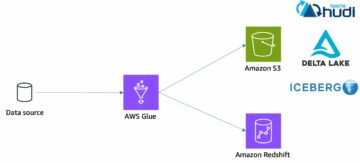
Organisationer har valgt at bygge datasøer ovenpå Amazon Simple Storage Service (Amazon S3) i mange år. En datasø er det mest populære valg for organisationer til at gemme alle deres organisationsdata genereret af forskellige teams, på tværs af forretningsdomæner, fra alle forskellige formater og endda gennem historien. Ifølge et studie, ser den gennemsnitlige virksomhed mængden af deres data vokse med en hastighed, der overstiger 50 % om året, og administrerer normalt i gennemsnit 33 unikke datakilder til analyse.
Teams forsøger ofte at replikere tusindvis af job fra relationelle databaser med det samme udtræk, transformation og indlæsning (ETL) mønster. Der er en stor indsats i at opretholde jobtilstandene og planlægge disse individuelle job. Denne tilgang hjælper teamene med at tilføje tabeller med få ændringer og opretholder også jobstatus med minimal indsats. Dette kan føre til en enorm forbedring af udviklingstidslinjen og let sporing af job.
I dette indlæg viser vi dig, hvordan du nemt kan replikere alle dine relationelle datalagre til en transaktionsdatasø på en automatiseret måde med et enkelt ETL-job ved hjælp af Apache Iceberg og AWS Lim.
Løsningsarkitektur
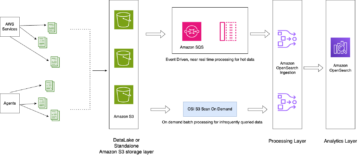
Datasøer er normalt organiseret ved at bruge separate S3-buckets til tre datalag: rålaget, der indeholder data i sin oprindelige form, faselaget, der indeholder mellemliggende behandlede data, der er optimeret til forbrug, og analyselaget, der indeholder aggregerede data til specifikke anvendelsestilfælde. I rålaget er tabeller normalt organiseret baseret på deres datakilder, hvorimod tabeller i faselaget er organiseret baseret på de forretningsdomæner, de tilhører.
Dette indlæg giver en AWS CloudFormation skabelon, der implementerer et AWS Glue-job, der læser en Amazon S3-sti for én datakilde i datasøens rålag og indtager dataene i Apache Iceberg-tabeller på scenelaget ved hjælp af AWS Glue-understøttelse til data lake frameworks. Jobbet forventer, at tabeller i rålaget er struktureret på den måde AWS Database Migration Service (AWS DMS) indtager dem: skema, derefter tabel og derefter datafiler.
Denne løsning bruger AWS Systems Manager Parameter Store til tabelkonfiguration. Du bør ændre denne parameter for at specificere de tabeller, du vil behandle og hvordan, herunder oplysninger såsom primærnøgle, partitioner og det tilknyttede forretningsdomæne. Jobbet bruger disse oplysninger til automatisk at oprette en database (hvis den ikke allerede eksisterer) for hvert forretningsdomæne, oprette Iceberg-tabellerne og udføre dataindlæsningen.
Endelig kan vi bruge Amazonas Athena for at forespørge dataene i Iceberg-tabellerne.
Følgende diagram illustrerer denne arkitektur.

Denne implementering har følgende overvejelser:
- Alle tabeller fra datakilden skal have en primær nøgle for at blive replikeret ved hjælp af denne løsning. Den primære nøgle kan være en enkelt kolonne eller en sammensat nøgle med mere end én kolonne.
- Hvis datasøen indeholder tabeller, der ikke behøver upserts eller ikke har en primær nøgle, kan du ekskludere dem fra parameterkonfigurationen og implementere traditionelle ETL-processer for at indlæse dem i datasøen. Det er uden for rammerne af dette indlæg.
- Hvis der er yderligere datakilder, der skal indlæses, kan du implementere flere CloudFormation-stakke, en til at håndtere hver datakilde.
- AWS Glue-jobbet er designet til at behandle data i to faser: den indledende belastning, der kører efter AWS DMS afslutter den fulde load-opgave, og den trinvise belastning, der kører efter en tidsplan, der anvender ændringsdatafangst-filer (CDC) optaget af AWS DMS. Inkrementel behandling udføres ved hjælp af en AWS Lim job bogmærke.
Der er ni trin til at fuldføre denne øvelse:
- Konfigurer et kildeslutpunkt for AWS DMS.
- Implementer løsningen ved hjælp af AWS CloudFormation.
- Gennemgå AWS DMS-replikeringsopgaven.
- Tilføj eventuelt tilladelser til kryptering og dekryptering eller AWS søformation.
- Gennemgå tabelkonfigurationen i Parameter Store.
- Udfør indledende dataindlæsning.
- Udfør trinvis dataindlæsning.
- Overvåg bordindtagelse.
- Planlæg trinvis batchdataindlæsning.
Forudsætninger
Før du starter denne tutorial, bør du allerede være bekendt med Iceberg. Hvis du ikke er det, kan du komme i gang ved at replikere en enkelt tabel ved at følge instruktionerne i Implementer en CDC-baseret UPSERT i en datasø ved hjælp af Apache Iceberg og AWS Glue. Derudover skal du konfigurere følgende:
Konfigurer et kildeslutpunkt for AWS DMS
Før vi opretter vores AWS DMS-opgave, skal vi konfigurere et kildeslutpunkt for at oprette forbindelse til kildedatabasen:
- På AWS DMS-konsollen skal du vælge Endpoints i navigationsruden.
- Vælg Opret slutpunkt.
- Hvis din database kører på Amazon RDS, skal du vælge Vælg RDS DB-instans, og vælg derefter forekomsten fra listen. Ellers skal du vælge kildemotoren og angive forbindelsesoplysningerne enten igennem AWS Secrets Manager eller manuelt.
- Til Endpoint identifier, indtast et navn til slutpunktet; for eksempel source-postgresql.
- Vælg Opret slutpunkt.
Implementer løsningen ved hjælp af AWS CloudFormation
Opret en CloudFormation-stak ved hjælp af den medfølgende skabelon. Udfør følgende trin:
- Vælg Start stak:

- Vælg Næste.
- Angiv et staknavn, som f.eks
transactionaldl-postgresql. - Indtast de nødvendige parametre:
- DMSS3EndpointIAMRoleARN – IAM-rollen ARN for AWS DMS til at skrive data ind i Amazon S3.
- ReplicationInstanceArn – AWS DMS-replikeringsinstansen ARN.
- S3BucketStage – Navnet på den eksisterende spand, der bruges til datasøens scenelag.
- S3BucketLim – Navnet på den eksisterende S3-spand til opbevaring af AWS Glue-scripts.
- S3BucketRaw – Navnet på den eksisterende spand, der bruges til datasøens rålag.
- SourceEndpointArn – AWS DMS-slutpunktet ARN, som du oprettede tidligere.
- Kildenavn – Den vilkårlige identifikator for den datakilde, der skal replikeres (f.eks.
postgres). Dette bruges til at definere S3-stien for datasøen (rålaget), hvor data vil blive lagret.
- Rediger ikke følgende parametre:
- SourceS3BucketBlog – Bøttens navn, hvor det medfølgende AWS Glue-script er gemt.
- SourceS3BucketPrefix – Bøttepræfiksnavnet, hvor det medfølgende AWS Glue-script er gemt.
- Vælg Næste to gange.
- Type Jeg anerkender, at AWS CloudFormation kan skabe IAM-ressourcer med brugerdefinerede navne.
- Vælg Opret stak.
Efter cirka 5 minutter er CloudFormation-stakken implementeret.
Gennemgå AWS DMS-replikeringsopgaven
AWS CloudFormation-implementeringen skabte et AWS DMS-målslutpunkt for dig. På grund af to specifikke slutpunktsindstillinger vil dataene blive indtaget, efterhånden som vi har brug for dem på Amazon S3.
- På AWS DMS-konsollen skal du vælge Endpoints i navigationsruden.
- Søg efter og vælg det slutpunkt, der begynder med
dmsIcebergs3endpoint. - Gennemgå slutpunktindstillingerne:
DataFormater angivet somparquet.TimestampColumnNamevil tilføje kolonnenlast_update_timemed datoen for oprettelse af posterne på Amazon S3.

