اباتشي فيض هو تنسيق جدول مفتوح لمجموعات البيانات التحليلية الكبيرة جدًا ، والذي يلتقط معلومات البيانات الوصفية عن حالة مجموعات البيانات أثناء تطورها وتغيرها بمرور الوقت. يضيف جداول لحساب المحركات بما في ذلك Spark و Trino و PrestoDB و Flink و Hive باستخدام تنسيق جدول عالي الأداء يعمل تمامًا مثل جدول SQL. أصبح Iceberg شائعًا جدًا لدعمه لمعاملات ACID في بحيرات البيانات والميزات مثل تطور المخطط والقسم والسفر عبر الزمن والتراجع.
يتم دعم تكامل Apache Iceberg من خلال خدمات تحليلات AWS بما في ذلك أمازون EMR, أمازون أثيناو غراء AWS. يمكن لـ Amazon EMR توفير مجموعات باستخدام Spark و Hive و Trino و Flink التي يمكنها تشغيل Iceberg. بدءًا من الإصدار 6.5.0 من Amazon EMR ، يمكنك ذلك استخدام Iceberg مع مجموعة EMR الخاصة بك دون الحاجة إلى إجراء التمهيد. في أوائل عام 2022 ، أعلنت AWS عن التوافر العام لمعاملات Athena ACID ، المدعومة من Apache Iceberg. تم إصداره مؤخرًا الإصدار 3 من محرك استعلام أثينا يوفر تكاملاً أفضل مع تنسيق جدول Iceberg. AWS Glue 3.0 والإصدارات الأحدث يدعم إطار Apache Iceberg لبحيرات البيانات.
في هذا المنشور ، نناقش ما يريده العملاء في بحيرات البيانات الحديثة وكيف يساعد Apache Iceberg في تلبية احتياجات العملاء. ثم نسير عبر حل لإنشاء بحيرة بيانات Iceberg عالية الأداء ومتطورة خدمة تخزين أمازون البسيطة (Amazon S3) ومعالجة البيانات الإضافية عن طريق تشغيل إدراج وتحديث وحذف عبارات SQL. أخيرًا ، نوضح لك كيفية ضبط الأداء للعملية لتحسين أداء القراءة والكتابة.
كيف يعالج Apache Iceberg ما يريده العملاء في بحيرات البيانات الحديثة
يقوم المزيد والمزيد من العملاء ببناء بحيرات بيانات ، باستخدام بيانات منظمة وغير منظمة ، لدعم العديد من المستخدمين والتطبيقات وأدوات التحليل. هناك حاجة متزايدة لبحيرات البيانات لدعم قاعدة البيانات مثل ميزات مثل معاملات ACID والتحديثات والحذف على مستوى السجل والسفر عبر الزمن والتراجع. تم تصميم Apache Iceberg لدعم هذه الميزات في بحيرات بيانات ذات تكلفة منخفضة على نطاق البيتابايت على Amazon S3.
يلبي Apache Iceberg احتياجات العملاء من خلال التقاط معلومات بيانات وصفية غنية حول مجموعة البيانات في الوقت الذي يتم فيه إنشاء ملفات البيانات الفردية. توجد ثلاث طبقات في بنية جدول Iceberg: كتالوج Iceberg ، وطبقة البيانات الوصفية ، وطبقة البيانات ، كما هو موضح في الشكل التالي (مصدر).

يخزن كتالوج Iceberg مؤشر البيانات الأولية إلى ملف البيانات الأولية للجدول الحالي. عندما يقرأ استعلام تحديد جدول Iceberg ، ينتقل محرك الاستعلام أولاً إلى كتالوج Iceberg ، ثم يسترجع موقع ملف البيانات الوصفية الحالي. عندما يكون هناك تحديث لجدول Iceberg ، يتم إنشاء لقطة جديدة للجدول ، ويشير مؤشر البيانات الأولية إلى ملف البيانات الأولية للجدول الحالي.
فيما يلي مثال على كتالوج Iceberg مع تنفيذ AWS Glue. يمكنك رؤية اسم قاعدة البيانات والموقع (مسار S3) لجدول Iceberg وموقع البيانات الوصفية.

تحتوي طبقة البيانات الأولية على ثلاثة أنواع من الملفات: ملف البيانات الأولية ، وقائمة البيان ، وملف البيان في تسلسل هرمي. يوجد ملف البيانات الوصفية في أعلى التسلسل الهرمي ، والذي يخزن معلومات حول مخطط الجدول ومعلومات القسم واللقطات. اللقطة تشير إلى قائمة البيان. تحتوي قائمة البيان على معلومات حول كل ملف بيان يتكون من اللقطة ، مثل موقع ملف البيان والأقسام التي ينتمي إليها والحدود الدنيا والعليا لأعمدة الأقسام لملفات البيانات التي يتتبعها. يتتبع ملف البيان ملفات البيانات بالإضافة إلى تفاصيل إضافية حول كل ملف ، مثل تنسيق الملف. تعمل جميع الملفات الثلاثة في تسلسل هرمي لتتبع اللقطات والمخطط والتقسيم والخصائص وملفات البيانات في جدول Iceberg.
تحتوي طبقة البيانات على ملفات البيانات الفردية لجدول Iceberg. يدعم Iceberg مجموعة كبيرة من تنسيقات الملفات بما في ذلك Parquet و ORC و Avro. نظرًا لأن جدول Iceberg يتتبع ملفات البيانات الفردية بدلاً من الإشارة فقط إلى موقع القسم بملفات البيانات ، فإنه يعزل عمليات الكتابة عن عمليات القراءة. يمكنك كتابة ملفات البيانات في أي وقت ، ولكن فقط تنفيذ التغيير بشكل صريح ، مما يؤدي إلى إنشاء إصدار جديد من ملفات اللقطة والبيانات الوصفية.
حل نظرة عامة
في هذا المنشور ، نوجهك عبر حل لإنشاء بحيرة بيانات Apache Iceberg عالية الأداء على Amazon S3 ؛ معالجة البيانات الإضافية مع إدراج وتحديث وحذف عبارات SQL ؛ وضبط جدول Iceberg لتحسين أداء القراءة والكتابة. يوضح الرسم البياني التالي بنية الحل.

لشرح هذا الحل ، نستخدم أمازون مراجعات العملاء مجموعة البيانات في دلو S3 (s3://amazon-reviews-pds/parquet/). في حالة الاستخدام الحقيقي ، ستكون بيانات أولية مخزنة في حاوية S3 الخاصة بك. يمكننا التحقق من حجم البيانات باستخدام الكود التالي في ملف واجهة سطر الأوامر AWS (AWS CLI):
إجمالي عدد العناصر هو 430 ، والحجم الإجمالي هو 47.4 جيجا بايت.
لإعداد هذا الحل واختباره ، نكمل الخطوات عالية المستوى التالية:
- قم بإعداد دلو S3 في المنطقة المنسقة لتخزين البيانات المحولة بتنسيق جدول Iceberg.
- قم بتشغيل مجموعة EMR مع التكوينات المناسبة لـ Apache Iceberg.
- قم بإنشاء دفتر ملاحظات في EMR Studio.
- قم بتكوين جلسة Spark لـ Apache Iceberg.
- تحويل البيانات إلى تنسيق جدول Iceberg ونقل البيانات إلى المنطقة المنسقة.
- قم بتشغيل استعلامات الإدراج والتحديث والحذف في Athena لمعالجة البيانات المتزايدة.
- قم بضبط الأداء.
المتطلبات الأساسية المسبقة
لمتابعة هذه الإرشادات ، يجب أن يكون لديك ملف حساب AWS مع إدارة الهوية والوصول AWS (IAM) الذي يتمتع بإمكانية الوصول الكافي لتوفير الموارد المطلوبة.
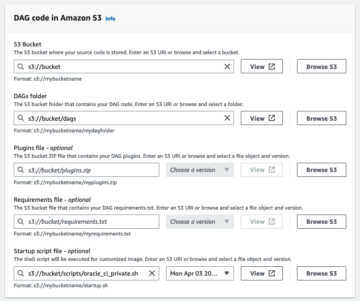
قم بإعداد دلو S3 لبيانات Iceberg في المنطقة المنسقة في بحيرة البيانات الخاصة بك
اختر المنطقة التي تريد إنشاء حاوية S3 فيها وقدم اسمًا فريدًا:
قم بتشغيل مجموعة EMR لتشغيل وظائف Iceberg باستخدام Spark
يمكنك إنشاء مجموعة EMR من ملف وحدة تحكم إدارة AWSأو Amazon EMR CLI أو مجموعة تطوير سحابة AWS (AWS CDK). في هذا المنشور ، نرشدك إلى كيفية إنشاء مجموعة EMR من وحدة التحكم.
- في وحدة تحكم Amazon EMR ، اختر إنشاء الكتلة.
- اختار خيارات متقدمة.
- في حالة برامج التكوين، اختر أحدث إصدار من Amazon EMR. اعتبارًا من يناير 2023 ، الإصدار الأخير هو 6.9.0. يتطلب Iceberg الإصدار 6.5.0 وما فوق.
- أختار JupyterEnterpriseGateway و شرارة كبرنامج للتثبيت.
- في حالة تحرير إعدادات البرنامج، حدد أدخل التكوين وأدخل
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - اترك الإعدادات الأخرى على الإعدادات الافتراضية الخاصة بها واختر التالى.

- في حالة أجهزة التبخير، استخدم الإعداد الافتراضي.
- اختار التالى.
- في حالة اسم الكتلة، إدخال اسم. نحن نستخدم
iceberg-blog-cluster. - اترك الإعدادات المتبقية دون تغيير واختر التالى.
- اختار إنشاء الكتلة.
قم بإنشاء دفتر ملاحظات في EMR Studio
نرشدك الآن إلى كيفية إنشاء دفتر ملاحظات في EMR Studio من وحدة التحكم.
- على وحدة تحكم IAM ، إنشاء دور خدمة EMR Studio.
- في وحدة تحكم Amazon EMR ، اختر استوديو EMR.
- اختار إبداء الأن.
• إبداء الأن تظهر الصفحة في علامة تبويب جديدة.
- اختار إنشاء الاستوديو في علامة التبويب الجديدة.
- إدخال اسم. نستخدم فيض-استوديو.
- اختر نفس VPC والشبكة الفرعية كتلك الخاصة بمجموعة EMR ومجموعة الأمان الافتراضية.
- اختار إدارة الهوية والوصول (IAM) AWS للمصادقة ، واختر دور خدمة EMR Studio الذي أنشأته للتو.
- اختر مسار S3 لـ مساحات العمل الاحتياطية.
- اختار إنشاء الاستوديو.
- بعد إنشاء الاستوديو ، اختر عنوان URL للوصول إلى الاستوديو.
- في لوحة معلومات EMR Studio ، اختر قم بإنشاء مساحة عمل.
- أدخل اسمًا لمساحة العمل الخاصة بك. نحن نستخدم
iceberg-workspace. - وسع التكوين المتقدم واختر إرفاق مساحة العمل إلى كتلة EMR.
- اختر مجموعة EMR التي أنشأتها سابقًا.
- اختار قم بإنشاء مساحة عمل.
- اختر اسم مساحة العمل لفتح علامة تبويب جديدة.
في جزء التنقل ، يوجد دفتر ملاحظات يحمل نفس اسم مساحة العمل. في حالتنا ، إنها مساحة عمل فيض.
- افتح دفتر الملاحظات.
- عند مطالبتك باختيار kernel ، اختر شرارة.
تكوين جلسة Spark لـ Apache Iceberg
استخدم الكود التالي ، مع تقديم اسم حاوية S3 الخاص بك:
هذا يعيّن تكوينات جلسة Spark التالية:
- spark.sql.catalog.demo.sql.catalog.demo - يسجل كتالوج Spark المسمى demo ، والذي يستخدم البرنامج المساعد لكتالوج Iceberg Spark.
- spark.sql.catalog.demo.catalog- ضمني - يستخدم كتالوج Spark التجريبي AWS Glue باعتباره الكتالوج المادي لتخزين معلومات الجدول وقاعدة بيانات Iceberg.
- spark.sql.catalog.demo.warehouse - يخزن كتالوج Spark التجريبي جميع البيانات الوصفية وملفات البيانات في Iceberg ضمن مسار الجذر المحدد بواسطة هذه الخاصية:
s3://iceberg-curated-blog-data. - تمديدات شرارة - يضيف دعمًا إلى امتدادات Iceberg Spark SQL ، والتي تسمح لك بتشغيل إجراءات Iceberg Spark وبعض أوامر Iceberg-only SQL (يمكنك استخدام هذا في خطوة لاحقة).
- spark.sql.catalog.demo.io-impl - يسمح Iceberg للمستخدمين بكتابة البيانات إلى Amazon S3 من خلال S3FileIO. يستخدم AWS Glue Data Catalog بشكل افتراضي ملف FileIO هذا ، ويمكن للكتالوجات الأخرى تحميل FileIO باستخدام خاصية الكتالوج io-impl.
تحويل البيانات إلى تنسيق جدول Iceberg
يمكنك استخدام Spark على Amazon EMR أو Athena لتحميل جدول Iceberg. في جلسة Spark الخاصة بدفتر مساحة العمل EMR Studio ، قم بتشغيل الأوامر التالية لتحميل البيانات:
بعد تشغيل الكود ، يجب أن تجد بادئتين تم إنشاؤهما في مسار مستودع البيانات الخاص بك S3 (s3://iceberg-curated-blog-data/reviews.db/all_reviews): البيانات والبيانات الوصفية.
معالجة البيانات الإضافية باستخدام إدراج وتحديث وحذف عبارات SQL في أثينا
Athena هو محرك استعلام بدون خادم يمكنك استخدامه لأداء مهام القراءة والكتابة والتحديث والتحسين مقابل جداول Iceberg. لتوضيح كيف يدعم تنسيق بحيرة بيانات Apache Iceberg استيعاب البيانات المتزايد ، نقوم بتشغيل عبارات SQL وإدراجها وتحديثها وحذفها في بحيرة البيانات.
انتقل إلى وحدة تحكم أثينا واختر محرر الاستعلام. إذا كانت هذه هي المرة الأولى التي تستخدم فيها محرر استعلام Athena ، فأنت بحاجة إلى ذلك تكوين موقع نتيجة الاستعلام لتكون حاوية S3 التي أنشأتها سابقًا. يجب أن تكون قادرًا على رؤية أن الجدول reviews.all_reviews متاح للاستعلام. قم بتشغيل الاستعلام التالي للتحقق من أنك قمت بتحميل جدول Iceberg بنجاح:
معالجة البيانات المتزايدة عن طريق تشغيل إدراج وتحديث وحذف عبارات SQL:
ضبط الأداء
في هذا القسم ، نتعرف على طرق مختلفة لتحسين أداء قراءة وكتابة Apache Iceberg.
تكوين خصائص جدول Apache Iceberg
Apache Iceberg هو تنسيق جدول ، وهو يدعم خصائص الجدول لتكوين سلوك الجدول مثل القراءة والكتابة والكتالوج. يمكنك تحسين أداء القراءة والكتابة على جداول Iceberg عن طريق ضبط خصائص الجدول.
على سبيل المثال ، إذا لاحظت أنك تكتب عددًا كبيرًا جدًا من الملفات الصغيرة لجدول Iceberg ، فيمكنك تكوين حجم ملف الكتابة لكتابة ملفات أقل ولكن أكبر حجمًا للمساعدة في تحسين أداء الاستعلام.
| الممتلكات | الترتيب | الوصف |
| write.target- حجم الملف بايت | شنومكس (شنومكس مب) | يتحكم في حجم الملفات التي تم إنشاؤها لاستهداف هذا العدد من وحدات البايت |
استخدم الكود التالي لتغيير تنسيق الجدول:
التقسيم والفرز
لجعل استعلام يعمل بسرعة ، كلما قلت البيانات كلما كان ذلك أفضل. يستفيد Iceberg من البيانات الوصفية الغنية التي يلتقطها في وقت الكتابة ويسهل تقنيات مثل تخطيط المسح والتقسيم والتقليم والإحصائيات على مستوى العمود مثل قيم min / max لتخطي ملفات البيانات التي لا تحتوي على سجلات مطابقة. نوجهك خلال كيفية عمل تخطيط مسح الاستعلام وتقسيمه في Iceberg وكيف نستخدمها لتحسين أداء الاستعلام.
تخطيط مسح الاستعلام
بالنسبة إلى استعلام معين ، فإن الخطوة الأولى في محرك الاستعلام هي تخطيط الفحص ، وهي عملية البحث عن الملفات في الجدول المطلوب للاستعلام. يعد التخطيط في جدول Iceberg فعالًا للغاية ، لأنه يمكن استخدام البيانات الوصفية الغنية لـ Iceberg لتقليم ملفات البيانات الوصفية غير الضرورية ، بالإضافة إلى تصفية ملفات البيانات التي لا تحتوي على بيانات مطابقة. في اختباراتنا ، لاحظنا أن أثينا قامت بمسح 50٪ أو أقل من البيانات لاستعلام معين على جدول Iceberg مقارنة بالبيانات الأصلية قبل التحويل إلى تنسيق Iceberg.
هناك نوعان من التصفية:
- تصفية البيانات الوصفية - يستخدم Iceberg مستويين من البيانات الوصفية لتتبع الملفات في لقطة: قائمة البيان وملفات البيان. يستخدم أولاً قائمة البيان ، والتي تعمل كفهرس لملفات البيان. أثناء التخطيط ، تظهر مرشحات Iceberg باستخدام نطاق قيمة القسم في قائمة البيان دون قراءة جميع ملفات البيان. ثم يستخدم ملفات البيان المحددة للحصول على ملفات البيانات.
- تصفية البيانات - بعد تحديد قائمة ملفات البيان ، يستخدم Iceberg بيانات القسم وإحصائيات مستوى العمود لكل ملف بيانات مخزن في ملفات البيان لتصفية ملفات البيانات. أثناء التخطيط ، يتم تحويل مسندات الاستعلام إلى مسندات على بيانات القسم ويتم تطبيقها أولاً لتصفية ملفات البيانات. بعد ذلك ، يتم استخدام إحصائيات العمود مثل أعداد القيم على مستوى العمود ، والأعداد الفارغة ، والحدود السفلية ، والحدود العليا لتصفية ملفات البيانات التي لا يمكن أن تتطابق مع مؤشر الاستعلام. باستخدام الحدود العليا والسفلى لتصفية ملفات البيانات في وقت التخطيط ، يحسن Iceberg أداء الاستعلام بشكل كبير.
التقسيم والفرز
التقسيم هو طريقة لتجميع السجلات مع نفس قيم العمود الأساسي معًا كتابةً. فائدة التقسيم هي الاستعلامات الأسرع التي تصل فقط إلى جزء من البيانات ، كما هو موضح سابقًا في تخطيط فحص الاستعلام: تصفية البيانات. يجعل Iceberg التقسيم بسيطًا من خلال دعم التقسيم المخفي ، بالطريقة التي ينتج بها Iceberg قيم التقسيم عن طريق أخذ قيمة العمود وتحويلها اختياريًا.
في حالة الاستخدام الخاصة بنا ، نقوم أولاً بتشغيل الاستعلام التالي على جدول Iceberg غير المقسم. ثم نقوم بتقسيم جدول Iceberg حسب فئة المراجعات ، والتي سيتم استخدامها في حالة الاستعلام WHERE لتصفية السجلات. مع التقسيم ، يمكن أن يقوم الاستعلام بمسح بيانات أقل بكثير. انظر الكود التالي:
قم بتشغيل عبارة select التالية على جدول all_reviews غير المقسم مقابل الجدول المقسم لمعرفة فرق الأداء:
يوضح الجدول التالي تحسين أداء تقسيم البيانات ، مع تحسن أداء بنسبة 50٪ تقريبًا و 70٪ أقل للبيانات الممسوحة ضوئيًا.
| اسم مجموعة البيانات | مجموعة البيانات غير المقسمة | مجموعة البيانات المقسمة |
| وقت التشغيل (بالثواني) | 8.20 | 4.25 |
| البيانات الممسوحة ضوئيًا (ميغا بايت) | 131.55 | 33.79 |
لاحظ أن وقت التشغيل هو متوسط وقت التشغيل مع عدة عمليات تشغيل في اختبارنا.
لقد رأينا تحسنًا جيدًا في الأداء بعد التقسيم. ومع ذلك ، يمكن تحسين ذلك بشكل أكبر باستخدام إحصائيات على مستوى العمود من ملفات بيان Iceberg. من أجل استخدام الإحصائيات على مستوى العمود بشكل فعال ، فأنت تريد فرز سجلاتك بشكل أكبر بناءً على أنماط الاستعلام. سيؤدي فرز مجموعة البيانات بأكملها باستخدام الأعمدة التي تُستخدم غالبًا في الاستعلامات إلى إعادة ترتيب البيانات بحيث ينتهي كل ملف بيانات بنطاق فريد من القيم للأعمدة المحددة. إذا تم استخدام هذه الأعمدة في حالة الاستعلام ، فإنها تسمح لمحركات الاستعلام بتخطي ملفات البيانات بشكل أكبر ، وبالتالي تمكين استعلامات أسرع.
النسخ عند الكتابة مقابل القراءة عند الدمج
عند تنفيذ التحديث والحذف على جداول Iceberg في بحيرة البيانات ، هناك طريقتان تحددهما خصائص جدول Iceberg:
- نسخ عند الكتابة - باستخدام هذا النهج ، عند إجراء تغييرات على جدول Iceberg ، إما تحديثات أو حذف ، سيتم تكرار وتحديث ملفات البيانات المرتبطة بالسجلات المتأثرة. سيتم تحديث السجلات أو حذفها من ملفات البيانات المكررة. سيتم إنشاء لقطة جديدة لجدول Iceberg وتشير إلى الإصدار الأحدث من ملفات البيانات. هذا يجعل عمليات الكتابة الإجمالية أبطأ. قد تكون هناك مواقف تتطلب عمليات الكتابة المتزامنة مع التعارضات ، لذا يجب أن تحدث إعادة المحاولة ، مما يزيد من وقت الكتابة أكثر. من ناحية أخرى ، عند قراءة البيانات ، لا توجد عملية إضافية مطلوبة. سيقوم الاستعلام باسترداد البيانات من أحدث إصدار من ملفات البيانات.
- دمج على القراءة - مع هذا النهج ، عند وجود تحديثات أو حذف على جدول Iceberg ، لن تتم إعادة كتابة ملفات البيانات الحالية ؛ بدلاً من ذلك ، سيتم إنشاء ملفات حذف جديدة لتتبع التغييرات. للحذف ، سيتم إنشاء ملف حذف جديد مع السجلات المحذوفة. عند قراءة جدول Iceberg ، سيتم تطبيق ملف الحذف على البيانات المستردة لتصفية سجلات الحذف. بالنسبة للتحديثات ، سيتم إنشاء ملف حذف جديد لتمييز السجلات المحدثة على أنها محذوفة. ثم سيتم إنشاء ملف جديد لتلك السجلات ولكن بقيم محدثة. عند قراءة جدول Iceberg ، سيتم تطبيق كل من الملفات المحذوفة والجديدة على البيانات المستردة لتعكس أحدث التغييرات وإنتاج النتائج الصحيحة. لذلك ، بالنسبة لأي استعلامات لاحقة ، ستحدث خطوة إضافية لدمج ملفات البيانات مع الحذف وستحدث ملفات جديدة ، مما سيزيد عادةً من وقت الاستعلام. من ناحية أخرى ، قد تكون عمليات الكتابة أسرع لأنه لا توجد حاجة لإعادة كتابة ملفات البيانات الموجودة.
لاختبار تأثير الطريقتين ، يمكنك تشغيل الكود التالي لتعيين خصائص جدول Iceberg:
قم بتشغيل التحديث والحذف وتحديد عبارات SQL في Athena لإظهار فرق وقت التشغيل للنسخ عند الكتابة مقابل الدمج عند القراءة:
يلخص الجدول التالي أوقات تشغيل الاستعلام.
| سؤال | نسخ على الكتابة | دمج عند القراءة | ||||
| قم | حذف | اختر | قم | حذف | اختر | |
| وقت التشغيل (بالثواني) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| البيانات الممسوحة ضوئيًا (ميغا بايت) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
لاحظ أن وقت التشغيل هو متوسط وقت التشغيل مع عدة عمليات تشغيل في اختبارنا.
كما تظهر نتائج الاختبار لدينا ، هناك دائمًا مفاضلات في النهجين. يعتمد الأسلوب الذي يجب استخدامه على حالات الاستخدام الخاصة بك. باختصار ، تنخفض الاعتبارات إلى وقت الاستجابة في القراءة مقابل الكتابة. يمكنك الرجوع إلى الجدول التالي واتخاذ القرار الصحيح.
| . | نسخ على الكتابة | دمج عند القراءة |
| الايجابيات | قراءات أسرع | يكتب أسرع |
| سلبيات | يكتب باهظة الثمن | زمن انتقال أعلى للقراءات |
| متى يجب استخدام | جيد للقراءات المتكررة والتحديثات غير المتكررة والحذف أو تحديثات الدُفعات الكبيرة | جيد للجداول ذات التحديثات والحذف المتكررة |
ضغط البيانات
إذا كان حجم ملف البيانات الخاص بك صغيرًا ، فقد ينتهي بك الأمر مع آلاف أو ملايين الملفات في جدول Iceberg. يؤدي هذا إلى زيادة عملية الإدخال / الإخراج بشكل كبير وإبطاء الاستعلامات. علاوة على ذلك ، يتتبع Iceberg كل ملف بيانات في مجموعة بيانات. يؤدي المزيد من ملفات البيانات إلى مزيد من البيانات الوصفية. وهذا بدوره يزيد من الحمل وعملية الإدخال / الإخراج على قراءة ملفات البيانات الوصفية. لتحسين أداء الاستعلام ، يوصى بضغط ملفات البيانات الصغيرة على ملفات بيانات أكبر.
عند تحديث السجلات وحذفها في جدول Iceberg ، إذا تم استخدام أسلوب القراءة عند الدمج ، فقد ينتهي بك الأمر بالعديد من عمليات الحذف الصغيرة أو ملفات البيانات الجديدة. سيؤدي الضغط الجاري إلى دمج كل هذه الملفات وإنشاء إصدار أحدث من ملف البيانات. هذا يلغي الحاجة إلى التوفيق بينها أثناء عمليات القراءة. من المستحسن أن يكون لديك وظائف ضغط منتظمة للتأثير على القراءات بأقل قدر ممكن مع الحفاظ على سرعة كتابة أسرع.
قم بتشغيل أمر ضغط البيانات التالي ، ثم قم بتشغيل استعلام التحديد من أثينا:
يقارن الجدول التالي وقت التشغيل قبل ضغط البيانات مقابل بعده. يمكنك أن ترى حوالي 40٪ تحسن في الأداء.
| سؤال | قبل ضغط البيانات | بعد ضغط البيانات |
| وقت التشغيل (بالثواني) | 97.75 | 32.676 ثانية |
| البيانات الممسوحة ضوئيًا (ميغا بايت) | 137.16 M | 189.19 M |
لاحظ أن استعلامات التحديد تعمل على all_reviews الجدول بعد عمليات التحديث والحذف ، قبل وبعد ضغط البيانات. وقت التشغيل هو متوسط وقت التشغيل مع عدة عمليات تشغيل في اختبارنا.
تنظيف
بعد اتباع الإرشادات التفصيلية للحل لتنفيذ حالات الاستخدام ، أكمل الخطوات التالية لتنظيف مواردك وتجنب المزيد من التكاليف:
- قم بإسقاط جداول وقاعدة بيانات AWS Glue من Athena أو قم بتشغيل الكود التالي في دفتر ملاحظاتك:
- في وحدة تحكم استوديو EMR ، اختر مساحات العمل في جزء التنقل.
- حدد مساحة العمل التي قمت بإنشائها واخترها حذف.
- في وحدة تحكم EMR ، انتقل إلى ملف استوديوهات .
- حدد الاستوديو الذي قمت بإنشائه واختر حذف.
- في وحدة تحكم EMR ، اختر مجموعات في جزء التنقل.
- حدد الكتلة واختر إنهاء.
- احذف حاوية S3 وأي موارد أخرى قمت بإنشائها كجزء من المتطلبات الأساسية لهذه المشاركة.
وفي الختام
في هذا المنشور ، قدمنا إطار عمل Apache Iceberg وكيف يساعد في حل بعض التحديات التي نواجهها في بحيرة البيانات الحديثة. ثم قدمنا لك حلًا لمعالجة البيانات المتزايدة في بحيرة البيانات باستخدام Apache Iceberg. أخيرًا ، كان لدينا غوص عميق في ضبط الأداء لتحسين أداء القراءة والكتابة لحالات الاستخدام الخاصة بنا.
نأمل أن يوفر هذا المنشور بعض المعلومات المفيدة لك لتقرير ما إذا كنت تريد اعتماد Apache Iceberg في حل بحيرة البيانات الخاص بك.
حول المؤلف
 فلورا وو مهندس معماري مقيم في AWS Data Lab. تساعد عملاء المؤسسات على إنشاء استراتيجيات تحليل البيانات وبناء الحلول لتسريع نتائج أعمالهم. في أوقات فراغها ، تستمتع بلعب التنس ورقص السالسا والسفر.
فلورا وو مهندس معماري مقيم في AWS Data Lab. تساعد عملاء المؤسسات على إنشاء استراتيجيات تحليل البيانات وبناء الحلول لتسريع نتائج أعمالهم. في أوقات فراغها ، تستمتع بلعب التنس ورقص السالسا والسفر.
 دانييل لي مهندس حلول في Amazon Web Services. يركز على مساعدة العملاء في تطوير واعتماد وتنفيذ الخدمات السحابية والاستراتيجية. عندما لا يعمل ، يحب قضاء الوقت في الهواء الطلق مع أسرته.
دانييل لي مهندس حلول في Amazon Web Services. يركز على مساعدة العملاء في تطوير واعتماد وتنفيذ الخدمات السحابية والاستراتيجية. عندما لا يعمل ، يحب قضاء الوقت في الهواء الطلق مع أسرته.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- ماهرون
- من نحن
- فوق
- تسريع
- الوصول
- ادارة الوصول
- اكشن
- الأفعال
- إضافة
- إضافي
- العنوان
- عناوين
- يضيف
- تبنى
- مميزات
- بعد
- ضد
- الكل
- يسمح
- دائما
- أمازون
- أمازون EMR
- أمازون ويب سيرفيسز
- تحليلي
- تحليلات
- و
- أعلن
- أباتشي
- التطبيقات
- تطبيقي
- نهج
- اقتراب
- مناسب
- هندسة معمارية
- أسوشيتد
- التحقّق من المُستخدم
- توفر
- متاح
- المتوسط
- تجنب
- AWS
- غراء AWS
- على أساس
- لان
- أصبح
- قبل
- تستفيد
- أفضل
- ما بين
- أكبر
- التمهيد
- نساعدك في بناء
- ابني
- الأعمال
- يلتقط
- اسر
- حقيبة
- الحالات
- الأقسام
- كتالوجات
- الفئة
- التحديات
- تغيير
- التغييرات
- التحقق
- خيار
- اختار
- تصنيف
- سحابة
- الخدمات السحابية
- كتلة
- الكود
- عمود
- الأعمدة
- دمج
- تأتي
- ارتكاب
- مقارنة
- إكمال
- إحصاء
- منافس
- حالة
- تكوينات
- الاعتبارات
- كنسولات
- تحويل
- تحويلها
- فعاله من حيث التكلفه
- التكاليف
- استطاع
- خلق
- خلق
- يخلق
- من تنسيق
- حالياًّ
- زبون
- العملاء
- رقص
- لوحة أجهزة القياس
- البيانات
- تحليلات البيانات
- بحيرة البيانات
- معالجة المعلومات
- مستودع البيانات
- قاعدة البيانات
- قواعد البيانات
- عميق
- غوص عميق
- الترتيب
- تعريف
- تجربة
- شرح
- يعتمد
- تصميم
- تفاصيل
- تطوير
- التطوير التجاري
- فرق
- مختلف
- بحث
- لا
- إلى أسفل
- بشكل كبير
- قطرة
- أثناء
- كل
- في وقت سابق
- في وقت مبكر
- رئيس التحرير
- على نحو فعال
- فعال
- إما
- يقضي على
- تمكين
- تمكين
- ينتهي
- محرك
- محركات
- أدخل
- مشروع
- عملاء المؤسسة
- الأثير (ETH)
- حتى
- تطور
- يتطور
- المتطورة
- مثال
- القائمة
- موجود
- شرح
- اضافات المتصفح
- احتفل على
- يسهل
- للعائلات
- FAST
- أسرع
- المميزات
- الشكل
- قم بتقديم
- ملفات
- تصفية
- تصفية
- مرشحات
- أخيرا
- الاسم الأول
- لأول مرة
- ويركز
- اتباع
- متابعيك
- شكل
- الإطار
- متكرر
- تبدأ من
- إضافي
- علاوة على ذلك
- العلاجات العامة
- ولدت
- دولار فقط واحصل على خصم XNUMX% على جميع
- معطى
- يذهب
- خير
- جدا
- تجمع
- يد
- يحدث
- مساعدة
- مساعدة
- يساعد
- مخفي
- تسلسل
- رفيع المستوى
- أداء عالي
- عالية الأداء
- خلية النحل
- أمل
- كيفية
- كيفية
- لكن
- HTML
- HTTPS
- IAM
- هوية
- إدارة الهوية والوصول
- التأثير
- أثر
- تنفيذ
- التنفيذ
- تحقيق
- تحسن
- تحسن
- تحسين
- يحسن
- in
- بما فيه
- القيمة الاسمية
- زيادة
- الزيادات
- مؤشر
- فرد
- معلومات
- تثبيت
- بدلًا من ذلك
- التكامل
- أدخلت
- عزلة
- IT
- يناير
- المشــاريــع
- القفل
- مختبر
- بحيرة
- كبير
- أكبر
- كمون
- آخر
- أحدث إصدار
- طبقة
- طبقات
- قيادة
- ومستوياتها
- مما سيحدث
- خط
- قائمة
- القليل
- تحميل
- موقع
- جعل
- يصنع
- إدارة
- كثير
- علامة
- السوق
- مباراة
- مطابقة
- دمج
- البيانات الوصفية
- ربما
- ملايين
- تقدم
- الأكثر من ذلك
- خطوة
- متعدد
- الاسم
- عين
- التنقل
- قائمة الإختيارات
- حاجة
- بحاجة
- إحتياجات
- جديد
- مفكرة
- موضوع
- جاكيت
- عملية
- عمليات
- التحسين
- الأمثل
- طلب
- أصلي
- أخرى
- في الهواء الطلق
- الكلي
- الخاصة
- خبز
- جزء
- مسار
- أنماط
- نفذ
- أداء
- مادي
- تخطيط
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- لعب
- المساعد
- نقاط
- أكثر الاستفسارات
- ممكن
- منشور
- مدعوم
- الشروط
- الإجراءات
- عملية المعالجة
- معالجة
- إنتاج
- HAS
- الملكية
- تزود
- ويوفر
- توفير
- تقديم
- نطاق
- الخام
- مسودة بيانات
- عرض
- نادي القراءة
- حقيقي
- مؤخرا
- موصى به
- تسجيل
- تعكس
- منطقة
- سجلات
- منتظم
- الافراج عن
- صدر
- المتبقية
- مطلوب
- يتطلب
- الموارد
- نتيجة
- النتائج
- التقييمات
- النوادي الثرية
- النوع
- جذر
- يجري
- تشغيل
- نفسه
- تفحص
- ثواني
- القسم
- أمن
- مختار
- اختيار
- Serverless
- الخدمة
- خدمات
- الجلسة
- طقم
- باكجات
- ضبط
- إعدادات
- ينبغي
- إظهار
- يظهر
- الاشارات
- حالات
- حجم
- يبطئ
- صغير
- لقطة
- So
- تطبيقات الكمبيوتر
- حل
- الحلول
- بعض
- شرارة
- محدد
- سرعة
- الإنفاق
- SQL
- ابتداء
- الولايه او المحافظه
- ملخص الحساب
- البيانات
- الإحصائيات
- خطوة
- خطوات
- لا يزال
- تخزين
- متجر
- تخزين
- فروعنا
- استراتيجيات
- الإستراتيجيات
- منظم
- البيانات المنظمة وغير المهيكلة
- ستوديو
- الشبكة الفرعية
- لاحق
- بنجاح
- هذه
- كاف
- ملخص
- الدعم
- مدعومة
- دعم
- الدعم
- جدول
- يأخذ
- مع الأخذ
- الهدف
- المهام
- تقنيات
- كرة المضرب
- تجربه بالعربي
- الاختبار
- اختبارات
- •
- المعلومات
- الدولة
- من مشاركة
- وبالتالي
- الآلاف
- ثلاثة
- عبر
- الوقت
- وقت السفر
- إلى
- سويا
- جدا
- أدوات
- تيشرت
- الإجمالي
- مسار
- المعاملات
- تحويل
- سفر
- السفر
- منعطف أو دور
- أنواع
- مع
- فريد من نوعه
- تحديث
- تحديث
- آخر التحديثات
- تحديث
- URL
- تستخدم
- حالة الاستخدام
- المستخدمين
- عادة
- فال
- قيمنا
- القيم
- تحقق من
- الإصدار
- مشى
- تجول
- المخزن
- الساعات
- طرق
- الويب
- خدمات ويب
- ابحث عن
- سواء
- التي
- في حين
- واسع
- مدى واسع
- سوف
- بدون
- للعمل
- عامل
- أعمال
- سوف
- اكتب
- جاري الكتابة
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت