اختارت المنظمات بناء بحيرات بيانات فوقها خدمة تخزين أمازون البسيطة (Amazon S3) لسنوات عديدة. بحيرة البيانات هي الخيار الأكثر شيوعًا للمؤسسات لتخزين جميع بياناتها التنظيمية التي تم إنشاؤها بواسطة فرق مختلفة ، عبر مجالات الأعمال ، من جميع التنسيقات المختلفة ، وحتى عبر التاريخ. وفق دراسة، ترى الشركة المتوسطة أن حجم بياناتها ينمو بمعدل يتجاوز 50٪ سنويًا ، وعادةً ما تدير 33 مصدرًا فريدًا للبيانات للتحليل.
تحاول الفرق غالبًا نسخ آلاف الوظائف من قواعد البيانات العلائقية بنفس نمط الاستخراج والتحويل والتحميل (ETL). هناك الكثير من الجهد في الحفاظ على حالات العمل وجدولة هذه الوظائف الفردية. يساعد هذا الأسلوب الفرق على إضافة جداول مع بعض التغييرات ويحافظ أيضًا على حالة الوظيفة بأقل جهد. يمكن أن يؤدي ذلك إلى تحسن كبير في الجدول الزمني للتطوير وتتبع الوظائف بسهولة.
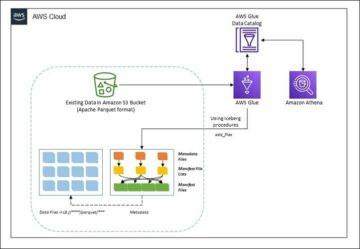
في هذا المنشور ، نوضح لك كيفية تكرار جميع مخازن البيانات الارتباطية الخاصة بك بسهولة في بحيرة بيانات المعاملات بطريقة آلية مع وظيفة ETL واحدة باستخدام Apache Iceberg و غراء AWS.
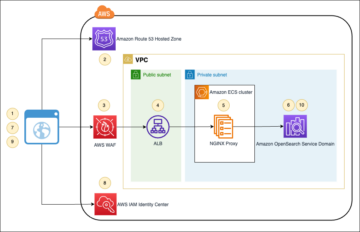
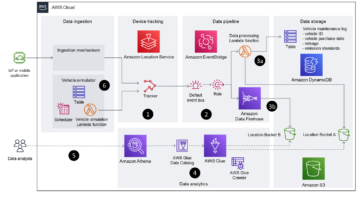
هندسة الحل
بحيرات البيانات عادة ما تكون منظمة باستخدام حاويات S3 منفصلة لثلاث طبقات من البيانات: الطبقة الأولية التي تحتوي على البيانات في شكلها الأصلي ، وطبقة المرحلة التي تحتوي على بيانات معالجة وسيطة محسّنة للاستهلاك ، وطبقة التحليلات التي تحتوي على بيانات مجمعة لحالات استخدام محددة. في الطبقة الأولية ، عادةً ما يتم تنظيم الجداول بناءً على مصادر البيانات الخاصة بها ، بينما يتم تنظيم الجداول في طبقة المرحلة بناءً على مجالات الأعمال التي تنتمي إليها.
يوفر هذا المنشور ملف تكوين سحابة AWS قالب ينشر وظيفة AWS Glue التي تقرأ مسار Amazon S3 لمصدر بيانات واحد لطبقة البيانات الأولية في بحيرة البيانات ، وتستوعب البيانات في جداول Apache Iceberg على طبقة المرحلة باستخدام دعم AWS Glue لأطر عمل بحيرة البيانات. تتوقع الوظيفة هيكلة الجداول في الطبقة الأولية بالطريقة خدمة ترحيل قاعدة بيانات AWS (AWS DMS) يستوعبها: المخطط ، ثم الجدول ، ثم ملفات البيانات.
يستخدم هذا الحل متجر معلمات مدير أنظمة AWS لتكوين الجدول. يجب عليك تعديل هذه المعلمة مع تحديد الجداول التي تريد معالجتها وكيفية معالجتها ، بما في ذلك معلومات مثل المفتاح الأساسي والأقسام ومجال الأعمال المرتبط. تستخدم الوظيفة هذه المعلومات لإنشاء قاعدة بيانات تلقائيًا (إذا لم تكن موجودة بالفعل) لكل مجال عمل ، وإنشاء جداول Iceberg ، وتنفيذ تحميل البيانات.
أخيرا ، يمكننا استخدام أمازون أثينا للاستعلام عن البيانات في جداول Iceberg.
يوضح الرسم البياني التالي هذه العمارة.

هذا التنفيذ لديه الاعتبارات التالية:
- يجب أن تحتوي جميع الجداول من مصدر البيانات على مفتاح أساسي ليتم نسخه باستخدام هذا الحل. يمكن أن يكون المفتاح الأساسي عمودًا واحدًا أو مفتاحًا مركبًا يحتوي على أكثر من عمود واحد.
- إذا كانت بحيرة البيانات تحتوي على جداول لا تحتاج إلى زيادات أو لا تحتوي على مفتاح أساسي ، فيمكنك استبعادها من تكوين المعلمة وتنفيذ عمليات ETL التقليدية لاستيعابها في بحيرة البيانات. هذا خارج نطاق هذا المنشور.
- إذا كانت هناك مصادر بيانات إضافية تحتاج إلى استيعابها ، فيمكنك نشر حزم CloudFormation متعددة ، واحدة للتعامل مع كل مصدر بيانات.
- تم تصميم مهمة AWS Glue لمعالجة البيانات على مرحلتين: التحميل الأولي الذي يتم تشغيله بعد انتهاء AWS DMS من مهمة التحميل الكامل ، والحمل المتزايد الذي يتم تشغيله وفقًا لجدول يطبق ملفات التقاط البيانات (CDC) التي تم التقاطها بواسطة AWS DMS. يتم تنفيذ المعالجة الإضافية باستخدام ملف إشارة مرجعية لوظيفة AWS Glue.
هناك تسع خطوات لإكمال هذا البرنامج التعليمي:
- قم بإعداد نقطة نهاية المصدر لـ AWS DMS.
- انشر الحل باستخدام AWS CloudFormation.
- راجع مهمة النسخ المتماثل لـ AWS DMS.
- اختياريًا ، أضف أذونات للتشفير وفك التشفير أو تكوين بحيرة AWS.
- راجع تكوين الجدول في Parameter Store.
- قم بتحميل البيانات الأولية.
- قم بتحميل البيانات التزايدي.
- مراقبة ابتلاع الجدول.
- جدولة تحميل بيانات الدُفعة التزايدية.
المتطلبات الأساسية المسبقة
قبل البدء في هذا البرنامج التعليمي ، يجب أن تكون بالفعل على دراية بـ Iceberg. إذا لم تكن كذلك ، فيمكنك البدء عن طريق نسخ جدول واحد باتباع الإرشادات الموجودة فيه قم بتنفيذ UPSERT القائم على CDC في مخزن بيانات باستخدام Apache Iceberg و AWS Glue. بالإضافة إلى ذلك ، قم بإعداد ما يلي:
قم بإعداد نقطة نهاية المصدر لـ AWS DMS
قبل إنشاء مهمة AWS DMS الخاصة بنا ، نحتاج إلى إعداد نقطة نهاية المصدر للاتصال بقاعدة البيانات المصدر:
- في وحدة تحكم AWS DMS ، اختر النهاية في جزء التنقل.
- اختار إنشاء نقطة نهاية.
- إذا كانت قاعدة البيانات الخاصة بك تعمل على Amazon RDS ، فاختر حدد مثيل RDS DB، ثم اختر المثيل من القائمة. خلاف ذلك ، اختر المحرك المصدر وقم بتوفير معلومات الاتصال إما من خلال مدير أسرار AWS أو يدويًا.
- في حالة معرف نقطة النهاية، أدخل اسمًا لنقطة النهاية ؛ على سبيل المثال ، source-postgresql.
- اختار إنشاء نقطة نهاية.
انشر الحل باستخدام AWS CloudFormation
قم بإنشاء حزمة CloudFormation باستخدام القالب المتوفر. أكمل الخطوات التالية:
- اختار إطلاق ستاك:

- اختار التالى.
- أدخل اسم مكدس ، مثل
transactionaldl-postgresql. - أدخل المعلمات المطلوبة:
- DMSS3 نقطة النهاية - دور IAM ARN لـ AWS DMS لكتابة البيانات في Amazon S3.
- النسخ المتماثل - مثيل النسخ المتماثل لـ AWS DMS ARN.
- S3BucketStage - اسم الحاوية الحالية المستخدمة لطبقة المرحلة لبحيرة البيانات.
- S3BucketGlue - اسم حاوية S3 الحالية لتخزين البرامج النصية لـ AWS Glue.
- S3BucketRaw - اسم الحاوية الحالية المستخدمة للطبقة الأولية لبحيرة البيانات.
- المصدر - ARN لنقطة نهاية AWS DMS التي قمت بإنشائها مسبقًا.
- SOURCENAME - المعرف التعسفي لمصدر البيانات المراد نسخه (على سبيل المثال ،
postgres). يستخدم هذا لتحديد مسار S3 لبحيرة البيانات (الطبقة الأولية) حيث سيتم تخزين البيانات.
- لا تقم بتعديل المعلمات التالية:
- المصدر S3BucketBlog - اسم الحاوية حيث يتم تخزين البرنامج النصي AWS Glue المقدم.
- المصدر - اسم بادئة الحاوية حيث يتم تخزين البرنامج النصي AWS Glue المقدم.
- اختار التالى مرتين.
- أختار أقر بأن AWS CloudFormation قد ينشئ موارد IAM بأسماء مخصصة.
- اختار إنشاء مكدس.
بعد حوالي 5 دقائق ، يتم نشر حزمة CloudFormation.
راجع مهمة النسخ المتماثل لـ AWS DMS
أدى نشر AWS CloudFormation إلى إنشاء نقطة نهاية هدف AWS DMS لك. نظرًا لوجود إعدادين محددين لنقطة النهاية ، سيتم استيعاب البيانات التي نحتاجها في Amazon S3.
- في وحدة تحكم AWS DMS ، اختر النهاية في جزء التنقل.
- ابحث عن واختر نقطة النهاية التي تبدأ بـ
dmsIcebergs3endpoint. - راجع إعدادات نقطة النهاية:
DataFormatتم تحديده على أنهparquet.TimestampColumnNameسيضيف العمودlast_update_timeبتاريخ إنشاء السجلات على Amazon S3.

ينشئ النشر أيضًا مهمة نسخ AWS DMS تبدأ بـ dmsicebergtask.
- اختار مهام النسخ المتماثل في جزء التنقل وابحث عن المهمة.
سترى أن نوع المهمة تم وضع علامة على أنه تحميل كامل ، النسخ المتماثل المستمر. ستقوم AWS DMS بإجراء تحميل أولي كامل للبيانات الموجودة ، ثم إنشاء ملفات إضافية بالتغييرات التي يتم إجراؤها على قاعدة البيانات المصدر.
على قواعد التعيين علامة التبويب ، هناك نوعان من القواعد:
- قاعدة تحديد باسم مخطط المصدر والجداول التي سيتم استيعابها من قاعدة البيانات المصدر. بشكل افتراضي ، يستخدم نموذج قاعدة البيانات المتوفرة في المتطلبات الأساسية ،
dms_sample، وجميع الجداول التي تحتوي على الكلمة الأساسية٪. - قاعدتا تحويل تتضمن في الملفات الهدف على Amazon S3 اسم المخطط واسم الجدول كأعمدة. يتم استخدام هذا من خلال وظيفة AWS Glue الخاصة بنا لمعرفة الجداول التي تتوافق معها الملفات الموجودة في بحيرة البيانات.
لمعرفة المزيد حول كيفية تخصيص هذا لمصادر البيانات الخاصة بك ، ارجع إلى قواعد الاختيار والإجراءات.

دعنا نغير بعض التكوينات لإنهاء إعداد مهمتنا.
- على الإجراءات القائمة، اختر عدل.
- في مجلة إعدادات المهمة القسم، تحت أوقف المهمة بعد اكتمال التحميل الكامل، اختر توقف بعد تطبيق التغييرات المخزنة مؤقتًا.
بهذه الطريقة ، يمكننا التحكم في التحميل الأولي وإنشاء الملف التزايدي كخطوتين مختلفتين. نستخدم هذا النهج المكون من خطوتين لتشغيل وظيفة AWS Glue مرة واحدة في كل خطوة.
- تحت سجلات المهام، اختر قم بتشغيل سجلات CloudWatch.
- اختار حفظ.
- انتظر حوالي دقيقة واحدة حتى تظهر حالة مهمة ترحيل قاعدة البيانات كـ استعداد.
أضف أذونات للتشفير وفك التشفير أو Lake Formation
اختياريًا ، يمكنك إضافة أذونات للتشفير وفك التشفير أو Lake Formation.
أضف أذونات التشفير وفك التشفير
إذا كانت حاويات S3 المستخدمة للطبقات الأولية والمرحلة مشفرة باستخدام خدمة إدارة مفتاح AWS (AWS KMS) مفاتيح يديرها العميل ، تحتاج إلى إضافة أذونات للسماح لوظيفة AWS Glue بالوصول إلى البيانات:
أضف أذونات تكوين البحيرة
إذا كنت تدير الأذونات باستخدام Lake Formation ، فأنت بحاجة إلى السماح لوظيفة AWS Glue الخاصة بك بإنشاء قواعد بيانات وجداول مجالك من خلال دور IAM GlueJobRole.
- منح أذونات لإنشاء قواعد البيانات (للحصول على التعليمات ، يرجى الرجوع إلى إنشاء قاعدة بيانات).
- منح أذونات SUPER لـ
defaultقاعدة البيانات. - منح أذونات موقع البيانات.
- إذا قمت بإنشاء قواعد بيانات يدويًا ، فامنح الأذونات لجميع قواعد البيانات لإنشاء الجداول. تشير إلى منح أذونات الجدول باستخدام وحدة التحكم Lake Formation وطريقة المورد المسمى or منح أذونات كتالوج البيانات باستخدام طريقة LF-TBAC وفقًا لحالة الاستخدام الخاصة بك.
بعد إكمال الخطوة اللاحقة لإجراء تحميل البيانات الأولي ، تأكد أيضًا من إضافة أذونات للعملاء للاستعلام عن الجداول. سيصبح دور الوظيفة هو مالك كل الجداول التي تم إنشاؤها ، ويمكن لمسؤول بحيرة البيانات بعد ذلك إجراء منح لمستخدمين إضافيين.
راجع تكوين الجدول في Parameter Store
تستخدم وظيفة AWS Glue التي تقوم باستيعاب البيانات في جداول Iceberg مواصفات الجدول المتوفرة في Parameter Store. أكمل الخطوات التالية لمراجعة مخزن المعلمات الذي تم تكوينه تلقائيًا لك. إذا لزم الأمر ، قم بالتعديل وفقًا لاحتياجاتك الخاصة.
- في وحدة تحكم Parameter Store ، اختر المعلمات الخاصة بي في جزء التنقل.
أنشأت حزمة CloudFormation معلمتين:
iceberg-configلتكوينات الوظائفiceberg-tablesلتكوين الجدول
- اختر المعلمة طاولات فيض.
تحتوي بنية JSON على المعلومات التي يستخدمها AWS Glue لقراءة البيانات وكتابة جداول Iceberg في المجال الهدف:
- كائن واحد لكل جدول - يتم إنشاء اسم الكائن باستخدام اسم المخطط والنقطة واسم الجدول ؛ على سبيل المثال،
schema.table. - المفتاح الأساسي - يجب تحديد هذا لكل جدول مصدر. يمكنك تقديم عمود واحد أو قائمة أعمدة مفصولة بفواصل (بدون مسافات).
