অ্যাপাচি আইসবার্গ খুব বড় বিশ্লেষণাত্মক ডেটাসেটের জন্য একটি উন্মুক্ত টেবিল বিন্যাস, যা ডেটাসেটের অবস্থার মেটাডেটা তথ্য ক্যাপচার করে যখন তারা বিবর্তিত হয় এবং সময়ের সাথে সাথে পরিবর্তিত হয়। এটি একটি উচ্চ-পারফরম্যান্স টেবিল বিন্যাস ব্যবহার করে স্পার্ক, ট্রিনো, প্রেস্টোডিবি, ফ্লিঙ্ক এবং হাইভ সহ গণনা ইঞ্জিনগুলিতে টেবিল যুক্ত করে যা ঠিক একটি SQL টেবিলের মতো কাজ করে। আইসবার্গ ডেটা লেকে ACID লেনদেনের সমর্থনের জন্য এবং স্কিমা এবং পার্টিশন বিবর্তন, সময় ভ্রমণ এবং রোলব্যাকের মতো বৈশিষ্ট্যগুলির জন্য খুব জনপ্রিয় হয়ে উঠেছে।
Apache Iceberg ইন্টিগ্রেশন সহ AWS বিশ্লেষণ পরিষেবা দ্বারা সমর্থিত আমাজন ইএমআর, অ্যামাজন অ্যাথেনা, এবং এডাব্লুএস আঠালো. অ্যামাজন ইএমআর স্পার্ক, হাইভ, ট্রিনো এবং ফ্লিঙ্ক সহ ক্লাস্টার সরবরাহ করতে পারে যা আইসবার্গ চালাতে পারে। Amazon EMR সংস্করণ 6.5.0 দিয়ে শুরু করে, আপনি করতে পারেন আপনার EMR ক্লাস্টারের সাথে আইসবার্গ ব্যবহার করুন একটি বুটস্ট্র্যাপ কর্মের প্রয়োজন ছাড়াই। 2022 সালের গোড়ার দিকে, AWS Apache Iceberg দ্বারা চালিত Athena ACID লেনদেনের সাধারণ উপলব্ধতা ঘোষণা করেছে। সম্প্রতি মুক্তি পেয়েছে এথেনা কোয়েরি ইঞ্জিন সংস্করণ 3 আইসবার্গ টেবিল বিন্যাসের সাথে আরও ভাল ইন্টিগ্রেশন প্রদান করে। AWS Glue 3.0 এবং পরবর্তী Apache Iceberg ফ্রেমওয়ার্ক সমর্থন করে ডেটা লেকের জন্য।
এই পোস্টে, আমরা আধুনিক ডেটা লেকে গ্রাহকরা কী চায় এবং কীভাবে Apache Iceberg গ্রাহকের চাহিদা পূরণে সহায়তা করে তা নিয়ে আলোচনা করি। তারপরে আমরা একটি উচ্চ-কর্মক্ষমতা এবং বিকশিত আইসবার্গ ডেটা লেক তৈরি করার সমাধানের মধ্য দিয়ে হাঁটছি আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3) এবং এসকিউএল স্টেটমেন্ট সন্নিবেশ, আপডেট এবং মুছে দিয়ে ক্রমবর্ধমান ডেটা প্রক্রিয়া করুন। পরিশেষে, আমরা আপনাকে দেখাই কিভাবে পঠন এবং লেখার কর্মক্ষমতা উন্নত করতে প্রক্রিয়া টিউন করতে হয়।
কিভাবে Apache Iceberg আধুনিক ডেটা লেকে গ্রাহকরা যা চান তা সম্বোধন করে
অনেক ব্যবহারকারী, অ্যাপ্লিকেশন, এবং বিশ্লেষণী সরঞ্জামগুলিকে সমর্থন করার জন্য আরও বেশি সংখ্যক গ্রাহক কাঠামোগত এবং অসংগঠিত ডেটা সহ ডেটা লেক তৈরি করছেন৷ এসিআইডি লেনদেন, রেকর্ড-লেভেল আপডেট এবং ডিলিট, টাইম ট্রাভেল এবং রোলব্যাকের মতো বৈশিষ্ট্যের মতো ডেটাবেসকে সমর্থন করার জন্য ডেটা লেকের প্রয়োজন বেড়েছে। Apache Iceberg কে Amazon S3-তে সাশ্রয়ী পেটাবাইট-স্কেল ডেটা লেকে এই বৈশিষ্ট্যগুলিকে সমর্থন করার জন্য ডিজাইন করা হয়েছে৷
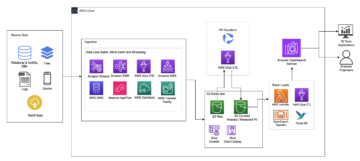
Apache Iceberg পৃথক ডেটা ফাইলগুলি তৈরি করার সময় ডেটাসেট সম্পর্কে সমৃদ্ধ মেটাডেটা তথ্য ক্যাপচার করে গ্রাহকের চাহিদাগুলিকে সম্বোধন করে৷ একটি আইসবার্গ টেবিলের আর্কিটেকচারে তিনটি স্তর রয়েছে: আইসবার্গ ক্যাটালগ, মেটাডেটা স্তর এবং ডেটা স্তর, যেমনটি নিম্নলিখিত চিত্রে চিত্রিত হয়েছে (উৎস).

আইসবার্গ ক্যাটালগ বর্তমান টেবিলের মেটাডেটা ফাইলে মেটাডেটা পয়েন্টার সঞ্চয় করে। যখন একটি নির্বাচিত ক্যোয়ারী একটি আইসবার্গ টেবিল পড়ছে, তখন ক্যোয়ারী ইঞ্জিনটি প্রথমে আইসবার্গ ক্যাটালগে যায়, তারপর বর্তমান মেটাডেটা ফাইলের অবস্থান পুনরুদ্ধার করে। যখনই আইসবার্গ টেবিলে একটি আপডেট থাকে, টেবিলের একটি নতুন স্ন্যাপশট তৈরি করা হয় এবং মেটাডেটা পয়েন্টার বর্তমান টেবিলের মেটাডেটা ফাইলের দিকে নির্দেশ করে।
নিচে AWS Glue বাস্তবায়ন সহ আইসবার্গ ক্যাটালগের একটি উদাহরণ। আপনি ডাটাবেসের নাম, আইসবার্গ টেবিলের অবস্থান (S3 পথ) এবং মেটাডেটা অবস্থান দেখতে পারেন।

মেটাডেটা লেয়ারে তিন ধরনের ফাইল আছে: মেটাডেটা ফাইল, ম্যানিফেস্ট তালিকা এবং ম্যানিফেস্ট ফাইল একটি ক্রমানুসারে। অনুক্রমের শীর্ষে রয়েছে মেটাডেটা ফাইল, যা টেবিলের স্কিমা, পার্টিশন তথ্য এবং স্ন্যাপশট সম্পর্কে তথ্য সংরক্ষণ করে। স্ন্যাপশট ম্যানিফেস্ট তালিকার দিকে নির্দেশ করে। ম্যানিফেস্ট তালিকায় প্রতিটি ম্যানিফেস্ট ফাইল সম্পর্কে তথ্য রয়েছে যা স্ন্যাপশট তৈরি করে, যেমন ম্যানিফেস্ট ফাইলের অবস্থান, এটি যে পার্টিশনগুলির অন্তর্গত, এবং এটি যে ডেটা ফাইলগুলি ট্র্যাক করে তার জন্য পার্টিশন কলামগুলির নিম্ন এবং উপরের সীমানা। ম্যানিফেস্ট ফাইল ডেটা ফাইলের পাশাপাশি প্রতিটি ফাইলের অতিরিক্ত বিবরণ যেমন ফাইল ফর্ম্যাট ট্র্যাক করে। একটি আইসবার্গ টেবিলের স্ন্যাপশট, স্কিমা, পার্টিশন, বৈশিষ্ট্য এবং ডেটা ফাইলগুলি ট্র্যাক করার জন্য তিনটি ফাইলই একটি অনুক্রমে কাজ করে।
ডেটা স্তরে আইসবার্গ টেবিলের পৃথক ডেটা ফাইল রয়েছে। আইসবার্গ Parquet, ORC, এবং Avro সহ বিস্তৃত ফাইল বিন্যাস সমর্থন করে। যেহেতু আইসবার্গ টেবিল ডেটা ফাইলের সাথে পার্টিশনের অবস্থান নির্দেশ করার পরিবর্তে পৃথক ডেটা ফাইলগুলিকে ট্র্যাক করে, এটি লেখার ক্রিয়াকলাপগুলিকে পড়ার ক্রিয়াকলাপ থেকে বিচ্ছিন্ন করে। আপনি যে কোনো সময় ডেটা ফাইল লিখতে পারেন, কিন্তু শুধুমাত্র স্পষ্টভাবে পরিবর্তন করতে পারেন, যা স্ন্যাপশট এবং মেটাডেটা ফাইলগুলির একটি নতুন সংস্করণ তৈরি করে।
সমাধান ওভারভিউ
এই পোস্টে, আমরা আপনাকে Amazon S3-এ একটি উচ্চ-কার্যক্ষমতাসম্পন্ন অ্যাপাচি আইসবার্গ ডেটা লেক তৈরির সমাধানের মাধ্যমে নিয়ে যেতে চাই; এসকিউএল স্টেটমেন্ট সন্নিবেশ, আপডেট এবং মুছে ফেলার সাথে ক্রমবর্ধমান ডেটা প্রক্রিয়া করুন; এবং পড়া এবং লেখার কর্মক্ষমতা উন্নত করতে আইসবার্গ টেবিল টিউন করুন। নিম্নলিখিত চিত্রটি সমাধানের আর্কিটেকচারকে চিত্রিত করে।

এই সমাধানটি প্রদর্শন করতে, আমরা ব্যবহার করি আমাজন গ্রাহক পর্যালোচনা একটি S3 বালতিতে ডেটাসেট (s3://amazon-reviews-pds/parquet/) বাস্তব ব্যবহারের ক্ষেত্রে, এটি আপনার S3 বালতিতে সংরক্ষিত কাঁচা ডেটা হবে। আমরা নিচের কোড দিয়ে ডেটা সাইজ চেক করতে পারি এডাব্লুএস কমান্ড লাইন ইন্টারফেস (AWS CLI):
মোট বস্তুর সংখ্যা হল 430, এবং মোট আকার হল 47.4 GiB।
এই সমাধান সেট আপ এবং পরীক্ষা করতে, আমরা নিম্নলিখিত উচ্চ-স্তরের পদক্ষেপগুলি সম্পূর্ণ করি:
- আইসবার্গ টেবিল বিন্যাসে রূপান্তরিত ডেটা সংরক্ষণ করতে কিউরেটেড জোনে একটি S3 বালতি সেট আপ করুন।
- Apache Iceberg এর জন্য উপযুক্ত কনফিগারেশন সহ একটি EMR ক্লাস্টার চালু করুন।
- EMR স্টুডিওতে একটি নোটবুক তৈরি করুন।
- Apache Iceberg এর জন্য Spark সেশন কনফিগার করুন।
- আইসবার্গ টেবিল ফরম্যাটে ডেটা রূপান্তর করুন এবং কিউরেটেড জোনে ডেটা সরান।
- ক্রমবর্ধমান ডেটা প্রক্রিয়া করতে এথেনায় প্রশ্ন সন্নিবেশ, আপডেট এবং মুছুন চালান।
- কর্মক্ষমতা টিউনিং আউট বহন.
পূর্বশর্ত
এই ওয়াকথ্রু বরাবর অনুসরণ করতে, আপনার অবশ্যই একটি থাকতে হবে এডাব্লুএস অ্যাকাউন্ট একটি সঙ্গে এডাব্লুএস আইডেন্টিটি এবং অ্যাক্সেস ম্যানেজমেন্ট (IAM) ভূমিকা যা প্রয়োজনীয় সংস্থান সরবরাহ করার জন্য পর্যাপ্ত অ্যাক্সেস রয়েছে।
আপনার ডেটা লেকের কিউরেটেড জোনে আইসবার্গ ডেটার জন্য S3 বালতি সেট আপ করুন৷
যে অঞ্চলে আপনি S3 বালতি তৈরি করতে চান এবং একটি অনন্য নাম প্রদান করতে চান তা চয়ন করুন:
স্পার্ক ব্যবহার করে আইসবার্গ কাজ চালানোর জন্য একটি EMR ক্লাস্টার চালু করুন
আপনি থেকে একটি EMR ক্লাস্টার তৈরি করতে পারেন এডাব্লুএস ম্যানেজমেন্ট কনসোল, Amazon EMR CLI, বা এডাব্লুএস ক্লাউড ডেভেলপমেন্ট কিট (AWS CDK)। এই পোস্টের জন্য, আমরা আপনাকে কিভাবে কনসোল থেকে একটি EMR ক্লাস্টার তৈরি করতে হয় তা নিয়ে আলোচনা করব।
- আমাজন ইএমআর কনসোলে, চয়ন করুন ক্লাস্টার তৈরি করুন.
- বেছে নিন উন্নত বিকল্প.
- জন্য সফ্টওয়্যার কনফিগারেশন, সর্বশেষ Amazon EMR রিলিজ বেছে নিন। জানুয়ারী 2023 পর্যন্ত, সর্বশেষ রিলিজ হল 6.9.0। আইসবার্গের জন্য রিলিজ 6.5.0 এবং তার বেশি প্রয়োজন।
- নির্বাচন করা জুপিটার এন্টারপ্রাইজ গেটওয়ে এবং স্ফুলিঙ্গ সফ্টওয়্যার ইনস্টল করার জন্য।
- জন্য সফ্টওয়্যার সেটিংস সম্পাদনা করুন, নির্বাচন করুন কনফিগারেশন লিখুন এবং প্রবেশ করান
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - অন্যান্য সেটিংস তাদের ডিফল্টে ছেড়ে দিন এবং নির্বাচন করুন পরবর্তী.

