- একটি সময়-সিরিজ সময়-ভিত্তিক আদেশের একটি সিরিজ প্রতিনিধিত্ব করে। এটি হবে বছর, মাস, সপ্তাহ, দিন, হোরাস, মিনিট এবং সেকেন্ড
- একটি টাইম সিরিজ হল ধারাবাহিক বিরতির বিচ্ছিন্ন সময়ের ক্রম থেকে একটি পর্যবেক্ষণ।
- একটি সময় সিরিজ একটি চলমান চার্ট।
- সময় পরিবর্তনশীল/বৈশিষ্ট্য হল স্বাধীন পরিবর্তনশীল এবং ফলাফলের পূর্বাভাস দিতে লক্ষ্য পরিবর্তনশীলকে সমর্থন করে।
- টাইম সিরিজ অ্যানালাইসিস (TSA) সময়-ভিত্তিক ভবিষ্যদ্বাণীগুলির জন্য বিভিন্ন ক্ষেত্রে ব্যবহার করা হয় - যেমন আবহাওয়ার পূর্বাভাস, আর্থিক, সংকেত প্রক্রিয়াকরণ, ইঞ্জিনিয়ারিং ডোমেন - কন্ট্রোল সিস্টেম, কমিউনিকেশন সিস্টেম।
- যেহেতু টিএসএ একটি নির্দিষ্ট ক্রমানুসারে তথ্যের সেট তৈরি করে, তাই এটি স্থানিক এবং অন্যান্য বিশ্লেষণ থেকে আলাদা করে তোলে।
- AR, MA, ARMA, এবং ARIMA মডেলগুলি ব্যবহার করে, আমরা ভবিষ্যতের ভবিষ্যদ্বাণী করতে পারি৷
সময় সিরিজ বিশ্লেষণ ভূমিকা
সময় সিরিজ বিশ্লেষণ হল স্বাধীন পরিবর্তনশীল হিসাবে সময়ের সাপেক্ষে প্রতিক্রিয়া ভেরিয়েবলের বৈশিষ্ট্যগুলি অধ্যয়ন করার উপায়। ভবিষ্যদ্বাণী বা পূর্বাভাসের নামে লক্ষ্য পরিবর্তনশীল অনুমান করতে, সময় পরিবর্তনশীলটিকে রেফারেন্সের পয়েন্ট হিসাবে ব্যবহার করুন। এই নিবন্ধে আমরা বিস্তারিত আলোচনা করব TSA উদ্দেশ্য, অনুমান, উপাদান (স্থির, এবং অস্থির)। পাইথনে TSA অ্যালগরিদম এবং নির্দিষ্ট ব্যবহারের ক্ষেত্রে।
-
টাইম সিরিজ বিশ্লেষণ (TSA) এবং তার অনুমান কি
- কিভাবে বিশ্লেষণ করবেন)?
- সময় সিরিজ বিশ্লেষণ তাত্পর্য এবং তার প্রকার.
- সময় সিরিজের উপাদান
- সময় সিরিজের সীমাবদ্ধতা কি?
- সময় সিরিজ ডেটা প্রকারের বিস্তারিত অধ্যয়ন।
- স্থির এবং অস্থির উপাদান নিয়ে আলোচনা
- অস্থিরকে স্থির-এ রূপান্তর
- কেন ডেটা সায়েন্স এবং মেশিন লার্নিং-এ টাইম সিরিজ বিশ্লেষণ ব্যবহার করা হয়?
- ডেটা সায়েন্স এবং মেশিন লার্নিং-এ টাইম সিরিজ বিশ্লেষণ
- অটো-রিগ্রেসিভ মডেলের বাস্তবায়ন
- চলমান গড় বাস্তবায়ন (ওজন - সরল চলন গড়)
- ARMA এবং ARIMA বোঝা
- ARIMA এর জন্য বাস্তবায়নের পদক্ষেপ
- সময় সিরিজ বিশ্লেষণ – প্রক্রিয়া প্রবাহ (পুনরায় ফাঁক)
সময় সিরিজ বিশ্লেষণ কি
সংজ্ঞা: আপনি যদি দেখেন, TSA এর আরও অনেক সংজ্ঞা আছে। কিন্তু এটা সহজ করুন.
একটি নির্দিষ্ট সময়ের জন্য ধারাবাহিক ক্রমে ঘটে যাওয়া বিভিন্ন ডেটা পয়েন্টের একটি ক্রম ছাড়া টাইম সিরিজ কিছুই নয়
উদ্দেশ্য:
- টাইম সিরিজ কীভাবে কাজ করে তা বোঝার জন্য, বিভিন্ন সময়ে কোন নির্দিষ্ট ভেরিয়েবল(গুলি) কে প্রভাবিত করছে।
- সময় সিরিজ বিশ্লেষণ প্রদত্ত ডেটাসেটের বৈশিষ্ট্যগুলির ফলাফল এবং অন্তর্দৃষ্টি প্রদান করবে যা সময়ের সাথে সাথে পরিবর্তিত হয়।
- টাইম সিরিজ ভেরিয়েবলের ভবিষ্যত মানের ভবিষ্যদ্বাণী বের করতে সহায়তা করে।
- অনুমান: একটি এবং একমাত্র অনুমান রয়েছে যা "স্থির", যার অর্থ সময়ের উৎপত্তি, পরিসংখ্যানগত ফ্যাক্টরের অধীনে প্রক্রিয়াটির বৈশিষ্ট্যগুলিকে প্রভাবিত করে না।
সময় সিরিজ বিশ্লেষণ কিভাবে?
আপনার রেফারেন্সের জন্য এখানে দ্রুত পদক্ষেপ, যাইহোক। পরে এই নিবন্ধে এটি বিস্তারিতভাবে দেখতে পাবেন।
- তথ্য সংগ্রহ করে পরিষ্কার করা
- সময় বনাম মূল বৈশিষ্ট্য সাপেক্ষে ভিজ্যুয়ালাইজেশন প্রস্তুত করা হচ্ছে
- সিরিজের স্থিরতা পর্যবেক্ষণ করা
- এর প্রকৃতি বোঝার জন্য চার্ট তৈরি করা।
- মডেল বিল্ডিং - AR, MA, ARMA এবং ARIMA
- ভবিষ্যদ্বাণী থেকে অন্তর্দৃষ্টি নিষ্কাশন
সময় সিরিজের তাৎপর্য এবং এর প্রকার
TSA হল ভবিষ্যদ্বাণী এবং পূর্বাভাস বিশ্লেষণের মেরুদণ্ড, সময়-ভিত্তিক সমস্যা বিবৃতির জন্য নির্দিষ্ট।
- ঐতিহাসিক ডেটাসেট এবং এর নিদর্শন বিশ্লেষণ করা
- পূর্ববর্তী পর্যায় থেকে প্রাপ্ত নিদর্শনগুলির সাথে বর্তমান পরিস্থিতি বোঝা এবং মেলানো।
- বিভিন্ন সময়কালে নির্দিষ্ট পরিবর্তনশীল(গুলি) কে প্রভাবিত করে ফ্যাক্টর বা ফ্যাক্টর বোঝা।
"টাইম সিরিজ" এর সাহায্যে আমরা অনেক সময়-ভিত্তিক বিশ্লেষণ এবং ফলাফল প্রস্তুত করতে পারি।
- পূর্বাভাস
- সেগমেন্টেশন
- শ্রেণীবিন্যাস
- বর্ণনামূলক বিশ্লেষণ''
- হস্তক্ষেপ বিশ্লেষণ
সময় সিরিজ বিশ্লেষণ উপাদান
- প্রবণতা
- ঋতু
- চক্রাকার
- অনিয়ম
- প্রবণতা: যেটিতে কোনো নির্দিষ্ট ব্যবধান নেই এবং প্রদত্ত ডেটাসেটের মধ্যে কোনো ভিন্নতা একটি অবিচ্ছিন্ন সময়রেখা। প্রবণতা হবে নেতিবাচক বা ইতিবাচক বা শূন্য প্রবণতা
- ঋতু: যেটিতে নিয়মিত বা নির্দিষ্ট ব্যবধান একটি ক্রমাগত টাইমলাইনে ডেটাসেটের মধ্যে স্থানান্তরিত হয়। বেল কার্ভ বা করাত দাঁত হবে
- চক্রাকার: যেটিতে কোন নির্দিষ্ট ব্যবধান নেই, চলাচলে অনিশ্চয়তা এবং এর প্যাটার্ন
- অনিয়ম: অপ্রত্যাশিত পরিস্থিতি/ঘটনা/পরিস্থিতি এবং অল্প সময়ের মধ্যে স্পাইক।

সময় সিরিজ বিশ্লেষণের সীমাবদ্ধতা কি?
টাইম সিরিজের নিচে উল্লেখিত সীমাবদ্ধতা রয়েছে, আমাদের বিশ্লেষণের সময় সেগুলির যত্ন নিতে হবে,
- অন্যান্য মডেলের মতো, অনুপস্থিত মানগুলি TSA দ্বারা সমর্থিত নয়
- ডেটা পয়েন্ট অবশ্যই তাদের সম্পর্কের মধ্যে রৈখিক হতে হবে।
- ডেটা রূপান্তর বাধ্যতামূলক, তাই একটু ব্যয়বহুল।
- মডেলগুলি বেশিরভাগ ইউনি-ভেরিয়েট ডেটাতে কাজ করে।
সময় সিরিজের ডেটা প্রকার
টাইম সিরিজের ডাটা টাইপ এবং তাদের প্রভাব নিয়ে আলোচনা করা যাক। টিএস ডেটা-টাইপ নিয়ে আলোচনা করার সময়, দুটি প্রধান প্রকার রয়েছে।
- নিশ্চল
- অ-স্থির
6.1 নিশ্চল: একটি ডেটাসেটকে টাইম সিরিজের ট্রেন্ড, সিজন্যালিটি, সাইক্লিক্যাল, এবং অনিয়মিত উপাদান ছাড়াই নীচের থাম্ব নিয়মগুলি অনুসরণ করা উচিত
- বিশ্লেষণের সময় ডেটাতে তাদের MEAN মান সম্পূর্ণরূপে ধ্রুবক হওয়া উচিত
- সময়সীমার সাপেক্ষে VARIANCE ধ্রুবক হওয়া উচিত
- COVARIANCE দুটি ভেরিয়েবলের মধ্যে সম্পর্ক পরিমাপ করে।
6.2 নন- স্টেশনারy: এটা Stationary এর ঠিক বিপরীত।

স্থিতিশীলতা পরীক্ষা করার পদ্ধতি
TSA মডেল প্রস্তুতি কর্মপ্রবাহের সময়, প্রদত্ত ডেটাসেটটি স্থির বা না থাকলে আমাদের অবশ্যই অ্যাক্সেস করতে হবে। ব্যবহার পরিসংখ্যান এবং প্লট পরীক্ষা।
7.1 পরিসংখ্যান পরীক্ষা: ডেটাসেটটি স্থির কি না তা পরীক্ষা করার জন্য দুটি পরীক্ষা উপলব্ধ।
- অগমেন্টেড ডিকি-ফুলার (ADF) পরীক্ষা
- Kwiatkowski-Phillips-Schmidt-Shin (KPSS) টেস্ট
7.1.1 অগমেন্টেড ডিকি-ফুলার (ADF) পরীক্ষা বা ইউনিট রুট টেস্ট: ADF পরীক্ষা হল সবচেয়ে জনপ্রিয় পরিসংখ্যানগত পরীক্ষা এবং নিম্নলিখিত অনুমান সহ।
- নাল হাইপোথিসিস (H0): সিরিজ অস্থির
- বিকল্প হাইপোথিসিস (HA): সিরিজ স্থির
- p-মান >0.05 প্রত্যাখ্যান করতে ব্যর্থ (H0)
- পি-মান <= 0.05 স্বীকার করুন (H1)
7.1.2 Kwiatkowski-Philips-Schmidt-Shin (KPSS): এই পরীক্ষাগুলি একটি NULL হাইপোথিসিস (HO) পরীক্ষা করার জন্য ব্যবহার করা হয়, যা সময়-সিরিজটিকে অনুধাবন করবে, একটি ইউনিট রুটের বিকল্পের বিপরীতে একটি নির্ধারক প্রবণতার চারপাশে স্থির। যেহেতু TSA তার আরও বিশ্লেষণের জন্য স্থির ডেটা খুঁজছে, তাই আমাদের নিশ্চিত করতে হবে যে ডেটাসেটটি স্থির হওয়া উচিত।
অস্থিরকে স্থির করে রুপান্তর করা
কার্যকর টাইম সিরিজ মডেলিংয়ের জন্য কীভাবে নন-স্টেশনারিকে স্থির তে রূপান্তর করা যায় তা দ্রুত আলোচনা করা যাক। এই রূপান্তরের জন্য দুটি প্রধান পদ্ধতি উপলব্ধ আছে।
- ডিট্রেন্ডিং
- ভিন্নতা
- রুপান্তর
8.1 ডিটেনিং: এটি প্রদত্ত ডেটাসেট থেকে প্রবণতা প্রভাবগুলি অপসারণ করে এবং প্রবণতা থেকে মানগুলির মধ্যে পার্থক্যগুলি প্রদর্শন করে৷ এটি সর্বদা চক্রীয় নিদর্শন সনাক্ত করার অনুমতি দেয়।

8.2 পার্থক্য: এটি একটি নতুন টাইম সিরিজে সিরিজের একটি সাধারণ রূপান্তর, যা আমরা সময়ের উপর সিরিজ নির্ভরতা দূর করতে এবং টাইম সিরিজের গড়কে স্থিতিশীল করতে ব্যবহার করি, তাই এই রূপান্তরের সময় প্রবণতা এবং মৌসুমীতা হ্রাস পায়।
Yt = Yt – Yt-1
Yt = সময়ের সাথে মান
ডিট্রেন্ডিং এবং ডিফারেন্সিং এক্সট্রাকশন

8.3 রূপান্তর: এতে তিনটি ভিন্ন পদ্ধতি রয়েছে সেগুলো হল পাওয়ার ট্রান্সফর্ম, স্কয়ার রুট এবং লগ ট্রান্সফার।, সবচেয়ে বেশি ব্যবহৃত একটি হল লগ ট্রান্সফার।
চলমান গড় পদ্ধতি
সাধারণত ব্যবহৃত টাইম সিরিজ পদ্ধতি হল মুভিং এভারেজ। এই পদ্ধতিটি এলোমেলো স্বল্প-মেয়াদী পরিবর্তনের সাথে চটকদার। টাইম সিরিজের উপাদানগুলির সাথে তুলনামূলকভাবে যুক্ত।
চলমান গড় (MA) (বা) রোলিং মানে: যেখানে MA সময়-সিরিজের গড় ডেটা নিয়ে k সময়ের মধ্যে গণনা করেছে।
চলুন চলন্ত গড় ধরন দেখি:
- সরল মুভিং এভারেজ (SMA),
- ক্রমবর্ধমান মুভিং এভারেজ (CMA)
- সূচকীয় মুভিং গড় (EMA)
9.1 সরল মুভিং এভারেজ (SMA)
SMA হল পূর্ববর্তী M বা N পয়েন্টগুলির ওজনহীন গড়। স্লাইডিং উইন্ডো ডেটা পয়েন্ট নির্বাচন, মসৃণ করার পরিমাণের উপর নির্ভর করে পছন্দ করা হয় যেহেতু M বা N-এর মান বৃদ্ধি করে, নির্ভুলতার খরচে মসৃণতা উন্নত করে।

ভালোভাবে বোঝার জন্য, বায়ু-তাপমাত্রা ব্যবহার করবে।
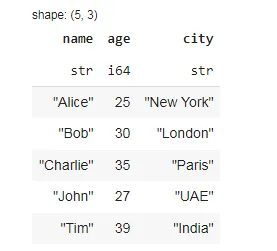
matplotlib থেকে pd হিসাবে পান্ডা আমদানি করুন statsmodels.graphics.tsaplots থেকে plt হিসাবে pyplot আমদানি করুন plot_acf df_temperature = pd.read_csv('temperature_TSA.csv', encoding='utf-8') df_temperature.head()

df_temperature.info()

# বছরের কলামের জন্য সূচক সেট করুন df_temperature.set_index('Any', inplace=True) df_temperature.index.name = 'বছর' # বার্ষিক গড় বায়ু তাপমাত্রা - গণনা df_temperature['average_temperature'] = df_temperature.mean(axis=1) # অবাঞ্ছিত কলাম বাদ দিন এবং ডেটাফ্রেম রিসেট করুন df_temperature = df_temperature[['average_temperature']] df_temperature.head()

# 10 এবং 20 বছরের সময়কালের SMA df_temperature['SMA_10'] = df_temperature.average_temperature.rolling(10, min_periods=1).mean() df_temperature['SMA_20'] = df_temperature.average_temperature, 20 মিনিট 1) মানে()
# সবুজ = গড় বায়ু তাপমাত্রা, লাল = 10 বছর, লাইন প্লটের রঙের জন্য ORANG রং = ['সবুজ', 'লাল', 'কমলা'] # লাইন প্লট df_temperature.plot(color=colors, linewidth=3, figsize= (12,6)) plt.xticks(fontsize=14) plt.yticks(fontsize=14) plt.legend(লেবেল =['গড় বায়ু তাপমাত্রা', '10-বছর SMA', '20-বছর SMA'], fontsize=14) plt.title('শহরে বার্ষিক গড় বাতাসের তাপমাত্রা', fontsize=20) plt.xlabel('বছর', fontsize=16) plt.ylabel('তাপমাত্রা [°C]', fontsize=16)

9.2 ক্রমবর্ধমান চলমান গড় (CMA)
CMA হল বর্তমান সময় পর্যন্ত অতীতের মানগুলির ওজনহীন গড়।

# CMA বাতাসের তাপমাত্রা df_temperature['CMA'] = df_temperature.average_temperature.expanding().mean()
# সবুজ -গড় বায়ু তাপমাত্রা এবং কমলা -CMA রং = ['সবুজ', 'কমলা'] # লাইন প্লট df_temperature[['Average_temperature', 'CMA']].plot(color=colors, linewidth=3, figsize=( 12,6)) plt.xticks(fontsize=14) plt.yticks(fontsize=14) plt.legend(লেবেল =['গড় বায়ু তাপমাত্রা', 'CMA'], fontsize=14) plt.title('বার্ষিক শহরের গড় বাতাসের তাপমাত্রা', fontsize=20) plt.xlabel('Year', fontsize=16) plt.ylabel('তাপমাত্রা [°C]', fontsize=16)

9.3 এক্সপোনেনশিয়াল মুভিং এভারেজ (EMA)
EMA প্রধানত প্রবণতা সনাক্ত করতে এবং শব্দ ফিল্টার করতে ব্যবহৃত হয়। উপাদানগুলির ওজন সময়ের সাথে ধীরে ধীরে হ্রাস পায়। এর মানে এটি সাম্প্রতিক ডেটা পয়েন্টগুলিতে ওজন দেয়, ঐতিহাসিক নয়। SMA এর সাথে তুলনা করে, EMA পরিবর্তনের জন্য দ্রুত এবং আরও সংবেদনশীল।
α -> স্মুথিং ফ্যাক্টর।
- এটির মান 0,1 এর মধ্যে রয়েছে।
- খুব সাম্প্রতিক সময়ের জন্য প্রয়োগ করা ওজনের প্রতিনিধিত্ব করে।
আসুন প্রদত্ত ডেটাসেটে 0.1 এবং 0.3 এর স্মুথিং ফ্যাক্টর সহ সূচকীয় চলমান গড় প্রয়োগ করব।

# EMA এয়ার টেম্পারেচার # আসুন স্মুথিং ফ্যাক্টর - 0.1 df_temperature['EMA_0.1'] = df_temperature.average_temperature.ewm(alpha=0.1, adjust=False).mean() # আসুন স্মুথিং ফ্যাক্টর - 0.3 df_temperature['EMA_E'0.3. ] = df_temperature.average_temperature.ewm(alpha=0.3, adjust=False).mean()
# সবুজ - গড় এয়ার টেম্পারেচার, লাল- স্মুথিং ফ্যাক্টর - 0.1, হলুদ - মসৃণ ফ্যাক্টর - 0.3 রং = ['সবুজ', 'লাল', 'হলুদ'] df_temperature[['Average_temperature', 'EMA_0.1', 'EMA_0.3 .3']].plot(color=colors, linewidth=12,6, figsize=(0.8), alpha=14) plt.xticks(fontsize=14) plt.yticks(fontsize=0.1) plt.legend(labels= ['গড় বাতাসের তাপমাত্রা', 'EMA - alpha=0.3', 'EMA - alpha=14'], fontsize=20) plt.title('শহরে বার্ষিক গড় বাতাসের তাপমাত্রা', fontsize=16) plt.xlabel( 'বছর', fontsize=16) plt.ylabel('তাপমাত্রা [°C]', fontsize=XNUMX)

ডেটা সায়েন্স এবং মেশিন লার্নিং-এ টাইম সিরিজ বিশ্লেষণ
ডেটা সায়েন্স এবং মেশিন লার্নিং-এ TSA-এর সাথে ডিল করার সময়, একাধিক মডেল অপশন পাওয়া যায়। যেখানে অটোরিগ্রেসিভ-মুভিং-অ্যাভারেজ (ARMA) মডেলগুলি [p, d, এবং q] সহ।
- P==> অটোরিগ্রেসিভ ল্যাগস
- q== চলমান গড় ল্যাগ
- d==> অর্ডারে পার্থক্য
আমরা আরিমা সম্পর্কে জানার আগে, প্রথমে আপনাকে নীচের শর্তগুলি আরও ভালভাবে বুঝতে হবে।
- অটো-কোরিলেশন ফাংশন (ACF)
- আংশিক অটো-কোরিলেশন ফাংশন (PACF)
10.1 অটো-কোরিলেশন ফাংশন (ACF): ACF একটি নির্দিষ্ট সময়ের সিরিজ এবং পূর্ববর্তী মানের মধ্যে একটি মান কতটা অনুরূপ তা নির্দেশ করতে ব্যবহৃত হয়। (অথবা) এটি একটি নির্দিষ্ট সময়ের সিরিজ এবং সেই সময় সিরিজের পিছিয়ে থাকা সংস্করণের মধ্যে সাদৃশ্যের মাত্রা পরিমাপ করে বিভিন্ন বিরতিতে যা আমরা পর্যবেক্ষণ করেছি।
Python Statsmodels লাইব্রেরি স্বয়ংক্রিয় সম্পর্ক গণনা করে। এটি প্রদত্ত ডেটাসেটের প্রবণতাগুলির একটি সেট এবং বর্তমানে পর্যবেক্ষণ করা মানগুলির উপর পূর্বের পর্যবেক্ষিত মানগুলির প্রভাব সনাক্ত করতে ব্যবহৃত হয়।
10.2 আংশিক স্বয়ংক্রিয় সম্পর্ক (PACF): PACF অটো-কোরিলেশন ফাংশনের অনুরূপ এবং বুঝতে একটু চ্যালেঞ্জিং। এটি সর্বদা ক্রম প্রতি ক্রমানুসারে কিছু সংখ্যক সময়ের এককের সাথে নিজের সাথে ক্রমটির পারস্পরিক সম্পর্ক দেখায় যেখানে শুধুমাত্র সরাসরি প্রভাব দেখানো হয়েছে এবং প্রদত্ত সময় সিরিজ থেকে অন্য সমস্ত মধ্যস্থতাকারী প্রভাবগুলি সরানো হয়েছে।
স্বয়ংক্রিয় সম্পর্ক এবং আংশিক স্বয়ংক্রিয় সম্পর্ক
plot_acf(df_temperature) plt.show()
plot_acf(df_temperature, lags=30) plt.show()

পর্যবেক্ষণ: পূর্ববর্তী তাপমাত্রা বর্তমান তাপমাত্রাকে প্রভাবিত করে, তবে সেই প্রভাবের তাত্পর্য নিয়মিত সময়ের ব্যবধানের সাথে তাপমাত্রার সাথে উপরের দৃশ্যায়ন থেকে হ্রাস পায় এবং সামান্য বৃদ্ধি পায়।
10.3 অটো-সম্পর্কের প্রকার

10.4 ACF এবং PACF প্লট ব্যাখ্যা করুন
| এসিএফ |
PACF |
পারফেক্ট এমএল -মডেল |
| প্লট ধীরে ধীরে হ্রাস পায় | প্লট সঙ্গে সঙ্গে ড্রপ | অটো রিগ্রেসিভ মডেল। |
| প্লট সঙ্গে সঙ্গে ড্রপ | প্লট ধীরে ধীরে হ্রাস পায় | চলমান গড় মডেল |
| প্লট ধীরে ধীরে হ্রাস | প্লট ধীরে ধীরে হ্রাস | এআরএমএ |
| প্লট অবিলম্বে ড্রপ | প্লট অবিলম্বে ড্রপ | আপনি কোন মডেল সঞ্চালন হবে না |
মনে রাখবেন যে ACF এবং PACF উভয়েরই বিশ্লেষণের জন্য স্থির সময়ের সিরিজ প্রয়োজন।
এখন, আমরা সম্পর্কে শিখেছি অটো-রিগ্রেসিভ মডেল
এটি একটি সাধারণ মডেল, যা অতীতের পারফরম্যান্সের উপর ভিত্তি করে ভবিষ্যৎ কর্মক্ষমতার পূর্বাভাস দেয়। প্রধানত পূর্বাভাসের জন্য ব্যবহৃত হয়, যখন একটি নির্দিষ্ট সময়ের সিরিজের মান এবং পূর্বে এবং সফল (আগে এবং পিছনে) মানগুলির মধ্যে কিছু সম্পর্ক থাকে।
একটি AR মডেল হল একটি লিনিয়ার রিগ্রেশন মডেল, যা ইনপুট হিসাবে ল্যাগড ভেরিয়েবল ব্যবহার করে। লিনিয়ার রিগ্রেশন মডেলটি ব্যবহার করার জন্য ইনপুট নির্দেশ করে স্কিট-লার্ন লাইব্রেরি ব্যবহার করে সহজেই তৈরি করা যেতে পারে। স্ট্যাটসমডেলস লাইব্রেরি অটোরিগ্রেশন মডেল-নির্দিষ্ট ফাংশন প্রদান করতে ব্যবহৃত হয় যেখানে আপনাকে একটি উপযুক্ত ল্যাগ মান নির্দিষ্ট করতে হবে এবং মডেলটিকে প্রশিক্ষণ দিতে হবে। সহজ ধাপগুলি ব্যবহার করে ফলাফল পেতে এটি AutoTeg ক্লাসে প্রদান করা হয়
AR মডেলের সমীকরণ (আসুন Y=mX+c তুলনা করা যাক)
Yt =C+b1 Yটি-1+ খ2 Yটি-2+……+ খp Yটিপি+ এরt
মূল পরামিতি
- p=অতীত মান
- Yt= বিভিন্ন অতীত মানের ফাংশন
- Ert= সময়ে ত্রুটি
- C = বাধা
আসুন পরীক্ষা করে দেখি, প্রদত্ত ডেটা-সেট বা টাইম সিরিজ এলোমেলো কি না
matplotlib থেকে pandas.plotting আমদানি lag_plot lag_plot(df_temperature) pyplot.show() থেকে আমদানি pyplot

পর্যবেক্ষণ: হ্যাঁ, এলোমেলো এবং বিক্ষিপ্ত দেখায়।
অটো-রিগ্রেসিভ মডেলের বাস্তবায়ন
matplotlib থেকে লাইব্রেরি আমদানি করুন statsmodels.tsa.ar_model থেকে pyplot আমদানি করুন sklearn.metrics থেকে অটোরেগ আমদানি করুন গণিত আমদানি sqrt থেকে mean_squared_error # লোড csv ডেটাসেট হিসাবে #series = read_csv('daily-min-temperatures.col=csv', index) =0, parse_dates=True, squeeze=True) # পরীক্ষা এবং প্রশিক্ষণের জন্য বিভক্ত ডেটাসেট X = df_temperature.values ট্রেন, পরীক্ষা = X[0:len(X)-1], X[len(X)-7:] # ট্রেন অটোরিগ্রেশন মডেল = AutoReg(train, lags=7) model_fit = model.fit() print('coefficients: %s' % model_fit.params) # ভবিষ্যদ্বাণী পূর্বাভাস = model_fit.predict(start=len(train), end=len (ট্রেন)+লেন(পরীক্ষা)-20, ডাইনামিক=ফলস) রেঞ্জে i এর জন্য(লেন(ভবিষ্যদ্বাণী)): প্রিন্ট('ভবিষ্যদ্বাণী=%f, প্রত্যাশিত=%f' % (ভবিষ্যদ্বাণী[i], পরীক্ষা[i] )) rmse = sqrt(mean_squared_error(test, predictions)) print('Test RMSE: %.1f' % rmse) # প্লটের ফলাফল pyplot.plot(test) pyplot.plot(ভবিষ্যদ্বাণী, রঙ='লাল') pyplot.show ()
আউটপুট
ভবিষ্যদ্বাণী=15.893972, প্রত্যাশিত=16.275000 পূর্বাভাস=15.917959, প্রত্যাশিত=16.600000 পূর্বাভাস=15.812741, প্রত্যাশিত=16.475000 পূর্বাভাস=15.787555, প্রত্যাশিত=16.375000, প্রত্যাশিত=16.023780=16.283333 15.940271 ভবিষ্যদ্বাণী=16.525000, প্রত্যাশিত=15.831538 পূর্বাভাস=16.758333, প্রত্যাশিত=0.617 পরীক্ষা RMSE: XNUMX

পর্যবেক্ষণ: প্রত্যাশিত (নীল) পূর্বাভাসের বিপরীতে (লাল)। পূর্বাভাস 4 তারিখে ভাল এবং 6 তম দিনে বিচ্যুতি দেখা যাচ্ছে।
চলমান গড় বাস্তবায়ন (ওজন - সরল চলন গড়)
np alpha= 0.3 n = 10 w_sma = np.repeat(1/n, n) রং = ['সবুজ', 'হলুদ'] # ওজন - সূচকীয় চলমান গড় আলফা=0.3 সামঞ্জস্য = মিথ্যা w_ema = [(1) হিসাবে আমদানি করুন -ALPHA)**i if i==N-1 else alpha*(1-alpha)**i for i range(n)] pd.DataFrame({'w_sma': w_sma, 'w_ema': w_ema}) .plot(color=colors, kind='bar', figsize=(8,5)) plt.xticks([]) plt.yticks(fontsize=10) plt.legend(labels=['সিম্পল মুভিং এভারেজ',' সূচকীয় চলমান গড় (α=0.3)'], fontsize=10) # শিরোনাম এবং লেবেল plt.title('Moving Average Weights', fontsize=10) plt.ylabel('ওজন', fontsize=10)

ARMA এবং ARIMA বোঝা
এআরএমএ এটি পূর্বাভাসের জন্য অটো-রিগ্রেসিভ এবং মুভিং এভারেজ মডেলের সংমিশ্রণ। এই মডেল দুটি বহুপদে একটি দুর্বলভাবে স্থির স্টোকাস্টিক প্রক্রিয়া প্রদান করে, একটি অটো-রিগ্রেসিভের জন্য এবং দ্বিতীয়টি মুভিং এভারেজের জন্য।

এআরএমএ স্থির সিরিজের পূর্বাভাস দেওয়ার জন্য সেরা। সুতরাং ARIMA এসেছে যেহেতু এটি স্থির এবং অস্থির সমর্থন করে।

AR+I+MA= আরিমা
আরিমার স্বাক্ষর বুঝে নিন
- p==> লগ অর্ডার => ল্যাগ পর্যবেক্ষণের সংখ্যা।
- d==> ডিগ্রী ডিফারেন্সিং => কতবার অশোধিত পর্যবেক্ষণের পার্থক্য হয়।
- q==>অর্ডার অফ মুভিং এভারেজ => মুভিং এভারেজ উইন্ডোর সাইজ
ARIMA এর জন্য বাস্তবায়নের পদক্ষেপ
ধাপ 1: একটি সময় সিরিজ বিন্যাস প্লট করুন
ধাপ 2: প্রবণতা অপসারণ করে গড় উপর স্থির করার পার্থক্য
ধাপ 3: লগ ট্রান্সফর্ম প্রয়োগ করে স্থির করুন।
ধাপ 4: পরিসংখ্যান গড় এবং প্রকরণ উভয়ের উপর স্থির হিসাবে পার্থক্য লগ রূপান্তর
ধাপ 5: ACF এবং PACF প্লট করুন এবং সম্ভাব্য AR এবং MA মডেল শনাক্ত করুন
ধাপ 6: সেরা ফিট ARIMA মডেলের আবিষ্কার
ধাপ 7: সবচেয়ে উপযুক্ত ARIMA মডেল ব্যবহার করে মানটির পূর্বাভাস/পূর্বাভাস করুন
ধাপ 8: ARIMA মডেলের অবশিষ্টাংশের জন্য ACF এবং PACF প্লট করুন এবং নিশ্চিত করুন যে আর কোনো তথ্য অবশিষ্ট নেই।
ARIMA বাস্তবায়ন
ইতিমধ্যে আমরা 1-5 ধাপ নিয়ে আলোচনা করেছি, আসুন এখানে বাকিগুলির উপর ফোকাস করি।
statsmodels.tsa.arima_model থেকে আমদানি করুন ARIMA মডেল = ARIMA(df_temperature, order=(0, 1, 1)) results_ARIMA = model.fit()
ফলাফল_ARIMA.summary()

results_ARIMA.forecast(3)[0]
আউটপুট
অ্যারে([16.47648941, 16.48621826, 16.49594711])
results_ARIMA.plot_predict(start=200) plt.show()

(পুনরায় ফাঁক)


রিকারেন্ট নিউরাল নেটওয়ার্ক হল সবচেয়ে ঐতিহ্যবাহী এবং গৃহীত স্থাপত্য, সময়-সিরিজের পূর্বাভাস ভিত্তিক সমস্যার জন্য উপযুক্ত।
RNN ধারাবাহিক স্তরে সংগঠিত এবং বিভক্ত
- ইনপুট
- গোপন
- আউটপুট
প্রতিটি স্তরের সমান ওজন রয়েছে এবং প্রতিটি নিউরনকে নির্দিষ্ট সময়ের ধাপে বরাদ্দ করতে হবে। এবং মনে রাখবেন যে তাদের প্রত্যেকটি একটি লুকানো স্তরের (ইনপুট এবং আউটপুট) সাথে একই সময়ের পদক্ষেপের সাথে সম্পূর্ণভাবে সংযুক্ত এবং লুকানো স্তরগুলি ফরোয়ার্ড করা হয় এবং সময়-নির্ভর দিকনির্দেশিত হয়।

RNN এর উপাদান
- ইনপুট: x(t) এর ফাংশন ভেক্টর হল ইনপুট, সময়ে ধাপ টি।
-
গোপন:
- ফাংশন ভেক্টর h(t) হল টি সময়ে লুকানো অবস্থা,
- এটি প্রতিষ্ঠিত নেটওয়ার্কের এক ধরনের মেমরি;
- বর্তমান ইনপুট x(t) এবং পূর্ববর্তী ধাপের হিডেন-স্টেট h(t-1) এর উপর ভিত্তি করে এটি গণনা করা হয়েছে:
- আউটপুট: ফাংশন ভেক্টর y(t) হল আউটপুট, সময়ে ধাপ টি।
- ওজন : ওজন: RNN-এ, ইনপুট ভেক্টর-সংযুক্ত লুকানো স্তর নিউরনের সাথে টি সময়ে একটি ওজন ম্যাট্রিক্স দ্বারা U (উপরের ছবিটি পড়ুন দয়া করে),
অভ্যন্তরীণ ওজন ম্যাট্রিক্স W T-1 এবং t+1 সময়ের লুকানো স্তর নিউরন দ্বারা গঠিত হয়। এর পরে এই হিডেন-লেয়ারটি আউটপুট ভেক্টর y(t) এর সাথে সময় t দ্বারা a V (ওজন ম্যাট্রিক্স); সমস্ত ওজন ম্যাট্রিক্স U, W, এবং V প্রতিটি সময় ধাপের জন্য ধ্রুবক।
| উপকারিতা | অসুবিধা সমূহ |
| এটির বিশেষ বৈশিষ্ট্য রয়েছে যে এটি প্রতিটি তথ্য মনে রাখবে, তাই RNN সময় সিরিজের পূর্বাভাসের জন্য অনেক বেশি কার্যকর | বড় চ্যালেঞ্জ হল প্রশিক্ষণের সময়। |
| ইনপুট টাইম সিরিজ ডেটাসেট থেকে জটিল নিদর্শন তৈরি করার জন্য উপযুক্ত। | ব্যয়বহুল গণনা খরচ |
| ভবিষ্যদ্বাণী/পূর্বাভাসে দ্রুত | |
| অনুপস্থিত মান দ্বারা প্রভাবিত হয় না, তাই পরিস্কার প্রক্রিয়া সীমিত হতে পারে |
আমি বিশ্বাস করি এই গাইডটি আপনাকে সকলকে সাহায্য করবে, সময় সিরিজ, প্রবাহ এবং এটি কীভাবে কাজ করে তা বুঝতে।
এই নিবন্ধে দেখানো মিডিয়া Analytics বিদ্যার মালিকানাধীন নয় এবং লেখকের বিবেচনার ভিত্তিতে ব্যবহার করা হয়।
সূত্র: https://www.analyticsvidhya.com/blog/2021/10/a-comprehensive-guide-to-time-series-analysis/
- "
- &
- 11
- 7
- 9
- প্রবেশ
- অ্যালগরিদম
- সব
- বিশ্লেষণ
- বৈশ্লেষিক ন্যায়
- AR
- স্থাপত্য
- কাছাকাছি
- প্রবন্ধ
- গাড়ী
- গড়
- ঘণ্টা
- সর্বোত্তম
- ভবন
- যত্ন
- মামলা
- চ্যালেঞ্জ
- পরিবর্তন
- চার্ট
- শহর
- পরিস্কার করা
- স্তম্ভ
- যোগাযোগমন্ত্রী
- উপাদান
- পরিবর্তন
- তৈরি করা হচ্ছে
- বর্তমান
- বাঁক
- উপাত্ত
- তথ্য বিজ্ঞান
- দিন
- ডিলিং
- গভীর জ্ঞানার্জন
- বিস্তারিত
- আবিষ্কার
- ড্রপ
- কার্যকর
- ইএমএ
- প্রকৌশল
- বৈশিষ্ট্য
- বৈশিষ্ট্য
- ক্ষেত্রসমূহ
- আর্থিক
- প্রথম
- ফিট
- প্রবাহ
- কেন্দ্রবিন্দু
- অনুসরণ করা
- ক্রিয়া
- ভবিষ্যৎ
- ভাল
- Green
- কৌশল
- মাথা
- এখানে
- কিভাবে
- কিভাবে
- HTTPS দ্বারা
- সনাক্ত করা
- ভাবমূর্তি
- সূচক
- প্রভাব
- তথ্য
- অর্ন্তদৃষ্টি
- IT
- চাবি
- লেবেলগুলি
- শিখতে
- শিক্ষা
- লাইব্রেরি
- লাইন
- বোঝা
- মেশিন লার্নিং
- মুখ্য
- গণিত
- জরায়ু
- মিডিয়া
- ছন্দোবিজ্ঞান
- ML
- মডেল
- মূর্তিনির্মাণ
- মাসের
- সবচেয়ে জনপ্রিয়
- নেটওয়ার্ক
- নেটওয়ার্ক
- নিউরাল
- নিউরাল নেটওয়ার্ক
- গোলমাল
- অপশন সমূহ
- ক্রম
- আদেশ
- অন্যান্য
- কর্মক্ষমতা
- ছবি
- জনপ্রিয়
- ক্ষমতা
- ভবিষ্যদ্বাণী
- ভবিষ্যতবাণী
- পাইথন
- কাঁচা
- প্রত্যাগতি
- প্রতিক্রিয়া
- বিশ্রাম
- ফলাফল
- নিয়ম
- দৌড়
- বিজ্ঞান
- ক্রম
- সেট
- সংক্ষিপ্ত
- সহজ
- আয়তন
- So
- স্থান-সংক্রান্ত
- বিভক্ত করা
- বর্গক্ষেত্র
- পর্যায়
- অধ্যয়ন
- সমর্থিত
- সমর্থন
- সিস্টেম
- লক্ষ্য
- পরীক্ষা
- পরীক্ষামূলক
- পরীক্ষা
- ভবিষ্যৎ
- সময়
- প্রশিক্ষণ
- রুপান্তর
- প্রবণতা
- মূল্য
- কল্পনা
- W
- মধ্যে
- হয়া যাই ?
- কর্মপ্রবাহ
- কাজ
- X
- বছর
- বছর