- التقسيم - يؤدي هذا اختياريًا إلى تقسيم الأعمدة للجداول المستهدفة. إذا كنت لا تريد إنشاء جداول مقسمة ، فقدم سلسلة فارغة. بخلاف ذلك ، قم بتوفير عمود واحد أو قائمة أعمدة مفصولة بفواصل لاستخدامها (بدون مسافات).
- إذا كنت تريد استخدام مصدر البيانات الخاص بك ، فاستخدم كود JSON التالي واستبدل النص في CAPS من القالب المقدم. إذا كنت تستخدم نموذج مصدر البيانات المقدم ، فاحتفظ بالإعدادات الافتراضية:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- اختار حفظ التغييرات.
قم بتحميل البيانات الأولية
الآن وبعد الانتهاء من التهيئة المطلوبة ، نستوعب البيانات الأولية. تتضمن هذه الخطوة ثلاثة أجزاء: استيعاب البيانات من قاعدة البيانات العلائقية المصدر في الطبقة الأولية من بحيرة البيانات ، وإنشاء جداول Iceberg على طبقة المرحلة لبحيرة البيانات ، والتحقق من النتائج باستخدام أثينا.
استيعاب البيانات في الطبقة الأولية من بحيرة البيانات
لاستيعاب البيانات من مصدر البيانات العلائقية (PostgreSQL إذا كنت تستخدم العينة المتوفرة) إلى بحيرة بيانات المعاملات الخاصة بنا باستخدام Iceberg ، أكمل الخطوات التالية:
- في وحدة تحكم AWS DMS ، اختر مهام ترحيل قاعدة البيانات في جزء التنقل.
- حدد مهمة النسخ المتماثل التي قمت بإنشائها وعلى الإجراءات القائمة، اختر أعد تشغيل / استئناف.
- انتظر حوالي 5 دقائق حتى تكتمل مهمة النسخ المتماثل. يمكنك مراقبة الجداول التي يتم تناولها على ملف إحصائيات علامة تبويب مهمة النسخ المتماثل.

بعد بضع دقائق ، تنتهي المهمة بالرسالة اكتمال التحميل الكامل.
- في وحدة تحكم Amazon S3 ، اختر الحاوية التي حددتها على أنها الطبقة الأولية.
ضمن بادئة S3 المحددة في AWS DMS (على سبيل المثال ، postgres) ، يجب أن تشاهد تسلسلاً هرميًا للمجلدات بالهيكل التالي:
- مخطط
- اسم الطاولة
LOAD00000001.parquetLOAD0000000N.parquet
- اسم الطاولة

إذا كانت حاوية S3 فارغة ، فقم بمراجعتها استكشاف أخطاء مهام الترحيل وإصلاحها في AWS Database Migration Service قبل تشغيل مهمة AWS Glue.
إنشاء واستيعاب البيانات في جداول Iceberg
قبل تشغيل الوظيفة ، دعنا نتنقل في النص البرمجي لوظيفة AWS Glue المقدمة كجزء من حزمة CloudFormation لفهم سلوكها.
- في وحدة تحكم AWS Glue Studio ، اختر المشــاريــع في جزء التنقل.
- ابحث عن الوظيفة التي تبدأ بـ
IcebergJob-ولاحقة اسم مكدس CloudFormation (على سبيل المثال ،IcebergJob-transactionaldl-postgresql). - اختر الوظيفة.

يحصل البرنامج النصي للمهمة على التكوين الذي يحتاجه من Parameter Store. الوظيفة getConfigFromSSM() إرجاع التكوينات المتعلقة بالوظيفة مثل حاويات المصدر والهدف حيث يجب قراءة البيانات وكتابتها. المتغير ssmparam_table_values تحتوي على معلومات متعلقة بالجدول مثل مجال البيانات واسم الجدول وأعمدة القسم والمفتاح الأساسي للجداول التي يجب استيعابها. انظر التعليمات البرمجية بايثون التالية:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']يستخدم البرنامج النصي اسم كتالوج عشوائي لـ Iceberg الذي تم تعريفه على أنه my_catalog. يتم تنفيذ ذلك على كتالوج بيانات AWS Glue باستخدام تكوينات Spark ، لذلك سيتم تطبيق عملية SQL التي تشير إلى my_catalog على كتالوج البيانات. انظر الكود التالي:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
يتكرر البرنامج النصي عبر الجداول المحددة في Parameter Store ويقوم بتنفيذ المنطق لاكتشاف ما إذا كان الجدول موجودًا وما إذا كانت البيانات الواردة عبارة عن تحميل أولي أو زيادة:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')• initialLoadRecordsSparkSQL() تقوم الوظيفة بتحميل البيانات الأولية في حالة عدم وجود عمود تشغيل في ملفات S3. يضيف AWS DMS هذا العمود فقط إلى ملفات بيانات Parquet التي ينتجها النسخ المتماثل المستمر (CDC). يتم تحميل البيانات باستخدام الأمر INSERT INTO مع SparkSQL. انظر الكود التالي:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
نقوم الآن بتشغيل مهمة AWS Glue لاستيعاب البيانات الأولية في جداول Iceberg. يضيف مكدس CloudFormation امتداد الملف --datalake-formats المعلمة ، إضافة مكتبات Iceberg المطلوبة إلى الوظيفة.
- اختار شغل الوظيفة.
- اختار يدير الوظيفة لرصد الحالة. انتظر حتى تكون الحالة نجح تشغيل.
تحقق من البيانات التي تم تحميلها
لتأكيد أن الوظيفة عالجت البيانات كما هو متوقع ، أكمل الخطوات التالية:
- في وحدة تحكم أثينا ، اختر محرر الاستعلام في جزء التنقل.
- التحقق من البريد
AwsDataCatalogتم تحديده كمصدر للبيانات. - تحت قاعدة البيانات، اختر مجال البيانات الذي تريد استكشافه ، بناءً على التكوين الذي حددته في مخزن المعلمات. إذا كنت تستخدم نموذج قاعدة البيانات المتوفرة ، فاستخدم
sports.
تحت الجداول ووجهات النظر، يمكننا رؤية قائمة الجداول التي تم إنشاؤها بواسطة وظيفة AWS Glue.
- اختر قائمة الخيارات (ثلاث نقاط) بجوار اسم الجدول الأول ، ثم اختر معاينة البيانات.
يمكنك مشاهدة البيانات التي تم تحميلها في جداول Iceberg. 
قم بتحميل البيانات التزايدي
نبدأ الآن في التقاط التغييرات من قاعدة البيانات الارتباطية الخاصة بنا وتطبيقها على بحيرة بيانات المعاملات. هذه الخطوة مقسمة أيضًا إلى ثلاثة أجزاء: التقاط التغييرات ، وتطبيقها على جداول Iceberg ، والتحقق من النتائج.
التقاط التغييرات من قاعدة البيانات العلائقية
نظرًا للتكوين الذي حددناه ، توقفت مهمة النسخ المتماثل بعد تشغيل مرحلة التحميل الكامل. نقوم الآن بإعادة تشغيل المهمة لإضافة ملفات تزايدية مع التغييرات في الطبقة الأولية من بحيرة البيانات.
- في وحدة تحكم AWS DMS ، حدد المهمة التي أنشأناها وقمنا بتشغيلها من قبل.
- على الإجراءات القائمة، اختر سيرة ذاتية.
- اختار ابدأ المهمة لبدء التقاط التغييرات.
- لبدء إنشاء ملف جديد في بحيرة البيانات ، قم بتنفيذ عمليات الإدراج أو التحديث أو الحذف على جداول قاعدة البيانات المصدر باستخدام أداة إدارة قاعدة البيانات المفضلة لديك. إذا كنت تستخدم نموذج قاعدة البيانات المتوفرة ، فيمكنك تشغيل أوامر SQL التالية:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- في صفحة تفاصيل مهمة AWS DMS ، اختر ملف إحصائيات الجدول علامة التبويب لرؤية التغييرات التي تم التقاطها.

- افتح الطبقة الأولية من بحيرة البيانات للعثور على ملف جديد يحتوي على التغييرات المتزايدة داخل بادئة كل جدول ، على سبيل المثال أسفل
sporting_eventاختصار.
السجل مع التغييرات الخاصة بـ sporting_event الجدول يشبه لقطة الشاشة التالية.

تلاحظ Op العمود في البداية المحدد مع تحديث (U). أيضًا ، القيمة الثانية للتاريخ / الوقت هي عمود التحكم الذي أضافه AWS DMS مع وقت تسجيل التغيير.

قم بتطبيق التغييرات على جداول Iceberg باستخدام AWS Glue
نقوم الآن بتشغيل وظيفة AWS Glue مرة أخرى ، وستقوم تلقائيًا بمعالجة الملفات المتزايدة الجديدة فقط منذ تمكين الإشارة المرجعية للوظيفة. دعونا نراجع كيف يعمل.
• dedupCDCRecords() تقوم الوظيفة بإلغاء تكرار البيانات لأنه يمكن التقاط تغييرات متعددة لمعرف سجل واحد في نفس ملف البيانات على Amazon S3. يتم تنفيذ إلغاء البيانات المكررة على أساس last_update_time العمود الذي تمت إضافته بواسطة AWS DMS والذي يشير إلى الطابع الزمني لوقت التقاط التغيير. انظر التعليمات البرمجية بايثون التالية:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFعلى خط 99 ، upsertRecordsSparkSQL() تؤدي الدالة upert بطريقة مماثلة للتحميل الأولي ، ولكن هذه المرة باستخدام أمر SQL MERGE.
راجع التغييرات المطبقة
افتح وحدة تحكم Athena وقم بتشغيل استعلام يحدد السجلات التي تم تغييرها في قاعدة البيانات المصدر. إذا كنت تستخدم نموذج قاعدة البيانات المتوفرة ، فاستخدم أحد استعلامات SQL التالية:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

مراقبة ابتلاع الجدول
يتم ترميز النص البرمجي لمهمة AWS Glue بكل بساطة معالجة استثناء Python للقبض على الأخطاء أثناء معالجة جدول معين. يتم حفظ الإشارة المرجعية للمهمة بعد انتهاء معالجة كل جدول بنجاح ، لتجنب إعادة معالجة الجداول إذا تمت إعادة محاولة تشغيل المهمة للجداول التي بها أخطاء.
• واجهة سطر الأوامر AWS (AWS CLI) يوفر ملف get-job-bookmark الأمر الخاص بـ AWS Glue الذي يوفر نظرة ثاقبة على حالة الإشارة المرجعية لكل جدول تمت معالجته.
- في وحدة تحكم AWS Glue Studio ، اختر وظيفة ETL.
- اختيار يدير الوظيفة علامة التبويب وانسخ معرف تشغيل الوظيفة.
