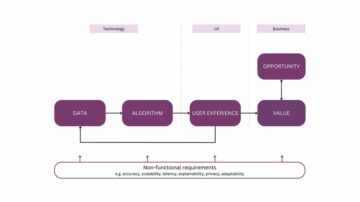
গ্রাফ নিউরাল নেটওয়ার্ক (GNNs) গ্রাফ ডেটা থেকে শেখার জন্য আদর্শ টুলবক্স হিসাবে আবির্ভূত হয়েছে। জিএনএনগুলি বিভিন্ন ক্ষেত্রে উচ্চ-প্রভাবিত সমস্যাগুলির জন্য উন্নতি করতে সক্ষম, যেমন বিষয়বস্তু সুপারিশ বা ওষুধ আবিষ্কার। অন্যান্য ধরনের ডেটা যেমন ইমেজ থেকে ভিন্ন, গ্রাফ ডেটা থেকে শেখার জন্য নির্দিষ্ট পদ্ধতির প্রয়োজন হয়। দ্বারা সংজ্ঞায়িত হিসাবে মাইকেল ব্রনস্টেইন:
[..] এই পদ্ধতিগুলি বিভিন্ন নোডগুলিকে তথ্য আদান-প্রদান করার অনুমতি দেয় গ্রাফে পাস করা কিছু বার্তার উপর ভিত্তি করে।
গ্রাফগুলিতে নির্দিষ্ট কাজগুলি সম্পন্ন করার জন্য (নোডের শ্রেণিবিন্যাস, লিঙ্কের পূর্বাভাস, ইত্যাদি), একটি GNN স্তর তথাকথিত মাধ্যমে নোড এবং প্রান্তের উপস্থাপনা গণনা করে। পুনরাবৃত্ত প্রতিবেশী বিস্তার (অথবা বার্তা পাস) এই নীতি অনুসারে, প্রতিটি গ্রাফ নোড স্থানীয় গ্রাফ কাঠামোর প্রতিনিধিত্ব করার জন্য তার প্রতিবেশীদের কাছ থেকে বৈশিষ্ট্যগুলি গ্রহণ করে এবং একত্রিত করে: বিভিন্ন ধরনের GNN স্তরগুলি বিভিন্ন একত্রীকরণ কৌশল সম্পাদন করে।
GNN স্তরের সহজতম ফর্মুলেশন, যেমন গ্রাফ কনভোলিউশনাল নেটওয়ার্ক (GCNs) বা GraphSage, একটি আইসোট্রপিক একত্রীকরণ চালায়, যেখানে প্রতিটি প্রতিবেশী কেন্দ্রীয় নোডের উপস্থাপনা আপডেট করতে সমানভাবে অবদান রাখে। এই ব্লগ পোস্টটি গ্রাফ অ্যাটেনশন নেটওয়ার্ক (GATs) এর বিশ্লেষণের জন্য নিবেদিত একটি মিনি-সিরিজ (2টি নিবন্ধ) উপস্থাপন করেছে, যা পুনরাবৃত্ত আশেপাশের বিস্তারে একটি অ্যানিসোট্রপি অপারেশনকে সংজ্ঞায়িত করে। অ্যানিসোট্রপি দৃষ্টান্তকে কাজে লাগিয়ে, মনোযোগের প্রক্রিয়া দ্বারা শেখার ক্ষমতা উন্নত হয়, যা প্রতিটি প্রতিবেশীর অবদানকে আলাদা গুরুত্ব দেয়।
এই ওয়ার্ম-আপটি ডিপ গ্রাফ লাইব্রেরি দ্বারা রিপোর্ট করা GAT বিবরণের উপর ভিত্তি করে ওয়েবসাইট.
