم بتأليف فصل عن PyTorch الفعال في كتاب التعلم العميق الفعال على https://efficientdlbook.com/. آراؤه خاصة به، وليست آراء أي من أصحاب العمل لديه؛ الماضي أو الحاضر أو المستقبل.
ناريش مهتم بشدة بالجانب "التعلمي" للشبكة العصبية. يركز عمله على بنيات الشبكات العصبية وكيف تعمل التغييرات الطوبولوجية البسيطة على تعزيز قدرات التعلم. وقد شغل مناصب هندسية في Microsoft وAmazon وCitrix خلال مسيرته المهنية التي استمرت لعقد من الزمن. لقد شارك في مجال التعلم العميق على مدار 6-7 سنوات الماضية. يمكنك العثور عليه على المتوسط على https://medium.com/u/1e659a80cffd.
غوراف هو مهندس برمجيات للموظفين في Google Research حيث يقود مشاريع بحثية موجهة نحو تحسين نماذج التعلم الآلي الكبيرة من أجل التدريب الفعال والاستدلال على الأجهزة التي تتراوح من وحدات التحكم الدقيقة الصغيرة إلى الخوادم المستندة إلى وحدة معالجة Tensor (TPU). لقد أثر عمله بشكل إيجابي على أكثر من مليار مستخدم نشط عبر YouTube والسحابة والإعلانات وChrome وما إلى ذلك. وهو أيضًا مؤلف كتاب قادم مع منشورات Manning حول التعلم الآلي الفعال. قبل Google، عمل غوراف في Facebook لمدة 1 سنوات وساهم بشكل كبير في نظام بحث Facebook وقواعد البيانات الموزعة واسعة النطاق. حصل على درجة الماجستير في علوم الكمبيوتر من جامعة ستوني بروك.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- تمويل EVM. واجهة موحدة للتمويل اللامركزي. الوصول هنا.
- مجموعة كوانتوم ميديا. تضخيم IR / PR. الوصول هنا.
- أفلاطونايستريم. ذكاء بيانات Web3. تضخيم المعرفة. الوصول هنا.
- المصدر https://www.kdnuggets.com/2023/06/practical-guide-transfer-learning-pytorch.html?utm_source=rss&utm_medium=rss&utm_campaign=a-practical-guide-to-transfer-learning-using-pytorch
- :لديها
- :يكون
- :ليس
- :أين
- ] [ص
- $ UP
- 1
- 10
- 102
- 11
- 12
- 16
- 2021
- 22
- 8
- 80
- a
- القدرة
- ماهرون
- من نحن
- فوق
- AC
- دقة
- دقيق
- التأهيل
- تحقيق
- في
- نشط
- ادم
- تكيف
- تكيف
- تضيف
- وأضاف
- إضافي
- تبنى
- متقدم
- مميزات
- مزايا
- نصيحة
- تؤثر
- بعد
- AI
- هدف
- الكل
- السماح
- وحده
- على طول
- سابقا
- أيضا
- أمازون
- كمية
- an
- تحليل
- و
- أي وقت
- اى شى
- ذو صلة
- تطبيقي
- هي
- حول
- فنـون
- البند
- مقالات
- AS
- جانب
- الجوانب
- تعيين
- At
- محاولات
- جذاب
- جمهور
- المؤلفة
- التأليف
- الكتاب
- تلقائيا
- متاح
- تجنب
- علم
- بعيدا
- العمود الفقري
- خلفية
- الرصيد
- قاعدة
- الأساسية
- BE
- لان
- أن تصبح
- كان
- قبل
- بدأ
- وراء
- أقل من
- المقارنة
- المعايير
- تستفيد
- الفوائد
- أفضل
- أفضل
- ما بين
- انحياز
- مليار
- قطعة
- كتاب
- مولود
- على حد سواء
- دماغ
- استراحة
- ابني
- بنيت
- لكن
- by
- CAN
- مرشح
- قدرات
- سيارة
- التوظيف
- حذر
- حقيبة
- قط
- الفئات
- تحدى
- التغييرات
- باب
- التحقق
- طفل
- خيار
- الخيارات
- اختار
- اختيار
- اختار
- الكروم
- فئة
- فصول
- تصنيف
- صنف
- واضح
- أقرب
- سحابة
- سي ان ان
- الكود
- يأتي
- تجاري
- مشترك
- المجتمعات
- مجتمع
- مماثل
- قارن
- مقارنة
- مقارنة
- تنافس
- إكمال
- تعقيد
- الكمبيوتر
- علوم الكمبيوتر
- رؤية الكمبيوتر
- مفهوم
- المفاهيم
- قلق
- الخلط
- نظر
- الاعتبارات
- مقيدة
- يحتوي
- ساهمت
- ضوابط
- شبكة عصبية تلافيفية
- مكلفة
- استطاع
- بهيكل
- تغطية
- ويغطي
- حالياًّ
- الوضع الحالي
- على
- البيانات
- تحليل البيانات
- البنية التحتية للبيانات
- علم البيانات
- قواعد البيانات
- قواعد البيانات
- قررت
- يقلل
- عميق
- غوص عميق
- التعلم العميق
- الشبكة العصبية العميقة
- أعمق
- الترتيب
- تحديد
- اعتمادا
- نشر
- التفاصيل
- تفاصيل
- كشف
- حدد
- المتقدمة
- الأجهزة
- الرسوم البيانية
- اختلف
- فرق
- مختلف
- بحث
- ناقش
- وزعت
- توزيع
- do
- هل
- لا
- كلب
- فعل
- نطاق
- فعل
- لا
- إلى أسفل
- اثنان
- أثناء
- e
- كل
- في وقت سابق
- أسهل
- بسهولة
- سهل
- حافة
- الطُرق الفعّالة
- فعالية
- فعال
- بكفاءة
- آخر
- تمكين
- تمكين
- النهاية
- مهندس
- الهندسة
- تعزيز
- ضمان
- يضمن
- متحمس
- كامل
- عصر
- عهود
- إلخ
- الأثير (ETH)
- حتى
- كل
- مثال
- أمثلة
- إلا
- حصري
- ممارسة
- القائمة
- تجربة
- تجارب
- خبير
- شرح
- تفسير
- استكشاف
- تحليل البيانات استكشافية
- اكتشف
- أضعافا مضاعفة
- استخلاص
- فيسبوك
- عامل
- العوامل
- بإنصاف
- زائف
- مألوف
- بعيدا
- FAST
- fc
- الميزات
- المميزات
- شعور
- قليل
- أقل
- حقل
- الشكل
- نهائي
- ويرى
- نهاية
- الأول
- أول نظرة
- حل
- نقف
- زهرة
- ويركز
- التركيز
- تركيزا
- يتبع
- متابعيك
- متابعات
- في حالة
- رسميا
- وجدت
- الأطر
- مجانا
- تجمد
- تجميد
- تبدأ من
- من 2021
- وظيفة
- وظيفة
- إضافي
- مستقبل
- موجهة
- العلاجات العامة
- ولدت
- علم الهندسة
- دولار فقط واحصل على خصم XNUMX% على جميع
- الحصول على
- منح
- يعطي
- Go
- هدف
- الذهاب
- خير
- شراء مراجعات جوجل
- وحدة معالجة الرسوميات:
- عظيم
- تجمع
- متزايد
- توجيه
- حفنة
- مقبض
- الثابت
- يملك
- he
- رئيس
- رأس
- عقد
- مساعدة
- يساعد
- من هنا
- هنا
- رفيع المستوى
- عالي الجودة
- أعلى
- وسلم
- له
- تاريخي
- تاريخ
- كيفية
- كيفية
- هوارد
- لكن
- HTML
- HTTP
- HTTPS
- الانسان
- البشر
- i
- فكرة
- تحديد
- تحديد
- if
- صورة
- تصنيف الصورة
- تقطيع الصورة
- IMAGEnet
- صور
- أثر
- تنفيذ
- الأدوات
- أهمية
- يحسن
- in
- تتضمن
- يشمل
- القيمة الاسمية
- يشير
- معلومات
- البنية التحتية
- في البداية
- إدخال
- مصلحة
- يستفد
- متوسط
- إلى
- تقديم
- حدس
- حدسي
- المشاركة
- ينطوي
- تنطوي
- IT
- انها
- م
- KD nuggets
- احتفظ
- القفل
- علم
- ملصقات
- كبير
- على نطاق واسع
- والأخير
- كمون
- الى وقت لاحق
- طبقة
- layer1
- Layer2
- layer3
- طبقات
- يؤدي
- تعلم
- تعلم
- تعلم
- شروط وأحكام
- قانونيا
- أقل
- الرافعة المالية
- الاستفادة من
- المكتبة
- التراخيص
- الترخيص
- مثل
- على الأرجح
- خط
- لينكدين:
- قائمة
- ll
- الأحمال
- التعريب
- طويل
- بحث
- خسارة
- الكثير
- منخفض
- خفض
- آلة
- آلة التعلم
- صنع
- الرئيسية
- جعل
- يصنع
- القيام ب
- كثير
- برنامج Maps
- مايو..
- تعني
- يعني
- ميكانيكي
- متوسط
- طريقة
- مایکروسافت
- مانع
- ML
- الجوال
- أجهزة محمولة
- نموذج
- عارضات ازياء
- الأكثر من ذلك
- أكثر
- الاكثر شهره
- التحفيز
- خطوة
- كثيرا
- متعدد
- يجب
- متبادل
- عين
- أي
- حاجة
- بحاجة
- شبكة
- الشبكات
- عصبي
- الشبكة العصبية
- جديد
- حديثا
- التالي
- لا
- غير التجارية
- مفكرة
- الآن
- الظل
- عدد
- كثير
- موضوع
- الأجسام
- تم الحصول عليها
- of
- قديم
- أقدم
- on
- ONE
- online
- مجتمعات الانترنت
- فقط
- التحسين
- الأمثل
- الأمثل
- تحسين
- مزيد من الخيارات
- or
- طلب
- أخرى
- لنا
- خارج
- الناتج
- على مدى
- الخاصة
- أكسفورد
- صفحة
- ورق
- أوراق
- المعلمة
- المعلمات
- جزء
- pass
- الماضي
- نفذ
- أداء
- تنفيذ
- أداء
- ينفذ
- مرحلة جديدة
- PHP
- مادي
- خطة
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- من فضلك
- البوينت
- الرائج
- ممكن
- محتمل
- عملية
- ممارسة
- وتوقع
- تنبؤات
- وجود
- يقدم
- قدم
- جميل
- منع
- سابق
- المحتمل
- المشكلة
- عملية المعالجة
- معالجة
- الإنتــاج
- محترف
- التقدّم
- تدريجيا
- مشروع ناجح
- واعد
- ويوفر
- توفير
- منشور
- غرض
- أغراض
- pytorch
- سؤال
- بسرعة
- عشوائية
- تتراوح
- معدل
- الأجور
- الوصول
- عرض
- استعداد
- حقيقي
- في الحقيقة
- نوصي
- أحمر
- تخفيض
- تقليص
- ذات صلة
- صدر
- يحل محل
- استبدال
- ممثل
- بحث
- مجتمع الأبحاث
- الباحثين
- الموارد
- REST
- النتائج
- عائد أعلى
- حق
- الروبوتات
- الأدوار
- يجري
- تشغيل
- s
- نفسه
- حفظ
- سيناريو
- علوم
- خدش
- بحث
- الثاني
- القسم
- أقسام
- انظر تعريف
- طلب
- بدا
- تقسيم
- اختيار
- SELF
- إحساس
- مستقل
- على حدة
- تسلسل
- جدي
- خوادم
- طقم
- ضبط
- عدة
- ينبغي
- أظهرت
- تبين
- أظهرت
- يظهر
- هام
- بشكل ملحوظ
- مماثل
- الاشارات
- منذ
- عزباء
- حالة
- المقاس
- الأحجام
- مهارات
- الأصغر
- So
- تطبيقات الكمبيوتر
- مهندس البرمجيات
- بعض
- شيء
- قريبا
- مصدر
- محدد
- محدد
- خطاب
- انقسم
- فريق العمل
- المسرح
- مراحل
- موقف
- بداية
- ابتداء
- الولايه او المحافظه
- خطوة
- خطوات
- تخزين
- استراتيجيات
- الإستراتيجيات
- الضربات
- منظم
- دراسة
- ناجح
- هذه
- وتقترح
- فائق
- مفترض
- تحول
- نظام
- أخذ
- يأخذ
- الهدف
- مهمة
- المهام
- تقنيات
- وحدة معالجة الموتر
- سياسة الحجب وتقييد الوصول
- تجربه بالعربي
- من
- أن
- •
- من مشاركة
- منهم
- then
- هناك.
- تشبه
- هم
- الأشياء
- اعتقد
- الثالث
- هؤلاء
- على الرغم من؟
- ثلاثة
- عبر
- طوال
- إلى
- الوقت
- بعنوان
- إلى
- شعلة
- تورشفيجن
- نحو
- نحو
- مسار
- قطار
- متدرب
- قادة الإيمان
- تحويل
- محولات
- صحيح
- محاولة
- يتحول
- عادة
- غير مألوف
- فهم
- فهم
- تجمد
- وحدة
- جامعة
- من غير المحتمل
- المقبلة
- us
- تستخدم
- مستعمل
- المستخدمين
- يستخدم
- استخدام
- عادة
- التحقق من صحة
- قيمنا
- القيم
- تشكيلة
- مختلف
- عمودي
- جدا
- المزيد
- شاهدوا
- الرؤى
- رؤيتنا
- قم بزيارتنا
- تريد
- وكان
- طريق..
- we
- المواقع
- حسن
- كان
- ابحث عن
- ما هي تفاصيل
- متى
- سواء
- التي
- في حين
- من الذى
- لمن
- لماذا
- ويكيبيديا
- سوف
- مع
- في غضون
- بدون
- للعمل
- عمل
- أعمال
- قلق
- قيمة
- سوف
- التفاف
- سنوات
- لصحتك!
- حل متجر العقارات الشامل الخاص بك في جورجيا
- نفسك
- موقع YouTube
- زفيرنت









