تشير البرمجة اللغوية العصبية المتعددة التسميات إلى مهمة تعيين تسميات متعددة لإدخال نص معين ، بدلاً من تسمية واحدة فقط. في مهام البرمجة اللغوية العصبية التقليدية ، مثل تصنيف النص أو تحليل المشاعر ، يتم عادةً تعيين تسمية واحدة لكل إدخال بناءً على محتواه. ومع ذلك ، في العديد من سيناريوهات العالم الحقيقي ، يمكن أن ينتمي جزء من النص إلى فئات متعددة أو يعبر عن مشاعر متعددة في وقت واحد.
تعد معالجة اللغات الطبيعية متعددة التسميات أمرًا مهمًا لأنها تتيح لنا الحصول على معلومات أكثر دقة وتعقيدًا من البيانات النصية. على سبيل المثال ، في مجال تحليل ملاحظات العملاء ، قد تعبر مراجعة العميل عن المشاعر الإيجابية والسلبية في نفس الوقت ، أو قد تمس جوانب متعددة من منتج أو خدمة. من خلال تعيين تسميات متعددة لمثل هذه المدخلات ، يمكننا الحصول على فهم أكثر شمولاً لملاحظات العميل واتخاذ إجراءات أكثر استهدافًا لمعالجة مخاوفهم.
تتعمق هذه المقالة في حالة جديرة بالملاحظة لاستخدام Provectus في معالجة اللغات الطبيعية متعددة العلامات.
السياق:
اتصل بنا أحد العملاء وطلب منهم مساعدتهم أتمتة وثائق العنونة من نوع معين. للوهلة الأولى ، بدت المهمة واضحة ومباشرة ويمكن حلها بسهولة. ومع ذلك ، أثناء عملنا على الحالة ، واجهنا مجموعة بيانات بها تعليقات توضيحية غير متسقة. على الرغم من أن عملائنا واجهوا تحديات مع اختلاف أعداد الفصول والتغييرات في فريق المراجعة الخاص بهم بمرور الوقت ، فقد استثمروا جهودًا كبيرة في إنشاء مجموعة بيانات متنوعة مع مجموعة من التعليقات التوضيحية. على الرغم من وجود بعض الاختلالات والشكوك في الملصقات ، فقد وفرت مجموعة البيانات هذه فرصة قيمة للتحليل والمزيد من الاستكشاف.
دعنا نلقي نظرة فاحصة على مجموعة البيانات ، ونستكشف المقاييس ومنهجنا ، ونلخص كيف حل Provectus مشكلة تصنيف النص متعدد التسميات.
تحتوي مجموعة البيانات على 14,354 ملاحظة ، مع 124 فئة فريدة (ملصقات). مهمتنا هي تخصيص فئة واحدة أو أكثر لكل ملاحظة.
يوفر الجدول 1 إحصائيات وصفية لمجموعة البيانات.
في المتوسط ، لدينا حوالي فصلين لكل ملاحظة ، بمتوسط 261 نصًا مختلفًا يصف فصلًا واحدًا.

الجدول 1: إحصاء مجموعة البيانات
في الشكل 1 ، نرى توزيع الفئات في الرسم البياني العلوي ، ولدينا عدد معين من تسميات HEAD مع أعلى معدل تكرار في مجموعة البيانات. لاحظ أيضًا أن غالبية الفئات لها تكرار منخفض.
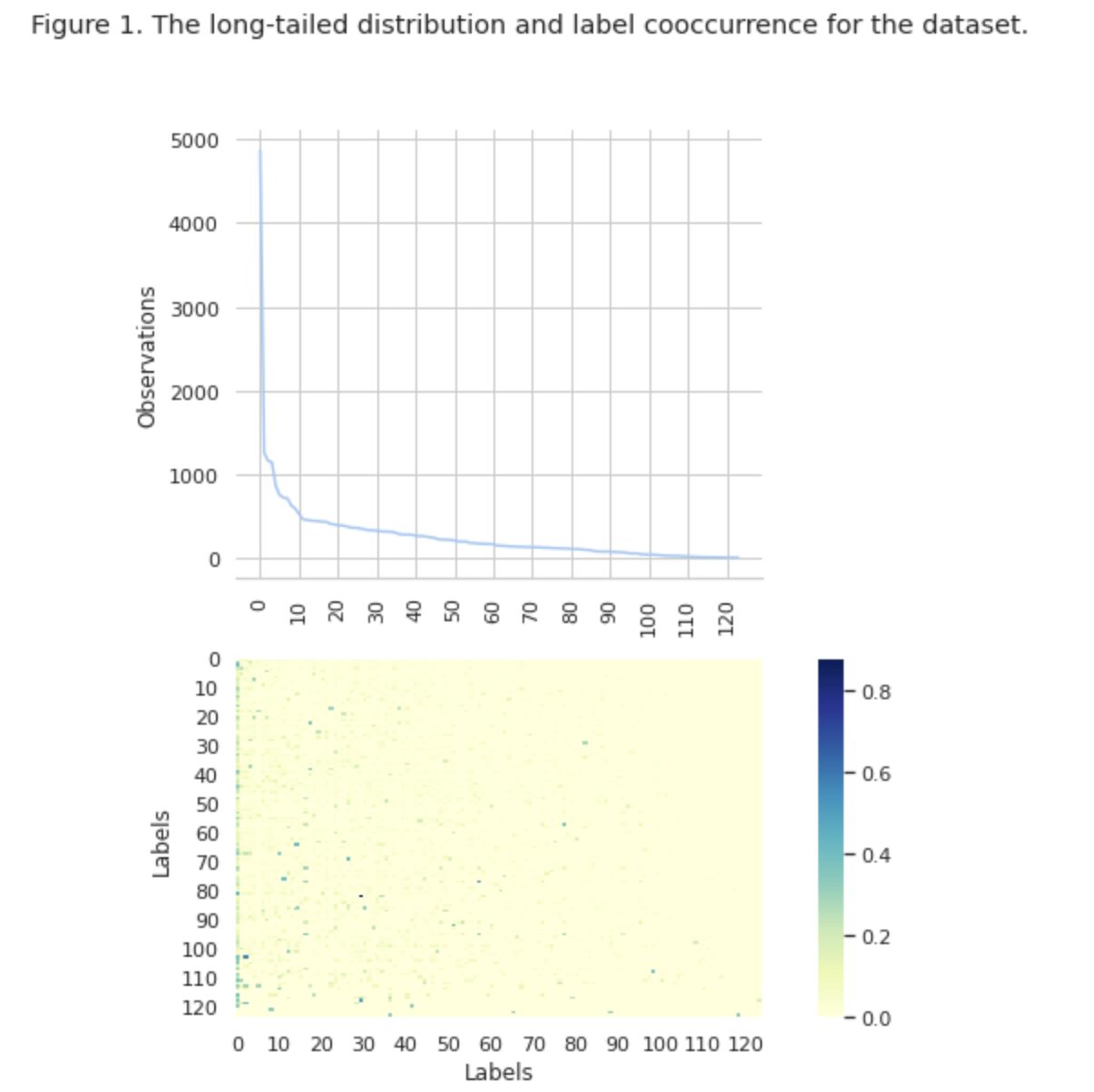
في الرسم البياني السفلي ، نرى أن هناك تداخلًا متكررًا بين الفئات التي يتم تمثيلها بشكل أفضل في مجموعة البيانات ، والفئات ذات الأهمية المنخفضة.
لقد غيرنا عملية تقسيم مجموعة البيانات إلى مجموعات تدريب / اختبار / اختبار. بدلاً من استخدام الطريقة التقليدية ، استخدمنا التقسيم الطبقي التكراري ، لتوفير توزيع متوازن جيدًا للأدلة على علاقات التسمية. لذلك ، استخدمنا Scikit متعدد التعلم
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
حصلنا على التوزيع التالي:
- تحتوي مجموعة بيانات التدريب على 60٪ من البيانات وتغطي جميع الملصقات البالغ عددها 124 ملصقًا
- تحتوي مجموعة بيانات التحقق من الصحة على 20٪ من البيانات وتغطي جميع التصنيفات البالغ عددها 124
- تحتوي مجموعة بيانات الاختبار على 20٪ من البيانات وتغطي جميع الملصقات البالغ عددها 124 ملصقًا
التصنيف متعدد الملصقات هو نوع من خوارزمية التعلم الآلي الخاضعة للإشراف والتي تسمح لنا بتعيين تسميات متعددة لعينة بيانات واحدة. وهو يختلف عن التصنيف الثنائي حيث يتنبأ النموذج بفئتين فقط ، وتصنيف متعدد الفئات حيث يتنبأ النموذج بفئة واحدة فقط من بين فئات متعددة لعينة.
تختلف مقاييس التقييم لأداء التصنيف متعدد التصنيفات بطبيعتها عن تلك المستخدمة في التصنيف متعدد الفئات (أو الثنائي) بسبب الاختلافات الكامنة في مشكلة التصنيف. يمكن العثور على مزيد من المعلومات التفصيلية على ويكيبيديا.
اخترنا المقاييس الأكثر ملاءمة لنا:
- دقة يقيس نسبة التوقعات الإيجابية الحقيقية بين إجمالي التوقعات الإيجابية التي قدمها النموذج.
- تذكر يقيس نسبة التوقعات الإيجابية الحقيقية بين جميع العينات الإيجابية الفعلية.
- درجة F1 هي الوسيلة التوافقية للدقة والاستدعاء ، مما يساعد على إعادة التوازن بين الاثنين.
- يدق الخسارة هي جزء التسميات التي تم توقعها بشكل غير صحيح
نحن أيضا نتتبع عدد التسميات المتوقعة في المجموعة {المُعرَّفة على أنها عدد التصنيفات ، والتي نحقق لها درجة F1> 0}.
يعد التصنيف متعدد الملصقات نوعًا من مشكلات التعلم الخاضع للإشراف حيث يمكن ربط مثيل واحد أو مثال واحد بتسميات أو تصنيفات متعددة ، على عكس التصنيف التقليدي أحادي التسمية ، حيث يرتبط كل مثيل فقط بتسمية فئة واحدة.
لحل مشاكل التصنيف متعدد العلامات ، هناك فئتان رئيسيتان من التقنيات:
- طرق تحويل المشكلة
- طرق التكيف الخوارزمية
تمكّننا طرق تحويل المشكلة من تحويل مهام التصنيف متعددة التسميات إلى مهام تصنيف متعددة ذات تسمية واحدة. على سبيل المثال ، يعامل نهج خط الأساس للصلة الثنائية (BR) كل تسمية على أنها مشكلة تصنيف ثنائية منفصلة. في هذه الحالة ، يتم تحويل مشكلة التسمية المتعددة إلى مشاكل متعددة ذات تسمية واحدة.
تعدل طرق تكيف الخوارزميات الخوارزميات نفسها للتعامل مع البيانات متعددة التسمية محليًا ، دون تحويل المهمة إلى مهام تصنيف متعددة ذات تسمية واحدة. مثال على هذا النهج هو نموذج بيرت، وهو نموذج لغة قائم على المحولات مدرب مسبقًا ويمكن ضبطه لمهام معالجة اللغات الطبيعية المختلفة ، بما في ذلك تصنيف النص متعدد التسميات. تم تصميم BERT للتعامل مع البيانات متعددة التسميات مباشرة ، دون الحاجة إلى تحويل المشكلة.
في سياق استخدام BERT لتصنيف النص متعدد التسميات ، فإن النهج القياسي هو استخدام خسارة Binary Cross-Entropy (BCE) كوظيفة خسارة. خسارة BCE هي دالة خسارة شائعة الاستخدام لمشاكل التصنيف الثنائي ويمكن توسيعها بسهولة للتعامل مع مشاكل التصنيف متعدد العلامات عن طريق حساب الخسارة لكل ملصق بشكل مستقل ، ثم جمع الخسائر. في هذه الحالة ، تقيس دالة خسارة BCE الخطأ بين الاحتمالات المتوقعة والتسميات الحقيقية ، حيث يتم الحصول على الاحتمالات المتوقعة من طبقة التنشيط السيني النهائية في نموذج BERT.
الآن ، دعنا نلقي نظرة فاحصة على الشكل 2 أدناه.
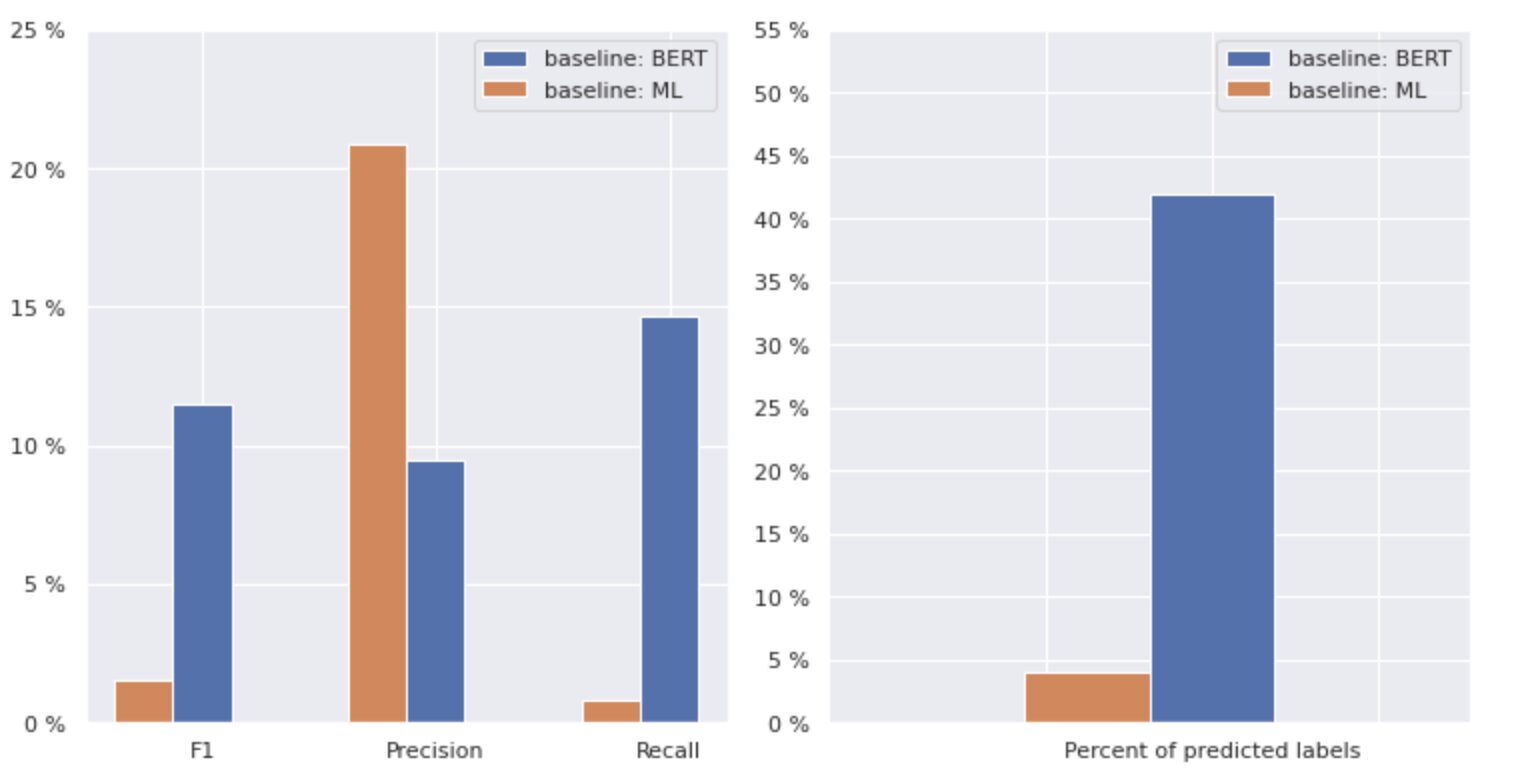
الشكل 2. مقاييس النماذج الأساسية
يوضح الرسم البياني الموجود على اليسار مقارنة بين مقاييس "خط الأساس: BERT" و "خط الأساس: ML". وبالتالي ، يمكن ملاحظة أنه بالنسبة "لخط الأساس: BERT" ، فإن درجات F1 و Recall أعلى بحوالي 1.5 مرة ، في حين أن دقة "خط الأساس: ML" أعلى بمرتين من تلك الخاصة بالنموذج 2. من خلال تحليل النسبة المئوية الإجمالية لـ تظهر الفئات المتوقعة على اليمين ، نرى أن "خط الأساس: BERT" تنبأ بالفئات بأكثر من 1 مرات من "خط الأساس: ML".
نظرًا لأن النتيجة القصوى لـ "خط الأساس: BERT" أقل من 50٪ من جميع الفئات ، فإن النتائج غير مشجعة تمامًا. دعنا نتعرف على كيفية تحسين هذه النتائج.
بناء على المقال المتميز "طرق الموازنة لتصنيف النص متعدد العلامات مع توزيع الفئة طويل الذيل"، تعلمنا أن الخسارة المتوازنة في التوزيع قد تكون الطريقة الأنسب لنا.
توزيع الخسارة المتوازن
الخسارة المتوازنة للتوزيع هي تقنية مستخدمة في مشاكل تصنيف النص متعدد التسميات لمعالجة الاختلالات في توزيع الفئات. في هذه المشكلات ، يكون لبعض الفئات تكرار حدوث أعلى بكثير مقارنة بالآخرين ، مما يؤدي إلى تحيز النموذج تجاه هذه الفئات الأكثر تكرارًا.
لمعالجة هذه المشكلة ، تهدف الخسارة المتوازنة للتوزيع إلى موازنة مساهمة كل عينة في دالة الخسارة. يتم تحقيق ذلك من خلال إعادة ترجيح فقدان كل عينة بناءً على معكوس تكرار حدوثها في مجموعة البيانات. من خلال القيام بذلك ، يتم زيادة مساهمة الفصول الأقل تكرارا ، وتقل مساهمة الفئات الأكثر تكرارا ، وبالتالي موازنة التوزيع الكلي للفئة.
لقد أثبتت هذه التقنية فعاليتها في تحسين أداء النماذج في مشاكل التوزيع الصنفية طويلة الذيل. من خلال تقليل تأثير الفصول المتكررة وزيادة تأثير الفئات النادرة ، يكون النموذج قادرًا على التقاط أنماط في البيانات بشكل أفضل وإنتاج تنبؤات أكثر توازناً.

تنفيذ فئة إعادة العينة
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
DBLoss
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
من خلال التحقيق عن كثب في مجموعة البيانات ، توصلنا إلى أن المعلمة
= 0.405.
ضبط العتبة
كانت الخطوة الأخرى في تحسين نموذجنا هي عملية ضبط العتبة ، سواء في مرحلة التدريب أو في مرحلتي التحقق من الصحة والاختبار. قمنا بحساب تبعيات المقاييس مثل الدرجة f1 والدقة والاستدعاء على مستوى العتبة ، واخترنا العتبة بناءً على أعلى درجة للمقياس. أدناه يمكنك رؤية تنفيذ الوظيفة لهذه العملية.
تحسين درجة F1 عن طريق ضبط العتبة:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]التقييم والمقارنة مع خط الأساس
سمحت لنا هذه الأساليب بتدريب نموذج جديد والحصول على النتيجة التالية ، والتي تتم مقارنتها بخط الأساس: BERT في الشكل 3 أدناه.

الشكل 3. مقاييس المقارنة حسب النهج الأساسي والأحدث.
بمقارنة المقاييس ذات الصلة بالتصنيف ، نرى زيادة ملحوظة في مقاييس الأداء تقريبًا بحوالي 5-6 مرات:
زادت درجة F1 من 12٪ - 55٪ ، بينما زادت الدقة من 9٪ - 59٪ وزادت درجة الاستدعاء من 15٪ - 51٪.
من خلال التغييرات الموضحة في الرسم البياني الأيمن في الشكل 3 ، يمكننا الآن توقع 80٪ من الفئات.
شرائح من الفصول
قمنا بتقسيم ملصقاتنا إلى أربع مجموعات: HEAD و MEDIUM و TAIL و ZERO. تحتوي كل مجموعة على ملصقات تحتوي على قدر مماثل من ملاحظات البيانات الداعمة.
كما هو موضح في الشكل 4 ، توزيعات المجموعات متميزة. يحتوي صندوق الورود (HEAD) على توزيع منحرف سلبيًا ، بينما يحتوي المربع الأوسط (MEDIUM) على توزيع منحرف إيجابيًا ، ويبدو أن المربع الأخضر (TAIL) له توزيع طبيعي.
تحتوي جميع المجموعات أيضًا على قيم متطرفة ، وهي نقاط خارج الشعيرات في مخطط الصندوق. مجموعة HEAD لها تأثير كبير على فئة رئيسية.
بالإضافة إلى ذلك ، حددنا مجموعة منفصلة تسمى "صفر" والتي تحتوي على تسميات لم يتمكن النموذج من التعرف عليها ولا يمكن التعرف عليها بسبب الحد الأدنى لعدد مرات الحدوث في مجموعة البيانات (أقل من 3٪ من جميع الملاحظات).
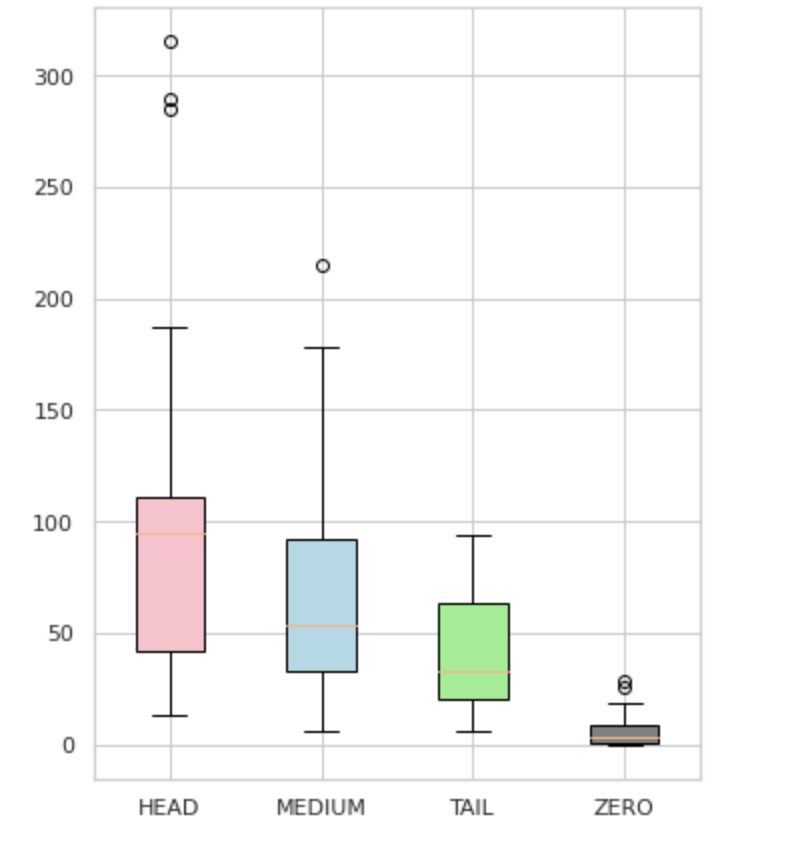
الشكل 4. تسمية التهم مقابل المجموعات
يوفر الجدول 2 معلومات حول المقاييس لكل مجموعة تسميات لمجموعة فرعية من البيانات.
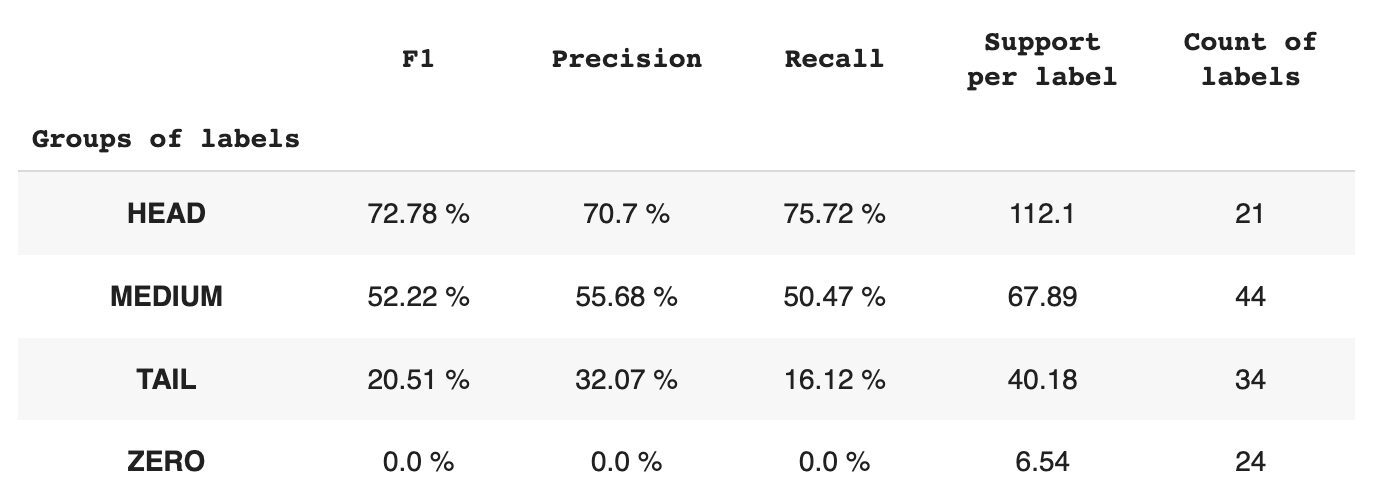
الجدول 2. المقاييس لكل مجموعة.
- تحتوي مجموعة HEAD على 21 تسمية بمتوسط 112 ملاحظة دعم لكل ملصق. تتأثر هذه المجموعة بالقيم المتطرفة ، وبسبب تمثيلها العالي في مجموعة البيانات ، فإن مقاييسها عالية: F1 - 73٪ ، الدقة - 71٪ ، Recall - 75٪.
- تتكون مجموعة MEDIUM من 44 تسمية مع دعم متوسط لـ 67 ملاحظة ، وهو ما يقرب من مرتين أقل من مجموعة HEAD. من المتوقع أن تنخفض المقاييس الخاصة بهذه المجموعة بنسبة 50٪: F1 - 52٪ ، الدقة - 56٪ ، Recall - 51٪.
- تحتوي مجموعة TAIL على أكبر عدد من الفئات ، ولكن جميعها ممثلة بشكل ضعيف في مجموعة البيانات ، بمتوسط 40 ملاحظة دعم لكل ملصق. نتيجة لذلك ، تنخفض المقاييس بشكل ملحوظ: F1 - 21٪ ، الدقة - 32٪ ، Recall - 16٪.
- تشتمل المجموعة ZERO على فئات لا يستطيع النموذج التعرف عليها على الإطلاق ، ويرجع ذلك على الأرجح إلى قلة حدوثها في مجموعة البيانات. كل تصنيف من 24 تصنيفًا في هذه المجموعة لديه 7 ملاحظات دعم في المتوسط.
يصور الشكل 5 المعلومات الواردة في الجدول 2 ، مما يوفر تمثيلًا مرئيًا للمقاييس لكل مجموعة من الملصقات.
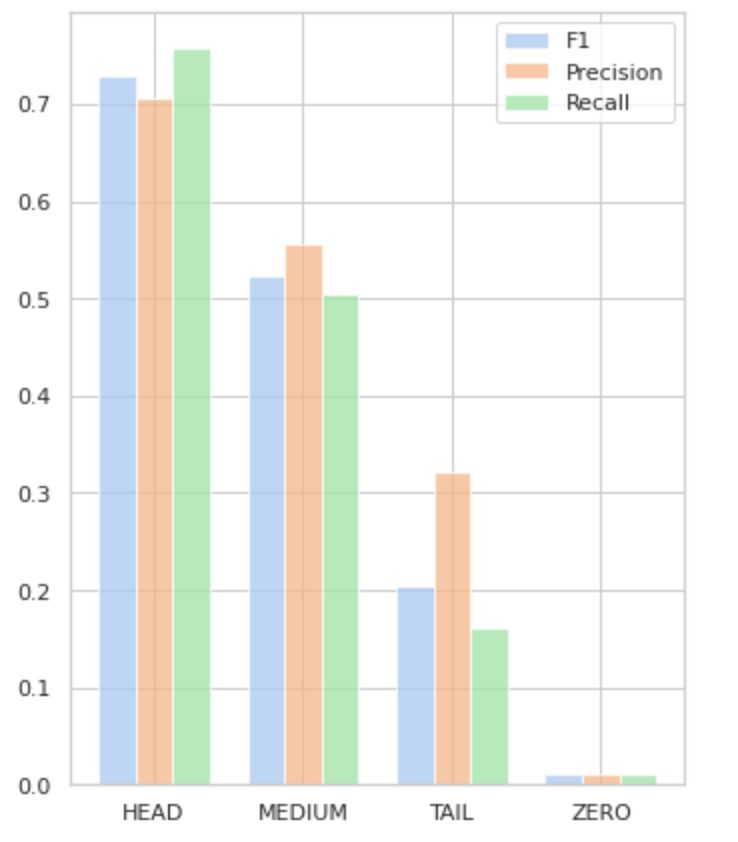
الشكل 5. المقاييس مقابل مجموعات التسمية. جميع القيم الصفرية = 0.
في هذه المقالة الشاملة ، أوضحنا أن مهمة بسيطة على ما يبدو لتصنيف النص متعدد التسميات يمكن أن تكون صعبة عند تطبيق الطرق التقليدية. لقد اقترحنا استخدام وظائف خسارة موازنة التوزيع لمعالجة مشكلة عدم التوازن الطبقي.
لقد قارنا أداء نهجنا المقترح بالطريقة الكلاسيكية ، وقمنا بتقييمه باستخدام مقاييس الأعمال الواقعية. توضح النتائج أن استخدام وظائف الخسارة لمعالجة اختلالات الفئة وتكرار التكرار يوفر حلاً قابلاً للتطبيق لتصنيف النص متعدد التسميات.
تسلط حالة الاستخدام المقترحة الضوء على أهمية النظر في الأساليب والتقنيات المختلفة عند التعامل مع تصنيف النص متعدد العلامات ، والفوائد المحتملة لوظائف خسارة موازنة التوزيع في معالجة اختلالات الفئات.
إذا كنت تواجه مشكلة مماثلة وتسعى إلى تبسيط عمليات معالجة المستندات داخل مؤسستك ، يرجى الاتصال بي أو بفريق Provectus. يسعدنا مساعدتك في إيجاد طرق أكثر كفاءة لأتمتة عملياتك.
أولكسي بيبيش هو مهندس تعلم الآلة في Provectus. مع خلفية في الفيزياء ، يمتلك مهارات تحليلية ورياضية ممتازة ، واكتسب خبرة قيمة من خلال البحث العلمي وعروض المؤتمرات الدولية ، بما في ذلك SPIE Photonics West. تتخصص Oleksii في إنشاء حلول AI / ML شاملة وواسعة النطاق للرعاية الصحية وصناعات التكنولوجيا المالية. يشارك في كل مرحلة من مراحل دورة حياة تطوير ML ، من تحديد مشاكل العمل إلى نشر وتشغيل نماذج ML للإنتاج.
رينات أحمدوف هو مهندس حلول ML في Provectus. مع خلفية عملية قوية في التعلم الآلي (خاصة في رؤية الكمبيوتر) ، فإن Rinat هو الطالب الذي يذاكر كثيرا ، والمتحمسين للبيانات ، ومهندس البرمجيات ، ومدمن العمل ولديه ثاني أكبر شغفه هو البرمجة. في Provectus ، يكون Rinat مسؤولاً عن اكتشاف وإثبات مراحل المفهوم ، ويقود تنفيذ مشاريع الذكاء الاصطناعي المعقدة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- :يكون
- 1
- 10
- 100
- 15%
- 67
- 7
- 9
- a
- ماهرون
- من نحن
- التأهيل
- تحقق
- الإجراءات
- تفعيل
- تكيف
- العنوان
- معالجة
- AI
- AI / ML
- وتهدف
- خوارزمية
- خوارزميات
- الكل
- يسمح
- ألفا
- من بين
- كمية
- تحليل
- تحليلية
- تحليل
- و
- ظهر
- تطبيقي
- التقديم
- نهج
- اقتراب
- ما يقرب من
- هي
- البند
- AS
- الجوانب
- تعيين
- مساعدة
- أسوشيتد
- At
- أتمتة
- المتوسط
- خلفية
- الرصيد
- على أساس
- خط الأساس
- BE
- لان
- أقل من
- الفوائد
- أفضل
- بيتا
- أفضل
- ما بين
- انحياز
- أكبر
- الملابس السفلية
- صندوق
- مدمج
- الأعمال
- by
- محسوب
- CAN
- لا تستطيع
- أسر
- حقيبة
- الفئات
- CB
- معين
- التحديات
- تحدي
- التغييرات
- تهمة
- فئة
- فصول
- كلاسيكي
- تصنيف
- زبون
- عن كثب
- أقرب
- عادة
- مقارنة
- مقارنة
- مقارنة
- مجمع
- شامل
- الكمبيوتر
- رؤية الكمبيوتر
- الحوسبة
- مفهوم
- اهتمامات
- وخلص
- مؤتمر
- النظر
- التواصل
- يحتوي
- محتوى
- سياق الكلام
- إسهام
- ويغطي
- خلق
- زبون
- دورة
- البيانات
- تعامل
- تخفيض
- تعريف
- شرح
- تظاهر
- نشر
- تصميم
- مفصلة
- التطوير التجاري
- الخلافات
- مختلف
- مباشرة
- اكتشاف
- خامد
- توزيع
- التوزيعات
- عدة
- منقسم
- وثيقة
- وثائق
- فعل
- نطاق
- قطرة
- كل
- بسهولة
- الطُرق الفعّالة
- فعال
- جهود
- تمكين
- النهائي إلى نهاية
- مهندس
- متحمس
- بالتساوي
- خطأ
- خاصة
- الأثير (ETH)
- تقييم
- كل
- دليل
- مثال
- ممتاز
- متوقع
- الخبره في مجال الغطس
- استكشاف
- اكتشف
- التعبير
- f1
- واجه
- مواجهة
- ردود الفعل
- الشكل
- نهائي
- العثور على
- FINTECH
- الاسم الأول
- تطفو
- متابعيك
- في حالة
- وجدت
- جزء
- تردد
- متكرر
- تبدأ من
- وظيفة
- وظيفي
- وظائف
- إضافي
- ربح
- معطى
- لمحة
- رسم بياني
- أخضر
- تجمع
- مجموعات
- مقبض
- سعيد
- يملك
- رئيس
- الرعاية الصحية
- مساعدة
- يساعد
- مرتفع
- أعلى
- أعلى
- ويبرز
- كيفية
- كيفية
- لكن
- HTML
- HTTP
- HTTPS
- محدد
- تحديد
- عدم التوازن
- التأثير
- أثر
- التنفيذ
- استيراد
- أهمية
- أهمية
- تحسن
- تحسين
- in
- يشمل
- بما فيه
- غير صحيح
- القيمة الاسمية
- زيادة
- في ازدياد
- بشكل مستقل
- الصناعات
- معلومات
- متأصل
- إدخال
- مثل
- بدلًا من ذلك
- عالميا
- استثمرت
- المشاركة
- قضية
- IT
- انها
- JPG
- واحد فقط
- KD nuggets
- تُشير
- وصفها
- ملصقات
- لغة
- على نطاق واسع
- أكبر
- طبقة
- يؤدي
- تعلم
- تعلم
- تعلم
- مستوى
- الحياة
- لينكدين:
- قائمة
- بحث
- خسارة
- خسائر
- منخفض
- آلة
- آلة التعلم
- صنع
- الرئيسية
- رائد
- أغلبية
- كثير
- رسم الخرائط
- الرياضيات
- أقصى
- الإجراءات
- متوسط
- طريقة
- طرق
- متري
- المقاييس
- أدنى
- ML
- MLB
- نموذج
- عارضات ازياء
- تعديل
- وحدة
- الأكثر من ذلك
- أكثر فعالية
- أكثر
- متعدد
- عين
- حاجة
- سلبي
- سلبا
- جديد
- البرمجة اللغوية العصبية
- عادي
- جدير بالملاحظة
- عدد
- أرقام
- نمباي
- تحصل
- تم الحصول عليها
- of
- عرض
- on
- ONE
- الفرصة
- معارض
- مزيد من الخيارات
- منظمة
- أخرى
- وإلا
- في الخارج
- معلقة
- الكلي
- المعلمة
- شغف
- أنماط
- نسبة مئوية
- أداء
- فيزياء
- قطعة
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- من فضلك
- نقاط
- نقاط البيع
- إيجابي
- محتمل
- يحتمل
- عملية
- دقة
- تنبأ
- وتوقع
- تنبؤات
- تتوقع
- العروض
- قدم
- المشكلة
- مشاكل
- عملية المعالجة
- العمليات
- معالجة
- إنتاج
- منتج
- الإنتــاج
- برمجة وتطوير
- مشروع ناجح
- دليل
- دليل على المفهوم
- المقترح
- تزود
- المقدمة
- ويوفر
- توفير
- pytorch
- رفع
- نطاق
- بدلا
- العالم الحقيقي
- إعادة التوازن
- خلاصة
- الاعتراف
- تخفيض
- عقار مخفض
- تقليص
- يشير
- العلاقات
- مدى صلة
- ذات الصلة
- التمثيل
- ممثلة
- طلب
- بحث
- نتيجة
- مما أدى
- النتائج
- عائد أعلى
- عائدات
- مراجعة
- ROSE
- تشغيل
- s
- نفسه
- سيناريوهات
- بحث علمي
- الثاني
- تسعى
- مختار
- SELF
- عاطفة
- مستقل
- الخدمة
- طقم
- باكجات
- الشكل
- أظهرت
- يظهر
- أهمية
- هام
- بشكل ملحوظ
- مماثل
- الاشارات
- معا
- عزباء
- مقاس
- مهارات
- So
- تطبيقات الكمبيوتر
- مهندس البرمجيات
- الصلبة
- حل
- الحلول
- حل
- بعض
- تتخصص
- محدد
- المسرح
- مراحل
- معيار
- إحصائيات
- خطوة
- صريح
- هذه
- مناسب
- التعلم تحت إشراف
- الدعم
- دعم
- جدول
- TAG
- أخذ
- المستهدفة
- مهمة
- المهام
- فريق
- تقنيات
- تجربه بالعربي
- الاختبار
- تصنيف النص
- أن
- •
- المعلومات
- من مشاركة
- منهم
- أنفسهم
- تشبه
- عتبة
- عبر
- الوقت
- مرات
- إلى
- تيشرت
- شعلة
- الإجمالي
- تواصل
- نحو
- مسار
- تقليدي
- قطار
- قادة الإيمان
- تحول
- تحول
- تحول
- تحويل
- يعامل
- صحيح
- عادة
- الشكوك
- فهم
- فريد من نوعه
- us
- تستخدم
- حالة الاستخدام
- استخدام
- التحقق من صحة
- القيمة
- القيم
- مختلف
- قابل للحياة
- رؤيتنا
- vs
- وزن
- West Side
- التي
- في حين
- ويكيبيديا
- سوف
- مع
- في غضون
- بدون
- عمل
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت
- صفر