Implementeringen opretter også en AWS DMS-replikeringsopgave, der begynder med dmsicebergtask.
- Vælg Replikeringsopgaver i navigationsruden og søg efter opgaven.
Du vil se, at Opgavetype er markeret som Fuld belastning, løbende replikering. AWS DMS vil udføre en indledende fuld belastning af eksisterende data og derefter oprette trinvise filer med ændringer udført i kildedatabasen.
På Kortlægningsregler fanen, er der to typer regler:
- En udvælgelsesregel med navnet på kildeskemaet og tabeller, der indlæses fra kildedatabasen. Som standard bruger den prøvedatabasen, der er angivet i forudsætningerne,
dms_sample, og alle tabeller med søgeordet %. - To transformationsregler, der inkluderer i målfilerne på Amazon S3 skemanavnet og tabelnavnet som kolonner. Dette bruges af vores AWS Glue-job til at vide, hvilke tabeller filerne i datasøen svarer til.
For at lære mere om, hvordan du tilpasser dette til dine egne datakilder, se Udvælgelsesregler og handlinger.

Lad os ændre nogle konfigurationer for at afslutte vores opgaveforberedelse.
- På handlinger menu, vælg Ændre.
- I Opgaveindstillinger afsnit under Stop opgaven efter fuld belastning, vælg Stop efter at have anvendt cachelagrede ændringer.
På denne måde kan vi kontrollere den indledende belastning og den trinvise filgenerering som to forskellige trin. Vi bruger denne to-trins tilgang til at køre AWS Glue-jobbet én gang for hvert trin.
- Under Opgavelogs, vælg Slå CloudWatch-logfiler til.
- Vælg Gem.
- Vent ca. 1 minut, indtil status for databasemigreringsopgaven vises som Ready.
Tilføj tilladelser til kryptering og dekryptering eller Lake Formation
Du kan eventuelt tilføje tilladelser til kryptering og dekryptering eller Lake Formation.
Tilføj kryptering og dekrypteringstilladelser
Hvis dine S3-bøtter, der bruges til rå- og scenelagene, er krypteret vha AWS Key Management Service (AWS KMS) kundeadministrerede nøgler, skal du tilføje tilladelser for at tillade AWS Glue-jobbet at få adgang til dataene:
Tilføj Lake Formation-tilladelser
Hvis du administrerer tilladelser ved hjælp af Lake Formation, skal du tillade dit AWS Glue-job at oprette dit domænes databaser og tabeller gennem IAM-rollen GlueJobRole.
- Giv tilladelser til at oprette databaser (for instruktioner, se Oprettelse af en database).
- Giv SUPER-tilladelser til
defaultdatabasen. - Giv dataplaceringstilladelser.
- Hvis du opretter databaser manuelt, skal du give alle databaser tilladelse til at oprette tabeller. Henvise til Tildeling af tabeltilladelser ved hjælp af Lake Formation-konsollen og den navngivne ressourcemetode or Tildeling af datakatalogtilladelser ved hjælp af LF-TBAC-metoden i henhold til din brugssituation.
Når du har gennemført det senere trin med at udføre den indledende dataindlæsning, skal du sørge for også at tilføje tilladelser for forbrugere til at forespørge i tabellerne. Jobrollen bliver ejer af alle de oprettede tabeller, og datasø-administratoren kan derefter udføre bevillinger til yderligere brugere.
Gennemgå tabelkonfigurationen i Parameter Store
AWS Glue-jobbet, der udfører dataindtagelsen i Iceberg-tabeller, bruger tabelspecifikationen i Parameter Store. Udfør følgende trin for at gennemgå parameterlageret, der blev konfigureret automatisk for dig. Hvis det er nødvendigt, ændres efter dine egne behov.
- På Parameter Store-konsollen skal du vælge Mine parametre i navigationsruden.
CloudFormation-stakken skabte to parametre:
iceberg-configtil jobkonfigurationericeberg-tablestil tabelkonfiguration
- Vælg parameteren isbjerg-borde.
JSON-strukturen indeholder information, som AWS Glue bruger til at læse data og skrive Iceberg-tabellerne på måldomænet:
- Et objekt pr. bord – Navnet på objektet oprettes ved hjælp af skemanavnet, et punktum og tabelnavnet; for eksempel,
schema.table. - primærnøgle – Dette bør angives for hver kildetabel. Du kan angive en enkelt kolonne eller en kommasepareret liste over kolonner (uden mellemrum).
- partitionCols – Dette opdeler valgfrit kolonner for måltabeller. Hvis du ikke ønsker at oprette partitionerede tabeller, skal du angive en tom streng. Ellers skal du angive en enkelt kolonne eller en kommasepareret liste over kolonner, der skal bruges (uden mellemrum).
- Hvis du vil bruge din egen datakilde, skal du bruge følgende JSON-kode og erstatte teksten i CAPS fra den medfølgende skabelon. Hvis du bruger den medfølgende eksempeldatakilde, skal du beholde standardindstillingerne:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Vælg Gem ændringer.
Udfør indledende dataindlæsning
Nu hvor den nødvendige konfiguration er færdig, indtager vi de indledende data. Dette trin omfatter tre dele: indlæsning af data fra den relationelle kildedatabase i datasøens rå lag, oprettelse af Iceberg-tabellerne på datasøens faselag og verifikation af resultater ved hjælp af Athena.
Indtag data i datasøens rå lag
For at indlæse data fra den relationelle datakilde (PostgreSQL, hvis du bruger den leverede prøve) til vores transaktionsdatasø ved hjælp af Iceberg, skal du udføre følgende trin:
- På AWS DMS-konsollen skal du vælge Databasemigreringsopgaver i navigationsruden.
- Vælg den replikeringsopgave, du har oprettet, og på handlinger menu, vælg Genstart/Genoptag.
- Vent ca. 5 minutter på, at replikeringsopgaven er fuldført. Du kan overvåge tabellerne indtaget på Statistik fanen i replikeringsopgaven.

