Introduktion
Enhver dataforsker kræver et effektivt og pålideligt værktøj til at behandle disse store ustoppelige data. I dag diskuterer vi et sådant værktøj kaldet Delta Lake, som dataentusiaster bruger til at gøre deres databehandlingspipelines mere effektive og pålidelige.
Dybest set er Delta Lake et open source-lagerlag, der ligger oven på vores eksisterende datalagringsinfrastruktur og muliggør skemahåndhævelse, versionering og ACID-transaktioner (atomicitet, konsistens, isolation og holdbarhed) for vores data. Delta Lake byder på adskillige fordele, såsom at administrere den enorme mængde data, nemt at kunne rulle ændringer tilbage og give datakonsistens på tværs af flere Spark-sessioner.
Hvis du forbereder dig til Delta Lake-interviewet, er du havnet på den rigtige blog. Her diskuterer vi de oftest stillede Delta Lake-interviewspørgsmål.
Læringsmål
Nedenfor er hvad vi lærer efter at have læst denne blog omhyggeligt:
- Forståelse af, hvad en Delta Lake er, og hvilken rolle den spiller i den tekniske æra.
- Kendskab til dets forhold til Apache Spark.
- En forståelse af dataindsættelse eller indlæsningsprocessen i Delta Lake.
- En forståelse af Delta Lake-komponenterne og deres ACID-kompatible egenskaber.
- Indsigt i begreber som Upserts, måder at læse data på og batch- og streamingoperationer i Delta Lake.
Samlet set vil vi ved at læse denne guide få en omfattende forståelse af Delta Lake for at gemme dataene. Efter at have afsluttet denne blog, har vi nok viden og evner til at bruge denne teknik effektivt og svare på almindelige forespørgsler på mellemniveau, og du kan klare dit delta-sø-interview.
.
Denne artikel blev offentliggjort som en del af Data Science Blogathon.
Indholdsfortegnelse
Q1. Hvordan adskiller Delta Lake sig fra andre transaktionslagre?
Selvom Delta Lake også løser de samme udfordringer, der løses af andre transaktionslag, er det ikke det; den har en bredere dækning af anvendelsessager på tværs af dataøkosystemet, hvilket giver den berømmelse. Delta Lake giver datasikkerhed, pålidelighed og bedre ydeevne og tilbyder en samlet ramme for batch- og streaming-arbejdsbelastninger. Det forbedrer effektiviteten af forskellige downstream-aktiviteter som BI, ML, datavidenskab og datatransformationspipelines.
Kilde: kpipartners
For at få flere fordele kan vi også bruge Delta Lake på Databrikker; det giver bredere økosystemunderstøttelse med hurtigere indbyggede forbindelser til de mest populære Business Intelligence-værktøjer, muliggør bedre ydeevne med Delta Engine og tilbyder bedre sikkerhed og styring med finmasket adgangskontrol.
Endelig, når man kommer til statistikken, indtages omkring 3 petabyte data af Delta-søer på daglig basis og har været i produktion i over 3 år; tusindvis af brugere bruger Delta Lake på Databricks.
Q2. Forklar, hvordan Delta Lakes er ACID-kompatible.
Delta Lakes er ACID kompatibel fordi:
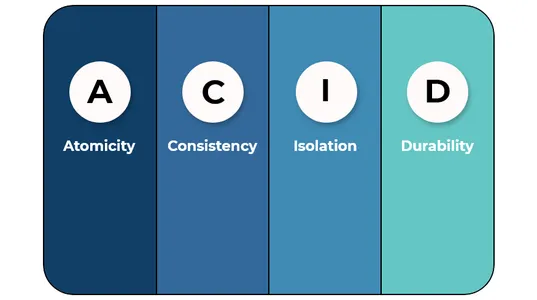
A(Atomicitet)- Delta Lake tilbyder atomtransaktioner, hvilket indebærer, at alle ændringer af dataene i en Delta-tabel enten er forpligtet eller alle rullet tilbage.
C(Konsistens)- Delta Lake tilbyder datakonsistens, hvilket indebærer, at datalæserne altid vil læse de samme data på det tidspunkt, hvor transaktionen blev startet.
I(Isolation)- Ved hjælp af en tidsrejsefunktion understøtter Data Lakes isolering og giver brugerne mulighed for at se data, som de eksisterer til enhver tid.
D(holdbarhed)- Data Lake understøtter holdbarhed ved at vise alle transaktionsændringer på trods af systemfejl.
Q3. Forklar forholdet mellem Delta Lake og Apache Spark.
Delta Lake er et værktøj bygget ovenpå Apache Spark og tilbyder en vej til at administrere lagring og forbedre ydeevnen for Spark-applikationer. Delta Lake forbedrer ydeevnen, når Spark læser og skriver data ved at gemme data i Parquet-filer. Det bruger et søjleformat, og for at sikre datakonsistens tilbyder det en måde at administrere transaktioner på og holde styr på dataændringer.
Q4. Hvorfor bruge Delta Lake, hvis vi kan gemme data i parketformat på S3 eller HDFS?
Delta Lake er et godt valg frem for Parket, når vi skal udføre databehandling i stor skala, fordi det giver høj skalerbarhed og bedre ydeevne. På trods af strømafbrydelser eller hardwarefejl vil dataene også forblive sikre mod korruption på grund af det ACID-kompatible design af Delta Lakes.
Q5. Forklar processen med at importere data til Delta Lake.
Vi kan importere data til Delta Lake blot ved at bruge Databrikker Auto Loader-værktøj eller COPY INTO-kommandoen med SQL; den optager automatisk nye datafiler i Delta Lake, fordi de kommer i vores datasø (dvs. på S3 eller ADLS). Desuden kan vi bruge Apache SparkTM til at batchlæse vores data ved at udføre de nødvendige ændringer og gemme resultatet i Delta Lake.
Q6. Forklar hovedkomponenterne i en deltasø.
Delta Lake består af tre vigtige komponenter: Delta-tabellen, Delta-loggen og Delta-cachen.
Deltatabel: Det er den centrale lagerdel, der bærer alle data for en Delta Lake.
Deltalog: En transaktionslog bruges til at spore eller overvåge alle de ændringer, der er foretaget i Delta-tabellen.
Delta Cache: Det er en kolonneformet cache, og ligesom den normale cache gemmer den den aktuelle version af dataene i Delta-tabellen.
Q7. Hvordan udfører vi Upserts i Delta Lake?
Upsert er en kombination af to ord/operationer, dvs. Opdater og Indsæt. Vi kan udføre upserts i delta sø ved hjælp af MERGE og INSERT INTO kommandoer:
Fusionere: Ved hjælp af MERGE-kommandoen kan vi opdatere eller indsætte alle data i en Delta-tabel afhængigt af en given tilstand. Ved at bruge WHERE-sætningen sætter vi en betingelse på enhver kommando, og hvis betingelsen resulterer i sand, udføres UPDATE-handlingen; hvis betingelsen resulterer i falsk, udføres INSERT-handlingen.
Indsæt:Ved hjælp af INSERT INTO-kommandoen kan vi indsætte data i en Delta-tabel, men denne kommando vil kun indsætte nye rækker i tabellen, uden opdatering af de eksisterende rækker.
Q8. Forklar de forskellige tilstande, der er tilgængelige til at læse data fra en Delta Lake-tabel.
For at læse dataene fra en Delta Lake-tabel har vi to tilgængelige tilstande:
1. Fuld scanningstilstand: Denne tilstand bruges til at læse hele indholdet af Delta Lake-tabellen.
2. Inkrementel scanningstilstand: Denne tilstand bruges til kun at læse data, der er indsat eller ændret siden sidste gang, Delta-tabellen blev læst.
Q9. Forklar betydningen af batch- og streamingoperationer i Delta Lake.
Vi kan køre batch- og streamingoperationer med Delta Lake på en enkelt forenklet arkitektur og undgå komplekse, redundante systemer og driftsmæssige udfordringer. I Delta Lake er en tabel både en batch-tabel og en streamingkilde.
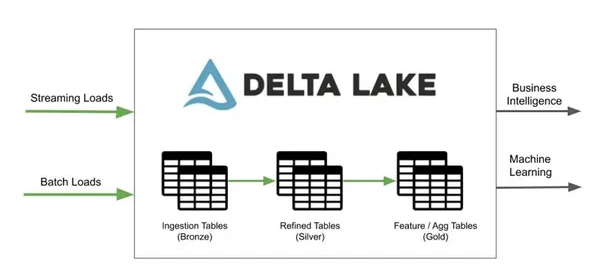
Kilde: hevodata.com
Med hensyn til betydning fungerer interaktive forespørgsler, streamingdataindtagelse og batch-historisk tilbagefyldning ud af boksen og integreres direkte med Spark Structured Streaming.
Q10. Hvordan kan vi indlæse data i en tabel fra et andet filsystem i Delta Lake?
For at udføre belastningsoperationen understøtter Delta Lake en proces kaldet "upserts". Den indlæser data i en Delta-tabel fra et andet eksisterende filsystem. I denne proces kontrollerer vi først, om en række med den samme primærnøgle allerede findes i tabellen eller ej. Hvis rækken eksisterer, bliver den opdateret med de nye data; ellers bliver det indsat i tabellen.
Konklusion
Denne blog dækker nogle af de ofte stillede Delta Lake-interviewspørgsmål, der kunne stilles i datavidenskab og big data-udviklerinterviews. Ved at bruge disse deltasø-interviewspørgsmål som reference kan du bedre forstå begreberne og formulere effektive svar til kommende interviews. De vigtigste takeaways fra denne Delta Lake-blog er: -
- Delta Lake er et ACID-kompatibelt open source-lagerlag, der ligger oven på vores eksisterende datalagringsinfrastruktur.
- Delta Lake letter os med håndtering af enorme data og opretholdelse af datakonsistens på tværs af flere Spark-sessioner.
- Delta Lake er bedre end forskellige transaktionelle lagerlag mht
- Vi diskuterede upserts, en måde at indlæse data i Data Lake-tabellerne på.
- I denne blog diskuterede vi også komponenterne i Delta Lake, herunder tabel, log og Delta-cache.
Mediet vist i denne artikel ejes ikke af Analytics Vidhya og bruges efter forfatterens skøn.
Relaterede
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.analyticsvidhya.com/blog/2023/02/ace-your-interview-with-top-10-interview-questions-on-delta-lake/
- 10
- 11
- a
- evne
- I stand
- adgang
- tværs
- Handling
- aktiviteter
- Efter
- Alle
- allerede
- altid
- analytics
- Analyse Vidhya
- ,
- En anden
- svar
- Apache
- Apache Spark
- applikationer
- arkitektur
- omkring
- artikel
- auto
- automatisk
- til rådighed
- undgå
- tilbage
- grundlag
- fordi
- være
- fordele
- Bedre
- Big
- Big data
- Blog
- blogathon
- Boks
- bredere
- bygget
- virksomhed
- business intelligence
- cache
- kaldet
- omhyggeligt
- tilfælde
- central
- udfordringer
- Ændringer
- kontrollere
- valg
- kombination
- Kom
- kommer
- engageret
- Fælles
- færdiggøre
- komplekse
- kompatibel
- komponenter
- omfattende
- begreber
- konklusion
- betingelse
- indhold
- kontrol
- Korruption
- kunne
- dækning
- dækker
- Nuværende
- dagligt
- data
- Data Lake
- databehandling
- datalogi
- dataforsker
- datasikkerhed
- data opbevaring
- Databrikker
- Delta
- krav
- Afhængigt
- Design
- Trods
- Udvikler
- afvige
- forskellige
- direkte
- diskretion
- diskutere
- drøftet
- holdbarhed
- nemt
- økosystem
- Effektiv
- effektivt
- effektivitet
- effektiv
- enten
- muliggør
- håndhævelse
- Engine (Motor)
- Forbedrer
- nok
- sikre
- entusiaster
- Hele
- Era
- eksisterende
- eksisterer
- Forklar
- letter
- BERØMMELSE
- hurtigere
- Feature
- File (Felt)
- Filer
- Fornavn
- format
- Framework
- hyppigt
- fra
- fuld
- Gevinst
- få
- given
- godt
- regeringsførelse
- vejlede
- Hardware
- hjælpe
- link.
- Høj
- historisk
- Hvordan
- HTTPS
- kæmpe
- importere
- vigtigt
- importere
- forbedrer
- in
- Herunder
- Infrastruktur
- integrere
- Intelligens
- interaktiv
- Interview
- interview spørgsmål
- Interviews
- Introduktion
- isolation
- IT
- Holde
- Nøgle
- viden
- sø
- storstilet
- Efternavn
- lag
- lag
- LÆR
- belastning
- loader
- lastning
- belastninger
- lavet
- Main
- lave
- administrere
- ledelse
- styring
- Medier
- Flet
- ML
- tilstand
- modes
- Modifikationer
- modificeret
- Overvåg
- mere
- mere effektiv
- mest
- Mest Populære
- flere
- indfødte
- nav
- nødvendig
- Ny
- normal
- Tilbud
- ONE
- open source
- drift
- operationelle
- Produktion
- Andet
- Ellers
- udfald
- Resultat
- ejede
- del
- sti
- udføre
- ydeevne
- udfører
- plato
- Platon Data Intelligence
- PlatoData
- Populær
- magt
- forberede
- primære
- behandle
- forarbejdning
- produktion
- egenskaber
- giver
- leverer
- offentliggjort
- sætte
- Q1
- Q2
- Q3
- Spørgsmål
- Læs
- læsere
- Læsning
- forhold
- pålidelighed
- pålidelig
- forblive
- Svar
- Resultater
- roller
- Roll
- Rullet
- RÆKKE
- Kør
- sikker
- samme
- Skalerbarhed
- scanne
- Videnskab
- Videnskabsmand
- sikkerhed
- sessioner
- flere
- vist
- betydning
- forenklet
- siden
- enkelt
- Løser
- nogle
- Kilde
- Spark
- SQL
- påbegyndt
- statistik
- opbevaring
- butik
- Gem dataene
- forhandler
- streaming
- struktureret
- sådan
- support
- Understøtter
- systemet
- Systemer
- bord
- Takeaways
- Teknisk
- vilkår
- Fusionen
- deres
- tusinder
- tre
- tid
- tidsrejser
- til
- i dag
- værktøj
- værktøjer
- top
- Top 10
- spor
- transaktion
- transaktionsbeslutning
- Transaktioner
- Transformation
- rejse
- sand
- forstå
- forståelse
- forenet
- ustoppelig.
- kommende
- Opdatering
- opdateret
- us
- brug
- brug tilfælde
- brugere
- forskellige
- udgave
- Specifikation
- bind
- Hvad
- hvorvidt
- som
- vilje
- Arbejde
- træning
- år
- Din
- zephyrnet