GAT স্তরের আচরণ বোঝার আগে, আসুন GCN স্তর দ্বারা সম্পাদিত একত্রিতকরণের পিছনের গণিতটি পুনরুদ্ধার করি।
GCN লেয়ার — অ্যাগ্রিগেশন ফাংশন
N নোডের ওয়ান-হপ প্রতিবেশীদের সেট i. এই নোডটি একটি স্ব-লুপ যোগ করে প্রতিবেশীদের মধ্যেও অন্তর্ভুক্ত করা যেতে পারে।
c গ্রাফ কাঠামোর উপর ভিত্তি করে একটি স্বাভাবিককরণ ধ্রুবক, যা একটি আইসোট্রপিক গড় গণনাকে সংজ্ঞায়িত করে।
σ একটি সক্রিয়করণ ফাংশন, যা রূপান্তরে অ-রৈখিকতার পরিচয় দেয়।
W বৈশিষ্ট্য রূপান্তরের জন্য গৃহীত শেখারযোগ্য পরামিতিগুলির ওজন ম্যাট্রিক্স।
GAT স্তর GCN স্তরের মৌলিক একত্রীকরণ ফাংশনকে প্রসারিত করে, মনোযোগ সহগগুলির মাধ্যমে প্রতিটি প্রান্তকে আলাদা গুরুত্ব প্রদান করে।
GAT স্তর সমীকরণ
সমীকরণ (1) নিম্ন স্তর এমবেডিং এর একটি রৈখিক রূপান্তর ওহে, এবং W এটা শেখার যোগ্য ওজন ম্যাট্রিক্স. এই রূপান্তরটি ইনপুট বৈশিষ্ট্যগুলিকে উচ্চ-স্তরের এবং ঘন বৈশিষ্ট্যগুলিতে রূপান্তর করার জন্য পর্যাপ্ত অভিব্যক্তিপূর্ণ শক্তি অর্জনে সহায়তা করে।
সমীকরণ (2) দুই প্রতিবেশীর মধ্যে একটি জোড়া-ভিত্তিক অ-স্বাভাবিক মনোযোগ স্কোর গণনা করে। এখানে, এটি প্রথমে সংযুক্ত করে z দুটি নোডের এমবেডিং, যেখানে || সংমিশ্রণ বোঝায়। তারপর, এটি এই ধরনের সংমিশ্রণের একটি বিন্দু পণ্য এবং একটি শেখার যোগ্য ওজন ভেক্টর লাগে a. শেষ পর্যন্ত, ডট পণ্যের ফলাফলে একটি LeakyReLU প্রয়োগ করা হয়। মনোযোগ স্কোর বার্তা পাসিং কাঠামোতে একটি প্রতিবেশী নোডের গুরুত্ব নির্দেশ করে।
সমীকরণ (3) প্রতিটি নোডের আগত প্রান্তে মনোযোগ স্কোর স্বাভাবিক করার জন্য একটি সফটম্যাক্স প্রয়োগ করে। সফটম্যাক্স একটি সম্ভাব্যতা বন্টনে পূর্ববর্তী ধাপের আউটপুটকে এনকোড করে। ফলস্বরূপ, মনোযোগের স্কোরগুলি বিভিন্ন নোড জুড়ে অনেক বেশি তুলনীয়।
সমীকরণ (4) GCN সমষ্টির অনুরূপ (বিভাগের শুরুতে সমীকরণ দেখুন)। প্রতিবেশীদের থেকে এমবেডিংগুলিকে একত্রিত করা হয়, মনোযোগের স্কোর দ্বারা মাপানো হয়৷ এই স্কেলিং প্রক্রিয়ার প্রধান পরিণতি হল প্রতিটি আশেপাশের নোড থেকে একটি ভিন্ন অবদান শেখা।
NumPy বাস্তবায়ন
প্রথম ধাপ হল একটি সরল গ্রাফ উপস্থাপন এবং রৈখিক রূপান্তর সম্পাদন করার জন্য উপাদান (ম্যাট্রিস) প্রস্তুত করা।
NumPy কোড
print('nn----- One-hot vector representation of nodes. Shape(n,n)n')
X = np.eye(5, 5)
n = X.shape[0]
np.random.shuffle(X)
print(X) print('nn----- Embedding dimensionn')
emb = 3
print(emb) print('nn----- Weight Matrix. Shape(emb, n)n')
W = np.random.uniform(-np.sqrt(1. / emb), np.sqrt(1. / emb), (emb, n))
print(W) print('nn----- Adjacency Matrix (undirected graph). Shape(n,n)n')
A = np.random.randint(2, size=(n, n))
np.fill_diagonal(A, 1) A = (A + A.T)
A[A > 1] = 1
print(A)
প্রথম ম্যাট্রিক্স নোডগুলির একটি এক-হট এনকোডেড উপস্থাপনা সংজ্ঞায়িত করে (নোড 1 গাঢ়ভাবে দেখানো হয়েছে)। তারপরে, আমরা একটি ওজন ম্যাট্রিক্স সংজ্ঞায়িত করি, সংজ্ঞায়িত এমবেডিং মাত্রাকে কাজে লাগিয়ে। আমি এর 3য় কলাম ভেক্টর হাইলাইট করেছি W কারণ, আপনি শীঘ্রই দেখতে পাবেন, এই ভেক্টরটি নোড 1-এর আপডেটেড উপস্থাপনাকে সংজ্ঞায়িত করে (একটি 1-মান 3য় অবস্থানে শুরু করা হয়)। এই উপাদানগুলি থেকে শুরু করে নোড বৈশিষ্ট্যগুলির জন্য পর্যাপ্ত অভিব্যক্তিপূর্ণ শক্তি অর্জন করতে আমরা রৈখিক রূপান্তর করতে পারি। এই পদক্ষেপের লক্ষ্য হল (এক-হট এনকোডেড) ইনপুট বৈশিষ্ট্যগুলিকে একটি নিম্ন এবং ঘন প্রতিনিধিত্বে রূপান্তর করা।
পরবর্তী অপারেশন প্রতিটি প্রান্তের জন্য স্ব-মনোযোগ সহগ প্রবর্তন করা হয়। আমরা উৎস নোডের উপস্থাপনা এবং প্রান্তের প্রতিনিধিত্বের জন্য গন্তব্য নোডের উপস্থাপনাকে সংযুক্ত করি। এই সংযোজন প্রক্রিয়া সংলগ্ন ম্যাট্রিক্স দ্বারা সক্রিয় করা হয়েছে A, যা গ্রাফের সমস্ত নোডের মধ্যে সম্পর্ক সংজ্ঞায়িত করে।
GAT স্তর (সমীকরণ 2)
NumPy কোড
# equation (2) - First part
print('nn----- Concat hidden features to represent edges. Shape(len(emb.concat(emb)), number of edges)n')
edge_coords = np.where(A==1)
h_src_nodes = z1[edge_coords[0]]
h_dst_nodes = z1[edge_coords[1]]
z2 = np.concatenate((h_src_nodes, h_dst_nodes), axis=1)
পূর্ববর্তী ব্লকে, আমি নোড 4 এর সাথে সংযুক্ত 4টি ইন-এজকে প্রতিনিধিত্বকারী 1টি সারি হাইলাইট করেছি। প্রতিটি সারির প্রথম 3টি উপাদান নোড 1 প্রতিবেশীর এমবেডিং উপস্থাপনাকে সংজ্ঞায়িত করে, যেখানে প্রতিটি সারির অন্য 3টি উপাদান নোড 1-এর সাথে সংযুক্ত এম্বেডিংগুলিকে সংজ্ঞায়িত করে নোড XNUMX নিজেই (যেমন আপনি লক্ষ্য করতে পারেন, প্রথম সারিটি একটি স্ব-লুপ এনকোড করে)।
এই ক্রিয়াকলাপের পরে, আমরা মনোযোগ সহগগুলি প্রবর্তন করতে পারি এবং সংযুক্তকরণ প্রক্রিয়ার ফলে, প্রান্তের প্রতিনিধিত্বের সাথে তাদের গুণ করতে পারি। অবশেষে, Leaky Relu ফাংশন এই পণ্যের আউটপুট প্রয়োগ করা হয়.
NumPy কোড
# equation (2) - Second part
print('nn----- Attention coefficients. Shape(1, len(emb.concat(emb)))n')
att = np.random.rand(1, z2.shape[1])
print(att) print('nn----- Edge representations combined with the attention coefficients. Shape(1, number of edges)n')
z2_att = z2.dot(att.T)
print(z2_att) print('nn----- Leaky Relu. Shape(1, number of edges)')
e = leaky_relu(z2_att)
print(e)
এই প্রক্রিয়ার শেষে, আমরা গ্রাফের প্রতিটি প্রান্তের জন্য একটি ভিন্ন স্কোর অর্জন করেছি। উপরের ব্লকে, আমি প্রথম প্রান্তের সাথে যুক্ত সহগটির বিবর্তন তুলে ধরেছি। তারপর, বিভিন্ন নোড জুড়ে সহগকে সহজে তুলনীয় করতে, প্রতিটি গন্তব্য নোডের জন্য সমস্ত প্রতিবেশীর অবদানে একটি সফটম্যাক্স ফাংশন প্রয়োগ করা হয়।
আপনি দেখতে পাচ্ছেন, প্রান্তগুলিকে সংজ্ঞায়িত করার জন্য 1টি মান থাকার পরিবর্তে, আমরা প্রতিটি প্রতিবেশীর অবদানকে পুনরায় স্কেল করেছি। চূড়ান্ত ধাপ হল আশেপাশের সমষ্টি গণনা করা: প্রতিবেশীদের থেকে এম্বেডিংগুলি গন্তব্য নোডে অন্তর্ভুক্ত করা হয়, মনোযোগের স্কোর দ্বারা স্কেল করা হয়।
ভবিষ্যতের নিবন্ধে, আমি মাল্টি-হেড GAT লেয়ারের পিছনের প্রক্রিয়াগুলি বর্ণনা করব, এবং আমরা লিঙ্ক ভবিষ্যদ্বাণী কাজের জন্য কিছু অ্যাপ্লিকেশন দেখতে পাব।
তথ্যসূত্র
কোডের চলমান সংস্করণ নিম্নলিখিত পাওয়া যায় নোটবই. আপনি একটি DGL বাস্তবায়নও পাবেন, যা বাস্তবায়নের সঠিকতা পরীক্ষা করতে কার্যকর।
Petar Veličković, Guillem Cucurul, Arantxa Casanova, Adriana Romero, Pietro Liò, Yoshua Bengiois-এর থেকে গ্রাফ অ্যাটেনশন নেটওয়ার্কের মূল কাগজ এখানে উপলব্ধ নথিপত্র.
বিষয়টির গভীর ব্যাখ্যার জন্য, আমি ভিডিওটি থেকেও পরামর্শ দিচ্ছি আলেক্সা গর্ডিক.
এই নিবন্ধটি মূলত উপর প্রকাশ করা হয়েছিল ডেটা সায়েন্সের দিকে এবং লেখকের অনুমতি নিয়ে TOPBOTS এ আবার প্রকাশিত।
এই নিবন্ধটি উপভোগ করবেন? আরও এআই আপডেটের জন্য সাইন আপ করুন।
আমরা আরও প্রযুক্তিগত শিক্ষা ছেড়ে দিলে আমরা আপনাকে জানাব।