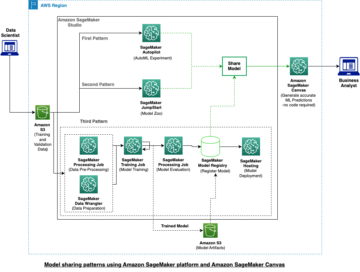
متى OpenAI أصدرت الجيل الثالث من نموذج التعلم الآلي (ML) المتخصص في إنشاء النصوص في يوليو 2020 ، كنت أعرف أن شيئًا مختلفًا. ضرب هذا النموذج عصبًا مثل لم يسبقه أحد. فجأة سمعت أصدقاء وزملاء ، قد يكونون مهتمين بالتكنولوجيا ولكنهم عادة لا يهتمون كثيرًا بآخر التطورات في مجال الذكاء الاصطناعي / التعلم الآلي ، تحدثوا عن ذلك. كتب حتى الجارديان مقالة حوله. أو ، على وجه الدقة ، ملف نموذج كتب المقال وصحيفة الغارديان حررته ونشرته. كان هناك من ينكر ذلك - GPT-3 كان تغيير قواعد اللعبة.
بعد إطلاق النموذج ، بدأ الناس على الفور في ابتكار تطبيقات محتملة له. في غضون أسابيع ، تم إنشاء العديد من العروض الرائعة ، والتي يمكن العثور عليها في موقع ويب GPT-3. أحد التطبيقات التي لفتت انتباهي كان تلخيص النص - قدرة الكمبيوتر على قراءة نص معين وتلخيص محتواه. إنها واحدة من أصعب المهام للكمبيوتر لأنها تجمع بين حقلين في مجال معالجة اللغة الطبيعية (NLP): فهم القراءة وتوليد النص. وهذا هو سبب إعجابي الشديد بعروض GPT-3 لتلخيص النص.
يمكنك أن تجربهم على موقع ويب Hugging Face Spaces. المفضل لدي في الوقت الحالي هو استمارتنا يُنشئ ملخصات للمقالات الإخبارية باستخدام عنوان URL للمقالة فقط كمدخل.
في هذه السلسلة المكونة من جزأين ، أقترح دليلًا عمليًا للمؤسسات حتى تتمكن من تقييم جودة نماذج تلخيص النص في مجالك.
نظرة عامة على البرنامج التعليمي
العديد من المنظمات التي أعمل معها (جمعيات خيرية ، شركات ، منظمات غير حكومية) لديها كميات هائلة من النصوص التي تحتاج إلى قراءتها وتلخيصها - التقارير المالية أو المقالات الإخبارية ، وأوراق البحث العلمي ، وطلبات براءات الاختراع ، والعقود القانونية ، والمزيد. بطبيعة الحال ، تهتم هذه المنظمات بأتمتة هذه المهام باستخدام تقنية البرمجة اللغوية العصبية. لإثبات فن الممكن ، غالبًا ما أستخدم العروض التوضيحية لتلخيص النص ، والتي تكاد لا تفشل أبدًا في التأثير.
لكن الآن ماذا؟
يتمثل التحدي الذي تواجهه هذه المؤسسات في أنها تريد تقييم نماذج تلخيص النص بناءً على ملخصات للعديد من المستندات - وليس واحدة تلو الأخرى. إنهم لا يريدون تعيين متدرب وظيفته الوحيدة هي فتح التطبيق ، ولصق مستند ، والضغط على ملف تلخيص ، انتظر الإخراج ، وقم بتقييم ما إذا كان الملخص جيدًا ، وقم بذلك مرة أخرى لآلاف المستندات.
لقد كتبت هذا البرنامج التعليمي مع وضع نفسي السابقة في الاعتبار منذ أربعة أسابيع - إنه البرنامج التعليمي الذي كنت أتمنى لو كان لدي في ذلك الوقت عندما بدأت في هذه الرحلة. بهذا المعنى ، فإن الجمهور المستهدف في هذا البرنامج التعليمي هو شخص على دراية بـ AI / ML وقد استخدم نماذج Transformer من قبل ، ولكنه في بداية رحلة تلخيص النص الخاصة بهم ويريد التعمق فيها. لأنه مكتوب من قبل "مبتدئ" وللمبتدئين ، أريد التأكيد على حقيقة أن هذا البرنامج التعليمي هو كذلك a دليل عملي - لا ال دليل عملي. يرجى التعامل معها كما لو جورج إي بوكس قال:
![]()
من حيث مقدار المعرفة التقنية المطلوبة في هذا البرنامج التعليمي: إنه يتضمن بعض الترميز في Python ، ولكن في معظم الأوقات نستخدم الكود فقط لاستدعاء واجهات برمجة التطبيقات ، لذلك لا يلزم معرفة عميقة بالشفرة أيضًا. من المفيد أن تكون على دراية بمفاهيم معينة من ML ، مثل ما يعنيه ذلك قطار و نشر نموذج مفاهيم السلامه اولا, التحقق من صحةو اختبار مجموعات البيانات، وما إلى ذلك وهلم جرا. بعد أن انغمس أيضًا في ملف مكتبة المحولات من قبل قد يكون مفيدًا ، لأننا نستخدم هذه المكتبة على نطاق واسع خلال هذا البرنامج التعليمي. أقوم أيضًا بتضمين روابط مفيدة لمزيد من القراءة لهذه المفاهيم.
نظرًا لأن هذا البرنامج التعليمي مكتوب بواسطة مبتدئ ، لا أتوقع أن يحصل خبراء البرمجة اللغوية العصبية وممارسي التعلم العميق المتقدم على الكثير من هذا البرنامج التعليمي. على الأقل ليس من منظور تقني - ربما لا تزال تستمتع بالقراءة ، لذا من فضلك لا تغادر بعد! لكن سيتعين عليك التحلي بالصبر فيما يتعلق بالتبسيط - لقد حاولت أن أعيش بمفهوم جعل كل شيء في هذا البرنامج التعليمي بسيطًا قدر الإمكان ، ولكن ليس أبسط.
هيكل هذا البرنامج التعليمي
تمتد هذه السلسلة على أربعة أقسام مقسمة إلى وظيفتين ، حيث نمر بمراحل مختلفة من مشروع تلخيص النص. في المنشور الأول (القسم 1) ، نبدأ بتقديم مقياس لمهام تلخيص النص - وهو مقياس للأداء يسمح لنا بتقييم ما إذا كان الملخص جيدًا أم سيئًا. نقدم أيضًا مجموعة البيانات التي نريد تلخيصها وإنشاء خط أساس باستخدام نموذج no-ML - نستخدم مجريات بسيطة لإنشاء ملخص من نص معين. يعد إنشاء هذا الأساس خطوة مهمة للغاية في أي مشروع ML لأنه يمكننا من تحديد مقدار التقدم الذي نحرزه باستخدام الذكاء الاصطناعي في المستقبل. يسمح لنا بالإجابة على السؤال "هل يستحق الأمر حقًا الاستثمار في تقنية الذكاء الاصطناعي؟"
في المنشور الثاني ، نستخدم نموذجًا سبق تدريبه مسبقًا لإنشاء الملخصات (القسم 2). هذا ممكن مع نهج حديث في ML يسمى نقل التعلم. إنها خطوة مفيدة أخرى لأننا نأخذ نموذجًا جاهزًا ونختبره على مجموعة البيانات الخاصة بنا. يتيح لنا ذلك إنشاء خط أساس آخر ، مما يساعدنا على رؤية ما يحدث عندما نقوم بالفعل بتدريب النموذج على مجموعة البيانات الخاصة بنا. النهج يسمى تلخيص بدون طلقة، لأن النموذج لم يتعرض لمجموعة البيانات الخاصة بنا.
بعد ذلك ، حان الوقت لاستخدام نموذج مدرب مسبقًا وتدريبه على مجموعة البيانات الخاصة بنا (القسم 3). هذا يسمى أيضا الكون المثالى. إنها تمكن النموذج من التعلم من أنماط وخصوصيات بياناتنا والتكيف معها ببطء. بعد تدريب النموذج ، نستخدمه لإنشاء ملخصات (القسم 4).
كي تختصر:
- جزء 1:
- القسم 1: استخدم نموذج no-ML لإنشاء خط أساس
- جزء 2:
- القسم 2: إنشاء الملخصات باستخدام نموذج اللقطة الصفرية
- القسم 3: تدريب نموذج التلخيص
- القسم 4: تقييم النموذج المدرب
الكود الكامل لهذا البرنامج التعليمي متاح في ما يلي جيثب ريبو.
ما الذي سنحققه بنهاية هذا البرنامج التعليمي؟
بنهاية هذا البرنامج التعليمي ، نحن ولن لديك نموذج تلخيص نصي يمكن استخدامه في الإنتاج. لن يكون لدينا حتى ملف خير نموذج التلخيص (أدخل الرموز التعبيرية للصراخ هنا)!
ما سيكون لدينا بدلاً من ذلك هو نقطة انطلاق للمرحلة التالية من المشروع ، وهي مرحلة التجريب. هذا هو المكان الذي يأتي فيه "العلم" في علم البيانات ، لأن الأمر كله يتعلق الآن بتجربة نماذج مختلفة وإعدادات مختلفة لفهم ما إذا كان يمكن تدريب نموذج تلخيص جيد بما يكفي باستخدام بيانات التدريب المتاحة.
ولكي نكون شفافين تمامًا ، هناك فرصة جيدة أن تكون النتيجة أن التكنولوجيا لم تنضج بعد وأن المشروع لن يتم تنفيذه. وعليك أن تعد أصحاب المصلحة في عملك لهذا الاحتمال. لكن هذا موضوع لمنشور آخر.
القسم 1: استخدم نموذج no-ML لإنشاء خط أساس
هذا هو القسم الأول من برنامجنا التعليمي حول إعداد مشروع تلخيص نصي. في هذا القسم ، قمنا بإنشاء خط أساس باستخدام نموذج بسيط للغاية ، دون استخدام ML فعليًا. هذه خطوة مهمة جدًا في أي مشروع ML ، لأنها تتيح لنا فهم مقدار القيمة التي يضيفها ML على مدار وقت المشروع وما إذا كان يستحق الاستثمار فيه.
يمكن العثور على رمز البرنامج التعليمي في ما يلي جيثب ريبو.
البيانات والبيانات والبيانات
كل مشروع ML يبدأ بالبيانات! إذا أمكن ، يجب علينا دائمًا استخدام البيانات المتعلقة بما نريد تحقيقه من خلال مشروع تلخيص النص. على سبيل المثال ، إذا كان هدفنا هو تلخيص طلبات البراءات ، فيجب علينا أيضًا استخدام طلبات براءات الاختراع لتدريب النموذج. التحذير الكبير لمشروع ML هو أن بيانات التدريب تحتاج عادةً إلى تسمية. في سياق تلخيص النص ، هذا يعني أننا بحاجة إلى تقديم النص المراد تلخيصه بالإضافة إلى الملخص (التسمية). فقط من خلال توفير كلاهما يمكن للنموذج معرفة شكل الملخص الجيد.
في هذا البرنامج التعليمي ، نستخدم مجموعة بيانات متاحة للجمهور ، ولكن تظل الخطوات والرمز كما هي تمامًا إذا استخدمنا مجموعة بيانات مخصصة أو خاصة. ومرة أخرى ، إذا كان لديك هدف لنموذج تلخيص النص الخاص بك ولديك بيانات مقابلة ، فيرجى استخدام بياناتك بدلاً من ذلك لتحقيق أقصى استفادة من هذا.
البيانات التي نستخدمها هي مجموعة بيانات arXiv، والذي يحتوي على ملخصات لأوراق arXiv بالإضافة إلى عناوينها. لغرضنا ، نستخدم الملخص باعتباره النص الذي نريد تلخيصه والعنوان باعتباره ملخصًا مرجعيًا. تتوفر جميع خطوات تنزيل البيانات ومعالجتها مسبقًا في ما يلي مفكرة. نحن نطلب إدارة الهوية والوصول AWS (IAM) الذي يسمح بتحميل البيانات من وإلى خدمة تخزين أمازون البسيطة (Amazon S3) لتشغيل هذا الكمبيوتر الدفتري بنجاح. تم تطوير مجموعة البيانات كجزء من الورقة حول استخدام ArXiv كمجموعة بيانات ومرخصة بموجب المشاع الإبداعي CC0 1.0 إهداء المجال العام العالمي.
يتم تقسيم البيانات إلى ثلاث مجموعات بيانات: بيانات التدريب والتحقق من الصحة والاختبار. إذا كنت تريد استخدام بياناتك الخاصة ، فتأكد من أن هذا هو الحال أيضًا. يوضح الرسم البياني التالي كيف نستخدم مجموعات البيانات المختلفة.
![]()
بطبيعة الحال ، فإن السؤال الشائع في هذه المرحلة هو: ما مقدار البيانات التي نحتاجها؟ كما يمكنك أن تخمن بالفعل ، فإن الإجابة هي: هذا يعتمد. يعتمد ذلك على مدى تخصص المجال (يختلف تلخيص طلبات براءات الاختراع تمامًا عن تلخيص المقالات الإخبارية) ، ومدى دقة النموذج ليكون مفيدًا ، ومقدار تكلفة التدريب على النموذج ، وما إلى ذلك. نعود إلى هذا السؤال في وقت لاحق عندما نقوم بالفعل بتدريب النموذج ، ولكن باختصار أنه يتعين علينا تجربة أحجام مجموعات بيانات مختلفة عندما نكون في مرحلة الاختبار من المشروع.
ما الذي يجعل النموذج الجيد؟
في العديد من مشاريع ML ، من السهل قياس أداء النموذج. هذا بسبب وجود القليل من الغموض حول ما إذا كانت نتيجة النموذج صحيحة. غالبًا ما تكون التصنيفات في مجموعة البيانات ثنائية (صواب / خطأ ، نعم / لا) أو قاطعة. على أي حال ، من السهل في هذا السيناريو مقارنة إخراج النموذج بالتسمية ووضع علامة عليها على أنها صحيحة أو غير صحيحة.
عند إنشاء نص ، يصبح هذا الأمر أكثر صعوبة. الملخصات (الملصقات) التي نقدمها في مجموعة البيانات الخاصة بنا ليست سوى طريقة واحدة لتلخيص النص. ولكن هناك العديد من الاحتمالات لتلخيص نص معين. لذلك ، حتى إذا كان النموذج لا يتطابق مع التسمية الخاصة بنا 1: 1 ، فقد يظل الناتج ملخصًا صالحًا ومفيدًا. إذًا ، كيف نقارن ملخص النموذج بالموجز الذي نقدمه؟ المقياس الأكثر استخدامًا في تلخيص النص لقياس جودة النموذج هو النتيجة ROUGE. لفهم آليات هذا المقياس ، يرجى الرجوع إلى مقياس الأداء النهائي في البرمجة اللغوية العصبية. باختصار ، تقيس درجة ROUGE تداخل ن غرام (تسلسل متجاور من n العناصر) بين ملخص النموذج (ملخص المرشح) والملخص المرجعي (التسمية التي نقدمها في مجموعة البيانات الخاصة بنا). لكن ، بالطبع ، هذا ليس مقياسًا مثاليًا. لفهم حدودها ، تحقق من إلى ROUGE أو لا إلى ROUGE؟
لذا ، كيف نحسب درجة ROUGE؟ هناك عدد غير قليل من حزم Python لحساب هذا المقياس. لضمان الاتساق ، يجب أن نستخدم نفس الطريقة في جميع مراحل مشروعنا. نظرًا لأننا سنستخدم ، في وقت لاحق من هذا البرنامج التعليمي ، نصًا تدريبيًا من مكتبة Transformers بدلاً من كتابة نصنا الخاص ، يمكننا فقط إلقاء نظرة خاطفة على شفرة المصدر من البرنامج النصي وانسخ الكود الذي يحسب درجة ROUGE:
باستخدام هذه الطريقة لحساب النتيجة ، نضمن أننا نقارن دائمًا التفاح بالتفاح في جميع مراحل المشروع.
تحسب هذه الوظيفة عدة درجات من ROUGE: rouge1, rouge2, rougeLو rougeLsum. "المجموع" في rougeLsum يشير إلى حقيقة أن هذا المقياس يتم حسابه على ملخص كامل ، بينما rougeL يتم حسابه كمتوسط على الجمل الفردية. إذن ، ما هي درجة ROUGE التي يجب أن نستخدمها في مشروعنا؟ مرة أخرى ، علينا تجربة طرق مختلفة في مرحلة التجريب. لما يستحق ، فإن ورق ROUGE الأصلي تنص على أن "ROUGE-2 و ROUGE-L يعملان جيدًا في مهام تلخيص مستند واحد" بينما تؤدي "ROUGE-1 و ROUGE-L أداءً رائعًا في تقييم الملخصات القصيرة."
أنشئ خط الأساس
بعد ذلك ، نريد إنشاء خط الأساس باستخدام نموذج بسيط بدون ML. ماذا يعني ذلك؟ في مجال تلخيص النص ، تستخدم العديد من الدراسات نهجًا بسيطًا للغاية: يأخذون الأول n جمل النص وتعلن أنه ملخص المرشح. ثم يقارنون ملخص المرشح مع الملخص المرجعي ويحسبون درجة ROUGE. هذا أسلوب بسيط ولكنه قوي يمكننا تنفيذه في بضعة أسطر من التعليمات البرمجية (الكود الكامل لهذا الجزء هو كما يلي مفكرة):
نستخدم مجموعة بيانات الاختبار لهذا التقييم. هذا منطقي لأنه بعد تدريب النموذج ، نستخدم أيضًا مجموعة بيانات الاختبار نفسها للتقييم النهائي. نحن نحاول أيضًا أرقامًا مختلفة لـ n: نبدأ بالجمل الأولى فقط كملخص للمرشح ، ثم الجملتين الأوليين ، وأخيرًا الجمل الثلاث الأولى.
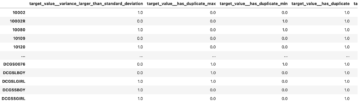
تُظهر لقطة الشاشة التالية نتائج نموذجنا الأول.
![]()
درجات ROUGE هي الأعلى ، مع الجملة الأولى فقط كملخص للمرشح. هذا يعني أن أخذ أكثر من جملة واحدة يجعل الملخص مطولًا جدًا ويؤدي إلى درجة أقل. هذا يعني أننا سنستخدم الدرجات لملخصات الجملة الواحدة كخط أساس.
من المهم ملاحظة أنه ، لمثل هذا الأسلوب البسيط ، فإن هذه الأرقام جيدة جدًا في الواقع ، خاصة بالنسبة لـ rouge1 نتيجة. لوضع هذه الأرقام في سياقها ، يمكننا الرجوع إليها موديلات بيغاسوس، والذي يعرض نتائج نموذج حديث لمجموعات بيانات مختلفة.
الخلاصة وماذا بعد
في الجزء الأول من سلسلتنا ، قدمنا مجموعة البيانات التي نستخدمها خلال مشروع التلخيص بالإضافة إلى مقياس لتقييم الملخصات. ثم أنشأنا خط الأساس التالي بنموذج بسيط بدون ML.
![]()
في مجلة آخر المقبل، نحن نستخدم نموذجًا خاليًا من الضربات - على وجه التحديد ، نموذج تم تدريبه خصيصًا لتلخيص نصوص المقالات الإخبارية العامة. ومع ذلك ، لن يتم تدريب هذا النموذج على الإطلاق على مجموعة البيانات الخاصة بنا (ومن هنا جاء اسم "اللقطة الصفرية").
أترك لك الأمر كواجب منزلي لتخمين كيفية أداء نموذج التسديد الصفري هذا مقارنة بخط الأساس البسيط لدينا. من ناحية ، سيكون نموذجًا أكثر تعقيدًا (إنه في الواقع شبكة عصبية). من ناحية أخرى ، يتم استخدامه فقط لتلخيص المقالات الإخبارية ، لذلك قد يواجه صعوبات مع الأنماط المتأصلة في مجموعة بيانات arXiv.
عن المؤلف
![]() هيكو هوتز هو مهندس حلول أول للذكاء الاصطناعي والتعلم الآلي ويقود مجتمع معالجة اللغات الطبيعية (NLP) داخل AWS. قبل هذا المنصب ، كان رئيسًا لعلوم البيانات لخدمة عملاء أمازون في الاتحاد الأوروبي. تساعد Heiko عملاءنا على تحقيق النجاح في رحلة الذكاء الاصطناعي / التعلم الآلي الخاصة بهم على AWS وعملت مع مؤسسات في العديد من الصناعات ، بما في ذلك التأمين والخدمات المالية والإعلام والترفيه والرعاية الصحية والمرافق والتصنيع. يسافر هيكو قدر الإمكان في أوقات فراغه.
هيكو هوتز هو مهندس حلول أول للذكاء الاصطناعي والتعلم الآلي ويقود مجتمع معالجة اللغات الطبيعية (NLP) داخل AWS. قبل هذا المنصب ، كان رئيسًا لعلوم البيانات لخدمة عملاء أمازون في الاتحاد الأوروبي. تساعد Heiko عملاءنا على تحقيق النجاح في رحلة الذكاء الاصطناعي / التعلم الآلي الخاصة بهم على AWS وعملت مع مؤسسات في العديد من الصناعات ، بما في ذلك التأمين والخدمات المالية والإعلام والترفيه والرعاية الصحية والمرافق والتصنيع. يسافر هيكو قدر الإمكان في أوقات فراغه.
- '
- "
- &
- 100
- 2020
- من نحن
- الملخص
- الوصول
- دقيق
- تحقق
- متقدم
- التطورات
- AI
- الكل
- سابقا
- أمازون
- غموض
- المبالغ
- آخر
- واجهات برمجة التطبيقات
- تطبيق
- التطبيقات
- نهج
- حول
- فنـون
- البند
- مقالات
- جمهور
- متاح
- المتوسط
- AWS
- خط الأساس
- في الأساس
- البداية
- يجري
- الأعمال
- دعوة
- يهمني
- اشتعلت
- تحدى
- الكود
- البرمجة
- مشترك
- مجتمع
- الشركات
- مقارنة
- تماما
- إحصاء
- مفهوم
- يحتوي
- محتوى
- عقود
- خلق
- على
- خدمة العملاء
- العملاء
- البيانات
- علم البيانات
- أعمق
- المتقدمة
- مختلف
- وثائق
- لا
- نطاق
- ترفيه
- خاصة
- إنشاء
- EU
- كل شىء
- مثال
- توقع
- خبرائنا
- عين
- الوجه
- مجال
- أخيرا
- مالي
- الخدمات المالية
- الاسم الأول
- متابعيك
- إلى الأمام
- وجدت
- وظيفة
- إضافي
- لعبة
- توليد
- جيل
- هدف
- الذهاب
- خير
- عظيم
- وصي
- توجيه
- وجود
- رئيس
- الرعاية الصحية
- مفيد
- يساعد
- هنا
- تأجير
- كيفية
- HTTPS
- ضخم
- هوية
- تنفيذ
- نفذت
- أهمية
- تتضمن
- بما فيه
- فرد
- الصناعات
- التأمين
- إدخال
- الاستثمار
- IT
- وظيفة
- يوليو
- القفل
- المعرفة
- ملصقات
- لغة
- آخر
- يؤدي
- تعلم
- تعلم
- يترك
- شروط وأحكام
- المكتبة
- مرخص
- وصلات
- القليل
- آلة
- آلة التعلم
- يصنع
- القيام ب
- تصنيع
- علامة
- مباراة
- قياس
- الوسائط
- مانع
- ML
- نموذج
- عارضات ازياء
- الأكثر من ذلك
- أكثر
- طبيعي
- شبكة
- أخبار
- مفكرة
- أرقام
- جاكيت
- طلب
- المنظمات
- أخرى
- ورق
- براءة الإختراع
- مجتمع
- أداء
- منظور
- مرحلة جديدة
- البوينت
- إمكانيات
- إمكانية
- ممكن
- المنشورات
- محتمل
- قوي
- خاص
- الإنتــاج
- تنفيذ المشاريع
- مشروع ناجح
- اقترح
- تزود
- توفير
- جمهور
- غرض
- جودة
- سؤال
- نطاق
- RE
- نادي القراءة
- التقارير
- تطلب
- مطلوب
- بحث
- النتائج
- يجري
- قال
- علوم
- إحساس
- مسلسلات
- الخدمة
- خدمات
- طقم
- ضبط
- قصير
- الاشارات
- So
- الحلول
- شخص ما
- شيء
- متطور
- الفضاء
- المساحات
- متخصص
- تتخصص
- على وجه التحديد
- انقسم
- بداية
- بدأت
- يبدأ
- دولة من بين الفن
- المحافظة
- تخزين
- إجهاد
- دراسات
- ناجح
- بنجاح
- حديث
- الهدف
- المهام
- تقني
- تكنولوجيا
- تجربه بالعربي
- الآلاف
- عبر
- طوال
- الوقت
- عنوان الاعلان
- قادة الإيمان
- شفاف
- علاج
- نهائي
- فهم
- عالمي
- us
- تستخدم
- عادة
- قيمنا
- انتظر
- ابحث عن
- سواء
- من الذى
- ويكيبيديا
- في غضون
- بدون
- للعمل
- عمل
- قيمة
- جاري الكتابة
- X
- صفر