আমি এই বছর পান্তা কানায় যেতে পারিনি  তবে আমি খুশি (দূর থেকে) যারা সমস্ত ভ্রমণ নিষেধাজ্ঞা থাকা সত্ত্বেও সেখানে যেতে পেরেছে! ভিতরে প্রিমিয়াম সামগ্রী।
তবে আমি খুশি (দূর থেকে) যারা সমস্ত ভ্রমণ নিষেধাজ্ঞা থাকা সত্ত্বেও সেখানে যেতে পেরেছে! ভিতরে প্রিমিয়াম সামগ্রী।
শরৎ খুব ব্যস্ত হয়ে গেছে এবং আমি একটি সংক্ষিপ্ত বিন্যাস চেষ্টা করতে চাই: প্রতিটি বড় বিষয়ের একটি "স্পটলাইট" আছে  প্রধান ব্লকে কাজ করুন যা আমি বিশেষভাবে আকর্ষণীয় বলে মনে করি, এবং বেশ কিছু প্রাসঙ্গিক কাজ যার বিবরণ একটু ছোট।
প্রধান ব্লকে কাজ করুন যা আমি বিশেষভাবে আকর্ষণীয় বলে মনে করি, এবং বেশ কিছু প্রাসঙ্গিক কাজ যার বিবরণ একটু ছোট।
আজকের জন্য পরিকল্পনা:
- কেজি-বর্ধিত ভাষা মডেল: শ্রেণীকরণ
- কথোপকথনমূলক এআই: হ্যালুসিনেটিং বন্ধ করুন, ভাই
- এন্টিটি লিঙ্কিং: ইন দ্য শ্যাডো অফ ক্লোসাল (সত্তা)
- কেজি কনস্ট্রাকশন
- কেজি প্রশ্নের উত্তর: কিছু যোগ করুন
 SPARQL
SPARQL
যদি এই গভীর-শিক্ষামূলক সামগ্রী আপনার জন্য দরকারী, আমাদের এআই গবেষণা মেলিং তালিকার সাবস্ক্রাইব করুন সতর্কতা অবলম্বন করার জন্য যখন আমরা নতুন উপাদান প্রকাশ করি।
কেজি-বর্ধিত ভাষা মডেল: শ্রেণীকরণ
প্রাসঙ্গিক ভাষার মডেলে রিলেশনাল ওয়ার্ল্ড নলেজ রিপ্রেজেন্টেশন: একটি রিভিউ তারা সাফাভি এবং দানাই কাউত্রার দ্বারা
আপনি যদি এই ধরনের ডাইজেস্টের (বা পূর্ববর্তী পোস্ট) একজন অভিজ্ঞ পাঠক হন তাহলে আপনি ভালোভাবে জানেন যে কেজি-অগমেন্টেড LM-এর প্রাচুর্য প্রতি কনফারেন্সে প্রকাশিত হয় এবং সাপ্তাহিক arxiv-এ আপলোড করা হয়। হারিয়ে গেলে মনে হয়  - আমি নিশ্চিত করতে পারি যে আপনি একা নন।
- আমি নিশ্চিত করতে পারি যে আপনি একা নন।
এই বছর, আমরা অবশেষে একটি আছে শব্দ কাঠামো এবং বিভিন্ন কেজি+এলএম পদ্ধতির শ্রেণীবিন্যাস! লেখকরা 3টি বড় পরিবারকে সংজ্ঞায়িত করেছেন: 1⃣ কোন কেজি তত্ত্বাবধান নেই, ক্লোজ-স্টাইল প্রম্পট সহ এলএম প্যারামে এনকোড করা জ্ঞান পরীক্ষা করা; 2⃣ সত্তা এবং আইডি সহ কেজি তত্ত্বাবধান; 3⃣ সম্পর্ক টেমপ্লেট এবং পৃষ্ঠ ফর্ম সঙ্গে কেজি তত্ত্বাবধান।
প্রতিটি পরিবারের কয়েকটি শাখা রয়েছে  উদাহরণস্বরূপ, আসুন নীচের চিত্রিত 4টি সত্তা-সচেতন মডেলের দিকে নজর দেওয়া যাক। থেকে ভিন্ন "কম প্রতীকী" থেকে "আরো প্রতীকী", কিছু LM উল্লেখ-স্প্যান মাস্কিং, বা বিপরীত শিক্ষা, বা পরিচিত শব্দভান্ডার থেকে সত্তা এমবেডিংয়ের ফিউশন সঞ্চালন করে। লেখকরা ফ্রেমওয়ার্ক অনুসারে কয়েক ডজন বিদ্যমান আর্কিটেকচারকে শ্রেণীবদ্ধ করে একটি দুর্দান্ত কাজ করেছেন এবং এটি এখন অনেক ভাল সংগঠিত দেখাচ্ছে। অনেক কাজের প্রয়োজন!
উদাহরণস্বরূপ, আসুন নীচের চিত্রিত 4টি সত্তা-সচেতন মডেলের দিকে নজর দেওয়া যাক। থেকে ভিন্ন "কম প্রতীকী" থেকে "আরো প্রতীকী", কিছু LM উল্লেখ-স্প্যান মাস্কিং, বা বিপরীত শিক্ষা, বা পরিচিত শব্দভান্ডার থেকে সত্তা এমবেডিংয়ের ফিউশন সঞ্চালন করে। লেখকরা ফ্রেমওয়ার্ক অনুসারে কয়েক ডজন বিদ্যমান আর্কিটেকচারকে শ্রেণীবদ্ধ করে একটি দুর্দান্ত কাজ করেছেন এবং এটি এখন অনেক ভাল সংগঠিত দেখাচ্ছে। অনেক কাজের প্রয়োজন! 

কয়েকটি সংক্ষিপ্ত কাগজ বায়োমেডিকেল কেজি দিয়ে LM-কে সমৃদ্ধ করার উপর ফোকাস করে, LM-কে একটি ডোমেন-নির্দিষ্ট বায়োমেডিকেল শেখানোর দীর্ঘস্থায়ী প্রচেষ্টা। অপবাদ মেং এট আল উত্থাপন করা পার্টিশনের মিশ্রণ (MoP), একটি এলএম এর উপর ভিত্তি করে অ্যাডাপ্টার ফিউশন কৌশল যা স্ক্র্যাচ থেকে LM-কে প্রাক-প্রশিক্ষণ দেওয়ার প্রয়োজনীয়তা হ্রাস করে। MoP কে সাধারণ বায়োমেডিকাল শব্দভান্ডার এবং অনটোলজি UMLS এবং SNOMED CT দিয়ে প্রশিক্ষিত করা হয়েছিল। সুং এট আল জিজ্ঞাসা করা "ভাষার মডেলগুলি কি বায়োমেডিকাল জ্ঞানের ভিত্তি হতে পারে?" উল্লেখ করে পেট্রোনি এট আল দ্বারা বিখ্যাত EMNLP'19 কাগজ. উত্তর অনেকাংশে কোন. লেখক নকশা বায়োলামা, UMLS, CTD, এবং Wikidata থেকে তৈরি বায়োমেডিকাল জ্ঞান অনুসন্ধানের জন্য একটি মানদণ্ড। তারা দেখতে পায় যে আধুনিক এলএমগুলি সেই প্রোবের উপর <10% নির্ভুলতা পায়, তাই সম্প্রদায়ের অবশ্যই আরও নির্ভরযোগ্য কিছু দরকার
মেং এট আল উত্থাপন করা পার্টিশনের মিশ্রণ (MoP), একটি এলএম এর উপর ভিত্তি করে অ্যাডাপ্টার ফিউশন কৌশল যা স্ক্র্যাচ থেকে LM-কে প্রাক-প্রশিক্ষণ দেওয়ার প্রয়োজনীয়তা হ্রাস করে। MoP কে সাধারণ বায়োমেডিকাল শব্দভান্ডার এবং অনটোলজি UMLS এবং SNOMED CT দিয়ে প্রশিক্ষিত করা হয়েছিল। সুং এট আল জিজ্ঞাসা করা "ভাষার মডেলগুলি কি বায়োমেডিকাল জ্ঞানের ভিত্তি হতে পারে?" উল্লেখ করে পেট্রোনি এট আল দ্বারা বিখ্যাত EMNLP'19 কাগজ. উত্তর অনেকাংশে কোন. লেখক নকশা বায়োলামা, UMLS, CTD, এবং Wikidata থেকে তৈরি বায়োমেডিকাল জ্ঞান অনুসন্ধানের জন্য একটি মানদণ্ড। তারা দেখতে পায় যে আধুনিক এলএমগুলি সেই প্রোবের উপর <10% নির্ভুলতা পায়, তাই সম্প্রদায়ের অবশ্যই আরও নির্ভরযোগ্য কিছু দরকার  .
.
কথোপকথনমূলক এআই: হ্যালুসিনেটিং বন্ধ করুন, ভাই
নিউরাল পাথ হান্টার: পাথ গ্রাউন্ডিংয়ের মাধ্যমে ডায়ালগ সিস্টেমে হ্যালুসিনেশন হ্রাস করা নৌহা ডিজিরি, আন্দ্রেয়া ম্যাডোটো, ওসমার জায়ানে, অভিষেক জোয়ে বোস দ্বারা
কেজি ব্যাকগ্রাউন্ড সহ একটি কনভাই সিস্টেমের সাথে প্রতিক্রিয়া তৈরি করা কঠিন। অনেক উপাদান সহ পাইপলাইন সিস্টেমে, আপনি কঠোরভাবে পৃষ্ঠের ফর্মগুলি (সত্তার নাম) ব্যবহার করেন এবং আপনি বেশিরভাগ টেমপ্লেটগুলি অবলম্বন করেন এবং টেমপ্লেট বিরক্তিকর এবং খুব কমই রক্ষণাবেক্ষণযোগ্য। অন্যদিকে, GPT-2 এবং GPT-2 এর মতো e3e জেনারেটিভ মডেলগুলি অনেক বেশি অনন্য উত্তর তৈরি করে কিন্তু প্রায়শই হ্যালুসিনেট করে, অর্থাৎ, আপনি যখন এটি আশা করেন না তখন ভুল সত্তার নাম সন্নিবেশ করান৷
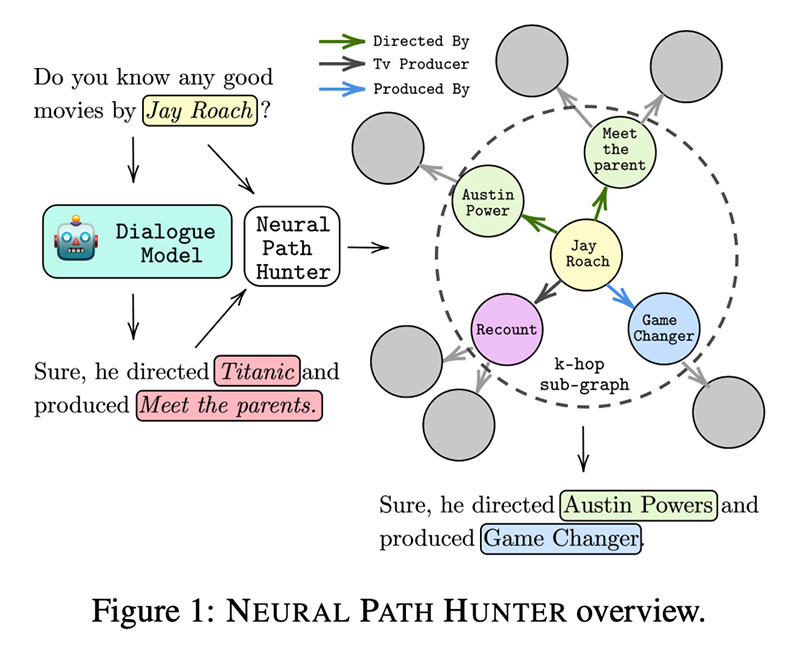
এই কাজের লেখক একটি শুরু খোজা  কেজি তত্ত্বাবধানের প্রস্তাব দিয়ে হ্যালুসিনেশন কমাতে নিউরাল পাথ হান্টার. প্রথমত, তারা বেশ কয়েকটি অধ্যয়ন করে ধরনের হ্যালুকেশন , তারা কোথা থেকে এসেছে (বেশিরভাগই টপ-কে স্যাম্পলিং থেকে), এবং কীভাবে এটি পরিমাপ করা যায়।
কেজি তত্ত্বাবধানের প্রস্তাব দিয়ে হ্যালুসিনেশন কমাতে নিউরাল পাথ হান্টার. প্রথমত, তারা বেশ কয়েকটি অধ্যয়ন করে ধরনের হ্যালুকেশন , তারা কোথা থেকে এসেছে (বেশিরভাগই টপ-কে স্যাম্পলিং থেকে), এবং কীভাবে এটি পরিমাপ করা যায়।
এনপিএইচ নিজেই দুটি মডিউল নিয়ে গঠিত: 1⃣ একজন সমালোচক (নন-অটোরিগ্রেসিভ এলএম) যে টোকেনগুলির উপর বাইনারি শ্রেণীবিভাগ সম্পাদন করে; 2⃣ সত্তা ত্রুটিগুলি ঠিক করার জন্য সত্তা পুনরুদ্ধারকারী: এটি মূলত একটি সত্তা মেমরি যেখানে সত্তা এম্বেডিংগুলি GPT থেকে আসে এবং গ্রাফ কাঠামো ব্যবহার করে CompGCN এর সাথে আপডেট করা হয়৷ সবচেয়ে প্রশংসনীয় প্রার্থীরা ডিস্টমল্ট স্কোরিং ফাংশন প্রয়োগ করে আসে। ভয়লা !
এনপিএইচকে যে কোনো প্রাক-প্রশিক্ষিত এলএম-এর সাথে যুক্ত করা যেতে পারে, পরীক্ষা-নিরীক্ষা OpenDialKG GPT2-KG সহ বেঞ্চমার্ক, GPT2-KE, এবং অ্যাডাপ্টারবট উল্লেখযোগ্য হ্রাস প্রদর্শন  হ্যালুসিনেশন এবং বৃদ্ধি
হ্যালুসিনেশন এবং বৃদ্ধি  বিশ্বস্ততায় একটি ব্যবহারকারী সমীক্ষা রিপোর্ট করেছে যে মানব-মাপা হ্যালুসিনেশন NPH মডেলগুলিতে ~2x হ্রাস পেয়েছে
বিশ্বস্ততায় একটি ব্যবহারকারী সমীক্ষা রিপোর্ট করেছে যে মানব-মাপা হ্যালুসিনেশন NPH মডেলগুলিতে ~2x হ্রাস পেয়েছে
এই প্রসঙ্গে আরেকটি প্রাসঙ্গিক কাজ: হোনোভিচ এট আল ডায়ালগ সিস্টেমে একই সমস্যা অধ্যয়ন করুন কিন্তু কেজি ব্যাকগ্রাউন্ডে এবং একটি নতুন বেঞ্চমার্ক প্রস্তাব করুন Q² প্রশ্ন জেনারেশন এবং প্রশ্নের উত্তর দেওয়ার ঘটনাগত সামঞ্জস্য পরিমাপ করতে (যদি আপনি জিজ্ঞাসা করেন উভয়ই Q থেকে এসেছে)।
আপনি যদি কনভাই এবং কমনসেন্স কেজিতে থাকেন - তাহলে নিশ্চিত হন যে ক্লু (কনভারসেশনাল মাল্টি-হপ রিজনার) আরবশাহী, লি, ইত্যাদিযে ধারণা অন্তর্ভুক্ত যদি-(রাষ্ট্র), তারপর-(কর্ম), কারণ-(লক্ষ্য) নিদর্শন লজিক্যাল নিয়ম এবং প্রতীকী যুক্তি.
সত্তা লিঙ্কিং: কলোসাসের ছায়ায়
পূর্বের অনুসন্ধানগুলি ব্যবহার করে সত্তা দ্ব্যর্থতা নিরসনের দৃঢ়তা মূল্যায়ন: সত্তা ওভারশ্যাডোয়িং কেস by ভেরা প্রোভাতোরোভা, স্বিতলানা ভাকুলেঙ্কো, সমর্থ ভার্গব, ইভানজেলোস কানোলাস
আপনি যখন ভাষার কাজের জন্য বাস্তব-বিশ্বের কেজি প্লাগ ইন করেন তখন আপনি অনিবার্যভাবে সম্মুখীন হবেন বিভিন্ন সত্ত্বা যে ঠিক আছে একই নাম  . দুর্ভাগ্যবশত, মানবতা বিশ্বের সমস্ত সত্তার জন্য অনন্য হ্যাশ ব্যবহার করে না, তাই সত্তা দ্ব্যর্থতা নিরসন সত্তা লিঙ্কিংয়ের একটি গুরুত্বপূর্ণ পদক্ষেপ হিসেবে রয়ে গেছে।
. দুর্ভাগ্যবশত, মানবতা বিশ্বের সমস্ত সত্তার জন্য অনন্য হ্যাশ ব্যবহার করে না, তাই সত্তা দ্ব্যর্থতা নিরসন সত্তা লিঙ্কিংয়ের একটি গুরুত্বপূর্ণ পদক্ষেপ হিসেবে রয়ে গেছে।

উদাহরণস্বরূপ, উইকিডাটা আছে "মাইকেল জর্ডান" নামে অন্তত 18টি সত্তা. প্রায়শই, EL সিস্টেমগুলি মৌলিক পরিসংখ্যান এবং জনপ্রিয়তার স্কোরের উপর নির্ভর করে, যেমন সবচেয়ে জনপ্রিয় "মাইকেল জর্ডান দ্য বাস্কেটবল খেলোয়াড়" কম বিশিষ্ট (পপ সংস্কৃতিতে, অন্তত) লোকদের ছাপিয়ে যাবে।
 লেখকরা এই সমস্যাটি মোকাবেলা করেন এবং একটি নতুন ডেটাসেট প্রবর্তন করেন, শ্যাডোলিংক, আধুনিক EL সিস্টেমের বিভ্রান্তির মাত্রা পরিমাপ করতে। দেখা যাচ্ছে সর্বোচ্চ F1 স্কোর সবেমাত্র 0.35 এ পৌঁছেছে (সাম্প্রতিক উৎপন্ন জেনার সবচেয়ে কঠিন অংশে 0.26) ফলন। সমস্ত সিস্টেম লং-টেইল বিরল সত্ত্বাগুলিতে তাদের স্কোর পরিপূর্ণ করে এবং আরও সাধারণ সত্ত্বাগুলির সাথেও মানিয়ে নেয়। প্রধান চ্যালেঞ্জ হিসাবে প্রণয়ন করা হয় "যা কাজটিকে চ্যালেঞ্জিং করে তোলে তা হল অস্পষ্টতা এবং অস্বাভাবিকতার সমন্বয়” আমি লেখকদের ডেটাসেট আপলোড করার সুপারিশ করব HuggingFace ডেটাসেট তাদের দুর্দান্ত প্রকল্পের দৃশ্যমানতা বাড়াতে
লেখকরা এই সমস্যাটি মোকাবেলা করেন এবং একটি নতুন ডেটাসেট প্রবর্তন করেন, শ্যাডোলিংক, আধুনিক EL সিস্টেমের বিভ্রান্তির মাত্রা পরিমাপ করতে। দেখা যাচ্ছে সর্বোচ্চ F1 স্কোর সবেমাত্র 0.35 এ পৌঁছেছে (সাম্প্রতিক উৎপন্ন জেনার সবচেয়ে কঠিন অংশে 0.26) ফলন। সমস্ত সিস্টেম লং-টেইল বিরল সত্ত্বাগুলিতে তাদের স্কোর পরিপূর্ণ করে এবং আরও সাধারণ সত্ত্বাগুলির সাথেও মানিয়ে নেয়। প্রধান চ্যালেঞ্জ হিসাবে প্রণয়ন করা হয় "যা কাজটিকে চ্যালেঞ্জিং করে তোলে তা হল অস্পষ্টতা এবং অস্বাভাবিকতার সমন্বয়” আমি লেখকদের ডেটাসেট আপলোড করার সুপারিশ করব HuggingFace ডেটাসেট তাদের দুর্দান্ত প্রকল্পের দৃশ্যমানতা বাড়াতে  .
.
অরোরা ইত্যাদি অন্য দিক থেকে সত্তা লিঙ্কিং সমস্যায় যান। মূল ভাবনাটা হল সত্য নামে সত্ত্বা একটি নথিতে (যৌথভাবে প্রক্রিয়া করা হয়, একে একে নয়) বিঘত একটি নিম্ন পদ subspace  প্রার্থী সহ সমস্ত সত্তার স্থানের মধ্যে (নীচে একটি চাক্ষুষ উদাহরণ দেখুন)। দ্য ইঞ্জেনথিম আপনার যদি প্রাক-প্রশিক্ষিত সত্তা এমবেডিং থাকে তবে পদ্ধতিটি তত্ত্বাবধান করা হয় না — লেখকরা উইকিডাটার ইংরেজি উপসেটের উপর ডিপওয়াক ব্যবহার করেন (বিকল্পভাবে, তারা শব্দ এমবেডিং চেষ্টা করে, কিন্তু এটি ভালভাবে কাজ করে না)।
প্রার্থী সহ সমস্ত সত্তার স্থানের মধ্যে (নীচে একটি চাক্ষুষ উদাহরণ দেখুন)। দ্য ইঞ্জেনথিম আপনার যদি প্রাক-প্রশিক্ষিত সত্তা এমবেডিং থাকে তবে পদ্ধতিটি তত্ত্বাবধান করা হয় না — লেখকরা উইকিডাটার ইংরেজি উপসেটের উপর ডিপওয়াক ব্যবহার করেন (বিকল্পভাবে, তারা শব্দ এমবেডিং চেষ্টা করে, কিন্তু এটি ভালভাবে কাজ করে না)।

একটি ধারণাগত অনুরূপ সত্তা-ভিত্তিক দ্বন্দ্বের সমস্যা দ্বারা অধ্যয়ন করা হয় লংপ্রে এট আল, যথা, জ্ঞান প্রতিস্থাপন — আপনি যদি একটি অনুচ্ছেদে একটি সত্য সত্তাকে র্যান্ডম (বা বিপরীতে) ফ্লিপ করেন, তাহলে মডেলটি কি উত্তর পরিবর্তন করবে? অন্য কথায়, QA মডেলগুলি কি প্রসঙ্গ বা মুখস্ত জ্ঞান পড়ার উপর নির্ভর করবে? দেখা যাচ্ছে, এই ধরনের প্রতিস্থাপনের সাথে QA মডেলগুলিকে প্রশিক্ষণ দেওয়ার সময়, আপনি একটি ভাল ব্যবধানে OOD সাধারণীকরণ বাড়াতে পারেন!
অবশেষে, এর জরিপটি দেখুন Tedeschi et al on "এনইআর ফর এন্টিটি লিঙ্কিং: কি কাজ করে এবং পরবর্তী কি". লেখকরা EL-এর মূল চ্যালেঞ্জগুলি চিহ্নিত করেছেন এবং এনইআর-প্রসঙ্গিকগুলিকে সমাধান করার চেষ্টা করেছেন NER4EL বৃহৎ প্রাক-প্রশিক্ষিত এলএম এবং ছোট মডেলের মধ্যে কর্মক্ষমতার ব্যবধান কমানোর লক্ষ্য যা বিশেষত স্বল্প-সম্পদ পরিস্থিতিতে প্রাসঙ্গিক .

কেজি কনস্ট্রাকশন
আমি এখানে একটি আকর্ষণীয় লাইন নিয়ে আসতে পারিনি :/ আপনি যদি OpenIE এবং KG কনস্ট্রাকশনে থাকেন তবে নিম্নলিখিত কাগজপত্রগুলি প্রাসঙ্গিক হতে পারে।
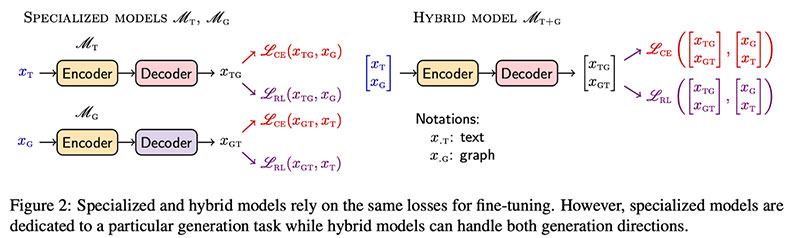
ডগনিন এট আল উত্থাপন করা রিজেন, Text2Graph এবং Graph2Text উভয় কাজ (বা ফাইন-টিউন বিশেষ মডেল) সম্পাদনের জন্য LM-এর ফাইন-টিউনিংয়ের একটি পদ্ধতি। মূল উপাদান  স্ট্যান্ডার্ড ক্রস-এনট্রপি (সিই) ছাড়াও একটি আরএল লস (সেলফ-ক্রিটিকাল সিকোয়েন্স ট্রেনিং) যোগ করছে। এটি সহজেই যেকোনো প্রাক-প্রশিক্ষিত এলএম-এ যোগ করা যেতে পারে — লেখকরা এটি T5-লার্জ (770M প্যারাম) এবং T5-বেস (220M প্যারাম) দিয়ে চেষ্টা করেন।
স্ট্যান্ডার্ড ক্রস-এনট্রপি (সিই) ছাড়াও একটি আরএল লস (সেলফ-ক্রিটিকাল সিকোয়েন্স ট্রেনিং) যোগ করছে। এটি সহজেই যেকোনো প্রাক-প্রশিক্ষিত এলএম-এ যোগ করা যেতে পারে — লেখকরা এটি T5-লার্জ (770M প্যারাম) এবং T5-বেস (220M প্যারাম) দিয়ে চেষ্টা করেন।  পরীক্ষামূলকভাবে, রিজেন Text2Graph WebNLG বেসলাইন (মেট্রিকের উপর নির্ভর করে 3-10 abs. পয়েন্ট) উল্লেখযোগ্যভাবে উন্নতি করে এবং কাজ করে অনেক বৃহত্তর টেকজেন ডেটাসেট (6M প্রশিক্ষণ জোড়া)।
পরীক্ষামূলকভাবে, রিজেন Text2Graph WebNLG বেসলাইন (মেট্রিকের উপর নির্ভর করে 3-10 abs. পয়েন্ট) উল্লেখযোগ্যভাবে উন্নতি করে এবং কাজ করে অনেক বৃহত্তর টেকজেন ডেটাসেট (6M প্রশিক্ষণ জোড়া)।
ড্যাশ এট আল অধ্যয়ন ক্যানোনিকালাইজেশন OpenIE-তে সমস্যা — যখন বিভিন্ন সারফেস ফর্ম সহ সত্তা যেমন (NYC, নিউ ইয়র্ক সিটি) একই প্রোটোটাইপ পড়ুন। একটি তত্ত্বাবধানহীন পদ্ধতিতে, আমরা চাই যে IE সিস্টেমগুলি স্বয়ংক্রিয়ভাবে সেই উল্লেখগুলিকে একসাথে ক্লাস্টার করুক। পদ্ধতি, ড্রাম, ক্লাস্টারগুলি সনাক্ত করতে ভেরিয়েশনাল অটোএনকোডার (VAEs) অবলম্বন করে (সত্তা এবং সম্পর্ক গাউসিয়ানদের দ্বারা প্যারামিটারাইজ করা হয়)। VAEs জন্য মান ছাড়াও পুনর্গঠন ক্ষতি, CUVA অতিরিক্ত নিয়োগ করে লিঙ্ক পূর্বাভাস ক্ষতি হোল স্কোরিং ফাংশনের উপর ভিত্তি করে।  তাছাড়া লেখক একটি উপন্যাসের পরিচয় দেন CanonicNELL ডেটাসেট!
তাছাড়া লেখক একটি উপন্যাসের পরিচয় দেন CanonicNELL ডেটাসেট!

কেজি প্রশ্নের উত্তর: কিছু যোগ করুন SPARQL
ইন্টারমিডিয়েট প্রশ্ন পচন থেকে SPARQLing ডেটাবেস কোয়েরি by ইরিনা সাপারিনা এবং অ্যান্টন ওসোকিন
দুর্ভাগ্যবশত *সিএল ডোমেনে SPARQL-এর এত বেশি অ্যাপ্লিকেশন নেই। আমি মনে করি এটি এনএলপিতে আরও ব্যাপক গ্রহণের দাবি রাখে। যখন এটি একটি দুর্দান্ত অ্যাপ্লিকেশন দ্বারা সমর্থিত হয় - আমি প্রবেশ করি৷  .
.
স্ট্রাকচার্ড QA ডেটাসেটের সংখ্যাগরিষ্ঠ বা মূল আউটপুট ফর্ম্যাট হিসাবে শব্দার্থিক পার্সিং টার্গেট SQL নিযুক্ত করে। SQL পাইপলাইনের বাইরে কি জীবন আছে?
সাপারিনা এবং ওসোকিন প্রথমে a ব্যবহার করে 1⃣ দ্বারা সেই সমস্যার উপর একটি নতুন চেহারা প্রস্তাব করুন প্রশ্ন পচন অর্থ প্রতিনিধিত্ব (QDMR) ফ্রেমওয়ার্ক যা একটি প্রশ্নকে সিনট্যাক্স-স্বাধীন লজিক্যাল ফর্মে অনুবাদ করে; 2⃣ এই ফর্মটি যেকোন স্ট্রাকচার্ড ফরম্যাটে অনুবাদ করা যেতে পারে, এবং এখানে লেখকরা SPARQL-এর আশ্রয় নেন যা দেখায় যে গ্রাফ ফর্ম্যাটে ডেটাবেস অনুসন্ধান করা অনেক সহজ। এটির জন্য একটি ইনপুট টেবিলকে RDF তে রূপান্তর করতে হবে, কিন্তু এর ডেটাসেটের জন্য মাকড়সা স্কেল এটা খুব সহজে করা যেতে পারে.
প্রশিক্ষণযোগ্য মডিউল অন্তর্ভুক্ত RAT ট্রান্সফরমার LSTM ডিকোডার সহ এনকোডার যা QDMR টোকেন তৈরি করে। QDMR -> SPARQL হল কয়েকটি নিয়মের উপর ভিত্তি করে একটি সোজা ট্রান্সপিলেশন। অন-পার-টু-সোটা ফলাফল; কোড উপলব্ধ ; SPARQL SQL এর চেয়ে ভালো কাজ করে;
অন-পার-টু-সোটা ফলাফল; কোড উপলব্ধ ; SPARQL SQL এর চেয়ে ভালো কাজ করে;
একটি ভাল কাগজের জন্য আপনার আর কি দরকার?

আরেকটি উত্তেজনাপূর্ণ কাজ "জ্ঞানের ভিত্তির উপর প্রাকৃতিক ভাষা প্রশ্নের ক্ষেত্রে-ভিত্তিক যুক্তি" দাস এট আল দ্বারা SPARQL এর সাথে একত্রিত করে কেস-ভিত্তিক যুক্তি (সিবিআর)। 80-এর দশকে CBR-এর বিশেষজ্ঞ সিস্টেমে গভীর শিকড় রয়েছে কিন্তু সম্প্রতি উপস্থাপনা শেখার শক্তি দিয়ে পুনরুজ্জীবিত করা হয়েছে। 2021 সালে CBR-এর TLDR ব্যাখ্যা: এটি ধারণাগতভাবে কম্পোজিশনাল সাধারণীকরণের কাছাকাছি, অর্থাৎ, কিছু মৌলিক উদাহরণ দেখে আপনি পূর্বে অদেখা সত্তা সম্পর্কে আরও জটিল প্রশ্ন তৈরি করতে পারেন।
নিচের উদাহরণটি দেখুন। আমরা একটি ইনপুট প্রশ্ন আছে "হবিটে গিমলির বাবার ভাই কে?". প্রশিক্ষণের ডেটাতে আমাদের কাছে জিমলি বা হবিট সম্পর্কে কিছু নাও থাকতে পারে, তবে আমাদের "অপেক্ষামূলকভাবে একই" থাকতে পারে মামলা সম্পর্কের ক্ষেত্রে আমরা আমাদের প্রশ্নের জন্য দরকারী খুঁজে পেতে পারি, যেমন, "চার্লি শিনের বাবা কে?" ফ্রিবেস সম্পর্কের সাথে people.person_parents এবং "রিহানার ভাই কে?" সম্পর্কের সাথে people.person.sibling_s . আমাদের প্রশ্নের জন্য সেগুলি রচনা করে, আমরা ডাটাবেসে একটি SPARQL ক্যোয়ারী তৈরি করি।
প্রস্তাবিত সিবিআর-কেবিকিউএ পন্থা 1⃣ ডিপিআর-শৈলীতে একটি প্রশিক্ষিত স্নায়ু পুনরুদ্ধারকে একত্রিত করে (তত্ত্বাবধান ওভারল্যাপিং সম্পর্কের উপর ভিত্তি করে), 2⃣ একটি লিনিয়ার ট্রান্সফরমার (তারা বিগবার্ড ব্যবহার করে) সংযুক্ত প্রাসঙ্গিক প্রশ্ন এবং প্রশ্নগুলি বেশ দীর্ঘ, 3⃣ বেশ কয়েকটি পুনরায় র্যাঙ্কিং প্রক্রিয়া পরিষ্কার করার জন্য ভবিষ্যদ্বাণী তারা অফ-দ্য-শেল্ফ এনইআর এবং এন্টিটি লিঙ্কিং মডিউল ব্যবহার করে এবং পুনরায় র্যাঙ্কিংয়ের জন্য প্রাক-প্রশিক্ষিত ট্রান্সই সম্পর্ক এমবেডিং নিযুক্ত করে। CBR-KBQA সহ বেশ কয়েকটি KBQA ডেটাসেটে চিত্তাকর্ষক কর্মক্ষমতা প্রদর্শন করে সিএফকিউ. একটি ছোট নোট: আমি কিছুটা সন্দেহজনক যে সেরা উপলব্ধ SOTA মডেল (67.3 MCD-Mean) 78.1-এ এইরকম একটি মার্জিন দ্বারা ছাড়িয়ে গেছে এবং বেঞ্চমার্কে জমা দেওয়া হয়নি, কোডটি এখনও উপলব্ধ নয়।

শি এট আল মাল্টি-হপ QA অধ্যয়ন করুন এবং তাদের বার্তা প্রচার কাঠামোর মধ্যে উভয় সত্তা/সম্পর্ক আইডি (লেবেল ফর্ম) এবং তাদের প্রাকৃতিক ভাষা বর্ণনা (টেক্সট ফর্ম) একীভূত করার প্রস্তাব করুন ট্রান্সফারনেট. মান MetaQA, WebQuestionsSP, এবং জটিল ওয়েব প্রশ্ন ডেটাসেটে মূল্যায়ন করা হয়।
একই টাস্কে (আগের কাজের মতো একই ডেটাসেট), ওলিয়া প্রমুখ লক্ষ্য করা গেছে যে বেশিরভাগ SOTA QA মডেলের জন্য ইতিমধ্যেই KG সত্তার সাথে লিঙ্ক করা পাঠ্য স্প্যান প্রয়োজন এবং KG সত্তার নোড পাড়ার বৈশিষ্ট্য এবং পাঠ্য স্প্যানগুলির বৈশিষ্ট্যগুলি ব্যবহার করে গতিশীল সত্তা পুনরায় র্যাঙ্কিংয়ের মাধ্যমে এই প্রয়োজনীয়তাটি কাটিয়ে উঠতে চেষ্টা করে।
এটা সব লোক
আপনি যদি এই ছোট "প্রিমাম" পছন্দ করেন তবে আমাকে জানান  আগের রিভিউর মতো টেক্সটের দেয়ালের চেয়ে ফরম্যাট ভালো! এখানে আপনার সময় বিনিয়োগ করার জন্য ধন্যবাদ, আশা করি আপনি বাড়িতে দরকারী কিছু নিয়ে গেছেন
আগের রিভিউর মতো টেক্সটের দেয়ালের চেয়ে ফরম্যাট ভালো! এখানে আপনার সময় বিনিয়োগ করার জন্য ধন্যবাদ, আশা করি আপনি বাড়িতে দরকারী কিছু নিয়ে গেছেন

এই নিবন্ধটি মূলত উপর প্রকাশ করা হয়েছিল মধ্যম এবং লেখকের অনুমতি নিয়ে TOPBOTS এ আবার প্রকাশিত।
এই নিবন্ধটি উপভোগ করবেন? আরও এআই আপডেটের জন্য সাইন আপ করুন।
আমরা আরও প্রযুক্তিগত শিক্ষা ছেড়ে দিলে আমরা আপনাকে জানাব।
পোস্টটি EMNLP 2021-এ নলেজ গ্রাফ প্রথম দেখা শীর্ষস্থানীয়.
- '
- "
- 10
- 11
- 2021
- 67
- 7
- 9
- a
- সম্পর্কে
- প্রাচুর্য
- অনুযায়ী
- কর্ম
- যোগ
- যোগ
- ঠিকানা
- প্রশাসন
- গ্রহণ
- AI
- আইআই গবেষণা
- লক্ষ্য
- সব
- ইতিমধ্যে
- অস্পষ্টতা
- বৈশ্লেষিক ন্যায়
- অন্য
- উত্তর
- আবেদন
- অ্যাপ্লিকেশন
- ফলিত
- প্রয়োগ করা হচ্ছে
- অভিগমন
- প্রবন্ধ
- লেখক
- স্বয়ংক্রিয়ভাবে
- সহজলভ্য
- পটভূমি
- বাস্কেটবল
- নিচে
- উচ্চতার চিহ্ন
- সর্বোত্তম
- মধ্যে
- তার পরেও
- বৃহত্তম
- বিট
- বাধা
- ব্যবসায়
- কল
- প্রার্থী
- কেস
- মামলা
- চ্যালেঞ্জ
- চ্যালেঞ্জ
- চ্যালেঞ্জিং
- পরিবর্তন
- শহর
- শ্রেণীবিন্যাস
- কোড
- সমাহার
- আসা
- সাধারণ
- সম্প্রদায়
- জটিল
- উপাদান
- সম্মেলন
- বিশৃঙ্খলা
- নির্মাণ
- বিষয়বস্তু
- পারা
- সংস্কৃতি
- ক্রেতা
- গ্রাহক সমর্থন
- উপাত্ত
- ডেটাবেস
- ডাটাবেস
- গভীর
- প্রদর্শন
- নির্ভর করে
- বর্ণনা করা
- DID
- বিভিন্ন
- না
- ডোমেইন
- প্রগতিশীল
- প্রতি
- সহজে
- প্রশিক্ষণ
- শিক্ষাবিষয়ক
- প্রচেষ্টা
- নিয়োগ
- ইংরেজি
- সত্ত্বা
- সত্তা
- বিশেষত
- মূলত
- মূল্যায়ন
- ঘটনা
- উদাহরণ
- উদাহরণ
- উত্তেজনাপূর্ণ
- বিদ্যমান
- আশা করা
- ক্যান্সার
- পরিবারের
- পরিবার
- বৈশিষ্ট্য
- পরিশেষে
- অর্থ
- প্রথম
- কেন্দ্রবিন্দু
- অনুসরণ
- ফর্ম
- বিন্যাস
- ফর্ম
- ফ্রেমওয়ার্ক
- থেকে
- ক্রিয়া
- ফাঁক
- প্রজন্ম
- সৃজক
- GitHub
- লক্ষ্য
- ভাল
- মহান
- খুশি
- জমিদারি
- উচ্চতা
- এখানে
- হোম
- আশা
- কিভাবে
- কিভাবে
- hr
- HTTPS দ্বারা
- মানবতা
- ধারণা
- সনাক্ত করা
- গুরুত্বপূর্ণ
- চিত্তাকর্ষক
- অন্যান্য
- সুদ্ধ
- বৃদ্ধি
- ইনপুট
- উদাহরণ
- সম্পূর্ণ
- বিনিয়োগ
- IT
- নিজেই
- কাজ
- চাবি
- জানা
- জ্ঞান
- পরিচিত
- লেবেল
- ভাষা
- বড়
- শিক্ষা
- আইনগত
- লাইন
- লিঙ্ক
- লণ্ডন
- দীর্ঘ
- দেখুন
- সংখ্যাগুরু
- করা
- তৈরি করে
- পরিচালনা করা
- পরিচালিত
- পদ্ধতি
- Marketing
- উপাদান
- অর্থ
- মাপ
- মধ্যম
- স্মৃতি
- উল্লেখ
- হতে পারে
- মডেল
- মডেল
- অধিক
- সেতু
- সবচেয়ে জনপ্রিয়
- যথা
- নাম
- প্রাকৃতিক
- চাহিদা
- নিউ ইয়র্ক
- নিউ ইয়র্ক সিটি
- ধারণা
- এনওয়াইসি
- অন্টারিও
- অপারেশনস
- সংগঠিত
- অন্যান্য
- কাগজ
- অংশ
- বিশেষত
- পিডিএফ
- কর্মক্ষমতা
- ব্যক্তি
- দয়া করে
- পয়েন্ট
- জনপ্রিয়
- জনপ্রিয়তা
- পোস্ট
- ক্ষমতা
- ভবিষ্যতবাণী
- প্রিমিয়াম
- চমত্কার
- আগে
- সমস্যা
- উৎপাদন করা
- পণ্য
- প্রকল্প
- বিশিষ্ট
- উত্থাপন করা
- প্রশ্ন
- পাঠক
- পড়া
- সাম্প্রতিক
- সম্প্রতি
- সুপারিশ করা
- হ্রাস করা
- হ্রাসপ্রাপ্ত
- হ্রাস
- সম্পর্ক
- মুক্তি
- প্রাসঙ্গিক
- বিশ্বাসযোগ্য
- দেহাবশেষ
- প্রতিবেদন
- প্রতিনিধিত্ব
- প্রয়োজন
- গবেষণা
- অবলম্বন
- ফলাফল
- নিয়ম
- বিক্রয়
- একই
- স্কেল
- স্কোরিং
- বিভিন্ন
- ছায়া
- সংক্ষিপ্ত
- চিহ্ন
- গুরুত্বপূর্ণ
- ছোট
- So
- কিছু
- কিছু
- স্থান
- বিশেষজ্ঞ
- মান
- রাষ্ট্র
- পরিসংখ্যান
- কাঠামোবদ্ধ
- অধ্যয়ন
- পেশ
- ভুল
- সমর্থন
- সমর্থিত
- পৃষ্ঠতল
- জরিপ
- পদ্ধতি
- সিস্টেম
- লক্ষ্য
- কাজ
- কারিগরী
- টেমপ্লেট
- সার্জারির
- বিশ্ব
- সময়
- আজ
- একসঙ্গে
- টোকেন
- বিষয়
- প্রশিক্ষণ
- রূপান্তর
- ভ্রমণ
- Uk
- অনন্য
- আপডেট
- ব্যবহার
- বিভিন্ন
- দৃষ্টিপাত
- W
- ওয়েব
- সাপ্তাহিক
- কি
- হু
- ব্যাপকতর
- শব্দ
- হয়া যাই ?
- কাজ
- বিশ্ব
- would
- বছর
- আপনার






