Med Tilpassede etiketter til Amazon-genkendelse, du kan have Amazon-anerkendelse træne en brugerdefineret model til objektdetektering eller billedklassificering, der er specifik til dine forretningsbehov. For eksempel kan Rekognition Custom Labels finde dit logo i opslag på sociale medier, identificere dine produkter på butikshylderne, klassificere maskindele i et samlebånd, skelne mellem sunde og inficerede planter eller opdage animerede figurer i videoer.
Udvikling af en Rekognition Custom Labels-model til at analysere billeder er en betydelig opgave, der kræver tid, ekspertise og ressourcer, som ofte tager måneder at gennemføre. Derudover kræver det ofte tusinder eller titusindvis af håndmærkede billeder for at give modellen nok data til nøjagtigt at træffe beslutninger. Generering af disse data kan tage måneder at indsamle og kræve store teams af etikettere til at forberede dem til brug i maskinlæring (ML).
Med Rekognition Custom Labels tager vi os af de tunge løft for dig. Anerkendte etiketter bygger på de eksisterende muligheder i Amazon Rekognition, som allerede er trænet på titusinder af billeder på tværs af mange kategorier. I stedet for tusindvis af billeder skal du blot uploade et lille sæt træningsbilleder (typisk et par hundrede billeder eller mindre), der er specifikke for din use case via vores brugervenlige konsol. Hvis dine billeder allerede er mærket, kan Amazon Rekognition begynde træningen med blot et par klik. Hvis ikke, kan du mærke dem direkte i Amazon Rekognition-mærkningsgrænsefladen eller bruge Amazon SageMaker Ground Truth at mærke dem for dig. Efter at Amazon Rekognition begynder at træne fra dit billedsæt, producerer det en tilpasset billedanalysemodel til dig på få timer. Bag kulisserne indlæser og inspicerer Rekognition Custom Labels automatisk træningsdataene, vælger de rigtige ML-algoritmer, træner en model og leverer modelpræstationsmålinger. Du kan derefter bruge din brugerdefinerede model via Rekognition Custom Labels API og integrere den i dine applikationer.
Opbygning af en Rekognition Custom Labels-model og hosting af den til forudsigelser i realtid involverer dog flere trin: oprettelse af et projekt, oprettelse af trænings- og valideringsdatasæt, træning af modellen, evaluering af modellen og derefter oprettelse af et slutpunkt. Efter at modellen er implementeret til inferens, skal du muligvis genoptræne modellen, når nye data bliver tilgængelige, eller hvis der modtages feedback fra den virkelige verden. Automatisering af hele arbejdsgangen kan hjælpe med at reducere manuelt arbejde.
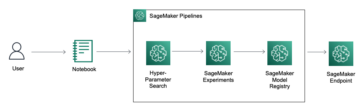
I dette indlæg viser vi, hvordan du kan bruge AWS-trinfunktioner at opbygge og automatisere arbejdsgangen. Step Functions er en visuel workflow-tjeneste, der hjælper udviklere med at bruge AWS-tjenester til at bygge distribuerede applikationer, automatisere processer, orkestrere mikrotjenester og skabe data- og ML-pipelines.
Løsningsoversigt
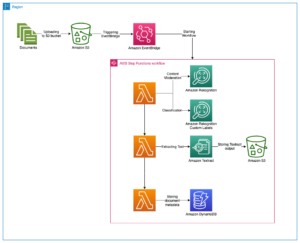
Workflowet for Trinfunktioner er som følger:
- Vi opretter først et Amazon Rekognition-projekt.
- Sideløbende opretter vi trænings- og valideringsdatasættene ved hjælp af eksisterende datasæt. Vi kan bruge følgende metoder:
- Importer en mappestruktur fra Amazon Simple Storage Service (Amazon S3) med mapperne, der repræsenterer etiketterne.
- Brug en lokal computer.
- Brug Ground Truth.
- Opret et datasæt ved hjælp af et eksisterende datasæt med AWS SDK.
- Opret et datasæt med en manifestfil med AWS SDK.
- Efter at datasættene er oprettet, træner vi en Custom Labels-model ved hjælp af CreateProjectVersion API. Dette kan tage fra minutter til timer at fuldføre.
- Efter at modellen er trænet, evaluerer vi modellen ved hjælp af F1-resultatet fra det forrige trin. Vi bruger F1-score som vores evalueringsmetrik, fordi det giver en balance mellem præcision og genkaldelse. Du kan også bruge præcision eller tilbagekaldelse som dine modelevalueringsmålinger. For flere oplysninger om tilpassede etiketevalueringsmetrics, se Metrics til evaluering af din model.
- Vi begynder derefter at bruge modellen til forudsigelser, hvis vi er tilfredse med F1-scoren.
Følgende diagram illustrerer arbejdsgangen Trinfunktioner.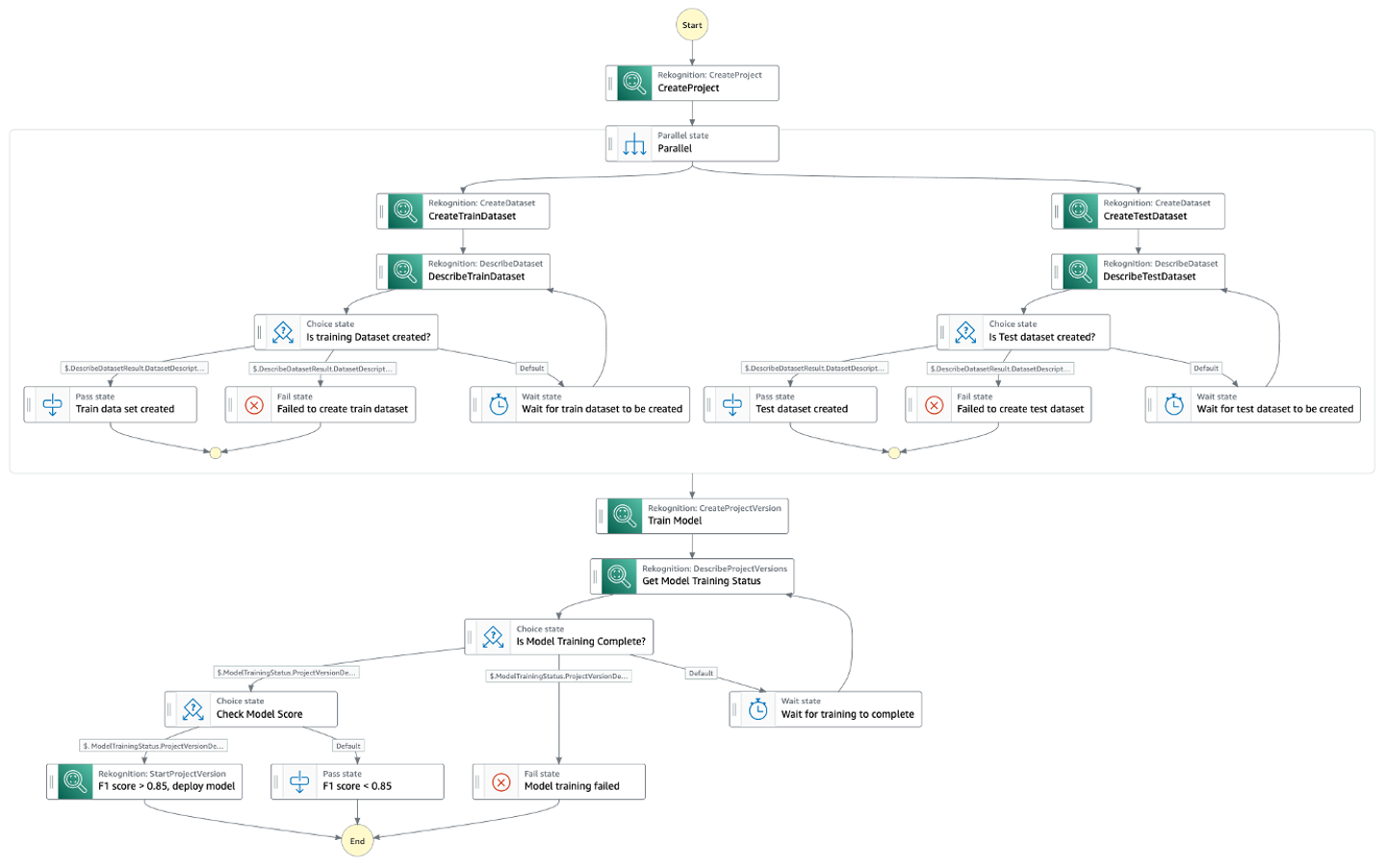
Forudsætninger
Før vi implementerer arbejdsgangen, skal vi oprette de eksisterende trænings- og valideringsdatasæt. Udfør følgende trin:
- First, oprette et Amazon Rekognition-projekt.
- Derefter oprette trænings- og valideringsdatasæt.
- Endelig installer AWS SAM CLI.
Implementer arbejdsgangen
For at implementere arbejdsgangen skal du klone GitHub repository:
Disse kommandoer bygger, pakker og implementerer din applikation til AWS med en række meddelelser som forklaret i lageret.
Kør arbejdsgangen
For at teste arbejdsgangen skal du navigere til den implementerede arbejdsgang på Trinfunktioner-konsollen og derefter vælge Start udførelse.
Workflowet kan tage et par minutter til et par timer at fuldføre. Hvis modellen består evalueringskriterierne, oprettes et slutpunkt for modellen i Amazon Rekognition. Hvis modellen ikke består evalueringskriterierne, eller træningen mislykkedes, fejler arbejdsgangen. Du kan kontrollere status for arbejdsgangen på konsollen Trinfunktioner. For mere information, se Visning og fejlretning af udførelser på Step Functions-konsollen.
Udfør modelforudsigelser
For at udføre forudsigelser mod modellen kan du ringe til Amazon Rekognition DetectCustomLabels API. For at aktivere denne API skal den, der ringer, have det nødvendige AWS identitets- og adgangsstyring (IAM) tilladelser. For flere detaljer om udførelse af forudsigelser ved hjælp af denne API, se Analyse af et billede med en trænet model.
Men hvis du har brug for at eksponere DetectCustomLabels API offentligt, kan du fronte DetectCustomLabels API med Amazon API Gateway. API Gateway er en fuldt administreret tjeneste, der gør det nemt for udviklere at oprette, udgive, vedligeholde, overvåge og sikre API'er i enhver skala. API Gateway fungerer som hoveddøren til din DetectCustomLabels API, som vist i følgende arkitekturdiagram.
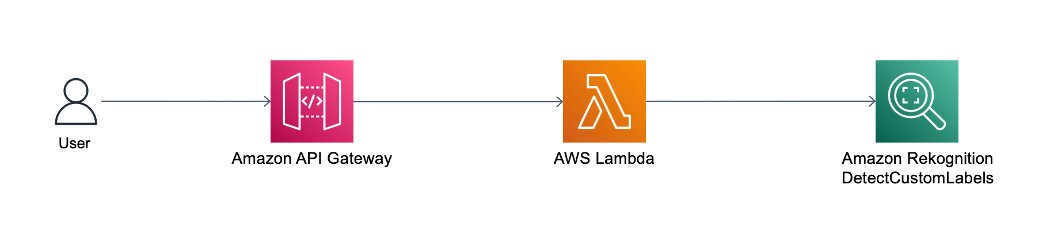
API Gateway videresender brugerens slutningsanmodning til AWS Lambda. Lambda er en serverløs, hændelsesdrevet beregningstjeneste, der lader dig køre kode til stort set enhver type applikation eller backend-tjeneste uden at klargøre eller administrere servere. Lambda modtager API-anmodningen og kalder Amazon Rekognition DetectCustomLabels API med de nødvendige IAM-tilladelser. For mere information om, hvordan du opsætter API Gateway med Lambda-integration, se Konfigurer Lambda proxy integrationer i API Gateway.
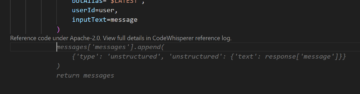
Følgende er et eksempel på en Lambda-funktionskode til at kalde DetectCustomLabels API:
Ryd op
For at slette arbejdsgangen skal du bruge AWS SAM CLI:
For at slette Rekognition Custom Labels-modellen kan du enten bruge Amazon Rekognition-konsollen eller AWS SDK. For mere information, se Sletning af en Amazon Rekognition Custom Labels-model.
Konklusion
I dette indlæg gik vi gennem et Step Functions-arbejdsforløb for at oprette et datasæt og derefter træne, evaluere og bruge en Rekognition Custom Labels-model. Workflowet giver applikationsudviklere og ML-ingeniører mulighed for at automatisere de tilpassede etiketklassificeringstrin for enhver computervisionsbrug. Koden til arbejdsgangen er open source.
For mere serverløse læringsressourcer, besøg Serverløst land. Besøg Tilpassede etiketter til Amazon-genkendelse.
Om forfatteren
 Veda Raman er en Senior Specialist Solutions Architect for machine learning baseret i Maryland. Veda arbejder sammen med kunder for at hjælpe dem med at udvikle effektive, sikre og skalerbare maskinlæringsapplikationer. Veda er interesseret i at hjælpe kunder med at udnytte serverløse teknologier til maskinlæring.
Veda Raman er en Senior Specialist Solutions Architect for machine learning baseret i Maryland. Veda arbejder sammen med kunder for at hjælpe dem med at udvikle effektive, sikre og skalerbare maskinlæringsapplikationer. Veda er interesseret i at hjælpe kunder med at udnytte serverløse teknologier til maskinlæring.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/automate-amazon-rekognition-custom-labels-model-training-and-deployment-using-aws-step-functions/
- :er
- $OP
- 100
- 7
- 8
- a
- Om
- adgang
- præcist
- tværs
- handlinger
- Derudover
- Efter
- mod
- algoritmer
- tillader
- allerede
- Amazon
- Amazon-anerkendelse
- analyse
- analysere
- ,
- api
- API'er
- Anvendelse
- applikationer
- arkitektur
- ER
- AS
- Assembly
- At
- automatisere
- automatisk
- Automatisering
- til rådighed
- AWS
- AWS-trinfunktioner
- Bagende
- Balance
- baseret
- fordi
- bliver
- begynde
- bag
- bag scenen
- mellem
- krop
- bygge
- Bygning
- bygger
- virksomhed
- ringe
- Caller
- Opkald
- CAN
- kapaciteter
- hvilken
- tilfælde
- kategorier
- CD
- tegn
- kontrollere
- Vælg
- klassificering
- Klassificere
- kunde
- kode
- fuldføre
- Compute
- computer
- Computer Vision
- Konsol
- sammenhæng
- kunne
- skabe
- oprettet
- Oprettelse af
- kriterier
- skik
- Kunder
- data
- datasæt
- afgørelser
- indsætte
- indsat
- implementering
- implementering
- detaljer
- Detektion
- udviklere
- direkte
- skelne
- distribueret
- Er ikke
- Ved
- let
- nem at bruge
- effektiv
- enten
- Endpoint
- Ingeniører
- nok
- Ether (ETH)
- evaluere
- evaluere
- evaluering
- begivenhed
- eksempel
- eksisterende
- ekspertise
- forklarede
- f1
- mislykkedes
- mislykkes
- tilbagemeldinger
- få
- File (Felt)
- Finde
- Fornavn
- efter
- følger
- Til
- fra
- forsiden
- fuldt ud
- funktion
- funktioner
- gateway
- generere
- Git
- Ground
- Have
- sund
- tunge
- tunge løft
- hjælpe
- hjælpe
- hjælper
- Hosting
- HOURS
- Hvordan
- How To
- HTML
- HTTPS
- IAM
- identificere
- Identity
- billede
- billedanalyse
- Billedklassificering
- billeder
- in
- oplysninger
- i stedet
- integrere
- integration
- integrationer
- interesseret
- grænseflade
- involverer
- IT
- json
- etiket
- mærkning
- Etiketter
- stor
- LÆR
- læring
- Lets
- Leverage
- løft
- Line (linje)
- belastninger
- lokale
- logo
- maskine
- machine learning
- vedligeholde
- lave
- maerker
- lykkedes
- styring
- manuel
- manuelt arbejde
- mange
- Maryland
- Medier
- metoder
- metrisk
- Metrics
- microservices
- måske
- millioner
- minutter
- ML
- ML algoritmer
- model
- Overvåg
- måned
- mere
- Naviger
- nødvendig
- Behov
- behov
- Ny
- objekt
- Objektdetektion
- of
- on
- OS
- output
- pakke
- Parallel
- dele
- gennemløb
- udføre
- ydeevne
- udfører
- Tilladelser
- planter
- plato
- Platon Data Intelligence
- PlatoData
- Indlæg
- Indlæg
- Precision
- Forudsigelser
- Forbered
- tidligere
- Processer
- Produkter
- projekt
- give
- giver
- proxy
- offentligt
- offentliggøre
- virkelige verden
- realtid
- modtaget
- modtager
- reducere
- Repository
- repræsenterer
- anmode
- kræver
- Kræver
- Ressourcer
- svar
- afkast
- Kør
- s
- sagemaker
- Sam
- tilfreds
- Tilfreds med
- skalerbar
- Scale
- scener
- score
- SDK
- sikker
- senior
- Series
- Serverless
- Servere
- tjeneste
- Tjenester
- sæt
- flere
- hylder
- Vis
- vist
- signifikant
- Simpelt
- ganske enkelt
- siden
- lille
- Social
- sociale medier
- Indlæg på sociale medier
- Løsninger
- specialist
- specifikke
- starte
- Status
- Trin
- Steps
- opbevaring
- butik
- struktur
- Tag
- tager
- hold
- Teknologier
- prøve
- at
- Them
- tusinder
- Gennem
- tid
- til
- Tog
- uddannet
- Kurser
- tog
- typisk
- brug
- brug tilfælde
- validering
- via
- Videoer
- næsten
- vision
- Besøg
- gik
- som
- med
- inden for
- uden
- Arbejde
- workflow
- virker
- Din
- zephyrnet