الأمازون SageMaker هي خدمة تعلم آلي مُدارة بالكامل (ML). باستخدام SageMaker ، يمكن لعلماء ومطوري البيانات إنشاء نماذج ML وتدريبها بسرعة وسهولة ، ثم نشرها مباشرةً في بيئة مستضافة جاهزة للإنتاج. إنه يوفر مثيلًا مدمجًا لدفتر تأليف Jupyter لسهولة الوصول إلى مصادر البيانات الخاصة بك للاستكشاف والتحليل ، حتى لا تضطر إلى إدارة الخوادم. كما أنها توفر المشتركة خوارزميات ML التي تم تحسينها للتشغيل بكفاءة مقابل البيانات الكبيرة للغاية في بيئة موزعة.
يُعد الاستدلال في الوقت الفعلي من SageMaker مثاليًا لأحمال العمل التي تتطلب متطلبات في الوقت الفعلي وتفاعلية وزمن انتقال منخفض. باستخدام الاستدلال في الوقت الحقيقي من SageMaker ، يمكنك نشر نقاط نهاية REST المدعومة بنوع مثيل معين مع قدر معين من الحوسبة والذاكرة. يعد نشر نقطة نهاية في الوقت الفعلي من SageMaker هو الخطوة الأولى فقط في مسار الإنتاج للعديد من العملاء. نريد أن نكون قادرين على تعظيم أداء نقطة النهاية لتحقيق المعاملات المستهدفة في الثانية (TPS) مع الالتزام بمتطلبات زمن الانتقال. يتمثل جزء كبير من تحسين الأداء للاستدلال في التأكد من تحديد نوع المثيل المناسب والرجوع إلى نقطة النهاية.
يصف هذا المنشور أفضل الممارسات لاختبار الحمل لنقطة نهاية SageMaker للعثور على التكوين الصحيح لعدد المثيلات والحجم. يمكن أن يساعدنا ذلك في فهم الحد الأدنى من متطلبات المثيلات المتوفرة لتلبية متطلبات زمن الوصول و TPS. من هناك ، نتعمق في كيفية تتبع وفهم مقاييس وأداء نقطة نهاية SageMaker باستخدام الأمازون CloudWatch المقاييس.
نقوم أولاً بقياس أداء نموذجنا على مثيل واحد لتحديد TPS التي يمكنه التعامل معها وفقًا لمتطلبات زمن الانتقال المقبولة لدينا. ثم نقوم باستقراء النتائج لتحديد عدد الحالات التي نحتاجها للتعامل مع حركة الإنتاج لدينا. أخيرًا ، نقوم بمحاكاة حركة المرور على مستوى الإنتاج وإعداد اختبارات تحميل لنقطة نهاية SageMaker في الوقت الفعلي للتأكد من أن نقطة النهاية لدينا يمكنها التعامل مع الحمل على مستوى الإنتاج. تتوفر مجموعة التعليمات البرمجية للمثال بالكامل في ما يلي مستودع جيثب.
نظرة عامة على الحل
بالنسبة لهذا المنشور ، نقوم بنشر ملف نموذج تعانق الوجه DistilBERT من معانقة الوجه المحور. يمكن لهذا النموذج أداء عدد من المهام ، لكننا نرسل حمولة خاصة لتحليل المشاعر وتصنيف النص. مع حمولة العينة هذه ، نسعى جاهدين لتحقيق 1000 TPS.
انشر نقطة نهاية في الوقت الفعلي
يفترض هذا المنشور أنك على دراية بكيفية نشر نموذج. تشير إلى قم بإنشاء نقطة النهاية الخاصة بك ونشر النموذج الخاص بك لفهم العناصر الداخلية الكامنة وراء استضافة نقطة النهاية. في الوقت الحالي ، يمكننا الإشارة بسرعة إلى هذا النموذج في Hugging Face Hub ونشر نقطة نهاية في الوقت الفعلي باستخدام مقتطف الشفرة التالي:
دعنا نختبر نقطة النهاية الخاصة بنا بسرعة باستخدام عينة الحمولة التي نريد استخدامها لاختبار الحمل:

لاحظ أننا ندعم نقطة النهاية باستخدام ملف الأمازون الحوسبة المرنة السحابية مثيل (Amazon EC2) من النوع ml.m5.12xlarge ، والذي يحتوي على 48 وحدة معالجة مركزية (vCPU) و 192 جيجا بايت من الذاكرة. يعد عدد وحدات vCPU مؤشرًا جيدًا على التزامن الذي يمكن للمثيل التعامل معه. بشكل عام ، يوصى باختبار أنواع مثيلات مختلفة للتأكد من أن لدينا مثيل به موارد يتم استخدامها بشكل صحيح. للاطلاع على قائمة كاملة بمثيلات SageMaker وقوتها الحسابية المقابلة للاستدلال في الوقت الفعلي ، ارجع إلى الأمازون SageMaker التسعير.
مقاييس للتتبع
قبل أن نتمكن من الدخول في اختبار الحمل ، من الضروري فهم المقاييس التي يجب تتبعها لفهم انهيار الأداء لنقطة نهاية SageMaker الخاصة بك. CloudWatch هي أداة التسجيل الأساسية التي يستخدمها SageMaker لمساعدتك على فهم المقاييس المختلفة التي تصف أداء نقطة النهاية الخاصة بك. يمكنك استخدام سجلات CloudWatch لتصحيح استدعاءات نقطة النهاية الخاصة بك ؛ يتم هنا تسجيل جميع بيانات التسجيل والطباعة الموجودة في كود الاستدلال الخاص بك. لمزيد من المعلومات ، يرجى الرجوع إلى كيف يعمل Amazon CloudWatch.
هناك نوعان مختلفان من المقاييس التي تغطيها CloudWatch لـ SageMaker: مستوى المثيل ومقاييس الاستدعاء.
مقاييس مستوى المثيل
المجموعة الأولى من المعلمات التي يجب مراعاتها هي المقاييس على مستوى المثيل: CPUUtilization و MemoryUtilization (للحالات المستندة إلى GPU ، GPUUtilization). إلى CPUUtilization، قد ترى نسبًا أعلى من 100٪ في البداية في CloudWatch. من المهم أن تدرك ذلك CPUUtilization، يتم عرض مجموع كل أنوية وحدة المعالجة المركزية. على سبيل المثال ، إذا كان المثيل الموجود خلف نقطة النهاية يحتوي على 4 وحدات معالجة افتراضية ، فهذا يعني أن نطاق الاستخدام يصل إلى 400٪. MemoryUtilization، من ناحية أخرى ، في حدود 0-100٪.
على وجه التحديد ، يمكنك استخدام CPUUtilization للحصول على فهم أعمق لما إذا كان لديك كمية كافية أو حتى كمية زائدة من الأجهزة. إذا كان لديك مثيل غير مستخدم بشكل كافٍ (أقل من 30٪) ، فمن المحتمل أن تقوم بتقليص نوع المثيل الخاص بك. على العكس من ذلك ، إذا كنت تستخدم حوالي 80-90٪ ، فسيكون من المفيد اختيار مثيل به قدر أكبر من الحوسبة / الذاكرة. من الاختبارات التي أجريناها ، نقترح استخدام حوالي 60-70٪ من أجهزتك.
مقاييس الدعاء
كما هو مقترح من الاسم ، فإن مقاييس الاستدعاء هي المكان الذي يمكننا فيه تتبع زمن الانتقال من طرف إلى طرف لأي استدعاءات لنقطة النهاية الخاصة بك. يمكنك استخدام مقاييس الاستدعاء لتسجيل عدد الأخطاء ونوع الأخطاء (5xx ، 4xx ، وما إلى ذلك) التي قد تواجهها نقطة النهاية الخاصة بك. والأهم من ذلك ، يمكنك فهم تفاصيل وقت الاستجابة لمكالمات نقطة النهاية الخاصة بك. يمكن التقاط الكثير من هذا باستخدام ModelLatency و OverheadLatency المقاييس ، كما هو موضح في الرسم البياني التالي.

• ModelLatency metric يلتقط الوقت الذي يستغرقه الاستنتاج داخل حاوية النموذج خلف نقطة نهاية SageMaker. لاحظ أن حاوية النموذج تتضمن أيضًا أي كود استنتاج مخصص أو نصوص برمجية قمت بتمريرها للاستدلال. يتم التقاط هذه الوحدة بالميكروثانية كمقياس استدعاء ، وعمومًا يمكنك رسم نسبة مئوية عبر CloudWatch (p99 ، p90 ، وما إلى ذلك) لمعرفة ما إذا كنت تحقق وقت الاستجابة المستهدف. لاحظ أن هناك عدة عوامل يمكن أن تؤثر على زمن انتقال النموذج والحاوية ، مثل ما يلي:
- نص برمجي مخصص للاستدلال - سواء كنت قد نفذت الحاوية الخاصة بك أو استخدمت حاوية تستند إلى SageMaker مع معالجات استدلال مخصصة ، فمن الأفضل أن تقوم بملف تعريف البرنامج النصي الخاص بك للقبض على أي عمليات تضيف على وجه التحديد الكثير من الوقت إلى وقت الاستجابة.
- بروتوكول الاتصالات - ضع في اعتبارك اتصالات REST مقابل gRPC بخادم النموذج داخل حاوية النموذج.
- تحسينات إطار النموذج - هذا إطار محدد ، على سبيل المثال مع TensorFlow، هناك عدد من متغيرات البيئة التي يمكنك ضبطها والتي تكون محددة لخدمة TF. تأكد من التحقق من الحاوية التي تستخدمها وما إذا كانت هناك أي تحسينات خاصة بإطار العمل يمكنك إضافتها داخل البرنامج النصي أو كمتغيرات بيئة لإدخالها في الحاوية.
OverheadLatency يتم قياسه من الوقت الذي يتلقى فيه SageMaker الطلب حتى يقوم بإرجاع استجابة للعميل ، مطروحًا منه زمن انتقال النموذج. هذا الجزء خارج عن سيطرتك إلى حد كبير ويقع تحت الوقت الذي تستغرقه SageMaker النفقات العامة.
يعتمد وقت الاستجابة الشامل ككل على مجموعة متنوعة من العوامل وليس بالضرورة مجموع ModelLatency المزيد OverheadLatency. على سبيل المثال ، إذا كان العميل يصنع ملف InvokeEndpoint استدعاء واجهة برمجة التطبيقات عبر الإنترنت ، من وجهة نظر العميل ، سيكون زمن الانتقال من طرف إلى طرف هو الإنترنت + ModelLatency + OverheadLatency. على هذا النحو ، عند تحميل اختبار نقطة النهاية الخاصة بك من أجل قياس نقطة النهاية نفسها بدقة ، يوصى بالتركيز على مقاييس نقطة النهاية (ModelLatency, OverheadLatencyو InvocationsPerInstance) لقياس نقطة نهاية SageMaker بدقة. يمكن بعد ذلك عزل أي مشكلات تتعلق بزمن الانتقال من طرف إلى طرف بشكل منفصل.
بعض الأسئلة التي يجب مراعاتها بخصوص وقت الاستجابة الشامل:
- أين العميل الذي يستدعي نقطة النهاية الخاصة بك؟
- هل هناك أي طبقات وسيطة بين العميل ووقت تشغيل SageMaker؟
التحجيم التلقائي
لا نغطي القياس التلقائي في هذا المنشور على وجه التحديد ، ولكنه اعتبار مهم لتوفير العدد الصحيح من المثيلات استنادًا إلى عبء العمل. بناءً على أنماط حركة المرور الخاصة بك ، يمكنك إرفاق ملف سياسة التحجيم التلقائي إلى نقطة نهاية SageMaker الخاصة بك. هناك خيارات تحجيم مختلفة ، مثل TargetTrackingScaling, SimpleScalingو StepScaling. يسمح هذا لنقطة النهاية الخاصة بك بالتدرج والخروج تلقائيًا بناءً على نمط حركة المرور الخاصة بك.
الخيار الشائع هو تتبع الهدف ، حيث يمكنك تحديد مقياس CloudWatch أو مقياس مخصص قمت بتحديده وتوسيع نطاقه بناءً على ذلك. الاستخدام المتكرر للقياس التلقائي هو تتبع InvocationsPerInstance قياس. بعد أن تحدد عنق الزجاجة عند TPS معين ، يمكنك غالبًا استخدام ذلك كمقياس لتوسيع نطاقه إلى عدد أكبر من الحالات لتتمكن من التعامل مع أحمال الذروة من حركة المرور. للحصول على تحليل أعمق لنقاط نهاية مقياس SageMaker التلقائي ، راجع تكوين نقاط نهاية الاستدلال التلقائي في Amazon SageMaker.
اختبار الحمل
على الرغم من أننا نستخدم Locust لعرض كيف يمكننا تحميل الاختبار على نطاق واسع ، إذا كنت تحاول تحديد حجم المثيل المناسب خلف نقطة النهاية الخاصة بك ، التوصية بالاستدلال SageMaker هو خيار أكثر كفاءة. باستخدام أدوات اختبار الحمل التابعة لجهات خارجية ، يجب عليك نشر نقاط النهاية يدويًا عبر مثيلات مختلفة. باستخدام Inference التوصية ، يمكنك ببساطة تمرير مجموعة من أنواع المثيلات التي تريد تحميل الاختبار عليها ، وسوف يدور SageMaker وظائف لكل من هذه الحالات.
جراد
في هذا المثال ، نستخدم جراد، أداة اختبار تحميل مفتوحة المصدر يمكنك تنفيذها باستخدام Python. يشبه Locust العديد من أدوات اختبار الحمل مفتوحة المصدر الأخرى ، ولكن له بعض الفوائد المحددة:
- من السهل فرده وطيه - كما أوضحنا في هذا المنشور ، سنقوم بتمرير نص برمجي بسيط من Python يمكن إعادة بنائه بسهولة لنقطة النهاية والحمولة المحددة الخاصة بك.
- موزعة وقابلة للتطوير - الجراد يعتمد على الأحداث ويستخدم جيفينت تحت الغطاء. هذا مفيد جدًا لاختبار أحمال العمل المتزامنة للغاية ومحاكاة الآلاف من المستخدمين المتزامنين. يمكنك تحقيق TPS عالية من خلال عملية واحدة تقوم بتشغيل Locust ، ولكنها تحتوي أيضًا على ملف توليد الحمل الموزع ميزة تمكّنك من التوسع في عمليات متعددة وأجهزة العميل ، كما سنستكشف في هذا المنشور.
- مقاييس الجراد وواجهة المستخدم - يلتقط الجراد أيضًا زمن الانتقال من طرف إلى طرف كمقياس. يمكن أن يساعد ذلك في استكمال مقاييس CloudWatch الخاصة بك لرسم صورة كاملة لاختباراتك. يتم التقاط كل هذا في Locust UI ، حيث يمكنك تتبع المستخدمين والعاملين المتزامنين والمزيد.
لفهم الجراد بشكل أكبر ، تحقق من ملفات توثيق.
إعداد Amazon EC2
يمكنك إعداد Locust في أي بيئة مناسبة لك. بالنسبة لهذا المنشور ، قمنا بإعداد مثيل EC2 وقمنا بتثبيت Locust هناك لإجراء اختباراتنا. نستخدم مثيل c5.18xlarge EC2. قوة الحوسبة من جانب العميل هي أيضًا شيء يجب مراعاته. في الأوقات التي تنفد فيها قوة الحوسبة من جانب العميل ، غالبًا لا يتم التقاط هذا ، ويتم اعتباره خطأ على أنه خطأ في نقطة نهاية SageMaker. من المهم وضع عميلك في موقع يتمتع بقدرة حوسبة كافية يمكنها التعامل مع الحمل الذي تختبر فيه. بالنسبة لمثال EC2 الخاص بنا ، نستخدم Ubuntu Deep Learning AMI ، ولكن يمكنك استخدام أي AMI طالما يمكنك إعداد Locust على الجهاز بشكل صحيح. لفهم كيفية بدء تشغيل مثيل EC2 الخاص بك والاتصال به ، ارجع إلى البرنامج التعليمي ابدأ مع مثيلات Amazon EC2 Linux.
