নিউরাল নেটওয়ার্কগুলি সংখ্যার মাধ্যমে শেখে, তাই প্রতিটি শব্দকে একটি নির্দিষ্ট শব্দের প্রতিনিধিত্ব করার জন্য ভেক্টরে ম্যাপ করা হবে। এমবেডিং লেয়ারটিকে একটি লুকআপ টেবিল হিসাবে ভাবা যেতে পারে যা শব্দ এম্বেডিং সংরক্ষণ করে এবং সূচক ব্যবহার করে সেগুলি পুনরুদ্ধার করে।
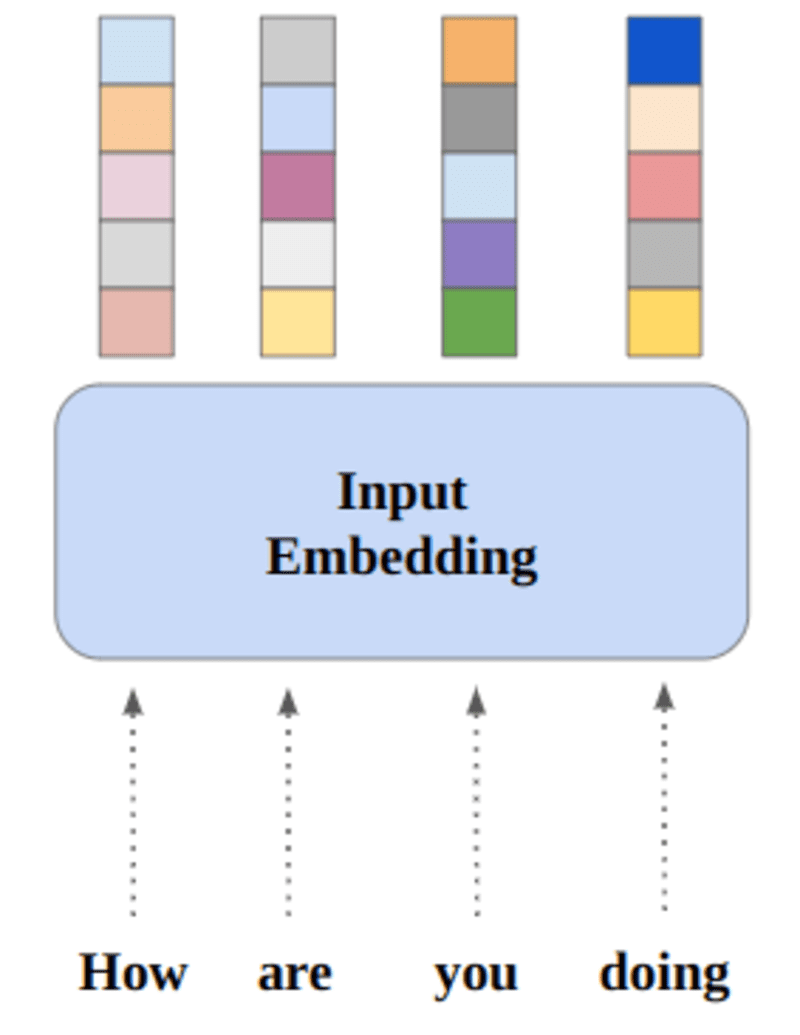
যে শব্দগুলির একই অর্থ রয়েছে সেগুলি ইউক্লিডিয়ান দূরত্ব/কোসাইন সাদৃশ্যের ক্ষেত্রে কাছাকাছি হবে। উদাহরণস্বরূপ, নীচের শব্দের উপস্থাপনায়, "শনিবার", "রবিবার" এবং "সোমবার" একই ধারণার সাথে যুক্ত, তাই আমরা দেখতে পাচ্ছি যে শব্দগুলি একই রকম।

শব্দের অবস্থান নির্ণয় করে, শব্দের অবস্থান নির্ণয় করতে হবে কেন? কারণ, ট্রান্সফরমার এনকোডারে পুনরাবৃত্ত নিউরাল নেটওয়ার্কের মতো কোনো পুনরাবৃত্তি নেই, আমাদের অবশ্যই ইনপুট এম্বেডিংয়ের অবস্থান সম্পর্কে কিছু তথ্য যোগ করতে হবে। এটি অবস্থানগত এনকোডিং ব্যবহার করে করা হয়। কাগজের লেখক একটি শব্দের অবস্থান মডেল করতে নিম্নলিখিত ফাংশন ব্যবহার করেছেন।
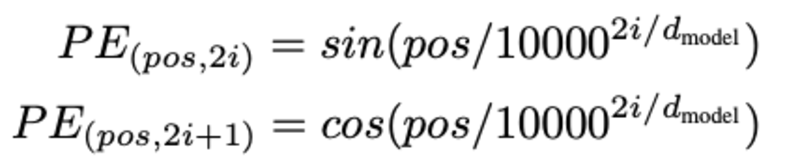
আমরা অবস্থানগত এনকোডিং ব্যাখ্যা করার চেষ্টা করব।
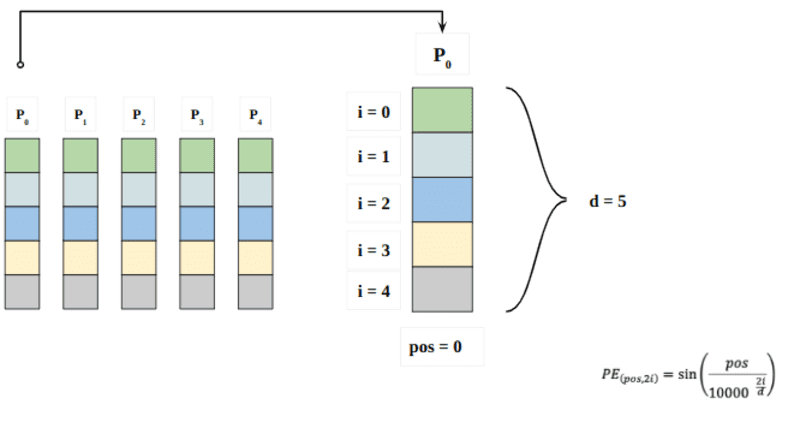
এখানে "pos" অনুক্রমের "শব্দ" এর অবস্থানকে বোঝায়। P0 প্রথম শব্দের অবস্থান এমবেডিং বোঝায়; "d" মানে শব্দ/টোকেন এমবেডিংয়ের আকার। এই উদাহরণে d=5. অবশেষে, "i" এম্বেডিংয়ের 5টি পৃথক মাত্রার প্রতিটিকে বোঝায় (যেমন 0, 1,2,3,4)
উপরের সমীকরণে যদি "i" পরিবর্তিত হয়, আপনি বিভিন্ন ফ্রিকোয়েন্সি সহ একগুচ্ছ বক্ররেখা পাবেন। বিভিন্ন ফ্রিকোয়েন্সির বিপরীতে অবস্থান এমবেডিং মান পড়া বন্ধ করা, P0 এবং P4 এর জন্য বিভিন্ন এমবেডিং মাত্রায় বিভিন্ন মান প্রদান করা।
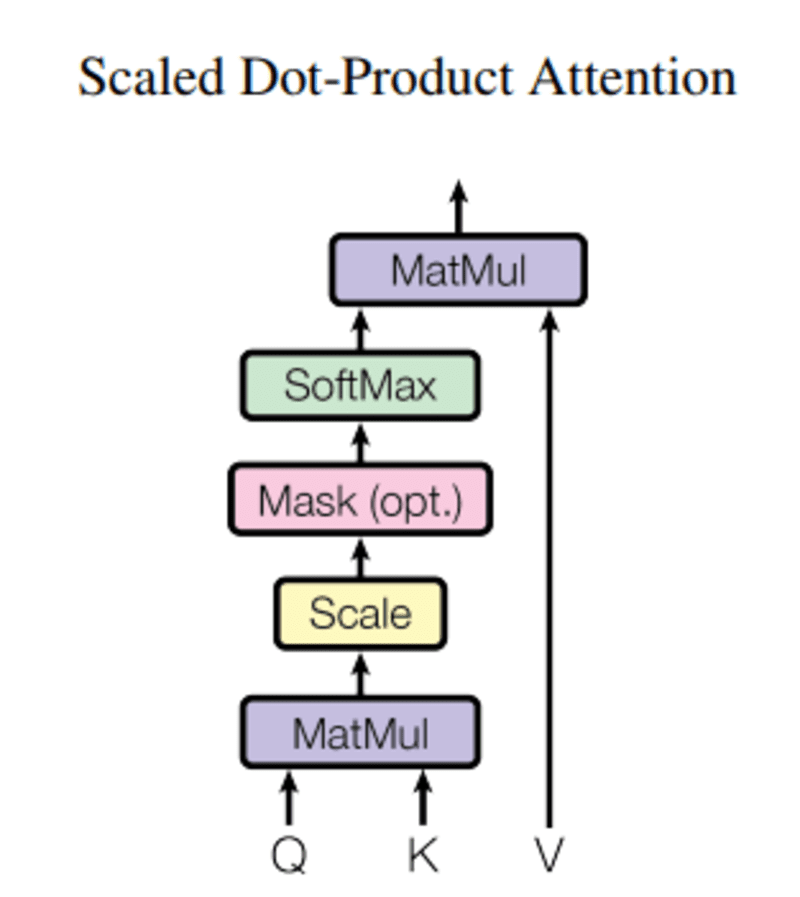
এই প্রশ্ন, প্রশ্ন একটি ভেক্টর শব্দ প্রতিনিধিত্ব করে, কী কে বাক্যটির অন্যান্য সমস্ত শব্দ এবং মান V শব্দের ভেক্টর প্রতিনিধিত্ব করে।
মনোযোগের উদ্দেশ্য হল একই ব্যক্তি/বস্তু বা ধারণার সাথে সম্পর্কিত ক্যোয়ারী শব্দের তুলনায় মূল শব্দের গুরুত্ব গণনা করা।
আমাদের ক্ষেত্রে, V সমান Q এর।
মনোযোগ প্রক্রিয়া আমাদের একটি বাক্যে শব্দের গুরুত্ব দেয়।
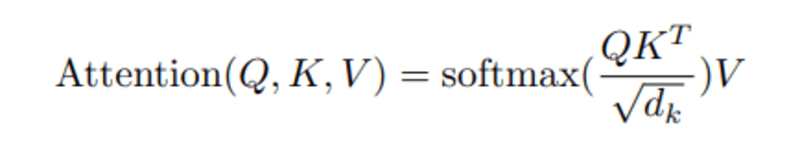
যখন আমরা ক্যোয়ারী এবং কী-এর মধ্যে নরমালাইজড ডট প্রোডাক্ট গণনা করি, তখন আমরা একটি টেনসর পাই যা কোয়েরির জন্য একে অপরের শব্দের আপেক্ষিক গুরুত্বকে উপস্থাপন করে।
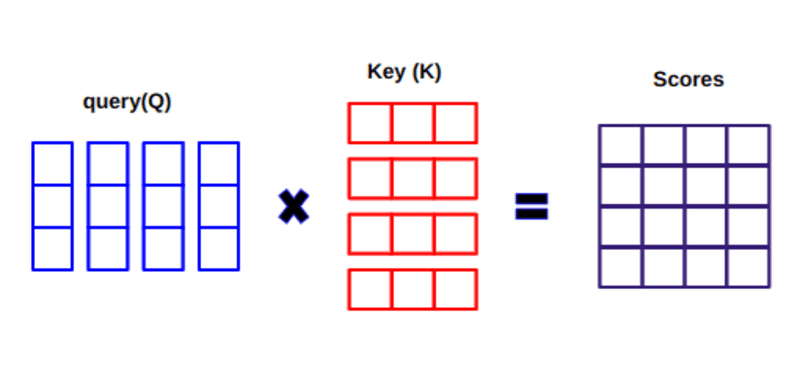
Q এবং KT-এর মধ্যে ডট প্রোডাক্ট গণনা করার সময়, আমরা অনুমান করার চেষ্টা করি যে কীভাবে ভেক্টরগুলি (অর্থাৎ ক্যোয়ারী এবং কীগুলির মধ্যে শব্দগুলি) সারিবদ্ধ হয় এবং বাক্যের প্রতিটি শব্দের জন্য একটি ওজন ফেরত দেয়।
তারপর, আমরা d_k-এর বর্গাকার ফলাফলকে স্বাভাবিক করি এবং সফটম্যাক্স ফাংশন পদগুলিকে নিয়মিত করে এবং 0 এবং 1-এর মধ্যে পুনরায় স্কেল করে।
অবশেষে, আমরা ফলাফলকে (অর্থাৎ ওজন) মান দিয়ে গুণ করি (অর্থাৎ সমস্ত শব্দ) অপ্রাসঙ্গিক শব্দের গুরুত্ব কমাতে এবং শুধুমাত্র সবচেয়ে গুরুত্বপূর্ণ শব্দগুলিতে ফোকাস করি।
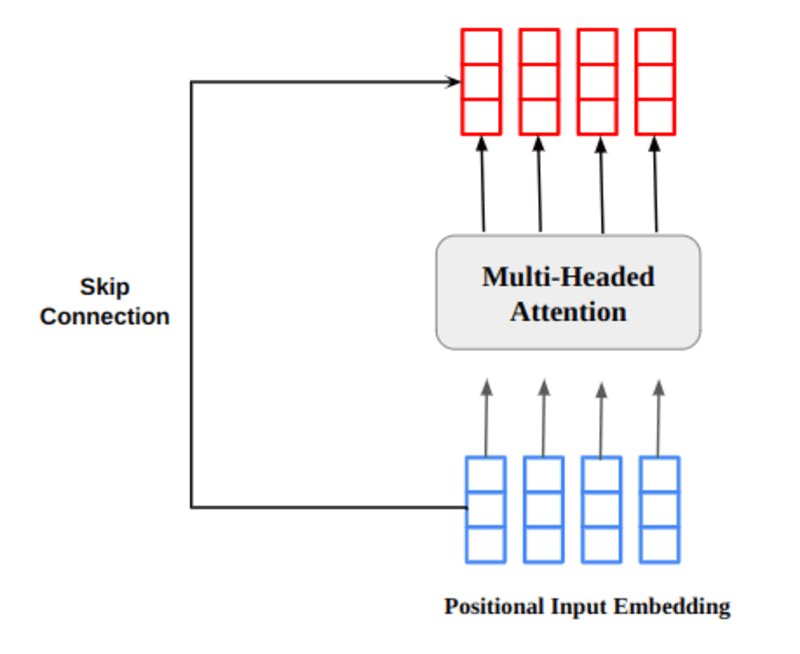
মাল্টি-হেডেড অ্যাটেনশন আউটপুট ভেক্টর মূল অবস্থানগত ইনপুট এম্বেডিং-এ যোগ করা হয়। একে বলা হয় রেসিডুয়াল কানেকশন/স্কিপ কানেকশন। অবশিষ্ট সংযোগের আউটপুট স্তর স্বাভাবিককরণের মাধ্যমে যায়। স্বাভাবিককৃত অবশিষ্ট আউটপুট আরও প্রক্রিয়াকরণের জন্য একটি পয়েন্টওয়াইজ ফিড-ফরোয়ার্ড নেটওয়ার্কের মাধ্যমে পাস করা হয়।
মুখোশ হল একটি ম্যাট্রিক্স যা মনোযোগ স্কোরের 0 এবং ঋণাত্মক অসীম মান দিয়ে ভরা একই আকারের।
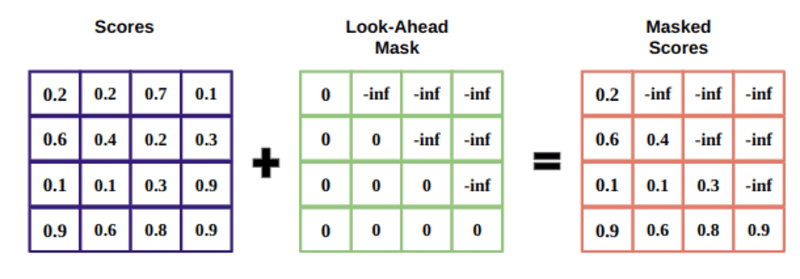
মুখোশের কারণ হল যে আপনি একবার মাস্কড স্কোরগুলির সফটম্যাক্স গ্রহণ করলে, নেতিবাচক অসীমতা শূন্য হয়ে যায়, ভবিষ্যতের টোকেনের জন্য শূন্য মনোযোগ স্কোর রেখে যায়।
এটি মডেলকে এই শব্দগুলিতে ফোকাস না করতে বলে৷
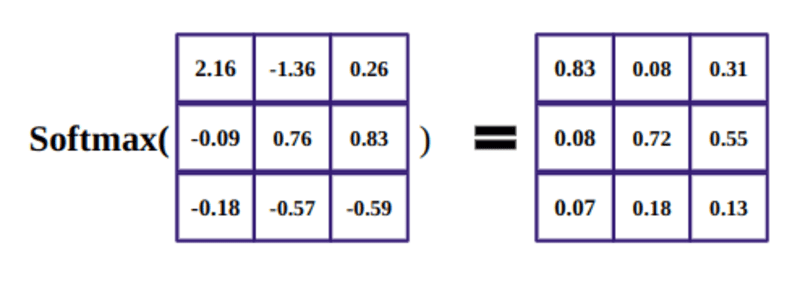
সফটম্যাক্স ফাংশনের উদ্দেশ্য হল বাস্তব সংখ্যা (ধনাত্মক এবং ঋণাত্মক) ধরা এবং তাদের ধনাত্মক সংখ্যায় পরিণত করা যার যোগফল 1।
রবিকুমার নাদুভিন PyTorch ব্যবহার করে NLP কাজগুলি তৈরি এবং বুঝতে ব্যস্ত।
মূল। অনুমতি নিয়ে পোস্ট করা।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- সম্পর্কে
- উপরে
- যোগ
- বিরুদ্ধে
- প্রান্তিককৃত
- সব
- এবং
- যুক্ত
- মনোযোগ
- লেখক
- কারণ
- আগে
- নিচে
- মধ্যে
- ভবন
- গুচ্ছ
- নামক
- কেস
- ঘনিষ্ঠ
- তুলনা
- গনা
- কম্পিউটিং
- ধারণা
- ধারণা
- সংযোগ
- নির্ধারণ
- নির্ণয়
- বিভিন্ন
- মাত্রা
- DOT
- প্রতি
- হিসাব
- উদাহরণ
- ব্যাখ্যা করা
- ভরা
- পরিশেষে
- প্রথম
- কেন্দ্রবিন্দু
- অনুসরণ
- ক্রিয়া
- ক্রিয়াকলাপ
- অধিকতর
- ভবিষ্যৎ
- পাওয়া
- পেয়ে
- GitHub
- দেয়
- দান
- Goes
- দখল
- কিভাবে
- HTTPS দ্বারা
- গুরুত্ব
- গুরুত্বপূর্ণ
- in
- ইন্ডিসিস
- স্বতন্ত্র
- তথ্য
- ইনপুট
- কেডনুগেটস
- চাবি
- কী
- জানা
- স্তর
- শিখতে
- ছোড়
- লিঙ্কডইন
- খুঁজে দেখো
- মাস্ক
- জরায়ু
- অর্থ
- মানে
- পদ্ধতি
- মডেল
- সেতু
- প্রয়োজন
- নেতিবাচক
- নেটওয়ার্ক
- নেটওয়ার্ক
- নিউরাল
- নিউরাল নেটওয়ার্ক
- NLP
- সংখ্যার
- মূল
- অন্যান্য
- কাগজ
- বিশেষ
- গৃহীত
- অনুমতি
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- অবস্থান
- অবস্থানের
- ধনাত্মক
- প্রক্রিয়াজাতকরণ
- পণ্য
- উদ্দেশ্য
- করা
- পাইটার্চ
- পড়া
- বাস্তব
- কারণ
- আবৃত্তি
- হ্রাস করা
- বোঝায়
- সংশ্লিষ্ট
- চিত্রিত করা
- প্রতিনিধিত্ব
- প্রতিনিধিত্ব করে
- ফল
- ফলে এবং
- প্রত্যাবর্তন
- একই
- বাক্য
- ক্রম
- উচিত
- অনুরূপ
- আয়তন
- So
- কিছু
- চৌকাকৃতি
- দোকান
- টেবিল
- গ্রহণ করা
- কাজ
- বলে
- শর্তাবলী
- সার্জারির
- চিন্তা
- দ্বারা
- থেকে
- টোকেন
- ট্রান্সফরমার
- চালু
- বোধশক্তি
- us
- মূল্য
- মানগুলি
- ওজন
- যে
- ইচ্ছা
- শব্দ
- শব্দ
- zephyrnet
- শূন্য