- قم بتشغيل الأمر التالي على محطة طرفية تمت مصادقتها لـ AWS CLI ، مع استبدال
<GLUE_JOB_RUN_ID>في السطر 1 بالقيمة التي نسختها. إذا لم يتم تسمية مكدس CloudFormation الخاص بكtransactionaldl-postgresql، أدخل اسم وظيفتك في السطر 2 من البرنامج النصي:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunفي هذا الحل ، عندما تتسبب معالجة الجدول في استثناء ، فلن تفشل مهمة AWS Glue وفقًا لهذا المنطق. بدلاً من ذلك ، سيتم إضافة الجدول إلى مصفوفة تتم طباعتها بعد اكتمال المهمة. في مثل هذا السيناريو ، سيتم تمييز الوظيفة على أنها فاشلة بعد محاولتها معالجة باقي الجداول التي تم اكتشافها في مصدر البيانات الأولية. بهذه الطريقة ، لا يتعين على الجداول الخالية من الأخطاء الانتظار حتى يحدد المستخدم المشكلة ويحلها في الجداول المتضاربة. يمكن للمستخدم أن يكتشف بسرعة عمليات تشغيل المهام التي بها مشكلات في استخدام حالة تشغيل مهمة AWS Glue ، وتحديد الجداول المحددة التي تسبب المشكلة باستخدام سجلات CloudWatch لتشغيل المهمة.
- يقوم البرنامج النصي للمهمة بتنفيذ هذه الميزة برمز Python التالي:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')توضح لقطة الشاشة التالية كيف تبحث سجلات CloudWatch عن الجداول التي تسبب أخطاء في المعالجة.

يتماشى مع AWS Well-Architured Framework Data Analytics Lens الممارسات ، يمكنك تكييف آليات تحكم أكثر تعقيدًا لتحديد وإخطار أصحاب المصلحة عند ظهور أخطاء في خطوط أنابيب البيانات. على سبيل المثال ، يمكنك استخدام ملف الأمازون DynamoDB جدول التحكم لتخزين جميع الجداول وتشغيل المهام مع وجود أخطاء ، أو استخدام خدمة إعلام أمازون البسيطة (Amazon SNS) إلى إرسال تنبيهات إلى المشغلين عندما يتم استيفاء معايير معينة.
جدولة تحميل بيانات الدُفعة التزايدية
تنشر حزمة CloudFormation ملف أمازون إيفينت بريدج قاعدة (معطلة افتراضيًا) يمكنها تشغيل وظيفة AWS Glue وفقًا لجدول زمني. لتقديم جدولك الخاص وتمكين القاعدة ، أكمل الخطوات التالية:
- في وحدة تحكم EventBridge ، اختر قوانيـن في جزء التنقل.
- ابحث عن القاعدة مسبوقة باسم مكدس CloudFormation متبوعًا بـ
JobTrigger(فمثلا،transactionaldl-postgresql-JobTrigger-randomvalue). - اختر القاعدة.
- تحت الحدث الجدول، اختر تعديل.
يتم تكوين الجدول الافتراضي ليتم تشغيله كل ساعة.
- قدم الجدول الذي تريده لتشغيل الوظيفة.
- بالإضافة إلى ذلك ، يمكنك استخدام ملف تعبير كرون EventBridge عن طريق اختيار جدول دقيق الحبيبات.

- عند الانتهاء من إعداد تعبير cron ، اختر التالى ثلاث مرات ، وأخيراً اختر تحديث القاعدة لحفظ التغييرات.
يتم تعطيل القاعدة افتراضيًا للسماح لك بتشغيل تحميل البيانات الأولية أولاً.
- قم بتنشيط القاعدة عن طريق الاختيار تفعيل.
يمكنك استخدام مراقبة لعرض استدعاءات القواعد ، أو مباشرة على AWS Glue تشغيل الوظيفة تفاصيل.
وفي الختام
بعد نشر هذا الحل ، تكون قد أتممت عرض جداولك تلقائيًا على مصدر بيانات علائقي واحد. عادةً ما تحتاج المؤسسات التي تستخدم بحيرة البيانات كمنصة بيانات مركزية إلى التعامل مع مصادر بيانات متعددة ، بل وأحيانًا عشرات. أيضًا ، يتطلب المزيد والمزيد من حالات الاستخدام من المؤسسات تنفيذ إمكانات المعاملات لبحيرة البيانات. يمكنك استخدام هذا الحل لتسريع اعتماد هذه الإمكانات عبر جميع مصادر البيانات الارتباطية الخاصة بك لتمكين حالات استخدام الأعمال الجديدة ، وأتمتة عملية التنفيذ للحصول على قيمة أكبر من بياناتك.
حول المؤلف
 لويس جيراردو بايزا هو مهندس بيانات كبير في مختبر بيانات Amazon Web Services (AWS). يتمتع بخبرة 12 عامًا في مساعدة المؤسسات في قطاعات الرعاية الصحية والمالية والتعليم على تبني برامج هندسة المؤسسات والحوسبة السحابية وقدرات تحليل البيانات. يساعد لويس حاليًا المؤسسات في جميع أنحاء أمريكا اللاتينية على تسريع مبادرات البيانات الاستراتيجية.
لويس جيراردو بايزا هو مهندس بيانات كبير في مختبر بيانات Amazon Web Services (AWS). يتمتع بخبرة 12 عامًا في مساعدة المؤسسات في قطاعات الرعاية الصحية والمالية والتعليم على تبني برامج هندسة المؤسسات والحوسبة السحابية وقدرات تحليل البيانات. يساعد لويس حاليًا المؤسسات في جميع أنحاء أمريكا اللاتينية على تسريع مبادرات البيانات الاستراتيجية.
