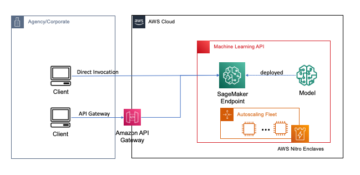
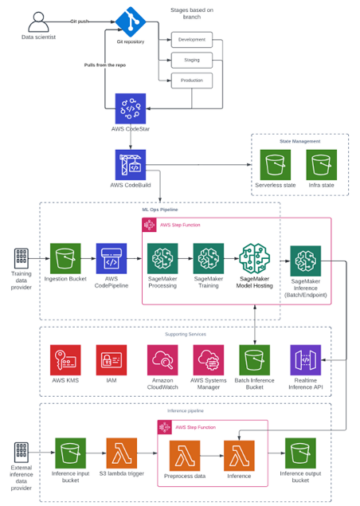
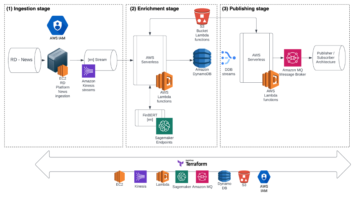
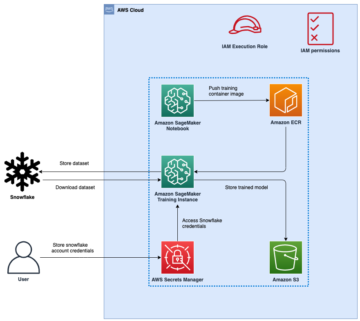
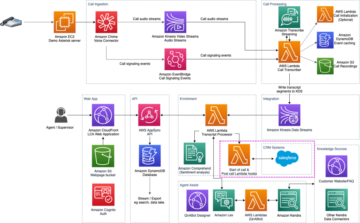
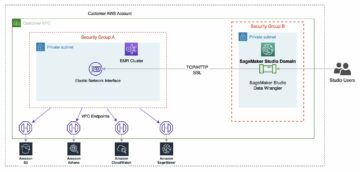
ম্যানগ্রোভ বনগুলি একটি স্বাস্থ্যকর বাস্তুতন্ত্রের একটি আমদানি অংশ, এবং মানব ক্রিয়াকলাপগুলি বিশ্বের উপকূলরেখা থেকে ধীরে ধীরে অন্তর্ধানের একটি প্রধান কারণ। একটি স্যাটেলাইট ইমেজ থেকে ম্যানগ্রোভ অঞ্চল সনাক্ত করতে একটি মেশিন লার্নিং (এমএল) মডেল ব্যবহার করা গবেষকদের সময়ের সাথে বনের আকার নিরীক্ষণ করার একটি কার্যকর উপায় দেয়। ভিতরে পার্ট 1 এই সিরিজের, আমরা দেখিয়েছি কিভাবে একটি স্বয়ংক্রিয় পদ্ধতিতে স্যাটেলাইট ডেটা সংগ্রহ করা যায় এবং এটি বিশ্লেষণ করা যায় অ্যামাজন সেজমেকার স্টুডিও ইন্টারেক্টিভ ভিজ্যুয়ালাইজেশন সহ। এই পোস্টে, আমরা কীভাবে ব্যবহার করব তা দেখাই অ্যামাজন সেজমেকার অটোপাইলট একটি কাস্টম ম্যানগ্রোভ ক্লাসিফায়ার নির্মাণের প্রক্রিয়া স্বয়ংক্রিয় করতে।
অটোপাইলটের সাথে একটি মডেলকে প্রশিক্ষণ দিন
অটোপাইলট বেশ কয়েকটি মডেল তৈরি করার এবং সেরাটি নির্বাচন করার একটি ভারসাম্যপূর্ণ উপায় প্রদান করে। ন্যূনতম প্রচেষ্টার সাথে বিভিন্ন ডেটা প্রিপ্রসেসিং কৌশল এবং ML মডেলগুলির একাধিক সমন্বয় তৈরি করার সময়, অটোপাইলট ইচ্ছা করলে ডেটা বিজ্ঞানীকে এই উপাদান পদক্ষেপগুলির উপর সম্পূর্ণ নিয়ন্ত্রণ প্রদান করে।
আপনি AWS SDK-এর একটি ব্যবহার করে অটোপাইলট ব্যবহার করতে পারেন (বিস্তারিত Autopilot জন্য API রেফারেন্স গাইড) বা স্টুডিওর মাধ্যমে। এই বিভাগে বর্ণিত পদক্ষেপগুলি অনুসরণ করে আমরা আমাদের স্টুডিও সমাধানে অটোপাইলট ব্যবহার করি:
- স্টুডিও লঞ্চার পৃষ্ঠায়, এর জন্য প্লাস চিহ্নটি বেছে নিন নতুন অটোপাইলট পরীক্ষা.

- জন্য আপনার ডেটা সংযুক্ত করুন, নির্বাচন করুন S3 বালতি খুঁজুন, এবং বালতির নাম লিখুন যেখানে আপনি প্রশিক্ষণ এবং পরীক্ষার ডেটাসেট রেখেছিলেন।
- জন্য ডেটাসেট ফাইলের নাম, আপনার তৈরি করা প্রশিক্ষণ ডেটা ফাইলের নাম লিখুন প্রশিক্ষণের তথ্য প্রস্তুত করুন বিভাগে পার্ট 1.
- জন্য আউটপুট ডেটা অবস্থান (S3 বালতি), আপনি ধাপ 2 এ ব্যবহার করা একই বালতি নাম লিখুন।
- জন্য ডেটাসেট ডিরেক্টরির নাম, বালতির নীচে একটি ফোল্ডারের নাম লিখুন যেখানে আপনি অটোপাইলটকে আর্টিফ্যাক্টগুলি সংরক্ষণ করতে চান৷
- জন্য আপনার S3 ইনপুট একটি ম্যানিফেস্ট ফাইল?নির্বাচন বন্ধ.
- জন্য লক্ষ্যনির্বাচন লেবেল.
- জন্য স্বয়ংক্রিয় স্থাপননির্বাচন বন্ধ.

- অধীনে উন্নত সেটিংসজন্য মেশিন লার্নিং সমস্যার ধরননির্বাচন বাইনারি শ্রেণীবিভাগ.
- জন্য উদ্দেশ্য মেট্রিকনির্বাচন AUC.
- জন্য আপনার পরীক্ষা চালানোর উপায় চয়ন করুননির্বাচন না, প্রার্থীর সংজ্ঞা সহ একটি নোটবুক তৈরি করতে একটি পাইলট চালান.
- বেছে নিন পরীক্ষা তৈরি করুন.

একটি পরীক্ষা তৈরি সম্পর্কে আরও তথ্যের জন্য, পড়ুন একটি Amazon SageMaker Autopilot পরীক্ষা তৈরি করুন.এই ধাপটি চালাতে প্রায় 15 মিনিট সময় লাগতে পারে৷ - সম্পূর্ণ হলে, নির্বাচন করুন প্রার্থী প্রজন্মের নোটবুক খুলুন, যা শুধুমাত্র-পঠন মোডে একটি নতুন নোটবুক খোলে।

- বেছে নিন নোটবুক আমদানি করুন নোটবুক সম্পাদনাযোগ্য করতে।

- ছবির জন্য, নির্বাচন করুন ডেটা বিজ্ঞান.
- জন্য শাঁসনির্বাচন পাইথন 3.
- বেছে নিন নির্বাচন করা.

এই স্বয়ংক্রিয়-উত্পন্ন নোটবুকের বিস্তারিত ব্যাখ্যা রয়েছে এবং অনুসরণ করার জন্য প্রকৃত মডেল বিল্ডিং টাস্কের উপর সম্পূর্ণ নিয়ন্ত্রণ প্রদান করে। একটি কাস্টমাইজড সংস্করণ নোটবই, যেখানে 2013 থেকে ল্যান্ডস্যাট স্যাটেলাইট ব্যান্ডগুলি ব্যবহার করে একটি শ্রেণিবদ্ধকারীকে প্রশিক্ষণ দেওয়া হয়, এর অধীনে কোড সংগ্রহস্থলে উপলব্ধ notebooks/mangrove-2013.ipynb.
মডেল বিল্ডিং ফ্রেমওয়ার্ক দুটি অংশ নিয়ে গঠিত: ডেটা প্রসেসিং ধাপের অংশ হিসেবে বৈশিষ্ট্য রূপান্তর এবং মডেল নির্বাচন ধাপের অংশ হিসেবে হাইপারপ্যারামিটার অপ্টিমাইজেশান (HPO)। এই কাজের জন্য সমস্ত প্রয়োজনীয় শিল্পকর্ম অটোপাইলট পরীক্ষার সময় তৈরি করা হয়েছিল এবং সংরক্ষণ করা হয়েছিল আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3)। প্রথম নোটবুক সেল সেই নিদর্শনগুলিকে Amazon S3 থেকে স্থানীয়ভাবে ডাউনলোড করে আমাজন সেজমেকার পরিদর্শন এবং কোনো প্রয়োজনীয় পরিবর্তনের জন্য ফাইল সিস্টেম। দুটি ফোল্ডার আছে: generated_module এবং sagemaker_automl, যেখানে নোটবুক চালানোর জন্য প্রয়োজনীয় সমস্ত পাইথন মডিউল এবং স্ক্রিপ্ট সংরক্ষণ করা হয়। অভিযোজন, স্কেলিং, এবং PCA এর মত বিভিন্ন বৈশিষ্ট্য রূপান্তর পদক্ষেপ হিসাবে সংরক্ষিত হয় generated_modules/candidate_data_processors/dpp*.py.
অটোপাইলট XGBoost, লিনিয়ার লার্নার এবং মাল্টি-লেয়ার পারসেপ্টরন (MLP) অ্যালগরিদমের উপর ভিত্তি করে তিনটি ভিন্ন মডেল তৈরি করে। একটি প্রার্থী পাইপলাইন বৈশিষ্ট্য রূপান্তর বিকল্পগুলির মধ্যে একটি নিয়ে গঠিত, যা নামে পরিচিত data_transformer, এবং একটি অ্যালগরিদম। একটি পাইপলাইন একটি পাইথন অভিধান এবং নিম্নরূপ সংজ্ঞায়িত করা যেতে পারে:
এই উদাহরণে, পাইপলাইন ইন স্ক্রিপ্ট অনুযায়ী প্রশিক্ষণ ডেটা রূপান্তরিত করে generated_modules/candidate_data_processors/dpp5.py এবং একটি XGBoost মডেল তৈরি করে। এখানেই অটোপাইলট ডেটা বিজ্ঞানীকে সম্পূর্ণ নিয়ন্ত্রণ প্রদান করে, যারা স্বয়ংক্রিয়ভাবে উৎপন্ন বৈশিষ্ট্য রূপান্তর এবং মডেল নির্বাচনের ধাপগুলি বেছে নিতে পারে বা তাদের নিজস্ব সমন্বয় তৈরি করতে পারে।
আপনি এখন নিম্নরূপ পরীক্ষা চালানোর জন্য অটোপাইলটের জন্য একটি পুলে পাইপলাইন যোগ করতে পারেন:
এটি একটি গুরুত্বপূর্ণ পদক্ষেপ যেখানে আপনি মোট রানটাইম কমাতে বিষয়গত দক্ষতার উপর ভিত্তি করে অটোপাইলট দ্বারা প্রস্তাবিত প্রার্থীদের শুধুমাত্র একটি উপসেট রাখার সিদ্ধান্ত নিতে পারেন। আপাতত, সমস্ত অটোপাইলট পরামর্শ রাখুন, যা আপনি নিম্নরূপ তালিকাভুক্ত করতে পারেন:
| প্রার্থীর নাম | অ্যালগরিদম | বৈশিষ্ট্য ট্রান্সফরমার |
| dpp0-xgboost | xgboost | dpp0.py |
| dpp1-xgboost | xgboost | dpp1.py |
| dpp2-লিনিয়ার-শিক্ষক | রৈখিক-শিক্ষক | dpp2.py |
| dpp3-xgboost | xgboost | dpp3.py |
| dpp4-xgboost | xgboost | dpp4.py |
| dpp5-xgboost | xgboost | dpp5.py |
| dpp6-mlp | mlp | dpp6.py |
সম্পূর্ণ অটোপাইলট পরীক্ষা দুটি অংশে করা হয়। প্রথমত, আপনাকে ডেটা ট্রান্সফরমেশন কাজগুলি চালাতে হবে:
আপনি যদি আর কোন পরিবর্তন না করেন তবে সমস্ত প্রার্থীদের জন্য এই পদক্ষেপটি প্রায় 30 মিনিটের মধ্যে সম্পন্ন করা উচিত dpp*.py ফাইল।
পরবর্তী ধাপ হল সংশ্লিষ্ট অ্যালগরিদমের জন্য হাইপারপ্যারামিটার টিউন করে মডেলের সেরা সেট তৈরি করা। হাইপারপ্যারামিটারগুলি সাধারণত দুটি ভাগে বিভক্ত হয়: স্ট্যাটিক এবং টিউনেবল। স্ট্যাটিক হাইপারপ্যারামিটারগুলি একই অ্যালগরিদম ভাগ করে এমন সমস্ত প্রার্থীদের জন্য পরীক্ষা জুড়ে অপরিবর্তিত থাকে। এই হাইপারপ্যারামিটারগুলি একটি অভিধান হিসাবে পরীক্ষায় পাস করা হয়। আপনি যদি পাঁচ-গুণ ক্রস-ভ্যালিডেশন স্কিমের তিনটি রাউন্ড থেকে AUC সর্বাধিক করে সেরা XGBoost মডেল বেছে নিতে চান, অভিধানটি নিম্নলিখিত কোডের মতো দেখায়:
টিউনযোগ্য হাইপারপ্যারামিটারের জন্য, আপনাকে রেঞ্জ এবং স্কেলিং টাইপ সহ আরেকটি অভিধান পাস করতে হবে:
হাইপারপ্যারামিটারের সম্পূর্ণ সেট পাওয়া যায় mangrove-2013.ipynb নোটবই.
একটি পরীক্ষা তৈরি করতে যেখানে সমস্ত সাত প্রার্থীকে সমান্তরালভাবে পরীক্ষা করা যেতে পারে, একটি মাল্টি-অ্যালগরিদম HPO টিউনার তৈরি করুন:
প্রতিটি অ্যালগরিদমের জন্য উদ্দেশ্য মেট্রিক্স স্বাধীনভাবে সংজ্ঞায়িত করা হয়:
সমস্ত পরীক্ষা-নিরীক্ষার জন্য হাইপারপ্যারামিটারের সমস্ত সম্ভাব্য মান চেষ্টা করা বৃথা; আপনি একটি HPO টিউনার তৈরি করতে একটি Bayesian কৌশল গ্রহণ করতে পারেন:
ডিফল্ট সেটিংয়ে, অটোপাইলট সেরা মডেল বাছাই করতে টিউনারে 250টি কাজ বেছে নেয়। এই ব্যবহারের ক্ষেত্রে, এটি সেট করা যথেষ্ট max_jobs=50 হাইপারপ্যারামিটারের সেরা সেট বাছাই করার ক্ষেত্রে কোন উল্লেখযোগ্য জরিমানা ছাড়াই সময় এবং সংস্থান বাঁচাতে। অবশেষে, নিম্নরূপ HPO কাজ জমা দিন:
ml.m80x বড় দৃষ্টান্তে প্রক্রিয়াটি প্রায় 5.4 মিনিট সময় নেয়। আপনি বেছে নিয়ে সেজমেকার কনসোলে অগ্রগতি নিরীক্ষণ করতে পারেন হাইপারপ্যারামিটার টিউনিং কাজ অধীনে প্রশিক্ষণ নেভিগেশন ফলকে।

আপনি প্রগতিশীল কাজের নাম বেছে নিয়ে প্রতিটি প্রার্থীর কর্মক্ষমতা সহ দরকারী তথ্যের একটি হোস্ট কল্পনা করতে পারেন।

অবশেষে, সেরা প্রার্থীদের মডেল পারফরম্যান্সের তুলনা করুন নিম্নরূপ:
| প্রার্থী | AUC | রান_টাইম (গুলি) |
| dpp6-mlp | 0.96008 | 2711.0 |
| dpp4-xgboost | 0.95236 | 385.0 |
| dpp3-xgboost | 0.95095 | 202.0 |
| dpp4-xgboost | 0.95069 | 458.0 |
| dpp3-xgboost | 0.95015 | 361.0 |
এমএলপি-র উপর ভিত্তি করে সেরা পারফরমিং মডেল, যদিও ডেটা প্রসেসিং পদক্ষেপের বিভিন্ন পছন্দ সহ XGBoost মডেলগুলির তুলনায় সামান্য ভাল, প্রশিক্ষণের জন্যও অনেক বেশি সময় লাগে। আপনি নিম্নলিখিত হিসাবে ব্যবহৃত হাইপারপ্যারামিটারের সংমিশ্রণ সহ MLP মডেল প্রশিক্ষণ সম্পর্কে গুরুত্বপূর্ণ বিবরণ পেতে পারেন:
| প্রশিক্ষণ কাজের নাম | mangrove-2-notebook–211021-2016-012-500271c8 |
| প্রশিক্ষণ জব স্ট্যাটাস | সম্পন্ন হয়েছে |
| ফাইনাল অবজেক্টিভ ভ্যালু | 0.96008 |
| প্রশিক্ষণ শুরুর সময় | 2021-10-21 20:22:55+00:00 |
| প্রশিক্ষণ শেষ সময় | 2021-10-21 21:08:06+00:00 |
| প্রশিক্ষণ অতিবাহিত সময় সেকেন্ড | 2711 |
| TrainingJob DefinitionName | dpp6-mlp |
| ড্রপআউট_সমস্যা | 0.415778 |
| এমবেডিং_সাইজ_ফ্যাক্টর | 0.849226 |
| স্তর | 256 |
| শেখার_হার | 0.00013862 |
| mini_batch_size | 317 |
| নেটওয়ার্ক টাইপ | ফিডফোর্ড |
| ওজন_ক্ষয় | 1.29323e -12 |
একটি অনুমান পাইপলাইন তৈরি করুন
নতুন ডেটাতে অনুমান তৈরি করতে, আপনাকে সেরা মডেল হোস্ট করতে সেজমেকারে একটি অনুমান পাইপলাইন তৈরি করতে হবে যা অনুমান তৈরি করতে পরে কল করা যেতে পারে। সেজমেকার পাইপলাইন মডেলটির উপাদান হিসেবে তিনটি পাত্রের প্রয়োজন: ডেটা ট্রান্সফরমেশন, অ্যালগরিদম এবং ইনভার্স লেবেল ট্রান্সফরমেশন (যদি সংখ্যাসূচক ভবিষ্যদ্বাণীগুলি অ-সংখ্যাসূচক লেবেলে ম্যাপ করতে হয়)। সংক্ষিপ্ততার জন্য, প্রয়োজনীয় কোডের শুধুমাত্র একটি অংশ নিম্নলিখিত স্নিপেটে দেখানো হয়েছে; সম্পূর্ণ কোড পাওয়া যায় mangrove-2013.ipynb নোটবই:
মডেল কন্টেইনারগুলি তৈরি করার পরে, আপনি নিম্নরূপ পাইপলাইন তৈরি এবং স্থাপন করতে পারেন:
শেষ পয়েন্ট স্থাপনা সম্পূর্ণ হতে প্রায় 10 মিনিট সময় নেয়।
একটি শেষ পয়েন্ট ব্যবহার করে পরীক্ষার ডেটাসেটের উপর অনুমান পান
এন্ডপয়েন্ট মোতায়েন করার পরে, আপনি একটি চিত্রের প্রতিটি পিক্সেলকে ম্যানগ্রোভ (1) বা অন্য (7) হিসাবে শ্রেণীবদ্ধ করতে B1–B0 বৈশিষ্ট্যগুলির একটি পেলোড সহ এটিকে আহ্বান করতে পারেন:
মূল্যায়ন এবং প্লটিংয়ের জন্য মডেল ভবিষ্যদ্বাণীগুলির পোস্টপ্রসেসিং সম্পর্কে সম্পূর্ণ বিবরণ পাওয়া যায় notebooks/model_performance.ipynb.
একটি ব্যাচ ট্রান্সফর্ম ব্যবহার করে পরীক্ষার ডেটাসেটের অনুমান পান
এখন আপনি অটোপাইলট দিয়ে সেরা-পারফর্মিং মডেল তৈরি করেছেন, আমরা অনুমানের জন্য মডেলটি ব্যবহার করতে পারি। বড় ডেটাসেটের অনুমান পেতে, একটি ব্যাচ ট্রান্সফর্ম ব্যবহার করা আরও দক্ষ। আসুন পুরো ডেটাসেটের (প্রশিক্ষণ এবং পরীক্ষা) ভবিষ্যদ্বাণী তৈরি করি এবং ফলাফলগুলিকে বৈশিষ্ট্যগুলিতে যুক্ত করি, যাতে আমরা আরও বিশ্লেষণ করতে পারি, উদাহরণস্বরূপ, ভবিষ্যদ্বাণী করা বনাম বাস্তব এবং ভবিষ্যদ্বাণী করা ক্লাসগুলির মধ্যে বৈশিষ্ট্যগুলির বিতরণ পরীক্ষা করতে পারি৷
প্রথমত, আমরা Amazon S3-এ একটি ম্যানিফেস্ট ফাইল তৈরি করি যা পূর্ববর্তী ডেটা প্রক্রিয়াকরণ পদক্ষেপগুলি থেকে প্রশিক্ষণের অবস্থান এবং পরীক্ষার ডেটা নির্দেশ করে:
এখন আমরা একটি ব্যাচ ট্রান্সফর্ম কাজ তৈরি করতে পারি। কারণ আমাদের ইনপুট ট্রেন এবং টেস্ট ডেটাসেট আছে label শেষ কলাম হিসাবে, অনুমানের সময় আমাদের এটি ফেলে দিতে হবে। যে করতে, আমরা পাস InputFilter মধ্যে DataProcessing যুক্তি. কোড "$[:-2]" শেষ কলাম ড্রপ ইঙ্গিত. পরবর্তী বিশ্লেষণের জন্য পূর্বাভাসিত আউটপুট উত্স ডেটার সাথে যুক্ত হয়।
নিম্নলিখিত কোডে, আমরা ব্যাচ ট্রান্সফর্ম কাজের জন্য আর্গুমেন্ট তৈরি করি এবং তারপরে পাস করি create_transform_job ফাংশন:
আপনি SageMaker কনসোলে কাজের অবস্থা নিরীক্ষণ করতে পারেন।

মডেল কর্মক্ষমতা কল্পনা করুন
আপনি এখন একটি বিভ্রান্তি ম্যাট্রিক্স হিসাবে ভারত, মায়ানমার, কিউবা এবং ভিয়েতনাম থেকে অঞ্চলগুলি নিয়ে গঠিত পরীক্ষার ডেটাসেটে সেরা মডেলের কার্যকারিতা কল্পনা করতে পারেন৷ মডেলটিতে ম্যানগ্রোভের প্রতিনিধিত্বকারী পিক্সেলগুলির জন্য একটি উচ্চ প্রত্যাহার মান রয়েছে, তবে মাত্র 75% নির্ভুলতা। নন-ম্যানগ্রোভ বা অন্যান্য পিক্সেলের নির্ভুলতা 99% রিকল সহ 85% এ দাঁড়িয়েছে। আপনি নির্দিষ্ট ব্যবহারের ক্ষেত্রে নির্ভর করে সংশ্লিষ্ট মানগুলি সামঞ্জস্য করতে মডেল ভবিষ্যদ্বাণীগুলির সম্ভাব্যতা কাটঅফ টিউন করতে পারেন।


এটি লক্ষণীয় যে বিল্ট-ইন স্মাইলকার্ট মডেলের তুলনায় ফলাফলগুলি একটি উল্লেখযোগ্য উন্নতি।
মডেল ভবিষ্যদ্বাণী কল্পনা করুন
অবশেষে, মানচিত্রে নির্দিষ্ট অঞ্চলে মডেলের কার্যকারিতা পর্যবেক্ষণ করা দরকারী। নিম্নলিখিত ছবিতে, ভারত-বাংলাদেশ সীমান্তের ম্যানগ্রোভ এলাকাটিকে লাল রঙে চিত্রিত করা হয়েছে। টেস্ট ডেটাসেটের অন্তর্গত ল্যান্ডস্যাট ইমেজ প্যাচ থেকে নমুনা করা পয়েন্টগুলি অঞ্চলের উপর চাপানো হয়, যেখানে প্রতিটি বিন্দু একটি পিক্সেল যা মডেলটি ম্যানগ্রোভের প্রতিনিধিত্ব করে তা নির্ধারণ করে। নীল বিন্দুগুলি মডেল দ্বারা সঠিকভাবে শ্রেণীবদ্ধ করা হয়, যেখানে কালো পয়েন্টগুলি মডেলের ভুলগুলিকে উপস্থাপন করে।

নিম্নলিখিত চিত্রটি কেবলমাত্র সেই পয়েন্টগুলি দেখায় যা মডেলটি ম্যানগ্রোভকে প্রতিনিধিত্ব করবে না বলে ভবিষ্যদ্বাণী করেছিল, পূর্বের উদাহরণের মতো একই রঙের স্কিম। ধূসর রূপরেখাটি ল্যান্ডস্যাট প্যাচের অংশ যা কোনো ম্যানগ্রোভ অন্তর্ভুক্ত করে না। চিত্র থেকে স্পষ্ট, মডেলটি জলের উপর বিন্দু শ্রেণীবদ্ধ করতে কোনও ভুল করে না, তবে নিয়মিত পাতার প্রতিনিধিত্বকারী পিক্সেলগুলি থেকে ম্যানগ্রোভের প্রতিনিধিত্বকারী পিক্সেলগুলিকে আলাদা করার সময় একটি চ্যালেঞ্জের সম্মুখীন হয়৷

নিম্নলিখিত চিত্রটি মিয়ানমারের ম্যানগ্রোভ অঞ্চলে মডেলের কর্মক্ষমতা দেখায়।

নিম্নলিখিত ছবিতে, মডেলটি ম্যানগ্রোভ পিক্সেল সনাক্ত করার জন্য একটি ভাল কাজ করে।

পরিষ্কার কর
সেজমেকার ইনফারেন্স এন্ডপয়েন্টটি চলতে থাকলে খরচ বহন করতে থাকে। আপনার কাজ শেষ হলে নিম্নরূপ শেষ পয়েন্ট মুছুন:
উপসংহার
পোস্টের এই সিরিজটি জিআইএস সমস্যা সমাধানের জন্য ডেটা বিজ্ঞানীদের জন্য শেষ থেকে শেষ ফ্রেমওয়ার্ক প্রদান করেছে। পার্ট 1 ETL প্রক্রিয়া এবং তথ্যের সাথে দৃশ্যত ইন্টারঅ্যাক্ট করার একটি সুবিধাজনক উপায় দেখিয়েছে। পার্ট 2 দেখিয়েছে কিভাবে একটি কাস্টম ম্যানগ্রোভ ক্লাসিফায়ার তৈরি করতে স্বয়ংক্রিয়ভাবে অটোপাইলট ব্যবহার করতে হয়।
আপনি এই ফ্রেমওয়ার্কটি ব্যবহার করতে পারেন নতুন স্যাটেলাইট ডেটাসেট অন্বেষণ করতে যাতে ম্যানগ্রোভ শ্রেণীবিভাগের জন্য দরকারী ব্যান্ডগুলির একটি সমৃদ্ধ সেট রয়েছে এবং ডোমেন জ্ঞান অন্তর্ভুক্ত করে বৈশিষ্ট্য প্রকৌশল অন্বেষণ করতে পারেন।
লেখক সম্পর্কে
 আন্দ্রেই ইভানোভিচ তিনি টরন্টো বিশ্ববিদ্যালয়ের কম্পিউটার সায়েন্সের স্নাতকোত্তর ছাত্র এবং টরন্টো বিশ্ববিদ্যালয়ের ইঞ্জিনিয়ারিং সায়েন্স প্রোগ্রামের সাম্প্রতিক স্নাতক, একজন রোবোটিক্স/মেকাট্রনিক্স নাবালকের সাথে মেশিন ইন্টেলিজেন্সে মেজর। তিনি কম্পিউটার দৃষ্টি, গভীর শিক্ষা এবং রোবোটিক্সে আগ্রহী। তিনি আমাজনে তার গ্রীষ্মকালীন ইন্টার্নশিপের সময় এই পোস্টে উপস্থাপিত কাজটি করেছিলেন।
আন্দ্রেই ইভানোভিচ তিনি টরন্টো বিশ্ববিদ্যালয়ের কম্পিউটার সায়েন্সের স্নাতকোত্তর ছাত্র এবং টরন্টো বিশ্ববিদ্যালয়ের ইঞ্জিনিয়ারিং সায়েন্স প্রোগ্রামের সাম্প্রতিক স্নাতক, একজন রোবোটিক্স/মেকাট্রনিক্স নাবালকের সাথে মেশিন ইন্টেলিজেন্সে মেজর। তিনি কম্পিউটার দৃষ্টি, গভীর শিক্ষা এবং রোবোটিক্সে আগ্রহী। তিনি আমাজনে তার গ্রীষ্মকালীন ইন্টার্নশিপের সময় এই পোস্টে উপস্থাপিত কাজটি করেছিলেন।
 ডেভিড ডং অ্যামাজন ওয়েব সার্ভিসেসের একজন ডেটা সায়েন্টিস্ট।
ডেভিড ডং অ্যামাজন ওয়েব সার্ভিসেসের একজন ডেটা সায়েন্টিস্ট।
 অর্কজ্যোতি মিশ্র অ্যামাজন লাস্টমাইল ট্রান্সপোর্টেশনের একজন ডেটা সায়েন্টিস্ট। তিনি পৃথিবীকে সাহায্য করে এমন সমস্যা সমাধানের জন্য কম্পিউটার ভিশন কৌশল প্রয়োগ করার বিষয়ে উত্সাহী। তিনি অলাভজনক সংস্থার সাথে কাজ করতে ভালবাসেন এবং এর প্রতিষ্ঠাতা সদস্য ekipi.org.
অর্কজ্যোতি মিশ্র অ্যামাজন লাস্টমাইল ট্রান্সপোর্টেশনের একজন ডেটা সায়েন্টিস্ট। তিনি পৃথিবীকে সাহায্য করে এমন সমস্যা সমাধানের জন্য কম্পিউটার ভিশন কৌশল প্রয়োগ করার বিষয়ে উত্সাহী। তিনি অলাভজনক সংস্থার সাথে কাজ করতে ভালবাসেন এবং এর প্রতিষ্ঠাতা সদস্য ekipi.org.
- Coinsmart. ইউরোপের সেরা বিটকয়েন এবং ক্রিপ্টো এক্সচেঞ্জ।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. বিনামূল্যে এক্সেস.
- ক্রিপ্টোহক। Altcoin রাডার। বিনামূল্যে ট্রায়াল.
- সূত্র: https://aws.amazon.com/blogs/machine-learning/part-2-identify-mangrove-forests-using-satellite-image-features-using-amazon-sagemaker-studio-and-amazon-sagemaker- অটোপাইলট/
- "
- 10
- 100
- a
- সম্পর্কে
- অনুযায়ী
- ক্রিয়াকলাপ
- অ্যালগরিদম
- আলগোরিদিম
- সব
- মর্দানী স্ত্রীলোক
- অ্যামাজন ওয়েব সার্ভিসেস
- মধ্যে
- বিশ্লেষণ
- বৈশ্লেষিক ন্যায়
- বিশ্লেষণ করা
- অন্য
- প্রয়োগ করা হচ্ছে
- এলাকায়
- আর্গুমেন্ট
- কাছাকাছি
- স্বয়ংক্রিয় পদ্ধতি প্রয়োগ করা
- অটোমেটেড
- স্বয়ংক্রিয়ভাবে
- সহজলভ্য
- ডেস্কটপ AWS
- কারণ
- সর্বোত্তম
- কালো
- শরীর
- সীমান্ত
- নির্মাণ করা
- ভবন
- তৈরী করে
- বিল্ট-ইন
- প্রার্থী
- প্রার্থী
- কেস
- চ্যালেঞ্জ
- পছন্দ
- বেছে নিন
- ক্লাস
- শ্রেণীবিন্যাস
- শ্রেণীবদ্ধ
- কোড
- স্তম্ভ
- সমাহার
- সমন্বয়
- সম্পূর্ণ
- উপাদান
- উপাদান
- কম্পিউটার
- কম্পিউটার বিজ্ঞান
- বিশৃঙ্খলা
- কনসোল
- কন্টেনারগুলি
- চলতে
- নিয়ন্ত্রণ
- সুবিধাজনক
- সৃষ্টি
- নির্মিত
- সৃষ্টি
- তৈরি করা হচ্ছে
- কুবা
- প্রথা
- উপাত্ত
- তথ্য প্রক্রিয়াজাতকরণ
- তথ্য বিজ্ঞানী
- গভীর
- নির্ভর করে
- স্থাপন
- মোতায়েন
- বিস্তৃতি
- বিশদ
- বিস্তারিত
- DID
- বিভিন্ন
- প্রদর্শন
- বিতরণ
- না
- ডোমেইন
- ডাউনলোড
- ড্রপ
- সময়
- প্রতি
- পৃথিবী
- বাস্তু
- কার্যকর
- দক্ষ
- প্রচেষ্টা
- সর্বশেষ সীমা
- শেষপ্রান্ত
- প্রকৌশল
- প্রবেশ করান
- মূল্যায়ন
- উদাহরণ
- পরীক্ষা
- ল্যাপারোস্কোপিক পদ্ধতি
- অন্বেষণ করুণ
- মুখ
- ফ্যাশন
- বৈশিষ্ট্য
- বৈশিষ্ট্য
- পরিশেষে
- প্রথম
- অনুসরণ করা
- অনুসরণ
- অনুসরণ
- প্রতিষ্ঠাতা
- ফ্রেমওয়ার্ক
- থেকে
- সম্পূর্ণ
- ক্রিয়া
- অধিকতর
- উত্পাদন করা
- উত্পন্ন
- প্রজন্ম
- স্নাতক
- ধূসর
- কৌশল
- উচ্চতা
- সাহায্য
- উচ্চ
- কিভাবে
- কিভাবে
- HTTPS দ্বারা
- মানবীয়
- সনাক্ত করা
- চিহ্নিতকরণের
- ভাবমূর্তি
- গুরুত্বপূর্ণ
- উন্নতি
- অন্তর্ভুক্ত করা
- সুদ্ধ
- স্বাধীনভাবে
- ভারত
- তথ্য
- ইনপুট
- উদাহরণ
- বুদ্ধিমত্তা
- ইন্টারেক্টিভ
- আগ্রহী
- IT
- কাজ
- জবস
- যোগদান
- রাখা
- জ্ঞান
- পরিচিত
- লেবেল
- লেবেলগুলি
- বড়
- শিক্ষা
- লাইন
- তালিকা
- স্থানীয়
- অবস্থান
- অবস্থানগুলি
- মেশিন
- মেশিন লার্নিং
- মুখ্য
- করা
- মানচিত্র
- মাস্টার্স
- জরায়ু
- ব্যাপার
- সদস্য
- ছন্দোবিজ্ঞান
- ভুল
- ML
- মডেল
- মডেল
- মনিটর
- অধিক
- বহু
- মিয়ানমার
- ন্যাভিগেশন
- প্রয়োজনীয়
- পরবর্তী
- অলাভজনক
- নোটবই
- প্রর্দশিত
- অপ্টিমাইজেশান
- অপশন সমূহ
- সংগঠন
- অন্যান্য
- নিজের
- অংশ
- বিশেষ
- কামুক
- তালি
- কর্মক্ষমতা
- ক্রিয়াকাণ্ড
- করণ
- চালক
- বিন্দু
- পয়েন্ট
- পুকুর
- সম্ভব
- পোস্ট
- ভবিষ্যতবাণী
- আগে
- সমস্যা
- সমস্যা
- প্রক্রিয়া
- প্রক্রিয়াজাতকরণ
- কার্যক্রম
- প্রদত্ত
- উপলব্ধ
- কারণে
- সাম্প্রতিক
- হ্রাস করা
- এলাকা
- নিয়মিত
- থাকা
- সংগ্রহস্থলের
- চিত্রিত করা
- প্রতিনিধিত্বমূলক
- অনুরোধ
- প্রয়োজনীয়
- প্রয়োজন
- গবেষকরা
- Resources
- ফলাফল
- রোবোটিক্স
- ভূমিকা
- চক্রের
- চালান
- দৌড়
- একই
- উপগ্রহ
- সংরক্ষণ করুন
- আরোহী
- পরিকল্পনা
- বিজ্ঞান
- বিজ্ঞানী
- বিজ্ঞানীরা
- নির্বাচন
- ক্রম
- সেবা
- সেট
- বিন্যাস
- বিভিন্ন
- শেয়ার
- প্রদর্শনী
- প্রদর্শিত
- চিহ্ন
- গুরুত্বপূর্ণ
- সহজ
- আয়তন
- So
- কঠিন
- সমাধান
- সমাধান
- নির্দিষ্ট
- থাকা
- অবস্থা
- স্টোরেজ
- দোকান
- কৌশল
- ছাত্র
- চিত্রশালা
- বিষয়
- গ্রীষ্ম
- পদ্ধতি
- কাজ
- প্রযুক্তি
- শর্তাবলী
- পরীক্ষা
- সার্জারির
- উৎস
- বিশ্ব
- তিন
- দ্বারা
- সর্বত্র
- সময়
- শীর্ষ
- শীর্ষ 5
- টরন্টো
- প্রশিক্ষণ
- রুপান্তর
- রুপান্তর
- রূপান্তরের
- পরিবহন
- অধীনে
- বিশ্ববিদ্যালয়
- ব্যবহার
- সাধারণত
- বৈধতা
- মূল্য
- বিভিন্ন
- সংস্করণ
- দৃষ্টি
- কল্পনা
- পানি
- ওয়েব
- ওয়েব সার্ভিস
- যখন
- হু
- ছাড়া
- হয়া যাই ?
- বিশ্ব
- মূল্য
- X
- আপনার