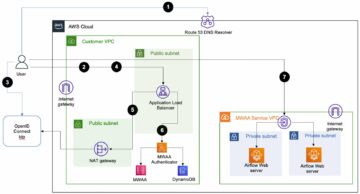
أمازون EMR بدون خادم يسمح لك بتشغيل أطر عمل البيانات الضخمة مفتوحة المصدر مثل Apache Spark و Apache Hive دون إدارة المجموعات والخوادم. باستخدام EMR Serverless ، يمكنك تشغيل أحمال عمل التحليلات على أي نطاق باستخدام القياس التلقائي الذي يغير حجم الموارد في ثوانٍ لتلبية أحجام البيانات المتغيرة ومتطلبات المعالجة. تقوم EMR Serverless تلقائيًا بترقية الموارد لأعلى ولأسفل لتوفير المقدار المناسب من السعة لتطبيقك.
يسعدنا أن نعلن أن EMR Serverless تقدم الآن تكوينات للعاملين من 8 وحدات معالجة مركزية مع ذاكرة تصل إلى 60 جيجا بايت و 16 وحدة معالجة مركزية مع ذاكرة تصل إلى 120 جيجا بايت ، مما يتيح لك تشغيل المزيد من أعباء العمل التي تستهلك الكثير من الذاكرة والحوسبة على EMR Serverless. يستخدم تطبيق EMR Serverless داخليًا العمال لتنفيذ أحمال العمل. ويمكنك تكوين تكوينات مختلفة للعاملين بناءً على متطلبات عبء العمل الخاص بك. في السابق ، كان أكبر تكوين للعمال متاح على EMR Serverless هو 4 وحدات معالجة مركزية (vCPU) بسعة تصل إلى 30 جيجابايت من الذاكرة. هذه القدرة مفيدة بشكل خاص للسيناريوهات الشائعة التالية:
- خلط أحمال العمل الثقيلة
- أعباء العمل كثيفة الذاكرة
لنلقِ نظرة على كل حالة من حالات الاستخدام هذه وفوائد وجود أحجام عمال أكبر.
فوائد استخدام العمالة الكبيرة لأعباء العمل المتقطعة
في Spark and Hive ، يحدث التبديل العشوائي عندما تحتاج البيانات إلى إعادة توزيعها عبر المجموعة أثناء الحساب. عندما يقوم تطبيقك بإجراء تحويلات واسعة أو تقليل عمليات مثل join, groupBy, sortByالطرق أو repartition، يقوم Spark و Hive بتشغيل خلط ورق اللعب. أيضًا ، كل مرحلة من مراحل Spark ورأس Tez مقيدة بعملية تبديل عشوائي. بأخذ Spark كمثال ، بشكل افتراضي ، هناك 200 قسم لكل وظيفة Spark محددة بواسطة spark.sql.shuffle.partitions. ومع ذلك ، ستحسب Spark عدد المهام أثناء الطيران بناءً على حجم البيانات والعملية التي يتم تنفيذها. عند إجراء تحويل واسع فوق مجموعة بيانات كبيرة ، يمكن أن يكون هناك غيغابايت أو حتى تيرابايت من البيانات التي يجب جلبها من خلال جميع المهام.
عادةً ما تكون المراوغات مكلفة من حيث الوقت والموارد ، ويمكن أن تؤدي إلى اختناقات في الأداء. لذلك ، يمكن أن يكون لتحسين المراسلات العشوائية تأثير كبير على أداء وتكلفة وظيفة Spark. مع وجود عدد كبير من العمال ، يمكن تخصيص المزيد من البيانات لذاكرة كل منفذ ، مما يقلل من تبادل البيانات بين المنفذين. يؤدي هذا بدوره إلى زيادة أداء القراءة العشوائية لأنه سيتم جلب المزيد من البيانات محليًا من نفس العامل وسيتم جلب بيانات أقل عن بُعد من العمال الآخرين.
التجارب
لتوضيح فوائد استخدام عدد كبير من العمال للاستعلامات المراوغة المكثفة ، دعنا نستخدم q78 من TPC-DS ، وهو استعلام Spark كثيف عشوائي يقوم بتبديل 167 جيجابايت من البيانات عبر 12 مرحلة Spark. لنقم بإجراء تكراريْن لنفس الاستعلام بتكوينات مختلفة.
تكوينات الاختبار 1 هي كما يلي:
- حجم المنفذ المطلوب أثناء إنشاء تطبيق EMR Serverless = 4 وحدات معالجة مركزية ، ذاكرة 8 جيجا بايت ، قرص 200 جيجا بايت
- تكوين وظيفة شرارة:
spark.executor.cores= 4spark.executor.memory= 8spark.executor.instances= 48- التوازي = 192 (
spark.executor.instances*spark.executor.cores)
تكوينات الاختبار 2 هي كما يلي:
- حجم المنفذ المطلوب أثناء إنشاء تطبيق EMR Serverless = 8 وحدات معالجة مركزية ، ذاكرة 16 جيجا بايت ، قرص 200 جيجا بايت
- تكوين وظيفة شرارة:
spark.executor.cores= 8spark.executor.memory= 16spark.executor.instances= 24- التوازي = 192 (
spark.executor.instances*spark.executor.cores)
لنقم أيضًا بتعطيل التخصيص الديناميكي عن طريق الإعداد spark.dynamicAllocation.enabled إلى false لكلا الاختبارين لتجنب أي ضوضاء محتملة بسبب أوقات إطلاق المنفذ المتغيرة والحفاظ على اتساق استخدام الموارد لكلا الاختبارين. نحن نستخدم قياس شرارة، وهي أداة مفتوحة المصدر تعمل على تبسيط عملية جمع وتحليل مقاييس أداء Spark. نظرًا لأننا نستخدم عددًا ثابتًا من المنفذين ، فإن العدد الإجمالي لوحدات المعالجة المركزية الافتراضية والذاكرة المطلوبة هو نفسه لكلا الاختبارين. يلخص الجدول التالي الملاحظات من المقاييس التي تم جمعها باستخدام Spark Measure.
| . | إجمالي الوقت المستغرق للاستعلام بالمللي ثانية | خلط ورق اللعب LocalBlocks تم جلبها | المراوغة RemoteBlocks تم جلبها | خلط ورق اللعب LocalBytesRead | المراوغة RemoteBytesRead | خلط ورق اللعب | خلط ورق الكتابة |
| اختبار 1 | 153244 | 114175 | 5291825 | 3.5 جيجا بايت | 163.1 جيجا بايت | 1.9 ساعة | 4.7 دقيقة |
| اختبار 2 | 108136 | 225448 | 5185552 | 6.9 جيجا بايت | 159.7 جيجا بايت | 3.2 دقيقة | 5.2 دقيقة |
كما يتضح من الجدول ، هناك فرق كبير في الأداء بسبب التحسينات العشوائية. الاختبار 2 ، مع نصف عدد المنفذين الذين يبلغ حجمهم ضعف الاختبار 1 ، تم تشغيله بشكل أسرع بنسبة 29.44٪ ، مع جلب بيانات عشوائية أكبر بمقدار 1.97 مرة محليًا مقارنةً بالاختبار 1 لنفس الاستعلام ، ونفس التوازي ، ونفس وحدة المعالجة المركزية الافتراضية الكلية وموارد الذاكرة . لذلك ، يمكنك الاستفادة من الأداء المحسن دون المساومة على التكلفة أو التوازي الوظيفي بمساعدة كبار التنفيذيين. لقد لاحظنا فوائد أداء مماثلة لاستعلامات TPC-DS الأخرى ذات الترتيب العشوائي مثل q23a و q23b.
توصيات
لتحديد ما إذا كان العمال الكبار سيستفيدون من تطبيقات Spark كثيفة الاستخدام ، ضع في اعتبارك ما يلي:
- افحص ال المستويات علامة التبويب من واجهة مستخدم خادم Spark History لتطبيق EMR Serverless. على سبيل المثال ، من لقطة الشاشة التالية لخادم Spark History ، يمكننا تحديد أن مهمة Spark هذه كتبت وقراءة 167 جيجابايت من البيانات العشوائية المجمعة عبر 12 مرحلة ، بالنظر إلى قراءة عشوائي و المراوغة الكتابة الأعمدة. إذا كانت وظائفك تتخطى أكثر من 50 جيجابايت من البيانات ، فمن المحتمل أن تستفيد من استخدام عمال أكبر مع 8 أو 16 vCPUs أو
spark.executor.cores.