- জন্য হার্ডওয়্যারের, ডিফল্ট সেটিং ব্যবহার করুন।
- বেছে নিন পরবর্তী.
- জন্য গুচ্ছ নাম, একটি নাম লিখুন। আমরা ব্যাবহার করি
iceberg-blog-cluster. - অবশিষ্ট সেটিংস অপরিবর্তিত রাখুন এবং নির্বাচন করুন পরবর্তী.
- বেছে নিন ক্লাস্টার তৈরি করুন.
EMR স্টুডিওতে একটি নোটবুক তৈরি করুন
কনসোল থেকে ইএমআর স্টুডিওতে কীভাবে একটি নোটবুক তৈরি করা যায় তা আমরা এখন আপনাকে নিয়ে চলেছি।
- IAM কনসোলে, একটি EMR স্টুডিও পরিষেবা ভূমিকা তৈরি করুন.
- আমাজন ইএমআর কনসোলে, চয়ন করুন ইএমআর স্টুডিও.
- বেছে নিন এবার শুরু করা যাক.
সার্জারির এবার শুরু করা যাক পৃষ্ঠাটি একটি নতুন ট্যাবে প্রদর্শিত হবে।
- বেছে নিন স্টুডিও তৈরি করুন নতুন ট্যাবে।
- একটি নাম লিখুন। আমরা আইসবার্গ-স্টুডিও ব্যবহার করি।
- EMR ক্লাস্টার এবং ডিফল্ট নিরাপত্তা গোষ্ঠীর জন্য একই VPC এবং সাবনেট বেছে নিন।
- বেছে নিন AWS আইডেন্টিটি অ্যান্ড অ্যাকসেস ম্যানেজমেন্ট (IAM) প্রমাণীকরণের জন্য, এবং আপনার তৈরি করা EMR স্টুডিও পরিষেবা ভূমিকা বেছে নিন।
- এর জন্য একটি S3 পথ বেছে নিন ওয়ার্কস্পেস ব্যাকআপ.
- বেছে নিন স্টুডিও তৈরি করুন.
- স্টুডিও তৈরি হওয়ার পরে, স্টুডিও অ্যাক্সেস URL বেছে নিন।
- EMR স্টুডিও ড্যাশবোর্ডে, নির্বাচন করুন কর্মক্ষেত্র তৈরি করুন.
- আপনার কর্মক্ষেত্রের জন্য একটি নাম লিখুন। আমরা ব্যাবহার করি
iceberg-workspace. - বিস্তৃত করা উন্নত কনফিগারেশন এবং নির্বাচন করুন একটি EMR ক্লাস্টারে ওয়ার্কস্পেস সংযুক্ত করুন.
- আপনি আগে তৈরি করা EMR ক্লাস্টার বেছে নিন।
- বেছে নিন কর্মক্ষেত্র তৈরি করুন.
- একটি নতুন ট্যাব খুলতে ওয়ার্কস্পেস নামটি চয়ন করুন৷
নেভিগেশন প্যানে, ওয়ার্কস্পেসের মতো একই নামের একটি নোটবুক রয়েছে। আমাদের ক্ষেত্রে, এটি আইসবার্গ-ওয়ার্কস্পেস।
- খাতা খুলুন।
- একটি কার্নেল নির্বাচন করার জন্য অনুরোধ করা হলে, নির্বাচন করুন স্ফুলিঙ্গ.
Apache Iceberg এর জন্য একটি স্পার্ক সেশন কনফিগার করুন
আপনার নিজের S3 বালতি নাম প্রদান করে নিম্নলিখিত কোড ব্যবহার করুন:
এটি নিম্নলিখিত স্পার্ক সেশন কনফিগারেশন সেট করে:
- spark.sql.catalog.demo - ডেমো নামে একটি স্পার্ক ক্যাটালগ নিবন্ধন করে, যা আইসবার্গ স্পার্ক ক্যাটালগ প্লাগইন ব্যবহার করে।
- spark.sql.catalog.demo.catalog-impl - ডেমো স্পার্ক ক্যাটালগ আইসবার্গ ডাটাবেস এবং টেবিলের তথ্য সঞ্চয় করতে শারীরিক ক্যাটালগ হিসাবে AWS আঠালো ব্যবহার করে।
- spark.sql.catalog.demo.warehouse - ডেমো স্পার্ক ক্যাটালগ এই সম্পত্তি দ্বারা সংজ্ঞায়িত রুট পাথের অধীনে সমস্ত আইসবার্গ মেটাডেটা এবং ডেটা ফাইল সঞ্চয় করে:
s3://iceberg-curated-blog-data. - spark.sql.extensions - আইসবার্গ স্পার্ক এসকিউএল এক্সটেনশনগুলিতে সমর্থন যোগ করে, যা আপনাকে আইসবার্গ স্পার্ক পদ্ধতি এবং কিছু আইসবার্গ-কেবল এসকিউএল কমান্ড চালানোর অনুমতি দেয় (আপনি এটি পরবর্তী ধাপে ব্যবহার করেন)।
- spark.sql.catalog.demo.io-impl - আইসবার্গ ব্যবহারকারীদের S3FileIO এর মাধ্যমে Amazon S3 এ ডেটা লেখার অনুমতি দেয়। ডিফল্টরূপে AWS Glue ডেটা ক্যাটালগ এই FileIO ব্যবহার করে, এবং অন্যান্য ক্যাটালগ io-impl ক্যাটালগ বৈশিষ্ট্য ব্যবহার করে এই FileIO লোড করতে পারে।
আইসবার্গ টেবিল বিন্যাসে ডেটা রূপান্তর করুন
আপনি আইসবার্গ টেবিল লোড করতে অ্যামাজন EMR বা অ্যাথেনাতে স্পার্ক ব্যবহার করতে পারেন। EMR স্টুডিও ওয়ার্কস্পেস নোটবুক স্পার্ক সেশনে, ডেটা লোড করতে নিম্নলিখিত কমান্ডগুলি চালান:
আপনি কোডটি চালানোর পরে, আপনার ডেটা গুদাম S3 পাথে তৈরি দুটি উপসর্গ খুঁজে পাওয়া উচিত (s3://iceberg-curated-blog-data/reviews.db/all_reviews): ডেটা এবং মেটাডেটা।
এথেনায় এসকিউএল স্টেটমেন্ট সন্নিবেশ, আপডেট এবং ডিলিট ব্যবহার করে ইনক্রিমেন্টাল ডেটা প্রসেস করুন
অ্যাথেনা হল একটি সার্ভারহীন ক্যোয়ারী ইঞ্জিন যা আপনি আইসবার্গ টেবিলের বিপরীতে পড়া, লিখতে, আপডেট করতে এবং অপ্টিমাইজেশন কাজগুলি সম্পাদন করতে ব্যবহার করতে পারেন। Apache Iceberg ডেটা লেক ফর্ম্যাট কীভাবে ক্রমবর্ধমান ডেটা ইনজেশন সমর্থন করে তা প্রদর্শন করতে, আমরা ডেটা লেকে SQL স্টেটমেন্ট সন্নিবেশ, আপডেট এবং মুছে ফেলি।
এথেনা কনসোলে নেভিগেট করুন এবং নির্বাচন করুন প্রশ্ন-সম্পাদক. যদি এটি আপনার প্রথমবার অ্যাথেনা ক্যোয়ারী এডিটর ব্যবহার করে থাকে, তাহলে আপনাকে করতে হবে ক্যোয়ারী ফলাফলের অবস্থান কনফিগার করুন আপনি আগে তৈরি S3 বালতি হতে হবে. আপনি দেখতে সক্ষম হবেন যে টেবিল reviews.all_reviews অনুসন্ধানের জন্য উপলব্ধ। আপনি সফলভাবে আইসবার্গ টেবিল লোড করেছেন তা যাচাই করতে নিম্নলিখিত ক্যোয়ারীটি চালান:
এসকিউএল বিবৃতি সন্নিবেশ, আপডেট এবং মুছে ফেলার মাধ্যমে ক্রমবর্ধমান ডেটা প্রক্রিয়া করুন:
পারফরম্যান্স টিউনিং
এই বিভাগে, আমরা Apache Iceberg পড়া এবং লেখার পারফরম্যান্স উন্নত করার জন্য বিভিন্ন উপায়ে হাঁটছি।
Apache Iceberg টেবিল বৈশিষ্ট্য কনফিগার করুন
Apache Iceberg হল একটি টেবিল বিন্যাস, এবং এটি টেবিলের বৈশিষ্ট্যগুলিকে সমর্থন করে টেবিলের আচরণ যেমন পড়া, লিখতে এবং ক্যাটালগ কনফিগার করতে। আপনি টেবিলের বৈশিষ্ট্যগুলি সামঞ্জস্য করে আইসবার্গ টেবিলে পড়া এবং লেখার কর্মক্ষমতা উন্নত করতে পারেন।
উদাহরণস্বরূপ, যদি আপনি লক্ষ্য করেন যে আপনি একটি আইসবার্গ টেবিলের জন্য অনেকগুলি ছোট ফাইল লিখেছেন, আপনি ক্যোয়ারী কর্মক্ষমতা উন্নত করতে সাহায্য করার জন্য কম কিন্তু বড় আকারের ফাইলগুলি লিখতে লিখতে ফাইলের আকার কনফিগার করতে পারেন।
| সম্পত্তি | ডিফল্ট | বিবরণ |
| write.target-file-size-bytes | 536870912 (512 MB) | এই অনেক বাইট সম্পর্কে টার্গেট করা ফাইলের আকার নিয়ন্ত্রণ করে |
টেবিল বিন্যাস পরিবর্তন করতে নিম্নলিখিত কোড ব্যবহার করুন:
বিভাজন এবং বাছাই
একটি ক্যোয়ারী দ্রুত চালানোর জন্য, কম ডেটা পড়া ভাল। আইসবার্গ এটি লেখার সময় ক্যাপচার করা সমৃদ্ধ মেটাডেটাগুলির সুবিধা নেয় এবং স্ক্যান পরিকল্পনা, পার্টিশন, ছাঁটাই এবং কলাম-স্তরের পরিসংখ্যান যেমন ন্যূনতম/সর্বোচ্চ মানগুলির মতো ডেটা ফাইলগুলি এড়িয়ে যাওয়ার জন্য কৌশলগুলি সহজ করে দেয় যেগুলির ম্যাচ রেকর্ড নেই৷ আইসবার্গে কীভাবে কোয়েরি স্ক্যান পরিকল্পনা এবং পার্টিশন কাজ করে এবং আমরা ক্যোয়ারী কর্মক্ষমতা উন্নত করতে কীভাবে সেগুলি ব্যবহার করি তা আমরা আপনাকে নিয়ে চলেছি।
প্রশ্ন স্ক্যান পরিকল্পনা
একটি প্রদত্ত প্রশ্নের জন্য, একটি ক্যোয়ারী ইঞ্জিনের প্রথম ধাপ হল স্ক্যান পরিকল্পনা, যা একটি প্রশ্নের জন্য প্রয়োজনীয় একটি টেবিলে ফাইলগুলি খুঁজে বের করার প্রক্রিয়া। একটি আইসবার্গ টেবিলে পরিকল্পনা করা খুবই কার্যকর, কারণ আইসবার্গের সমৃদ্ধ মেটাডেটা ব্যবহার করা যেতে পারে মেটাডেটা ফাইলগুলিকে ছাঁটাই করতে যা প্রয়োজন নেই, ডেটা ফাইলগুলি ফিল্টার করার পাশাপাশি যেগুলিতে মিলিত ডেটা নেই৷ আমাদের পরীক্ষায়, আমরা লক্ষ্য করেছি যে আইসবার্গ ফর্ম্যাটে রূপান্তর করার আগে আসল ডেটার তুলনায় একটি আইসবার্গ টেবিলে প্রদত্ত প্রশ্নের জন্য অ্যাথেনা 50% বা কম ডেটা স্ক্যান করেছে৷
ফিল্টারিং দুই ধরনের আছে:
- মেটাডেটা ফিল্টারিং - আইসবার্গ একটি স্ন্যাপশটে ফাইলগুলি ট্র্যাক করতে দুটি স্তরের মেটাডেটা ব্যবহার করে: ম্যানিফেস্ট তালিকা এবং ম্যানিফেস্ট ফাইল৷ এটি প্রথমে ম্যানিফেস্ট তালিকা ব্যবহার করে, যা ম্যানিফেস্ট ফাইলগুলির একটি সূচী হিসাবে কাজ করে। পরিকল্পনার সময়, সমস্ত ম্যানিফেস্ট ফাইল না পড়েই আইসবার্গ ফিল্টার ম্যানিফেস্ট তালিকায় পার্টিশন মান পরিসর ব্যবহার করে প্রকাশ করে। তারপরে এটি ডেটা ফাইলগুলি পেতে নির্বাচিত ম্যানিফেস্ট ফাইলগুলি ব্যবহার করে।
- ডেটা ফিল্টারিং – ম্যানিফেস্ট ফাইলের তালিকা নির্বাচন করার পর, আইসবার্গ ডেটা ফাইল ফিল্টার করতে ম্যানিফেস্ট ফাইলে সঞ্চিত প্রতিটি ডেটা ফাইলের জন্য পার্টিশন ডেটা এবং কলাম-স্তরের পরিসংখ্যান ব্যবহার করে। পরিকল্পনা করার সময়, ক্যোয়ারী প্রিডিকেটগুলি পার্টিশন ডেটার পূর্বনির্ধারণে রূপান্তরিত হয় এবং ডেটা ফাইলগুলি ফিল্টার করতে প্রথমে প্রয়োগ করা হয়। তারপর, কলামের পরিসংখ্যান যেমন কলাম-স্তরের মান গণনা, শূন্য গণনা, নিম্ন সীমা এবং উপরের সীমাগুলি ডেটা ফাইলগুলিকে ফিল্টার করতে ব্যবহৃত হয় যা ক্যোয়ারী প্রিডিকেটের সাথে মেলে না। পরিকল্পনার সময় ডেটা ফাইলগুলি ফিল্টার করার জন্য উপরের এবং নীচের সীমানা ব্যবহার করে, আইসবার্গ ক্যোয়ারী কর্মক্ষমতা ব্যাপকভাবে উন্নত করে।
বিভাজন এবং বাছাই
পার্টিশনিং হল একই কী কলামের মানগুলিকে একসাথে লিখিতভাবে গোষ্ঠীভুক্ত করার একটি উপায়। বিভাজন করার সুবিধা হল দ্রুত ক্যোয়ারী যা শুধুমাত্র ডেটার কিছু অংশ অ্যাক্সেস করে, যেমনটি আগে ক্যোয়ারী স্ক্যান প্ল্যানিং: ডেটা ফিল্টারিং-এ ব্যাখ্যা করা হয়েছে। আইসবার্গ লুকানো পার্টিশনকে সমর্থন করে পার্টিশনকে সহজ করে তোলে, যেভাবে আইসবার্গ একটি কলামের মান গ্রহণ করে এবং ঐচ্ছিকভাবে এটিকে রূপান্তর করে পার্টিশন মান তৈরি করে।
আমাদের ব্যবহারের ক্ষেত্রে, আমরা প্রথমে আইসবার্গ টেবিলে নিম্নলিখিত ক্যোয়ারীটি চালাই যা বিভাজিত নয়। তারপরে আমরা আইসবার্গ টেবিলটিকে পর্যালোচনার বিভাগ দ্বারা বিভাজন করি, যা রেকর্ডগুলি ফিল্টার করার জন্য WHERE শর্তে ব্যবহার করা হবে। পার্টিশনের সাথে, ক্যোয়ারী অনেক কম ডেটা স্ক্যান করতে পারে। নিম্নলিখিত কোড দেখুন:
পারফরম্যান্সের পার্থক্য দেখতে অ-বিভাজনকৃত all_reviews টেবিল বনাম পার্টিশন করা টেবিলে নিম্নলিখিত নির্বাচন বিবৃতিটি চালান:
নিম্নলিখিত সারণীটি প্রায় 50% কর্মক্ষমতা উন্নতি এবং 70% কম ডেটা স্ক্যান করা সহ ডেটা পার্টিশনের কর্মক্ষমতা উন্নতি দেখায়।
| ডেটাসেটের নাম | অ-বিভাজনকৃত ডেটাসেট | বিভাজিত ডেটাসেট |
| রানটাইম (সেকেন্ড) | 8.20 | 4.25 |
| ডেটা স্ক্যান করা হয়েছে (MB) | 131.55 | 33.79 |
উল্লেখ্য যে রানটাইম হল আমাদের টেস্টে একাধিক রান সহ গড় রানটাইম।
আমরা পার্টিশনের পরে ভাল কর্মক্ষমতা উন্নতি দেখেছি। যাইহোক, আইসবার্গ ম্যানিফেস্ট ফাইল থেকে কলাম-স্তরের পরিসংখ্যান ব্যবহার করে এটি আরও উন্নত করা যেতে পারে। কলাম-স্তরের পরিসংখ্যানগুলি কার্যকরভাবে ব্যবহার করার জন্য, আপনি ক্যোয়ারী প্যাটার্নের উপর ভিত্তি করে আপনার রেকর্ডগুলি আরও বাছাই করতে চান। কলামগুলি ব্যবহার করে সমগ্র ডেটাসেট বাছাই করা যা প্রায়শই কোয়েরিতে ব্যবহৃত হয় ডেটাকে এমনভাবে সাজানো হবে যাতে প্রতিটি ডেটা ফাইল নির্দিষ্ট কলামগুলির জন্য একটি অনন্য মানের সাথে শেষ হয়। যদি এই কলামগুলি ক্যোয়ারী অবস্থায় ব্যবহার করা হয়, তাহলে এটি ক্যোয়ারী ইঞ্জিনগুলিকে ডেটা ফাইলগুলি এড়িয়ে যেতে দেয়, যার ফলে আরও দ্রুত ক্যোয়ারীগুলি সক্ষম হয়৷
কপি-অন-রাইট বনাম রিড-অন-মার্জ
ডেটা লেকের আইসবার্গ টেবিলে আপডেট এবং মুছে ফেলার সময়, আইসবার্গ টেবিল বৈশিষ্ট্য দ্বারা সংজ্ঞায়িত দুটি পদ্ধতি রয়েছে:
- অনুরূপ লিখ - এই পদ্ধতির সাথে, যখন আইসবার্গ টেবিলে পরিবর্তন হয়, হয় আপডেট বা মুছে ফেলা হয়, প্রভাবিত রেকর্ডগুলির সাথে সম্পর্কিত ডেটা ফাইলগুলি সদৃশ এবং আপডেট করা হবে। নকল করা ডেটা ফাইলগুলি থেকে রেকর্ডগুলি আপডেট করা হবে বা মুছে ফেলা হবে। আইসবার্গ টেবিলের একটি নতুন স্ন্যাপশট তৈরি করা হবে এবং ডেটা ফাইলের নতুন সংস্করণের দিকে নির্দেশ করা হবে। এটি সামগ্রিক লেখাকে ধীর করে তোলে। এমন পরিস্থিতি হতে পারে যে সমসাময়িক লেখাগুলি দ্বন্দ্বের সাথে প্রয়োজন তাই পুনরায় চেষ্টা করতে হবে, যা লেখার সময়কে আরও বাড়িয়ে দেয়। অন্যদিকে, ডেটা পড়ার সময়, কোনও অতিরিক্ত প্রক্রিয়ার প্রয়োজন নেই। প্রশ্নটি ডেটা ফাইলের সর্বশেষ সংস্করণ থেকে ডেটা পুনরুদ্ধার করবে।
- মার্জ-অন-রিড - এই পদ্ধতির সাথে, যখন আইসবার্গ টেবিলে আপডেট বা মুছে ফেলা হয়, বিদ্যমান ডেটা ফাইলগুলি পুনরায় লেখা হবে না; পরিবর্তে পরিবর্তনগুলি ট্র্যাক করতে নতুন মুছে ফেলা ফাইল তৈরি করা হবে। মুছে ফেলার জন্য, মুছে ফেলা রেকর্ডগুলির সাথে একটি নতুন মুছে ফেলা ফাইল তৈরি করা হবে। আইসবার্গ টেবিল পড়ার সময়, মুছে ফেলার রেকর্ডগুলি ফিল্টার করতে পুনরুদ্ধার করা ডেটাতে মুছে ফেলা ফাইলটি প্রয়োগ করা হবে। আপডেটের জন্য, আপডেট করা রেকর্ডগুলিকে মুছে ফেলা হিসাবে চিহ্নিত করতে একটি নতুন মুছে ফেলা ফাইল তৈরি করা হবে। তারপর সেই রেকর্ডগুলির জন্য একটি নতুন ফাইল তৈরি করা হবে তবে আপডেট করা মান সহ। আইসবার্গ টেবিল পড়ার সময়, সর্বশেষ পরিবর্তনগুলি প্রতিফলিত করতে এবং সঠিক ফলাফল তৈরি করতে পুনরুদ্ধার করা ডেটাতে মুছে ফেলা এবং নতুন ফাইল উভয়ই প্রয়োগ করা হবে। সুতরাং, পরবর্তী যেকোন প্রশ্নের জন্য, ডেটা ফাইলগুলিকে মুছে ফেলা এবং নতুন ফাইলগুলির সাথে একত্রিত করার জন্য একটি অতিরিক্ত পদক্ষেপ ঘটবে, যা সাধারণত ক্যোয়ারী সময় বৃদ্ধি করবে৷ অন্যদিকে, লেখাগুলি দ্রুত হতে পারে কারণ বিদ্যমান ডেটা ফাইলগুলি পুনরায় লেখার প্রয়োজন নেই।
দুটি পদ্ধতির প্রভাব পরীক্ষা করতে, আপনি আইসবার্গ টেবিল বৈশিষ্ট্য সেট করতে নিম্নলিখিত কোড চালাতে পারেন:
কপি-অন-রাইট বনাম মার্জ-অন-রিডের জন্য রানটাইম পার্থক্য দেখাতে অ্যাথেনায় আপডেট চালান, মুছুন এবং SQL স্টেটমেন্ট নির্বাচন করুন:
নিম্নলিখিত সারণী কোয়েরি রানটাইম সারসংক্ষেপ.
| প্রশ্ন | অনুরূপ লিখ | মার্জ-অন-রিড | ||||
| হালনাগাদ | মুছে ফেলা | নির্বাচন | হালনাগাদ | মুছে ফেলা | নির্বাচন | |
| রানটাইম (সেকেন্ড) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| ডেটা স্ক্যান করা হয়েছে (এমবি) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
উল্লেখ্য যে রানটাইম হল আমাদের টেস্টে একাধিক রান সহ গড় রানটাইম।
আমাদের পরীক্ষার ফলাফলগুলি দেখায়, দুটি পদ্ধতিতে সর্বদা ট্রেড-অফ থাকে। কোন পদ্ধতি ব্যবহার করবেন তা আপনার ব্যবহারের ক্ষেত্রে নির্ভর করে। সংক্ষেপে, বিবেচ্য বিষয়গুলি পঠন বনাম লেখার দেরীতে নেমে আসে। আপনি নিম্নলিখিত টেবিলটি উল্লেখ করতে পারেন এবং সঠিক পছন্দ করতে পারেন।
| . | অনুরূপ লিখ | মার্জ-অন-রিড |
| ভালো দিক | দ্রুত পড়া | দ্রুত লেখেন |
| মন্দ দিক | দামী লেখা | পড়ার ক্ষেত্রে উচ্চতর বিলম্ব |
| কখন ব্যবহার করতে হবে | ঘন ঘন পড়া, বিরল আপডেট এবং মুছে ফেলা বা বড় ব্যাচ আপডেটের জন্য ভাল | ঘন ঘন আপডেট এবং মুছে ফেলার সাথে টেবিলের জন্য ভাল |
ডেটা কম্প্যাকশন
আপনার ডেটা ফাইলের আকার ছোট হলে, আপনি একটি আইসবার্গ টেবিলে হাজার হাজার বা লক্ষাধিক ফাইলের সাথে শেষ করতে পারেন। এটি নাটকীয়ভাবে I/O ক্রিয়াকলাপ বাড়ায় এবং প্রশ্নগুলিকে ধীর করে দেয়। উপরন্তু, আইসবার্গ একটি ডেটাসেটে প্রতিটি ডেটা ফাইল ট্র্যাক করে। আরও ডেটা ফাইলগুলি আরও মেটাডেটা নিয়ে যায়। এর ফলে মেটাডেটা ফাইল পড়ার উপর ওভারহেড এবং I/O অপারেশন বৃদ্ধি পায়। ক্যোয়ারী কর্মক্ষমতা উন্নত করার জন্য, ছোট ডেটা ফাইলগুলিকে বড় ডেটা ফাইলগুলিতে কমপ্যাক্ট করার সুপারিশ করা হয়৷
আইসবার্গ টেবিলে রেকর্ড আপডেট এবং মুছে ফেলার সময়, যদি রিড-অন-মার্জ পদ্ধতি ব্যবহার করা হয়, আপনি অনেক ছোট মুছে ফেলা বা নতুন ডেটা ফাইলের সাথে শেষ হতে পারেন। চলমান কমপ্যাকশন এই সমস্ত ফাইলকে একত্রিত করবে এবং ডেটা ফাইলের একটি নতুন সংস্করণ তৈরি করবে। এটি পড়ার সময় তাদের পুনর্মিলনের প্রয়োজনীয়তা দূর করে। লেখার দ্রুত গতি বজায় রেখে যতটা সম্ভব কম পড়াকে প্রভাবিত করার জন্য নিয়মিত কমপ্যাকশন কাজ করার পরামর্শ দেওয়া হয়।
নিম্নলিখিত ডেটা কমপ্যাকশন কমান্ডটি চালান, তারপর এথেনা থেকে নির্বাচন ক্যোয়ারী চালান:
নিচের টেবিলে রানটাইম আগের বনাম ডেটা কমপ্যাকশনের পরে তুলনা করা হয়েছে। আপনি প্রায় 40% কর্মক্ষমতা উন্নতি দেখতে পারেন।
| প্রশ্ন | ডেটা কমপ্যাকশনের আগে | ডেটা কমপ্যাকশনের পরে |
| রানটাইম (সেকেন্ড) | 97.75 | 32.676 সেকেন্ড |
| ডেটা স্ক্যান করা হয়েছে (এমবি) | 137.16 M | 189.19 M |
উল্লেখ্য যে নির্বাচন করা প্রশ্নগুলি তে চলেছিল all_reviews আপডেট এবং ডিলিট অপারেশনের পরে টেবিল, ডেটা কমপ্যাকশনের আগে এবং পরে। রানটাইম হল আমাদের টেস্টে একাধিক রান সহ গড় রানটাইম।
পরিষ্কার কর
আপনি ব্যবহারের ক্ষেত্রে সঞ্চালনের জন্য সমাধানের ওয়াকথ্রু অনুসরণ করার পরে, আপনার সংস্থানগুলি পরিষ্কার করতে এবং আরও খরচ এড়াতে নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- এথেনা থেকে AWS আঠালো টেবিল এবং ডাটাবেস ফেলে দিন বা আপনার নোটবুকে নিম্নলিখিত কোডটি চালান:
- EMR স্টুডিও কনসোলে, নির্বাচন করুন ওয়ার্কস্পেস নেভিগেশন ফলকে।
- আপনার তৈরি করা ওয়ার্কস্পেস নির্বাচন করুন এবং নির্বাচন করুন মুছে ফেলা.
- EMR কনসোলে, নেভিগেট করুন স্টুডিওর পাতা.
- আপনার তৈরি করা স্টুডিও নির্বাচন করুন এবং নির্বাচন করুন মুছে ফেলা.
- EMR কনসোলে, নির্বাচন করুন ক্লাস্টার নেভিগেশন ফলকে।
- ক্লাস্টার নির্বাচন করুন এবং নির্বাচন করুন ফুরান.
- এই পোস্টের পূর্বশর্তের অংশ হিসাবে আপনি যে S3 বালতি এবং অন্য কোনও সংস্থান তৈরি করেছেন তা মুছুন।
উপসংহার
এই পোস্টে, আমরা অ্যাপাচি আইসবার্গ ফ্রেমওয়ার্ক প্রবর্তন করেছি এবং কীভাবে এটি একটি আধুনিক ডেটা লেকে আমাদের কিছু চ্যালেঞ্জের সমাধান করতে সহায়তা করে। তারপরে আমরা আপনাকে অ্যাপাচি আইসবার্গ ব্যবহার করে ডেটা লেকে ক্রমবর্ধমান ডেটা প্রক্রিয়া করার একটি সমাধান দিয়েছি। অবশেষে, আমাদের ব্যবহারের ক্ষেত্রে পড়ার এবং লেখার পারফরম্যান্স উন্নত করতে পারফরম্যান্স টিউনিংয়ে আমরা গভীরভাবে ডুব দিয়েছিলাম।
আমরা আশা করি যে আপনি আপনার ডেটা লেক সমাধানে Apache Iceberg গ্রহণ করতে চান কিনা তা সিদ্ধান্ত নেওয়ার জন্য এই পোস্টটি আপনার জন্য কিছু দরকারী তথ্য সরবরাহ করবে।
লেখক সম্পর্কে
 ফ্লোরা উ AWS ডেটা ল্যাবের একজন সিনিয়র রেসিডেন্ট আর্কিটেক্ট। তিনি এন্টারপ্রাইজ গ্রাহকদের ডেটা বিশ্লেষণ কৌশল তৈরি করতে এবং তাদের ব্যবসার ফলাফলগুলিকে ত্বরান্বিত করতে সমাধান তৈরি করতে সহায়তা করেন। তার অবসর সময়ে, তিনি টেনিস খেলা, সালসা নাচ এবং ভ্রমণ উপভোগ করেন।
ফ্লোরা উ AWS ডেটা ল্যাবের একজন সিনিয়র রেসিডেন্ট আর্কিটেক্ট। তিনি এন্টারপ্রাইজ গ্রাহকদের ডেটা বিশ্লেষণ কৌশল তৈরি করতে এবং তাদের ব্যবসার ফলাফলগুলিকে ত্বরান্বিত করতে সমাধান তৈরি করতে সহায়তা করেন। তার অবসর সময়ে, তিনি টেনিস খেলা, সালসা নাচ এবং ভ্রমণ উপভোগ করেন।
 ড্যানিয়েল লি অ্যামাজন ওয়েব সার্ভিসেসের একজন সিনিয়র সলিউশন আর্কিটেক্ট। তিনি গ্রাহকদের ক্লাউড পরিষেবা এবং কৌশল বিকাশ, গ্রহণ এবং বাস্তবায়নে সহায়তা করার দিকে মনোনিবেশ করেন। কাজ না করলে, তিনি তার পরিবারের সাথে বাইরে সময় কাটাতে পছন্দ করেন।
ড্যানিয়েল লি অ্যামাজন ওয়েব সার্ভিসেসের একজন সিনিয়র সলিউশন আর্কিটেক্ট। তিনি গ্রাহকদের ক্লাউড পরিষেবা এবং কৌশল বিকাশ, গ্রহণ এবং বাস্তবায়নে সহায়তা করার দিকে মনোনিবেশ করেন। কাজ না করলে, তিনি তার পরিবারের সাথে বাইরে সময় কাটাতে পছন্দ করেন।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- সক্ষম
- সম্পর্কে
- উপরে
- দ্রুততর করা
- প্রবেশ
- অ্যাক্সেস ম্যানেজমেন্ট
- কর্ম
- কাজ
- যোগ
- অতিরিক্ত
- ঠিকানা
- ঠিকানাগুলি
- যোগ করে
- পোষ্যপুত্র গ্রহণ করা
- সুবিধা
- পর
- বিরুদ্ধে
- সব
- অনুমতি
- সর্বদা
- মর্দানী স্ত্রীলোক
- আমাজন ইএমআর
- অ্যামাজন ওয়েব সার্ভিসেস
- বিশ্লেষণমূলক
- বৈশ্লেষিক ন্যায়
- এবং
- ঘোষিত
- এ্যাপাচি
- অ্যাপ্লিকেশন
- ফলিত
- অভিগমন
- পন্থা
- যথাযথ
- স্থাপত্য
- যুক্ত
- প্রমাণীকরণ
- উপস্থিতি
- সহজলভ্য
- গড়
- এড়াতে
- ডেস্কটপ AWS
- এডাব্লুএস আঠালো
- ভিত্তি
- কারণ
- পরিণত
- আগে
- সুবিধা
- উত্তম
- মধ্যে
- বড়
- বুটস্ট্র্যাপ
- নির্মাণ করা
- ভবন
- ব্যবসা
- ক্যাচ
- ক্যাপচার
- কেস
- মামলা
- তালিকা
- ক্যাটালগ
- বিভাগ
- চ্যালেঞ্জ
- পরিবর্তন
- পরিবর্তন
- চেক
- পছন্দ
- বেছে নিন
- শ্রেণীবিন্যাস
- মেঘ
- মেঘ পরিষেবা
- গুচ্ছ
- কোড
- স্তম্ভ
- কলাম
- মেশা
- আসা
- সমর্পণ করা
- তুলনা
- সম্পূর্ণ
- গনা
- সহগামী
- শর্ত
- কনফিগারেশনের
- বিবেচ্য বিষয়
- কনসোল
- পরিবর্তন
- ধর্মান্তরিত
- সাশ্রয়ের
- খরচ
- পারা
- সৃষ্টি
- নির্মিত
- সৃষ্টি
- প্লেলিস্টে যোগ করা
- বর্তমান
- ক্রেতা
- গ্রাহকদের
- নাট্য
- ড্যাশবোর্ড
- উপাত্ত
- ডেটা বিশ্লেষণ
- ডেটা লেক
- তথ্য প্রক্রিয়াজাতকরণ
- তথ্য গুদাম
- ডেটাবেস
- ডেটাসেট
- গভীর
- গভীর ডুব
- ডিফল্ট
- সংজ্ঞায়িত
- ডেমো
- প্রদর্শন
- নির্ভর করে
- পরিকল্পিত
- বিস্তারিত
- বিকাশ
- উন্নয়ন
- পার্থক্য
- বিভিন্ন
- আলোচনা করা
- Dont
- নিচে
- নাটকীয়ভাবে
- ড্রপ
- সময়
- প্রতি
- পূর্বে
- গোড়ার দিকে
- সম্পাদক
- কার্যকরীভাবে
- দক্ষ
- পারেন
- ঘটিয়েছে
- সক্ষম করা
- সক্রিয়
- প্রান্ত
- ইঞ্জিন
- ইঞ্জিন
- প্রবেশ করান
- উদ্যোগ
- এন্টারপ্রাইজ গ্রাহকরা
- থার (eth)
- এমন কি
- বিবর্তন
- গজান
- নব্য
- উদাহরণ
- বিদ্যমান
- বিদ্যমান
- ব্যাখ্যা
- এক্সটেনশন
- অতিরিক্ত
- সমাধা
- পরিবার
- দ্রুত
- দ্রুত
- বৈশিষ্ট্য
- ব্যক্তিত্ব
- ফাইল
- নথি পত্র
- ছাঁকনি
- ফিল্টারিং
- ফিল্টার
- পরিশেষে
- আবিষ্কার
- প্রথম
- প্রথমবার
- গুরুত্ত্ব
- অনুসরণ করা
- অনুসরণ
- বিন্যাস
- ফ্রেমওয়ার্ক
- ঘন
- থেকে
- অধিকতর
- তদ্ব্যতীত
- সাধারণ
- উত্পন্ন
- পাওয়া
- প্রদত্ত
- Goes
- ভাল
- অতিশয়
- গ্রুপ
- হাত
- ঘটা
- সাহায্য
- সাহায্য
- সাহায্য
- গোপন
- যাজকতন্ত্র
- উচ্চস্তর
- উচ্চ পারদর্শিতা
- উচ্চ দক্ষতা
- মধুচক্র
- আশা
- কিভাবে
- কিভাবে
- যাহোক
- এইচটিএমএল
- HTTPS দ্বারা
- আমি
- পরিচয়
- পরিচয় এবং অ্যাক্সেস পরিচালনা
- প্রভাব
- প্রভাব
- বাস্তবায়ন
- বাস্তবায়ন
- বাস্তবায়ন
- উন্নত করা
- উন্নত
- উন্নতি
- উন্নত
- in
- সুদ্ধ
- বৃদ্ধি
- বর্ধিত
- বৃদ্ধি
- সূচক
- স্বতন্ত্র
- তথ্য
- ইনস্টল
- পরিবর্তে
- ইন্টিগ্রেশন
- উপস্থাপিত
- বিচ্ছিন্ন
- IT
- জানুয়ারী
- জবস
- চাবি
- গবেষণাগার
- হ্রদ
- বড়
- বৃহত্তর
- অদৃশ্যতা
- সর্বশেষ
- সর্বশেষ রিলিজ
- স্তর
- স্তর
- নেতৃত্ব
- মাত্রা
- LIMIT টি
- লাইন
- তালিকা
- সামান্য
- বোঝা
- অবস্থান
- করা
- তৈরি করে
- ব্যবস্থাপনা
- অনেক
- ছাপ
- নগরচত্বর
- ম্যাচ
- ম্যাচিং
- মার্জ
- মেটাডাটা
- হতে পারে
- লক্ষ লক্ষ
- আধুনিক
- অধিক
- পদক্ষেপ
- বহু
- নাম
- নামে
- নেভিগেট করুন
- ন্যাভিগেশন
- প্রয়োজন
- প্রয়োজন
- চাহিদা
- নতুন
- নোটবই
- লক্ষ্য
- খোলা
- অপারেশন
- অপারেশনস
- অপ্টিমাইজেশান
- অপ্টিমিজ
- ক্রম
- মূল
- অন্যান্য
- বিদেশে
- সামগ্রিক
- নিজের
- শার্সি
- অংশ
- পথ
- নিদর্শন
- সম্পাদন করা
- কর্মক্ষমতা
- শারীরিক
- পরিকল্পনা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- কেলি
- প্লাগ লাগানো
- পয়েন্ট
- জনপ্রিয়
- সম্ভব
- পোস্ট
- চালিত
- পূর্বশর্ত
- পদ্ধতি
- প্রক্রিয়া
- প্রক্রিয়াজাতকরণ
- উৎপাদন করা
- বৈশিষ্ট্য
- সম্পত্তি
- প্রদান
- উপলব্ধ
- প্রদানের
- বিধান
- পরিসর
- কাঁচা
- মূল তথ্য
- পড়া
- পড়া
- বাস্তব
- সম্প্রতি
- সুপারিশ করা
- রেকর্ড
- প্রতিফলিত করা
- এলাকা
- খাতাপত্র
- নিয়মিত
- মুক্তি
- মুক্ত
- অবশিষ্ট
- প্রয়োজনীয়
- প্রয়োজন
- Resources
- ফল
- ফলাফল
- পর্যালোচনা
- ধনী
- ভূমিকা
- শিকড়
- চালান
- দৌড়
- একই
- স্ক্যান
- সেকেন্ড
- অধ্যায়
- নিরাপত্তা
- নির্বাচিত
- নির্বাচন
- Serverless
- সেবা
- সেবা
- সেশন
- সেট
- সেট
- বিন্যাস
- সেটিংস
- উচিত
- প্রদর্শনী
- শো
- সহজ
- পরিস্থিতিতে
- আয়তন
- গতি
- ছোট
- স্ন্যাপশট
- So
- সফটওয়্যার
- সমাধান
- সলিউশন
- কিছু
- স্ফুলিঙ্গ
- নির্দিষ্ট
- স্পীড
- খরচ
- এসকিউএল
- শুরু হচ্ছে
- রাষ্ট্র
- বিবৃতি
- বিবৃতি
- পরিসংখ্যান
- ধাপ
- প্রারম্ভিক ব্যবহারের নির্দেশাবলী
- এখনো
- স্টোরেজ
- দোকান
- সঞ্চিত
- দোকান
- কৌশল
- কৌশল
- কাঠামোবদ্ধ
- কাঠামোগত এবং কাঠামোগত ডেটা
- চিত্রশালা
- সাবনেট
- পরবর্তী
- সফলভাবে
- এমন
- যথেষ্ট
- সংক্ষিপ্তসার
- সমর্থন
- সমর্থিত
- সমর্থক
- সমর্থন
- টেবিল
- লাগে
- গ্রহণ
- লক্ষ্য
- কাজ
- প্রযুক্তি
- টেনিস
- পরীক্ষা
- পরীক্ষামূলক
- পরীক্ষা
- সার্জারির
- তথ্য
- রাষ্ট্র
- তাদের
- যার ফলে
- হাজার হাজার
- তিন
- দ্বারা
- সময়
- সময় ভ্রমণ
- থেকে
- একসঙ্গে
- অত্যধিক
- সরঞ্জাম
- শীর্ষ
- মোট
- পথ
- লেনদেন
- রূপান্তর
- ভ্রমণ
- ভ্রমণ
- চালু
- ধরনের
- অধীনে
- অনন্য
- আপডেট
- আপডেট
- আপডেট
- আপডেট
- URL টি
- ব্যবহার
- ব্যবহার ক্ষেত্রে
- ব্যবহারকারী
- সাধারণত
- Val
- মূল্য
- মানগুলি
- যাচাই
- সংস্করণ
- পদচারণা
- , walkthrough
- গুদাম
- ঘড়ির
- উপায়
- ওয়েব
- ওয়েব সার্ভিস
- কি
- কিনা
- যে
- যখন
- ব্যাপক
- প্রশস্ত পরিসর
- ইচ্ছা
- ছাড়া
- হয়া যাই ?
- কাজ
- কাজ
- would
- লেখা
- লেখা
- আপনার
- zephyrnet