Efter nogle minutter afsluttes opgaven med beskeden Fuld belastning færdig.
- På Amazon S3-konsollen skal du vælge den bøtte, du definerede som rålaget.
Under S3-præfikset defineret på AWS DMS (f.eks. postgres), bør du se et hierarki af mapper med følgende struktur:
- Planlæg
- Tabelnavn
LOAD00000001.parquetLOAD0000000N.parquet
- Tabelnavn

Hvis din S3-spand er tom, skal du gennemgå den Fejlfinding af migreringsopgaver i AWS Database Migration Service før du kører AWS Glue-jobbet.
Opret og indtag data i Iceberg-tabeller
Før vi kører jobbet, lad os navigere i scriptet til AWS Glue-jobbet, der er leveret som en del af CloudFormation-stakken, for at forstå dets adfærd.
- På AWS Glue Studio-konsollen skal du vælge Karriere i navigationsruden.
- Søg efter det job, der starter med
IcebergJob-og et suffiks af dit CloudFormation-staknavn (f.eks.IcebergJob-transactionaldl-postgresql). - Vælg jobbet.

Jobscriptet får den konfiguration, det har brug for, fra Parameter Store. Funktionen getConfigFromSSM() returnerer jobrelaterede konfigurationer såsom kilde- og målinddelinger, hvorfra dataene skal læses og skrives. Variablen ssmparam_table_values indeholde tabelrelaterede oplysninger såsom datadomæne, tabelnavn, partitionskolonner og primærnøgle for de tabeller, der skal indlæses. Se følgende Python-kode:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Scriptet bruger et vilkårligt katalognavn for Iceberg, der er defineret som mit_katalog. Dette er implementeret på AWS Glue Data Catalog ved hjælp af Spark-konfigurationer, så en SQL-handling, der peger på my_catalog, vil blive anvendt på Data Catalog. Se følgende kode:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Scriptet itererer over de tabeller, der er defineret i Parameter Store og udfører logikken til at detektere, om tabellen eksisterer, og om de indkommende data er en indledende indlæsning eller en upsert:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}') initialLoadRecordsSparkSQL() funktionen indlæser startdata, når der ikke er nogen operationskolonne i S3-filerne. AWS DMS tilføjer kun denne kolonne til Parket-datafiler produceret af den kontinuerlige replikering (CDC). Dataindlæsningen udføres ved hjælp af kommandoen INSERT INTO med SparkSQL. Se følgende kode:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Nu kører vi AWS Glue-jobbet for at indlæse de indledende data i Iceberg-tabellerne. CloudFormation-stakken tilføjer --datalake-formats parameter ved at tilføje de nødvendige Iceberg-biblioteker til jobbet.
- Vælg Kør job.
- Vælg Job kører at overvåge status. Vent til status er Kørsel lykkedes.
Bekræft de indlæste data
For at bekræfte, at jobbet behandlede dataene som forventet, skal du udføre følgende trin:
- Vælg på Athena-konsollen Query Editor i navigationsruden.
- Bekræft
AwsDataCataloger valgt som datakilde. - Under Database, vælg det datadomæne, du vil udforske, baseret på den konfiguration, du definerede i parameterlageret. Hvis du bruger den medfølgende eksempeldatabase, skal du bruge
sports.
Under Tabeller og udsigter, kan vi se listen over tabeller, der blev oprettet af AWS Glue-jobbet.
- Vælg indstillingsmenuen (tre prikker) ud for det første tabelnavn, og vælg derefter Forhåndsvis data.
Du kan se dataene indlæst i Iceberg-tabeller. 
Udfør trinvis dataindlæsning
Nu begynder vi at fange ændringer fra vores relationelle database og anvende dem på transaktionsdatasøen. Dette trin er også opdelt i tre dele: at fange ændringerne, anvende dem på Iceberg-tabellerne og verificere resultaterne.
Hent ændringer fra relationsdatabasen
På grund af den konfiguration, vi specificerede, stoppede replikeringsopgaven efter at have kørt hele indlæsningsfasen. Nu genstarter vi opgaven for at tilføje trinvise filer med ændringer i datasøens rå lag.
- På AWS DMS-konsollen skal du vælge den opgave, vi oprettede og kørte før.
- På handlinger menu, vælg CV.
- Vælg Start opgave for at begynde at fange ændringer.
- For at udløse oprettelse af nye filer på datasøen skal du udføre indsættelser, opdateringer eller sletninger på tabellerne i din kildedatabase ved hjælp af dit foretrukne databaseadministrationsværktøj. Hvis du bruger den medfølgende eksempeldatabase, kan du køre følgende SQL-kommandoer:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- På siden med AWS DMS-opgaveoplysninger skal du vælge Tabel statistik fanen for at se de registrerede ændringer.

