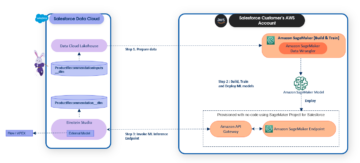
কখন OpenAI জুলাই 2020-এ তাদের মেশিন লার্নিং (ML) মডেলের তৃতীয় প্রজন্ম প্রকাশ করেছে যা টেক্সট জেনারেশনে বিশেষজ্ঞ, আমি জানতাম যে কিছু আলাদা ছিল। এই মডেলটি এমন একটি স্নায়ুতে আঘাত করেছে যেটা আগে আসেনি। হঠাৎ আমি বন্ধু এবং সহকর্মীদের শুনতে পেলাম, যারা প্রযুক্তিতে আগ্রহী হতে পারে কিন্তু সাধারণত AI/ML স্পেসের সাম্প্রতিক অগ্রগতি সম্পর্কে খুব বেশি চিন্তা করেন না, এটি সম্পর্কে কথা বলুন। এমনকি গার্ডিয়ান লিখেছেন একটি নিবন্ধ এটা সম্পর্কে অথবা, সুনির্দিষ্ট হতে, মডেল নিবন্ধটি লিখেছেন এবং গার্ডিয়ান এটি সম্পাদনা করে প্রকাশ করেছে। অস্বীকার করার কিছু ছিল না- GPT-3 একটি খেলা পরিবর্তনকারী ছিল.
মডেলটি প্রকাশের পরে, লোকেরা অবিলম্বে এটির জন্য সম্ভাব্য অ্যাপ্লিকেশন নিয়ে আসতে শুরু করে। সপ্তাহের মধ্যে, অনেক চিত্তাকর্ষক ডেমো তৈরি করা হয়েছিল, যা পাওয়া যাবে GPT-3 ওয়েবসাইট. একটি বিশেষ অ্যাপ্লিকেশন যা আমার নজর কেড়েছিল পাঠ্য সংক্ষিপ্তকরণ - একটি প্রদত্ত পাঠ্য পড়তে এবং এর বিষয়বস্তু সংক্ষিপ্ত করার জন্য একটি কম্পিউটারের ক্ষমতা। এটি একটি কম্পিউটারের জন্য সবচেয়ে কঠিন কাজগুলির মধ্যে একটি কারণ এটি প্রাকৃতিক ভাষা প্রক্রিয়াকরণের (এনএলপি) ক্ষেত্রের মধ্যে দুটি ক্ষেত্রকে একত্রিত করে: পাঠ বোঝা এবং পাঠ্য তৈরি করা। যে কারণে আমি পাঠ্য সংক্ষিপ্তকরণের জন্য GPT-3 ডেমো দ্বারা এত মুগ্ধ হয়েছি।
আপনি তাদের একটি চেষ্টা করতে পারেন আলিঙ্গন ফেস স্পেস ওয়েবসাইট. এই মুহূর্তে আমার প্রিয় একটি হল একটি আবেদন যেটি ইনপুট হিসাবে নিবন্ধের URL দিয়ে সংবাদ নিবন্ধের সারাংশ তৈরি করে।
এই দুই-অংশের সিরিজে, আমি সংস্থাগুলির জন্য একটি ব্যবহারিক নির্দেশিকা প্রস্তাব করছি যাতে আপনি আপনার ডোমেনের জন্য পাঠ্য সংক্ষিপ্তকরণ মডেলগুলির গুণমান মূল্যায়ন করতে পারেন।
টিউটোরিয়াল ওভারভিউ
অনেক প্রতিষ্ঠানের সাথে আমি কাজ করি (দাতব্য, কোম্পানি, এনজিও) তাদের পড়তে এবং সংক্ষিপ্ত করার জন্য প্রচুর পাঠ্য রয়েছে – আর্থিক প্রতিবেদন বা সংবাদ নিবন্ধ, বৈজ্ঞানিক গবেষণাপত্র, পেটেন্ট অ্যাপ্লিকেশন, আইনি চুক্তি এবং আরও অনেক কিছু। স্বাভাবিকভাবেই, এই সংস্থাগুলি এনএলপি প্রযুক্তির সাহায্যে এই কাজগুলি স্বয়ংক্রিয় করতে আগ্রহী। সম্ভাব্য শিল্প প্রদর্শন করতে, আমি প্রায়ই পাঠ্য সংক্ষিপ্তকরণ ডেমো ব্যবহার করি, যা প্রায়ই প্রভাবিত করতে ব্যর্থ হয় না।
কিন্তু এখন কি?
