Finansielle markedsdeltagere står over for en overbelastning af information, der påvirker deres beslutninger, og sentimentanalyse skiller sig ud som et nyttigt værktøj til at hjælpe med at adskille de relevante og meningsfulde fakta og tal. Den samme nyhed kan dog have en positiv eller negativ indflydelse på aktiekurserne, hvilket er en udfordring for denne opgave. Sentimentanalyse og andre NLP-opgaver starter ofte med præ-trænede NLP-modeller og implementerer finjustering af hyperparametrene for at tilpasse modellen til ændringer i miljøet. Transformatorbaserede sprogmodeller såsom BERT (Tovejstransformere til sprogforståelse) har evnen til at fange ord eller sætninger inden for en større kontekst af data og give mulighed for klassificering af nyhedsstemningen givet den aktuelle tilstand i verden. For at tage højde for ændringer i det økonomiske miljø skal modellen finjusteres igen, når dataene begynder at glide, eller modellens forudsigelsesnøjagtighed begynder at blive forringet.
Hyperparameteroptimering er meget beregningsmæssigt krævende for modeller med dyb læring. Den arkitektoniske kompleksitet øges, når en enkelt modeltræningskørsel kræver flere GPU'er. I dette indlæg bruger vi Vægte og skævheder (W&B) Fejefunktion og Amazon Elastic Kubernetes Service (Amazon EKS) for at løse disse udfordringer. Amazon EKS er en meget tilgængelig administreret Kubernetes-tjeneste, der automatisk skalerer forekomster baseret på belastning og er velegnet til at køre distribuerede træningsbelastninger.
I vores løsning implementerer vi en hyperparameter-gittersøgning på en EKS-klynge til tuning af en bert-baseret model til klassificering af positiv eller negativ stemning for aktiemarkedsdataoverskrifter. Koden kan findes på GitHub repo.
Løsningsoversigt
I dette indlæg præsenterer vi et overblik over løsningsarkitekturen og diskuterer dens nøglekomponenter. Mere specifikt diskuterer vi følgende:
- Sådan opsætter du en EKS-klynge med et skalerbart filsystem
- Sådan træner du PyTorch-modeller ved hjælp af TorchElastic
- Hvorfor W&B-platformen er det rigtige valg til eksperimentering med maskinlæring (ML) og søgning i hyperparametergitter
- En løsningsarkitektur, der integrerer W&B med EKS og TorchElastic
Forudsætninger
For at følge med i løsningen bør du have en forståelse af PyTorch, distribueret data parallel (DDP) træning og Kubernetes.
Opsæt en EKS-klynge med et skalerbart filsystem
En måde at komme i gang med Amazon EKS er aws-do-eks, som er et open source-projekt, der tilbyder brugervenlige og konfigurerbare scripts og værktøjer til at levere EKS-klynger og køre distribuerede træningsjob. Dette projekt er bygget efter principperne i Lav Framework: enkelhed, intuitivitet og produktivitet. En ønsket klynge kan simpelthen konfigureres ved hjælp af eks.konf fil og startes ved at køre eks-create.sh manuskript. Detaljerede instruktioner findes i GitHub-lageret for aws-do-eks.
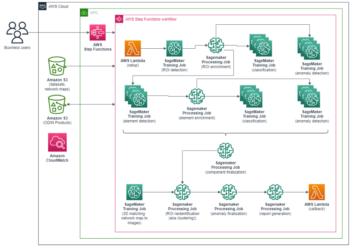
Følgende diagram illustrerer EKS-klyngearkitekturen.
