في نوفمبر 2022 ، نحن أعلن يمكن لعملاء AWS إنشاء صور من نص باستخدام انتشار مستقر نماذج في أمازون سيج ميكر جومب ستارت. يعد Stable Diffusion نموذجًا تعليميًا عميقًا يتيح لك إنشاء صور واقعية عالية الجودة وفنًا مذهلاً في بضع ثوانٍ فقط. على الرغم من أن إنشاء صور رائعة يمكن أن تجد استخدامه في صناعات تتراوح من الفن إلى NFTs وما بعدها ، فإننا نتوقع اليوم أيضًا أن يكون الذكاء الاصطناعي قابلاً للتخصيص. نعلن اليوم أنه يمكنك تخصيص نموذج إنشاء الصور ليناسب حالة الاستخدام الخاصة بك عن طريق ضبطه على مجموعة البيانات المخصصة الخاصة بك في أمازون سيج ميكر جومب ستارت. يمكن أن يكون هذا مفيدًا عند إنشاء الفن والشعارات والتصميمات المخصصة و NFTs وما إلى ذلك ، أو الأشياء الممتعة مثل إنشاء صور AI مخصصة لحيواناتك الأليفة أو صورك الرمزية.
في هذا المنشور ، نقدم نظرة عامة حول كيفية ضبط نموذج الانتشار المستقر بطريقتين: برمجيًا من خلال واجهات برمجة تطبيقات JumpStart متوفر في SageMaker بيثون SDK، وواجهة مستخدم JumpStart بتنسيق أمازون ساجميكر ستوديو. نناقش أيضًا كيفية تحديد خيارات التصميم بما في ذلك جودة مجموعة البيانات وحجم مجموعة بيانات التدريب واختيار قيم المعلمات الفائقة وإمكانية التطبيق على مجموعات بيانات متعددة. أخيرًا ، نناقش أكثر من 80 نموذجًا مضبوطًا متاحًا للجمهور مع لغات وأنماط إدخال مختلفة تمت إضافتها مؤخرًا في JumpStart.
انتشار مستقر ونقل التعلم
الانتشار المستقر هو نموذج نص إلى صورة يمكّنك من إنشاء صور واقعية من مجرد مطالبة نصية. يتدرب نموذج الانتشار من خلال تعلم إزالة الضوضاء التي تمت إضافتها إلى صورة حقيقية. تولد عملية إزالة الضوضاء هذه صورة واقعية. يمكن لهذه النماذج أيضًا إنشاء صور من النص وحده عن طريق تكييف عملية الإنشاء على النص. على سبيل المثال ، يعد Stable Diffusion انتشارًا كامنًا حيث يتعلم النموذج التعرف على الأشكال في صورة ضوضاء خالصة ويضع هذه الأشكال في التركيز تدريجيًا إذا كانت الأشكال تتطابق مع الكلمات الموجودة في نص الإدخال. يجب أولاً تضمين النص في مساحة كامنة باستخدام نموذج اللغة. بعد ذلك ، يتم إجراء سلسلة من عمليات إضافة الضوضاء وإزالة الضوضاء في المساحة الكامنة باستخدام بنية U-Net. أخيرًا ، يتم فك تشفير الإخراج غير المشوش في مساحة البكسل.
في التعلم الآلي (ML) ، تسمى القدرة على نقل المعرفة المكتسبة في مجال إلى آخر نقل التعلم. يمكنك استخدام نقل التعلم لإنتاج نماذج دقيقة على مجموعات البيانات الأصغر ، مع تكاليف تدريب أقل بكثير من تلك المستخدمة في تدريب النموذج الأصلي. باستخدام نقل التعلم ، يمكنك ضبط نموذج الانتشار المستقر على مجموعة البيانات الخاصة بك مع أقل من خمس صور. على سبيل المثال ، توجد على اليسار صور تدريب لكلب يُدعى دوبلر تُستخدم لضبط النموذج ، في المنتصف واليمين توجد صور تم إنشاؤها بواسطة النموذج الدقيق عندما يُطلب منك التنبؤ بصورة دوبلر على الشاطئ ورسم بالقلم الرصاص.

على اليسار توجد صور لكرسي أبيض يستخدم لضبط النموذج وصورة للكرسي باللون الأحمر تم إنشاؤها بواسطة النموذج الدقيق. على اليمين توجد صور لعثماني يستخدم لضبط النموذج وصورة قطة جالسة على عثماني.

عادةً ما يتطلب منك الضبط الدقيق للنماذج الكبيرة مثل Stable Diffusion توفير نصوص تدريبية. هناك مجموعة من المشكلات ، بما في ذلك مشكلات نفاد الذاكرة ومشكلات حجم الحمولة والمزيد. علاوة على ذلك ، يجب عليك إجراء اختبارات شاملة للتأكد من أن البرنامج النصي والنموذج والمثيل المطلوب يعملان معًا بطريقة فعالة. يبسط JumpStart هذه العملية من خلال توفير البرامج النصية الجاهزة للاستخدام التي تم اختبارها بقوة. يعتمد البرنامج النصي لصقل JumpStart لنماذج Stable Diffusion على نص الضبط الدقيق من دريم بوث. يمكنك الوصول إلى هذه البرامج النصية بنقرة واحدة من خلال Studio UI أو بأسطر قليلة جدًا من التعليمات البرمجية من خلال ملف واجهات برمجة تطبيقات JumpStart.
لاحظ أنه باستخدام نموذج Stable Diffusion ، فإنك توافق على CreativeML Open RAIL ++ - ترخيص M..
استخدم JumpStart برمجيًا مع SageMaker SDK
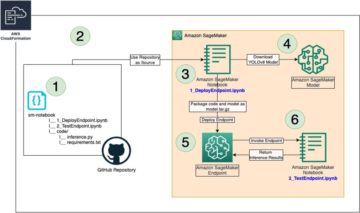
يصف هذا القسم كيفية تدريب النموذج ونشره باستخدام ملف SageMaker بيثون SDK. نختار نموذجًا مناسبًا تم تدريبه مسبقًا في JumpStart ، ونقوم بتدريب هذا النموذج بوظيفة تدريب SageMaker ، ونشر النموذج المدرب إلى نقطة نهاية SageMaker. علاوة على ذلك ، نقوم بتشغيل الاستدلال على نقطة النهاية المنشورة ، وكل ذلك باستخدام SageMaker Python SDK. تحتوي الأمثلة التالية على مقتطفات التعليمات البرمجية. للحصول على الكود الكامل مع جميع الخطوات في هذا العرض التوضيحي ، راجع ملف مقدمة إلى JumpStart - تحويل النص إلى صورة مثال مفكرة.
تدريب وضبط نموذج الانتشار المستقر
يتم تحديد كل نموذج من قبل فريد model_id. يوضح الكود التالي كيفية ضبط نموذج أساسي للانتشار المستقر 2.1 المحدد بواسطة model_id model-txt2img-stabilityai-stable-diffusion-v2-1-base على مجموعة بيانات تدريب مخصصة. للحصول على قائمة كاملة من model_id القيم والنماذج التي يمكن ضبطها ، راجع خوارزميات مدمجة مع نموذج جدول مدرب مسبقًا. لكل واحد model_id، من أجل إطلاق وظيفة تدريب SageMaker من خلال مقدر فئة SageMaker Python SDK ، فأنت بحاجة إلى إحضار URI لصورة Docker ، و URI للبرنامج النصي للتدريب ، و URI للنموذج المدرّب مسبقًا من خلال وظائف الأداة المساعدة المتوفرة في SageMaker. يحتوي البرنامج النصي للتدريب URI على جميع الكودات اللازمة لمعالجة البيانات ، وتحميل النموذج المدرب مسبقًا ، وتدريب النموذج ، وحفظ النموذج المدرب للاستدلال. يحتوي نموذج URI المدربين مسبقًا على تعريف بنية النموذج المدربين مسبقًا ومعلمات النموذج. نموذج URI المدرب مسبقًا خاص بالنموذج المعين. تم تنزيل كرات القطران النموذجية المدربة مسبقًا مسبقًا من Hugging Face وحفظها بتوقيع النموذج المناسب بتنسيق خدمة تخزين أمازون البسيطة حاويات (Amazon S3) ، مثل أن وظيفة التدريب تعمل بمعزل عن الشبكة. انظر الكود التالي:
باستخدام هذه الأدوات التدريبية الخاصة بالنموذج ، يمكنك إنشاء كائن من مقدر صف دراسي:
مجموعة بيانات التدريب
فيما يلي التعليمات الخاصة بكيفية تنسيق بيانات التدريب:
- إدخال - دليل يحتوي على صور المثيل ،
dataset_info.json، بالتكوين التالي:- قد تكون الصور بتنسيق .png أو .jpg أو .jpeg
- •
dataset_info.jsonيجب أن يكون الملف بالتنسيق{'instance_prompt':<<instance_prompt>>}
- الناتج - نموذج مدرب يمكن نشره للاستدلال
يجب أن يبدو مسار S3 مثل s3://bucket_name/input_directory/. لاحظ الزائدة / هو مطلوب.
فيما يلي مثال على تنسيق بيانات التدريب:
للحصول على إرشادات حول كيفية تنسيق البيانات أثناء استخدام الحفظ المسبق ، راجع القسم الحفظ المسبق في هذا المنشور.
نحن نقدم مجموعة بيانات افتراضية لصور القطط. يتكون من ثماني صور (صور مثيل تتوافق مع موجه المثيل) لقط واحد بدون صور للفئة. يمكن تنزيله من GitHub جيثب:. في حالة استخدام مجموعة البيانات الافتراضية ، جرب المطالبة "صورة لقطط riobugger" أثناء القيام بالاستدلال في دفتر العرض التوضيحي.
رخصة: معهد ماساتشوستس للتكنولوجيا.
معلمات هايبر
بعد ذلك ، لنقل التعلم على مجموعة البيانات المخصصة الخاصة بك ، قد تحتاج إلى تغيير القيم الافتراضية لمعلمات التدريب التشعبية. يمكنك إحضار قاموس Python لهذه المعلمات التشعبية بقيمها الافتراضية عن طريق الاتصال hyperparameters.retrieve_default، قم بتحديثها حسب الحاجة ، ثم قم بتمريرها إلى فئة المقدر. انظر الكود التالي:
يتم دعم المعلمات التشعبية التالية بواسطة خوارزمية الصقل:
- مع_الحفظ_السابق - علامة لإضافة فقدان الحفظ المسبق. الحفظ المسبق هو منظم يتجنب الإفراط في التجهيز. (اختيارات:
[“True”,“False”]، تقصير:“False”.) - عدد_صورة_صور - الحد الأدنى من صور الفئة لفقدان الحفظ المسبق. لو
with_prior_preservation = Trueولا توجد صور كافية موجودة بالفعل فيclass_data_dir، سيتم أخذ عينات من الصور الإضافية باستخدامclass_prompt. (القيم: عدد صحيح موجب ، الافتراضي: 100.) - العصور - عدد التمريرات التي تمر بها خوارزمية الضبط عبر مجموعة بيانات التدريب. (القيم: عدد صحيح موجب ، افتراضي: 20.)
- ماكس_ستيبس - العدد الإجمالي لخطوات التدريب المراد أداؤها. ان لم
None، يتجاوز العصور. (قيم:“None”أو سلسلة من عدد صحيح ، الافتراضي:“None”.) - حجم الدفعة -: عدد الأمثلة التدريبية التي تم العمل عليها قبل تحديث أوزان النموذج. نفس حجم الدُفعة أثناء إنشاء صور الفصل إذا كان
with_prior_preservation = True. (القيم: عدد صحيح موجب ، الافتراضي: 1.) - معدل التعليم - معدل تحديث أوزان النموذج بعد العمل من خلال كل دفعة من الأمثلة التدريبية. (القيم: تعويم موجب ، افتراضي: 2e-06.)
- الوزن_السابق - فقدان الوزن قبل الحفظ. (القيم: عدد عشري موجب ، افتراضي: 1.0.)
- center_crop - ما إذا كنت تريد اقتصاص الصور قبل تغيير حجمها إلى الدقة المطلوبة. (اختيارات:
[“True”/“False”]، تقصير:“False”.) - lr_scheduler - نوع جدول معدل التعلم. (اختيارات:
["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"]، تقصير:"constant".) لمزيد من المعلومات، راجع جدولة معدل التعلم. - adam_weight_decay - تسوس الوزن المطبق (إن لم يكن صفرًا) على جميع الطبقات باستثناء كل التحيز و
LayerNormالأوزان فيAdamWمحسن. (القيمة: تعويم ، الافتراضي: 1e-2.) - adam_beta1 - المعلمة الفائقة beta1 (معدل الانحلال الأسي لتقديرات اللحظة الأولى) لـ
AdamWمحسن. (القيمة: تعويم ، الافتراضي: 0.9.) - adam_beta2 - المعلمة الفائقة beta2 (معدل الانحلال الأسي لتقديرات اللحظة الأولى) لـ
AdamWمحسن. (القيمة: تعويم ، الافتراضي: 0.999.) - adam_epsilon - و
epsilonHyperparameter لAdamWمحسن. عادةً ما يتم تعيينه على قيمة صغيرة لتجنب القسمة على 0. (القيمة: تعويم ، الافتراضي: 1e-8.) - خطوات_تراكم_التدرج - عدد خطوات التحديثات التي يجب تجميعها قبل إجراء تمرير رجوع / تحديث. (القيمة: عدد صحيح ، الافتراضي: 1.)
- max_grad_norm - الحد الأقصى لمعيار التدرج (لقص التدرج). (القيمة: عائم ، الافتراضي: 1.0.)
- بذرة - إصلاح الحالة العشوائية لتحقيق نتائج قابلة للتكرار في التدريب. (القيمة: عدد صحيح ، الافتراضي: 0.)
نشر النموذج الجيد التدريب
بعد انتهاء تدريب النموذج ، يمكنك نشر النموذج مباشرةً إلى نقطة نهاية مستمرة في الوقت الفعلي. نجلب Docker Image URIs و script URIs وننشر النموذج. انظر الكود التالي:
على اليسار توجد صور تدريب لقط يدعى riobugger يستخدم لضبط النموذج (المعلمات الافتراضية باستثناء max_steps = 400). في المنتصف واليمين توجد الصور التي تم إنشاؤها بواسطة النموذج الدقيق عندما يُطلب منك التنبؤ بصورة riobugger على الشاطئ ورسم بالقلم الرصاص.

لمزيد من التفاصيل حول الاستدلال ، بما في ذلك المعلمات المدعومة وتنسيق الاستجابة وما إلى ذلك ، يرجى الرجوع إلى قم بإنشاء صور من نص باستخدام نموذج الانتشار المستقر على Amazon SageMaker JumpStart.
قم بالوصول إلى JumpStart من خلال Studio UI
في هذا القسم ، نوضح كيفية تدريب نماذج JumpStart ونشرها من خلال Studio UI. يوضح الفيديو التالي كيفية العثور على نموذج Stable Diffusion الذي تم تدريبه مسبقًا على JumpStart ، وتدريبه ، ثم نشره. تحتوي صفحة النموذج على معلومات قيمة حول النموذج وكيفية استخدامه. بعد تكوين مثيل تدريب SageMaker ، اختر قطار. بعد تدريب النموذج ، يمكنك نشر النموذج المدرب عن طريق الاختيار نشر. بعد أن تكون نقطة النهاية في مرحلة "قيد الخدمة" ، تكون جاهزة للرد على طلبات الاستدلال.
لتسريع وقت الاستدلال ، يوفر JumpStart نموذج دفتر ملاحظات يوضح كيفية تشغيل الاستدلال على نقطة النهاية المنشأة حديثًا. للوصول إلى دفتر الملاحظات في Studio ، اختر افتح المفكرة في ال استخدم نقطة النهاية من الاستوديو قسم من صفحة نقطة نهاية النموذج.
يوفر JumpStart أيضًا جهاز كمبيوتر محمول بسيطًا يمكنك استخدامه لضبط نموذج الانتشار المستقر ونشر النموذج الناتج المحسن. يمكنك استخدامه لإنشاء صور ممتعة لكلبك. للوصول إلى دفتر الملاحظات ، ابحث عن "إنشاء صور ممتعة لكلبك" في شريط بحث JumpStart. لتنفيذ دفتر الملاحظات ، يمكنك استخدام أقل من خمس صور تدريب وتحميلها إلى مجلد الاستوديو المحلي. إذا كان لديك أكثر من خمس صور ، فيمكنك تحميلها أيضًا. يقوم Notebook بتحميل صور التدريب إلى S3 ، ويقوم بتدريب النموذج على مجموعة البيانات الخاصة بك ونشر النموذج الناتج. قد يستغرق التدريب 20 دقيقة للانتهاء. يمكنك تغيير عدد الخطوات لتسريع التدريب. يوفر Notebook بعض نماذج المطالبات لتجربتها مع النموذج المنشور ولكن يمكنك تجربة أي مطالبة تريدها. يمكنك أيضًا تكييف الكمبيوتر الدفتري لإنشاء صور رمزية لك أو لحيواناتك الأليفة. على سبيل المثال ، بدلاً من الكلب الخاص بك ، يمكنك تحميل صور لقطتك في الخطوة الأولى ثم تغيير المطالبات من الكلاب إلى القطط وسوف يقوم النموذج بإنشاء صور لقطتك.
صقل الاعتبارات
تميل نماذج الانتشار المستقر للتدريب إلى التجهيز الزائد بسرعة. للحصول على صور عالية الجودة ، يجب أن نجد توازنًا جيدًا بين معلمات التدريب الفائقة المتاحة مثل عدد خطوات التدريب ومعدل التعلم. في هذا القسم ، نعرض بعض النتائج التجريبية ونقدم إرشادات حول كيفية تعيين هذه المعلمات.
توصيات
ضع في اعتبارك التوصيات التالية:
- ابدأ بنوعية جيدة من صور التدريب (4-20). إذا كنت تتدرب على الوجوه البشرية ، فقد تحتاج إلى المزيد من الصور.
- تدرب من 200 إلى 400 خطوة عند التدريب على الكلاب أو القطط وغيرها من الموضوعات غير البشرية. إذا كنت تتدرب على الوجوه البشرية ، فقد تحتاج إلى المزيد من الخطوات. إذا حدث التجاوز ، قلل عدد الخطوات. إذا حدث نقص في التركيب (لا يمكن للنموذج الدقيق إنشاء صورة الهدف المستهدف) ، فقم بزيادة عدد الخطوات.
- إذا كنت تتدرب على وجوه غير بشرية ، فيمكنك ضبطها
with_prior_preservation = Falseلأنه لا يؤثر بشكل كبير على الأداء. على الوجوه البشرية ، قد تحتاج إلى ضبطwith_prior_preservation=True. - إذا كان الإعداد
with_prior_preservation=True، استخدم نوع المثيل ml.g5.2xlarge. - عند التدريب على مواضيع متعددة بالتتابع ، إذا كانت الموضوعات متشابهة جدًا (على سبيل المثال ، كل الكلاب) ، يحتفظ النموذج بالموضوع الأخير وينسى الموضوعات السابقة. إذا كانت الموضوعات مختلفة (على سبيل المثال ، قطة أولاً ثم كلب) ، يحتفظ النموذج بكلا الموضوعين.
- نوصي باستخدام معدل تعلم منخفض وزيادة عدد الخطوات تدريجيًا حتى تصبح النتائج مرضية.
مجموعة بيانات التدريب
تتأثر جودة النموذج الدقيق بشكل مباشر بجودة صور التدريب. لذلك ، تحتاج إلى جمع صور عالية الجودة للحصول على نتائج جيدة. ستؤثر الصور غير الواضحة أو منخفضة الدقة على جودة النموذج الدقيق. ضع في اعتبارك المعلمات الإضافية التالية:
- عدد صور التدريب - يمكنك ضبط النموذج بدقة على أقل من أربع صور تدريب. لقد جربنا مجموعات بيانات تدريبية بحجم أقل من 4 صور وما يصل إلى 16 صورة. في كلتا الحالتين ، كان الضبط الدقيق قادرًا على تكييف النموذج مع الموضوع.
- تنسيقات مجموعة البيانات - اختبرنا خوارزمية الضبط الدقيق للصور بتنسيق .png و. jpg و. jpeg. قد تعمل التنسيقات الأخرى أيضًا.
- صورة قرار - صور التدريب قد تكون بأي دقة. ستعمل خوارزمية الضبط الدقيق على تغيير حجم جميع صور التدريب قبل البدء في الضبط الدقيق. ومع ذلك ، إذا كنت ترغب في الحصول على مزيد من التحكم في اقتصاص الصور التدريبية وتغيير حجمها ، فإننا نوصي بتغيير حجم الصور بنفسك إلى الدقة الأساسية للنموذج (في هذا المثال ، 512 × 512 بكسل).
إعدادات التجربة
في التجربة في هذا المنشور ، أثناء الضبط الدقيق ، نستخدم القيم الافتراضية للمعلمات الفائقة ما لم يتم تحديدها. علاوة على ذلك ، نستخدم إحدى مجموعات البيانات الأربع:
- الكلب1-8 - الكلب 1 مع 8 صور
- الكلب1-16 - الكلب 1 مع 16 صور
- الكلب2-4 - الكلب 2 مع أربع صور
- كات -8 - قطة مع 8 صور
لتقليل الازدحام ، نعرض فقط صورة تمثيلية واحدة لمجموعة البيانات في كل قسم جنبًا إلى جنب مع اسم مجموعة البيانات. يمكنك العثور على مجموعة التدريب الكاملة في القسم مجموعات بيانات التجربة في هذا المنشور.
Overfitting
تميل نماذج الانتشار المستقر إلى التجهيز الزائد عند ضبط بعض الصور. لذلك ، تحتاج إلى تحديد المعلمات مثل epochs, max_epochs، ومعدل التعلم بعناية. في هذا القسم ، استخدمنا مجموعة البيانات Dog1-16.

لتقييم أداء النموذج ، نقوم بتقييم النموذج الدقيق لأربع مهام:
- هل يمكن للنموذج الدقيق أن يولد صورًا للموضوع (كلب دوبلر) في نفس الإعداد الذي تم تدريبه عليه؟
- ملاحظة - نعم انها تستطيع. تجدر الإشارة إلى أن أداء النموذج يزداد مع عدد خطوات التدريب.
- هل يمكن للنموذج الدقيق إنشاء صور للموضوع في إعداد مختلف عما تم التدريب عليه؟ على سبيل المثال ، هل يمكنه إنشاء صور دوبلر على الشاطئ؟
- ملاحظة - نعم انها تستطيع. تجدر الإشارة إلى أن أداء النموذج يزداد مع عدد خطوات التدريب حتى نقطة معينة. إذا تم تدريب النموذج لفترة طويلة جدًا ، فإن أداء النموذج يتدهور حيث يميل النموذج إلى التجهيز الزائد.
- هل يمكن للنموذج الدقيق إنتاج صور لفصل ينتمي إليه موضوع التدريب؟ على سبيل المثال ، هل يمكنه إنشاء صورة لكلب عام؟
- ملاحظة - مع زيادة عدد خطوات التدريب ، يبدأ النموذج في التجهيز. نتيجة لذلك ، فإنه ينسى الفئة العامة للكلب وينتج فقط الصور ذات الصلة بالموضوع.
- هل يمكن للنموذج الدقيق إنشاء صور لفصل دراسي أو موضوع غير موجود في مجموعة بيانات التدريب؟ على سبيل المثال ، هل يمكنه إنشاء صورة قطة؟
- ملاحظة - مع زيادة عدد خطوات التدريب ، يبدأ النموذج في التجهيز. نتيجة لذلك ، لن ينتج سوى الصور المتعلقة بالموضوع ، بغض النظر عن الفئة المحددة.
نقوم بضبط النموذج لعدد مختلف من الخطوات (عن طريق الضبط max_steps hyperparameters) ولكل نموذج مضبوط بدقة ، نقوم بإنشاء صور لكل من المطالبات الأربعة التالية (الموضحة في الأمثلة التالية من اليسار إلى اليمين:
- "صورة لكلب دوبلر"
- "صورة لكلب دوبلر على الشاطئ"
- "صورة كلب"
- "صورة قطة"
الصور التالية مأخوذة من نموذج تم تدريبه بـ 50 خطوة.

تم تدريب النموذج التالي بـ 100 خطوة.

قمنا بتدريب النموذج التالي بـ 200 خطوة.

الصور التالية مأخوذة من نموذج تم تدريبه على 400 خطوة.

أخيرًا ، الصور التالية هي نتيجة 800 خطوة.

تدريب على مجموعات بيانات متعددة
أثناء الضبط الدقيق ، قد ترغب في إجراء ضبط دقيق لموضوعات متعددة وجعل النموذج الدقيق قادرًا على إنشاء صور لجميع الأهداف. لسوء الحظ ، يقتصر برنامج JumpStart حاليًا على التدريب على موضوع واحد. لا يمكنك ضبط النموذج بدقة على عدة مواضيع في نفس الوقت. علاوة على ذلك ، يؤدي الضبط الدقيق للنموذج لمواضيع مختلفة بالتتابع إلى نسيان النموذج الأول للموضوع إذا كانت الموضوعات متشابهة.
نعتبر التجريب التالي في هذا القسم:
- صقل النموذج للموضوع أ.
- صقل النموذج الناتج من الخطوة 1 للموضوع ب.
- قم بإنشاء صور للموضوع A والموضوع B باستخدام نموذج الإخراج من الخطوة 2.
في التجارب التالية نلاحظ أن:
- إذا كان A هو الكلب 1 و B هو الكلب 2 ، فإن كل الصور التي تم إنشاؤها في الخطوة 3 تشبه الكلب 2
- إذا كان A هو الكلب 2 و B هو الكلب 1 ، فإن كل الصور التي تم إنشاؤها في الخطوة 3 تشبه الكلب 1
- إذا كان A هو الكلب 1 و B عبارة عن قطة ، فإن الصور التي تم إنشاؤها باستخدام مطالبات الكلب تشبه الكلب 1 والصور التي تم إنشاؤها باستخدام مطالبات القطط تشبه القط
تدريب على الكلب 1 ثم الكلب 2
في الخطوة 1 ، قمنا بضبط النموذج بدقة 200 خطوة على ثماني صور للكلب 1. في الخطوة 2 ، قمنا بضبط النموذج بشكل أكبر للحصول على 200 خطوة على أربع صور للكلب 2.

فيما يلي الصور التي تم إنشاؤها بواسطة النموذج الدقيق في نهاية الخطوة 2 لمطالبات مختلفة.

تدريب على الكلب 2 ثم الكلب 1
في الخطوة 1 ، قمنا بضبط النموذج بدقة لـ 200 خطوة على أربع صور للكلب 2. في الخطوة 2 ، قمنا بضبط النموذج بشكل أكبر للحصول على 200 خطوة على ثماني صور لكلب 1.

فيما يلي الصور التي تم إنشاؤها بواسطة النموذج الدقيق في نهاية الخطوة 2 مع مطالبات مختلفة.

تدريب الكلاب والقطط
في الخطوة 1 ، قمنا بضبط النموذج بدقة 200 خطوة على ثماني صور لقط. ثم قمنا بضبط النموذج بشكل أكبر لـ 200 خطوة على ثماني صور لكلب 1.

فيما يلي الصور التي تم إنشاؤها بواسطة النموذج الدقيق في نهاية الخطوة 2. الصور ذات المطالبات المتعلقة بالقطط تبدو مثل القطة في الخطوة 1 من الضبط الدقيق ، والصور ذات المطالبات المتعلقة بالكلب تبدو مثل الكلب في الخطوة 2 من الصقل.

الحفظ المسبق
الحفظ المسبق هو تقنية تستخدم صورًا إضافية لنفس الفصل الذي نحاول التدرب عليه. على سبيل المثال ، إذا كانت بيانات التدريب تتكون من صور لكلب معين ، مع حفظ مسبق ، فإننا ندمج صورًا لفئة كلاب عامة. يحاول تجنب فرط التجهيز من خلال عرض صور لكلاب مختلفة أثناء التدريب لكلب معين. علامة تشير إلى الكلب المحدد الموجود في موجه المثيل مفقود في موجه الفصل. على سبيل المثال ، قد يكون موجه المثال "صورة لقطط ريوبوجر" وقد يكون موجه الفصل هو "صورة قطة". يمكنك تمكين الحفظ المسبق عن طريق تعيين المعامل التشعبي with_prior_preservation = True. إذا كان الإعداد with_prior_preservation = True، يجب عليك تضمين class_prompt in dataset_info.json وقد تتضمن أي صور فصل متاحة لك. فيما يلي تنسيق مجموعة بيانات التدريب عند الإعداد with_prior_preservation = True:
- إدخال - دليل يحتوي على صور المثيل ،
dataset_info.jsonو (اختياري) دليلclass_data_dir. لاحظ ما يلي:- قد تكون الصور بتنسيق .png أو .jpg أو .jpeg.
- •
dataset_info.jsonيجب أن يكون الملف بالتنسيق{'instance_prompt':<<instance_prompt>>,'class_prompt':<<class_prompt>>}. - •
class_data_dirيجب أن يحتوي الدليل على صور فئة. لوclass_data_dirغير موجود أو لا توجد صور كافية بالفعل فيclass_data_dir، سيتم أخذ عينات من الصور الإضافية باستخدامclass_prompt.
بالنسبة لمجموعات البيانات مثل القطط والكلاب ، لا يؤثر الحفظ المسبق بشكل كبير على أداء النموذج الدقيق وبالتالي يمكن تجنبه. ومع ذلك ، عند التدريب على الوجوه ، هذا ضروري. لمزيد من المعلومات ، يرجى الرجوع إلى تدريب الانتشار المستقر مع Dreambooth باستخدام الموزعات.
أنواع المثيل
تتطلب نماذج الانتشار المستقر الضبط الدقيق للحساب السريع الذي توفره المثيلات المدعومة من وحدة معالجة الرسومات. قمنا بتجربة الضبط الدقيق مع ml.g4dn.2xlarge (16 جيجا بايت ذاكرة CUDA ، 1 GPU) و ml.g5.2xlarge (24 جيجا بايت ذاكرة CUDA ، 1 GPU). تكون متطلبات الذاكرة أعلى عند إنشاء صور للفئة. لذلك ، إذا وضع with_prior_preservation=True، استخدم نوع المثيل ml.g5.2xlarge ، لأن التدريب يعمل في مشكلة نفاد الذاكرة في CUDA على مثيل ml.g4dn.2xlarge. يستخدم البرنامج النصي للضبط الدقيق لـ JumpStart حاليًا وحدة معالجة رسومات واحدة ، وبالتالي ، لن يؤدي الضبط الدقيق لمثيلات وحدات معالجة الرسومات المتعددة إلى تحقيق مكاسب في الأداء. لمزيد من المعلومات حول أنواع المثيل المختلفة ، راجع أنواع مثيلات Amazon EC2.
القيود والتحيز
على الرغم من أن Stable Diffusion له أداء مثير للإعجاب في إنشاء الصور ، إلا أنه يعاني من العديد من القيود والتحيزات. وتشمل هذه على سبيل المثال لا الحصر:
- قد لا يولد النموذج وجوهًا أو أطرافًا دقيقة لأن بيانات التدريب لا تتضمن صورًا كافية بهذه الميزات
- تم تدريب النموذج على مجموعة بيانات LAION-5Bالتي تحتوي على محتوى للبالغين وقد لا تكون مناسبة لاستخدام المنتج دون مزيد من الاعتبارات
- قد لا يعمل النموذج بشكل جيد مع اللغات غير الإنجليزية لأن النموذج تم تدريبه على نص باللغة الإنجليزية
- لا يمكن للنموذج إنشاء نص جيد داخل الصور
لمزيد من المعلومات حول القيود والتحيز ، انظر بطاقة طراز V2-1 ذات القاعدة الثابتة للانتشار المستقر. يمكن أيضًا أن تنتقل هذه القيود الخاصة بالنموذج المدرب مسبقًا إلى النماذج الدقيقة.
تنظيف
بعد الانتهاء من تشغيل دفتر الملاحظات ، تأكد من حذف جميع الموارد التي تم إنشاؤها في العملية لضمان إيقاف الفواتير. يتم توفير التعليمات البرمجية لتنظيف نقطة النهاية في الملف المرتبط مقدمة إلى JumpStart - تحويل النص إلى صورة مثال مفكرة.
النماذج الدقيقة المتاحة للجمهور في JumpStart
على الرغم من إصدار نماذج Stable Diffusion بواسطة الاستقرار تتمتع بأداء مثير للإعجاب ، ولديها قيود من حيث اللغة أو المجال الذي تم التدريب عليه. على سبيل المثال ، تم تدريب نماذج Stable Diffusion على نص باللغة الإنجليزية ، ولكن قد تحتاج إلى إنشاء صور من نصوص غير إنجليزية. بدلاً من ذلك ، تم تدريب نماذج Stable Diffusion لإنشاء صور واقعية ، ولكن قد تحتاج إلى إنشاء صور متحركة أو فنية.
يوفر JumpStart أكثر من 80 نموذجًا متاحًا للجمهور بلغات وموضوعات مختلفة. غالبًا ما تكون هذه النماذج عبارة عن إصدارات مضبوطة بدقة من طرازات Stable Diffusion الصادرة عن StabilityAI. إذا كانت حالة الاستخدام الخاصة بك تتطابق مع أحد النماذج المضبوطة بدقة ، فلن تحتاج إلى جمع مجموعة البيانات الخاصة بك وضبطها. يمكنك ببساطة نشر أحد هذه النماذج من خلال Studio UI أو استخدام واجهات برمجة تطبيقات JumpStart سهلة الاستخدام. لنشر نموذج Stable Diffusion تم تدريبه مسبقًا في JumpStart ، يرجى الرجوع إلى قم بإنشاء صور من نص باستخدام نموذج الانتشار المستقر على Amazon SageMaker JumpStart.
فيما يلي بعض الأمثلة على الصور التي تم إنشاؤها بواسطة النماذج المختلفة المتوفرة في JumpStart.


لاحظ أن هذه النماذج لم يتم ضبطها بدقة باستخدام البرامج النصية لـ JumpStart أو نصوص DreamBooth. يمكنك تنزيل القائمة الكاملة للنماذج الدقيقة المتاحة للجمهور مع أمثلة للمطالبات من هنا.
لمزيد من الأمثلة على الصور التي تم إنشاؤها من هذه النماذج ، يرجى الاطلاع على القسم نماذج مفتوحة المصدر دقيقة في الملحق.
وفي الختام
في هذا المنشور ، أوضحنا كيفية ضبط نموذج الانتشار المستقر من أجل تحويل النص إلى صورة ثم نشره باستخدام JumpStart. علاوة على ذلك ، ناقشنا بعض الاعتبارات التي يجب أن تضعها أثناء ضبط النموذج وكيف يمكن أن يؤثر على أداء النموذج الذي تم ضبطه بدقة. ناقشنا أيضًا أكثر من 80 نموذجًا جاهزًا للاستخدام مضبوطًا ومتاحًا في JumpStart. عرضنا مقتطفات التعليمات البرمجية في هذا المنشور — للحصول على الشفرة الكاملة مع جميع الخطوات في هذا العرض التوضيحي ، راجع مقدمة إلى JumpStart - تحويل النص إلى صورة مثال مفكرة. جرب الحل بنفسك وأرسل لنا تعليقاتك.
لمعرفة المزيد حول النموذج والضبط الدقيق لـ DreamBooth ، راجع الموارد التالية:
لمعرفة المزيد حول JumpStart ، تحقق من منشورات المدونة التالية:
حول المؤلف
 الدكتور فيفيك مادان هو عالم تطبيقي مع فريق Amazon SageMaker JumpStart. حصل على الدكتوراه من جامعة إلينوي في Urbana-Champaign وكان باحثًا بعد الدكتوراه في Georgia Tech. وهو باحث نشط في التعلم الآلي وتصميم الخوارزمية وقد نشر أوراقًا علمية في مؤتمرات EMNLP و ICLR و COLT و FOCS و SODA.
الدكتور فيفيك مادان هو عالم تطبيقي مع فريق Amazon SageMaker JumpStart. حصل على الدكتوراه من جامعة إلينوي في Urbana-Champaign وكان باحثًا بعد الدكتوراه في Georgia Tech. وهو باحث نشط في التعلم الآلي وتصميم الخوارزمية وقد نشر أوراقًا علمية في مؤتمرات EMNLP و ICLR و COLT و FOCS و SODA.
 هيكو هوتز هو مهندس حلول أول للذكاء الاصطناعي والتعلم الآلي مع التركيز بشكل خاص على معالجة اللغة الطبيعية (NLP) ونماذج اللغات الكبيرة (LLMs) والذكاء الاصطناعي التوليدي. قبل هذا المنصب ، كان رئيسًا لعلوم البيانات لخدمة عملاء Amazon في الاتحاد الأوروبي. تساعد Heiko عملاءنا على تحقيق النجاح في رحلة الذكاء الاصطناعي / التعلم الآلي على AWS وعملت مع مؤسسات في العديد من الصناعات ، بما في ذلك التأمين والخدمات المالية والإعلام والترفيه والرعاية الصحية والمرافق والتصنيع. في أوقات فراغه ، يسافر هيكو قدر الإمكان.
هيكو هوتز هو مهندس حلول أول للذكاء الاصطناعي والتعلم الآلي مع التركيز بشكل خاص على معالجة اللغة الطبيعية (NLP) ونماذج اللغات الكبيرة (LLMs) والذكاء الاصطناعي التوليدي. قبل هذا المنصب ، كان رئيسًا لعلوم البيانات لخدمة عملاء Amazon في الاتحاد الأوروبي. تساعد Heiko عملاءنا على تحقيق النجاح في رحلة الذكاء الاصطناعي / التعلم الآلي على AWS وعملت مع مؤسسات في العديد من الصناعات ، بما في ذلك التأمين والخدمات المالية والإعلام والترفيه والرعاية الصحية والمرافق والتصنيع. في أوقات فراغه ، يسافر هيكو قدر الإمكان.
الملحق: مجموعات بيانات التجربة
يحتوي هذا القسم على مجموعات البيانات المستخدمة في التجارب في هذا المنشور.
الكلب1-8

الكلب1-16

الكلب2-4

الكلب3-8

الملحق: فتح نماذج من مصادر دقيقة
فيما يلي بعض الأمثلة على الصور التي تم إنشاؤها بواسطة النماذج المختلفة المتوفرة في JumpStart. يتم تعليق كل صورة بامتداد model_id تبدأ بالبادئة huggingface-txt2img- متبوعًا بالموجه المستخدم لإنشاء الصورة في السطر التالي.

























- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/fine-tune-text-to-image-stable-diffusion-models-with-amazon-sagemaker-jumpstart/
- 1
- 100
- 11
- 2022
- 9
- a
- القدرة
- ماهرون
- من نحن
- تسريع
- معجل
- الوصول
- جمع
- دقيق
- التأهيل
- نشط
- تكيف
- وأضاف
- إضافة
- إضافي
- بالغ
- بعد
- AI
- الذكاء الاصطناعي والتعلم الآلي
- AI / ML
- خوارزمية
- خوارزميات
- الكل
- يسمح
- وحده
- سابقا
- بالرغم ان
- أمازون
- الأمازون SageMaker
- أمازون سيج ميكر جومب ستارت
- و
- أعلن
- آخر
- واجهات برمجة التطبيقات
- تطبيقي
- التقديم
- مناسب
- هندسة معمارية
- فنـون
- فني
- أسوشيتد
- تلقائيا
- متاح
- الآلهة
- تجنب
- تجنب
- AWS
- الرصيد
- شريط
- قاعدة
- شاطئ
- لان
- قبل
- يجري
- ما بين
- Beyond
- انحياز
- الفواتير
- المدونة
- المقالات والأخبار
- يجلب
- يبني
- تسمى
- دعوة
- بعناية
- حمل
- حقيبة
- الحالات
- قط
- القطط
- معين
- كرسي
- تغيير
- التحقق
- خيار
- الخيارات
- اختار
- اختيار
- فئة
- فوضى
- الكود
- جمع
- تعليقات
- حساب
- المؤتمرات
- الاعداد
- نظر
- الاعتبارات
- ثابت
- بناء
- وعاء
- يحتوي
- محتوى
- مراقبة
- المقابلة
- التكاليف
- خلق
- خلق
- خلق
- محصول
- حاليا
- على
- زبون
- خدمة العملاء
- العملاء
- البيانات
- معالجة المعلومات
- علم البيانات
- قواعد البيانات
- عميق
- التعلم العميق
- الترتيب
- تجربة
- شرح
- نشر
- نشر
- تصميم
- تصاميم
- تفاصيل
- مختلف
- التوزيع
- مباشرة
- بحث
- ناقش
- تقسيم
- عامل في حوض السفن
- حاوية عامل الميناء
- لا
- كلب
- الكلاب
- فعل
- نطاق
- لا
- بإمكانك تحميله
- أثناء
- كل
- سهلة الاستخدام
- فعال
- جزءا لا يتجزأ من
- تمكين
- تمكن
- النهائي إلى نهاية
- نقطة النهاية
- عربي
- كاف
- ضمان
- ترفيه
- دخول
- عهود
- تقديرات
- إلخ
- الأثير (ETH)
- EU
- تقييم
- مثال
- أمثلة
- إلا
- تنفيذ
- توقع
- تجربة
- الأسي
- الوجه
- وجوه
- قليل
- قم بتقديم
- ملفات
- أخيرا
- مالي
- الخدمات المالية
- نهاية
- الاسم الأول
- تناسب
- حل
- تطفو
- تركز
- يتبع
- متابعيك
- شكل
- تبدأ من
- بالإضافة إلى
- مرح
- وظائف
- إضافي
- علاوة على ذلك
- ربح
- توليد
- ولدت
- يولد
- توليد
- جيل
- توليدي
- الذكاء الاصطناعي التوليدي
- جورجيا
- دولار فقط واحصل على خصم XNUMX% على جميع
- GitHub جيثب:
- خير
- وحدة معالجة الرسوميات:
- تدريجيا
- معالجة
- يحدث
- رئيس
- الرعاية الصحية
- يساعد
- عالي الجودة
- أعلى
- مضيف
- كيفية
- كيفية
- لكن
- HTML
- HTTPS
- الانسان
- ICLR
- محدد
- إلينوي
- صورة
- توليد الصور
- صور
- التأثير
- أثر
- استيراد
- مثير للإعجاب
- in
- تتضمن
- يشمل
- بما فيه
- دمج
- القيمة الاسمية
- الزيادات
- في ازدياد
- الصناعات
- معلومات
- إدخال
- مثل
- بدلًا من ذلك
- تعليمات
- التأمين
- السطح البيني
- المشاركة
- عزل
- قضية
- مسائل
- IT
- وظيفة
- رحلة
- جسون
- احتفظ
- المعرفة
- لغة
- اللغات
- كبير
- اسم العائلة
- إطلاق
- طبقات
- تعلم
- تعلم
- تعلم
- القيود
- محدود
- خط
- خطوط
- قائمة
- القليل
- جار التحميل
- محلي
- طويل
- بحث
- يبدو مثل
- خسارة
- منخفض
- آلة
- آلة التعلم
- جعل
- أسلوب
- يدويا
- تصنيع
- كثير
- مباراة
- أقصى
- الوسائط
- مكبر الصوت : يدعم، مع دعم ميكروفون مدمج لمنع الضوضاء
- وسط
- ربما
- مانع
- الحد الأدنى
- مفقود
- ML
- نموذج
- عارضات ازياء
- لحظة
- الأكثر من ذلك
- متعدد
- الاسم
- عين
- طبيعي
- اللغة الطبيعية
- معالجة اللغات الطبيعية
- ضروري
- حاجة
- بحاجة
- شبكة
- التالي
- NFTS
- البرمجة اللغوية العصبية
- ضجيج
- مفكرة
- نوفمبر
- عدد
- موضوع
- رصد
- ONE
- جاكيت
- عمليات
- طلب
- المنظمات
- أصلي
- أخرى
- نظرة عامة
- الخاصة
- أوراق
- المعلمات
- خاص
- يمر
- مرور
- مسار
- نفذ
- أداء
- أداء
- إضفاء الطابع الشخصي
- الحيوانات الأليفة
- واقعي
- بكسل
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- من فضلك
- البوينت
- إيجابي
- ممكن
- منشور
- المنشورات
- تنبأ
- يقدم
- سابق
- قبل
- عملية المعالجة
- معالجة
- إنتاج
- منتج
- تدريجيا
- تزود
- المقدمة
- ويوفر
- توفير
- علانية
- نشرت
- بايثون
- جودة
- بسرعة
- عشوائية
- تتراوح
- معدل
- استعداد
- حقيقي
- في الوقت الحقيقي
- واقعي
- مؤخرا
- الاعتراف
- نوصي
- ساندي خ. ميليك
- أحمر
- تخفيض
- بغض النظر
- ذات صلة
- صدر
- إزالة
- إزالة
- ممثل
- طلبات
- تطلب
- مطلوب
- المتطلبات
- يتطلب
- الباحث
- دقة الشاشة
- الموارد
- الرد
- استجابة
- نتيجة
- مما أدى
- النتائج
- النوع
- يجري
- تشغيل
- sagemaker
- قال
- نفسه
- إنقاذ
- علوم
- عالم
- مخطوطات
- الإستراحة
- بحث
- ثواني
- القسم
- كبير
- مسلسلات
- الخدمة
- خدمات
- طقم
- ضبط
- عدة
- الأشكال
- ينبغي
- إظهار
- أظهرت
- يظهر
- بشكل ملحوظ
- مماثل
- الاشارات
- ببساطة
- عزباء
- جلسة
- مقاس
- صغير
- الأصغر
- So
- حل
- الحلول
- بعض
- الفضاء
- تختص
- محدد
- محدد
- سرعة
- مستقر
- المسرح
- ابتداء
- يبدأ
- الولايه او المحافظه
- خطوة
- خطوات
- توقف
- تخزين
- ستوديو
- موضوع
- ناجح
- هذه
- يعاني
- كاف
- الدعم
- مدعومة
- الدعم
- TAG
- أخذ
- يأخذ
- الهدف
- المهام
- فريق
- التكنولوجيا
- سياسة الحجب وتقييد الوصول
- اختبارات
- •
- من مشاركة
- وبالتالي
- عبر
- الوقت
- إلى
- اليوم
- سويا
- جدا
- الإجمالي
- قطار
- متدرب
- قادة الإيمان
- القطارات
- تحويل
- يسافر
- أنواع
- ui
- فريد من نوعه
- جامعة
- تحديث
- تحديث
- آخر التحديثات
- URI
- us
- تستخدم
- حالة الاستخدام
- مستخدم
- واجهة المستخدم
- عادة
- خدمات
- سهل حياتك
- يستخدم
- القيمة
- معلومات قيمة
- قيمنا
- القيم
- مختلف
- فيديو
- طرق
- وزن
- سواء
- التي
- في حين
- أبيض
- سوف
- في غضون
- بدون
- كلمات
- للعمل
- العمل معا
- عمل
- عامل
- قيمة
- التوزيعات للسهم الواحد
- حل متجر العقارات الشامل الخاص بك في جورجيا
- نفسك
- زفيرنت
- صفر