المُقدّمة
يمكن أن يكون عالم تدقيق البيانات معقدًا ، مع وجود العديد من التحديات للتغلب عليها. أحد أكبر التحديات هو التعامل مع السمات الفئوية أثناء التعامل مع مجموعات البيانات. في هذه المقالة ، سوف نتعمق في عالم تدقيق البيانات ، واكتشاف العيوب ، وتأثير ترميز السمات الفئوية على النماذج.
واحدة من التحديات الرئيسية المرتبطة باكتشاف الشذوذ لبيانات التدقيق هو التعامل مع السمات الفئوية. يعد ترميز السمات الفئوية إلزاميًا لأن النماذج لا يمكنها تفسير إدخال النص. عادةً ما يتم ذلك باستخدام ترميز Label أو ترميز One Hot. ومع ذلك ، في مجموعة كبيرة من البيانات ، يمكن أن يؤدي ترميز One-hot إلى أداء نموذج ضعيف بسبب لعنة الأبعاد.
أهداف التعلم
-
لفهم مفهوم تدقيق البيانات والتحدي
- لتقييم الطرق المختلفة لاكتشاف الشذوذ العميق غير الخاضع للرقابة.
- لفهم تأثير ترميز السمات الفئوية على النماذج المستخدمة لاكتشاف الشذوذ في بيانات التدقيق.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
- ما هو Auata؟
- ما هو كشف الشذوذ؟
- التحديات الرئيسية التي واجهتها أثناء تدقيق البيانات
- تدقيق مجموعات البيانات لاكتشاف الشذوذ
- ترميز السمات الفئوية
- الترميزات الفئوية
- نماذج كشف الشذوذ غير الخاضعة للرقابة
- كيف يؤثر ترميز السمات الفئوية على النماذج؟
8.1 تمثيل t-SNE لمجموعة بيانات تأمين السيارات
تمثيل 8.2 t-SNE لمجموعة بيانات تأمين المركبات
تمثيل 8.3 t-SNE لمجموعة بيانات مطالبات المركبات - وفي الختام
في هو تدقيق البيانات؟
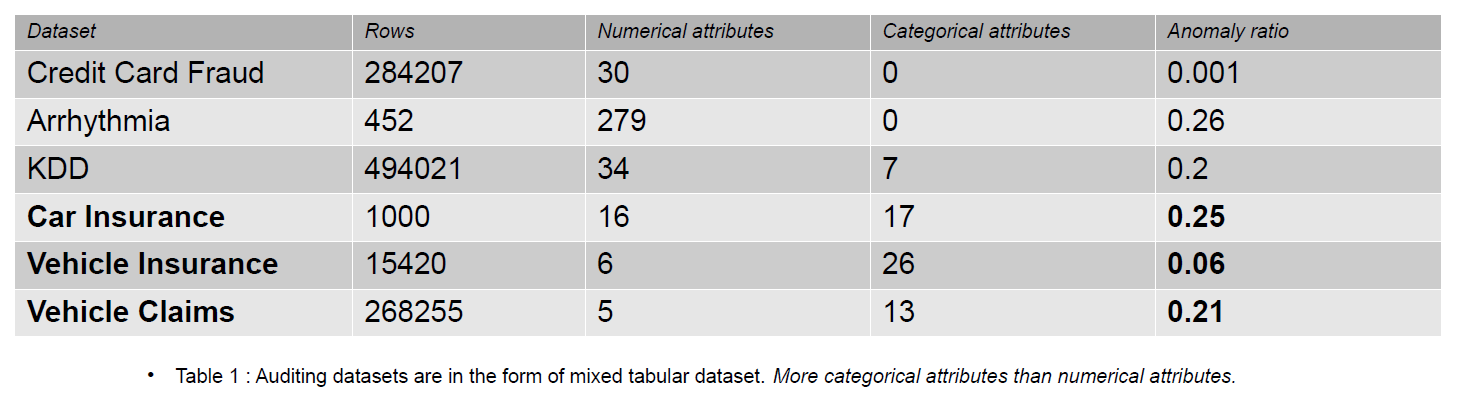
يمكن أن تتضمن بيانات المراجعة المجلات ومطالبات التأمين وبيانات التطفل لأنظمة المعلومات ؛ في هذه المقالة ، الأمثلة المقدمة هي مطالبات التأمين على المركبات. يمكن تمييز مطالبات التأمين عن مجموعات بيانات الكشف عن العيوب ، على سبيل المثال ، KDD ، من خلال عدد أكبر من الميزات الفئوية.
الميزات الفئوية هي أقراص في بياناتنا يمكن أن تكون إما من نوع عدد صحيح أو حرف. الميزات العددية هي سمات مستمرة في بياناتنا تكون دائمًا ذات قيمة حقيقية. تحظى مجموعات البيانات ذات الميزات العددية بشعبية في مجتمع الكشف عن الحالات الشاذة مثل بيانات الاحتيال على بطاقة الائتمان. تحتوي معظم مجموعات البيانات المتاحة للجمهور على ميزات فئوية أقل من بيانات مطالبات التأمين. الميزات الفئوية هي أكثر في العدد من السمات العددية في مجموعات بيانات مطالبات التأمين.
تتضمن مطالبة التأمين ميزات مثل الطراز والعلامة التجارية والدخل والتكلفة والإصدار واللون وما إلى ذلك. عدد الميزات الفئوية أعلى في بيانات التدقيق مقارنة بمجموعات بيانات بطاقة الائتمان و KDD. مجموعات البيانات هذه هي معايير في طرق اكتشاف الشذوذ غير الخاضعة للإشراف. كما هو موضح في الجدول أدناه ، تحتوي مجموعات بيانات مطالبات التأمين على المزيد من الميزات الفئوية ، والتي تعتبر مهمة لفهم سلوك البيانات الاحتيالية.
مجموعات بيانات المراجعة المستخدمة لتقييم تأثير الترميزات الفئوية هي التأمين على السيارات والتأمين على السيارة ومطالبات المركبات.
ما هو كشف الشذوذ؟
الشذوذ هو ملاحظة تقع بعيدًا عن البيانات العادية في مجموعة بيانات بمسافة محددة (الحد الأدنى). من حيث تدقيق البيانات ، نفضل مصطلح البيانات الاحتيالية. يميز اكتشاف الشذوذ بين البيانات العادية والاحتيالية باستخدام التعلم الآلي أو نموذج التعلم العميق. طرق مختلفة يمكن استخدامها لاكتشاف الشذوذ ، مثل تقدير الكثافة ، وخطأ إعادة البناء ، وطرق التصنيف.
- تقدير الكثافة - تقدر هذه الطرق التوزيع الطبيعي للبيانات وتصنف البيانات الشاذة إذا لم يتم أخذ عينات منها من التوزيع الذي تم تعلمه.
- خطأ في إعادة البناء - تعتمد الأساليب القائمة على أخطاء إعادة البناء على مبدأ أنه يمكن إعادة بناء البيانات العادية بخسائر أقل من البيانات الشاذة. كلما زادت خسارة إعادة الإعمار ، زادت فرص أن تكون البيانات شاذة.
- طرق التصنيف - طرق التصنيف مثل غابة عشوائيةوغابة العزل وفئة واحدة - آلات المتجهات الداعمة والعوامل الخارجية المحلية يمكن استخدامها لاكتشاف الشذوذ. يتضمن التصنيف في اكتشاف الشذوذ تحديد إحدى الفئات على أنها حالة شاذة. ومع ذلك ، يتم تقسيم الفئات إلى مجموعتين (0 و 1) في سيناريو متعدد الطبقات ، والفئة ذات البيانات الأقل هي الفئة الشاذة.
ناتج الطرق المذكورة أعلاه عبارة عن درجات شاذة أو أخطاء في إعادة البناء. ثم يتعين علينا اتخاذ قرار بشأن العتبة ، والتي بموجبها نصنف البيانات الشاذة.
التحديات الرئيسية التي واجهتها أثناء تدقيق البيانات
- التعامل مع السمات الفئوية: يعد ترميز السمات الفئوية إلزاميًا لأن النموذج لا يمكنه تفسير إدخال النص. لذلك ، يتم ترميز القيم بترميز Label أو ترميز One Hot. ولكن في مجموعة بيانات كبيرة ، يحول أحد الترميز الساخن البيانات إلى مساحة عالية الأبعاد عن طريق زيادة عدد السمات. أداء النموذج ضعيف بسبب لعنة الأبعاد.
- تحديد عتبة التصنيف: إذا لم يتم تصنيف البيانات ، فمن الصعب تقييم أداء النموذج لأننا لا نعرف عدد الحالات الشاذة الموجودة في مجموعة البيانات. تسهل المعرفة المسبقة حول مجموعة البيانات تحديد الحد الأدنى. لنفترض أن لدينا 5 من كل 10 عينات شاذة في بياناتنا. لذلك ، يمكننا تحديد العتبة عند درجة 50 مئوية.
- مجموعات البيانات العامة: تعتبر معظم مجموعات بيانات التدقيق سرية لأنها تنتمي إلى شركات الشركات وتحتوي على معلومات حساسة وشخصية. تتمثل إحدى الطرق الممكنة للتخفيف من مشكلات السرية في التدريب على استخدام مجموعات البيانات التركيبية (مطالبات المركبات).
تدقيق مجموعات البيانات لاكتشاف الشذوذ
تتضمن مطالبات التأمين الخاصة بالمركبات معلومات حول خصائص السيارة ، مثل الطراز والعلامة التجارية والسعر والسنة ونوع الوقود. يتضمن معلومات حول السائق وتاريخ الميلاد والجنس والمهنة. بالإضافة إلى ذلك ، قد تتضمن المطالبة معلومات حول التكلفة الإجمالية للإصلاح. مجموعات البيانات المستخدمة في هذه المقالة كلها من مجال واحد ، لكنها تختلف في عدد السمات وعدد المثيلات.
-
مجموعة بيانات مطالبات المركبات كبيرة ، وتحتوي على أكثر من 250,000 صف ، ولسماتها الفئوية عدد أساسي من 1171. نظرًا لحجمها الكبير ، تعاني مجموعة البيانات هذه من لعنة الأبعاد.
- مجموعة بيانات التأمين على المركبات متوسطة الحجم ، وتحتوي على 15,420،151 صفًا و XNUMX قيمة فئوية فريدة. هذا يجعلها أقل عرضة للمعاناة من لعنة الأبعاد.
- مجموعة بيانات التأمين على السيارات صغيرة ، مع ملصقات و 25٪ عينات شاذة ، وتحتوي على عدد مماثل من الميزات العددية والفئوية. مع 169 فئة فريدة ، لا يعاني من لعنة الأبعاد.
ترميز السمات الفئوية
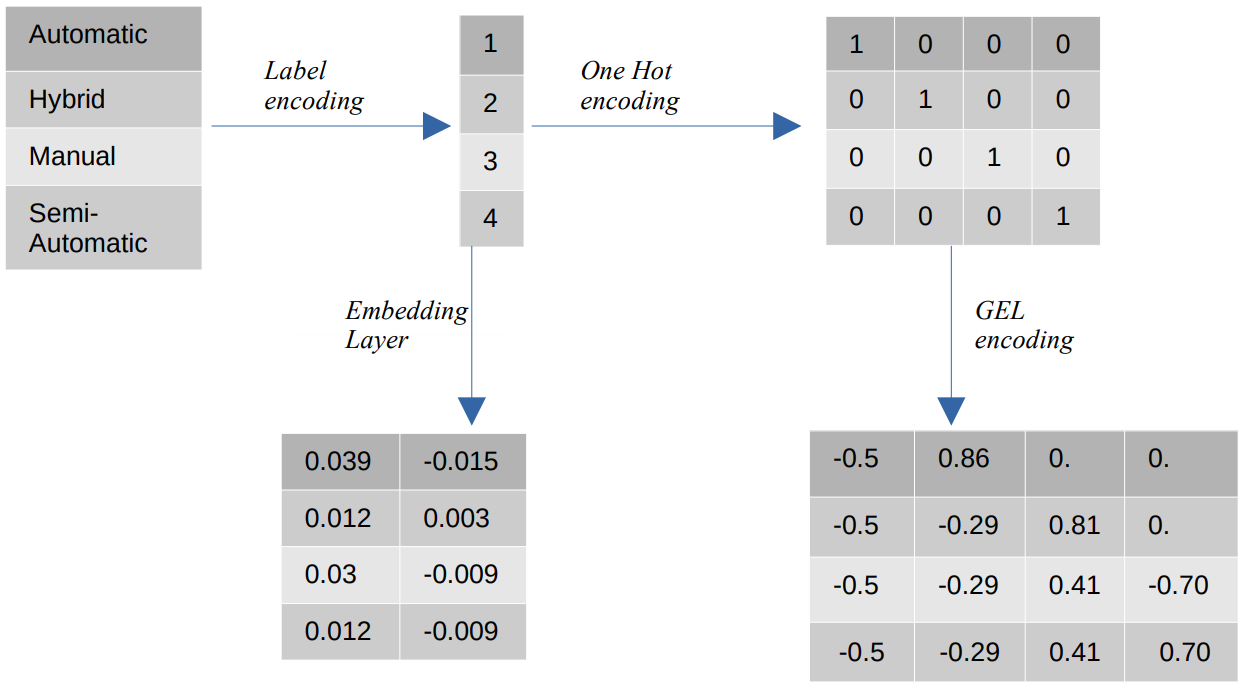
ترميزات مختلفة للقيم الفئوية
- ترميز التسمية - في تشفير الوسم ، يتم استبدال القيم الفئوية بقيم عددية صحيحة بين 1 وعدد الفئات. يمثل ترميز التسمية الفئات بالطريقة المقصودة للقيم الترتيبية. ومع ذلك ، عندما تكون الميزات اسمية ، يكون التمثيل غير صحيح لأن القيم الفئوية لا تتوافق مع ترتيب معين.
على سبيل المثال ، إذا كانت لدينا فئات مثل تلقائي ، ومختلط ، ويدوي ، وشبه تلقائي في ميزة ما ، فإن ترميز الملصق يحول هذه القيم إلى {1: تلقائي ، 2: مختلط ، 3: يدوي ، 4: شبه تلقائي}. لا يوفر هذا التمثيل أي معلومات حول القيم الفئوية ، ولكن التمثيل مثل {0: Low ، 1: Medium ، 2: High} يوفر تمثيلاً واضحًا لأن متغير الميزة Low يتم تعيين قيمة رقمية أقل له. لذلك ، يعد ترميز الملصق أفضل للقيم الترتيبية ولكنه غير ملائم للقيم الاسمية. - ترميز واحد ساخن - يستخدم ترميز واحد ساخن لمعالجة مشكلة قيم التشفير الاسمية ، والتي تحول كل قيمة فئوية إلى سمة مميزة في مجموعة البيانات تتكون من قيم ثنائية. على سبيل المثال ، في حالة وجود أربع فئات مختلفة مشفرة كـ {1 ، 2 ، 3 ، 4} ، فإن ترميز One Hot سينشئ ميزات جديدة مثل {تلقائي: [1,0,0,0،0,1,0,0،0,0,1,0،0,0,0,1] ، مختلط: [XNUMX،XNUMX ، XNUMX،XNUMX] ، يدوي: [XNUMX،XNUMX،XNUMX،XNUMX] ، شبه تلقائي: [XNUMX،XNUMX،XNUMX،XNUMX]}.
بعد ذلك ، يعتمد بُعد مجموعة البيانات بشكل مباشر على عدد الفئات الموجودة في مجموعة البيانات. نتيجة لذلك ، يمكن أن يؤدي ترميز One Hot إلى لعنة الأبعاد ، وهو عيب في طريقة التشفير هذه. - ترميز GEL - ترميز GEL هو تقنية تضمين يمكن استخدامها في طرق التعلم الخاضعة للإشراف وغير الخاضعة للإشراف. يعتمد على مبدأ ترميز One Hot ويمكن استخدامه لتقليل أبعاد الميزات الفئوية التي تم تشفيرها باستخدام ترميز One Hot.
- طبقة التضمين - توفر عمليات دمج الكلمات طريقة لاستخدام تمثيل مضغوط ومكثف حيث تحتوي الكلمات المتشابهة على ترميزات متشابهة. التضمين هو متجه كثيف لقيم الفاصلة العائمة التي يمكن تدريبها. يمكن أن تتراوح عمليات تضمين Word من 8 أبعاد (لمجموعات البيانات الصغيرة) إلى 1024 بعدًا (لمجموعات البيانات الكبيرة).
يمكن أن يؤدي التضمين ذو الأبعاد الأعلى إلى التقاط علاقات أكثر تفصيلاً بين الكلمات ، ولكنه يتطلب المزيد من البيانات للتعلم. طبقة التضمين هي جدول بحث يحول كل كلمة موجودة في المصفوفة إلى متجه بحجم معين.
نماذج كشف الشذوذ غير الخاضعة للرقابة
في العالم الحقيقي ، لا يتم تصنيف البيانات في معظم الحالات ، وتصنيف البيانات مكلف ويستغرق وقتًا طويلاً. لذلك ، سوف نستخدم نماذج غير خاضعة للرقابة في تقييماتنا.
- SOM - تعد خريطة التنظيم الذاتي (SOM) طريقة تعلم تنافسية حيث يتم تحديث أوزان الخلايا العصبية بشكل تنافسي بدلاً من استخدام التعلم العكسي. يتكون SOM من خريطة للخلايا العصبية ، ولكل منها ناقل وزن بنفس حجم متجه الإدخال. يتم تهيئة متجه الوزن بأوزان عشوائية قبل بدء التدريب. أثناء التدريب ، تتم مقارنة كل مدخلات مع الخلايا العصبية في الخريطة بناءً على مقياس المسافة (على سبيل المثال ، المسافة الإقليدية) ويتم تعيينها إلى أفضل وحدة مطابقة (BMU) ، وهي الخلية العصبية ذات المسافة الدنيا إلى متجه الإدخال.
يتم تحديث أوزان وحدة BMU بأوزان متجه الإدخال ، ويتم تحديث الخلايا العصبية المجاورة بناءً على نصف قطر الجوار (سيغما). نظرًا لأن الخلايا العصبية تتنافس مع بعضها البعض لتكون أفضل وحدة مطابقة ، تُعرف هذه العملية بالتعلم التنافسي. في النهاية ، تكون الخلايا العصبية للعينات الطبيعية أقرب من الخلايا الشاذة. يتم تحديد درجات الشذوذ من خلال خطأ التكميم ، وهو الفرق بين عينة الإدخال وأوزان أفضل وحدة مطابقة. يشير خطأ التكميم الأعلى إلى احتمال أكبر أن تكون العينة شذوذًا. - DAGMM - نموذج المزيج الغاوسي للتشفير التلقائي العميق (DAGMM) هو طريقة لتقدير الكثافة تفترض أن الحالات الشاذة تكمن في منطقة ذات احتمالية منخفضة. تنقسم الشبكة إلى جزأين: شبكة ضغط ، تُستخدم لعرض البيانات في أبعاد أقل باستخدام وحدة التشفير التلقائي ، وشبكة تقدير ، والتي تُستخدم لتقدير معلمات نموذج الخليط الغاوسي. تقدر DAGMM عدد k من الخلائط الغوسية ، حيث يمكن أن يكون k أي رقم من 1 إلى N (عدد نقاط البيانات) ، ويفترض أن النقاط العادية تقع في منطقة عالية الكثافة ، مما يعني أن احتمال أخذ عينات من خليط Gaussian أعلى للنقاط العادية من العينات الشاذة. يتم تحديد درجات الشذوذ من خلال الطاقة المقدرة للعينة.
- RSRAE - طبقة الاسترداد القوية للسطح لاكتشاف الشذوذ غير الخاضع للإشراف هي طريقة لإعادة بناء الخطأ تقوم أولاً بإخراج البيانات إلى بُعد أقل باستخدام وحدة تشفير تلقائية. ثم يخضع التمثيل الكامن لإسقاط متعامد على فضاء جزئي خطي يكون متينًا مع القيم المتطرفة. ثم يعيد مفكك الشفرة بناء الناتج من الفضاء الجزئي الخطي. في هذه الطريقة ، يشير خطأ إعادة الإعمار الأعلى إلى احتمال أكبر أن تكون العينة شذوذًا.
- سوم-داجمم- خريطة التنظيم الذاتي (SOM) - نموذج المزيج الغاوسي ذو الترميز التلقائي العميق (DAGMM) هو أيضًا نموذج تقدير الكثافة. مثل DAGMM ، فإنه يقدر أيضًا التوزيع الاحتمالي لنقاط البيانات العادية ويصنف نقطة البيانات على أنها شذوذ إذا كان لديها احتمال ضئيل لأخذ عينات من التوزيع الذي تم تعلمه. يتمثل الاختلاف الرئيسي بين SOM-DAGMM و DAGMM في أن SOM-DAGMM يتضمن الإحداثيات الطبيعية لـ SOM لعينة الإدخال ، والتي توفر المعلومات الطوبولوجية المفقودة في حالة DAGMM لشبكة التقدير. الهدف مشابه أيضًا لـ DAGMM في أن درجات الشذوذ يتم تحديدها من خلال الطاقة المقدرة للعينة ، وتشير الطاقة المنخفضة إلى احتمال أعلى للعينة باعتبارها شذوذًا.
بعد ذلك ، سنتناول التحدي المتمثل في التعامل مع السمات الفئوية.
كيف يؤثر ترميز السمات الفئوية على النماذج؟
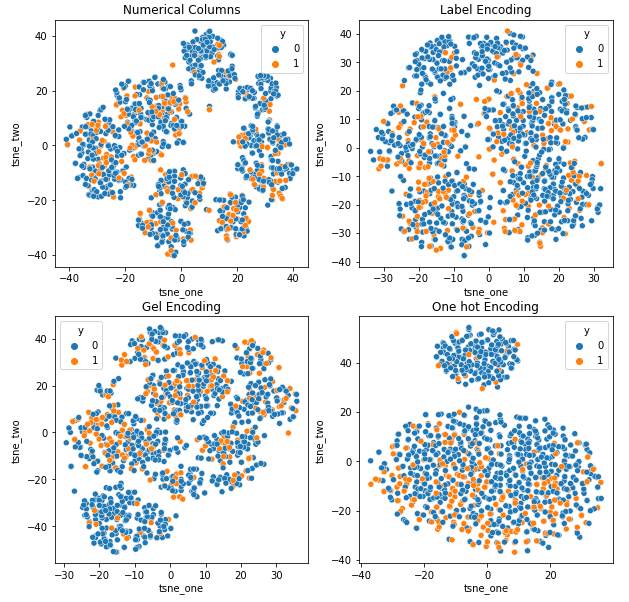
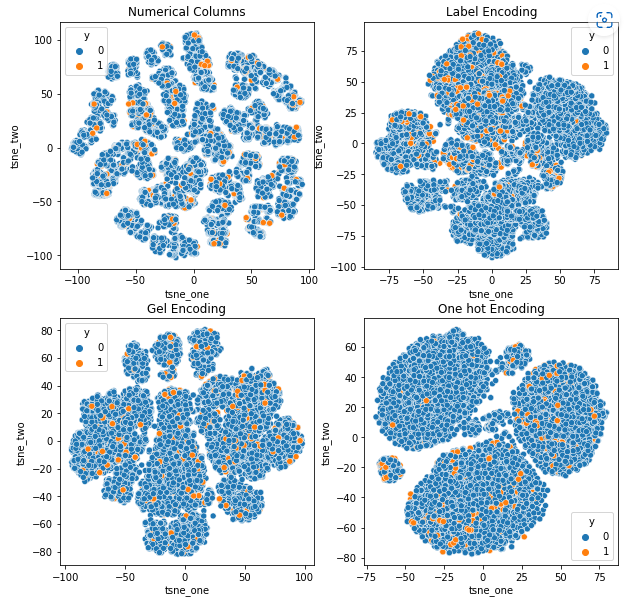
لفهم تأثير الترميزات المختلفة على مجموعات البيانات ، سوف نستخدم t-SNE لتصور التمثيلات منخفضة الأبعاد للبيانات للترميزات المختلفة. تقوم t-SNE بإسقاط بيانات عالية الأبعاد في مساحة ذات أبعاد أقل ، مما يسهل تصورها. من خلال مقارنة تصورات t-SNE والنتائج الرقمية للترميزات المختلفة لمجموعة البيانات نفسها ، لوحظ الاختلاف في التمثيلات الناتجة وفهم تأثير الترميز على مجموعة البيانات.
تمثيل t-SNE لمجموعة بيانات تأمين السيارات
تمثيل t-SNE لمجموعة بيانات تأمين المركبات
-
البيانات أقرب إلى بعضها البعض لأن عدد الصفوف أكبر مما هو موجود في مجموعة بيانات تأمين السيارات. يصبح من الصعب الفصل مع الأبعاد المتزايدة في ترميز One Hot.
-
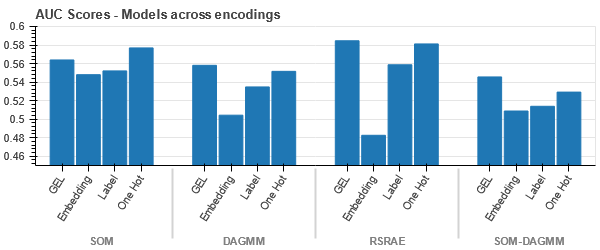
يعد ترميز GEL أفضل من ترميز One Hot في جميع الحالات باستثناء DAGMM.
تمثيل t-SNE لمجموعة بيانات مطالبات المركبات
-
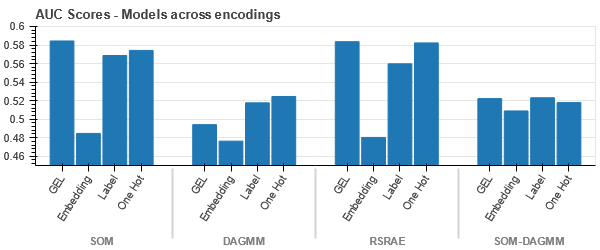
البيانات مرتبطة بإحكام في جميع الحالات ، مما يجعل من الصعب الفصل مع زيادة الأبعاد. هذا هو أحد أسباب الأداء الضعيف للنماذج بسبب الأبعاد المتزايدة.
- يتفوق SOM على جميع النماذج الأخرى لمجموعة البيانات هذه. ومع ذلك ، فإن طبقة التضمين أكثر ملاءمة في معظم الحالات ، مما يتيح لنا بديلاً عن التشفير السمات الفئوية لاكتشاف الشذوذ.
وفي الختام
تقدم هذه المقالة نظرة عامة مختصرة على بيانات التدقيق واكتشاف العيوب والتشفيرات الفئوية. من المهم أن نفهم أن التعامل مع السمات الفئوية في تدقيق البيانات يمثل تحديًا. من خلال فهم تأثير ترميز السمات على النماذج ، يمكننا تحسين دقة الكشف عن الانحرافات في مجموعات البيانات. النقاط الرئيسية من هذه المقالة هي:
- مع زيادة حجم البيانات ، من المهم استخدام طرق تشفير بديلة للسمات الفئوية ، مثل ترميز GEL وطبقات التضمين ، لأن ترميز One Hot غير مناسب.
- نموذج واحد لا يعمل لجميع مجموعات البيانات. بالنسبة لمجموعات البيانات المجدولة ، فإن معرفة المجال مهمة للغاية.
- يعتمد اختيار طريقة التشفير على اختيار النموذج.
رمز تقييم النماذج متاح على GitHub جيثب:.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- من نحن
- فوق
- وفقا
- دقة
- وبالإضافة إلى ذلك
- العنوان
- الكل
- يسمح
- البديل
- دائما
- تحليلات
- تحليلات Vidhya
- و
- إكتشاف عيب خلقي
- اقتراب
- البند
- تعيين
- أسوشيتد
- يفترض
- سمات
- التدقيق
- أوتوماتيك
- متاح
- على أساس
- لان
- يصبح
- قبل
- يجري
- أقل من
- المعايير
- أفضل
- أفضل
- ما بين
- أكبر
- ملزم
- العلامة تجارية
- لا تستطيع
- أسر
- سيارة
- التأمين على السيارات
- فيزا وماستركارد
- حقيبة
- الحالات
- الفئات
- تحدى
- التحديات
- تحدي
- فرص
- حرف
- خيار
- مطالبة
- مطالبات
- فئة
- فصول
- تصنيف
- صنف
- واضح
- أقرب
- الكود
- اللون
- عادة
- مجتمع
- الشركات
- مقارنة
- مقارنة
- تنافس
- تنافسي
- مجمع
- مفهوم
- سرية
- تتكون
- يحتوي
- متواصل
- منظمة
- التكلفة
- خلق
- ائتمان
- بطاقة إئتمان
- البيانات
- نقاط البيانات
- قواعد البيانات
- التاريخ
- تعامل
- تخفيض
- عميق
- التعلم العميق
- يعتمد
- مفصلة
- كشف
- حدد
- فرق
- مختلف
- صعبة
- بعد
- الأبعاد
- مباشرة
- حرية التصرف
- مسافة
- خامد
- توزيع
- منقسم
- نطاق
- سائق
- أثناء
- كل
- أسهل
- إما
- طاقة
- خطأ
- أخطاء
- تقدير
- مقدر
- تقديرات
- إلخ
- تقييم
- تقييم
- التقييمات
- مثال
- أمثلة
- إلا
- ذو تكلفة باهظة
- جدا
- واجه
- العوامل
- الميزات
- المميزات
- الاسم الأول
- غابة
- احتيال
- محتال
- تبدأ من
- وقود
- الجنس
- مجموعات
- معالجة
- مرتفع
- أعلى
- أفضل العروض
- لكن
- HTTPS
- مهجنة
- تحديد
- التأثير
- أهمية
- تحسن
- in
- تتضمن
- يشمل
- دخل
- زيادة
- الزيادات
- في ازدياد
- يشير
- معلومات
- نظم المعلومات
- إدخال
- التأمين
- عزل
- قضية
- مسائل
- IT
- القفل
- علم
- المعرفة
- معروف
- تُشير
- وصفها
- ملصقات
- كبير
- أكبر
- طبقة
- طبقات
- قيادة
- تعلم
- تعلم
- تعلم
- محلي
- تقع
- بحث
- خسارة
- خسائر
- منخفض
- آلة
- آلة التعلم
- الآلات
- الرئيسية
- يصنع
- القيام ب
- إلزامي
- كتيب
- كثير
- رسم خريطة
- مطابقة
- مصفوفة
- معنى
- الوسائط
- متوسط
- طريقة
- طرق
- متري
- الحد الأدنى
- مفقود
- تخفيف
- مزيج
- نموذج
- عارضات ازياء
- الأكثر من ذلك
- أكثر
- شبكة
- الخلايا العصبية
- جديد
- مزايا جديدة
- عادي
- عدد
- موضوعي
- ONE
- طلب
- أخرى
- يتفوق
- تغلب
- نظرة عامة
- مملوكة
- المعلمات
- جزء
- أجزاء
- أداء
- ينفذ
- الشخصية
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- البوينت
- نقاط
- فقير
- أكثر الاستفسارات
- ممكن
- تفضل
- يقدم
- الهدايا
- السعر
- مبدأ
- قبل
- الاحتمالات
- المشكلة
- عملية المعالجة
- مهنة
- تنفيذ المشاريع
- بيانات المشروع
- إسقاط
- مشروع ناجح
- HAS
- تزود
- المقدمة
- ويوفر
- نشرت
- عشوائية
- نطاق
- حقيقي
- العالم الحقيقي
- الأسباب
- استرجاع
- منطقة
- العلاقات
- إصلاح
- استبدال
- التمثيل
- يمثل
- يتطلب
- نتيجة
- مما أدى
- النتائج
- قوي
- نفسه
- علوم
- حساس
- مستقل
- أظهرت
- Sigma
- مماثل
- منذ
- عزباء
- مقاس
- صغير
- الأصغر
- So
- الفضاء
- محدد
- يبدأ
- لا يزال
- هذه
- يعاني
- مناسب
- الدعم
- المساحة
- اصطناعي
- أنظمة
- جدول
- الوجبات السريعة
- سياسة الحجب وتقييد الوصول
- •
- العالم
- وبالتالي
- عتبة
- بإحكام
- استهلاك الوقت
- إلى
- الإجمالي
- قطار
- قادة الإيمان
- فهم
- فهم
- فريد من نوعه
- وحدة
- تعليم غير مشرف عليه
- تحديث
- us
- تستخدم
- قيمنا
- القيم
- المثالية
- السيارات
- وزن
- ابحث عن
- ما هي تفاصيل
- التي
- في حين
- سوف
- كلمة
- كلمات
- للعمل
- العالم
- سوف
- عام
- زفيرنت