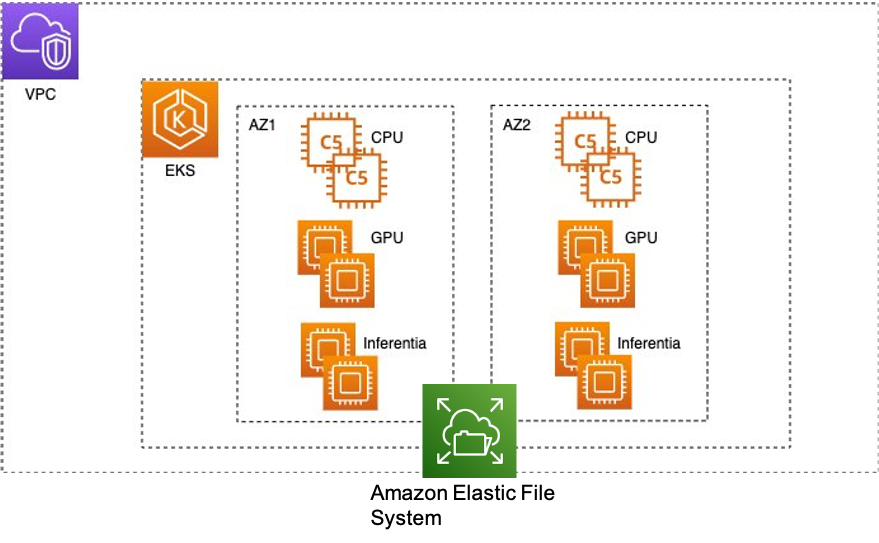
Nogle nyttige tips, når du opretter en EKS-klynge med aws-do-eks:
- Sørg
CLUSTER_REGIONin conf er det samme som din standardregion, når du laver aws-konfiguration. - Oprettelse af en EKS-klynge kan tage op til 30 minutter. Vi anbefalede at oprette en aws-do-eks container som GitHub repo foreslår for at sikre konsistens og enkelhed, fordi containeren har alle de nødvendige værktøjer såsom kubectl, aws cli, eksctl og så videre. Så kan du løbe ind i containeren og løbe
./eks-create.shfor at starte klyngen. - Medmindre du angiver Spot-forekomster i conf, oprettes forekomster efter behov.
- Du kan angive brugerdefinerede AMI'er eller specifikke zoner for forskellige instanstyper.
-
./eks-create.shscript vil oprette VPC, undernet, autoskaleringsgrupper, EKS-klyngen, dens noder og eventuelle andre nødvendige ressourcer. Dette vil oprette en instans af hver type. Derefter./eks-scale.shvil skalere dine nodegrupper til de ønskede størrelser. - Efter at klyngen er oprettet, AWS identitets- og adgangsstyring (IAM)-roller genereres med Amazon EKS-relaterede politikker for hver instanstype. Politikker kan være nødvendige for at få adgang Amazon Simple Storage Service (Amazon S3) eller andre tjenester med disse roller.
- Følgende er almindelige årsager til, at
./eks-create.shscript kan give en fejl:- Nodegrupper bliver ikke oprettet på grund af utilstrækkelig kapacitet. Tjek forekomstens tilgængelighed i den anmodede region og dine kapacitetsgrænser.
- En specifik instanstype er muligvis ikke tilgængelig eller understøttet i en given zone.
- EKS-klyngeoprettelse AWS CloudFormation stakke slettes ikke korrekt. Tjek de aktive CloudFormation-stakke for at se, om sletningen af stak er mislykkedes.
Der er behov for et skalerbart delt filsystem, så flere beregningsknuder i EKS-klyngen kan få adgang samtidigt. I dette indlæg bruger vi Amazon Elastic File System (Amazon EFS) som et delt filsystem, der er elastisk og giver høj gennemstrømning. Manuskripterne i aws-do-eks/Container-Root/eks/deployment/csi/ give instruktioner til at montere Amazon EFS på en EKS-klynge. Efter at klyngen er oprettet, og nodegrupperne er skaleret til det ønskede antal forekomster, kan du se de kørende pods med kubectl get pod -A. Her er aws-node-xxxx, kube-proxy-xxxxog nvidia-device-plugin-daemonset-xxxx pods kører på hver af de tre compute noder, og vi har en systemnode i kube-systemets navneområde.
Før du fortsætter med at oprette og montere en EFS-diskenhed, skal du sørge for, at du er i kube-systemets navneområde. Hvis ikke, kan du ændre det med følgende kode:
Se derefter de løbende pods med kubectl get pod -A.

efs-create.sh script vil oprette EFS-volumen og montere mål i hvert undernet og den vedvarende volumen. Så vil en ny EFS-volumen være synlig på Amazon EFS-konsollen.
Kør derefter ./deploy.sh script for at få EFS-filsystem-id'et, implementere en EFS-CSI-driver på hver nodegruppe og montere den vedvarende EFS-diskenhed ved hjælp af efs-sc.yaml , efs-pv.yaml manifest filer. Du kan validere, om en vedvarende volumen er monteret ved at kontrollere kubectl get pv. Du kan også løbe kubectl apply -f efs-share-test.yaml, som vil spinne en efs-share-test pod op i standardnavneområdet. Dette er en testpod, der skriver "hej fra EFS" i /shared-efs/test.txt fil. Du kan løbe ind i en pod vha kubectl exec -it <pod-name> -- bash. For at flytte data fra Amazon S3 til Amazon EFS, efs-data-prep-pod.yaml giver et eksempel på en manifestfil, forudsat at en data-prep.sh script findes i et Docker-billede, der kopierer data fra Amazon S3 til Amazon EFS.
Hvis din modeltræning har brug for højere gennemstrømning, Amazon FSx til Luster kan være en bedre mulighed.
Træn PyTorch-modeller ved hjælp af TorchElastic
For deep learning-modeller, der træner på mængder af data, der er for store til at passe i hukommelsen på en enkelt GPU, DistributedDataParallel (PyTorch DDP) vil muliggøre deling af store træningsdata til mini-batches på tværs af flere GPU'er og instanser, hvilket reducerer træningstiden.
TorchElastic er et PyTorch-bibliotek udviklet med en indbygget Kubernetes-strategi, der understøtter fejltolerance og elasticitet. Når du træner på Spot Instances, skal træningen være fejltolerant og kunne genoptages fra den epoke, hvor beregningsknuderne forlod, da Spot Instances sidst var tilgængelige. Elasticitet giver mulighed for problemfri tilføjelse af nye computerressourcer, når de er tilgængelige, eller fjernelse af ressourcer, når de er nødvendige andre steder.
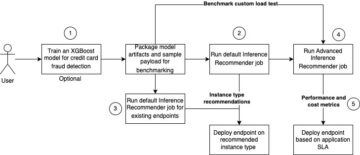
Følgende figur illustrerer arkitekturen for DistributedDataParallel med TorchElastic. TorchElastic til Kubernetes består af to komponenter: TorchElastic Kubernetes Controller og parameterserveren (osv.). Controlleren er ansvarlig for overvågning og styring af træningsjob, og parameterserveren holder styr på træningsjobmedarbejderne til distribueret synkronisering og peer-opdagelse.

W&B-platform til ML-eksperimentering og hyperparameter-gittersøgning
W&B hjælper ML-teams med at bygge bedre modeller hurtigere. Med blot et par linjer kode kan du øjeblikkeligt fejlsøge, sammenligne og reproducere dine modeller – arkitektur, hyperparametre, git-commits, modelvægte, GPU-brug, datasæt og forudsigelser – mens du samarbejder med dine holdkammerater.

W&B Sweeps er et kraftfuldt værktøj til at automatisere hyperparameteroptimering. Det giver udviklere mulighed for at opsætte hyperparameter-søgestrategien, inklusive gittersøgning, tilfældig søgning eller Bayesiansk søgning, og den vil automatisk implementere hver træningskørsel.
For at prøve W&B gratis, tilmeld dig på Vægte og skævheder, Eller besøg W&B AWS Marketplace notering.
Integrer W&B med Amazon EKS og TorchElastic
Følgende figur illustrerer ende-til-ende procesflowet til at orkestrere flere DistributedDataParallel træningskørsler på Amazon EKS med TorchElastic baseret på en W&B sweep-konfiguration. Konkret er de involverede trin:
- Flyt data fra Amazon S3 til Amazon EFS.
- Indlæs og forbehandle data med W&B.
- Byg et Docker-billede med træningskoden og alle nødvendige afhængigheder, og skub derefter billedet til Amazon ECR.
- Implementer TorchElastic-controlleren.
- Opret en W&B-sweep-konfigurationsfil, der indeholder alle hyperparametre, der skal fejes, og deres områder.
- Opret en yaml-manifestskabelonfil, der tager input fra sweep-konfigurationsfilen.
- Opret et Python-jobcontroller-script, der opretter N træningsmanifestfiler, en for hver træningskørsel, og indsender opgaverne til EKS-klyngen.
- Visualiser resultater på W&B-platformen.

I de følgende afsnit gennemgår vi hvert trin mere detaljeret.
Flyt data fra Amazon S3 til Amazon EFS
Det første trin er at flytte trænings-, validerings- og testdata fra Amazon S3 til Amazon EFS, så alle EKS-beregningsnoder kan få adgang til dem. Det s3_efs mappen har scripts til at flytte data fra Amazon S3 til Amazon EFS. Efter Lav Framework, har vi brug for en grundlæggende Dockerfile, der opretter en container med en data-prep.sh manuskript, build.sh script og push.sh script til at bygge billedet og skubbe det til Amazon ECR. Efter et Docker-billede er skubbet til Amazon ECR, kan du bruge efs-data-prep-pod.yaml manifest-fil (se følgende kode), som du kan køre som kubectl apply -f efs-data-prep-pod.yaml for at køre data-prep.sh scriptet i en pod:
apiVersion: v1
kind: ConfigMap
metadata
name: efs-data-prep-map
data:
S3_BUCKET:<S3 Bucket URI with data>
MOUNT_PATH: /shared-efs
---
apiVersion: v1
kind: Pod
metadata:
name: efs-data-prep-pod
spec:
containers:
- name: efs-data-prep-pod
image: <Path to Docker image in ECR>
envFrom:
- configMapRef:
name: efs-data-prep-map
command: ["/bin/bash"]
args: ["-c", "/data-prep.sh $(S3_BUCKET) $(MOUNT_PATH)"]
volumeMounts:
- name: efs-pvc
mountPath: /shared-efs
volumes:
- name: efs-pvc
persistentVolumeClaim:
claimName: efs-claim
restartPolicy: Never
Indlæs og forbehandle data med W&B
Processen med at indsende et forbehandlingsjob ligner meget det foregående trin med nogle få undtagelser. I stedet for et data-prep.sh-script skal du sandsynligvis køre et Python-job for at forbehandle dataene. Forbehandlingsmappen har scripts til at køre et forbehandlingsjob. Det pre-process_data.py scriptet udfører to opgaver: det tager rådataene i Amazon EFS og opdeler dem i tog- og testfiler, hvorefter det tilføjer dataene til W&B-projektet.
