ভূমিকা
অডিটিং ডেটার জগত জটিল হতে পারে, অনেক চ্যালেঞ্জ কাটিয়ে উঠতে পারে। ডেটাসেটগুলির সাথে কাজ করার সময় শ্রেণীবদ্ধ বৈশিষ্ট্যগুলি পরিচালনা করা সবচেয়ে বড় চ্যালেঞ্জগুলির মধ্যে একটি। এই নিবন্ধে, আমরা অডিটিং ডেটা, অসামঞ্জস্যতা সনাক্তকরণ এবং মডেলগুলিতে শ্রেণীবদ্ধ বৈশিষ্ট্যগুলি এনকোডিংয়ের প্রভাবের জগতে অনুসন্ধান করব।
অডিটিং ডেটার জন্য অসঙ্গতি সনাক্তকরণের সাথে যুক্ত প্রধান চ্যালেঞ্জগুলির মধ্যে একটি হল স্বতন্ত্র বৈশিষ্ট্যগুলি পরিচালনা করা। শ্রেণীগত বৈশিষ্ট্য এনকোডিং বাধ্যতামূলক কারণ মডেলগুলি পাঠ্য ইনপুট ব্যাখ্যা করতে পারে না। সাধারণত, এটি লেবেল এনকোডিং বা ওয়ান হট এনকোডিং ব্যবহার করে করা হয়। যাইহোক, একটি বৃহৎ ডেটাসেটে, এক-হট এনকোডিং মাত্রার অভিশাপের কারণে মডেলের কার্যকারিতা খারাপ হতে পারে।
শিক্ষার উদ্দেশ্য
-
অডিটিং ডেটা এবং চ্যালেঞ্জের ধারণা বোঝার জন্য
- গভীর তত্ত্বাবধানহীন অসঙ্গতি সনাক্তকরণের বিভিন্ন পদ্ধতির মূল্যায়ন করা।
- অডিটিং ডেটাতে অসঙ্গতি সনাক্তকরণের জন্য ব্যবহৃত মডেলগুলিতে শ্রেণীবদ্ধ বৈশিষ্ট্যগুলি এনকোডিংয়ের প্রভাব বোঝার জন্য।
এই নিবন্ধটি একটি অংশ হিসাবে প্রকাশিত হয়েছিল ডেটা সায়েন্স ব্লগাথন.
সুচিপত্র
- Auata কি?
- অসঙ্গতি সনাক্তকরণ কি?
- ডেটা অডিট করার সময় প্রধান চ্যালেঞ্জগুলির সম্মুখীন হন৷
- অসঙ্গতি সনাক্তকরণের জন্য ডেটাসেট নিরীক্ষণ করা
- শ্রেণীগত বৈশিষ্ট্যের এনকোডিং
- শ্রেণীবদ্ধ এনকোডিং
- তত্ত্বাবধানহীন অসঙ্গতি সনাক্তকরণ মডেল
- এনকোডিং শ্রেণীগত বৈশিষ্ট্যগুলি কীভাবে মডেলগুলিকে প্রভাবিত করে?
কার ইন্স্যুরেন্স ডেটাসেটের 8.1 t-SNE উপস্থাপনা
যানবাহন বীমা ডেটাসেটের 8.2 t-SNE উপস্থাপনা
যানবাহন দাবি ডেটাসেটের 8.3 t-SNE উপস্থাপনা - উপসংহার
অডিটিং ডেটা এ?
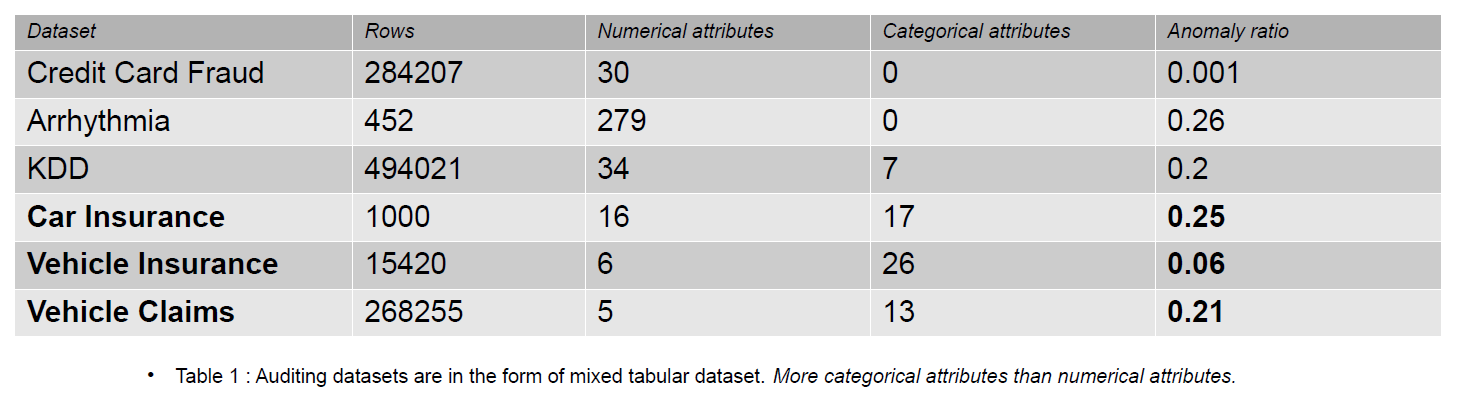
অডিটিং ডেটাতে জার্নাল, বীমা দাবি এবং তথ্য সিস্টেমের জন্য অনুপ্রবেশ ডেটা অন্তর্ভুক্ত থাকতে পারে; এই নিবন্ধে, প্রদত্ত উদাহরণগুলি হল গাড়ির বীমা দাবি। বিমা দাবিগুলি অসংগতি সনাক্তকরণ ডেটাসেট থেকে আলাদা করা যায়, যেমন, KDD, আরও বেশি সংখ্যক শ্রেণীগত বৈশিষ্ট্য দ্বারা।
শ্রেণীবদ্ধ বৈশিষ্ট্যগুলি হল আমাদের ডেটাতে ডিসকিউট যা টাইপ পূর্ণসংখ্যা বা অক্ষর হতে পারে। সংখ্যাসূচক বৈশিষ্ট্যগুলি আমাদের ডেটাতে অবিচ্ছিন্ন বৈশিষ্ট্য যা সর্বদা বাস্তব-মূল্যবান। ক্রেডিট কার্ড জালিয়াতি ডেটার মতো অসঙ্গতি সনাক্তকরণ সম্প্রদায়ে সংখ্যাসূচক বৈশিষ্ট্য সহ ডেটাসেটগুলি জনপ্রিয়। বেশিরভাগ সর্বজনীনভাবে উপলব্ধ ডেটাসেটে বীমা দাবির ডেটার তুলনায় কম শ্রেণীগত বৈশিষ্ট্য রয়েছে। বীমা দাবি ডেটাসেটে সংখ্যাসূচক বৈশিষ্ট্যের তুলনায় শ্রেণীগত বৈশিষ্ট্যগুলি সংখ্যায় বেশি।
একটি বীমা দাবিতে মডেল, ব্র্যান্ড, আয়, খরচ, ইস্যু, রঙ ইত্যাদির মতো বৈশিষ্ট্যগুলি অন্তর্ভুক্ত রয়েছে৷ ক্রেডিট কার্ড এবং কেডিডি ডেটাসেটের তুলনায় অডিটিং ডেটাতে শ্রেণীবদ্ধ বৈশিষ্ট্যের সংখ্যা বেশি৷ এই ডেটাসেটগুলি তত্ত্বাবধানহীন অসঙ্গতি সনাক্তকরণ পদ্ধতিতে বেঞ্চমার্ক। নীচের সারণীতে দেখা গেছে, বীমা দাবির ডেটাসেটগুলিতে আরও স্পষ্ট বৈশিষ্ট্য রয়েছে, যা প্রতারণামূলক ডেটার আচরণ বোঝার জন্য গুরুত্বপূর্ণ।
শ্রেণীবদ্ধ এনকোডিংগুলির প্রভাব মূল্যায়ন করতে ব্যবহৃত অডিটিং ডেটাসেটগুলি হল গাড়ি বীমা, যানবাহন বীমা এবং যানবাহনের দাবি।
অসঙ্গতি সনাক্তকরণ কি?
একটি অসংগতি একটি নির্দিষ্ট দূরত্ব (থ্রেশহোল্ড) দ্বারা একটি ডেটাসেটে স্বাভাবিক ডেটা থেকে অনেক দূরে অবস্থিত একটি পর্যবেক্ষণ। অডিটিং ডেটার ক্ষেত্রে, আমরা জালিয়াতি ডেটা শব্দটিকে পছন্দ করি। অসঙ্গতি সনাক্তকরণ মেশিন লার্নিং বা ডিপ লার্নিং মডেল ব্যবহার করে স্বাভাবিক এবং প্রতারণামূলক ডেটার মধ্যে পার্থক্য করে। বিভিন্ন পদ্ধতি ঘনত্ব অনুমান, পুনর্গঠন ত্রুটি, এবং শ্রেণীবিভাগ পদ্ধতির মত অসঙ্গতি সনাক্তকরণের জন্য ব্যবহার করা যেতে পারে।
- ঘনত্ব অনুমান - এই পদ্ধতিগুলি স্বাভাবিক ডেটা বিতরণ অনুমান করে এবং যদি শেখা বিতরণ থেকে নমুনা না করা হয় তবে অস্বাভাবিক ডেটা শ্রেণীবদ্ধ করে।
- পুনর্গঠন ত্রুটি - পুনর্গঠন ত্রুটি-ভিত্তিক পদ্ধতিগুলি এই নীতির উপর ভিত্তি করে যে সাধারণ ডেটা অস্বাভাবিক ডেটার চেয়ে ছোট ক্ষতির সাথে পুনর্গঠন করা যেতে পারে। পুনঃনির্মাণের ক্ষতি যত বেশি হবে ডেটা একটি অসঙ্গতি হওয়ার সম্ভাবনা বাড়ে।
- শ্রেণিবিন্যাস পদ্ধতি - শ্রেণিবিন্যাস পদ্ধতি যেমন এলোমেলো বন, আইসোলেশন ফরেস্ট, ওয়ান ক্লাস – সাপোর্ট ভেক্টর মেশিন, এবং লোকাল আউটলায়ার ফ্যাক্টরগুলি অসঙ্গতি সনাক্তকরণের জন্য ব্যবহার করা যেতে পারে। অসঙ্গতি সনাক্তকরণে শ্রেণিবিন্যাসের মধ্যে একটি শ্রেণিকে অসঙ্গতি হিসাবে চিহ্নিত করা জড়িত। তবুও, বহু-শ্রেণির দৃশ্যকল্পে ক্লাসগুলিকে দুটি গ্রুপে (0 এবং 1) ভাগ করা হয়েছে, এবং কম ডেটা সহ ক্লাসটি হল অস্বাভাবিক শ্রেণী।
উপরের পদ্ধতির আউটপুট হল অসঙ্গতি স্কোর বা পুনর্গঠন ত্রুটি। তারপরে আমাদের একটি থ্রেশহোল্ডের বিষয়ে সিদ্ধান্ত নিতে হবে, যা অনুসারে আমরা অস্বাভাবিক ডেটা শ্রেণীবদ্ধ করি।
ডেটা অডিট করার সময় প্রধান চ্যালেঞ্জগুলির সম্মুখীন হন৷
- শ্রেণীগত বৈশিষ্ট্য পরিচালনা: শ্রেণীগত বৈশিষ্ট্য এনকোডিং বাধ্যতামূলক কারণ মডেলটি পাঠ্য ইনপুট ব্যাখ্যা করতে পারে না। সুতরাং, মানগুলি লেবেল এনকোডিং বা ওয়ান হট এনকোডিং দিয়ে এনকোড করা হয়। কিন্তু একটি বৃহৎ ডেটাসেটে, ওয়ান হট এনকোডিং বৈশিষ্ট্যের সংখ্যা বাড়িয়ে ডেটাকে একটি উচ্চমাত্রিক স্থানে রূপান্তরিত করে। মডেল কারণে খারাপভাবে সঞ্চালন মাত্রিকতার অভিশাপ.
- শ্রেণীবিভাগের জন্য থ্রেশহোল্ড নির্বাচন করা: যদি ডেটা লেবেল না থাকে, তাহলে মডেলের কর্মক্ষমতা মূল্যায়ন করা কঠিন কারণ আমরা ডেটাসেটে উপস্থিত অসামঞ্জস্যের সংখ্যা জানি না। ডেটাসেট সম্পর্কে পূর্ব জ্ঞান থ্রেশহোল্ড নির্ধারণ করা সহজ করে তোলে। ধরা যাক আমাদের ডেটাতে 5টির মধ্যে 10টি অস্বাভাবিক নমুনা রয়েছে। সুতরাং, আমরা 50 শতাংশ স্কোরে থ্রেশহোল্ড নির্বাচন করতে পারি।
- পাবলিক ডেটাসেট: বেশিরভাগ অডিটিং ডেটাসেটগুলি গোপনীয় কারণ সেগুলি কর্পোরেট কোম্পানিগুলির অন্তর্গত এবং এতে সংবেদনশীল এবং ব্যক্তিগত তথ্য থাকে৷ গোপনীয়তা সমস্যাগুলি প্রশমিত করার একটি সম্ভাব্য উপায় হল সিন্থেটিক ডেটাসেট (যানবাহন দাবি) ব্যবহার করে প্রশিক্ষণ দেওয়া।
অসঙ্গতি সনাক্তকরণের জন্য ডেটাসেট নিরীক্ষণ করা
যানবাহনের জন্য বীমা দাবির মধ্যে গাড়ির বৈশিষ্ট্য, যেমন মডেল, ব্র্যান্ড, মূল্য, বছর এবং জ্বালানির প্রকারের তথ্য অন্তর্ভুক্ত থাকে। এটি ড্রাইভার, জন্ম তারিখ, লিঙ্গ এবং পেশা সম্পর্কে তথ্য অন্তর্ভুক্ত করে। অতিরিক্তভাবে, দাবিতে মেরামতের মোট খরচ সম্পর্কে তথ্য অন্তর্ভুক্ত থাকতে পারে। এই নিবন্ধে ব্যবহৃত ডেটাসেটগুলি সবই একটি একক ডোমেন থেকে, তবে তারা বৈশিষ্ট্যের সংখ্যা এবং দৃষ্টান্তের সংখ্যার মধ্যে পরিবর্তিত হয়৷
-
যানবাহন দাবির ডেটাসেটটি বড়, এতে 250,000 টিরও বেশি সারি রয়েছে এবং এর সুনির্দিষ্ট বৈশিষ্ট্যগুলির মূল বৈশিষ্ট্য রয়েছে 1171। এর বড় আকারের কারণে, এই ডেটাসেটটি মাত্রিকতার অভিশাপে ভোগে।
- যানবাহন বীমা ডেটাসেটটি মাঝারি আকারের, 15,420টি সারি এবং 151টি অনন্য শ্রেণীগত মান সহ। এটি মাত্রিকতার অভিশাপে ভোগার প্রবণতা কম করে তোলে।
- কার ইন্স্যুরেন্স ডেটাসেটটি ছোট, লেবেল এবং 25% অস্বাভাবিক নমুনা সহ, এবং এতে একই সংখ্যক সংখ্যাসূচক এবং শ্রেণীগত বৈশিষ্ট্য রয়েছে। 169টি অনন্য বিভাগ সহ, এটি মাত্রিকতার অভিশাপে ভোগে না।
ক্যাটাগরিক্যাল অ্যাট্রিবিউটের এনকোডিং
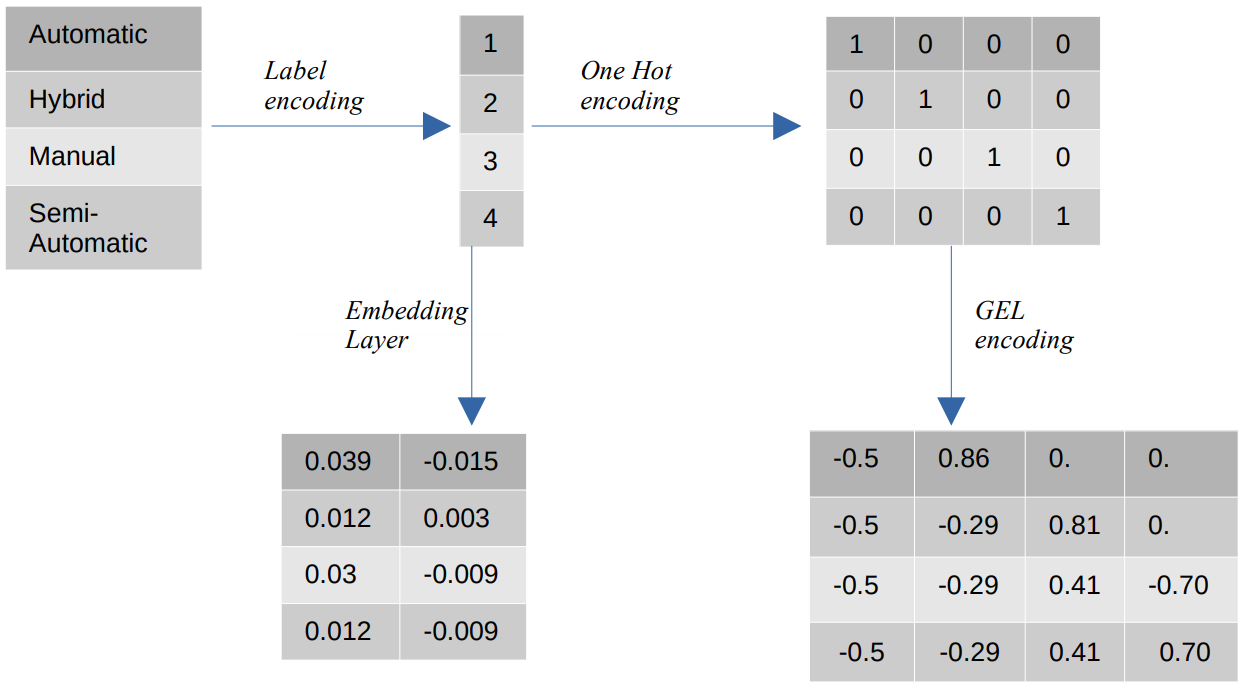
শ্রেণীবদ্ধ মানের বিভিন্ন এনকোডিং
- লেবেল এনকোডিং - লেবেল এনকোডিং-এ, শ্রেণীগত মানগুলি 1 এবং বিভাগের সংখ্যার মধ্যে সাংখ্যিক পূর্ণসংখ্যার মান দিয়ে প্রতিস্থাপিত হয়। লেবেল এনকোডিং অর্ডিনাল মানগুলির জন্য উদ্দেশ্যমূলক উপায়ে বিভাগগুলিকে উপস্থাপন করে। তবুও, যখন বৈশিষ্ট্যগুলি নামমাত্র, উপস্থাপনাটি ভুল কারণ শ্রেণীগত মানগুলি একটি নির্দিষ্ট ক্রম অনুসারে নয়৷
উদাহরণস্বরূপ, যদি আমাদের একটি বৈশিষ্ট্যে স্বয়ংক্রিয়, হাইব্রিড, ম্যানুয়াল এবং আধা-স্বয়ংক্রিয় বিভাগ থাকে, তাহলে লেবেল এনকোডিং এই মানগুলিকে {1: স্বয়ংক্রিয়, 2: হাইব্রিড, 3: ম্যানুয়াল, 4: আধা-স্বয়ংক্রিয়}-এ রূপান্তরিত করে। এই উপস্থাপনাটি শ্রেণীগত মান সম্পর্কে কোন তথ্য প্রদান করে না, তবে একটি উপস্থাপনা যেমন {0: নিম্ন, 1: মাঝারি, 2: উচ্চ} একটি স্পষ্ট উপস্থাপনা প্রদান করে কারণ নিম্ন বৈশিষ্ট্য পরিবর্তনশীল নিম্ন একটি নিম্ন সংখ্যাসূচক মান নির্ধারণ করা হয়েছে। অতএব, লেবেল এনকোডিং অর্ডিনাল মানের জন্য ভালো কিন্তু নামমাত্র মানের জন্য অসুবিধাজনক। - এক হট এনকোডিং - একটি হট এনকোডিং নামমাত্র এনকোডিং মানগুলির সমস্যা সমাধানের জন্য ব্যবহার করা হয়, যা বাইনারি মান সমন্বিত ডেটাসেটের প্রতিটি শ্রেণীগত মানকে একটি স্বতন্ত্র বৈশিষ্ট্যে রূপান্তরিত করে। উদাহরণস্বরূপ, {1, 2, 3, 4} হিসাবে এনকোড করা চারটি ভিন্ন বিভাগের ক্ষেত্রে, একটি হট এনকোডিং নতুন বৈশিষ্ট্য তৈরি করবে যেমন {স্বয়ংক্রিয়: [1,0,0,0], হাইব্রিড: [0,1,0,0 ,0,0,1,0], ম্যানুয়াল: [0,0,0,1], আধা-স্বয়ংক্রিয়: [XNUMX]}।
ডেটাসেটের মাত্রা সরাসরি ডেটাসেটে উপস্থিত বিভাগের সংখ্যার উপর নির্ভর করে। ফলস্বরূপ, ওয়ান হট এনকোডিং মাত্রিকতার অভিশাপের দিকে নিয়ে যেতে পারে, যা এই এনকোডিং পদ্ধতির একটি ত্রুটি। - GEL এনকোডিং - জিইএল এনকোডিং হল একটি এমবেডিং কৌশল যা তত্ত্বাবধানে এবং তত্ত্বাবধানহীন শেখার পদ্ধতিতে ব্যবহার করা যেতে পারে। এটি ওয়ান হট এনকোডিংয়ের নীতির উপর ভিত্তি করে এবং ওয়ান হট এনকোডিং ব্যবহার করে এনকোড করা শ্রেণীগত বৈশিষ্ট্যগুলির মাত্রা হ্রাস করতে ব্যবহার করা যেতে পারে।
- এম্বেডিং লেয়ার - শব্দ এমবেডিংগুলি একটি কম্প্যাক্ট এবং ঘন উপস্থাপনা ব্যবহার করার একটি উপায় প্রদান করে যেখানে একই শব্দের অনুরূপ এনকোডিং রয়েছে। একটি এমবেডিং হল ফ্লোটিং-পয়েন্ট মানগুলির একটি ঘন ভেক্টর যা প্রশিক্ষণযোগ্য পরামিতি। শব্দ এম্বেডিং 8-মাত্রিক (ছোট ডেটাসেটের জন্য) থেকে 1024-মাত্রিক (বড় ডেটাসেটের জন্য) পর্যন্ত হতে পারে।
একটি উচ্চমাত্রিক এম্বেডিং শব্দগুলির মধ্যে আরও বিশদ সম্পর্ক ক্যাপচার করতে পারে, তবে এটি শিখতে আরও ডেটা প্রয়োজন। এমবেডিং লেয়ার হল একটি লুকআপ টেবিল যা ম্যাট্রিক্সে উপস্থিত প্রতিটি শব্দকে একটি নির্দিষ্ট আকারের ভেক্টরে রূপান্তর করে।
তত্ত্বাবধানহীন অসঙ্গতি সনাক্তকরণ মডেল
বাস্তব জগতে, বেশিরভাগ ক্ষেত্রে ডেটা লেবেল করা হয় না, এবং ডেটা লেবেল করা ব্যয়বহুল এবং সময়সাপেক্ষ। অতএব, আমরা আমাদের মূল্যায়নের জন্য তত্ত্বাবধানহীন মডেলগুলি ব্যবহার করব।
- জন্য SOM - স্ব-সংগঠিত মানচিত্র (এসওএম) একটি প্রতিযোগিতামূলক শেখার পদ্ধতি যেখানে ব্যাকপ্রোপগেশন লার্নিং ব্যবহার করার পরিবর্তে নিউরনের ওজন প্রতিযোগিতামূলকভাবে আপডেট করা হয়। এসওএম নিউরনগুলির একটি মানচিত্র নিয়ে গঠিত, প্রতিটিতে ইনপুট ভেক্টরের মতো একই আকারের ওজন ভেক্টর রয়েছে। প্রশিক্ষণ শুরু হওয়ার আগে ওজন ভেক্টরকে এলোমেলো ওজন দিয়ে শুরু করা হয়। প্রশিক্ষণের সময়, প্রতিটি ইনপুটকে দূরত্ব মেট্রিকের (যেমন, ইউক্লিডীয় দূরত্ব) উপর ভিত্তি করে মানচিত্রের নিউরনের সাথে তুলনা করা হয় এবং সেরা ম্যাচিং ইউনিট (BMU) এর সাথে ম্যাপ করা হয়, যা ইনপুট ভেক্টরের সর্বনিম্ন দূরত্ব সহ নিউরন।
BMU এর ওজন ইনপুট ভেক্টরের ওজনের সাথে আপডেট করা হয়, এবং প্রতিবেশী নিউরনগুলি প্রতিবেশী ব্যাসার্ধের (সিগমা) উপর ভিত্তি করে আপডেট করা হয়। যেহেতু নিউরন একে অপরের সাথে সেরা মিলের ইউনিট হওয়ার জন্য প্রতিযোগিতা করে, এই প্রক্রিয়াটি প্রতিযোগিতামূলক শিক্ষা হিসাবে পরিচিত। শেষ পর্যন্ত, স্বাভাবিক নমুনার জন্য নিউরনগুলি অস্বাভাবিকগুলির চেয়ে কাছাকাছি। অসঙ্গতি স্কোরগুলি পরিমাপকরণ ত্রুটি দ্বারা সংজ্ঞায়িত করা হয়, যা ইনপুট নমুনা এবং সেরা মিলিত ইউনিটের ওজনের মধ্যে পার্থক্য। একটি উচ্চ পরিমাপকরণ ত্রুটি নমুনা একটি অসঙ্গতি হওয়ার উচ্চ সম্ভাবনা নির্দেশ করে। - DAGMM - ডিপ অটোএনকোডিং গাউসিয়ান মিক্সচার মডেল (ডিএজিএমএম) হল একটি ঘনত্ব অনুমান পদ্ধতি যা অনুমান করে যে অসঙ্গতিগুলি একটি কম-সম্ভাব্য অঞ্চলে রয়েছে। নেটওয়ার্কটি দুটি অংশে বিভক্ত: একটি কম্প্রেশন নেটওয়ার্ক, যা একটি অটোএনকোডার ব্যবহার করে নিম্ন মাত্রায় ডেটা প্রজেক্ট করতে ব্যবহৃত হয় এবং একটি অনুমান নেটওয়ার্ক, যা গাউসিয়ান মিশ্রণ মডেলের পরামিতিগুলি অনুমান করতে ব্যবহৃত হয়। ডিএজিএমএম গাউসিয়ান মিশ্রণের k সংখ্যা অনুমান করে, যেখানে k 1 থেকে N পর্যন্ত যে কোনো সংখ্যা হতে পারে (ডেটা পয়েন্টের সংখ্যা), এবং এটি ধরে নেওয়া হয় যে স্বাভাবিক বিন্দুগুলি একটি উচ্চ-ঘনত্বের অঞ্চলে থাকে, যার অর্থ একটি থেকে নমুনা নেওয়ার সম্ভাবনা অস্বাভাবিক নমুনার তুলনায় সাধারণ পয়েন্টের জন্য গাউসিয়ান মিশ্রণ বেশি। নমুনার আনুমানিক শক্তি দ্বারা অসঙ্গতি স্কোর সংজ্ঞায়িত করা হয়।
- RSRAE - অনিয়ন্ত্রিত অসঙ্গতি সনাক্তকরণের জন্য শক্তিশালী সারফেস রিকভারি লেয়ার হল একটি পুনর্গঠন ত্রুটি পদ্ধতি যা প্রথমে একটি অটোএনকোডার ব্যবহার করে ডেটাকে নিম্ন মাত্রায় প্রজেক্ট করে। সুপ্ত উপস্থাপনাটি তখন একটি রৈখিক সাবস্পেসে একটি অর্থোগোনাল প্রজেকশনের সাপেক্ষে যা আউটলায়ারদের জন্য শক্তিশালী। ডিকোডার তারপর লিনিয়ার সাবস্পেস থেকে আউটপুট পুনর্গঠন করে। এই পদ্ধতিতে, একটি উচ্চতর পুনর্গঠন ত্রুটি নমুনা একটি অসঙ্গতি হওয়ার উচ্চ সম্ভাবনা নির্দেশ করে।
- SOM-DAGMM- একটি স্ব-সংগঠিত মানচিত্র (SOM) - গভীর অটোএনকোডিং গাউসিয়ান মিশ্রণ মডেল (DAGMM) এছাড়াও একটি ঘনত্ব অনুমান মডেল। DAGMM-এর মতো, এটি স্বাভাবিক ডেটা পয়েন্টের সম্ভাব্যতা বন্টনও অনুমান করে এবং একটি ডেটা পয়েন্টকে একটি অসঙ্গতি হিসাবে শ্রেণীবদ্ধ করে যদি এটি শেখা বিতরণ থেকে নমুনা হওয়ার সম্ভাবনা কম থাকে। SOM-DAGMM এবং DAGMM-এর মধ্যে প্রধান পার্থক্য হল SOM-DAGMM ইনপুট নমুনার জন্য SOM-এর স্বাভাবিক স্থানাঙ্কগুলিকে অন্তর্ভুক্ত করে, যা অনুমান নেটওয়ার্কে DAGMM-এর ক্ষেত্রে অনুপস্থিত টপোলজিক্যাল তথ্য প্রদান করে। উদ্দেশ্যটিও ডিএজিএমএমের অনুরূপ যে নমুনার আনুমানিক শক্তি দ্বারা অসংগতি স্কোর সংজ্ঞায়িত করা হয়, এবং কম শক্তি একটি অসঙ্গতি হিসাবে নমুনার উচ্চ সম্ভাবনা নির্দেশ করে।
এর পরে, আমরা শ্রেণীবদ্ধ বৈশিষ্ট্যগুলি পরিচালনা করার চ্যালেঞ্জ মোকাবেলা করব।
এনকোডিং শ্রেণীগত বৈশিষ্ট্যগুলি কীভাবে মডেলগুলিকে প্রভাবিত করে?
ডেটাসেটগুলিতে বিভিন্ন এনকোডিংয়ের প্রভাব বোঝার জন্য, আমরা বিভিন্ন এনকোডিংয়ের জন্য ডেটার নিম্ন-মাত্রিক উপস্থাপনাগুলি কল্পনা করতে t-SNE ব্যবহার করব। t-SNE উচ্চ-মাত্রিক ডেটাকে নিম্ন-মাত্রিক স্থানে প্রজেক্ট করে, এটিকে কল্পনা করা সহজ করে তোলে। একই ডেটাসেটের বিভিন্ন এনকোডিংয়ের টি-এসএনই ভিজ্যুয়ালাইজেশন এবং সংখ্যাসূচক ফলাফলের তুলনা করে, ডেটাসেটের উপর এনকোডিংয়ের প্রভাবের ফলাফল উপস্থাপনা এবং বোঝার মধ্যে পার্থক্য পরিলক্ষিত হয়।
গাড়ি বীমা ডেটাসেটের t-SNE উপস্থাপনা
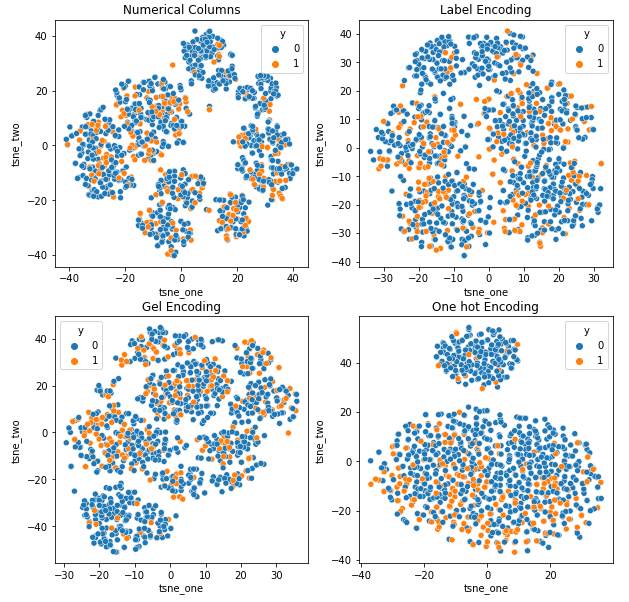
যানবাহন বীমা ডেটাসেটের t-SNE উপস্থাপনা
-
ডেটা একে অপরের কাছাকাছি কারণ সারির সংখ্যা গাড়ি বীমা ডেটাসেটের চেয়ে বেশি। ওয়ান হট এনকোডিং-এ বর্ধিত মাত্রার সাথে আলাদা করা কঠিন হয়ে পড়ে।
-
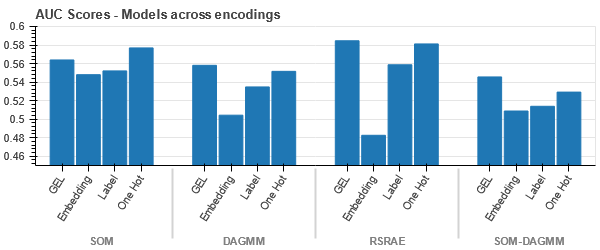
DAGMM ব্যতীত সকল ক্ষেত্রে GEL এনকোডিং ওয়ান হট এনকোডিং থেকে ভালো।
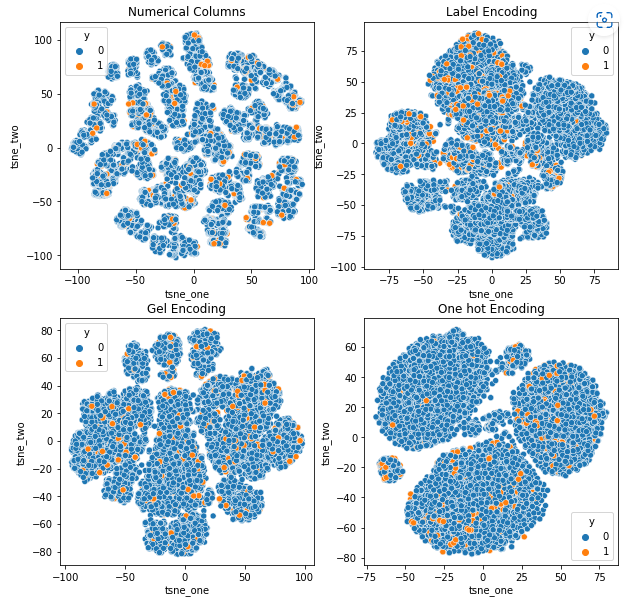
যানবাহন দাবি ডেটাসেটের t-SNE উপস্থাপনা
-
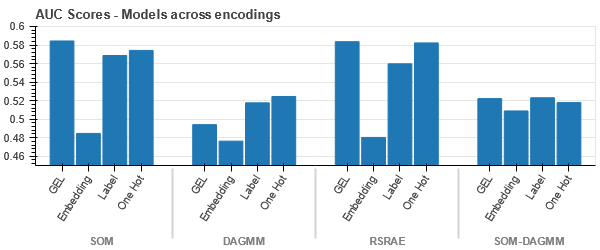
সমস্ত ক্ষেত্রে ডেটা শক্তভাবে আবদ্ধ থাকে, যা বর্ধিত মাত্রার সাথে আলাদা করা কঠিন করে তোলে। এটি বর্ধিত মাত্রার কারণে মডেলগুলির দুর্বল কর্মক্ষমতার একটি কারণ।
- SOM এই ডেটাসেটের জন্য অন্য সব মডেলকে ছাড়িয়ে যায়। তবুও, এমবেডিং স্তরটি বেশিরভাগ ক্ষেত্রেই বেশি উপযুক্ত, যা আমাদেরকে এনকোডিংয়ের বিকল্প দেয় সুনির্দিষ্ট বৈশিষ্ট্য অসঙ্গতি সনাক্তকরণের জন্য।
উপসংহার
এই নিবন্ধটি অডিটিং ডেটা, অসঙ্গতি সনাক্তকরণ এবং স্পষ্ট এনকোডিংয়ের একটি সংক্ষিপ্ত বিবরণ উপস্থাপন করে। এটা বোঝা গুরুত্বপূর্ণ যে অডিটিং ডেটাতে শ্রেণীবদ্ধ বৈশিষ্ট্যগুলি পরিচালনা করা চ্যালেঞ্জিং। মডেলগুলিতে অ্যাট্রিবিউট এনকোডিংয়ের প্রভাব বোঝার মাধ্যমে, আমরা ডেটাসেটের মধ্যে অসঙ্গতি সনাক্তকরণের সঠিকতা উন্নত করতে পারি। এই নিবন্ধ থেকে মূল টেকওয়ে হল:
- ডেটার আকার বাড়ার সাথে সাথে, GEL এনকোডিং এবং এম্বেডিং স্তরগুলির মতো শ্রেণীবদ্ধ বৈশিষ্ট্যগুলির জন্য বিকল্প এনকোডিং পদ্ধতিগুলি ব্যবহার করা গুরুত্বপূর্ণ, কারণ ওয়ান হট এনকোডিং অনুপযুক্ত।
- একটি মডেল সমস্ত ডেটাসেটের জন্য কাজ করে না। ট্যাবুলার ডেটাসেটের জন্য, ডোমেন জ্ঞান অত্যন্ত গুরুত্বপূর্ণ।
- এনকোডিং পদ্ধতির পছন্দ মডেলের পছন্দের উপর নির্ভর করে।
মডেল মূল্যায়নের জন্য কোড পাওয়া যায় GitHub.
এই নিবন্ধে দেখানো মিডিয়া Analytics বিদ্যার মালিকানাধীন নয় এবং লেখকের বিবেচনার ভিত্তিতে ব্যবহার করা হয়।
সংশ্লিষ্ট
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- সম্পর্কে
- উপরে
- অনুযায়ী
- সঠিকতা
- উপরন্তু
- ঠিকানা
- সব
- অনুমতি
- বিকল্প
- সর্বদা
- বৈশ্লেষিক ন্যায়
- বিশ্লেষণ বিদ্যা
- এবং
- অসঙ্গতি সনাক্তকরণ
- পন্থা
- প্রবন্ধ
- নির্ধারিত
- যুক্ত
- অধিকৃত
- বৈশিষ্ট্যাবলী
- নিরীক্ষণ
- স্বয়ংক্রিয়
- সহজলভ্য
- ভিত্তি
- কারণ
- হয়ে
- আগে
- হচ্ছে
- নিচে
- benchmarks
- সর্বোত্তম
- উত্তম
- মধ্যে
- বৃহত্তম
- আবদ্ধ
- তরবার
- না পারেন
- গ্রেপ্তার
- গাড়ী
- গাড়ী বীমা
- কার্ড
- কেস
- মামলা
- বিভাগ
- চ্যালেঞ্জ
- চ্যালেঞ্জ
- চ্যালেঞ্জিং
- মতভেদ
- চরিত্র
- পছন্দ
- দাবি
- দাবি
- শ্রেণী
- ক্লাস
- শ্রেণীবিন্যাস
- শ্রেণীভুক্ত করা
- পরিষ্কার
- কাছাকাছি
- কোড
- রঙ
- সাধারণভাবে
- সম্প্রদায়
- কোম্পানি
- তুলনা
- তুলনা
- প্রতিদ্বন্দ্বিতা করা
- প্রতিযোগিতামূলক
- জটিল
- ধারণা
- গোপনীয়তা
- গঠিত
- ধারণ
- একটানা
- কর্পোরেট
- মূল্য
- সৃষ্টি
- ধার
- ক্রেডিটকার্ড
- উপাত্ত
- ডেটা পয়েন্ট
- ডেটাসেট
- তারিখ
- ডিলিং
- হ্রাস
- গভীর
- গভীর জ্ঞানার্জন
- নির্ভর করে
- বিশদ
- সনাক্তকরণ
- নির্ধারণ
- পার্থক্য
- বিভিন্ন
- কঠিন
- মাত্রা
- মাত্রা
- সরাসরি
- বিচক্ষণতা
- দূরত্ব
- স্বতন্ত্র
- বিতরণ
- বিভক্ত
- ডোমেইন
- চালক
- সময়
- প্রতি
- সহজ
- পারেন
- শক্তি
- ভুল
- ত্রুটি
- হিসাব
- আনুমানিক
- অনুমান
- ইত্যাদি
- মূল্যায়ন
- মূল্যায়ন
- মূল্যায়ন
- উদাহরণ
- উদাহরণ
- ছাড়া
- ব্যয়বহুল
- অত্যন্ত
- মুখোমুখি
- কারণের
- বৈশিষ্ট্য
- বৈশিষ্ট্য
- প্রথম
- বন. জংগল
- প্রতারণা
- প্রতারণাপূর্ণ
- থেকে
- জ্বালানি
- লিঙ্গ
- গ্রুপের
- হ্যান্ডলিং
- উচ্চ
- ঊর্ধ্বতন
- গরম
- যাহোক
- HTTPS দ্বারা
- অকুলীন
- চিহ্নিতকরণের
- প্রভাব
- গুরুত্বপূর্ণ
- উন্নত করা
- in
- অন্তর্ভুক্ত করা
- অন্তর্ভুক্ত
- আয়
- বর্ধিত
- বৃদ্ধি
- ক্রমবর্ধমান
- ইঙ্গিত
- তথ্য
- তথ্য ব্যবস্থা
- ইনপুট
- বীমা
- বিচ্ছিন্নতা
- সমস্যা
- সমস্যা
- IT
- চাবি
- জানা
- জ্ঞান
- পরিচিত
- লেবেল
- লেবেল
- লেবেলগুলি
- বড়
- বৃহত্তর
- স্তর
- স্তর
- নেতৃত্ব
- শিখতে
- জ্ঞানী
- শিক্ষা
- স্থানীয়
- অবস্থিত
- খুঁজে দেখো
- ক্ষতি
- লোকসান
- কম
- মেশিন
- মেশিন লার্নিং
- মেশিন
- প্রধান
- তৈরি করে
- মেকিং
- কার্যভার
- ম্যানুয়াল
- অনেক
- মানচিত্র
- ম্যাচিং
- জরায়ু
- অর্থ
- মিডিয়া
- মধ্যম
- পদ্ধতি
- পদ্ধতি
- ছন্দোময়
- সর্বনিম্ন
- অনুপস্থিত
- প্রশমিত করা
- মিশ্রণ
- মডেল
- মডেল
- অধিক
- সেতু
- নেটওয়ার্ক
- নিউরোন
- নতুন
- নতুন বৈশিষ্ট
- সাধারণ
- সংখ্যা
- উদ্দেশ্য
- ONE
- ক্রম
- অন্যান্য
- outperforms
- পরাস্ত
- ওভারভিউ
- মালিক হয়েছেন
- পরামিতি
- অংশ
- যন্ত্রাংশ
- কর্মক্ষমতা
- সঞ্চালিত
- ব্যক্তিগত
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- বিন্দু
- পয়েন্ট
- দরিদ্র
- জনপ্রিয়
- সম্ভব
- পছন্দ করা
- বর্তমান
- উপস্থাপন
- মূল্য
- নীতি
- পূর্বে
- সম্ভাবনা
- সমস্যা
- প্রক্রিয়া
- পেশা
- প্রকল্প
- প্রকল্প তথ্য
- অভিক্ষেপ
- প্রকল্প
- বৈশিষ্ট্য
- প্রদান
- প্রদত্ত
- উপলব্ধ
- প্রকাশিত
- এলোমেলো
- পরিসর
- বাস্তব
- বাস্তব জগতে
- কারণে
- আরোগ্য
- এলাকা
- সম্পর্ক
- মেরামত
- প্রতিস্থাপিত
- প্রতিনিধিত্ব
- প্রতিনিধিত্ব করে
- প্রয়োজন
- ফল
- ফলে এবং
- ফলাফল
- শক্তসমর্থ
- একই
- বিজ্ঞান
- সংবেদনশীল
- আলাদা
- প্রদর্শিত
- সিগমা
- অনুরূপ
- থেকে
- একক
- আয়তন
- ছোট
- ক্ষুদ্রতর
- So
- স্থান
- নির্দিষ্ট
- শুরু
- এখনো
- এমন
- ভুগছেন
- উপযুক্ত
- সমর্থন
- পৃষ্ঠতল
- কৃত্রিম
- সিস্টেম
- টেবিল
- takeaways
- শর্তাবলী
- সার্জারির
- বিশ্ব
- অতএব
- গোবরাট
- আঁটসাঁটভাবে
- সময় অপগিত হয় এমন
- থেকে
- মোট
- রেলগাড়ি
- প্রশিক্ষণ
- বোঝা
- বোধশক্তি
- অনন্য
- একক
- অকার্যকর শেখা
- আপডেট
- us
- ব্যবহার
- মূল্য
- মানগুলি
- বাহন
- যানবাহন
- ওজন
- কি
- যে
- যখন
- ইচ্ছা
- শব্দ
- শব্দ
- হয়া যাই ?
- বিশ্ব
- would
- বছর
- zephyrnet