কম্পিউটার ভিশনে, শব্দার্থিক বিভাজন হল একটি চিত্রের প্রতিটি পিক্সেলকে একটি পরিচিত লেবেল থেকে একটি শ্রেণির সাথে শ্রেণীবদ্ধ করার কাজ যাতে একই লেবেলযুক্ত পিক্সেলগুলি নির্দিষ্ট বৈশিষ্ট্যগুলি ভাগ করে। এটি ইনপুট চিত্রগুলির একটি বিভাজন মাস্ক তৈরি করে। উদাহরণস্বরূপ, নিম্নলিখিত চিত্রগুলি এর একটি বিভাজন মাস্ক দেখায় cat লেবেল।
 |
 |
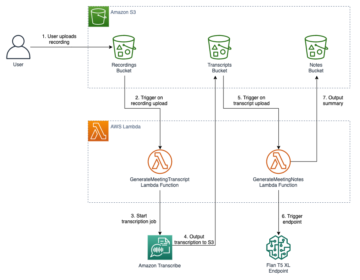
নভেম্বর 2018 সালে, আমাজন সেজমেকার SageMaker শব্দার্থিক সেগমেন্টেশন অ্যালগরিদম চালু করার ঘোষণা করেছে। এই অ্যালগরিদমের সাহায্যে, আপনি আপনার মডেলগুলিকে একটি পাবলিক ডেটাসেট বা আপনার নিজস্ব ডেটাসেট দিয়ে প্রশিক্ষণ দিতে পারেন৷ জনপ্রিয় ইমেজ সেগমেন্টেশন ডেটাসেটগুলিতে সাধারণ অবজেক্টস ইন কনটেক্সট (COCO) ডেটাসেট এবং PASCAL ভিজ্যুয়াল অবজেক্ট ক্লাস (PASCAL VOC) অন্তর্ভুক্ত রয়েছে, তবে তাদের লেবেলের ক্লাসগুলি সীমিত এবং আপনি লক্ষ্যবস্তুগুলির উপর একটি মডেল প্রশিক্ষণ দিতে চাইতে পারেন যা অন্তর্ভুক্ত নয় পাবলিক ডেটাসেট। এই ক্ষেত্রে, আপনি ব্যবহার করতে পারেন আমাজন সেজমেকার গ্রাউন্ড ট্রুথ আপনার নিজস্ব ডেটাসেট লেবেল করতে।
এই পোস্টে, আমি নিম্নলিখিত সমাধানগুলি প্রদর্শন করি:
- একটি শব্দার্থিক সেগমেন্টেশন ডেটাসেট লেবেল করতে গ্রাউন্ড ট্রুথ ব্যবহার করা
- গ্রাউন্ড ট্রুথ থেকে ফলাফলগুলিকে সেজমেকার বিল্ট-ইন সিমেন্টিক সেগমেন্টেশন অ্যালগরিদমের জন্য প্রয়োজনীয় ইনপুট ফর্ম্যাটে রূপান্তর করা
- একটি মডেল প্রশিক্ষণ এবং অনুমান সঞ্চালন শব্দার্থিক বিভাজন অ্যালগরিদম ব্যবহার করে
শব্দার্থিক সেগমেন্টেশন ডেটা লেবেলিং
শব্দার্থিক সেগমেন্টেশনের জন্য একটি মেশিন লার্নিং মডেল তৈরি করতে, আমাদের পিক্সেল স্তরে একটি ডেটাসেট লেবেল করতে হবে। গ্রাউন্ড ট্রুথ আপনাকে মানুষের টীকা ব্যবহার করার বিকল্প দেয় অ্যামাজন যান্ত্রিক তুর্ক, তৃতীয় পক্ষের বিক্রেতা, বা আপনার নিজের ব্যক্তিগত কর্মীবাহিনী। কর্মশক্তি সম্পর্কে আরও জানতে, পড়ুন কর্মীবাহিনী তৈরি এবং পরিচালনা করুন. আপনি যদি নিজেরাই লেবেলিং কর্মীবাহিনী পরিচালনা করতে না চান, আমাজন সেজমেকার গ্রাউন্ড ট্রুথ প্লাস একটি নতুন টার্নকি ডেটা লেবেলিং পরিষেবা হিসাবে আরেকটি দুর্দান্ত বিকল্প যা আপনাকে দ্রুত উচ্চ-মানের প্রশিক্ষণ ডেটাসেট তৈরি করতে এবং 40% পর্যন্ত খরচ কমাতে সক্ষম করে। এই পোস্টের জন্য, আমি আপনাকে দেখাচ্ছি কিভাবে গ্রাউন্ড ট্রুথ অটো-সেগমেন্ট বৈশিষ্ট্য এবং একটি যান্ত্রিক তুর্কি কর্মীর সাথে ক্রাউডসোর্স লেবেল দিয়ে ডেটাসেটকে ম্যানুয়ালি লেবেল করতে হয়।