Byg et Docker-billede med træningskode
main.py demonstrerer, hvordan man implementerer DistributedDataParallel træning med TorchElastic. For kompatibilitet med W&B er det almindelig praksis at tilføje WANDB_API_KEY som en miljøvariabel og tilføj wandb.login() helt i begyndelsen af koden. Ud over standardargumenterne (antal epoker, batchstørrelse, antal arbejdere for dataindlæseren), skal vi sende ind wandb_project navn og sweep_id også.
I main.py-koden er run() funktion gemmer ende-til-ende-pipelinen for følgende handlinger:
- Initialiserer wandb på node 0 for at logge resultater
- Indlæsning af den fortrænede model og opsætning af optimizer
- Initialisering af tilpassede trænings- og valideringsdataindlæsere
- Indlæser og gemmer kontrolpunkter ved hver epoke
- Går gennem epokerne og kalder trænings- og valideringsfunktionerne
- Når træningen er færdig, køres forudsigelser på det specificerede testsæt
Trænings-, validerings-, brugerdefinerede dataindlæser- og sorteringsfunktioner skal ikke ændres for at logge resultater til W&B. For en distribueret træningsopsætning skal vi tilføje følgende kodeblok for at logge på node 0-processen. Her er args parametrene for træningsfunktionen ud over sweep-id'et og W&B-projektnavnet:
if local_rank == 0: wandb.init(config=args, project=args.wandb_project) args = wandb.config do_log = True
else: do_log = False
For mere information om W&B og distribueret træning, se Log distribuerede træningseksperimenter.
I main() funktion, kan du kalde funktionen run() som vist i følgende kode. Her er wandb.agent er orkestrator af sweep, men fordi vi kører flere træningsjob på Amazon EKS parallelt, er vi nødt til at specificere count = 1:
wandb.require("service") wandb.setup() if args.sweep_id is not None: wandb.agent(args.sweep_id, lambda: run(args), project=args.wandb_project, count = 1) else: run(args=args)
Dockerfil installerer de nødvendige afhængigheder for PyTorch, HuggingFace og W&B, og angiver et Python-kald til torch.distributed.run som et indgangspunkt.
Implementer en TorchElastic-controller
Før træning skal vi implementere en TorchElastic-controller til Kubernetes, som administrerer en tilpasset Kubernetes-ressource ElasticJob til at køre TorchElastic-arbejdsbelastninger på Kubernetes. Vi installerer også en pod, der kører etcd-serveren ved at køre scriptet deploy.sh. Det anbefales at slette og genstarte etcd-serveren, når du genstarter et nyt træningsjob.
W&B sweep config
Efter at have sat klyngen og containeren op, opsatte vi flere kørsler parallelt med lidt forskellige parametre for at forbedre vores modelydelse. W&B Sweeps vil automatisere denne form for udforskning. Vi opretter en konfigurationsfil, hvor vi definerer søgestrategien, den metrik, der skal overvåges, og de parametre, der skal udforskes. Følgende kode viser et eksempel på en sweep-konfigurationsfil:
method: bayes
metric: name: val_loss goal: minimize
parameters: learning_rate: min: 0.001 max: 0.1
optimizer: values: ["adam", "sgd"]
For flere detaljer om, hvordan du konfigurerer dine sweeps, følg W&B Sweeps Quickstart.
Opret en train.yaml skabelon
Følgende kode er et eksempel på train.yaml-skabelonen, som vi skal oprette. Python-jobcontrolleren tager denne skabelon og genererer én trænings-.yaml-fil for hver kørsel i hyperparameter-gittersøgningen. Nogle nøglepunkter at bemærke er:
-
kubernetes.io/instance-typeværdi indtager navnet på instanstypen af EKS-beregningsknuderne. - Args-sektionen inkluderer alle parametre, som py-koden tager ind som argumenter, inklusive antal epoker, batchstørrelse, antal dataindlæserarbejdere,
sweep_id, wandb-projektnavn, kontrolpunktfilplacering, databiblioteksplacering og så videre. -
--nproc_per_node,nvidia.com/gpuværdier tager det antal GPU'er, du vil bruge til træning. For eksempel, i den følgende konfiguration, har vi p3.8xlarge som EKS compute noder, som har 4 Nvidia Tesla V100 GPU'er, og i hver træningskørsel bruger vi 2 GPU'er. Vi kan sætte gang i seks træningsløb parallelt, der vil udtømme alle tilgængelige 12 GPU'er, og derved sikre høj GPU-udnyttelse.
apiVersion: elastic.pytorch.org/v1alpha1
kind: ElasticJob
metadata: name: wandb-finbert-baseline #namespace: elastic-job
spec: # Use "etcd-service:2379" if you already apply etcd.yaml rdzvEndpoint: etcd-service:2379 minReplicas: 1 maxReplicas: 128 replicaSpecs: Worker: replicas: 1 restartPolicy: ExitCode template: apiVersion: v1 kind: Pod spec: nodeSelector: node.kubernetes.io/instance-type: p3.8xlarge containers: - name: elasticjob-worker image: <path to docker image in ECR> imagePullPolicy: Always env: - name: NCCL_DEBUG value: INFO # - name: NCCL_SOCKET_IFNAME # value: lo # - name: FI_PROVIDER # value: sockets args: - "--nproc_per_node=2" - "/workspace/examples/huggingface/main.py" - "--data=/shared-efs/wandb-finbert/" - "--epochs=1" - "--batch-size=16" - "--workers=6" - "--wandb_project=aws_eks_demo" - "--sweep_id=jba9d36p" - "--checkpoint-file=/shared-efs/wandb-finbert/job-z74e8ix8/run-baseline/checkpoint.tar" resources: limits: nvidia.com/gpu: 2 volumeMounts: - name: efs-pvc mountPath: /shared-efs - name: dshm mountPath: /dev/shm volumes: - name: efs-pvc persistentVolumeClaim: claimName: efs-claim - name: dshm emptyDir: medium: Memory
Opret en gittersøgningsjobcontroller
Manuskriptet run-grid.py er den vigtigste orkestrator, der tager i en TorchElastic træning .yaml skabelon og W&B sweep config fil, genererer flere trænings manifestfiler og indsender dem.
Visualiser resultaterne
Vi opretter en EKS-klynge med tre p3.8xlarge instanser med 4 Tesla V100 GPU'er hver. Vi opsætter seks parallelle kørsler med 2 GPU'er hver, mens vi varierer indlæringshastigheden og vægtnedbrydningsparametrene for Adam optimizer. Hvert individuelt træningsløb ville tage omkring 25 minutter, så hele hyperparametergitteret kunne fejes på 25 minutter, når det arbejdede parallelt, i modsætning til 150 minutter, hvis det arbejdede sekventielt. Hvis det ønskes, kan en enkelt GPU bruges til hver træningsrunde ved at ændre --nproc_per_node , nvidia.com/gpu værdier i træningsskabelonen .yaml.
TorchElastic implementerer elasticitet og fejltolerance. I dette arbejde bruger vi On-Demand-instanser, men en klynge af Spot-instanser kan genereres med nogle få ændringer i EKS-konfigurationen. Hvis en instans bliver tilgængelig på et senere tidspunkt og skal tilføjes til træningspuljen, mens træningen er i gang, skal vi blot opdatere træningsskabelonen .yaml og indsende den igen. Rendezvous-funktionaliteten i TorchElastic vil assimilere den nye instans i træningsjobbet dynamisk.
Når gittersøgningsjobcontrolleren kører, kan du se alle seks Kubernetes-job med kubectl get pod -A. Der vil være et job pr. træningskørsel, og hvert job vil have en arbejder pr. node. For at se logfilerne for hver pod, kan du hale logs vha kubectl logs -f <pod-name>. kubetail vil vise logfilerne for alle pods for hvert træningsjob samtidigt. I starten af grid-controlleren får du et link til W&B-platformen, hvor du kan se forløbet af alle jobs.
Følgende graf for parallelle koordinater visualiserer alle gittersøgningskørsler med hensyn til testnøjagtighed i ét plot, inklusive dem, der ikke blev færdige. Vi fik den højeste testnøjagtighed med en indlæringsrate på 9.1e-4 og vægtfald på 8.5e-3.
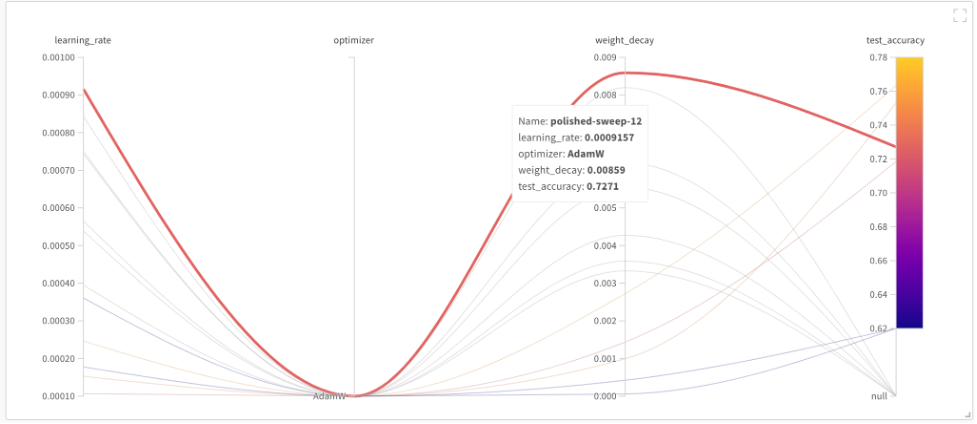
Følgende dashboard visualiserer alle gittersøgninger sammen for alle metrics.

Ryd op
Det er vigtigt at skrue ned for ressourcer efter modeltræning for at undgå omkostninger forbundet med at køre inaktive tilfælde. Med hvert script, der opretter ressourcer, GitHub repo giver et matchende script til at slette dem. For at rydde op i vores opsætning skal vi slette EFS-filsystemet, før vi sletter klyngen, fordi den er forbundet med et undernet i klyngens VPC. For at slette EFS-filsystemet skal du køre følgende kommando (indefra EFS folder):
Bemærk, at dette ikke kun vil slette den vedvarende volumen, det vil også slette EFS-filsystemet, og alle data på filsystemet vil gå tabt. Når dette trin er fuldført, skal du slette klyngen ved at bruge følgende script i EKS folder:
Dette vil slette alle eksisterende pods, fjerne klyngen og slette den VPC, der blev oprettet i begyndelsen.
Konklusion
I dette indlæg viste vi, hvordan man bruger en EKS-klynge med vægte og skævheder til at fremskynde hyperparameter-gittersøgning efter dybe læringsmodeller. Weights & Biases og Amazon EKS giver dig mulighed for at orkestrere flere træningsløb parallelt for at reducere tid og omkostninger til at finjustere din dybe læringsmodel. Vi har offentliggjort GitHub repo, som giver dig trin-for-trin instruktioner til at oprette en EKS-klynge, opsætte Weights & Biases og TorchElastic til distribueret data parallel træning og kickstart grid search kører på Amazon EKS med et enkelt klik.
Om forfatterne
Ankur Srivastava er Sr. Solutions Architect i ML Frameworks Team. Han fokuserer på at hjælpe kunder med selvstyret distribueret træning og konklusioner i stor skala om AWS. Hans erfaring omfatter industriel prædiktiv vedligeholdelse, digitale tvillinger, probabilistisk designoptimering og har afsluttet sine doktorgradsstudier fra Mechanical Engineering ved Rice University og post-doc forskning fra Massachusetts Institute of Technology.
Thomas Chapelle er maskinlæringsingeniør i vægte og skævheder. Han er ansvarlig for at holde www.github.com/wandb/examples-lageret live og opdateret. Han bygger også indhold på MLOPS, anvendelser af W&B til industrier og sjov dyb læring generelt. Tidligere brugte han dyb læring til at løse kortsigtede prognoser for solenergi. Han har en baggrund i byplanlægning, kombinatorisk optimering, transportøkonomi og anvendt matematik.
Scott Juang er direktør for Alliancer hos Weights & Biases. Før W&B ledede han en række strategiske alliancer hos AWS og Cloudera. Scott studerede Materials Engineering og har en passion for vedvarende energi.
Ilan Gleiser er en Principal Global Impact Computing Specialist hos AWS, der leder cirkulær økonomi, ansvarlig AI og ESG-virksomheder. Han er ekspertrådgiver for digitale teknologier til cirkulær økonomi hos FN. Før AWS ledede han AI Enterprise Solutions hos Wells Fargo. Han tilbragte 10 år som leder af Morgan Stanleys Algorithmic Trading Division i San Francisco.
Ana Simoes er Principal ML Specialist hos AWS med fokus på GTM-strategi for startups i det nye teknologiske område. Ana har haft adskillige lederroller hos startups og store virksomheder som Intel og eBay, og har ført ML-inferens og lingvistikrelaterede produkter. Ana har en Master i Computational Linguistics og en MBA fra Haas/UC Berkeley, og og har været gæsteforsker i Lingvistik ved Stanford. Hun har en teknisk baggrund i AI og Natural Language Processing.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/accelerate-hyperparameter-grid-search-for-sentiment-analysis-with-bert-models-using-weights-biases-amazon-eks-and-torchelastic/
- 1
- 10
- 7
- 9
- a
- evne
- I stand
- fremskynde
- adgang
- Konto
- nøjagtighed
- tværs
- aktioner
- aktiv
- Adam
- tilføjet
- Desuden
- adresse
- Tilføjer
- rådgiver
- Efter
- AI
- algoritmisk
- algoritmisk handel
- Alle
- tillader
- allerede
- altid
- Amazon
- beløb
- Ana
- analyse
- ,
- applikationer
- anvendt
- Indløs
- arkitektonisk
- arkitektur
- argumenter
- forbundet
- auto
- automatisere
- automatisk
- tilgængelighed
- til rådighed
- undgå
- AWS
- AWS Marketplace
- baggrund
- baseret
- grundlæggende
- Bayesiansk
- fordi
- bliver
- før
- Begyndelse
- Berkeley
- Bedre
- større
- Bloker
- bygge
- bygger
- bygget
- virksomheder
- ringe
- ringer
- Kapacitet
- fange
- udfordre
- udfordringer
- lave om
- Ændringer
- skiftende
- kontrollere
- kontrol
- valg
- cirkulær økonomi
- klassificering
- Cloudera
- Cluster
- kode
- samarbejde
- Fælles
- sammenligne
- kompatibilitet
- fuldføre
- Afsluttet
- kompleksitet
- komponenter
- Compute
- computing
- Konfiguration
- Konsol
- Container
- Beholdere
- indhold
- sammenhæng
- controller
- Selskaber
- Koste
- Omkostninger
- kunne
- skabe
- oprettet
- skaber
- Oprettelse af
- skabelse
- Nuværende
- Nuværende tilstand
- skik
- Kunder
- instrumentbræt
- data
- datasæt
- Dato
- DDP
- afgørelser
- dyb
- dyb læring
- Standard
- Efterspørgsel
- krævende
- demonstrerer
- indsætte
- Design
- detail
- detaljeret
- detaljer
- udviklet
- udviklere
- forskellige
- digital
- Digitale tvillinger
- Direktør
- opdagelse
- diskutere
- Skærm
- distribueret
- distribueret træning
- Afdeling
- Docker
- Dont
- ned
- driver
- dynamisk
- hver
- nem at bruge
- eBay
- Økonomisk
- Økonomi
- økonomi
- andetsteds
- smergel
- Emerging Technology
- muliggøre
- muliggør
- ende til ende
- energi
- ingeniør
- Engineering
- sikre
- sikring
- Enterprise
- Enterprise Solutions
- Hele
- indrejse
- Miljø
- epoke
- epoker
- fejl
- ESG
- Ether (ETH)
- Hver
- eksempel
- eksisterende
- eksisterer
- erfaring
- ekspert
- udforskning
- udforske
- konfronteret
- FAIL
- mislykkedes
- hurtigere
- få
- Figur
- tal
- File (Felt)
- Filer
- slut
- Fornavn
- passer
- flow
- fokuserer
- fokusering
- følger
- efter
- Til opstart
- formular
- fundet
- rammer
- Francisco
- Gratis
- frisk
- fra
- sjovt
- funktion
- funktionalitet
- funktioner
- Generelt
- generere
- genereret
- genererer
- få
- Git
- GitHub
- Giv
- given
- giver
- Global
- mål
- gå
- GPU
- GPU'er
- graf
- Grid
- gruppe
- Gruppens
- hoved
- Overskrifter
- hjælpe
- hjælpsom
- hjælpe
- hjælper
- link.