এই সংস্থাগুলির জন্য চ্যালেঞ্জ হল যে তারা অনেকগুলি, বহু নথির সারাংশের উপর ভিত্তি করে পাঠ্য সংক্ষিপ্তকরণ মডেলগুলি মূল্যায়ন করতে চায় - একবারে একটি নয়। তারা এমন একজন ইন্টার্ন নিয়োগ করতে চায় না যার একমাত্র কাজ হল অ্যাপ্লিকেশন খোলা, একটি নথিতে আটকানো, আঘাত করা সংক্ষিপ্ত করা বোতাম, আউটপুটের জন্য অপেক্ষা করুন, সারাংশটি ভাল কিনা তা মূল্যায়ন করুন এবং হাজার হাজার নথির জন্য এটি আবার করুন।
আমি এই টিউটোরিয়ালটি চার সপ্তাহ আগে থেকে আমার অতীতের কথা মাথায় রেখে লিখেছিলাম – এই টিউটোরিয়ালটি আমি যদি এই যাত্রা শুরু করি তখন যদি আমি ফিরে পেতাম। সেই অর্থে, এই টিউটোরিয়ালের টার্গেট শ্রোতারা হলেন এমন কেউ যিনি AI/ML এর সাথে পরিচিত এবং আগে ট্রান্সফরমার মডেলগুলি ব্যবহার করেছেন, কিন্তু তাদের পাঠ্য সংক্ষিপ্তকরণের যাত্রার শুরুতে রয়েছেন এবং এটির গভীরে যেতে চান৷ যেহেতু এটি একজন "শিশু" দ্বারা লিখিত এবং নতুনদের জন্য, আমি এই টিউটোরিয়ালটির উপর জোর দিতে চাই a ব্যবহারিক গাইড - না দ্য ব্যবহারিক গাইড। অনুগ্রহ করে এটির মতো আচরণ করুন জর্জ ইপি বক্স বলেছিলেন:
![]()
এই টিউটোরিয়ালটিতে কতটা প্রযুক্তিগত জ্ঞান প্রয়োজন তার পরিপ্রেক্ষিতে: এটি পাইথনে কিছু কোডিং জড়িত, কিন্তু বেশিরভাগ সময় আমরা API কল করার জন্য কোড ব্যবহার করি, তাই কোন গভীর কোডিং জ্ঞানের প্রয়োজন হয় না। ML এর কিছু ধারণার সাথে পরিচিত হওয়া সহায়ক, যেমন এর অর্থ কী রেলগাড়ি এবং স্থাপন একটি মডেল, এর ধারণা প্রশিক্ষণ, বৈধতা, এবং পরীক্ষা ডেটাসেট, এবং তাই। এছাড়াও সঙ্গে dabbled থাকার ট্রান্সফরমার লাইব্রেরি আগে দরকারী হতে পারে, কারণ আমরা এই টিউটোরিয়াল জুড়ে এই লাইব্রেরিটি ব্যাপকভাবে ব্যবহার করি। আমি এই ধারণাগুলির জন্য আরও পড়ার জন্য দরকারী লিঙ্কগুলিও অন্তর্ভুক্ত করি।
যেহেতু এই টিউটোরিয়ালটি একজন শিক্ষানবিস দ্বারা লেখা হয়েছে, আমি আশা করি না যে NLP বিশেষজ্ঞ এবং উন্নত ডিপ লার্নিং প্র্যাকটিশনাররা এই টিউটোরিয়ালটির বেশি কিছু পাবেন। অন্তত একটি প্রযুক্তিগত দৃষ্টিকোণ থেকে না - আপনি এখনও পড়া উপভোগ করতে পারেন, যদিও, তাই এখনও ছেড়ে না দয়া করে! কিন্তু আমার সরলীকরণের ব্যাপারে আপনাকে ধৈর্য ধরতে হবে – আমি এই টিউটোরিয়ালের সবকিছুকে যতটা সম্ভব সহজ করে তোলার ধারণা অনুযায়ী বাঁচার চেষ্টা করেছি, কিন্তু সহজ নয়।
এই টিউটোরিয়ালের গঠন
এই সিরিজটি চারটি বিভাগে বিভক্ত দুটি পোস্টে বিভক্ত, যেখানে আমরা একটি পাঠ্য সংক্ষিপ্তকরণ প্রকল্পের বিভিন্ন পর্যায়ে যাই। প্রথম পোস্টে (বিভাগ 1), আমরা পাঠ্য সংক্ষিপ্তকরণের কাজগুলির জন্য একটি মেট্রিক প্রবর্তন করে শুরু করি – কর্মক্ষমতার একটি পরিমাপ যা আমাদেরকে একটি সারাংশ ভাল বা খারাপ কিনা তা মূল্যায়ন করতে দেয়। আমরা একটি নো-এমএল মডেল ব্যবহার করে যে ডেটাসেটটিকে সংক্ষিপ্ত করতে চাই এবং