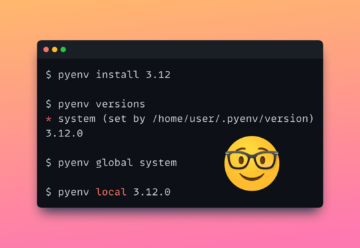
قم ببناء خط أنابيب بيانات اصطناعية باستخدام Gretel و Apache Airflow
في منشور المدونة هذا ، قمنا ببناء خط أنابيب ETL يقوم بإنشاء بيانات تركيبية من قاعدة بيانات PostgreSQL باستخدام واجهات برمجة تطبيقات البيانات الاصطناعية من Gretel و Apache Airflow.
By درو نيوبيري، Software Engineer في Gretel.ai

مرحبًا يا رفاق ، اسمي درو وأنا مهندس برمجيات هنا في جريتيل. لقد فكرت مؤخرًا في أنماط دمج Gretel APIs في الأدوات الحالية بحيث يكون من السهل إنشاء خطوط بيانات حيث يكون الأمان وخصوصية العميل من ميزات الدرجة الأولى ، وليست مجرد فكرة لاحقة أو مربع للتحقق منه.
تعد Apache Airflow إحدى أدوات هندسة البيانات الشائعة بين مهندسي وعملاء Gretel. يحدث أيضًا أن تعمل بشكل رائع مع Gretel. في منشور المدونة هذا ، سنوضح لك كيفية إنشاء خط أنابيب بيانات اصطناعية باستخدام Airflow و Gretel و PostgreSQL. دعنا نقفز!
ما هو تدفق الهواء
تدفق الهواء هي أداة أتمتة لسير العمل تُستخدم بشكل شائع لبناء خطوط أنابيب البيانات. إنه يمكّن مهندسي البيانات أو علماء البيانات من تحديد خطوط الأنابيب هذه ونشرها برمجيًا باستخدام Python وغيرها من التركيبات المألوفة. في جوهر تدفق الهواء هو مفهوم DAG ، أو الرسم البياني غير الدوري الموجه. يوفر Airflow DAG نموذجًا ومجموعة من واجهات برمجة التطبيقات لتحديد مكونات خطوط الأنابيب وتبعياتها وترتيب التنفيذ.
قد تجد خطوط أنابيب Airflow تنسخ البيانات من قاعدة بيانات المنتج إلى مستودع البيانات. قد تقوم خطوط الأنابيب الأخرى بتنفيذ الاستعلامات التي تربط البيانات الموحدة في مجموعة بيانات واحدة مناسبة للتحليلات أو النمذجة. قد ينشر خط أنابيب آخر تقريرًا يوميًا يجمع مقاييس العمل الرئيسية. موضوع مشترك بين حالات الاستخدام هذه: تنسيق حركة البيانات عبر الأنظمة. هذا هو المكان الذي يضيء فيه Airflow.
الاستفادة من تدفق الهواء ونظامه البيئي الغني بـ التكاملات، يمكن لمهندسي البيانات والعلماء تنسيق أي عدد من الأدوات أو الخدمات المتباينة في خط أنابيب موحد واحد يسهل صيانته وتشغيله. من خلال فهم إمكانات التكامل هذه ، سنبدأ الآن في الحديث عن كيفية دمج Gretel في خط أنابيب Airflow لتحسين تدفقات سير عمل عمليات البيانات الشائعة.
كيف يتلاءم جريتل؟
مهمتنا في Gretel هي جعل البيانات أسهل وأكثر أمانًا للعمل معها. عند التحدث إلى العملاء ، فإن إحدى النقاط المؤلمة التي نسمع عنها غالبًا هي الوقت والجهد اللازمين للوصول إلى علماء البيانات للوصول إلى البيانات الحساسة. استخدام جريتيل التركيبية، يمكننا تقليل مخاطر التعامل مع البيانات الحساسة من خلال إنشاء نسخة تركيبية من مجموعة البيانات. من خلال دمج Gretel مع Airflow ، من الممكن إنشاء خطوط أنابيب ذاتية الخدمة تسهل على علماء البيانات الحصول بسرعة على البيانات التي يحتاجونها دون الحاجة إلى مهندس بيانات لكل طلب بيانات جديد.
لإثبات هذه القدرات ، سنقوم ببناء خط أنابيب ETL يستخرج ميزات نشاط المستخدم من قاعدة بيانات ، وينشئ نسخة تركيبية من مجموعة البيانات ، ويحفظ مجموعة البيانات في S3. مع مجموعة البيانات التركيبية المحفوظة في S3 ، يمكن لعلماء البيانات استخدامها بعد ذلك من أجل النمذجة النهائية أو التحليل دون المساس بخصوصية العميل.
لبدء الأمور ، دعنا أولاً نلقي نظرة عامة على خط الأنابيب. تمثل كل عقدة في هذا الرسم البياني خطوة خط أنابيب أو "مهمة" في شروط تدفق الهواء.

مثال على خط أنابيب Gretel التركيبية على تدفق الهواء.
يمكننا تقسيم خط الأنابيب إلى 3 مراحل ، على غرار ما قد تجده في خط أنابيب ETL:
- مقتطف - ستعمل مهمة extract_features على الاستعلام عن قاعدة البيانات ، وتحويل البيانات إلى مجموعة من الميزات التي يمكن لعلماء البيانات استخدامها لبناء النماذج.
- تركيب - ستأخذ ميزة إنشاء_تصنيع_الميزات الميزات المستخرجة كمدخلات ، وتدريب نموذج تركيبي ، ثم إنشاء مجموعة تركيبية من الميزات باستخدام واجهات برمجة تطبيقات جريتيل والخدمات السحابية.
- حمل - يحفظ upload_synthetic_features مجموعة الميزات التركيبية في S3 حيث يمكن استيعابها في أي نموذج أو تحليل لاحق.
في الأقسام القليلة التالية سوف نتعمق في كل خطوة من هذه الخطوات الثلاث بمزيد من التفصيل. إذا كنت ترغب في المتابعة مع كل عينة رمز ، فيمكنك التوجه إلى خطوط أنابيب جريتلاي / جريتيل لتدفق الهواء وقم بتنزيل جميع الأكواد المستخدمة في منشور المدونة هذا. يحتوي الريبو أيضًا على إرشادات يمكنك اتباعها لبدء مثيل Airflow وتشغيل خط الأنابيب من النهاية إلى النهاية.
بالإضافة إلى ذلك ، قد يكون من المفيد عرض خط أنابيب Airflow بالكامل ، قبل أن نقوم بتشريح كل مكون ، dags / airbnb_user_bookings.py. يتم استخراج مقتطفات التعليمات البرمجية في الأقسام التالية من خط أنابيب حجز المستخدم المرتبط.
استخراج الميزات
المهمة الأولى ، extract_features هي المسؤولة عن استخراج البيانات الأولية من قاعدة البيانات المصدر وتحويلها إلى مجموعة من الميزات. هذا أمر شائع هندسة الميزات مشكلة قد تجدها في أي خط أنابيب للتعلم الآلي أو التحليلات.
في مثالنا ، سنوفر قاعدة بيانات PostgreSQL ونحمّلها ببيانات الحجز من ملف مسابقة Airbnb Kaggle.
تحتوي مجموعة البيانات هذه على جدولين ، المستخدمون والجلسات. تحتوي الجلسات على مرجع مفتاح خارجي ، user_id. باستخدام هذه العلاقة ، سننشئ مجموعة من الميزات التي تحتوي على مقاييس حجز متنوعة مجمعة من قبل المستخدم. يمثل الشكل التالي استعلام SQL المستخدم لبناء الميزات.
WITH Session_features_by_user AS (SELECT user_id، count (*) AS number_of_actions_taken، count (DISTINCT action_type) AS number_of_unique_actions، round (avg (secs_elapsed)) AS avg_session_time_seconds، round (max (secs_elapsed_sonds)) min_session_time_seconds ، (عدد التحديد (*) من الجلسات s حيث s.user_id = user_id AND s.action_type = 'booking_request') AS total_bookings من الجلسات GROUP BY user_id) حدد u.id AS user_id ، u.gender ، u.age ، u .language، u.signup_method، u.date_account_created، s.number_of_actions_taken، s.number_of_unique_actions، s.avg_session_time_seconds، s.min_session_time_seconds، s.max_session_time_seconds.