গ্রাউন্ড ট্রুথ সহ ম্যানুয়াল লেবেলিং
2019 সালের ডিসেম্বরে, গ্রাউন্ড ট্রুথ লেবেলিং থ্রুপুট বাড়াতে এবং নির্ভুলতা উন্নত করতে শব্দার্থিক সেগমেন্টেশন লেবেলিং ইউজার ইন্টারফেসে একটি অটো-সেগমেন্ট বৈশিষ্ট্য যুক্ত করেছে। আরো তথ্যের জন্য, পড়ুন অ্যামাজন সেজমেকার গ্রাউন্ড ট্রুথের সাথে শব্দার্থিক সেগমেন্টেশন লেবেল করার সময় স্বয়ংক্রিয়ভাবে বিভাজন করা বস্তু. এই নতুন বৈশিষ্ট্যের সাহায্যে, আপনি বিভাজন কাজগুলিতে আপনার লেবেল প্রক্রিয়াকে ত্বরান্বিত করতে পারেন। একটি আঁটসাঁটভাবে মানানসই বহুভুজ আঁকার পরিবর্তে বা একটি ছবিতে একটি বস্তু ক্যাপচার করার জন্য ব্রাশ টুল ব্যবহার করার পরিবর্তে, আপনি শুধুমাত্র চারটি পয়েন্ট আঁকুন: অবজেক্টের শীর্ষ-সবচেয়ে, নীচে-সবচেয়ে, বাম-সবচেয়ে এবং ডান-সবচেয়ে বিন্দুতে। গ্রাউন্ড ট্রুথ এই চারটি পয়েন্টকে ইনপুট হিসাবে নেয় এবং ডিপ এক্সট্রিম কাট (DEXTR) অ্যালগরিদম ব্যবহার করে বস্তুর চারপাশে শক্তভাবে ফিটিং মাস্ক তৈরি করে। ইমেজ সিমেন্টিক সেগমেন্টেশন লেবেলিংয়ের জন্য গ্রাউন্ড ট্রুথ ব্যবহার করে একটি টিউটোরিয়াল দেখুন ইমেজ শব্দার্থিক সেগমেন্টেশন. আপনি একটি বস্তুর চারটি চরম বিন্দু নির্বাচন করার পরে স্বয়ংক্রিয়-বিভাজন টুলটি কীভাবে স্বয়ংক্রিয়ভাবে একটি বিভাজন মাস্ক তৈরি করে তার একটি উদাহরণ নিচে দেওয়া হল।


একটি যান্ত্রিক তুর্কি কর্মীর সাথে ক্রাউডসোর্সিং লেবেল
যদি আপনার কাছে একটি বড় ডেটাসেট থাকে এবং আপনি নিজে শত শত বা হাজার হাজার ছবিকে ম্যানুয়ালি লেবেল করতে না চান, তাহলে আপনি মেকানিক্যাল তুর্ক ব্যবহার করতে পারেন, যা একটি অন-ডিমান্ড, স্কেলেবল, মানব কর্মশক্তি প্রদান করে কাজগুলি সম্পন্ন করার জন্য যা মানুষ কম্পিউটারের চেয়ে ভালো করতে পারে৷ মেকানিক্যাল তুর্ক সফ্টওয়্যার তাদের সুবিধামত টুকরো টুকরো কাজ করতে ইচ্ছুক হাজার হাজার কর্মীকে কাজের অফারকে আনুষ্ঠানিক করে। সফ্টওয়্যারটি সম্পাদিত কাজটি পুনরুদ্ধার করে এবং আপনার জন্য, অনুরোধকারীর জন্য সংকলন করে, যিনি কর্মীদের সন্তোষজনক কাজের জন্য অর্থ প্রদান করেন (শুধুমাত্র)। মেকানিক্যাল তুর্ক দিয়ে শুরু করতে, পড়ুন আমাজন মেকানিক্যাল তুর্কের পরিচিতি.
একটি লেবেলিং কাজ তৈরি করুন
নীচে একটি সমুদ্র কচ্ছপ ডেটাসেটের জন্য একটি যান্ত্রিক তুর্কি লেবেল কাজের একটি উদাহরণ। সামুদ্রিক কচ্ছপ ডেটাসেট কাগল প্রতিযোগিতা থেকে এসেছে সামুদ্রিক কচ্ছপের মুখ সনাক্তকরণ, এবং আমি প্রদর্শনের উদ্দেশ্যে ডেটাসেটের 300টি ছবি নির্বাচন করেছি। সামুদ্রিক কচ্ছপ পাবলিক ডেটাসেটে একটি সাধারণ শ্রেণী নয় তাই এটি এমন একটি পরিস্থিতির প্রতিনিধিত্ব করতে পারে যার জন্য একটি বিশাল ডেটাসেট লেবেল করা প্রয়োজন।
- সেজমেকার কনসোলে, নির্বাচন করুন লেবেল কাজ নেভিগেশন ফলকে।
- বেছে নিন লেবেলিং কাজ তৈরি করুন.
- আপনার কাজের জন্য একটি নাম লিখুন.
- জন্য ইনপুট ডেটা সেটআপ, নির্বাচন করুন স্বয়ংক্রিয় ডেটা সেটআপ.
এটি ইনপুট ডেটার একটি ম্যানিফেস্ট তৈরি করে। - জন্য ইনপুট ডেটাসেটের জন্য S3 অবস্থান, ডেটাসেটের জন্য পাথ লিখুন।

- জন্য কার্য বিভাগনির্বাচন ভাবমূর্তি.
- জন্য টাস্ক নির্বাচন, নির্বাচন করুন শব্দার্থ বিভাজন.

- জন্য শ্রমিকের ধরন, নির্বাচন করুন অ্যামাজন যান্ত্রিক তুর্ক.
- টাস্ক টাইমআউট, টাস্কের মেয়াদ শেষ হওয়ার সময় এবং টাস্ক প্রতি মূল্যের জন্য আপনার সেটিংস কনফিগার করুন।

- একটি লেবেল যোগ করুন (এই পোস্টের জন্য,
sea turtle), এবং লেবেলিং নির্দেশাবলী প্রদান করুন। - বেছে নিন সৃষ্টি.

আপনি লেবেলিং কাজ সেট আপ করার পরে, আপনি সেজমেকার কনসোলে লেবেলিংয়ের অগ্রগতি পরীক্ষা করতে পারেন। যখন এটি সম্পূর্ণ হিসাবে চিহ্নিত করা হয়, আপনি ফলাফলগুলি পরীক্ষা করার জন্য কাজটি বেছে নিতে পারেন এবং পরবর্তী পদক্ষেপগুলির জন্য সেগুলি ব্যবহার করতে পারেন৷

ডেটাসেট রূপান্তর
আপনি গ্রাউন্ড ট্রুথ থেকে আউটপুট পাওয়ার পরে, আপনি এই ডেটাসেটে একটি মডেল প্রশিক্ষণের জন্য সেজমেকার বিল্ট-ইন অ্যালগরিদম ব্যবহার করতে পারেন। প্রথমে, আপনাকে সেজমেকার শব্দার্থিক বিভাজন অ্যালগরিদমের জন্য অনুরোধকৃত ইনপুট ইন্টারফেস হিসাবে লেবেলযুক্ত ডেটাসেট প্রস্তুত করতে হবে।
ইনপুট তথ্য চ্যানেল অনুরোধ করা হয়েছে
SageMaker শব্দার্থিক বিভাজন আশা করে যে আপনার প্রশিক্ষণ ডেটাসেট সংরক্ষণ করা হবে আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3)। Amazon S3-এর ডেটাসেট দুটি চ্যানেলে উপস্থাপিত হবে বলে আশা করা হচ্ছে, একটির জন্য train এবং এক জন্য validation, চারটি ডিরেক্টরি ব্যবহার করে, দুটি ছবির জন্য এবং দুটি টীকাগুলির জন্য৷ টীকাগুলি কম্প্রেসড PNG ইমেজ হবে বলে আশা করা হচ্ছে। ডেটাসেটে একটি লেবেল মানচিত্রও থাকতে পারে যা বর্ণনা করে যে কীভাবে টীকা ম্যাপিংগুলি প্রতিষ্ঠিত হয়। যদি না হয়, অ্যালগরিদম একটি ডিফল্ট ব্যবহার করে। অনুমানের জন্য, একটি শেষবিন্দু একটি সহ চিত্রগুলি গ্রহণ করে image/jpeg বিষয়বস্তুর প্রকার. নিম্নলিখিত ডেটা চ্যানেলগুলির প্রয়োজনীয় কাঠামো:
ট্রেন এবং বৈধতা ডিরেক্টরিতে প্রতিটি JPG চিত্রের একই নামের সাথে একটি সংশ্লিষ্ট PNG লেবেল চিত্র রয়েছে train_annotation এবং validation_annotation ডিরেক্টরি এই নামকরণ কনভেনশন প্রশিক্ষণের সময় অ্যালগরিদমকে একটি লেবেলকে তার সংশ্লিষ্ট চিত্রের সাথে সংযুক্ত করতে সাহায্য করে। রেলগাড়ি, train_annotation, বৈধতা, এবং validation_annotation চ্যানেল বাধ্যতামূলক। টীকাগুলি হল একক-চ্যানেল PNG ছবি৷ ফর্ম্যাটটি ততক্ষণ কাজ করে যতক্ষণ পর্যন্ত ছবির মেটাডেটা (মোড) অ্যালগরিদমকে একটি একক-চ্যানেল 8-বিট স্বাক্ষরবিহীন পূর্ণসংখ্যাতে টীকা চিত্রগুলি পড়তে সাহায্য করে৷
গ্রাউন্ড ট্রুথ লেবেলিং কাজ থেকে আউটপুট
গ্রাউন্ড ট্রুথ লেবেলিং কাজ থেকে উৎপন্ন আউটপুটগুলির নিম্নলিখিত ফোল্ডার গঠন রয়েছে:
বিভাজন মাস্ক সংরক্ষিত হয় s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. প্রতিটি টীকা ইমেজ হল একটি .png ফাইল যার নাম সোর্স ইমেজের সূচী এবং এই ইমেজ লেবেলিং সম্পন্ন হওয়ার সময় অনুসারে। উদাহরণস্বরূপ, নিম্নোক্ত উৎস চিত্র (Image_1.jpg) এবং মেকানিক্যাল তুর্কি কর্মশক্তি (0_2022-02-10T17:41:04.724225.png) দ্বারা উত্পন্ন এর সেগমেন্টেশন মাস্ক। লক্ষ্য করুন যে মুখোশের সূচীটি উত্স চিত্রের নামের চেয়ে আলাদা।
 |
 |
লেবেলিং কাজ থেকে আউটপুট ম্যানিফেস্ট আছে /manifests/output/output.manifest ফাইল এটি একটি JSON ফাইল, এবং প্রতিটি লাইন সোর্স ইমেজ এবং এর লেবেল এবং অন্যান্য মেটাডেটার মধ্যে একটি ম্যাপিং রেকর্ড করে। নিম্নলিখিত JSON লাইনটি দেখানো উত্স চিত্র এবং এর টীকাগুলির মধ্যে একটি ম্যাপিং রেকর্ড করে:
উৎস চিত্রটিকে বলা হয় Image_1.jpg, এবং টীকাটির নাম 0_2022-02-10T17:41: 04.724225.png। সেজমেকার শব্দার্থিক সেগমেন্টেশন অ্যালগরিদমের প্রয়োজনীয় ডেটা চ্যানেল ফর্ম্যাট হিসাবে ডেটা প্রস্তুত করতে, আমাদের টীকাটির নাম পরিবর্তন করতে হবে যাতে এটির উত্স JPG চিত্রগুলির মতো একই নাম থাকে৷ এবং আমাদের ডেটাসেটকে বিভক্ত করতে হবে train এবং validation উৎস ইমেজ এবং টীকা জন্য ডিরেক্টরি.
একটি গ্রাউন্ড ট্রুথ লেবেলিং কাজ থেকে আউটপুটকে অনুরোধ করা ইনপুট ফর্ম্যাটে রূপান্তর করুন
আউটপুট রূপান্তর করতে, নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- অ্যামাজন এস 3 থেকে স্থানীয় ডিরেক্টরিতে লেবেলিং কাজ থেকে সমস্ত ফাইল ডাউনলোড করুন:
- ম্যানিফেস্ট ফাইলটি পড়ুন এবং সোর্স ইমেজগুলির মতো একই নামে টীকাটির নাম পরিবর্তন করুন:
- ট্রেন এবং বৈধতা ডেটাসেট বিভক্ত করুন:
- শব্দার্থিক সেগমেন্টেশন অ্যালগরিদম ডেটা চ্যানেলগুলির জন্য প্রয়োজনীয় বিন্যাসে একটি ডিরেক্টরি তৈরি করুন:
- তৈরি ডিরেক্টরিতে ট্রেন এবং যাচাইকরণের ছবি এবং তাদের টীকাগুলি সরান।
- ছবির জন্য, নিম্নলিখিত কোড ব্যবহার করুন:
- টীকা জন্য, নিম্নলিখিত কোড ব্যবহার করুন:
- ট্রেন এবং বৈধতা ডেটাসেট এবং তাদের টীকা ডেটাসেটগুলি Amazon S3 এ আপলোড করুন:
সেজমেকার শব্দার্থিক সেগমেন্টেশন মডেল প্রশিক্ষণ
এই বিভাগে, আমরা আপনার শব্দার্থিক সেগমেন্টেশন মডেলকে প্রশিক্ষণ দেওয়ার জন্য ধাপগুলি দিয়ে চলেছি।
নমুনা নোটবুক অনুসরণ করুন এবং ডেটা চ্যানেল সেট আপ করুন
আপনি নির্দেশাবলী অনুসরণ করতে পারেন শব্দার্থক সেগমেন্টেশন অ্যালগরিদম এখন Amazon SageMaker-এ উপলব্ধ আপনার লেবেল করা ডেটাসেটে শব্দার্থিক বিভাজন অ্যালগরিদম বাস্তবায়ন করতে। এই নমুনা নোটবই অ্যালগরিদম প্রবর্তন একটি এন্ড-টু-এন্ড উদাহরণ দেখায়। নোটবুকে, আপনি শিখবেন কিভাবে সম্পূর্ণ কনভোল্যুশনাল নেটওয়ার্ক ব্যবহার করে একটি শব্দার্থিক সেগমেন্টেশন মডেলকে প্রশিক্ষণ ও হোস্ট করতে হয় (FCN) অ্যালগরিদম ব্যবহার করে প্যাসকেল VOC ডেটাসেট প্রশিক্ষণের জন্য. যেহেতু আমি Pascal VOC ডেটাসেট থেকে একটি মডেলকে প্রশিক্ষণ দেওয়ার পরিকল্পনা করছি না, তাই আমি এই নোটবুকের ধাপ 3 (ডেটা প্রস্তুতি) এড়িয়ে গেছি। পরিবর্তে, আমি সরাসরি তৈরি train_channel, train_annotation_channe, validation_channel, এবং validation_annotation_channel S3 অবস্থানগুলি ব্যবহার করে যেখানে আমি আমার ছবি এবং টীকা সংরক্ষণ করেছি:
SageMaker এস্টিমেটরে আপনার নিজস্ব ডেটাসেটের জন্য হাইপারপ্যারামিটারগুলি সামঞ্জস্য করুন
আমি নোটবুক অনুসরণ করেছি এবং একটি সেজমেকার অনুমানকারী বস্তু তৈরি করেছি (ss_estimator) আমার সেগমেন্টেশন অ্যালগরিদমকে প্রশিক্ষণ দিতে। নতুন ডেটাসেটের জন্য আমাদের একটি জিনিস কাস্টমাইজ করতে হবে ss_estimator.set_hyperparameters: আমাদের পরিবর্তন করতে হবে num_classes=21 থেকে num_classes=2 (turtle এবং background), এবং আমিও পরিবর্তন করেছি epochs=10 থেকে epochs=30 কারণ 10 শুধুমাত্র ডেমো উদ্দেশ্যে। তারপর আমি সেট করে মডেল প্রশিক্ষণের জন্য p3.2xlarge উদাহরণ ব্যবহার করেছি instance_type="ml.p3.2xlarge". 8 মিনিটে প্রশিক্ষণ শেষ হয়। সেরা MIoU 0.846-এর (ইউনিয়নের উপর ছেদ করা গড়) 11-এ যুগে অর্জিত হয় pix_acc (আপনার চিত্রের পিক্সেলের শতাংশ যা সঠিকভাবে শ্রেণীবদ্ধ করা হয়েছে) 0.925, যা এই ছোট ডেটাসেটের জন্য একটি সুন্দর ফলাফল।
মডেল অনুমান ফলাফল
আমি একটি কম খরচে ml.c5.xlarge উদাহরণে মডেলটি হোস্ট করেছি:
অবশেষে, আমি প্রশিক্ষিত বিভাজন মডেলের অনুমান ফলাফল দেখতে 10টি কচ্ছপের চিত্রের একটি পরীক্ষা সেট প্রস্তুত করেছি:
নিম্নলিখিত ছবি ফলাফল দেখায়.

সামুদ্রিক কচ্ছপগুলির বিভাজন মাস্কগুলি সঠিক দেখায় এবং যান্ত্রিক তুর্কি কর্মীদের দ্বারা লেবেলযুক্ত একটি 300-চিত্রের ডেটাসেটে প্রশিক্ষণ দেওয়া এই ফলাফলে আমি খুশি। এছাড়াও আপনি অন্যান্য উপলব্ধ নেটওয়ার্ক যেমন অন্বেষণ করতে পারেন পিরামিড-দৃশ্য-পার্সিং নেটওয়ার্ক (PSP) or DeepLab-V3 আপনার ডেটাসেটের সাথে নমুনা নোটবুকে।
পরিষ্কার কর
ক্রমাগত খরচ এড়াতে আপনার শেষ হয়ে গেলে শেষ পয়েন্টটি মুছুন:
উপসংহার
এই পোস্টে, আমি দেখিয়েছি কীভাবে সেজমেকার ব্যবহার করে শব্দার্থিক সেগমেন্টেশন ডেটা লেবেলিং এবং মডেল প্রশিক্ষণ কাস্টমাইজ করা যায়। প্রথমত, আপনি অটো-সেগমেন্টেশন টুলের সাহায্যে একটি লেবেলিং কাজ সেট আপ করতে পারেন বা মেকানিক্যাল তুর্ক কর্মীবাহিনী ব্যবহার করতে পারেন (পাশাপাশি অন্যান্য বিকল্পগুলি)। আপনার যদি 5,000 টির বেশি বস্তু থাকে তবে আপনি স্বয়ংক্রিয় ডেটা লেবেলিং ব্যবহার করতে পারেন। তারপরে আপনি আপনার গ্রাউন্ড ট্রুথ লেবেলিং জব থেকে আউটপুটগুলিকে সেজমেকার বিল্ট-ইন সিমেন্টিক সেগমেন্টেশন প্রশিক্ষণের জন্য প্রয়োজনীয় ইনপুট ফর্ম্যাটে রূপান্তর করুন। এর পরে, আপনি একটি ত্বরিত কম্পিউটিং উদাহরণ ব্যবহার করতে পারেন (যেমন p2 বা p3) নিম্নলিখিতগুলির সাথে একটি শব্দার্থিক সেগমেন্টেশন মডেলকে প্রশিক্ষণ দিতে নোটবই এবং মডেলটিকে আরও ব্যয়-কার্যকর দৃষ্টান্তে স্থাপন করুন (যেমন ml.c5.xlarge)। শেষ অবধি, আপনি কোডের কয়েকটি লাইন দিয়ে আপনার পরীক্ষার ডেটাসেটে অনুমান ফলাফল পর্যালোচনা করতে পারেন।
SageMaker শব্দার্থিক সেগমেন্টেশন দিয়ে শুরু করুন ডেটা লেবেলিং এবং মডেল প্রশিক্ষণ আপনার প্রিয় ডেটাসেট সহ!
লেখক সম্পর্কে
 কারা ইয়াং AWS প্রফেশনাল সার্ভিসে একজন ডেটা সায়েন্টিস্ট। তিনি AWS ক্লাউড পরিষেবাগুলির মাধ্যমে গ্রাহকদের তাদের ব্যবসায়িক লক্ষ্য অর্জনে সহায়তা করার বিষয়ে উত্সাহী৷ তিনি একাধিক শিল্প যেমন উৎপাদন, স্বয়ংচালিত, পরিবেশগত স্থায়িত্ব এবং মহাকাশ জুড়ে এমএল সমাধান তৈরি করতে সংস্থাগুলিকে সাহায্য করেছেন।
কারা ইয়াং AWS প্রফেশনাল সার্ভিসে একজন ডেটা সায়েন্টিস্ট। তিনি AWS ক্লাউড পরিষেবাগুলির মাধ্যমে গ্রাহকদের তাদের ব্যবসায়িক লক্ষ্য অর্জনে সহায়তা করার বিষয়ে উত্সাহী৷ তিনি একাধিক শিল্প যেমন উৎপাদন, স্বয়ংচালিত, পরিবেশগত স্থায়িত্ব এবং মহাকাশ জুড়ে এমএল সমাধান তৈরি করতে সংস্থাগুলিকে সাহায্য করেছেন।
- Coinsmart. ইউরোপের সেরা বিটকয়েন এবং ক্রিপ্টো এক্সচেঞ্জ।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. বিনামূল্যে এক্সেস.
- ক্রিপ্টোহক। Altcoin রাডার। বিনামূল্যে ট্রায়াল.
- সূত্র: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- সম্পর্কে
- দ্রুততর করা
- দ্রুততর
- সঠিক
- অর্জন করা
- অর্জন
- দিয়ে
- যোগ
- মহাকাশ
- অ্যালগরিদম
- আলগোরিদিম
- সব
- মর্দানী স্ত্রীলোক
- ঘোষিত
- অন্য
- কাছাকাছি
- সহযোগী
- অটোমেটেড
- স্বয়ংক্রিয়ভাবে
- স্বয়ংচালিত
- সহজলভ্য
- ডেস্কটপ AWS
- পটভূমি
- কারণ
- সর্বোত্তম
- উত্তম
- মধ্যে
- নির্মাণ করা
- বিল্ট-ইন
- ব্যবসায়
- গ্রেপ্তার
- কেস
- কিছু
- পরিবর্তন
- চ্যানেল
- বেছে নিন
- শ্রেণী
- ক্লাস
- শ্রেণীবদ্ধ
- মেঘ
- মেঘ পরিষেবা
- কোড
- সাধারণ
- প্রতিযোগিতা
- সম্পূর্ণ
- কম্পিউটার
- কম্পিউটার
- কম্পিউটিং
- বিশ্বাস
- কনসোল
- বিষয়বস্তু
- সুবিধা
- অনুরূপ
- সাশ্রয়ের
- খরচ
- সৃষ্টি
- নির্মিত
- গ্রাহকদের
- কাস্টমাইজ
- উপাত্ত
- তথ্য বিজ্ঞানী
- গভীর
- প্রদর্শন
- স্থাপন
- বিভিন্ন
- সরাসরি
- অঙ্কন
- সময়
- প্রতি
- সম্ভব
- সর্বশেষ সীমা
- শেষপ্রান্ত
- প্রবেশ করান
- পরিবেশ
- প্রতিষ্ঠিত
- উদাহরণ
- ছাড়া
- প্রত্যাশিত
- আশা
- অন্বেষণ করুণ
- চরম
- মুখ
- বৈশিষ্ট্য
- প্রথম
- অনুসরণ করা
- অনুসরণ
- বিন্যাস
- থেকে
- উত্পন্ন
- গোল
- ভাল
- ধূসর
- মহান
- খুশি
- সাহায্য
- সাহায্য
- সাহায্য
- উচ্চ গুনসম্পন্ন
- হোস্ট
- কিভাবে
- কিভাবে
- HTTPS দ্বারা
- মানবীয়
- মানুষেরা
- শত শত
- ভাবমূর্তি
- চিত্র
- বাস্তবায়ন
- উন্নত করা
- অন্তর্ভুক্ত করা
- অন্তর্ভুক্ত
- বৃদ্ধি
- সূচক
- শিল্প
- তথ্য
- ইনপুট
- উদাহরণ
- ইন্টারফেস
- ছেদ
- উপস্থাপক
- IT
- কাজ
- জবস
- পরিচিত
- লেবেল
- লেবেল
- লেবেলগুলি
- বড়
- শুরু করা
- শিখতে
- শিক্ষা
- উচ্চতা
- সীমিত
- লাইন
- লাইন
- তালিকা
- স্থানীয়
- অবস্থান
- অবস্থানগুলি
- দীর্ঘ
- দেখুন
- মেশিন
- মেশিন লার্নিং
- পরিচালনা করা
- কার্যভার
- ম্যানুয়ালি
- উত্পাদন
- মানচিত্র
- ম্যাপিং
- মাস্ক
- মুখোশ
- বৃহদায়তন
- যান্ত্রিক
- হতে পারে
- ML
- মডেল
- মডেল
- অধিক
- বহু
- নাম
- নামকরণ
- ন্যাভিগেশন
- নেটওয়ার্ক
- নেটওয়ার্ক
- পরবর্তী
- নোটবই
- সংখ্যা
- অফার
- পছন্দ
- অপশন সমূহ
- সংগঠন
- অন্যান্য
- নিজের
- কামুক
- শতাংশ
- করণ
- পয়েন্ট
- বহুভুজ
- জনপ্রিয়
- প্রস্তুত করা
- চমত্কার
- মূল্য
- ব্যক্তিগত
- প্রক্রিয়া
- উৎপাদন করা
- পেশাদারী
- প্রদান
- উপলব্ধ
- প্রকাশ্য
- উদ্দেশ্য
- দ্রুত
- RE
- রেকর্ড
- চিত্রিত করা
- প্রয়োজনীয়
- প্রয়োজন
- ফলাফল
- এখানে ক্লিক করুন
- একই
- মাপযোগ্য
- বিজ্ঞানী
- সাগর
- সেগমেন্টেশন
- নির্বাচিত
- সেবা
- সেবা
- সেট
- বিন্যাস
- শেয়ার
- প্রদর্শনী
- প্রদর্শিত
- সহজ
- অবস্থা
- ছোট
- So
- সফটওয়্যার
- সলিউশন
- বিভক্ত করা
- শুরু
- স্টোরেজ
- সাস্টেনিবিলিটি
- লক্ষ্য
- কাজ
- টীম
- পরীক্ষা
- সার্জারির
- উৎস
- জিনিস
- তৃতীয় পক্ষের
- হাজার হাজার
- দ্বারা
- থ্রুপুট
- সময়
- টুল
- রেলগাড়ি
- প্রশিক্ষণ
- রুপান্তর
- মিলন
- ব্যবহার
- বৈধতা
- বিক্রেতারা
- দৃষ্টি
- হু
- হয়া যাই ?
- শ্রমিকদের
- কর্মীসংখ্যার
- কাজ
- আপনার