একটি বেসলাইন তৈরি করতে চাই তাও উপস্থাপন করি – আমরা একটি প্রদত্ত পাঠ্য থেকে একটি সারাংশ তৈরি করতে একটি সাধারণ হিউরিস্টিক ব্যবহার করি। এই বেসলাইন তৈরি করা যেকোন ML প্রোজেক্টে একটি অত্যন্ত গুরুত্বপূর্ণ পদক্ষেপ কারণ এটি আমাদেরকে AI ব্যবহার করে এগিয়ে যাওয়ার মাধ্যমে কতটা অগ্রগতি করছি তা পরিমাপ করতে সক্ষম করে। এটি আমাদের "এআই প্রযুক্তিতে বিনিয়োগ করা কি সত্যিই মূল্যবান?" প্রশ্নের উত্তর দিতে দেয়।
দ্বিতীয় পোস্টে, আমরা একটি মডেল ব্যবহার করি যা ইতিমধ্যেই সারাংশ তৈরি করার জন্য প্রাক-প্রশিক্ষিত হয়েছে (বিভাগ 2)। এমএল নামক একটি আধুনিক পদ্ধতির মাধ্যমে এটি সম্ভব প্রশিক্ষণ স্থানান্তর. এটি আরেকটি দরকারী পদক্ষেপ কারণ আমরা মূলত একটি অফ-দ্য-শেল্ফ মডেল নিয়ে থাকি এবং এটি আমাদের ডেটাসেটে পরীক্ষা করি। এটি আমাদের আরেকটি বেসলাইন তৈরি করতে দেয়, যা আমাদের ডেটাসেটে মডেলকে প্রশিক্ষণ দিলে কী ঘটে তা দেখতে আমাদের সাহায্য করে। পন্থা বলা হয় শূন্য-শট সংক্ষিপ্তকরণ, কারণ মডেলটির আমাদের ডেটাসেটের শূন্য এক্সপোজার ছিল।
এর পরে, এটি একটি প্রাক-প্রশিক্ষিত মডেল ব্যবহার করার এবং এটিকে আমাদের নিজস্ব ডেটাসেটে প্রশিক্ষণ দেওয়ার সময় এসেছে (বিভাগ 3)। এটাও বলা হয় ফাইন টিউনিং. এটি মডেলটিকে আমাদের ডেটার প্যাটার্ন এবং আইডিওসিঙ্ক্রাসিস থেকে শিখতে এবং ধীরে ধীরে এটির সাথে মানিয়ে নিতে সক্ষম করে। আমরা মডেলকে প্রশিক্ষণ দেওয়ার পরে, আমরা সারাংশ তৈরি করতে এটি ব্যবহার করি (বিভাগ 4)।
সংক্ষেপ:
- পার্ট 1:
- বিভাগ 1: একটি বেসলাইন স্থাপন করতে একটি no-ML মডেল ব্যবহার করুন
- পার্ট 2:
- বিভাগ 2: শূন্য-শট মডেলের সাথে সারাংশ তৈরি করুন
- বিভাগ 3: একটি সংক্ষিপ্তকরণ মডেল প্রশিক্ষণ
- বিভাগ 4: প্রশিক্ষিত মডেলের মূল্যায়ন করুন
এই টিউটোরিয়ালের জন্য সম্পূর্ণ কোড নিম্নলিখিত পাওয়া যায় গিটহুব রেপো.
এই টিউটোরিয়ালটি শেষ করে আমরা কী অর্জন করতে পারব?
এই টিউটোরিয়াল শেষে, আমরা হবে না একটি পাঠ্য সংক্ষিপ্তকরণ মডেল আছে যা উৎপাদনে ব্যবহার করা যেতে পারে। আমরা এমনকি একটি হবে না ভাল সারাংশ মডেল (এখানে চিৎকার ইমোজি ঢোকান)!
এর পরিবর্তে আমাদের কাছে যা থাকবে তা হল প্রকল্পের পরবর্তী পর্যায়ের জন্য একটি সূচনা বিন্দু, যা পরীক্ষামূলক পর্ব। এখানেই ডেটা সায়েন্সে "বিজ্ঞান" আসে, কারণ এখন উপলব্ধ প্রশিক্ষণ ডেটার সাথে একটি ভাল পর্যাপ্ত সারসংক্ষেপ মডেল প্রশিক্ষিত করা যেতে পারে কিনা তা বোঝার জন্য এটি বিভিন্ন মডেল এবং বিভিন্ন সেটিংস নিয়ে পরীক্ষা করা।
এবং, সম্পূর্ণ স্বচ্ছ হওয়ার জন্য, একটি ভাল সুযোগ রয়েছে যে উপসংহারটি হবে যে প্রযুক্তিটি এখনও পাকা হয়নি এবং প্রকল্পটি বাস্তবায়িত হবে না। এবং সেই সম্ভাবনার জন্য আপনাকে আপনার ব্যবসার স্টেকহোল্ডারদের প্রস্তুত করতে হবে। কিন্তু এটি অন্য পোস্টের জন্য একটি বিষয়.
বিভাগ 1: একটি বেসলাইন স্থাপন করতে একটি no-ML মডেল ব্যবহার করুন
এটি একটি পাঠ্য সংক্ষিপ্তকরণ প্রকল্প সেট আপ করার বিষয়ে আমাদের টিউটোরিয়ালের প্রথম বিভাগ। এই বিভাগে, আমরা আসলে ML ব্যবহার না করে একটি খুব সাধারণ মডেল ব্যবহার করে একটি বেসলাইন স্থাপন করি। যেকোন ML প্রোজেক্টে এটি একটি অত্যন্ত গুরুত্বপূর্ণ পদক্ষেপ, কারণ এটি আমাদের বুঝতে দেয় যে প্রোজেক্টের সময়ের সাথে ML কতটা মান যোগ করে এবং এটিতে বিনিয়োগ করা মূল্যবান কিনা।
টিউটোরিয়ালের জন্য কোড নিম্নলিখিত পাওয়া যাবে গিটহুব রেপো.
ডেটা, ডেটা, ডেটা
প্রতিটি এমএল প্রকল্প ডেটা দিয়ে শুরু হয়! যদি সম্ভব হয়, আমরা একটি পাঠ্য সংক্ষিপ্তকরণ প্রকল্পের মাধ্যমে যা অর্জন করতে চাই তার সাথে সম্পর্কিত ডেটা ব্যবহার করা উচিত। উদাহরণস্বরূপ, যদি আমাদের লক্ষ্য পেটেন্ট অ্যাপ্লিকেশনগুলিকে সংক্ষিপ্ত করা হয়, তবে আমাদের মডেলটিকে প্রশিক্ষণের জন্য পেটেন্ট অ্যাপ্লিকেশনগুলিও ব্যবহার করা উচিত। একটি এমএল প্রকল্পের জন্য একটি বড় সতর্কতা হল যে প্রশিক্ষণ ডেটা সাধারণত লেবেল করা প্রয়োজন। টেক্সট সারসংক্ষেপের প্রেক্ষাপটে, এর মানে আমাদেরকে সারাংশের পাশাপাশি সারাংশ (লেবেল) দেওয়ার জন্য টেক্সট প্রদান করতে হবে। শুধুমাত্র উভয় প্রদানের মাধ্যমে মডেলটি শিখতে পারে যে একটি ভাল সারাংশ দেখতে কেমন।
এই টিউটোরিয়ালে, আমরা একটি সর্বজনীনভাবে উপলব্ধ ডেটাসেট ব্যবহার করি, কিন্তু যদি আমরা একটি কাস্টম বা ব্যক্তিগত ডেটাসেট ব্যবহার করি তবে ধাপ এবং কোড ঠিক একই থাকে। এবং আবার, আপনার পাঠ্য সংক্ষিপ্তকরণ মডেলের জন্য যদি আপনার মনে একটি উদ্দেশ্য থাকে এবং সংশ্লিষ্ট ডেটা থাকে, তাহলে এর থেকে সর্বাধিক সুবিধা পেতে দয়া করে আপনার ডেটা ব্যবহার করুন।
আমরা যে ডেটা ব্যবহার করি তা হল arXiv ডেটাসেট, যাতে arXiv কাগজপত্রের বিমূর্ত এবং সেইসাথে তাদের শিরোনাম রয়েছে। আমাদের উদ্দেশ্যের জন্য, আমরা যে টেক্সটকে সংক্ষিপ্ত করতে চাই সেই টেক্সট হিসেবে আমরা বিমূর্ত ব্যবহার করি এবং শিরোনামটিকে রেফারেন্স সারাংশ হিসেবে ব্যবহার করি। ডাটা ডাউনলোড এবং প্রি-প্রসেস করার সমস্ত ধাপ নিচে দেওয়া আছে নোটবই. আমরা একটি প্রয়োজন এডাব্লুএস আইডেন্টিটি এবং অ্যাক্সেস ম্যানেজমেন্ট (IAM) ভূমিকা যা থেকে এবং থেকে ডেটা লোড করার অনুমতি দেয়৷ আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3) যাতে এই নোটবুকটি সফলভাবে চালানো যায়। ডেটাসেটটি কাগজের অংশ হিসাবে তৈরি করা হয়েছিল ডেটাসেট হিসাবে ArXiv-এর ব্যবহার সম্পর্কে এবং অধীনে লাইসেন্স করা হয় ক্রিয়েটিভ কমন্স CC0 1.0 ইউনিভার্সাল পাবলিক ডোমেন ডেডিকেশন.
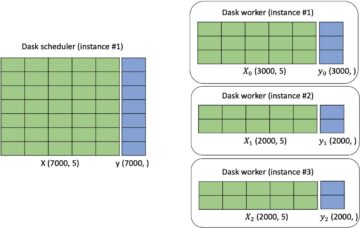
ডেটা তিনটি ডেটাসেটে বিভক্ত: প্রশিক্ষণ, বৈধতা এবং পরীক্ষার ডেটা। আপনি যদি নিজের ডেটা ব্যবহার করতে চান তবে নিশ্চিত করুন যে এটিও হয়। আমরা কিভাবে বিভিন্ন ডেটাসেট ব্যবহার করি তা নিচের চিত্রটি ব্যাখ্যা করে।
![]()
স্বাভাবিকভাবেই, এই মুহুর্তে একটি সাধারণ প্রশ্ন হল: আমাদের কত ডেটা দরকার? আপনি সম্ভবত ইতিমধ্যে অনুমান করতে পারেন, উত্তর হল: এটি নির্ভর করে। এটি নির্ভর করে ডোমেনটি কতটা বিশেষায়িত (পেটেন্ট অ্যাপ্লিকেশনের সংক্ষিপ্ত বিবরণ সংবাদ নিবন্ধের সংক্ষিপ্তসার থেকে বেশ আলাদা), মডেলটি কতটা সঠিক হতে হবে, মডেলটির প্রশিক্ষণের জন্য কত খরচ হতে হবে ইত্যাদি। আমরা পরবর্তী সময়ে এই প্রশ্নে ফিরে যাই যখন আমরা প্রকৃতপক্ষে মডেলকে প্রশিক্ষণ দিই, কিন্তু এর সংক্ষিপ্ত বিষয় হল যখন আমরা প্রকল্পের পরীক্ষামূলক পর্যায়ে থাকি তখন আমাদের বিভিন্ন ডেটাসেট আকার ব্যবহার করে দেখতে হবে।
কি একটি ভাল মডেল তোলে?
অনেক ML প্রকল্পে, একটি মডেলের কর্মক্ষমতা পরিমাপ করা বরং সহজ। কারণ মডেলের ফলাফল সঠিক কিনা তা নিয়ে সাধারণত সামান্য অস্পষ্টতা থাকে। ডেটাসেটের লেবেলগুলি প্রায়শই বাইনারি (সত্য/মিথ্যা, হ্যাঁ/না) বা শ্রেণীবদ্ধ। যাই হোক না কেন, এই পরিস্থিতিতে মডেলের আউটপুটকে লেবেলের সাথে তুলনা করা এবং এটি সঠিক বা ভুল হিসাবে চিহ্নিত করা সহজ।
পাঠ্য তৈরি করার সময়, এটি আরও চ্যালেঞ্জিং হয়ে ওঠে। আমরা আমাদের ডেটাসেটে যে সারাংশ (লেবেলগুলি) প্রদান করি তা পাঠ্যের সংক্ষিপ্তসারের একমাত্র উপায়। কিন্তু প্রদত্ত পাঠ্যের সারসংক্ষেপ করার অনেক সম্ভাবনা রয়েছে। সুতরাং, মডেলটি আমাদের লেবেল 1:1 এর সাথে না মিললেও, আউটপুট এখনও একটি বৈধ এবং দরকারী সারাংশ হতে পারে। তাহলে কিভাবে আমরা মডেলের সারাংশের সাথে তুলনা করব একটি মডেলের গুণমান পরিমাপের জন্য পাঠ্য সংক্ষিপ্তকরণে যে মেট্রিকটি প্রায়শই ব্যবহৃত হয় তা হল ROUGE স্কোর. এই মেট্রিকের মেকানিক্স বুঝতে, পড়ুন এনএলপিতে চূড়ান্ত পারফরম্যান্স মেট্রিক. সংক্ষেপে, ROUGE স্কোর এর ওভারল্যাপ পরিমাপ করে n-গ্রাম (এর সংলগ্ন ক্রম n আইটেম) মডেলের সারাংশ (প্রার্থীর সারাংশ) এবং রেফারেন্স সারাংশের মধ্যে (আমরা আমাদের ডেটাসেটে যে লেবেলটি প্রদান করি)। কিন্তু, অবশ্যই, এটি একটি নিখুঁত পরিমাপ নয়। এর সীমাবদ্ধতা বুঝতে, চেক আউট করুন ROUGE না ROUGE করতে?
সুতরাং, আমরা কিভাবে ROUGE স্কোর গণনা করব? এই মেট্রিক গণনা করার জন্য সেখানে বেশ কয়েকটি পাইথন প্যাকেজ রয়েছে। ধারাবাহিকতা নিশ্চিত করতে, আমাদের পুরো প্রকল্প জুড়ে একই পদ্ধতি ব্যবহার করা উচিত। কারণ আমরা এই টিউটোরিয়ালের পরবর্তী সময়ে আমাদের নিজস্ব লেখার পরিবর্তে ট্রান্সফরমার লাইব্রেরি থেকে একটি প্রশিক্ষণ স্ক্রিপ্ট ব্যবহার করব, আমরা শুধু উঁকি দিতে পারি সোর্স কোড স্ক্রিপ্টের এবং কোডটি অনুলিপি করুন যা ROUGE স্কোর গণনা করে:
স্কোর গণনা করার জন্য এই পদ্ধতিটি ব্যবহার করে, আমরা নিশ্চিত করি যে আমরা সর্বদা প্রকল্প জুড়ে আপেলের সাথে আপেলের তুলনা করি।
এই ফাংশনটি বিভিন্ন ROUGE স্কোর গণনা করে: rouge1, rouge2, rougeL, এবং rougeLsum. "সমষ্টি" ইন rougeLsum এই মেট্রিক একটি সম্পূর্ণ সারাংশ উপর গণনা করা হয় যে উল্লেখ করে, যেখানে rougeL পৃথক বাক্যের উপর গড় হিসাবে গণনা করা হয়। সুতরাং, আমাদের প্রকল্পের জন্য আমাদের কোন রুজ স্কোর ব্যবহার করা উচিত? আবার, আমাদের পরীক্ষা-নিরীক্ষা পর্বে বিভিন্ন পদ্ধতির চেষ্টা করতে হবে। এটা মূল্য কি জন্য, আসল রুজ কাগজ বলে যে "ROUGE-2 এবং ROUGE-L একক নথির সংক্ষিপ্তকরণের কাজগুলিতে ভাল কাজ করেছে" যখন "ROUGE-1 এবং ROUGE-L সংক্ষিপ্ত সারাংশ মূল্যায়নে দুর্দান্ত পারফর্ম করে।"
বেসলাইন তৈরি করুন
পরবর্তীতে আমরা একটি সাধারণ, নো-এমএল মডেল ব্যবহার করে বেসলাইন তৈরি করতে চাই। ওটার মানে কি? পাঠ্য সংক্ষিপ্তকরণের ক্ষেত্রে, অনেক গবেষণা একটি খুব সহজ পদ্ধতি ব্যবহার করে: তারা প্রথমটি নেয় n পাঠ্যের বাক্য এবং এটি প্রার্থীর সারাংশ ঘোষণা করুন। তারপর তারা রেফারেন্স সারাংশের সাথে প্রার্থীর সারাংশের তুলনা করে এবং ROUGE স্কোর গণনা করে। এটি একটি সহজ কিন্তু শক্তিশালী পদ্ধতি যা আমরা কোডের কয়েকটি লাইনে প্রয়োগ করতে পারি (এই অংশের জন্য সম্পূর্ণ কোডটি নিম্নলিখিতটিতে রয়েছে নোটবই):
আমরা এই মূল্যায়নের জন্য পরীক্ষার ডেটাসেট ব্যবহার করি। এটি বোধগম্য কারণ আমরা মডেলটিকে প্রশিক্ষণ দেওয়ার পরে, আমরা চূড়ান্ত মূল্যায়নের জন্য একই পরীক্ষার ডেটাসেটও ব্যবহার করি। আমরা বিভিন্ন সংখ্যার জন্যও চেষ্টা করি n: আমরা প্রার্থীর সারাংশ হিসাবে শুধুমাত্র প্রথম বাক্য দিয়ে শুরু করি, তারপর প্রথম দুটি বাক্য এবং অবশেষে প্রথম তিনটি বাক্য।
নিম্নলিখিত স্ক্রিনশটটি আমাদের প্রথম মডেলের ফলাফল দেখায়।
![]()
ROUGE স্কোর সর্বোচ্চ, শুধুমাত্র প্রার্থীর সারাংশ হিসেবে প্রথম বাক্যটি। এর মানে হল যে একাধিক বাক্য গ্রহণ করা সারাংশটিকে খুব বেশি শব্দযুক্ত করে তোলে এবং একটি কম স্কোরের দিকে নিয়ে যায়। সুতরাং এর মানে আমরা আমাদের বেসলাইন হিসাবে এক-বাক্য সারাংশের জন্য স্কোর ব্যবহার করব।
এটি লক্ষ করা গুরুত্বপূর্ণ যে, এই ধরনের একটি সহজ পদ্ধতির জন্য, এই সংখ্যাগুলি আসলে বেশ ভাল, বিশেষ করে এর জন্য rouge1 স্কোর এই সংখ্যাগুলিকে প্রসঙ্গে রাখতে, আমরা উল্লেখ করতে পারি পেগাসাস মডেল, যা বিভিন্ন ডেটাসেটের জন্য একটি অত্যাধুনিক মডেলের স্কোর দেখায়।
উপসংহার এবং পরবর্তী কি
আমাদের সিরিজের পার্ট 1-এ, আমরা ডেটাসেট প্রবর্তন করেছি যা আমরা সমগ্র সারাংশ প্রকল্পের পাশাপাশি সারাংশ মূল্যায়ন করার জন্য একটি মেট্রিক ব্যবহার করি। তারপরে আমরা একটি সাধারণ, নো-এমএল মডেলের সাথে নিম্নলিখিত বেসলাইন তৈরি করেছি।
![]()
মধ্যে পরের পোস্টে, আমরা একটি শূন্য-শট মডেল ব্যবহার করি - বিশেষত, একটি মডেল যা পাবলিক নিউজ নিবন্ধগুলিতে পাঠ্য সংক্ষিপ্তকরণের জন্য বিশেষভাবে প্রশিক্ষিত হয়েছে৷ যাইহোক, এই মডেলটি আমাদের ডেটাসেটে মোটেও প্রশিক্ষিত হবে না (তাই নাম "জিরো-শট")।
আমাদের খুব সাধারণ বেসলাইনের তুলনায় এই জিরো-শট মডেলটি কীভাবে পারফর্ম করবে তা অনুমান করার জন্য আমি এটিকে হোমওয়ার্ক হিসাবে আপনার উপর ছেড়ে দিয়েছি। একদিকে, এটি হবে অনেক বেশি পরিশীলিত মডেল (এটি আসলে একটি নিউরাল নেটওয়ার্ক)। অন্যদিকে, এটি শুধুমাত্র সংবাদ নিবন্ধগুলির সংক্ষিপ্তসারে ব্যবহৃত হয়, তাই এটি arXiv ডেটাসেটের অন্তর্নিহিত নিদর্শনগুলির সাথে লড়াই করতে পারে।
লেখক সম্পর্কে
![]() হেইকো হটজ তিনি এআই এবং মেশিন লার্নিংয়ের একজন সিনিয়র সলিউশন আর্কিটেক্ট এবং AWS-এর মধ্যে ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং (NLP) সম্প্রদায়ের নেতৃত্ব দেন। এই ভূমিকার আগে, তিনি আমাজনের ইইউ গ্রাহক পরিষেবার ডেটা সায়েন্সের প্রধান ছিলেন। Heiko আমাদের গ্রাহকদের AWS-এ তাদের AI/ML যাত্রায় সফল হতে সাহায্য করে এবং বীমা, আর্থিক পরিষেবা, মিডিয়া এবং বিনোদন, স্বাস্থ্যসেবা, উপযোগিতা এবং উত্পাদন সহ অনেক শিল্পে সংস্থার সাথে কাজ করেছে। তার অবসর সময়ে হেইকো যতটা সম্ভব ভ্রমণ করে।
হেইকো হটজ তিনি এআই এবং মেশিন লার্নিংয়ের একজন সিনিয়র সলিউশন আর্কিটেক্ট এবং AWS-এর মধ্যে ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং (NLP) সম্প্রদায়ের নেতৃত্ব দেন। এই ভূমিকার আগে, তিনি আমাজনের ইইউ গ্রাহক পরিষেবার ডেটা সায়েন্সের প্রধান ছিলেন। Heiko আমাদের গ্রাহকদের AWS-এ তাদের AI/ML যাত্রায় সফল হতে সাহায্য করে এবং বীমা, আর্থিক পরিষেবা, মিডিয়া এবং বিনোদন, স্বাস্থ্যসেবা, উপযোগিতা এবং উত্পাদন সহ অনেক শিল্পে সংস্থার সাথে কাজ করেছে। তার অবসর সময়ে হেইকো যতটা সম্ভব ভ্রমণ করে।
- Coinsmart. ইউরোপের সেরা বিটকয়েন এবং ক্রিপ্টো এক্সচেঞ্জ।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. বিনামূল্যে এক্সেস.
- ক্রিপ্টোহক। Altcoin রাডার। বিনামূল্যে ট্রায়াল.
- সূত্র: https://aws.amazon.com/blogs/machine-learning/part-1-set-up-a-text-summarization-project-with-hugging-face-transformers/
- '
- "
- &
- 100
- 2020
- সম্পর্কে
- বিমূর্ত
- প্রবেশ
- সঠিক
- অর্জন
- অগ্রসর
- উন্নয়নের
- AI
- সব
- ইতিমধ্যে
- মর্দানী স্ত্রীলোক
- অস্পষ্টতা
- পরিমাণে
- অন্য
- API গুলি
- আবেদন
- অ্যাপ্লিকেশন
- অভিগমন
- কাছাকাছি
- শিল্প
- প্রবন্ধ
- প্রবন্ধ
- পাঠকবর্গ
- সহজলভ্য
- গড়
- ডেস্কটপ AWS
- বেসলাইন
- মূলত
- শুরু
- হচ্ছে
- ব্যবসায়
- কল
- যত্ন
- ধরা
- চ্যালেঞ্জ
- কোড
- কোডিং
- সাধারণ
- সম্প্রদায়
- কোম্পানি
- তুলনা
- সম্পূর্ণরূপে
- গনা
- ধারণা
- ধারণ
- বিষয়বস্তু
- চুক্তি
- তৈরি করা হচ্ছে
- প্রথা
- গ্রাহক সেবা
- গ্রাহকদের
- উপাত্ত
- তথ্য বিজ্ঞান
- গভীর
- উন্নত
- বিভিন্ন
- কাগজপত্র
- না
- ডোমেইন
- বিনোদন
- বিশেষত
- স্থাপন করা
- EU
- সব
- উদাহরণ
- আশা করা
- বিশেষজ্ঞদের
- চোখ
- মুখ
- ক্ষেত্রসমূহ
- পরিশেষে
- আর্থিক
- অর্থনৈতিক সেবা সমূহ
- প্রথম
- অনুসরণ
- অগ্রবর্তী
- পাওয়া
- ক্রিয়া
- অধিকতর
- খেলা
- উত্পাদন করা
- প্রজন্ম
- লক্ষ্য
- চালু
- ভাল
- মহান
- অভিভাবক
- কৌশল
- জমিদারি
- মাথা
- স্বাস্থ্যসেবা
- সহায়ক
- সাহায্য
- এখানে
- ভাড়া
- কিভাবে
- HTTPS দ্বারা
- প্রচুর
- পরিচয়
- বাস্তবায়ন
- বাস্তবায়িত
- গুরুত্বপূর্ণ
- অন্তর্ভুক্ত করা
- সুদ্ধ
- স্বতন্ত্র
- শিল্প
- বীমা
- উপস্থাপক
- বিনিয়োগ
- IT
- কাজ
- জুলাই
- চাবি
- জ্ঞান
- লেবেলগুলি
- ভাষা
- সর্বশেষ
- বিশালাকার
- শিখতে
- শিক্ষা
- ত্যাগ
- আইনগত
- লাইব্রেরি
- অনুমতিপ্রাপ্ত
- লিঙ্ক
- সামান্য
- মেশিন
- মেশিন লার্নিং
- তৈরি করে
- মেকিং
- উত্পাদন
- ছাপ
- ম্যাচ
- মাপ
- মিডিয়া
- মন
- ML
- মডেল
- মডেল
- অধিক
- সেতু
- প্রাকৃতিক
- নেটওয়ার্ক
- সংবাদ
- নোটবই
- সংখ্যার
- খোলা
- ক্রম
- সংগঠন
- অন্যান্য
- কাগজ
- পেটেণ্ট
- পিডিএফ
- সম্প্রদায়
- কর্মক্ষমতা
- পরিপ্রেক্ষিত
- ফেজ
- বিন্দু
- সম্ভাবনার
- সম্ভাবনা
- সম্ভব
- পোস্ট
- সম্ভাব্য
- ক্ষমতাশালী
- ব্যক্তিগত
- উত্পাদনের
- প্রকল্প
- প্রকল্প
- উত্থাপন করা
- প্রদান
- প্রদানের
- প্রকাশ্য
- উদ্দেশ্য
- গুণ
- প্রশ্ন
- পরিসর
- RE
- পড়া
- প্রতিবেদন
- প্রয়োজন
- প্রয়োজনীয়
- গবেষণা
- ফলাফল
- চালান
- বলেছেন
- বিজ্ঞান
- অনুভূতি
- ক্রম
- সেবা
- সেবা
- সেট
- বিন্যাস
- সংক্ষিপ্ত
- সহজ
- So
- সলিউশন
- কেউ
- কিছু
- বাস্তববুদ্ধিসম্পন্ন
- স্থান
- শূণ্যস্থান
- বিশেষজ্ঞ
- বিশেষ
- বিশেষভাবে
- বিভক্ত করা
- শুরু
- শুরু
- শুরু
- রাষ্ট্র-এর-শিল্প
- যুক্তরাষ্ট্র
- স্টোরেজ
- জোর
- গবেষণায়
- সফল
- সফলভাবে
- আলাপ
- লক্ষ্য
- কাজ
- কারিগরী
- প্রযুক্তিঃ
- পরীক্ষা
- হাজার হাজার
- দ্বারা
- সর্বত্র
- সময়
- শিরনাম
- প্রশিক্ষণ
- স্বচ্ছ
- আচরণ করা
- চূড়ান্ত
- বোঝা
- সার্বজনীন
- us
- ব্যবহার
- সাধারণত
- মূল্য
- অপেক্ষা করুন
- কি
- কিনা
- হু
- উইকিপিডিয়া
- মধ্যে
- ছাড়া
- হয়া যাই ?
- কাজ করছে
- মূল্য
- লেখা
- X
- শূন্য