 سايكيران ريدي أينوجو مهندس بيانات في مختبر بيانات Amazon Web Services (AWS). يتمتع بخبرة 10 سنوات في تنفيذ عمليات تحميل البيانات والتحويل والتصور. تساعد SaiKiran حاليًا المؤسسات في أمريكا الشمالية على اعتماد هياكل البيانات الحديثة مثل بحيرات البيانات وشبكات البيانات. لديه خبرة في قطاعات البيع بالتجزئة والطيران والتمويل.
سايكيران ريدي أينوجو مهندس بيانات في مختبر بيانات Amazon Web Services (AWS). يتمتع بخبرة 10 سنوات في تنفيذ عمليات تحميل البيانات والتحويل والتصور. تساعد SaiKiran حاليًا المؤسسات في أمريكا الشمالية على اعتماد هياكل البيانات الحديثة مثل بحيرات البيانات وشبكات البيانات. لديه خبرة في قطاعات البيع بالتجزئة والطيران والتمويل.
 ناريندرا ميرلا مهندس بيانات في مختبر بيانات Amazon Web Services (AWS). يتمتع بخبرة 12 عامًا في تصميم وإنتاج كل من خطوط أنابيب البيانات في الوقت الفعلي والموجهة نحو الدُفعات وبناء بحيرات البيانات في كل من البيئات السحابية والمحلية. يساعد ناريندرا حاليًا المؤسسات في أمريكا الشمالية على بناء هياكل بيانات قوية وتصميمها ، ولديه خبرة في قطاعي الاتصالات والتمويل.
ناريندرا ميرلا مهندس بيانات في مختبر بيانات Amazon Web Services (AWS). يتمتع بخبرة 12 عامًا في تصميم وإنتاج كل من خطوط أنابيب البيانات في الوقت الفعلي والموجهة نحو الدُفعات وبناء بحيرات البيانات في كل من البيئات السحابية والمحلية. يساعد ناريندرا حاليًا المؤسسات في أمريكا الشمالية على بناء هياكل بيانات قوية وتصميمها ، ولديه خبرة في قطاعي الاتصالات والتمويل.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- من نحن
- تسريع
- الوصول
- وفقا
- نقر
- في
- تكيف
- وأضاف
- إضافي
- وبالإضافة إلى ذلك
- يضيف
- مشرف
- إدارة
- تبنى
- تبني
- بعد
- شركة الطيران
- الكل
- سابقا
- أمازون
- أمازون أثينا
- أمازون RDS
- أمازون ويب سيرفيسز
- أمازون ويب سيرفيسز (أوس)
- أمريكا
- تحليل
- تحليلات
- و
- لوس
- أباتشي
- تظهر
- تطبيق
- تطبيقي
- تطبيق
- نهج
- ما يقرب من
- هندسة معمارية
- مجموعة
- أسوشيتد
- موثق
- أتمتة
- الآلي
- تلقائيا
- أتمتة
- المتوسط
- تجنب
- AWS
- تكوين سحابة AWS
- غراء AWS
- على أساس
- الخفافيش
- لان
- أصبح
- قبل
- البداية
- كبير
- البيانات الكبيرة
- نساعدك في بناء
- باني
- ابني
- الأعمال
- يستطيع الحصول على
- قدرات
- قبعات
- أسر
- اسر
- حقيبة
- الحالات
- الأقسام
- يو كاتش
- سبب
- الأسباب
- مما تسبب في
- CDC
- مركزي
- معين
- تغيير
- التغييرات
- خيار
- اختار
- اختيار
- اختيار
- سحابة
- الحوسبة السحابية
- الكود
- عمود
- الأعمدة
- حول الشركة
- إكمال
- الحوسبة
- الاعداد
- تكوينات
- أكد
- متضارب
- التواصل
- صلة
- الاعتبارات
- كنسولات
- المستهلكين
- استهلاك
- يحتوي
- استمر
- متواصل
- مراقبة
- استطاع
- خلق
- خلق
- يخلق
- خلق
- خلق
- المعايير
- حاليا
- على
- زبون
- تصميم
- البيانات
- تحليلات البيانات
- بحيرة البيانات
- منصة البيانات
- قاعدة البيانات
- قواعد البيانات
- التاريخ
- الترتيب
- تعريف
- نشر
- نشر
- نشر
- نشر
- ينشر
- تصميم
- تصميم
- تصميم
- تفاصيل
- الكشف عن
- التطوير التجاري
- مختلف
- مباشرة
- معاق
- منقسم
- لا
- نطاق
- المجالات
- لا
- أثناء
- كل
- في وقت سابق
- بسهولة
- التعليم
- جهد
- إما
- تمكين
- تمكين
- مشفرة
- التشفير
- نقطة النهاية
- محرك
- أدخل
- مشروع
- البيئات
- أخطاء
- الأثير (ETH)
- حتى
- كل
- مثال
- يتجاوز
- إلا
- استثناء
- القائمة
- موجود
- متوقع
- تتوقع
- الخبره في مجال الغطس
- اكتشف
- اضافات المتصفح
- استخراج
- فشل
- مألوف
- الأزياء
- الميزات
- قليل
- قم بتقديم
- ملفات
- أخيرا
- تمويل
- مالي
- نهاية
- الاسم الأول
- يتبع
- متابعيك
- للمستهلكين
- النموذج المرفق
- تشكيل
- الإطار
- تبدأ من
- بالإضافة إلى
- وظيفة
- ولدت
- جيل
- دولار فقط واحصل على خصم XNUMX% على جميع
- منح
- منح
- متزايد
- مقبض
- الرعاية الصحية
- مساعدة
- يساعد
- تسلسل
- تاريخ
- عقد
- كيفية
- كيفية
- HTML
- HTTPS
- ضخم
- IAM
- محدد
- معرف
- يحدد
- تحديد
- تنفيذ
- التنفيذ
- نفذت
- تحقيق
- الأدوات
- تحسين
- in
- تتضمن
- يشمل
- بما فيه
- الوارد
- يشير
- فرد
- معلومات
- في البداية
- المبادرات
- إدراج
- تبصر
- مثل
- بدلًا من ذلك
- تعليمات
- متوسط
- قضية
- مسائل
- IT
- تكرير
- وظيفة
- المشــاريــع
- جسون
- احتفظ
- القفل
- مفاتيح
- علم
- مختبر
- بحيرة
- لاتيني
- أمريكا اللاتينية
- طبقة
- طبقات
- قيادة
- تعلم
- المكتبات
- مما سيحدث
- خط
- قائمة
- تحميل
- جار التحميل
- الأحمال
- موقع
- بحث
- تبدو
- ال
- لوس أنجلوس
- الكثير
- الرئيسية
- تحتفظ
- جعل
- تمكن
- إدارة
- مدير
- إدارة
- يدويا
- كثير
- رسم الخرائط
- ملحوظ
- القائمة
- دمج
- الرسالة
- ربما
- هجرة
- الحد الأدنى
- دقيقة
- دقائق
- تقدم
- تعديل
- مراقبة
- مراقبة
- الأكثر من ذلك
- أكثر
- الاكثر شهره
- متعدد
- الاسم
- عين
- أسماء
- التنقل
- قائمة الإختيارات
- حاجة
- بحاجة
- إحتياجات
- جديد
- التالي
- شمال
- امريكا الشمالية
- إعلام
- عدد
- موضوع
- الأجسام
- ONE
- جارية
- OP
- عملية
- الأمثل
- مزيد من الخيارات
- التنظيمية
- المنظمات
- منظم
- أصلي
- وإلا
- في الخارج
- الخاصة
- كاتوا ديلز
- خبز
- المعلمة
- المعلمات
- جزء
- أجزاء
- مسار
- نمط
- نفذ
- أداء
- ينفذ
- فترة
- أذونات
- مرحلة جديدة
- المنصة
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- أكثر الاستفسارات
- منشور
- كيو
- الممارسات
- المفضل
- الشروط
- يقدم
- ابتدائي
- المشكلة
- عملية المعالجة
- العمليات
- معالجة
- أنتج
- البرامج
- تزود
- المقدمة
- ويوفر
- بايثون
- بسرعة
- رفع
- معدل
- الخام
- مسودة بيانات
- عرض
- في الوقت الحقيقي
- سجل
- تسجيل
- يحل محل
- منسوخة
- تكرار
- تطلب
- مطلوب
- مورد
- الموارد
- REST
- النتائج
- بيع بالتجزئة
- عائد أعلى
- عائدات
- مراجعة
- قوي
- النوع
- قاعدة
- القواعد
- يجري
- تشغيل
- نفسه
- حفظ
- سيناريو
- جدول
- نطاق
- مخطوطات
- بحث
- الثاني
- قطاعات
- رؤية
- مختار
- اختيار
- اختيار
- مستقل
- خدمات
- طقم
- ضبط
- إعدادات
- ينبغي
- إظهار
- يظهر
- مماثل
- الاشارات
- منذ
- عزباء
- So
- حل
- يحل
- بعض
- متطور
- مصدر
- مصادر
- المساحات
- شرارة
- محدد
- مواصفة
- محدد
- رياضة
- SQL
- كومة
- كومات
- المسرح
- أصحاب المصلحة
- بداية
- بدأت
- ابتداء
- يبدأ
- المحافظة
- إحصائيات
- الحالة
- خطوة
- خطوات
- توقف
- تخزين
- متجر
- تخزين
- فروعنا
- إستراتيجي
- بناء
- منظم
- ستوديو
- بنجاح
- هذه
- فائق
- الدعم
- أنظمة
- جدول
- الهدف
- مهمة
- المهام
- فريق
- فريق
- الاتصالات
- قالب
- محطة
- •
- المصدر
- من مشاركة
- الآلاف
- ثلاثة
- عبر
- الوقت
- الجدول الزمني
- مرات
- الطابع الزمني
- إلى
- أداة
- تيشرت
- الإجمالي
- تتبع الشحنة
- تقليدي
- المعاملات
- تحول
- تحول
- يثير
- البرنامج التعليمي
- أنواع
- مع
- فهم
- فريد من نوعه
- تحديث
- آخر التحديثات
- تستخدم
- حالة الاستخدام
- مستخدم
- المستخدمين
- عادة
- قيمنا
- التحقق
- المزيد
- التصور
- حجم
- انتظر
- المخزن
- الويب
- خدمات ويب
- التي
- سوف
- في غضون
- بدون
- أعمال
- اكتب
- مكتوب
- يامل
- عام
- سنوات
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت