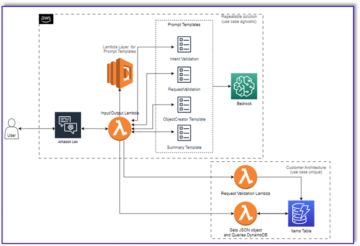
في رؤية الكمبيوتر ، التقسيم الدلالي هو مهمة تصنيف كل بكسل في صورة مع فئة من مجموعة معروفة من الملصقات بحيث تشترك وحدات البكسل التي لها نفس التسمية في خصائص معينة. يقوم بإنشاء قناع تجزئة لصور الإدخال. على سبيل المثال ، تُظهر الصور التالية قناع تجزئة لـ cat ضع الكلمة المناسبة.
 |
 |
في نوفمبر 2018، الأمازون SageMaker عن إطلاق خوارزمية التجزئة الدلالية SageMaker. باستخدام هذه الخوارزمية ، يمكنك تدريب نماذجك باستخدام مجموعة بيانات عامة أو مجموعة بيانات خاصة بك. تتضمن مجموعات بيانات تجزئة الصور الشائعة مجموعة بيانات الكائنات المشتركة في السياق (COCO) وفئات الكائنات المرئية PASCAL (PASCAL VOC) ، ولكن فئات تسمياتها محدودة وقد ترغب في تدريب نموذج على الكائنات المستهدفة التي لم يتم تضمينها في مجموعات البيانات العامة. في هذه الحالة ، يمكنك استخدام الحقيقة الأمازون SageMaker الأرض لتسمية مجموعة البيانات الخاصة بك.
في هذا المنشور ، أوضح الحلول التالية:
- استخدام Ground Truth لتسمية مجموعة بيانات التجزئة الدلالية
- تحويل النتائج من Ground Truth إلى تنسيق الإدخال المطلوب لخوارزمية التجزئة الدلالية المضمنة في SageMaker
- استخدام خوارزمية التجزئة الدلالية لتدريب نموذج وإجراء الاستدلال
تصنيف البيانات الدلالية التجزئة
لبناء نموذج تعلم آلي للتجزئة الدلالية ، نحتاج إلى تسمية مجموعة بيانات على مستوى البكسل. تمنحك Ground Truth خيار استخدام التعليقات التوضيحية البشرية من خلال الأمازون ميكانيكي تركأو البائعين الخارجيين أو القوى العاملة الخاصة بك. لمعرفة المزيد عن القوى العاملة ، يرجى الرجوع إلى إنشاء وإدارة القوى العاملة. إذا كنت لا ترغب في إدارة قوة العمل المصنفة بنفسك ، أمازون سيج ميكر جراوند تروث بلس يعد خيارًا رائعًا آخر كخدمة جديدة لوضع العلامات على البيانات بنظام تسليم المفتاح تتيح لك إنشاء مجموعات بيانات تدريبية عالية الجودة بسرعة وتقليل التكاليف بنسبة تصل إلى 40٪. بالنسبة إلى هذا المنشور ، أوضح لك كيفية تسمية مجموعة البيانات يدويًا باستخدام ميزة الجزء التلقائي لـ Ground Truth وتسمية التعهيد الجماعي مع القوى العاملة الميكانيكية التركية.
وضع الملصقات اليدوية مع Ground Truth
في ديسمبر 2019 ، أضافت Ground Truth ميزة قطاع تلقائي إلى واجهة مستخدم تسمية التجزئة الدلالية لزيادة إنتاجية الملصقات وتحسين الدقة. لمزيد من المعلومات ، يرجى الرجوع إلى تجزئة الكائنات تلقائيًا عند تنفيذ تسمية التجزئة الدلالية باستخدام Amazon SageMaker Ground Truth. باستخدام هذه الميزة الجديدة ، يمكنك تسريع عملية وضع العلامات على مهام التجزئة. بدلاً من رسم مضلع ملائم بإحكام أو استخدام أداة الفرشاة لالتقاط كائن في صورة ما ، فأنت ترسم أربع نقاط فقط: في أقصى نقطة من الكائن ، وفي أقصى أسفلها ، وفي أقصى اليسار ، وفي أقصى اليمين. تأخذ Ground Truth هذه النقاط الأربع كمدخلات وتستخدم خوارزمية Deep Extreme Cut (DEXTR) لإنتاج قناع مناسب بإحكام حول الكائن. للحصول على برنامج تعليمي باستخدام Ground Truth لتقسيم الصور إلى شرائح ، ارجع إلى تجزئة الصورة الدلالية. فيما يلي مثال على كيفية قيام أداة التجزئة التلقائية بإنشاء قناع تجزئة تلقائيًا بعد اختيار النقاط الأربع القصوى لكائن.


التعهيد الجماعي مع قوة عاملة ميكانيكية تركية
إذا كان لديك مجموعة بيانات كبيرة ولا ترغب في تسمية مئات أو آلاف الصور يدويًا بنفسك ، فيمكنك استخدام Mechanical Turk ، الذي يوفر قوة عاملة بشرية قابلة للتطوير عند الطلب لإكمال الوظائف التي يمكن للبشر القيام بها بشكل أفضل من أجهزة الكمبيوتر. يضفي برنامج Mechanical Turk طابعًا رسميًا على عروض العمل لآلاف العمال المستعدين للقيام بأعمال مجزأة في الوقت الذي يناسبهم. يقوم البرنامج أيضًا باسترداد العمل المنجز ويجمعه نيابة عنك ، كمقدم الطلب ، الذي يدفع للعمال مقابل العمل المُرضي (فقط). لتبدأ مع MECHANICAL TUR ، ارجع إلى مقدمة إلى Amazon Mechanical Turk.
إنشاء وظيفة التسمية
فيما يلي مثال على وظيفة وضع العلامات الميكانيكية التركية لمجموعة بيانات السلاحف البحرية. مجموعة بيانات السلاحف البحرية من مسابقة Kaggle كشف وجه السلاحف البحرية، واخترت 300 صورة لمجموعة البيانات لأغراض توضيحية. لا تعتبر السلاحف البحرية فئة شائعة في مجموعات البيانات العامة ، لذا يمكن أن تمثل موقفًا يتطلب تصنيف مجموعة بيانات ضخمة.
- في وحدة تحكم SageMaker ، اختر وضع العلامات على الوظائف في جزء التنقل.
- اختار إنشاء وظيفة وضع العلامات.
- أدخل اسمًا لعملك.
- في حالة إعداد بيانات الإدخال، حدد إعداد البيانات الآلي.
هذا يولد بيانا لبيانات الإدخال. - في حالة موقع S3 لمجموعات بيانات الإدخال، أدخل مسار مجموعة البيانات.

- في حالة فئة المهمة، اختر صورة.
- في حالة اختيار المهام، حدد التجزئة الدلالية.

- في حالة أنواع العمال، حدد الأمازون ميكانيكي ترك.
- قم بتكوين إعداداتك لمهلة المهمة ، ووقت انتهاء المهمة ، والسعر لكل مهمة.

- أضف تسمية (لهذه المشاركة ،
sea turtle) ، وتقديم إرشادات وضع العلامات. - اختار إنشاء.

بعد إعداد وظيفة وضع العلامات ، يمكنك التحقق من تقدم وضع العلامات على وحدة تحكم SageMaker. عندما يتم تمييزها على أنها مكتملة ، يمكنك اختيار الوظيفة للتحقق من النتائج واستخدامها للخطوات التالية.

تحويل مجموعة البيانات
بعد الحصول على الإخراج من Ground Truth ، يمكنك استخدام خوارزميات SageMaker المضمنة لتدريب نموذج على مجموعة البيانات هذه. أولاً ، تحتاج إلى إعداد مجموعة البيانات المصنفة كواجهة إدخال مطلوبة لخوارزمية التجزئة الدلالية SageMaker.
قنوات بيانات الإدخال المطلوبة
تتوقع التجزئة الدلالية لـ SageMaker أن يتم تخزين مجموعة بيانات التدريب الخاصة بك عليها خدمة تخزين أمازون البسيطة (أمازون S3). من المتوقع أن يتم تقديم مجموعة البيانات في Amazon S3 في قناتين ، واحدة لـ train واحدة لل validation، باستخدام أربعة أدلة ، اثنان للصور واثنان للتعليقات التوضيحية. من المتوقع أن تكون التعليقات التوضيحية عبارة عن صور PNG غير مضغوطة. قد تحتوي مجموعة البيانات أيضًا على خريطة تسمية تصف كيفية إنشاء تعيينات التعليقات التوضيحية. إذا لم يكن الأمر كذلك ، فإن الخوارزمية تستخدم الافتراضي. للاستدلال ، تقبل نقطة النهاية الصور ذات الامتداد image/jpeg نوع المحتوى. فيما يلي الهيكل المطلوب لقنوات البيانات:
تحتوي كل صورة بتنسيق JPG في أدلة القطار والتحقق من الصحة على صورة تسمية PNG مقابلة لها نفس الاسم في ملف train_annotation و validation_annotation الدلائل. يساعد اصطلاح التسمية هذا الخوارزمية على ربط تسمية بالصورة المقابلة لها أثناء التدريب. القطار، train_annotation، والتحقق ، و validation_annotation القنوات إلزامية. التعليقات التوضيحية هي صور PNG أحادية القناة. يعمل التنسيق طالما أن البيانات الوصفية (الأوضاع) في الصورة تساعد الخوارزمية على قراءة صور التعليقات التوضيحية في عدد صحيح بدون إشارة ذي قناة واحدة مكون من 8 بتات.
الإخراج من وظيفة وضع العلامات على حقيقة الأرض
تحتوي المخرجات الناتجة من وظيفة وضع العلامات على حقيقة الأرض على بنية المجلد التالية:
يتم حفظ أقنعة التجزئة بتنسيق s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. كل صورة تعليق توضيحي هي ملف .png مسمى على اسم فهرس الصورة المصدر والوقت الذي اكتمل فيه تسمية الصورة. على سبيل المثال ، فيما يلي الصورة المصدر (Image_1.jpg) وقناع التجزئة الخاص بها الذي تم إنشاؤه بواسطة قوة العمل الميكانيكية التركية (0_2022-02-10T17: 41: 04.724225.png). لاحظ أن فهرس القناع مختلف عن الرقم الموجود في اسم الصورة المصدر.
 |
 |
بيان الإخراج من وظيفة وضع العلامات موجود في /manifests/output/output.manifest ملف. إنه ملف JSON ، ويسجل كل سطر تعيينًا بين الصورة المصدر والتسمية والبيانات الوصفية الأخرى. يسجل سطر JSON التالي تعيينًا بين صورة المصدر المعروضة والتعليق التوضيحي الخاص بها:
تسمى الصورة المصدر Image_1.jpg ، واسم التعليق التوضيحي هو 0_2022-02-10T17: 41: 04.724225.png. لإعداد البيانات كتنسيقات قناة البيانات المطلوبة لخوارزمية التجزئة الدلالية SageMaker ، نحتاج إلى تغيير اسم التعليق التوضيحي بحيث يكون له نفس اسم صور JPG المصدر. ونحتاج أيضًا إلى تقسيم مجموعة البيانات إلى train و validation أدلة لصور المصدر والتعليقات التوضيحية.
قم بتحويل الإخراج من وظيفة وضع العلامات على حقيقة الأرض إلى تنسيق الإدخال المطلوب
لتحويل الإخراج ، أكمل الخطوات التالية:
- قم بتنزيل جميع الملفات من وظيفة وضع العلامات من Amazon S3 إلى دليل محلي:
- اقرأ ملف البيان وغيّر أسماء التعليق التوضيحي إلى نفس أسماء الصور المصدر:
- تقسيم القطار ومجموعات بيانات التحقق من الصحة:
- قم بعمل دليل بالتنسيق المطلوب لقنوات بيانات خوارزمية التجزئة الدلالية:
- انقل صور القطار والتحقق من الصحة وشروحها إلى الدلائل التي تم إنشاؤها.
- للصور استخدم الكود التالي:
- للتعليقات التوضيحية ، استخدم الكود التالي:
- قم بتحميل مجموعات بيانات القطار والتحقق من الصحة ومجموعات بيانات التعليقات التوضيحية الخاصة بها إلى Amazon S3:
تدريب نموذج SageMaker الدلالي
في هذا القسم ، نتصفح الخطوات لتدريب نموذج التجزئة الدلالية الخاص بك.
اتبع نموذج دفتر الملاحظات وقم بإعداد قنوات البيانات
يمكنك اتباع التعليمات الموجودة في خوارزمية التجزئة الدلالية متاحة الآن في Amazon SageMaker لتنفيذ خوارزمية التجزئة الدلالية لمجموعة البيانات المصنفة. هذه العينة مفكرة يُظهر مثالاً شاملاً يقدم الخوارزمية. في دفتر الملاحظات ، تتعلم كيفية تدريب واستضافة نموذج تجزئة دلالي باستخدام الشبكة التلافيفية بالكامل (FCN) باستخدام الخوارزمية مجموعة بيانات باسكال المركبات العضوية المتطايرة للتدريب. نظرًا لأنني لا أخطط لتدريب نموذج من مجموعة بيانات Pascal VOC ، فقد تخطيت الخطوة 3 (إعداد البيانات) في هذا الكمبيوتر الدفتري. بدلا من ذلك ، أنا خلقت مباشرة train_channel, train_annotation_channe, validation_channelو validation_annotation_channel باستخدام مواقع S3 حيث قمت بتخزين الصور والتعليقات التوضيحية:
اضبط المعلمات الفوقية لمجموعة البيانات الخاصة بك في مقدر SageMaker
لقد اتبعت دفتر الملاحظات وأنشأت كائنًا مقدرًا لـ SageMaker (ss_estimator) لتدريب خوارزمية التجزئة الخاصة بي. هناك شيء واحد نحتاج إلى تخصيصه لمجموعة البيانات الجديدة ss_estimator.set_hyperparameters: نحن بحاجة إلى التغيير num_classes=21 إلى num_classes=2 (turtle و background) ، ولقد تغيرت أيضًا epochs=10 إلى epochs=30 لأن 10 لأغراض تجريبية فقط. ثم استخدمت مثيل p3.2xlarge لتدريب النموذج من خلال الإعداد instance_type="ml.p3.2xlarge". اكتمل التدريب في 8 دقائق. الأفضل MIoU تم تحقيق (متوسط التقاطع على الاتحاد) عند 0.846 في العصر 11 مع أ pix_acc (النسبة المئوية لوحدات البكسل في صورتك التي تم تصنيفها بشكل صحيح) تبلغ 0.925 ، وهي نتيجة جيدة جدًا لمجموعة البيانات الصغيرة هذه.
نتائج الاستدلال النموذجي
لقد استضفت النموذج على مثيل ml.c5.xlarge منخفض التكلفة:
أخيرًا ، أعددت مجموعة اختبار مكونة من 10 صور سلحفاة لمعرفة نتيجة الاستدلال لنموذج التجزئة المدرب:
الصور التالية تظهر النتائج.

تبدو أقنعة تجزئة السلاحف البحرية دقيقة وأنا سعيد بهذه النتيجة المدربة على مجموعة بيانات مكونة من 300 صورة تم تصنيفها بواسطة عمال ميكانيكي ترك. يمكنك أيضًا استكشاف الشبكات الأخرى المتاحة مثل شبكة التحليل الهرمي للمشهد (PSP) or ديب لاب- V3 في نموذج دفتر الملاحظات مع مجموعة البيانات الخاصة بك.
تنظيف
احذف نقطة النهاية عند الانتهاء منها لتجنب تكبد تكاليف مستمرة:
وفي الختام
في هذا المنشور ، أوضحت كيفية تخصيص تسمية بيانات التجزئة الدلالية وتدريب النموذج باستخدام SageMaker. أولاً ، يمكنك إعداد وظيفة وضع العلامات باستخدام أداة التجزئة التلقائية أو استخدام القوى العاملة التركية الميكانيكية (بالإضافة إلى الخيارات الأخرى). إذا كان لديك أكثر من 5,000 عنصر ، فيمكنك أيضًا استخدام تسمية البيانات الآلية. ثم تقوم بتحويل المخرجات من وظيفة وضع العلامات على الحقيقة الأرضية إلى تنسيقات الإدخال المطلوبة لتدريب التجزئة الدلالي المدمج في SageMaker. بعد ذلك ، يمكنك استخدام مثيل حوسبة متسارعة (مثل p2 أو p3) لتدريب نموذج تجزئة دلالي باستخدام ما يلي مفكرة ونشر النموذج إلى مثيل أكثر فعالية من حيث التكلفة (مثل ml.c5.xlarge). أخيرًا ، يمكنك مراجعة نتائج الاستدلال على مجموعة بيانات الاختبار الخاصة بك ببضعة سطور من التعليمات البرمجية.
ابدأ مع التجزئة الدلالية SageMaker تسمية البيانات و تدريب نموذجي مع مجموعة البيانات المفضلة لديك!
عن المؤلف
 كارا يانغ هو عالم بيانات في خدمات AWS الاحترافية. إنها متحمسة لمساعدة العملاء على تحقيق أهداف أعمالهم من خلال خدمات AWS السحابية. لقد ساعدت المنظمات في بناء حلول ML عبر العديد من الصناعات مثل التصنيع والسيارات والاستدامة البيئية والفضاء.
كارا يانغ هو عالم بيانات في خدمات AWS الاحترافية. إنها متحمسة لمساعدة العملاء على تحقيق أهداف أعمالهم من خلال خدمات AWS السحابية. لقد ساعدت المنظمات في بناء حلول ML عبر العديد من الصناعات مثل التصنيع والسيارات والاستدامة البيئية والفضاء.
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- من نحن
- تسريع
- معجل
- دقيق
- التأهيل
- تحقق
- في
- وأضاف
- فضاء
- خوارزمية
- خوارزميات
- الكل
- أمازون
- أعلن
- آخر
- حول
- محام
- الآلي
- تلقائيا
- السيارات
- متاح
- AWS
- خلفية
- لان
- أفضل
- أفضل
- ما بين
- نساعدك في بناء
- مدمج
- الأعمال
- أسر
- حقيبة
- معين
- تغيير
- قنوات
- اختار
- فئة
- فصول
- مبوب
- سحابة
- الخدمات السحابية
- الكود
- مشترك
- منافسة
- إكمال
- الكمبيوتر
- أجهزة الكمبيوتر
- الحوسبة
- الثقة
- كنسولات
- محتوى
- ملاءمة
- المقابلة
- فعاله من حيث التكلفه
- التكاليف
- خلق
- خلق
- العملاء
- تصميم
- البيانات
- عالم البيانات
- عميق
- شرح
- نشر
- مختلف
- مباشرة
- رسم
- أثناء
- كل
- تمكن
- النهائي إلى نهاية
- نقطة النهاية
- أدخل
- بيئي
- أنشئ
- مثال
- إلا
- متوقع
- تتوقع
- اكتشف
- أقصى
- الوجه
- الميزات
- الاسم الأول
- اتباع
- متابعيك
- شكل
- تبدأ من
- ولدت
- الأهداف
- خير
- اللون الرمادي
- عظيم
- سعيد
- ساعد
- مساعدة
- يساعد
- عالي الجودة
- استضافت
- كيفية
- كيفية
- HTTPS
- الانسان
- البشر
- مئات
- صورة
- صور
- تنفيذ
- تحسن
- تتضمن
- شامل
- القيمة الاسمية
- مؤشر
- الصناعات
- معلومات
- إدخال
- مثل
- السطح البيني
- تقاطع طرق
- إدخال
- IT
- وظيفة
- المشــاريــع
- معروف
- تُشير
- وصفها
- ملصقات
- كبير
- إطلاق
- تعلم
- تعلم
- مستوى
- محدود
- خط
- خطوط
- قائمة
- محلي
- موقع
- المواقع
- طويل
- بحث
- آلة
- آلة التعلم
- إدارة
- إلزامي
- يدويا
- تصنيع
- رسم خريطة
- رسم الخرائط
- قناع
- ماسكات
- هائل
- ميكانيكي
- ربما
- ML
- نموذج
- عارضات ازياء
- الأكثر من ذلك
- متعدد
- أسماء
- تسمية
- قائمة الإختيارات
- شبكة
- الشبكات
- التالي
- مفكرة
- عدد
- عروض
- خيار
- مزيد من الخيارات
- المنظمات
- أخرى
- الخاصة
- عاطفي
- فى المائة
- أداء
- نقاط
- المضلع
- أكثر الاستفسارات
- إعداد
- جميل
- السعر
- خاص
- عملية المعالجة
- إنتاج
- محترف
- تزود
- ويوفر
- جمهور
- أغراض
- بسرعة
- RE
- تسجيل
- مثل
- مطلوب
- يتطلب
- النتائج
- مراجعة
- نفسه
- تحجيم
- عالم
- SEA
- تقسيم
- مختار
- الخدمة
- خدمات
- طقم
- ضبط
- مشاركة
- إظهار
- أظهرت
- الاشارات
- حالة
- صغير
- So
- تطبيقات الكمبيوتر
- الحلول
- انقسم
- بدأت
- تخزين
- الاستدامة
- الهدف
- المهام
- فريق
- تجربه بالعربي
- •
- المصدر
- شيء
- طرف ثالث
- الآلاف
- عبر
- الإنتاجية
- الوقت
- أداة
- قطار
- قادة الإيمان
- تحول
- الاتحاد
- تستخدم
- التحقق من صحة
- الباعة
- رؤيتنا
- من الذى
- للعمل
- العمال
- القوى العاملة
- أعمال
- حل متجر العقارات الشامل الخاص بك في جورجيا