ثم يتم تنفيذ استعلام SQL من خط أنابيب Airflow الخاص بنا وكتابته إلى موقع S3 وسيط باستخدام تعريف المهمة التالي.
task () def extract_features (sql_file: str) -> str: Context = get_current_context () sql_query = المسار (sql_file) .read_text () key = f "{Context ['dag_run']. run_id} _booking_features.csv" with NamedTporaryFile (mode = "r +"، لاحقة = ". csv") مثل tmp_csv: postgres.copy_expert (f "copy ({sql_query}) إلى stdout برأس csv" ، tmp_csv.name) s3.load_file (اسم الملف = tmp_csv.name ، key = key،) مفتاح الإرجاع
يحدد الإدخال إلى المهمة ، sql_file ، الاستعلام الذي سيتم تشغيله على قاعدة البيانات. ستتم قراءة هذا الاستعلام في المهمة ثم تنفيذه على قاعدة البيانات. ستتم كتابة نتائج الاستعلام بعد ذلك إلى S3 وسيعاد مفتاح الملف البعيد كناتج للمهمة.
تُظهر لقطة الشاشة أدناه عينة من نتائج استعلام الاستخراج أعلاه. سنشرح كيفية إنشاء نسخة تركيبية من مجموعة البيانات هذه في القسم التالي.

معاينة نتيجة الاستعلام.
تجميع الميزات باستخدام Gretel APIs
لإنشاء نسخة تركيبية من كل ميزة ، يجب علينا أولاً تدريب نموذج اصطناعي ، ثم تشغيل النموذج لإنشاء سجلات تركيبية. لدى Gretel مجموعة من Python SDKs التي تجعل من السهل دمجها في مهام Airflow.
بالإضافة إلى Python Client SDK ، أنشأنا ملف خطاف تدفق الهواء من جريتيل التي تدير اتصالات وأسرار Gretel API. بعد إعداد اتصال Gretel Airflow ، يكون الاتصال بـ Gretel API سهلاً مثل
من hooks.gretel استيراد GretelHook gretel = GretelHook () project = gretel.get_project ()
لمزيد من المعلومات حول كيفية تكوين اتصالات Airflow ، يرجى الرجوع إلى مستودع Github الخاص بنا README.
يمكن استخدام متغير المشروع في المثال أعلاه كنقطة دخول رئيسية للتدريب وتشغيل النماذج الاصطناعية باستخدام واجهة برمجة تطبيقات Gretel. لمزيد من التفاصيل ، يمكنك التحقق من موقعنا مستندات Python API.
بالرجوع إلى مسار الحجز ، سنراجع الآن مهمة create_synthetic_features. هذه الخطوة مسؤولة عن تدريب النموذج الاصطناعي باستخدام الميزات المستخرجة في المهمة السابقة.
task () def create_synthetic_features (data_source: str) -> str: project = gretel.get_project () model = project.create_model_obj (model_config = "synthetics / default" ، data_source = s3.download_file (data_source)) model.submit_cloud استطلاع (نموذج) إرجاع model.get_artifact_link ("data_preview")
بالنظر إلى توقيع الطريقة ، سترى أنه يأخذ مسار ، data_source. تشير هذه القيمة إلى ميزات S3 المستخرجة في الخطوة السابقة. في قسم لاحق ، سنتعرف على كيفية توصيل كل هذه المدخلات والمخرجات معًا.
عند إنشاء النموذج باستخدام project.create_model_obj ، تمثل معلمة model_config تكوين النموذج الاصطناعي المستخدم في إنشاء النموذج. في خط الأنابيب هذا ، نستخدم التكوين الافتراضي للنموذج، ولكن العديد من الآخرين خيارات التكوين متوفرة.
بعد تهيئة النموذج ، نسمي model.submit_cloud (). سيقدم هذا النموذج للتدريب وتوليد السجلات باستخدام Gretel Cloud. سيؤدي استطلاع الاستدعاء (النموذج) إلى حظر المهمة حتى يكمل النموذج التدريب.
الآن وقد تم تدريب النموذج ، سنستخدم get_artifact_link لإرجاع رابط لتنزيل الميزات التركيبية التي تم إنشاؤها.

معاينة البيانات لمجموعة الميزات التركيبية.
سيتم استخدام هذا الرابط الاصطناعي كمدخل لخطوة تحميل_الميزات_الصناعية النهائية.
تحميل الميزات الاصطناعية
تم استخراج الميزات الأصلية وإنشاء نسخة تركيبية. حان الوقت الآن لتحميل الميزات التركيبية بحيث يمكن الوصول إليها من قبل المستهلكين في المراحل النهائية. في هذا المثال ، سنستخدم حاوية S3 كوجهة نهائية لمجموعة البيانات.
task () def upload_synthetic_features (data_set: str): Context = get_current_context () with open (data_set، "rb") as synth_features: s3.load_file_obj (file_obj = synth_features، key = f "{..._ booking_features_synthetic.csv"، )
هذه المهمة واضحة ومباشرة. تحتوي قيمة الإدخال data_set على ارتباط HTTP موقع لتنزيل مجموعة البيانات التركيبية من واجهة برمجة تطبيقات Gretel. ستقرأ المهمة هذا الملف في عامل Airflow ، ثم تستخدم خطاف S3 الذي تم تكوينه بالفعل لتحميل ملف الميزة الاصطناعية إلى حاوية S3 حيث يمكن للمستهلكين أو الطرز الوصول إليه.
تنظيم خط الأنابيب
خلال الأقسام الثلاثة الماضية ، مررنا عبر جميع التعليمات البرمجية المطلوبة لاستخراج مجموعة بيانات وتوليفها وتحميلها. تتمثل الخطوة الأخيرة في ربط كل مهمة من هذه المهام معًا في خط أنابيب واحد لتدفق الهواء.
إذا كنت ستتذكر مرة أخرى إلى بداية هذا المنشور ، فقد ذكرنا بإيجاز مفهوم DAG. باستخدام واجهة برمجة تطبيقات TaskFlow الخاصة بـ Airflow ، يمكننا تكوين طرق Python الثلاثة هذه في DAG التي تحدد المدخلات والمخرجات وترتيب كل خطوة سيتم تشغيلها.
feature_path = extract_features ("/opt/airflow/dags/sql/session_rollups__by_user.sql")
إذا اتبعت مسار استدعاءات الطريقة هذه ، فستحصل في النهاية على رسم بياني يشبه خط أنابيب الميزات الأصلي الخاص بنا.
خط أنابيب جريتل التركيبي على تدفق الهواء.
إذا كنت ترغب في تشغيل خط الأنابيب هذا ، ورؤيته قيد التنفيذ ، فتوجه إلى المصاحب لمستودع جيثب. ستجد هناك إرشادات حول كيفية بدء مثيل Airflow وتشغيل خط الأنابيب من النهاية إلى النهاية.
التفاف الأشياء
إذا كنت قد وصلت إلى هذا الحد ، فقد رأيت كيف يمكن دمج Gretel في خط أنابيب بيانات مبني على Airflow. من خلال الجمع بين واجهات برمجة التطبيقات الصديقة للمطورين من Gretel ونظام Airflow القوي للخطافات والمشغلين ، من السهل إنشاء خطوط أنابيب ETL التي تجعل البيانات أكثر سهولة وأمانًا في الاستخدام.
تحدثنا أيضًا عن حالة استخدام هندسي للميزات الشائعة حيث قد لا يمكن الوصول إلى البيانات الحساسة بسهولة. من خلال إنشاء نسخة تركيبية من مجموعة البيانات ، فإننا نحد من مخاطر الكشف عن أي بيانات حساسة ، ولكننا لا نزال نحتفظ بفائدة مجموعة البيانات مع إتاحتها بسرعة لمن يحتاجونها.
بالتفكير في خط أنابيب الميزات بمصطلحات أكثر تجريدًا ، لدينا الآن نمط يمكن إعادة توجيهه لأي عدد من استعلامات SQL الجديدة. من خلال نشر إصدار جديد من خط الأنابيب ، واستبدال استعلام SQL الأولي ، يمكننا مواجهة أي استعلام يحتمل أن يكون حساسًا بمجموعة بيانات تركيبية تحافظ على خصوصية العميل. السطر الوحيد من التعليمات البرمجية الذي يحتاج إلى تغيير هو المسار إلى ملف sql. لا تتطلب هندسة بيانات معقدة.
شكرا للقراءة
أرسل لنا رسالة بريد إلكتروني على hi@gretel.ai أو تعال وانضم إلينا فترة ركود إذا كان لديك أي أسئلة أو تعليقات. نود أن نسمع كيف تستخدم Airflow وكيف يمكننا الاندماج بشكل أفضل مع خطوط أنابيب البيانات الحالية لديك.
السيرة الذاتية: درو نيوبيري هو مهندس برمجيات في Gretel.ai.
أصلي. تم إعادة النشر بإذن.
هذا الموضوع ذو علاقة بـ:
| أهم الأخبار في الثلاثين يومًا الماضية | |||||
|---|---|---|---|---|---|
|
|
||||
المصدر: https://www.kdnuggets.com/2021/09/build-synthetic-data-pipeline-gretel-apache-airflow.html
- "
- &
- الوصول
- اكشن
- AI
- الكل
- تحليل
- تحليلات
- أباتشي
- API
- واجهات برمجة التطبيقات
- تطبيق
- السيارات
- أتمتة
- أفضل
- المدونة
- صندوق
- نساعدك في بناء
- ابني
- الأعمال
- الحالات
- تغيير
- سحابة
- الخدمات السحابية
- الكود
- تعليقات
- مشترك
- عنصر
- التواصل
- المستهلكين
- خلق
- العملاء
- DAG
- البيانات
- علم البيانات
- مستودع البيانات
- قاعدة البيانات
- التعلم العميق
- التفاصيل
- المطور
- مدير المدارس
- النظام الإيكولوجي
- البريد الإلكتروني
- مهندس
- الهندسة
- المهندسين
- استخلاص
- مقتطفات
- عين
- الميزات
- المميزات
- الشكل
- الاسم الأول
- تناسب
- اتباع
- الجنس
- GitHub جيثب:
- وحدات معالجة الرسومات
- عظيم
- تجمع
- رئيس
- هنا
- كيفية
- كيفية
- HTTPS
- معلومات
- التكامل
- المقابلة الشخصية
- IT
- الانضمام
- قفز
- القفل
- لغة
- تعلم
- تعلم
- خط
- LINK
- لينكدين:
- تحميل
- موقع
- حب
- آلة التعلم
- القيام ب
- المقاييس
- الرسالة
- ML
- نموذج
- تصميم
- عصبي
- جاكيت
- المصدر المفتوح
- طلب
- أخرى
- الم
- نمط
- أكثر الاستفسارات
- أرسال
- خصوصية
- منتج
- تنفيذ المشاريع
- نشر
- بايثون
- الخام
- مسودة بيانات
- الأسباب
- تسجيل
- تخفيض
- تراجع
- تقرير
- النتائج
- مراجعة
- المخاطرة
- يجري
- تشغيل
- علوم
- العلماء
- أمن
- خدمات
- طقم
- ضبط
- شاركت
- So
- تطبيقات الكمبيوتر
- مهندس البرمجيات
- SQL
- بداية
- قصص
- البيانات الاصطناعية
- نظام
- أنظمة
- الحديث
- المصدر
- موضوع
- تفكير
- رابطة عنق
- الوقت
- تيشرت
- قادة الإيمان
- تحويل
- us
- المستخدمين
- سهل حياتك
- قيمنا
- المزيد
- المخزن
- من الذى
- ويكيبيديا
- للعمل
- سير العمل
- سير العمل الآلي
- X