- افحص ال SQL / إطار البيانات علامة التبويب من واجهة مستخدم خادم Spark History لتطبيق EMR Serverless (فقط من أجل Dataframe و Dataset APIs). عندما تختار إجراء Spark الذي تم تنفيذه ، مثل التجميع ، أو أخذ ، أو showString ، أو الحفظ ، سترى DAG مجمعة لجميع المراحل مفصولة عن طريق التبادلات. يتوافق كل تبادل في DAG مع عملية تبديل عشوائي ، وسيحتوي على وحدات البايت المحلية والبعيدة والكتل التي تم خلطها ، كما هو موضح في لقطة الشاشة التالية. إذا كانت الكتل العشوائية المحلية أو البايتات التي تم جلبها أقل بكثير مقارنة بالكتل البعيدة أو البايتات التي تم جلبها ، فيمكنك إعادة تشغيل التطبيق الخاص بك مع عمال أكبر (مع 8 أو 16 vCPUs أو spark.executor.cores) ومراجعة مقاييس التبادل هذه في DAG إلى معرفة ما إذا كان هناك أي تحسن.

- استخدم قياس شرارة أداة مع استعلام Spark الخاص بك للحصول على مقاييس خلط ورق اللعب في Spark driver's
stdoutسجلات ، كما هو موضح في السجل التالي لوظيفة Spark. راجع الوقت المستغرق للقراءات العشوائية (shuffleFetchWaitTime) وكتب المراوغة (shuffleWriteTime) ، ونسبة البايت المحلية التي تم جلبها إلى البايتات البعيدة التي تم جلبها. إذا استغرقت عملية التبديل العشوائي أكثر من دقيقتين ، فأعد تشغيل التطبيق الخاص بك مع عمال أكبر (مع 2 أو 8 vCPUs أوspark.executor.cores) باستخدام Spark Measure لتتبع التحسن في أداء خلط ورق اللعب ووقت تشغيل الوظيفة بشكل عام.
فوائد استخدام العمالة الكبيرة لأعباء العمل كثيفة الذاكرة
هناك أنواع معينة من أحمال العمل تستهلك الكثير من الذاكرة وقد تستفيد من تكوين ذاكرة أكبر لكل عامل. في هذا القسم ، نناقش السيناريوهات الشائعة حيث يمكن أن يكون العمال الكبار مفيدًا لتشغيل أحمال عمل كثيفة الذاكرة.
انحراف البيانات
تحدث انحرافات البيانات بشكل شائع في عدة أنواع من مجموعات البيانات. بعض الأمثلة الشائعة هي اكتشاف الاحتيال وتحليل السكان وتوزيع الدخل. على سبيل المثال ، عندما تريد اكتشاف الانحرافات في بياناتك ، فمن المتوقع أن يكون أقل من 1٪ فقط من البيانات غير طبيعية. إذا كنت تريد إجراء بعض التجميع فوق السجلات العادية مقابل السجلات غير الطبيعية ، فسيتم معالجة 99٪ من البيانات بواسطة عامل واحد ، مما قد يؤدي إلى نفاد ذاكرة هذا العامل. يمكن ملاحظة انحرافات البيانات للتحولات التي تتطلب ذاكرة مكثفة مثل groupBy, orderBy, join، وظائف النافذة ، collect_list, collect_set، وما إلى ذلك وهلم جرا. ربط أنواع مثل BroadcastNestedLoopJoin ومنتج Cartesan أيضًا كثيف الذاكرة بطبيعته وعرضة لانحرافات البيانات. وبالمثل ، إذا كانت بيانات الإدخال مضغوطة بتنسيق Gzip ، فلا يمكن قراءة ملف Gzip بأكثر من مهمة واحدة لأن نوع ضغط Gzip غير قابل للتقسيم. عندما يكون هناك عدد قليل من ملفات Gzip كبيرة جدًا في الإدخال ، فقد تنفد ذاكرة وظيفتك لأن مهمة واحدة قد تضطر إلى قراءة ملف Gzip ضخم لا يتناسب مع ذاكرة المنفذ.
يمكن التخفيف من حالات الفشل بسبب انحراف البيانات من خلال تطبيق استراتيجيات مثل التمليح. ومع ذلك ، غالبًا ما يتطلب هذا تغييرات واسعة في الكود ، وهو ما قد لا يكون ممكنًا بالنسبة لأعباء الإنتاج التي فشلت بسبب انحراف البيانات غير المسبوق الناتج عن الارتفاع المفاجئ في حجم البيانات الواردة. للحصول على حل بديل أبسط ، قد ترغب فقط في زيادة ذاكرة العامل. استخدام عمال أكبر مع المزيد spark.executor.memory يسمح لك بمعالجة انحراف البيانات دون إجراء أي تغييرات على كود التطبيق الخاص بك.
Caching
من أجل تحسين الأداء ، يتيح لك Spark تخزين إطارات البيانات ومجموعات البيانات وأقراص RDD في الذاكرة. يمكّنك هذا من إعادة استخدام إطار بيانات عدة مرات في تطبيقك دون الحاجة إلى إعادة حسابه. بشكل افتراضي ، يتم استخدام ما يصل إلى 50٪ من JVM للمنفذ الخاص بك للتخزين المؤقت لإطارات البيانات بناءً على ملف property spark.memory.storageFraction. على سبيل المثال ، إذا كان لديك spark.executor.memory تم تعيينه على 30 غيغابايت ، ثم يتم استخدام 15 غيغابايت للتخزين المؤقت الذي لا يمكن طرده.
مستوى التخزين الافتراضي لعملية التخزين المؤقت هو DISK_AND_MEMORY. إذا كان حجم إطار البيانات الذي تحاول تخزينه لا يتناسب مع ذاكرة المنفذ ، فإن جزءًا من ذاكرة التخزين المؤقت ينسكب على القرص. إذا لم تكن هناك مساحة كافية لكتابة البيانات المخزنة مؤقتًا في القرص ، فسيتم إخراج الكتل ولن تحصل على مزايا التخزين المؤقت. يتيح لك استخدام العمال الأكبر حجمًا تخزين المزيد من البيانات في الذاكرة مؤقتًا ، مما يعزز أداء المهام عن طريق استرداد الكتل المخزنة مؤقتًا من الذاكرة بدلاً من التخزين الأساسي.
التجارب
على سبيل المثال ، ما يلي وظيفة PySpark يؤدي إلى انحراف ، حيث يقوم منفذ واحد بمعالجة 99.95٪ من البيانات باستخدام مجاميع كثيفة الذاكرة مثل collect_list. الوظيفة تخزن أيضًا إطار بيانات كبير جدًا (2.2 تيرابايت). لنقم بتشغيل تكرارين من نفس المهمة على EMR Serverless باستخدام تكوينات وحدة المعالجة المركزية الافتراضية والذاكرة التالية.
لنجري الاختبار 3 مع أكبر تكوينات العمال الممكنة سابقًا:
- حجم مجموعة المنفذ أثناء إنشاء تطبيق EMR Serverless = 4 وحدات معالجة مركزية ، ذاكرة 30 جيجا بايت ، قرص 200 جيجا بايت
- تكوين وظيفة شرارة:
spark.executor.cores= 4spark.executor.memory= 27 جرام
لنجري الاختبار 4 مع تكوينات العمال الكبيرة التي تم إصدارها حديثًا:
- تم تعيين حجم المنفذ أثناء إنشاء تطبيق EMR Serverless = 8 وحدات معالجة مركزية ، وذاكرة 60 جيجابايت ، وقرص 200 جيجابايت
- تكوين وظيفة شرارة:
spark.executor.cores= 8spark.executor.memory= 54 جرام
فشل الاختبار 3 مع FetchFailedException، والذي نتج عن عدم كفاية ذاكرة المنفذ للوظيفة.

أيضًا ، من Spark UI للاختبار 3 ، نرى أن ذاكرة التخزين المحجوزة للمنفذين تم استخدامها بالكامل للتخزين المؤقت لإطارات البيانات.

تم سكب الكتل المتبقية للتخزين المؤقت على القرص ، كما هو موضح في المنفذ stderr السجلات:
تم تخزين حوالي 33٪ من إطار البيانات الدائم مؤقتًا على القرص ، كما يظهر في ملف الخزائن علامة التبويب Spark UI.

تم إجراء الاختبار 4 مع المنفذين الأكبر و vCores بنجاح دون إلقاء أي أخطاء متعلقة بالذاكرة. أيضًا ، تم تخزين حوالي 2.2٪ فقط من إطار البيانات مؤقتًا على القرص. لذلك ، سيتم استرداد الكتل المخزنة مؤقتًا لإطار البيانات من الذاكرة بدلاً من القرص ، مما يوفر أداءً أفضل.

توصيات
لتحديد ما إذا كان العمال الكبار سيستفيدون من تطبيقات Spark كثيفة الاستخدام للذاكرة ، ضع في اعتبارك ما يلي:
- حدد ما إذا كان تطبيق Spark الخاص بك يحتوي على أي انحرافات في البيانات من خلال النظر إلى Spark UI. تُظهر لقطة الشاشة التالية لواجهة Spark UI مثالاً على سيناريو انحراف البيانات حيث تعالج مهمة واحدة معظم البيانات (145.2 جيجابايت) ، بالنظر إلى قراءة عشوائي مقاس. إذا كانت هناك مهمة واحدة أو أقل تعالج بيانات أكثر بكثير من المهام الأخرى ، فأعد تشغيل التطبيق الخاص بك مع عمال أكبر حجمًا بذاكرة 60-120 جيجا بايت (
spark.executor.memoryتعيين في أي مكان من 54-109 غيغابايت مع الأخذ في الاعتبار 10٪ منspark.executor.memoryOverhead).

- افحص ال الخزائن علامة التبويب Spark History Server لمراجعة نسبة البيانات المخزنة مؤقتًا في الذاكرة إلى القرص من ملف الحجم في الذاكرة و الحجم في القرص الأعمدة. إذا تم تخزين أكثر من 10٪ من بياناتك مؤقتًا على القرص ، فأعد تشغيل التطبيق الخاص بك مع عمال أكبر لزيادة كمية البيانات المخزنة مؤقتًا في الذاكرة.
- هناك طريقة أخرى لتحديد ما إذا كانت وظيفتك تحتاج إلى مزيد من الذاكرة بشكل استباقي وهي المراقبة ذاكرة الذروة JVM على Spark UI منفذي فاتورة غير مدفوعة. إذا كانت ذروة ذاكرة JVM المستخدمة قريبة من ذاكرة المنفذ أو برنامج التشغيل ، فيمكنك إنشاء تطبيق مع عامل أكبر وتكوين قيمة أعلى لـ
spark.executor.memoryorspark.driver.memory. على سبيل المثال ، في لقطة الشاشة التالية ، الحد الأقصى لقيمة ذروة استخدام ذاكرة JVM هو 26 جيجابايت وspark.executor.memoryتم ضبطه على 27 G. في هذه الحالة ، قد يكون من المفيد استخدام عمال أكبر بسعة 60 جيجا بايت وذاكرةspark.executor.memoryتم ضبطه على 54 غ.

الاعتبارات
على الرغم من أن وحدات المعالجة المركزية الافتراضية الكبيرة تساعد في زيادة موقع الكتل العشوائية ، إلا أن هناك عوامل أخرى متضمنة مثل سرعة نقل القرص ، و IOPS للقرص (عمليات الإدخال / الإخراج في الثانية) ، وعرض النطاق الترددي للشبكة. في بعض الحالات ، يمكن لعدد أكبر من العمال الصغار الذين لديهم عدد أكبر من الأقراص أن يقدموا عمليات IOPS أعلى للقرص ، ومعدل نقل ، ونطاق ترددي للشبكة بشكل عام مقارنة بعدد أقل من العمال الكبار. نحن نشجعك على قياس أعباء عملك مقابل تكوينات وحدة المعالجة المركزية الافتراضية المناسبة لاختيار أفضل تكوين لعبء عملك.
بالنسبة للمهام ذات التشغيل العشوائي ، يوصى باستخدام الأقراص الكبيرة. يمكنك إرفاق ما يصل إلى 200 جيجا بايت من القرص لكل عامل عند إنشاء التطبيق الخاص بك. استخدام وحدات المعالجة المركزية الافتراضية الكبيرة (spark.executor.cores) لكل منفذ قد يزيد من استخدام القرص لكل عامل. إذا فشل تطبيقك مع "عدم ترك مساحة على الجهاز" بسبب عدم القدرة على احتواء البيانات العشوائية في القرص ، فاستخدم عددًا أكبر من العمال الأصغر حجمًا مع قرص سعة 200 جيجابايت.
وفي الختام
في هذا المنشور ، تعرفت على فوائد استخدام منفذين كبار لوظائف EMR Serverless الخاصة بك. لمزيد من المعلومات حول تكوينات العمال المختلفة ، راجع تكوينات العمال. تتوفر تكوينات العمال الكبيرة في جميع المناطق التي توجد بها EMR Serverless متاح.
عن المؤلف
 فينا فاسوديفان هو مهندس حلول شريك أول ومتخصص في Amazon EMR في AWS يركز على البيانات الضخمة والتحليلات. تساعد العملاء والشركاء في بناء حلول محسّنة وقابلة للتطوير وآمنة ؛ تحديث بنياتهم ؛ وترحيل أعباء عمل البيانات الضخمة الخاصة بهم إلى AWS.
فينا فاسوديفان هو مهندس حلول شريك أول ومتخصص في Amazon EMR في AWS يركز على البيانات الضخمة والتحليلات. تساعد العملاء والشركاء في بناء حلول محسّنة وقابلة للتطوير وآمنة ؛ تحديث بنياتهم ؛ وترحيل أعباء عمل البيانات الضخمة الخاصة بهم إلى AWS.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/amazon-emr-serverless-supports-larger-worker-sizes-to-run-more-compute-and-memory-intensive-workloads/
- 1
- 10
- 100
- 11
- 2%
- 7
- 70
- 9
- 95%
- a
- من نحن
- في
- اكشن
- ضد
- تجميع
- الكل
- تخصيص
- توزيع
- السماح
- يسمح
- أمازون
- أمازون EMR
- كمية
- تحليل
- تحليلات
- و
- أعلن
- في أى مكان
- أباتشي
- أباتشي سبارك
- واجهات برمجة التطبيقات
- تطبيق
- التطبيقات
- تطبيق
- يرفق
- أوتوماتيك
- تلقائيا
- متاح
- تجنب
- AWS
- عرض النطاق الترددي
- على أساس
- لان
- يجري
- مؤشر
- مفيد
- تستفيد
- الفوائد
- أفضل
- أفضل
- كبير
- البيانات الكبيرة
- حظر
- Blocks
- تعزيز
- الاختناقات
- نساعدك في بناء
- مخبأ
- الطاقة الإنتاجية
- حقيبة
- الحالات
- تسبب
- التغييرات
- متغير
- اختار
- اغلاق
- كتلة
- الكود
- جمع
- مجموعة شتاء XNUMX
- الأعمدة
- مشترك
- عادة
- مقارنة
- مساومة
- حساب
- إحصاء
- الاعداد
- تكوينات
- نظر
- ثابتة
- سياق الكلام
- يتوافق
- التكلفة
- استطاع
- خلق
- خلق
- العملاء
- DAG
- البيانات
- قواعد البيانات
- الترتيب
- تعريف
- الدرجة العلمية
- شرح
- كشف
- حدد
- فرق
- مختلف
- بحث
- توزيع
- لا
- لا
- إلى أسفل
- سائق
- أثناء
- ديناميكي
- كل
- تمكن
- شجع
- كاف
- أخطاء
- خاصة
- الأثير (ETH)
- حتى
- كل
- مثال
- أمثلة
- تبادل
- الاستبدال
- متحمس
- تنفيذ
- متوقع
- ذو تكلفة باهظة
- واسع
- العوامل
- فشل
- فشل
- بعيدا
- أسرع
- قابليه
- المنال
- قليل
- قم بتقديم
- ملفات
- تناسب
- ثابت
- التركيز
- متابعيك
- متابعات
- FRAME
- الأطر
- احتيال
- الكشف عن الغش
- تبدأ من
- تماما
- وظائف
- دولار فقط واحصل على خصم XNUMX% على جميع
- نصفي
- مقبض
- وجود
- مساعدة
- يساعد
- أعلى
- جدا
- تاريخ
- خلية النحل
- لكن
- HTML
- HTTPS
- ضخم
- التأثير
- تحسن
- تحسن
- تحسين
- تحسينات
- in
- عجز
- دخل
- الوارد
- القيمة الاسمية
- زيادة
- info
- معلومات
- إدخال
- بدلًا من ذلك
- المشاركة
- IT
- التكرارات
- وظيفة
- المشــاريــع
- الانضمام
- احتفظ
- كبير
- أكبر
- أكبر
- إطلاق
- قيادة
- يؤدي
- تعلم
- مستوى
- مما سيحدث
- محلي
- محليا
- بحث
- أبحث
- القيام ب
- إدارة
- أقصى
- قياس
- تعرف علي
- مكبر الصوت : يدعم، مع دعم ميكروفون مدمج لمنع الضوضاء
- المقاييس
- الهجرة
- دقائق
- موضة
- تحديث
- مراقبة
- الأكثر من ذلك
- أكثر
- MS
- متعدد
- حاجة
- إحتياجات
- شبكة
- ضجيج
- عادي
- عدد
- تحصل
- عرض
- الوهب
- عروض
- ONE
- المصدر المفتوح
- عملية
- عمليات
- الأمثل
- تحسين
- طلب
- أخرى
- الكلي
- الشريكة
- شركاء
- قمة
- نفذ
- أداء
- ينفذ
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- سكان
- ممكن
- منشور
- محتمل
- يحتمل
- سابقا
- عملية المعالجة
- العمليات
- معالجة
- منتج
- الإنتــاج
- تزود
- نسبة
- عرض
- موصى به
- تسجيل
- تخفيض
- المناطق
- صدر
- المتبقية
- عن بعد
- طلب
- المتطلبات الأساسية
- يتطلب
- محفوظة
- مورد
- الموارد
- مراجعة
- يجري
- تشغيل
- نفسه
- حفظ
- تحجيم
- حجم
- النطاقات
- التحجيم
- سيناريو
- سيناريوهات
- الثاني
- ثواني
- القسم
- تأمين
- كبير
- Serverless
- خوادم
- طقم
- ضبط
- عدة
- شاركت
- أظهرت
- يظهر
- خلط ورق اللعب
- هام
- بشكل ملحوظ
- مماثل
- وبالمثل
- عزباء
- مقاس
- الأحجام
- انحرف
- صغير
- الأصغر
- So
- حتى الآن
- الحلول
- بعض
- الفضاء
- شرارة
- متخصص
- SQL
- المسرح
- مراحل
- تخزين
- متجر
- استراتيجيات
- بنجاح
- هذه
- مفاجئ
- كاف
- مناسب
- الدعم
- موجة
- عرضة
- جدول
- أخذ
- يأخذ
- مع الأخذ
- مهمة
- المهام
- سياسة الحجب وتقييد الوصول
- تجربه بالعربي
- اختبارات
- •
- من مشاركة
- وبالتالي
- الإنتاجية
- رمي
- الوقت
- مرات
- إلى
- أداة
- تيشرت
- الإجمالي
- مسار
- تحول
- التحولات
- منعطف أو دور
- أنواع
- عادة
- ui
- التي تقوم عليها
- غير مسبوق
- الأستعمال
- تستخدم
- تستخدم
- قيمنا
- حجم
- مجلدات
- التي
- في حين
- واسع
- سوف
- بدون
- عامل
- العمال
- اكتب
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت