أمازون ساجميكر ستوديو يمكن أن تساعدك في إنشاء نماذجك وتدريبها وتصحيحها ونشرها ومراقبتها وإدارة سير عمل التعلم الآلي (ML). خطوط أنابيب Amazon SageMaker تمكنك من بناء ملف منصة MLOps آمنة وقابلة للتطوير ومرنة داخل الاستوديو.
في هذا المنشور ، نشرح كيفية تشغيل مهام معالجة PySpark داخل خط أنابيب. يمكّن هذا أي شخص يرغب في تدريب نموذج باستخدام خطوط الأنابيب على معالجة بيانات التدريب أو بيانات استدلال ما بعد العملية أو تقييم النماذج باستخدام PySpark. هذه الإمكانية مهمة بشكل خاص عندما تحتاج إلى معالجة بيانات واسعة النطاق. بالإضافة إلى ذلك ، نعرض كيفية تحسين خطوات PySpark باستخدام التكوينات وسجلات Spark UI.
خطوط الأنابيب هي الأمازون SageMaker أداة لبناء وإدارة خطوط أنابيب ML من طرف إلى طرف. إنها خدمة مُدارة بالكامل عند الطلب ، ومتكاملة مع SageMaker وخدمات AWS الأخرى ، وبالتالي تنشئ وتدير الموارد من أجلك. يضمن ذلك توفير المثيلات واستخدامها فقط عند تشغيل خطوط الأنابيب. علاوة على ذلك ، يتم دعم خطوط الأنابيب من قبل SageMaker بيثون SDK، مما يتيح لك تتبع ملفات نسب البيانات و إعادة استخدام الخطوات عن طريق تخزينها مؤقتًا لتسهيل وقت التطوير وتكلفته. يمكن استخدام خط أنابيب SageMaker خطوات المعالجة لمعالجة البيانات أو إجراء تقييم النموذج.
عند معالجة البيانات واسعة النطاق ، غالبًا ما يستخدمها علماء البيانات ومهندسو تعلم الآلة بايسبارك، واجهة أباتشي سبارك في بايثون. يوفر SageMaker صور Docker تم إنشاؤها مسبقًا والتي تتضمن PySpark والتبعيات الأخرى اللازمة لتشغيل مهام معالجة البيانات الموزعة ، بما في ذلك تحويلات البيانات وهندسة الميزات باستخدام إطار عمل Spark. على الرغم من أن هذه الصور تسمح لك بالبدء بسرعة في استخدام PySpark في مهام المعالجة ، إلا أن معالجة البيانات على نطاق واسع تتطلب غالبًا تكوينات Spark محددة من أجل تحسين الحوسبة الموزعة للمجموعة التي أنشأتها SageMaker.
في مثالنا ، قمنا بإنشاء خط أنابيب SageMaker يدير خطوة معالجة واحدة. لمزيد من المعلومات حول الخطوات الأخرى التي يمكنك إضافتها إلى خط الأنابيب ، راجع خطوات خط الأنابيب.
مكتبة معالجة SageMaker
يمكن تشغيل SageMaker Processing مع ملفات الأطر (على سبيل المثال ، SKlearnProcessor أو PySparkProcessor أو Hugging Face). مستقل عن الإطار المستخدم ، لكل منهما الخطوة المعالجة يتطلب ما يلي:
- اسم الخطوة - الاسم الذي سيتم استخدامه لخطوة خط أنابيب SageMaker
- حجج الخطوة - الحجج الخاصة بك
ProcessingStep
بالإضافة إلى ذلك ، يمكنك تقديم ما يلي:
- تكوين ذاكرة التخزين المؤقت للخطوة الخاصة بك لتجنب عمليات التشغيل غير الضرورية لخطوتك في خط أنابيب SageMaker
- قائمة بأسماء الخطوات ، أو مثيلات الخطوة ، أو أمثلة مجموعة الخطوات التي يحتوي عليها
ProcessingStepيعتمد على - اسم العرض الخاص بـ
ProcessingStep - وصف لل
ProcessingStep - ملفات الخصائص
- نُهج إعادة المحاولة
يتم تسليم الحجج إلى ProcessingStep. يمكنك استخدام ال sagemaker.spark.PySparkProcessor or sagemaker.spark.SparkJar المعالج فئة لتشغيل تطبيق Spark الخاص بك داخل مهمة المعالجة.
يأتي كل معالج باحتياجاته الخاصة ، اعتمادًا على إطار العمل. يتم توضيح هذا بشكل أفضل باستخدام PySparkProcessor، حيث يمكنك تمرير معلومات إضافية لتحسين ProcessingStep كذلك ، على سبيل المثال عبر configuration المعلمة عند تشغيل عملك.
قم بتشغيل وظائف SageMaker Processing في بيئة آمنة
انها أفضل الممارسات لإنشاء Amazon VPC خاص وتهيئته بحيث لا يمكن الوصول إلى وظائفك عبر الإنترنت العام. تتيح لك مهام معالجة SageMaker تحديد الشبكات الفرعية ومجموعات الأمان الخاصة في VPC بالإضافة إلى تمكين عزل الشبكة وتشفير حركة المرور بين الحاويات باستخدام NetworkConfig.VpcConfig طلب معلمة من CreateProcessingJob API. نقدم أمثلة على هذا التكوين باستخدام سيج ميكر SDK في القسم التالي.
PySpark ProcessingStep داخل خطوط أنابيب SageMaker
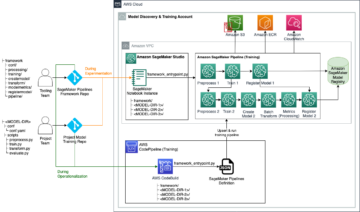
في هذا المثال ، نفترض أنك قمت بنشر Studio في بيئة آمنة متاحة بالفعل ، بما في ذلك VPC ونقاط نهاية VPC ومجموعات الأمان ، إدارة الهوية والوصول AWS (IAM) الأدوار ، و خدمة إدارة مفتاح AWS (AWS KMS). نفترض أيضًا أن لديك مجموعتين: واحدة للقطع الأثرية مثل التعليمات البرمجية والسجلات ، والأخرى لبياناتك. ال basic_infra.yaml يقدم ملف مثال تكوين سحابة AWS رمز لتوفير البنية التحتية اللازمة مسبقًا. يتوفر أيضًا مثال التعليمات البرمجية ودليل النشر على GitHub جيثب:.
على سبيل المثال ، قمنا بإعداد خط أنابيب يحتوي على واحد ProcessingStep الذي نقرأ فيه ونكتبه ببساطة مجموعة بيانات أذن البحر باستخدام سبارك. توضح لك نماذج التعليمات البرمجية كيفية إعداد وتكوين ملف ProcessingStep.
نحدد معلمات لخط الأنابيب (الاسم ، والدور ، والمجموعات ، وما إلى ذلك) والإعدادات الخاصة بالخطوة (نوع المثيل وعددها ، وإصدار إطار العمل ، وما إلى ذلك). في هذا المثال ، نستخدم إعدادًا آمنًا ونعرّف أيضًا الشبكات الفرعية ومجموعات الأمان وتشفير حركة المرور بين الحاويات. في هذا المثال ، تحتاج إلى دور تنفيذ خط أنابيب مع وصول كامل لـ SageMaker و VPC. انظر الكود التالي:
{ "pipeline_name": "ProcessingPipeline", "trial": "test-blog-post", "pipeline_role": "arn:aws:iam::<ACCOUNT_NUMBER>:role/<PIPELINE_EXECUTION_ROLE_NAME>", "network_subnet_ids": [ "subnet-<SUBNET_ID>", "subnet-<SUBNET_ID>" ], "network_security_group_ids": [ "sg-<SG_ID>" ], "pyspark_process_volume_kms": "arn:aws:kms:<REGION_NAME>:<ACCOUNT_NUMBER>:key/<KMS_KEY_ID>", "pyspark_process_output_kms": "arn:aws:kms:<REGION_NAME>:<ACCOUNT_NUMBER>:key/<KMS_KEY_ID>", "pyspark_helper_code": "s3://<INFRA_S3_BUCKET>/src/helper/data_utils.py", "spark_config_file": "s3://<INFRA_S3_BUCKET>/src/spark_configuration/configuration.json", "pyspark_process_code": "s3://<INFRA_S3_BUCKET>/src/processing/process_pyspark.py", "process_spark_ui_log_output": "s3://<DATA_S3_BUCKET>/spark_ui_logs/{}", "pyspark_framework_version": "2.4", "pyspark_process_name": "pyspark-processing", "pyspark_process_data_input": "s3a://<DATA_S3_BUCKET>/data_input/abalone_data.csv", "pyspark_process_data_output": "s3a://<DATA_S3_BUCKET>/pyspark/data_output", "pyspark_process_instance_type": "ml.m5.4xlarge", "pyspark_process_instance_count": 6, "tags": { "Project": "tag-for-project", "Owner": "tag-for-owner" }
}
للتوضيح ، يقوم مثال الكود التالي بتشغيل برنامج نصي PySpark على SageMaker Processing داخل خط أنابيب باستخدام PySparkProcessor:
# import code requirements
# standard libraries import
import logging
import json # sagemaker model import
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.pipeline_experiment_config import PipelineExperimentConfig
from sagemaker.workflow.steps import CacheConfig
from sagemaker.processing import ProcessingInput
from sagemaker.workflow.steps import ProcessingStep
from sagemaker.workflow.pipeline_context import PipelineSession
from sagemaker.spark.processing import PySparkProcessor from helpers.infra.networking.networking import get_network_configuration
from helpers.infra.tags.tags import get_tags_input
from helpers.pipeline_utils import get_pipeline_config def create_pipeline(pipeline_params, logger): """ Args: pipeline_params (ml_pipeline.params.pipeline_params.py.Params): pipeline parameters logger (logger): logger Returns: () """ # Create SageMaker Session sagemaker_session = PipelineSession() # Get Tags tags_input = get_tags_input(pipeline_params["tags"]) # get network configuration network_config = get_network_configuration( subnets=pipeline_params["network_subnet_ids"], security_group_ids=pipeline_params["network_security_group_ids"] ) # Get Pipeline Configurations pipeline_config = get_pipeline_config(pipeline_params) # setting processing cache obj logger.info("Setting " + pipeline_params["pyspark_process_name"] + " cache configuration 3 to 30 days") cache_config = CacheConfig(enable_caching=True, expire_after="p30d") # Create PySpark Processing Step logger.info("Creating " + pipeline_params["pyspark_process_name"] + " processor") # setting up spark processor processing_pyspark_processor = PySparkProcessor( base_job_name=pipeline_params["pyspark_process_name"], framework_version=pipeline_params["pyspark_framework_version"], role=pipeline_params["pipeline_role"], instance_count=pipeline_params["pyspark_process_instance_count"], instance_type=pipeline_params["pyspark_process_instance_type"], volume_kms_key=pipeline_params["pyspark_process_volume_kms"], output_kms_key=pipeline_params["pyspark_process_output_kms"], network_config=network_config, tags=tags_input, sagemaker_session=sagemaker_session ) # setting up arguments run_ags = processing_pyspark_processor.run( submit_app=pipeline_params["pyspark_process_code"], submit_py_files=[pipeline_params["pyspark_helper_code"]], arguments=[ # processing input arguments. To add new arguments to this list you need to provide two entrances: # 1st is the argument name preceded by "--" and the 2nd is the argument value # setting up processing arguments "--input_table", pipeline_params["pyspark_process_data_input"], "--output_table", pipeline_params["pyspark_process_data_output"] ], spark_event_logs_s3_uri=pipeline_params["process_spark_ui_log_output"].format(pipeline_params["trial"]), inputs = [ ProcessingInput( source=pipeline_params["spark_config_file"], destination="/opt/ml/processing/input/conf", s3_data_type="S3Prefix", s3_input_mode="File", s3_data_distribution_type="FullyReplicated", s3_compression_type="None" ) ], ) # create step pyspark_processing_step = ProcessingStep( name=pipeline_params["pyspark_process_name"], step_args=run_ags, cache_config=cache_config, ) # Create Pipeline pipeline = Pipeline( name=pipeline_params["pipeline_name"], steps=[ pyspark_processing_step ], pipeline_experiment_config=PipelineExperimentConfig( pipeline_params["pipeline_name"], pipeline_config["trial"] ), sagemaker_session=sagemaker_session ) pipeline.upsert( role_arn=pipeline_params["pipeline_role"], description="Example pipeline", tags=tags_input ) return pipeline def main(): # set up logging logger = logging.getLogger(__name__) logger.setLevel(logging.INFO) logger.info("Get Pipeline Parameter") with open("ml_pipeline/params/pipeline_params.json", "r") as f: pipeline_params = json.load(f) print(pipeline_params) logger.info("Create Pipeline") pipeline = create_pipeline(pipeline_params, logger=logger) logger.info("Execute Pipeline") execution = pipeline.start() return execution if __name__ == "__main__": main()
كما هو موضح في الكود السابق ، نقوم بالكتابة فوق تكوينات Spark الافتراضية من خلال توفير configuration.json ك ProcessingInput. نحن نستخدم configuration.json الملف الذي تم حفظه بتنسيق خدمة تخزين أمازون البسيطة (Amazon S3) بالإعدادات التالية:
[ { "Classification":"spark-defaults", "Properties":{ "spark.executor.memory":"10g", "spark.executor.memoryOverhead":"5g", "spark.driver.memory":"10g", "spark.driver.memoryOverhead":"10g", "spark.driver.maxResultSize":"10g", "spark.executor.cores":5, "spark.executor.instances":5, "spark.yarn.maxAppAttempts":1 "spark.hadoop.fs.s3a.endpoint":"s3.<region>.amazonaws.com", "spark.sql.parquet.fs.optimized.comitter.optimization-enabled":true } }
]
يمكننا تحديث تكوين Spark الافتراضي إما عن طريق تمرير الملف كملف ProcessingInput أو باستخدام وسيطة التكوين عند تشغيل run() وظيفة.
يعتمد تكوين Spark على خيارات أخرى ، مثل نوع المثيل وعدد المثيل المختار لوظيفة المعالجة. الاعتبار الأول هو عدد المثيلات ، ونواة vCPU التي تحتوي عليها كل من هذه الحالات ، وذاكرة المثيل. يمكنك استخدام شرارة UIs or مقاييس مثيل CloudWatch والسجلات لمعايرة هذه القيم عبر تكرارات تشغيل متعددة.
بالإضافة إلى ذلك ، يمكن تحسين إعدادات المنفذ والسائق بشكل أكبر. للحصول على مثال لكيفية حساب هذه ، ارجع إلى أفضل الممارسات لإدارة الذاكرة بنجاح لتطبيقات Apache Spark على Amazon EMR.
بعد ذلك ، بالنسبة لإعدادات برنامج التشغيل والمنفذ ، نوصي بالتحقق من إعدادات المشترك لتحسين الأداء عند الكتابة إلى Amazon S3. في حالتنا ، نكتب ملفات باركيه إلى Amazon S3 ونضبط "spark.sql.parquet.fs.optimized.comitter.optimization-enabled"إلى الحقيقة.
إذا لزم الأمر للاتصال بـ Amazon S3 ، فإن نقطة نهاية إقليمية "spark.hadoop.fs.s3a.endpointيمكن تحديد "ضمن ملف التكوينات.
في مثال خط الأنابيب هذا ، نص PySpark النصي spark_process.py (كما هو موضح في الكود التالي) يقوم بتحميل ملف CSV من Amazon S3 في إطار بيانات Spark ، ويحفظ البيانات كـ Parquet مرة أخرى إلى Amazon S3.
لاحظ أن تكوين المثال الخاص بنا لا يتناسب مع عبء العمل لأن قراءة مجموعة بيانات أذن البحر وكتابتها يمكن إجراؤها على الإعدادات الافتراضية في مثيل واحد. يجب تحديد التكوينات التي ذكرناها بناءً على احتياجاتك الخاصة.
# import requirements
import argparse
import logging
import sys
import os
import pandas as pd # spark imports
from pyspark.sql import SparkSession
from pyspark.sql.functions import (udf, col)
from pyspark.sql.types import StringType, StructField, StructType, FloatType from data_utils import( spark_read_parquet, Unbuffered
) sys.stdout = Unbuffered(sys.stdout) # Define custom handler
logger = logging.getLogger(__name__)
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(logging.Formatter("%(asctime)s %(message)s"))
logger.addHandler(handler)
logger.setLevel(logging.INFO) def main(data_path): spark = SparkSession.builder.appName("PySparkJob").getOrCreate() spark.sparkContext.setLogLevel("ERROR") schema = StructType( [ StructField("sex", StringType(), True), StructField("length", FloatType(), True), StructField("diameter", FloatType(), True), StructField("height", FloatType(), True), StructField("whole_weight", FloatType(), True), StructField("shucked_weight", FloatType(), True), StructField("viscera_weight", FloatType(), True), StructField("rings", FloatType(), True), ] ) df = spark.read.csv(data_path, header=False, schema=schema) return df.select("sex", "length", "diameter", "rings") if __name__ == "__main__": logger.info(f"===============================================================") logger.info(f"================= Starting pyspark-processing =================") parser = argparse.ArgumentParser(description="app inputs") parser.add_argument("--input_table", type=str, help="path to the channel data") parser.add_argument("--output_table", type=str, help="path to the output data") args = parser.parse_args() df = main(args.input_table) logger.info("Writing transformed data") df.write.csv(os.path.join(args.output_table, "transformed.csv"), header=True, mode="overwrite") # save data df.coalesce(10).write.mode("overwrite").parquet(args.output_table) logger.info(f"================== Ending pyspark-processing ==================") logger.info(f"===============================================================")
للتعمق في تحسين وظائف معالجة Spark ، يمكنك استخدام سجلات CloudWatch بالإضافة إلى Spark UI. يمكنك إنشاء Spark UI من خلال تشغيل مهمة معالجة على مثيل دفتر ملاحظات SageMaker. يمكنك عرض ملف Spark UI لوظائف المعالجة التي تعمل ضمن خط أنابيب by تشغيل خادم التاريخ داخل مثيل دفتر ملاحظات SageMaker إذا تم حفظ سجلات Spark UI في نفس موقع Amazon S3.
تنظيف
إذا اتبعت البرنامج التعليمي ، فمن الممارسات الجيدة حذف الموارد التي لم تعد مستخدمة لإيقاف تكبد الرسوم. تاكد من حذف مكدس CloudFormation التي استخدمتها لإنشاء مواردك. سيؤدي هذا إلى حذف المكدس الذي تم إنشاؤه بالإضافة إلى الموارد التي أنشأها.
وفي الختام
في هذا المنشور ، أوضحنا كيفية تشغيل وظيفة معالجة SageMaker آمنة باستخدام PySpark داخل خطوط أنابيب SageMaker. لقد أوضحنا أيضًا كيفية تحسين PySpark باستخدام تكوينات Spark وإعداد مهمة المعالجة الخاصة بك للتشغيل في تكوين شبكة آمنة.
كخطوة تالية ، استكشف كيفية أتمتة دورة حياة النموذج بالكامل وكيف قام العملاء ببناء منصات MLOps آمنة وقابلة للتطوير باستخدام خدمات SageMaker.
حول المؤلف
 مارين سويلمان هو عالم بيانات في الخدمات المهنية AWS. تعمل مع العملاء عبر الصناعات لتكشف عن قوة الذكاء الاصطناعي / تعلم الآلة لتحقيق نتائج أعمالهم. تعمل Maren مع AWS منذ نوفمبر 2019. في أوقات فراغها ، تستمتع بممارسة رياضة الكيك بوكسينغ والمشي لمسافات طويلة للوصول إلى مناظر رائعة وليالي ألعاب الطاولة.
مارين سويلمان هو عالم بيانات في الخدمات المهنية AWS. تعمل مع العملاء عبر الصناعات لتكشف عن قوة الذكاء الاصطناعي / تعلم الآلة لتحقيق نتائج أعمالهم. تعمل Maren مع AWS منذ نوفمبر 2019. في أوقات فراغها ، تستمتع بممارسة رياضة الكيك بوكسينغ والمشي لمسافات طويلة للوصول إلى مناظر رائعة وليالي ألعاب الطاولة.
 ميرا لاديرا تانك هو أخصائي ML في AWS. تتمتع بخلفية في علم البيانات ، ولديها 9 سنوات من الخبرة في تصميم وبناء تطبيقات ML مع العملاء عبر الصناعات. بصفتها رائدة فنية ، فهي تساعد العملاء على تسريع تحقيقهم لقيمة الأعمال من خلال التقنيات الناشئة والحلول المبتكرة. في أوقات فراغها ، تستمتع ميرا بالسفر وقضاء الوقت مع أسرتها في مكان دافئ.
ميرا لاديرا تانك هو أخصائي ML في AWS. تتمتع بخلفية في علم البيانات ، ولديها 9 سنوات من الخبرة في تصميم وبناء تطبيقات ML مع العملاء عبر الصناعات. بصفتها رائدة فنية ، فهي تساعد العملاء على تسريع تحقيقهم لقيمة الأعمال من خلال التقنيات الناشئة والحلول المبتكرة. في أوقات فراغها ، تستمتع ميرا بالسفر وقضاء الوقت مع أسرتها في مكان دافئ.
 بولين تينج هو عالم بيانات في الخدمات المهنية AWS فريق. إنها تدعم العملاء في تحقيق وتسريع نتائج أعمالهم من خلال تطوير حلول الذكاء الاصطناعي / التعلم الآلي. في أوقات فراغها ، تستمتع بولين بالسفر وركوب الأمواج وتجربة أماكن الحلوى الجديدة.
بولين تينج هو عالم بيانات في الخدمات المهنية AWS فريق. إنها تدعم العملاء في تحقيق وتسريع نتائج أعمالهم من خلال تطوير حلول الذكاء الاصطناعي / التعلم الآلي. في أوقات فراغها ، تستمتع بولين بالسفر وركوب الأمواج وتجربة أماكن الحلوى الجديدة.
 دونالد فوسو هو مهندس بيانات Sr في الخدمات المهنية AWS فريق يعمل في الغالب مع Global Finance Service. يتعامل مع العملاء لإنشاء حلول مبتكرة تعالج مشاكل عمل العملاء وتسريع اعتماد خدمات AWS. في أوقات فراغه ، يستمتع دونالد بالقراءة والجري والسفر.
دونالد فوسو هو مهندس بيانات Sr في الخدمات المهنية AWS فريق يعمل في الغالب مع Global Finance Service. يتعامل مع العملاء لإنشاء حلول مبتكرة تعالج مشاكل عمل العملاء وتسريع اعتماد خدمات AWS. في أوقات فراغه ، يستمتع دونالد بالقراءة والجري والسفر.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/run-secure-processing-jobs-using-pyspark-in-amazon-sagemaker-pipelines/
- :يكون
- $ UP
- 1
- 10
- 100
- 2019
- 5G
- 9
- a
- من نحن
- تسريع
- تسريع
- الوصول
- يمكن الوصول
- التأهيل
- إنجاز
- تحقيق
- في
- إضافة
- إضافي
- معلومات اضافية
- العنوان
- تبني
- AI / ML
- سابقا
- بالرغم ان
- أمازون
- الأمازون SageMaker
- خطوط أنابيب Amazon SageMaker
- و
- أي شخص
- أباتشي
- أباتشي سبارك
- API
- التطبيق
- تطبيق
- التطبيقات
- هي
- حجة
- الحجج
- AS
- At
- أتمتة
- متاح
- تجنب
- AWS
- الى الخلف
- خلفية
- على أساس
- BE
- لان
- أفضل
- مجلس
- نساعدك في بناء
- باني
- ابني
- بنيت
- الأعمال
- by
- مخبأ
- حساب
- CAN
- حقيبة
- قناة
- اسعارنا محددة من قبل وزارة العمل
- اختيار
- فئة
- تصنيف
- كتلة
- الكود
- مجموعة شتاء XNUMX
- COM
- الحوسبة
- الاعداد
- تكوينات
- صلة
- نظر
- التكلفة
- استطاع
- خلق
- خلق
- يخلق
- خلق
- على
- زبون
- العملاء
- البيانات
- معالجة المعلومات
- علم البيانات
- عالم البيانات
- أيام
- الترتيب
- تعريف
- شرح
- تظاهر
- تابع
- اعتمادا
- يعتمد
- نشر
- نشر
- نشر
- وصف
- تطوير
- التطوير التجاري
- العرض
- وزعت
- الحوسبة الموزعة
- معالجة البيانات الموزعة
- عامل في حوض السفن
- سائق
- كل
- إما
- الناشئة
- التقنيات الناشئة
- تمكين
- تمكن
- التشفير
- النهائي إلى نهاية
- نقطة النهاية
- الهندسة
- المهندسين
- يضمن
- كامل
- البيئة
- خطأ
- خاصة
- الأثير (ETH)
- تقييم
- تقييم
- حتى
- مثال
- أمثلة
- تنفيذ
- الخبره في مجال الغطس
- شرح
- اكتشف
- الوجه
- للعائلات
- الميزات
- قم بتقديم
- ملفات
- تمويل
- الاسم الأول
- مرن
- يتبع
- متابعيك
- في حالة
- FRAME
- الإطار
- مجانًا
- تبدأ من
- FS
- بالإضافة إلى
- تماما
- وظيفة
- وظائف
- إضافي
- علاوة على ذلك
- لعبة
- دولار فقط واحصل على خصم XNUMX% على جميع
- العالمية
- خير
- عظيم
- مجموعات
- توجيه
- Hadoop
- يملك
- ارتفاع
- مساعدة
- يساعد
- المشي لمسافات طويلة
- تاريخ
- كيفية
- كيفية
- HTML
- HTTP
- HTTPS
- IAM
- ICS
- هوية
- صور
- استيراد
- واردات
- تحسن
- in
- تتضمن
- بما فيه
- مستقل
- الصناعات
- info
- معلومات
- البنية التحتية
- مبتكرة
- إدخال
- مثل
- المتكاملة
- السطح البيني
- Internet
- عزل
- IT
- التكرارات
- انها
- وظيفة
- المشــاريــع
- JPG
- جسون
- القفل
- مفاتيح
- على نطاق واسع
- قيادة
- تعلم
- الطول
- السماح
- المكتبات
- دورة حياة
- مثل
- قائمة
- الأحمال
- موقع
- يعد
- آلة
- آلة التعلم
- جعل
- إدارة
- تمكن
- إدارة
- يدير
- إدارة
- مكبر الصوت : يدعم، مع دعم ميكروفون مدمج لمنع الضوضاء
- المذكورة
- الرسالة
- ML
- MLOps
- نموذج
- عارضات ازياء
- مراقبة
- الأكثر من ذلك
- متعدد
- الاسم
- أسماء
- ضروري
- حاجة
- بحاجة
- إحتياجات
- شبكة
- الشبكات
- جديد
- التالي
- مفكرة
- نوفمبر
- عدد
- of
- on
- على الطلب
- ONE
- الأمثل
- الأمثل
- تحسين
- مزيد من الخيارات
- طلب
- OS
- أخرى
- نتيجة
- الناتج
- الخاصة
- كاتوا ديلز
- الباندا
- المعلمة
- المعلمات
- pass
- مرور
- مسار
- نفذ
- أداء
- خط أنابيب
- وجهات
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- منشور
- قوة
- ممارسة
- الممارسات
- خاص
- مشاكل
- عملية المعالجة
- معالجة
- المعالج
- محترف
- تنفيذ المشاريع
- HAS
- تزود
- ويوفر
- توفير
- تقديم
- جمهور
- بايثون
- بسرعة
- عرض
- نادي القراءة
- نوصي
- إقليمي
- ذات الصلة
- طلب
- المتطلبات الأساسية
- يتطلب
- الموارد
- عائد أعلى
- عائدات
- النوع
- الأدوار
- يجري
- تشغيل
- sagemaker
- خطوط الأنابيب SageMaker
- نفسه
- حفظ
- تحجيم
- علوم
- عالم
- العلماء
- القسم
- تأمين
- أمن
- الخدمة
- خدمات
- الجلسة
- طقم
- ضبط
- إعدادات
- الإعداد
- الجنس
- ينبغي
- إظهار
- عرض
- أظهرت
- الاشارات
- ببساطة
- منذ
- عزباء
- So
- الحلول
- شرارة
- متخصص
- محدد
- محدد
- الإنفاق
- SQL
- كومة
- معيار
- بداية
- ابتداء
- خطوة
- خطوات
- قلة النوم
- تخزين
- ستوديو
- الشبكات الفرعية
- بنجاح
- مدعومة
- الدعم
- فريق
- تقني
- التكنولوجيا
- أن
- •
- من مشاركة
- منهم
- وبالتالي
- تشبه
- عبر
- الوقت
- إلى
- أداة
- مسار
- حركة المرور
- قطار
- قادة الإيمان
- التحولات
- تحول
- السفر
- محاكمة
- صحيح
- البرنامج التعليمي
- أنواع
- ui
- إزاحة الستار
- تحديث
- تستخدم
- قيمنا
- القيم
- الإصدار
- بواسطة
- المزيد
- الرؤى
- دافئ
- حسن
- ابحث عن
- التي
- سوف
- مع
- في غضون
- سير العمل
- سير العمل
- عامل
- أعمال
- اكتب
- جاري الكتابة
- يامل
- سنوات
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت