اجعل Pandas أسرع 3 مرات مع PyPolars
تعرف على كيفية تسريع سير عمل Pandas باستخدام مكتبة PyPolars.
By ساتيام كومار، متحمس لتعلم الآلة ومبرمج

تصوير تيم غو on Unsplash
تعد Pandas واحدة من أهم حزم Python بين علماء البيانات للتلاعب بالبيانات. تُستخدم مكتبة Pandas في الغالب لاستكشاف البيانات والتصورات لأنها تأتي مع الكثير من الوظائف الداخلية. تفشل Pandas في التعامل مع مجموعات البيانات كبيرة الحجم لأنها لا تقوم بتوسيع نطاق عملياتها أو توزيعها عبر جميع أنوية وحدة المعالجة المركزية.
لتسريع العمليات الحسابية ، يمكن للمرء استخدام جميع أنوية وحدة المعالجة المركزية وتسريع سير العمل. هناك العديد من المكتبات مفتوحة المصدر بما في ذلك Dask و Vaex و Modin و Pandarallel و PyPolars وغيرها التي تقوم بالتوازي مع العمليات الحسابية عبر نوى متعددة لوحدة المعالجة المركزية. في هذه المقالة ، سنناقش تطبيق واستخدام مكتبة PyPolars ومقارنة أدائها بمكتبة Pandas.
ما هو PyPolars؟
PyPolars هي مكتبة إطار بيانات Python مفتوحة المصدر تشبه Pandas. يستخدم PyPolars جميع النوى المتاحة لوحدة المعالجة المركزية وبالتالي يقوم بإجراء العمليات الحسابية بشكل أسرع من Pandas. لدى PyPolars واجهة برمجة تطبيقات مشابهة لتلك الخاصة بـ Pandas. إنه مكتوب بالصدأ مع أغلفة بايثون.
من الناحية المثالية ، يتم استخدام PyPolars عندما تكون البيانات كبيرة جدًا بالنسبة إلى Pandas وصغيرة جدًا بالنسبة لـ Spark
كيف يعمل PyPolars؟
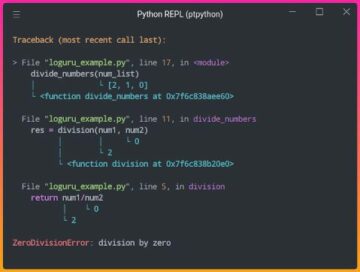
تحتوي مكتبة PyPolars على واجهتي API ، أحدهما هو Eager API والآخر هو Lazy API. تشبه Eager API تلك الخاصة بـ Pandas ، ويتم إنتاج النتائج مباشرة بعد اكتمال التنفيذ على غرار Pandas. تشبه Lazy API إلى حد كبير Spark ، حيث يتم تشكيل خريطة أو خطة عند تنفيذ استعلام. ثم يتم تنفيذ التنفيذ بشكل متوازي عبر جميع أنوية وحدة المعالجة المركزية.

(صورة المؤلف) ، PyPolars API's
يعد PyPolars أساسًا بمثابة ارتباط بيثون بمكتبة Polars. أفضل جزء في مكتبة PyPolars هو تشابه واجهة برمجة التطبيقات مع Pandas ، مما يسهل على المطورين.
تركيب:
يمكن تثبيت PyPolars من PyPl باستخدام الأمر التالي:
pip install py-polarsواستيراد المكتبة باستخدام ملفات
import pypolars as plقيود الوقت المعيارية:
بالنسبة للعروض التوضيحية ، لقد استخدمت مجموعة بيانات كبيرة الحجم (حوالي 6.4 جيجا بايت) بها 25 مليون نسخة.

(الصورة من المؤلف) ، رقم الوقت المعياري لعمليات Pandas و Py-Polars الأساسية
بالنسبة للأرقام القياسية المذكورة أعلاه لبعض العمليات الأساسية باستخدام مكتبة Pandas و PyPolars ، يمكننا أن نلاحظ أن PyPolars أسرع من Pandas بمقدار 2x إلى 3x تقريبًا.
نحن نعلم الآن أن PyPolars لديها واجهة برمجة تطبيقات مشابهة جدًا لتلك الخاصة بـ Pandas ، لكنها لا تزال لا تغطي جميع وظائف Pandas. على سبيل المثال ، ليس لدينا .describe() تعمل في PyPolars ، بدلاً من ذلك ، يمكننا استخدام df_pypolars.to_pandas().describe()
الاستخدام:
(كود المؤلف)
الخلاصة:
في هذه المقالة ، قمنا بتغطية مقدمة صغيرة لمكتبة PyPolars ، بما في ذلك تنفيذها ، واستخدامها ، ومقارنة أرقامها الزمنية المعيارية مع Pandas لبعض العمليات الأساسية. لاحظ أن PyPolars تعمل بشكل مشابه جدًا لتلك الخاصة بـ Pandas ، و PyPolars هي مكتبة فعالة للذاكرة لأن الذاكرة التي تدعمها غير قابلة للتغيير.
يمكن للمرء أن يمر من خلال توثيق للحصول على فهم تفصيلي للمكتبة. هناك العديد من المكتبات الأخرى مفتوحة المصدر التي يمكنها موازنة عمليات Pandas وتسريع العملية. إقرأ ال المادة المذكورة أدناه لمعرفة 4 مكتبات من هذا القبيل:
4 مكتبات يمكن أن توازي نظام Pandas البيئي الحالي
وزع عبء عمل Python عن طريق المعالجة المتوازية باستخدام هذه الأطر
المراجع:
[1] وثائق Polars ومستودع GitHub: https://github.com/ritchie46/polars
شكرا لقرائتك
السيرة الذاتية: ساتيام كومار هو متحمس للتعلم الآلي ومبرمج. ساتيام يكتب حول علوم البيانات ، وهو كاتب بارز في الذكاء الاصطناعي. إنه يبحث عن مهنة مليئة بالتحديات مع منظمة توفر فرصة للاستفادة من مهاراته وقدراته التقنية.
أصلي. تم إعادة النشر بإذن.
هذا الموضوع ذو علاقة بـ:
أهم الأخبار في الثلاثين يومًا الماضية
|
|
المصدر: https://www.kdnuggets.com/2021/05/pandas-faster-pypolars.html
- "
- &
- AI
- خوارزميات
- الكل
- من بين
- API
- واجهات برمجة التطبيقات
- حول
- البند
- السيارات
- مؤشر
- أفضل
- كُتُب
- التوظيف
- وظائف
- الكود
- البيانات
- علم البيانات
- عالم البيانات
- عرض مرئي للمعلومات
- صفقة
- المطورين
- مهندس
- إلخ
- GitHub جيثب:
- توجيه
- كيفية
- كيفية
- HTTPS
- صورة
- بما فيه
- IT
- كبير
- تعلم
- تعلم
- المكتبة
- لينكدين:
- آلة التعلم
- رسم خريطة
- متوسط
- مایکروسافت
- مايكروسوفت للبحوث
- مليون
- نموذج
- أرقام
- عمليات
- الفرصة
- أخرى
- أداء
- أنتج
- بايثون
- نادي القراءة
- بحث
- النتائج
- Rust
- حجم
- علوم
- حجم
- مهارات
- صغير
- سرعة
- SQL
- بداية
- قصص
- تقني
- الوقت
- نغمة
- تيشرت
- التصور
- سير العمل
- أعمال
- كاتب
- X