يمكن الوصول إلى Locust UI عبر المنفذ 8089. ويمكننا فتح هذا من خلال تعديل قواعد مجموعة الأمان الواردة الخاصة بنا لمثيل EC2. نفتح أيضًا المنفذ 22 حتى نتمكن من SSH في مثيل EC2. ضع في اعتبارك تحديد نطاق المصدر وصولاً إلى عنوان IP المحدد الذي تقوم بالوصول إلى مثيل EC2 منه.

بعد اتصالك بمثيل EC2 الخاص بك ، نقوم بإعداد بيئة Python الافتراضية وتثبيت واجهة برمجة تطبيقات Locust مفتوحة المصدر عبر CLI:
نحن الآن جاهزون للعمل مع Locust لاختبار الحمل لنقطة النهاية الخاصة بنا.
اختبار الجراد
يتم إجراء جميع اختبارات حمل الجراد بناءً على أ ملف الجراد التي تقدمها. يحدد ملف Locust هذا مهمة لاختبار الحمل ؛ هذا هو المكان الذي نحدد فيه Boto3 استدعاء invoke_endpoint API. انظر الكود التالي:
في الكود السابق ، اضبط معلمات استدعاء نقطة النهاية الخاصة بك لتلائم استدعاء النموذج المحدد الخاص بك. نحن نستخدم ال InvokeEndpoint API باستخدام الجزء التالي من التعليمات البرمجية في ملف Locust ؛ هذه هي نقطة تشغيل اختبار الحمل لدينا. ملف Locust الذي نستخدمه هو locust_script.py.
الآن بعد أن أصبح لدينا سكربت Locust جاهزًا ، نريد إجراء اختبارات Locust الموزعة للتأكيد على اختبار المثيل الفردي الخاص بنا لمعرفة مقدار حركة المرور التي يمكن لمثالنا التعامل معها.
يعد وضع توزيع الجراد أكثر دقة قليلاً من اختبار الجراد أحادي العملية. في الوضع الموزع ، لدينا عامل واحد أساسي ومتعدد. يقوم العامل الأساسي بإرشاد العمال حول كيفية التوليد والتحكم في المستخدمين المتزامنين الذين يرسلون طلبًا. في منطقتنا وزعت. sh البرنامج النصي ، نرى افتراضيًا أنه سيتم توزيع 240 مستخدمًا على 60 عاملاً. نلاحظ أن --headless علامة في Locust CLI تزيل ميزة واجهة المستخدم الخاصة بـ Locust.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
نقوم أولاً بإجراء الاختبار الموزع على مثيل واحد يدعم نقطة النهاية. الفكرة هنا هي أننا نريد تعظيم مثيل واحد بشكل كامل لفهم عدد الحالات التي نحتاجها لتحقيق TPS المستهدف مع البقاء ضمن متطلبات زمن الانتقال. لاحظ أنه إذا كنت تريد الوصول إلى واجهة المستخدم ، فقم بتغيير ملف Locust_UI متغير البيئة إلى True وانتقل إلى عنوان IP العام لمثيل EC2 الخاص بك وقم بتعيين المنفذ 8089 إلى عنوان URL.
تُظهر لقطة الشاشة التالية مقاييس CloudWatch الخاصة بنا.

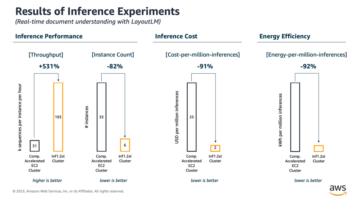
في النهاية ، لاحظنا أنه على الرغم من أننا حققنا في البداية TPS من 200 ، بدأنا في ملاحظة أخطاء 5xx في سجلاتنا من جانب عميل EC2 ، كما هو موضح في لقطة الشاشة التالية.
يمكننا أيضًا التحقق من ذلك من خلال النظر في المقاييس الخاصة بنا على مستوى المثيل ، على وجه التحديد CPUUtilization.
 هنا نلاحظ
هنا نلاحظ CPUUtilization بحوالي 4,800٪. يحتوي مثيل ml.m5.12x.large الخاص بنا على 48 وحدة معالجة مركزية كبيرة (48 * 100 = 4800 ~). هذا هو تشبع المثيل بالكامل ، مما يساعد أيضًا في تفسير أخطاء 5xx. نرى أيضًا زيادة في ModelLatency.
يبدو كما لو أن مثيلنا الوحيد قد تم إسقاطه وليس لديه الحوسبة للحفاظ على حمل يتجاوز 200 TPS التي نلاحظها. هدفنا TPS هو 1000 ، لذلك دعونا نحاول زيادة عدد المثيلات لدينا إلى 5. قد يكون هذا أكثر في إعداد الإنتاج ، لأننا كنا نلاحظ الأخطاء عند 200 TPS بعد نقطة معينة.

نرى في كل من سجلات Locust UI و CloudWatch أن لدينا TPS ما يقرب من 1000 مع خمس حالات تدعم نقطة النهاية.

 إذا بدأت في مواجهة الأخطاء حتى مع إعداد هذا الجهاز ، فتأكد من المراقبة
إذا بدأت في مواجهة الأخطاء حتى مع إعداد هذا الجهاز ، فتأكد من المراقبة CPUUtilization لفهم الصورة الكاملة لاستضافة نقطة النهاية الخاصة بك. من الأهمية بمكان فهم استخدامك للأجهزة لمعرفة ما إذا كنت بحاجة إلى توسيع النطاق أو حتى خفضه. في بعض الأحيان ، تؤدي مشكلات مستوى الحاوية إلى أخطاء 5xx ، ولكن إذا CPUUtilization منخفضة ، فهذا يشير إلى أنه ليس جهازك ولكن شيئًا ما على مستوى الحاوية أو الطراز قد يؤدي إلى هذه المشكلات (متغير البيئة المناسب لعدد العمال الذين لم يتم تعيينهم ، على سبيل المثال). من ناحية أخرى ، إذا لاحظت أن مثلك أصبح مشبعًا تمامًا ، فهذه علامة على أنك بحاجة إما إلى زيادة أسطول المثيل الحالي أو تجربة مثيل أكبر بأسطول أصغر.
على الرغم من أننا قمنا بزيادة عدد المثيلات إلى 5 للتعامل مع 100 TPS ، يمكننا أن نرى أن ملف ModelLatency المقياس لا يزال مرتفعًا. هذا يرجع إلى الحالات المشبعة. بشكل عام ، نقترح استهداف استخدام موارد المثيل بين 60-70٪.
تنظيف
بعد اختبار الحمل ، تأكد من تنظيف أي موارد لن تستخدمها عبر وحدة تحكم SageMaker أو من خلال ملف delete_endpoint استدعاء Boto3 API. بالإضافة إلى ذلك ، تأكد من إيقاف مثيل EC2 الخاص بك أو أي إعداد عميل لديك حتى لا تتحمل أي رسوم أخرى هناك أيضًا.
نبذة عامة
في هذا المنشور ، وصفنا كيف يمكنك تحميل اختبار نقطة النهاية في الوقت الفعلي من SageMaker. ناقشنا أيضًا المقاييس التي يجب عليك تقييمها عند تحميل اختبار نقطة النهاية الخاصة بك لفهم انهيار الأداء الخاص بك. تأكد من إطلاعك التوصية بالاستدلال SageMaker لفهم حجم المثيل الصحيح والمزيد من تقنيات تحسين الأداء.
حول المؤلف
 مارك كارب هو مهندس ML مع فريق خدمة SageMaker. يركز على مساعدة العملاء في تصميم ونشر وإدارة أعباء عمل ML على نطاق واسع. في أوقات فراغه ، يستمتع بالسفر واستكشاف أماكن جديدة.
مارك كارب هو مهندس ML مع فريق خدمة SageMaker. يركز على مساعدة العملاء في تصميم ونشر وإدارة أعباء عمل ML على نطاق واسع. في أوقات فراغه ، يستمتع بالسفر واستكشاف أماكن جديدة.
 رام فيجيراجو هو مهندس ML مع فريق خدمة SageMaker. يركز على مساعدة العملاء في بناء حلول الذكاء الاصطناعي / التعلم الآلي وتحسينها على Amazon SageMaker. يحب السفر والكتابة في أوقات فراغه.
رام فيجيراجو هو مهندس ML مع فريق خدمة SageMaker. يركز على مساعدة العملاء في بناء حلول الذكاء الاصطناعي / التعلم الآلي وتحسينها على Amazon SageMaker. يحب السفر والكتابة في أوقات فراغه.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- ماهرون
- فوق
- مقبول
- الوصول
- يمكن الوصول
- الوصول
- بدقة
- التأهيل
- في
- إضافة
- العنوان
- بعد
- ضد
- AI / ML
- تهدف
- الكل
- يسمح
- بالرغم ان
- أمازون
- Amazon EC2
- الأمازون SageMaker
- كمية
- تحليل
- و
- API
- حول
- مجموعة
- يرفق
- التأليف
- السيارات
- تلقائيا
- متاح
- AWS
- الى الخلف
- المدعومة
- دعم
- على أساس
- لان
- وراء
- يجري
- مؤشر
- تستفيد
- الفوائد
- أفضل
- أفضل الممارسات
- ما بين
- الجسدي
- انهيار
- نساعدك في بناء
- C + +
- دعوة
- دعوات
- يستطيع الحصول على
- أسر
- يلتقط
- يو كاتش
- معين
- تغيير
- اسعارنا محددة من قبل وزارة العمل
- التحقق
- فئة
- تصنيف
- زبون
- الكود
- مشترك
- متوافق
- إحصاء
- منافس
- إدارة
- الاعداد
- أكد
- التواصل
- متصل
- التواصل
- نظر
- نظر
- كنسولات
- وعاء
- يحتوي
- سياق الكلام
- مراقبة
- المقابلة
- استطاع
- بهيكل
- ويغطي
- وحدة المعالجة المركزية:
- خلق
- حاسم
- حالياًّ
- على
- العملاء
- البيانات
- عميق
- التعلم العميق
- أعمق
- الترتيب
- يعرف
- شرح
- اعتمادا
- يعتمد
- نشر
- نشر
- وصف
- وصف
- تصميم
- المطورين
- مختلف
- مباشرة
- ناقش
- العرض
- وزعت
- لا
- لا
- إلى أسفل
- كل
- بسهولة
- فعال
- بكفاءة
- إما
- تمكن
- النهائي إلى نهاية
- نقطة النهاية
- كامل
- البيئة
- خطأ
- أخطاء
- أساسي
- الأثير (ETH)
- حتى
- مثال
- استثناء
- تنفيذ
- تعاني
- شرح
- استكشاف
- اكتشف
- استكشاف
- تصدير
- جدا
- الوجه
- العوامل
- شلالات
- مألوف
- الميزات
- قليل
- قم بتقديم
- أخيرا
- الاسم الأول
- سريع
- تركز
- ويركز
- متابعيك
- شكل
- الإطار
- متكرر
- تبدأ من
- بالإضافة إلى
- تماما
- إضافي
- العلاجات العامة
- على العموم
- دولار فقط واحصل على خصم XNUMX% على جميع
- الحصول على
- خير
- رسم بياني
- أكبر
- تجمع
- مجموعات
- مقبض
- سعيد
- أجهزة التبخير
- مساعدة
- مساعدة
- يساعد
- هنا
- مرتفع
- جدا
- غطاء محرك السيارة
- مضيف
- استضافت
- استضافة
- كيفية
- كيفية
- HTML
- HTTPS
- محور
- فكرة
- المثالي
- محدد
- تحديد
- التأثير
- تنفيذ
- نفذت
- استيراد
- أهمية
- in
- يشمل
- القيمة الاسمية
- زيادة
- يشير
- إشارة
- معلومات
- في البداية
- تثبيت
- مثل
- المتكاملة
- التفاعلية
- Internet
- يتضرع
- IP
- عنوان IP
- معزول
- مسائل
- IT
- نفسها
- جسون
- كبير
- إلى حد كبير
- أكبر
- كمون
- إطلاق
- طبقات
- قيادة
- قيادة
- تعلم
- مستوى
- لينكس
- قائمة
- القليل
- تحميل
- الأحمال
- موقع
- طويل
- أبحث
- الكثير
- منخفض
- آلة
- آلة التعلم
- الآلات
- جعل
- القيام ب
- إدارة
- تمكن
- يدويا
- كثير
- رسم خريطة
- تعظيم
- يعني
- تعرف علي
- الاجتماع
- مكبر الصوت : يدعم، مع دعم ميكروفون مدمج لمنع الضوضاء
- متري
- المقاييس
- ربما
- الحد الأدنى
- ML
- موضة
- نموذج
- عارضات ازياء
- مراقبة
- الأكثر من ذلك
- أكثر فعالية
- متعدد
- الاسم
- تقريبا
- بالضرورة
- حاجة
- جديد
- مفكرة
- عدد
- ONE
- جاكيت
- المصدر المفتوح
- عمليات
- التحسين
- الأمثل
- الأمثل
- خيار
- مزيد من الخيارات
- طلب
- أخرى
- في الخارج
- الخاصة
- طلاء
- المعلمات
- جزء
- مرت
- الماضي
- مسار
- نمط
- أنماط
- قمة
- نفذ
- أداء
- منظور
- اختيار
- صورة
- قطعة
- المكان
- وجهات
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- المزيد
- البوينت
- منشور
- يحتمل
- قوة
- ممارسة
- الممارسات
- متنبئ
- ابتدائي
- طباعة
- مشاكل
- عملية المعالجة
- العمليات
- الإنتــاج
- ملفي الشخصي
- لائق
- بصورة صحيحة
- تزود
- ويوفر
- تقديم
- جمهور
- بايثون
- الأسئلة المتكررة
- بسرعة
- نطاق
- استعداد
- في الوقت الحقيقي
- أدرك
- يتلقى
- موصى به
- منطقة
- ذات صلة
- طلب
- المتطلبات الأساسية
- الموارد
- استجابة
- REST
- نتيجة
- النتائج
- عائدات
- القواعد
- يجري
- تشغيل
- sagemaker
- الاستدلال SageMaker
- حجم
- التحجيم
- العلماء
- الفحص
- مخطوطات
- الثاني
- أمن
- يبدو
- SELF
- إرسال
- عاطفة
- الخدمة
- خدمة
- طقم
- ضبط
- إعدادات
- الإعداد
- عدة
- ينبغي
- أظهرت
- يظهر
- إشارة
- مماثل
- الاشارات
- ببساطة
- عزباء
- حجم
- الأصغر
- So
- الحلول
- شيء
- مصدر
- مصادر
- نسل
- محدد
- على وجه التحديد
- غزل
- معيار
- بداية
- بدأت
- البيانات
- خطوة
- لا يزال
- قلة النوم
- إجهاد
- السعي
- هذه
- كاف
- بدلة
- فائق
- ملحق
- أخذ
- يأخذ
- الهدف
- مهمة
- المهام
- فريق
- تقنيات
- تجربه بالعربي
- اختبار المدى
- الاختبار
- اختبارات
- تصنيف النص
- •
- المصدر
- من مشاركة
- طرف ثالث
- الآلاف
- عبر
- الوقت
- مرات
- إلى
- أداة
- أدوات
- TPS
- مسار
- تتبع الشحنة
- حركة المرور
- قطار
- المعاملات
- السفر
- صحيح
- البرنامج التعليمي
- أنواع
- أوبونتو
- ui
- مع
- فهم
- فهم
- وحدة
- URL
- us
- تستخدم
- المستخدمين
- الاستفادة من
- تستخدم
- يستخدم
- استخدام
- تشكيلة
- تحقق من
- بواسطة
- افتراضي
- ابحث عن
- سواء
- التي
- في حين
- سوف
- في غضون
- للعمل
- عامل
- العمال
- سوف
- جاري الكتابة
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت