আমাজন সেজমেকার একটি সম্পূর্ণরূপে পরিচালিত মেশিন লার্নিং (ML) পরিষেবা৷ SageMaker-এর সাথে, ডেটা বিজ্ঞানী এবং বিকাশকারীরা দ্রুত এবং সহজে ML মডেলগুলি তৈরি এবং প্রশিক্ষণ দিতে পারে এবং তারপরে সরাসরি একটি উত্পাদন-প্রস্তুত হোস্ট করা পরিবেশে স্থাপন করতে পারে৷ এটি অনুসন্ধান এবং বিশ্লেষণের জন্য আপনার ডেটা উত্সগুলিতে সহজে অ্যাক্সেসের জন্য একটি সমন্বিত জুপিটার অথরিং নোটবুক উদাহরণ প্রদান করে, তাই আপনাকে সার্ভারগুলি পরিচালনা করতে হবে না। এটি সাধারণ প্রদান করে এমএল অ্যালগরিদম যেগুলি একটি বিতরণ করা পরিবেশে অত্যন্ত বড় ডেটার বিরুদ্ধে দক্ষতার সাথে চালানোর জন্য অপ্টিমাইজ করা হয়েছে।
সেজমেকার রিয়েল-টাইম ইনফারেন্স এমন কাজের চাপের জন্য আদর্শ যেগুলির রিয়েল-টাইম, ইন্টারেক্টিভ, কম লেটেন্সি প্রয়োজনীয়তা রয়েছে। SageMaker রিয়েল-টাইম ইনফারেন্সের সাহায্যে, আপনি REST এন্ডপয়েন্ট স্থাপন করতে পারেন যা একটি নির্দিষ্ট ইনস্ট্যান্স টাইপ দ্বারা সমর্থিত একটি নির্দিষ্ট পরিমাণ গণনা এবং মেমরির সাথে। একটি সেজমেকার রিয়েল-টাইম এন্ডপয়েন্ট স্থাপন করা অনেক গ্রাহকের জন্য উৎপাদনের পথে প্রথম ধাপ মাত্র। লেটেন্সি প্রয়োজনীয়তা মেনে চলার সময় আমরা প্রতি সেকেন্ডে একটি লক্ষ্য লেনদেন (TPS) অর্জনের জন্য এন্ডপয়েন্টের কর্মক্ষমতা সর্বাধিক করতে সক্ষম হতে চাই। অনুমানের জন্য পারফরম্যান্স অপ্টিমাইজেশানের একটি বড় অংশ নিশ্চিত করছে যে আপনি সঠিক উদাহরণের ধরণ নির্বাচন করেছেন এবং একটি শেষ পয়েন্ট ব্যাক করতে গণনা করেছেন।
এই পোস্টটি দৃষ্টান্তের সংখ্যা এবং আকারের জন্য সঠিক কনফিগারেশন খুঁজে পেতে একটি সেজমেকার এন্ডপয়েন্ট লোড পরীক্ষার জন্য সর্বোত্তম অনুশীলনগুলি বর্ণনা করে। এটি আমাদের লেটেন্সি এবং TPS প্রয়োজনীয়তাগুলি পূরণ করার জন্য ন্যূনতম প্রভিশন করা উদাহরণের প্রয়োজনীয়তাগুলি বুঝতে সাহায্য করতে পারে৷ সেখান থেকে, আপনি কীভাবে সেজমেকার এন্ডপয়েন্ট ব্যবহার করে মেট্রিক্স এবং পারফরম্যান্স ট্র্যাক করতে এবং বুঝতে পারবেন সে বিষয়ে আমরা ডুব দিয়েছি অ্যামাজন ক্লাউডওয়াচ মেট্রিক্স।
আমরা প্রথমে একটি একক উদাহরণে আমাদের মডেলের কার্যকারিতা বেঞ্চমার্ক করি যাতে এটি আমাদের গ্রহণযোগ্য লেটেন্সি প্রয়োজনীয়তা অনুযায়ী যে TPS পরিচালনা করতে পারে তা শনাক্ত করতে পারে। তারপরে আমরা আমাদের উত্পাদন ট্র্যাফিক পরিচালনা করার জন্য আমাদের প্রয়োজনীয় দৃষ্টান্তগুলির সংখ্যা নির্ধারণ করার জন্য ফলাফলগুলিকে এক্সট্রাপোলেট করি। অবশেষে, আমরা প্রোডাকশন-লেভেল ট্র্যাফিক সিমুলেট করি এবং আমাদের এন্ডপয়েন্ট প্রোডাকশন-লেভেল লোড পরিচালনা করতে পারে তা নিশ্চিত করতে একটি রিয়েল-টাইম সেজমেকার এন্ডপয়েন্টের জন্য লোড পরীক্ষা সেট আপ করি। উদাহরণের জন্য কোডের সম্পূর্ণ সেট নিম্নলিখিত পাওয়া যায় GitHub সংগ্রহস্থল.
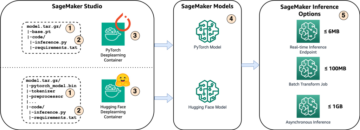
সমাধান ওভারভিউ
এই পোস্টের জন্য, আমরা একজন প্রাক-প্রশিক্ষিত মোতায়েন করি হাগিং ফেস ডিস্টিলবার্ট মডেল থেকে আলিঙ্গন ফেস হাব. এই মডেলটি বেশ কয়েকটি কাজ সম্পাদন করতে পারে, তবে আমরা বিশেষভাবে অনুভূতি বিশ্লেষণ এবং পাঠ্য শ্রেণীবিভাগের জন্য একটি পেলোড পাঠাই। এই নমুনা পেলোডের মাধ্যমে, আমরা 1000 টিপিএস অর্জনের চেষ্টা করি।
একটি রিয়েল-টাইম এন্ডপয়েন্ট স্থাপন করুন
এই পোস্টটি অনুমান করে যে আপনি কীভাবে একটি মডেল স্থাপন করবেন তার সাথে পরিচিত। নির্দেশ করে আপনার এন্ডপয়েন্ট তৈরি করুন এবং আপনার মডেল স্থাপন করুন একটি শেষ পয়েন্ট হোস্টিং পিছনে অভ্যন্তরীণ বুঝতে. আপাতত, আমরা হাগিং ফেস হাবে এই মডেলটিকে দ্রুত নির্দেশ করতে পারি এবং নিম্নলিখিত কোড স্নিপেট সহ একটি রিয়েল-টাইম এন্ডপয়েন্ট স্থাপন করতে পারি:
আসুন আমরা লোড পরীক্ষার জন্য যে নমুনা পেলোড ব্যবহার করতে চাই তার সাথে দ্রুত আমাদের শেষ পয়েন্টটি পরীক্ষা করি:

মনে রাখবেন যে আমরা একটি একক ব্যবহার করে শেষ বিন্দুকে সমর্থন করছি অ্যামাজন ইলাস্টিক কম্পিউট ক্লাউড (Amazon EC2) ml.m5.12xlarge টাইপের উদাহরণ, যাতে 48 vCPU এবং 192 GiB মেমরি রয়েছে। ভিসিপিইউ-এর সংখ্যা দৃষ্টান্ত পরিচালনা করতে পারে এমন একযোগে একটি ভাল ইঙ্গিত। সাধারণভাবে, আমাদের কাছে এমন একটি উদাহরণ আছে যা সঠিকভাবে ব্যবহার করা হয়েছে তা নিশ্চিত করতে বিভিন্ন ধরনের উদাহরণ পরীক্ষা করার পরামর্শ দেওয়া হয়। রিয়েল-টাইম ইনফারেন্সের জন্য সেজমেকার দৃষ্টান্তগুলির একটি সম্পূর্ণ তালিকা এবং তাদের সংশ্লিষ্ট গণনা শক্তি দেখতে, পড়ুন অ্যামাজন সেজমেকার প্রাইসিং.
ট্র্যাক করার মেট্রিক্স
আমরা লোড টেস্টিং এ যাওয়ার আগে, আপনার SageMaker এন্ডপয়েন্টের পারফরম্যান্স ব্রেকডাউন বোঝার জন্য কোন মেট্রিক্স ট্র্যাক করতে হবে তা বোঝা অপরিহার্য। ক্লাউডওয়াচ হল প্রাথমিক লগিং টুল যা সেজমেকার আপনাকে বিভিন্ন মেট্রিক্স বুঝতে সাহায্য করতে ব্যবহার করে যা আপনার এন্ডপয়েন্টের কর্মক্ষমতা বর্ণনা করে। আপনি আপনার এন্ডপয়েন্ট ইনভোকেশন ডিবাগ করতে CloudWatch লগ ব্যবহার করতে পারেন; আপনার অনুমান কোডে থাকা সমস্ত লগিং এবং প্রিন্ট স্টেটমেন্ট এখানে ক্যাপচার করা হয়েছে। আরো তথ্যের জন্য, পড়ুন অ্যামাজন ক্লাউডওয়াচ কীভাবে কাজ করে.
সেজমেকারের জন্য ক্লাউডওয়াচ কভারের দুটি ভিন্ন ধরনের মেট্রিক্স রয়েছে: ইনস্ট্যান্স-লেভেল এবং ইনভোকেশন মেট্রিক্স।
দৃষ্টান্ত-স্তরের মেট্রিক্স
বিবেচনা করার পরামিতিগুলির প্রথম সেটটি হল ইনস্ট্যান্স-লেভেল মেট্রিক্স: CPUUtilization এবং MemoryUtilization (GPU-ভিত্তিক উদাহরণের জন্য, GPUUtilization)। জন্য CPUUtilization, আপনি ক্লাউডওয়াচে প্রথমে 100% এর উপরে শতাংশ দেখতে পারেন। এটা জন্য উপলব্ধি করা গুরুত্বপূর্ণ CPUUtilization, সমস্ত CPU কোরের সমষ্টি প্রদর্শিত হচ্ছে। উদাহরণস্বরূপ, যদি আপনার এন্ডপয়েন্টের পিছনের উদাহরণে 4টি vCPU থাকে, তাহলে এর অর্থ হল ব্যবহারের পরিসীমা 400% পর্যন্ত। MemoryUtilization, অন্যদিকে, 0-100% এর মধ্যে।
বিশেষ করে, আপনি ব্যবহার করতে পারেন CPUUtilization আপনার কাছে পর্যাপ্ত বা অতিরিক্ত পরিমাণ হার্ডওয়্যার আছে কিনা তা গভীরভাবে বোঝার জন্য। যদি আপনার একটি কম-ব্যবহৃত উদাহরণ থাকে (30% এর কম), আপনি সম্ভাব্যভাবে আপনার উদাহরণের ধরন কমিয়ে দিতে পারেন। বিপরীতভাবে, আপনি যদি প্রায় 80-90% ব্যবহার করেন, তাহলে বৃহত্তর গণনা/মেমরি সহ একটি উদাহরণ বাছাই করা উপকারী হবে। আমাদের পরীক্ষা থেকে, আমরা আপনার হার্ডওয়্যারের প্রায় 60-70% ব্যবহারের পরামর্শ দিই।
আমন্ত্রণ মেট্রিক্স
নামের দ্বারা প্রস্তাবিত, আমন্ত্রণ মেট্রিক্স হল যেখানে আমরা আপনার শেষ পয়েন্টে যেকোনও আহ্বানের শেষ থেকে শেষ লেটেন্সি ট্র্যাক করতে পারি। আপনার এন্ডপয়েন্টের সম্মুখীন হতে পারে এমন ত্রুটির সংখ্যা এবং কি ধরনের ত্রুটি (5xx, 4xx এবং আরও) ক্যাপচার করতে আপনি আমন্ত্রণ মেট্রিক্স ব্যবহার করতে পারেন। আরও গুরুত্বপূর্ণ, আপনি আপনার এন্ডপয়েন্ট কলগুলির লেটেন্সি ব্রেকডাউন বুঝতে পারেন। এর সাথে অনেক কিছু ধরা যায় ModelLatency এবং OverheadLatency মেট্রিক্স, যেমন নিম্নলিখিত চিত্রে চিত্রিত করা হয়েছে।

সার্জারির ModelLatency মেট্রিক সেজমেকার এন্ডপয়েন্টের পিছনে মডেল কন্টেইনারের মধ্যে যে সময় নেয় তা ক্যাপচার করে। নোট করুন যে মডেল কন্টেনারে আপনার অনুমানের জন্য পাস করা কোনো কাস্টম ইনফারেন্স কোড বা স্ক্রিপ্টও অন্তর্ভুক্ত থাকে। এই ইউনিটটি একটি ইনভোকেশন মেট্রিক হিসাবে মাইক্রোসেকেন্ডে ক্যাপচার করা হয় এবং আপনি সাধারণত ক্লাউডওয়াচ (p99, p90 এবং আরও) জুড়ে একটি শতাংশ গ্রাফ করতে পারেন যে আপনি আপনার লক্ষ্য লেটেন্সি পূরণ করছেন কিনা। মনে রাখবেন যে বেশ কয়েকটি কারণ মডেল এবং কন্টেইনার লেটেন্সিকে প্রভাবিত করতে পারে, যেমন নিম্নলিখিতগুলি:
- কাস্টম অনুমান স্ক্রিপ্ট – আপনি আপনার নিজের কন্টেইনার প্রয়োগ করেছেন বা কাস্টম ইনফারেন্স হ্যান্ডলার সহ একটি সেজমেকার-ভিত্তিক কন্টেইনার ব্যবহার করেছেন কিনা, আপনার স্ক্রিপ্টটি প্রোফাইল করা সর্বোত্তম অভ্যাস যাতে আপনার লেটেন্সিতে বিশেষভাবে অনেক সময় যুক্ত হয় এমন কোনো অপারেশন ধরা যায়।
- যোগাযোগ নীতি - মডেল কন্টেইনারের মধ্যে মডেল সার্ভারে REST বনাম gRPC সংযোগ বিবেচনা করুন।
- মডেল ফ্রেমওয়ার্ক অপ্টিমাইজেশান - এই ফ্রেমওয়ার্ক নির্দিষ্ট, উদাহরণস্বরূপ সঙ্গে TensorFlow, এমন অনেকগুলি পরিবেশের ভেরিয়েবল রয়েছে যা আপনি টিউন করতে পারেন যা TF পরিবেশন নির্দিষ্ট। আপনি কোন ধারকটি ব্যবহার করছেন তা পরীক্ষা করে দেখুন এবং যদি কোনও কাঠামো-নির্দিষ্ট অপ্টিমাইজেশন থাকে তবে আপনি স্ক্রিপ্টের মধ্যে বা কন্টেইনারে ইনজেক্ট করার জন্য পরিবেশের ভেরিয়েবল হিসাবে যোগ করতে পারেন।
OverheadLatency SageMaker অনুরোধটি পাওয়ার সময় থেকে পরিমাপ করা হয় যতক্ষণ না এটি ক্লায়েন্টের কাছে একটি প্রতিক্রিয়া ফেরত দেয়, মডেল লেটেন্সি বিয়োগ করে। এই অংশটি মূলত আপনার নিয়ন্ত্রণের বাইরে এবং সেজমেকার ওভারহেডগুলির দ্বারা নেওয়া সময়ের অধীনে পড়ে।
সামগ্রিকভাবে এন্ড-টু-এন্ড লেটেন্সি বিভিন্ন কারণের উপর নির্ভর করে এবং অগত্যা এর সমষ্টি নয় ModelLatency যোগ OverheadLatency. উদাহরণস্বরূপ, যদি আপনি ক্লায়েন্ট তৈরি করছেন InvokeEndpoint ইন্টারনেটের মাধ্যমে API কল, ক্লায়েন্টের দৃষ্টিকোণ থেকে, শেষ থেকে শেষ লেটেন্সি হবে ইন্টারনেট + ModelLatency + OverheadLatency. যেমন, এন্ডপয়েন্টকে সঠিকভাবে বেঞ্চমার্ক করার জন্য আপনার এন্ডপয়েন্ট পরীক্ষা করার সময়, এন্ডপয়েন্ট মেট্রিক্সের উপর ফোকাস করার পরামর্শ দেওয়া হয় (ModelLatency, OverheadLatency, এবং InvocationsPerInstance) সঠিকভাবে সেজমেকার এন্ডপয়েন্ট বেঞ্চমার্ক করতে। এন্ড-টু-এন্ড লেটেন্সি সম্পর্কিত যেকোনো সমস্যা তারপর আলাদাভাবে আলাদা করা যেতে পারে।
শেষ থেকে শেষ বিলম্বের জন্য বিবেচনা করার জন্য কয়েকটি প্রশ্ন:
- ক্লায়েন্ট কোথায় যে আপনার শেষ পয়েন্ট আহ্বান করা হয়?
- আপনার ক্লায়েন্ট এবং SageMaker রানটাইমের মধ্যে কোন মধ্যস্থতাকারী স্তর আছে?
স্বয়ংক্রিয় স্কেলিং
আমরা এই পোস্টে স্বয়ংক্রিয় স্কেলিংকে বিশেষভাবে কভার করি না, তবে কাজের চাপের উপর ভিত্তি করে সঠিক সংখ্যক দৃষ্টান্তের ব্যবস্থা করার জন্য এটি একটি গুরুত্বপূর্ণ বিবেচনা। আপনার ট্রাফিক নিদর্শন উপর নির্ভর করে, আপনি একটি সংযুক্ত করতে পারেন স্বয়ংক্রিয় স্কেলিং নীতি আপনার সেজমেকার এন্ডপয়েন্টে। বিভিন্ন স্কেলিং বিকল্প আছে, যেমন TargetTrackingScaling, SimpleScaling, এবং StepScaling. এটি আপনার ট্র্যাফিক প্যাটার্নের উপর ভিত্তি করে আপনার এন্ডপয়েন্টকে স্বয়ংক্রিয়ভাবে স্কেল ইন এবং আউট করার অনুমতি দেয়।
একটি সাধারণ বিকল্প হল লক্ষ্য ট্র্যাকিং, যেখানে আপনি একটি ক্লাউডওয়াচ মেট্রিক বা কাস্টম মেট্রিক নির্দিষ্ট করতে পারেন যা আপনি সংজ্ঞায়িত করেছেন এবং তার উপর ভিত্তি করে স্কেল আউট করতে পারেন। স্বয়ংক্রিয় স্কেলিং একটি ঘন ব্যবহার ট্র্যাকিং হয় InvocationsPerInstance মেট্রিক আপনি একটি নির্দিষ্ট TPS-এ একটি বাধা শনাক্ত করার পরে, আপনি প্রায়শই এটিকে একটি মেট্রিক হিসাবে ব্যবহার করতে পারেন যাতে ট্রাফিকের সর্বোচ্চ লোড পরিচালনা করতে সক্ষম হতে আরও বেশি সংখ্যক দৃষ্টান্তে পরিমাপ করা যায়। স্বয়ংক্রিয় স্কেলিং সেজমেকার এন্ডপয়েন্টগুলির একটি গভীর ভাঙ্গন পেতে, পড়ুন Amazon SageMaker-এ অটোস্কেলিং ইনফারেন্স এন্ডপয়েন্ট কনফিগার করা হচ্ছে.
লোড পরীক্ষার
যদিও আমরা পঙ্গপাল ব্যবহার করি কিভাবে আমরা স্কেলে পরীক্ষা লোড করতে পারি, আপনি যদি আপনার শেষ পয়েন্টের পিছনের উদাহরণটিকে সঠিক আকার দেওয়ার চেষ্টা করছেন, সেজমেকার ইনফারেন্স সুপারিশকারী একটি আরো দক্ষ বিকল্প। থার্ড-পার্টি লোড টেস্টিং টুলের সাহায্যে, আপনাকে বিভিন্ন দৃষ্টান্ত জুড়ে ম্যানুয়ালি এন্ডপয়েন্ট স্থাপন করতে হবে। ইনফারেন্স রেকমেন্ডারের সাহায্যে, আপনি যে ধরনের উদাহরণগুলির বিরুদ্ধে পরীক্ষা লোড করতে চান তার একটি অ্যারে পাস করতে পারেন এবং সেজমেকার স্পিন হয়ে যাবে কাজ এই প্রতিটি উদাহরণের জন্য।
পঙ্গপাল
এই উদাহরণের জন্য, আমরা ব্যবহার করি পঙ্গপাল, একটি ওপেন সোর্স লোড টেস্টিং টুল যা আপনি পাইথন ব্যবহার করে প্রয়োগ করতে পারেন। পঙ্গপাল অন্যান্য অনেক ওপেন-সোর্স লোড টেস্টিং টুলের মতই, তবে এর কিছু নির্দিষ্ট সুবিধা রয়েছে:
- সেট আপ করা সহজ – যেমন আমরা এই পোস্টে প্রদর্শন করছি, আমরা একটি সাধারণ পাইথন স্ক্রিপ্ট পাস করব যা সহজেই আপনার নির্দিষ্ট এন্ডপয়েন্ট এবং পেলোডের জন্য রিফ্যাক্টর করা যেতে পারে।
- বিতরণ করা এবং মাপযোগ্য - পঙ্গপাল ঘটনা-ভিত্তিক এবং ব্যবহার করে gevent ফণা অধীনে এটি অত্যন্ত সমসাময়িক কাজের চাপ পরীক্ষা করার জন্য এবং হাজার হাজার সমসাময়িক ব্যবহারকারীদের অনুকরণ করার জন্য খুব দরকারী। আপনি পঙ্গপাল চালানোর একটি একক প্রক্রিয়ার মাধ্যমে উচ্চ টিপিএস অর্জন করতে পারেন, তবে এটিতে একটি রয়েছে বিতরণ করা লোড প্রজন্ম বৈশিষ্ট্য যা আপনাকে একাধিক প্রক্রিয়া এবং ক্লায়েন্ট মেশিনে স্কেল আউট করতে সক্ষম করে, আমরা এই পোস্টে অন্বেষণ করব।
- পঙ্গপাল মেট্রিক্স এবং UI - পঙ্গপাল একটি মেট্রিক হিসাবে এন্ড-টু-এন্ড লেটেন্সিও ক্যাপচার করে। এটি আপনার পরীক্ষার একটি সম্পূর্ণ ছবি আঁকার জন্য আপনার CloudWatch মেট্রিক্সের পরিপূরক সাহায্য করতে পারে। এটি সবই Locust UI-তে ক্যাপচার করা হয়েছে, যেখানে আপনি সমসাময়িক ব্যবহারকারী, কর্মী এবং আরও অনেক কিছু ট্র্যাক করতে পারেন।
পঙ্গপালকে আরও বুঝতে, তাদের দেখুন ডকুমেন্টেশন.
আমাজন EC2 সেটআপ
আপনার জন্য সামঞ্জস্যপূর্ণ পরিবেশে আপনি পঙ্গপাল সেট আপ করতে পারেন। এই পোস্টের জন্য, আমরা একটি EC2 দৃষ্টান্ত সেট আপ করি এবং আমাদের পরীক্ষা চালানোর জন্য সেখানে পঙ্গপাল ইনস্টল করি। আমরা একটি c5.18xlarge EC2 উদাহরণ ব্যবহার করি। ক্লায়েন্ট-সাইড কম্পিউট পাওয়ারও বিবেচনা করার মতো কিছু। অনেক সময় যখন আপনার ক্লায়েন্ট সাইডে কম্পিউট পাওয়ার ফুরিয়ে যায়, এটি প্রায়শই ক্যাপচার করা হয় না এবং এটিকে সেজমেকার এন্ডপয়েন্ট ত্রুটি হিসাবে ভুল করা হয়। আপনার ক্লায়েন্টকে পর্যাপ্ত কম্পিউট পাওয়ারের জায়গায় রাখা গুরুত্বপূর্ণ যা আপনি যে লোডটি পরীক্ষা করছেন তা পরিচালনা করতে পারে। আমাদের EC2 উদাহরণের জন্য, আমরা একটি উবুন্টু ডিপ লার্নিং এএমআই ব্যবহার করি, কিন্তু যতক্ষণ পর্যন্ত আপনি মেশিনে পঙ্গপালকে সঠিকভাবে সেট আপ করতে পারেন ততক্ষণ পর্যন্ত আপনি যেকোনো এএমআই ব্যবহার করতে পারেন। আপনার EC2 দৃষ্টান্তের সাথে কীভাবে লঞ্চ এবং সংযোগ করবেন তা বোঝার জন্য, টিউটোরিয়ালটি পড়ুন Amazon EC2 Linux দৃষ্টান্ত দিয়ে শুরু করুন.
Locust UI পোর্ট 8089 এর মাধ্যমে অ্যাক্সেসযোগ্য। আমরা EC2 ইন্সট্যান্সের জন্য আমাদের অন্তর্মুখী নিরাপত্তা গোষ্ঠীর নিয়মগুলি সামঞ্জস্য করে এটি খুলতে পারি। আমরা পোর্ট 22ও খুলি যাতে আমরা EC2 উদাহরণে SSH করতে পারি। আপনি যে নির্দিষ্ট আইপি অ্যাড্রেস থেকে EC2 ইন্সট্যান্স অ্যাক্সেস করছেন তার উৎসের স্কোপ করার কথা বিবেচনা করুন।

আপনি আপনার EC2 উদাহরণের সাথে সংযুক্ত হওয়ার পরে, আমরা একটি পাইথন ভার্চুয়াল পরিবেশ সেট আপ করি এবং CLI এর মাধ্যমে ওপেন-সোর্স Locust API ইনস্টল করি:
আমরা এখন আমাদের শেষ পয়েন্ট লোড পরীক্ষার জন্য পঙ্গপালের সাথে কাজ করতে প্রস্তুত।
পঙ্গপাল পরীক্ষা
সমস্ত পঙ্গপাল লোড পরীক্ষা ক এর উপর ভিত্তি করে পরিচালিত হয় পঙ্গপাল ফাইল যে আপনি প্রদান করেন। এই Locust ফাইলটি লোড পরীক্ষার জন্য একটি টাস্ক নির্ধারণ করে; এখানেই আমরা আমাদের Boto3 সংজ্ঞায়িত করি invoke_endpoint API কল। নিম্নলিখিত কোডটি দেখুন:
পূর্ববর্তী কোডে, আপনার নির্দিষ্ট মডেল আহ্বানের জন্য আপনার আহ্বানের এন্ডপয়েন্ট কল প্যারামিটারগুলি সামঞ্জস্য করুন। আমরা ব্যবহার করি InvokeEndpoint Locust ফাইলে নিম্নলিখিত কোড ব্যবহার করে API; এটি আমাদের লোড টেস্ট রান পয়েন্ট। Locust ফাইলটি আমরা ব্যবহার করছি locust_script.py.
এখন যেহেতু আমাদের Locust স্ক্রিপ্ট প্রস্তুত আছে, আমরা আমাদের ইন্সট্যান্স কতটা ট্র্যাফিক পরিচালনা করতে পারে তা খুঁজে বের করার জন্য আমাদের একক দৃষ্টান্তের চাপ পরীক্ষা করার জন্য বিতরণ করা পঙ্গপাল পরীক্ষা চালাতে চাই।
পঙ্গপাল বিতরণ মোড একটি একক প্রক্রিয়া পঙ্গপাল পরীক্ষার চেয়ে একটু বেশি সংক্ষিপ্ত। বিতরণ মোডে, আমাদের একজন প্রাথমিক এবং একাধিক কর্মী রয়েছে। প্রাথমিক কর্মী কর্মীদের নির্দেশ দেয় যে কিভাবে সমসাময়িক ব্যবহারকারীরা একটি অনুরোধ পাঠাচ্ছেন তাদের স্পন এবং নিয়ন্ত্রণ করতে হবে। আমাদের মাঝে distributed.sh স্ক্রিপ্ট, আমরা ডিফল্টরূপে দেখতে পাই যে 240 জন কর্মী জুড়ে 60 জন ব্যবহারকারীকে বিতরণ করা হবে। উল্লেখ্য যে --headless পঙ্গপাল CLI-তে পতাকা পঙ্গপালের UI বৈশিষ্ট্যকে সরিয়ে দেয়।
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
আমরা প্রথমে এন্ডপয়েন্টকে সমর্থন করে একটি একক উদাহরণে বিতরণ করা পরীক্ষা চালাই। এখানে ধারণাটি হল আমাদের লেটেন্সি প্রয়োজনীয়তার মধ্যে থাকার সময় আমাদের লক্ষ্য TPS অর্জনের জন্য আমাদের যে দৃষ্টান্ত গণনা প্রয়োজন তা বোঝার জন্য আমরা একটি একক দৃষ্টান্তকে সম্পূর্ণরূপে সর্বাধিক করতে চাই। মনে রাখবেন আপনি যদি UI অ্যাক্সেস করতে চান তবে পরিবর্তন করুন Locust_UI এনভায়রনমেন্ট ভেরিয়েবলকে True করুন এবং আপনার EC2 ইন্সট্যান্সের সর্বজনীন আইপি এবং ম্যাপ পোর্ট 8089 ইউআরএলে নিন।
নিম্নলিখিত স্ক্রিনশটটি আমাদের ক্লাউডওয়াচ মেট্রিক্স দেখায়।

অবশেষে, আমরা লক্ষ্য করেছি যে যদিও আমরা প্রাথমিকভাবে 200 টিপিএস অর্জন করেছি, আমরা আমাদের EC5 ক্লায়েন্ট-সাইড লগগুলিতে 2xx ত্রুটিগুলি লক্ষ্য করতে শুরু করি, যেমনটি নিম্নলিখিত স্ক্রিনশটে দেখানো হয়েছে।
আমরা বিশেষভাবে আমাদের ইনস্ট্যান্স-স্তরের মেট্রিক্স দেখেও এটি যাচাই করতে পারি CPUUtilization.
 এখানে আমরা লক্ষ্য করি
এখানে আমরা লক্ষ্য করি CPUUtilization প্রায় 4,800% এ। আমাদের ml.m5.12x.large উদাহরণে 48 vCPUs (48 * 100 = 4800~) আছে। এটি সম্পূর্ণ উদাহরণকে পরিপূর্ণ করছে, যা আমাদের 5xx ত্রুটিগুলি ব্যাখ্যা করতেও সহায়তা করে৷ আমরাও বৃদ্ধি দেখতে পাই ModelLatency.
দেখে মনে হচ্ছে যেন আমাদের একক দৃষ্টান্ত লোড হয়ে যাচ্ছে এবং আমরা যে 200 টিপিএস পর্যবেক্ষণ করছি তার লোড ধরে রাখার মতো গণনা নেই। আমাদের টার্গেট টিপিএস হল 1000, তাই আসুন আমাদের ইনস্ট্যান্স কাউন্ট 5-এ বাড়ানোর চেষ্টা করি। এটি একটি প্রোডাকশন সেটিংয়ে আরও বেশি হতে পারে, কারণ আমরা একটি নির্দিষ্ট পয়েন্টের পরে 200 টিপিএস-এ ত্রুটিগুলি পর্যবেক্ষণ করছিলাম।

আমরা Locust UI এবং CloudWatch লগ উভয়েই দেখতে পাচ্ছি যে আমাদের কাছে প্রায় 1000 টিপিএস রয়েছে যেখানে পাঁচটি দৃষ্টান্ত এন্ডপয়েন্টকে সমর্থন করে।

 আপনি যদি এই হার্ডওয়্যার সেটআপের সাথেও ত্রুটিগুলি অনুভব করা শুরু করেন তবে নিরীক্ষণ নিশ্চিত করুন৷
আপনি যদি এই হার্ডওয়্যার সেটআপের সাথেও ত্রুটিগুলি অনুভব করা শুরু করেন তবে নিরীক্ষণ নিশ্চিত করুন৷ CPUUtilization আপনার শেষ পয়েন্ট হোস্টিং পিছনে সম্পূর্ণ ছবি বুঝতে. আপনার হার্ডওয়্যার ব্যবহার বোঝার জন্য আপনার স্কেল বাড়ানোর প্রয়োজন আছে কিনা তা বোঝা অত্যন্ত গুরুত্বপূর্ণ। কখনও কখনও ধারক-স্তরের সমস্যা 5xx ত্রুটির দিকে পরিচালিত করে, কিন্তু যদি CPUUtilization কম, এটি ইঙ্গিত করে যে এটি আপনার হার্ডওয়্যার নয় তবে কন্টেইনার বা মডেল স্তরে এমন কিছু যা এই সমস্যাগুলির দিকে পরিচালিত করতে পারে (উদাহরণস্বরূপ, সেট না করা কর্মীদের সংখ্যার জন্য উপযুক্ত পরিবেশ পরিবর্তনশীল)৷ অন্যদিকে, আপনি যদি লক্ষ্য করেন যে আপনার দৃষ্টান্ত সম্পূর্ণরূপে স্যাচুরেটেড হচ্ছে, এটি একটি চিহ্ন যে আপনাকে হয় বর্তমান ইনস্ট্যান্স ফ্লিট বাড়াতে হবে বা একটি ছোট বহরের সাথে একটি বড় উদাহরণ চেষ্টা করতে হবে।
যদিও আমরা 5 টিপিএস হ্যান্ডেল করার জন্য দৃষ্টান্তের সংখ্যা বাড়িয়ে 100 করেছি, আমরা দেখতে পাচ্ছি যে ModelLatency মেট্রিক এখনও উচ্চ। এই ঘটনা স্যাচুরেটেড হওয়ার কারণে। সাধারণভাবে, আমরা 60-70% এর মধ্যে উদাহরণের সংস্থানগুলি ব্যবহার করার লক্ষ্য রাখার পরামর্শ দিই।
পরিষ্কার কর
লোড পরীক্ষার পরে, সেজমেকার কনসোলের মাধ্যমে বা এর মাধ্যমে আপনি ব্যবহার করবেন না এমন কোনও সংস্থান পরিষ্কার করতে ভুলবেন না ডিলিট_এন্ডপয়েন্ট Boto3 API কল। এছাড়াও, নিশ্চিত করুন যে আপনার EC2 ইন্সট্যান্স বা যেকোন ক্লায়েন্ট সেটআপ বন্ধ করার জন্য আপনাকে সেখানে আর কোনো চার্জ দিতে হবে না।
সারাংশ
এই পোস্টে, আমরা বর্ণনা করেছি কিভাবে আপনি আপনার সেজমেকার রিয়েল-টাইম এন্ডপয়েন্ট পরীক্ষা লোড করতে পারেন। আপনার পারফরম্যান্স ব্রেকডাউন বোঝার জন্য আপনার এন্ডপয়েন্ট লোড করার সময় আপনার কোন মেট্রিক্সের মূল্যায়ন করা উচিত তাও আমরা আলোচনা করেছি। চেক আউট নিশ্চিত করুন সেজমেকার ইনফারেন্স সুপারিশকারী দৃষ্টান্ত রাইট-সাইজিং এবং আরও কর্মক্ষমতা অপ্টিমাইজেশান কৌশল আরও বুঝতে।
লেখক সম্পর্কে
 মার্ক কার্প সেজমেকার সার্ভিস টিমের সাথে একজন এমএল আর্কিটেক্ট। তিনি গ্রাহকদের স্কেলে এমএল ওয়ার্কলোড ডিজাইন, স্থাপন এবং পরিচালনা করতে সহায়তা করার উপর ফোকাস করেন। তার অবসর সময়ে, তিনি ভ্রমণ এবং নতুন জায়গা অন্বেষণ উপভোগ করেন।
মার্ক কার্প সেজমেকার সার্ভিস টিমের সাথে একজন এমএল আর্কিটেক্ট। তিনি গ্রাহকদের স্কেলে এমএল ওয়ার্কলোড ডিজাইন, স্থাপন এবং পরিচালনা করতে সহায়তা করার উপর ফোকাস করেন। তার অবসর সময়ে, তিনি ভ্রমণ এবং নতুন জায়গা অন্বেষণ উপভোগ করেন।
 রাম ভেগিরাজু সেজমেকার সার্ভিস টিমের সাথে একজন এমএল আর্কিটেক্ট। তিনি গ্রাহকদের Amazon SageMaker-এ তাদের AI/ML সমাধানগুলি তৈরি এবং অপ্টিমাইজ করতে সাহায্য করার দিকে মনোনিবেশ করেন৷ অবসর সময়ে তিনি ভ্রমণ এবং লেখালেখি পছন্দ করেন।
রাম ভেগিরাজু সেজমেকার সার্ভিস টিমের সাথে একজন এমএল আর্কিটেক্ট। তিনি গ্রাহকদের Amazon SageMaker-এ তাদের AI/ML সমাধানগুলি তৈরি এবং অপ্টিমাইজ করতে সাহায্য করার দিকে মনোনিবেশ করেন৷ অবসর সময়ে তিনি ভ্রমণ এবং লেখালেখি পছন্দ করেন।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- সক্ষম
- উপরে
- গ্রহণযোগ্য
- প্রবেশ
- প্রবেশযোগ্য
- অ্যাক্সেস করা
- সঠিক
- অর্জন করা
- দিয়ে
- যোগ
- ঠিকানা
- পর
- বিরুদ্ধে
- এআই / এমএল
- লক্ষ্য
- সব
- অনুমতি
- যদিও
- মর্দানী স্ত্রীলোক
- আমাজন EC2
- আমাজন সেজমেকার
- পরিমাণ
- বিশ্লেষণ
- এবং
- API
- কাছাকাছি
- বিন্যাস
- সংযুক্ত
- রচনা
- গাড়ী
- স্বয়ংক্রিয়ভাবে
- সহজলভ্য
- ডেস্কটপ AWS
- পিছনে
- সাহায্যপ্রাপ্ত
- সমর্থন
- ভিত্তি
- কারণ
- পিছনে
- হচ্ছে
- উচ্চতার চিহ্ন
- সুবিধা
- সুবিধা
- সর্বোত্তম
- সেরা অভ্যাস
- মধ্যে
- শরীর
- ভাঙ্গন
- নির্মাণ করা
- সি ++
- কল
- কল
- পেতে পারি
- গ্রেপ্তার
- ক্যাচ
- দঙ্গল
- কিছু
- পরিবর্তন
- চার্জ
- চেক
- শ্রেণী
- শ্রেণীবিন্যাস
- মক্কেল
- কোড
- সাধারণ
- উপযুক্ত
- গনা
- সহগামী
- আচার
- কনফিগারেশন
- নিশ্চিত করা
- সংযোগ করা
- সংযুক্ত
- সংযোগ
- বিবেচনা
- বিবেচনা
- কনসোল
- আধার
- ধারণ
- প্রসঙ্গ
- নিয়ন্ত্রণ
- অনুরূপ
- পারা
- আবরণ
- কভার
- সিপিইউ
- সৃষ্টি
- কঠোর
- বর্তমান
- প্রথা
- গ্রাহকদের
- উপাত্ত
- গভীর
- গভীর জ্ঞানার্জন
- গভীর
- ডিফল্ট
- সংজ্ঞায়িত
- প্রদর্শন
- নির্ভর করে
- নির্ভর করে
- স্থাপন
- মোতায়েন
- বর্ণনা করা
- বর্ণিত
- নকশা
- ডেভেলপারদের
- বিভিন্ন
- সরাসরি
- আলোচনা
- প্রদর্শন
- বণ্টিত
- না
- Dont
- নিচে
- প্রতি
- সহজে
- দক্ষ
- দক্ষতার
- পারেন
- সম্ভব
- সর্বশেষ সীমা
- শেষপ্রান্ত
- সমগ্র
- পরিবেশ
- ভুল
- ত্রুটি
- অপরিহার্য
- থার (eth)
- এমন কি
- উদাহরণ
- ব্যতিক্রম
- এক্সিকিউট
- সম্মুখীন
- ব্যাখ্যা করা
- অন্বেষণ
- অন্বেষণ করুণ
- এক্সপ্লোরিং
- রপ্তানি
- অত্যন্ত
- মুখ
- কারণের
- ঝরনা
- পরিচিত
- বৈশিষ্ট্য
- কয়েক
- ফাইল
- পরিশেষে
- আবিষ্কার
- প্রথম
- ফ্লিট
- কেন্দ্রবিন্দু
- গুরুত্ত্ব
- অনুসরণ
- বিন্যাস
- ফ্রেমওয়ার্ক
- ঘন
- থেকে
- সম্পূর্ণ
- সম্পূর্ণরূপে
- অধিকতর
- সাধারণ
- সাধারণত
- পাওয়া
- পেয়ে
- ভাল
- চিত্রলেখ
- বৃহত্তর
- গ্রুপ
- গ্রুপের
- হাতল
- খুশি
- হার্ডওয়্যারের
- সাহায্য
- সাহায্য
- সাহায্য
- এখানে
- উচ্চ
- অত্যন্ত
- ঘোমটা
- নিমন্ত্রণকর্তা
- হোস্ট
- হোস্টিং
- কিভাবে
- কিভাবে
- এইচটিএমএল
- HTTPS দ্বারা
- নাভি
- ধারণা
- আদর্শ
- চিহ্নিত
- সনাক্ত করা
- প্রভাব
- বাস্তবায়ন
- বাস্তবায়িত
- আমদানি
- গুরুত্বপূর্ণ
- in
- অন্তর্ভুক্ত
- বৃদ্ধি
- বর্ধিত
- ইঙ্গিত
- ইঙ্গিত
- তথ্য
- প্রাথমিকভাবে
- ইনস্টল
- উদাহরণ
- সংহত
- ইন্টারেক্টিভ
- Internet
- পূজা
- IP
- আইপি ঠিকানা
- ভিন্ন
- সমস্যা
- IT
- নিজেই
- JSON
- বড়
- মূলত
- বৃহত্তর
- অদৃশ্যতা
- শুরু করা
- স্তর
- নেতৃত্ব
- নেতৃত্ব
- শিক্ষা
- উচ্চতা
- লিনাক্স
- তালিকা
- সামান্য
- বোঝা
- লোড
- অবস্থান
- দীর্ঘ
- খুঁজছি
- অনেক
- কম
- মেশিন
- মেশিন লার্নিং
- মেশিন
- করা
- মেকিং
- পরিচালনা করা
- পরিচালিত
- ম্যানুয়ালি
- অনেক
- মানচিত্র
- চরমে তোলা
- মানে
- সম্মেলন
- সাক্ষাৎ
- স্মৃতি
- ছন্দোময়
- ছন্দোবিজ্ঞান
- হতে পারে
- সর্বনিম্ন
- ML
- মোড
- মডেল
- মডেল
- মনিটর
- অধিক
- আরো দক্ষ
- বহু
- নাম
- প্রায়
- অগত্যা
- প্রয়োজন
- নতুন
- নোটবই
- সংখ্যা
- ONE
- খোলা
- ওপেন সোর্স
- অপারেশনস
- অপ্টিমাইজেশান
- অপ্টিমিজ
- অপ্টিমাইজ
- পছন্দ
- অপশন সমূহ
- ক্রম
- অন্যান্য
- বাহিরে
- নিজের
- রং
- পরামিতি
- অংশ
- গৃহীত
- গত
- পথ
- প্যাটার্ন
- নিদর্শন
- শিখর
- সম্পাদন করা
- কর্মক্ষমতা
- পরিপ্রেক্ষিত
- বাছাই
- ছবি
- টুকরা
- জায়গা
- জায়গা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- যোগ
- বিন্দু
- পোস্ট
- সম্ভাব্য
- ক্ষমতা
- অনুশীলন
- চর্চা
- Predictor
- প্রাথমিক
- প্রিন্ট
- সমস্যা
- প্রক্রিয়া
- প্রসেস
- উত্পাদনের
- প্রোফাইল
- সঠিক
- সঠিকভাবে
- প্রদান
- উপলব্ধ
- বিধান
- প্রকাশ্য
- পাইথন
- প্রশ্ন
- দ্রুত
- পরিসর
- প্রস্তুত
- প্রকৃত সময়
- সাধা
- পায়
- সুপারিশ করা
- এলাকা
- সংশ্লিষ্ট
- অনুরোধ
- আবশ্যকতা
- Resources
- প্রতিক্রিয়া
- বিশ্রাম
- ফল
- ফলাফল
- আয়
- নিয়ম
- চালান
- দৌড়
- ঋষি নির্মাতা
- সেজমেকার ইনফারেন্স
- স্কেল
- আরোহী
- বিজ্ঞানীরা
- স্কোপিং
- স্ক্রিপ্ট
- দ্বিতীয়
- নিরাপত্তা
- মনে হয়
- আত্ম
- পাঠানোর
- অনুভূতি
- সেবা
- ভজনা
- সেট
- বিন্যাস
- সেটিংস
- সেটআপ
- বিভিন্ন
- উচিত
- প্রদর্শিত
- শো
- চিহ্ন
- অনুরূপ
- সহজ
- কেবল
- একক
- আয়তন
- ক্ষুদ্রতর
- So
- সলিউশন
- কিছু
- উৎস
- সোর্স
- ডিম
- নির্দিষ্ট
- বিশেষভাবে
- ঘূর্ণন
- মান
- শুরু
- শুরু
- বিবৃতি
- ধাপ
- এখনো
- থামুন
- জোর
- সংগ্রাম করা
- এমন
- যথেষ্ট
- মামলা
- সুপার
- ক্রোড়পত্র
- গ্রহণ করা
- লাগে
- লক্ষ্য
- কার্য
- কাজ
- টীম
- প্রযুক্তি
- পরীক্ষা
- টেস্ট রান
- পরীক্ষামূলক
- পরীক্ষা
- পাঠ্য শ্রেণিবিন্যাস
- সার্জারির
- উৎস
- তাদের
- তৃতীয় পক্ষের
- হাজার হাজার
- দ্বারা
- সময়
- বার
- থেকে
- টুল
- সরঞ্জাম
- টিপিএস
- পথ
- অনুসরণকরণ
- ট্রাফিক
- রেলগাড়ি
- লেনদেন
- ভ্রমণ
- সত্য
- অভিভাবকসংবঁধীয়
- ধরনের
- উবুন্টু
- ui
- অধীনে
- বোঝা
- বোধশক্তি
- একক
- URL টি
- us
- ব্যবহার
- ব্যবহারকারী
- সদ্ব্যবহার করা
- ব্যবহার
- ব্যবহার
- ব্যবহার
- বৈচিত্র্য
- যাচাই
- মাধ্যমে
- ভার্চুয়াল
- কি
- কিনা
- যে
- যখন
- ইচ্ছা
- মধ্যে
- হয়া যাই ?
- কর্মী
- শ্রমিকদের
- would
- লেখা
- আপনার
- zephyrnet