- Høj
- højere
- højeste
- stærkt
- Hvordan
- How To
- Men
- HTML
- HTTPS
- KrammerFace
- Hyperparameter optimering
- IAM
- Identity
- tomgang
- billede
- KIMOs Succeshistorier
- gennemføre
- redskaber
- vigtigt
- Forbedre
- in
- omfatter
- Herunder
- Stigninger
- individuel
- industrielle
- industrier
- info
- oplysninger
- instans
- i stedet
- Institut
- anvisninger
- Integration
- Intel
- involverede
- IT
- Job
- Karriere
- holde
- Nøgle
- sparke
- Venlig
- Kubernetes
- Sprog
- stor
- Efternavn
- lancere
- lanceret
- Leadership" (virkelig menneskelig ledelse)
- førende
- læring
- Led
- Bibliotek
- Sandsynlig
- grænser
- linjer
- lingvistik
- LINK
- leve
- belastning
- loader
- placering
- maskine
- machine learning
- Main
- vedligeholdelse
- lave
- lykkedes
- administrerer
- styring
- Marked
- Markedsdata
- markedsplads
- Massachusetts
- Massachusetts Tekniske Institut
- matchende
- materialer
- matematik
- max
- MBA
- meningsfuld
- mekanisk
- maskiningeniør
- medium
- Hukommelse
- Metadata
- metrisk
- Metrics
- måske
- minimere
- minutter
- ML
- MLOps
- model
- modeller
- Overvåg
- overvågning
- mere
- Morgan
- MONTERING
- bevæge sig
- flere
- navn
- nationer
- indfødte
- Natural
- Naturligt sprog
- Natural Language Processing
- nødvendig
- Behov
- behov
- behov
- negativ
- Ny
- nyheder
- NLP
- node
- noder
- nummer
- Nvidia
- tilbyde
- ONE
- open source
- drift
- modsætning
- optimering
- Option
- ordrer
- Andet
- oversigt
- Parallel
- parameter
- parametre
- deltagere
- lidenskab
- sti
- peer
- ydeevne
- stykke
- pipeline
- planlægning
- perron
- plato
- Platon Data Intelligence
- PlatoData
- bælg
- Punkt
- punkter
- politikker
- pool
- positiv
- Indlæg
- vigtigste
- praksis
- forudsigelse
- Forudsigelser
- præsentere
- gaver
- tidligere
- Priser
- Main
- principper
- Forud
- behandle
- forarbejdning
- produktivitet
- Produkter
- Programmering
- Progress
- projekt
- korrekt
- give
- forudsat
- giver
- bestemmelse
- offentliggjort
- Skub ud
- skubbet
- Python
- pytorch
- tilfældig
- Sats
- Raw
- rådata
- årsager
- anbefales
- reducere
- reducere
- region
- relaterede
- relevant
- fjernelse
- Fjern
- Vedvarende
- vedvarende energi
- Repository
- anmodet
- Kræver
- forskning
- ressource
- Ressourcer
- ansvarlige
- Resultater
- Genoptag
- Ris
- roller
- groft
- rundt
- Kør
- kører
- samme
- San
- San Francisco
- besparelse
- skalerbar
- Scale
- skalaer
- skalering
- scripts
- sømløs
- Søg
- Sektion
- sektioner
- stemningen
- adskille
- tjeneste
- Tjenester
- sæt
- indstilling
- setup
- flere
- SGD
- sharding
- delt
- kort sigt
- bør
- vist
- Shows
- underskrive
- lignende
- Simpelt
- enkelhed
- ganske enkelt
- samtidigt
- enkelt
- SIX
- Størrelse
- størrelser
- lidt anderledes
- So
- sol
- solenergi
- løsninger
- Løsninger
- SOLVE
- nogle
- Space
- specialist
- specifikke
- specifikt
- specificeret
- brugt
- Spin
- splits
- Spot
- stable
- Stakke
- standard
- står
- Stanford
- starte
- påbegyndt
- starter
- Nystartede
- Tilstand
- Trin
- Steps
- bestand
- aktiemarkedet
- opbevaring
- forhandler
- Strategisk
- Strategi
- studeret
- undersøgelser
- indsende
- subnet
- undernet
- sådan
- foreslår
- Understøttet
- Støtte
- Sweep
- synkronisering
- systemet
- Tag
- tager
- mål
- Opgaver
- opgaver
- hold
- hold
- Teknisk
- Teknologier
- Teknologier
- skabelon
- Tesla
- prøve
- verdenen
- deres
- derved
- tre
- Gennem
- kapacitet
- tid
- tips
- til
- sammen
- tolerance
- også
- værktøj
- værktøjer
- fakkel
- spor
- Trading
- Tog
- Kurser
- transformers
- transport
- sand
- Twins
- typer
- forståelse
- Forenet
- Forenede Nationer
- universitet
- Opdatering
- urban
- URI
- Brug
- brug
- VALIDATE
- validering
- værdi
- Værdier
- Specifikation
- synlig
- bind
- mængder
- vægt
- Wells
- Wells Fargo
- hvorvidt
- som
- mens
- vilje
- inden for
- ord
- Arbejde
- arbejdstager
- arbejdere
- world
- ville
- yaml
- år
- Din
- zephyrnet
- zoner