- Åbn det rå lag af datasøen for at finde en ny fil, der indeholder de trinvise ændringer i hver tabels præfiks, for eksempel under
sporting_eventpræfiks.
Rekorden med ændringer for sporting_event tabel ser ud som følgende skærmbillede.

Læg mærke til Op kolonne i begyndelsen identificeret med en opdatering (U). Den anden dato/tidsværdi er også kontrolkolonnen tilføjet af AWS DMS med det tidspunkt, hvor ændringen blev registreret.

Anvend ændringer på Iceberg-bordene ved hjælp af AWS-lim
Nu kører vi AWS Glue-jobbet igen, og det vil automatisk kun behandle de nye inkrementelle filer, da jobbogmærket er aktiveret. Lad os gennemgå, hvordan det virker.
dedupCDCRecords() funktion udfører deduplikering af data, fordi flere ændringer af et enkelt registrerings-id kunne fanges i den samme datafil på Amazon S3. Deduplikering udføres baseret på last_update_time kolonne tilføjet af AWS DMS, der angiver tidsstemplet for, hvornår ændringen blev registreret. Se følgende Python-kode:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFPå linje 99 upsertRecordsSparkSQL() funktion udfører upsert på samme måde som den oprindelige load, men denne gang med en SQL MERGE-kommando.
Gennemgå de anvendte ændringer
Åbn Athena-konsollen, og kør en forespørgsel, der vælger de ændrede poster i kildedatabasen. Hvis du bruger den medfølgende eksempeldatabase, skal du bruge en af følgende SQL-forespørgsler:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Overvåg bordindtagelse
AWS Glue job scriptet er kodet med enkel Python undtagelseshåndtering at fange fejl under behandling af en specifik tabel. Jobbogmærket gemmes, efter at hver tabel er færdigbehandlet, for at undgå genbearbejdning af tabeller, hvis jobkørsel prøves igen for tabellerne med fejl.
AWS kommandolinjegrænseflade (AWS CLI) giver en get-job-bookmark kommando til AWS Glue, der giver indsigt i status for bogmærket for hver behandlet tabel.
- På AWS Glue Studio-konsollen skal du vælge ETL-jobbet.
- Vælg den Job kører fanen og kopier jobkørsels-id'et.
- Kør følgende kommando på en terminal, der er godkendt til AWS CLI, og erstatter
<GLUE_JOB_RUN_ID>på linje 1 med den værdi, du kopierede. Hvis din CloudFormation-stak ikke er navngivettransactionaldl-postgresql, angiv navnet på dit job på linje 2 i scriptet:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunI denne løsning, når en tabelbehandling forårsager en undtagelse, vil AWS Glue-jobbet ikke fejle ifølge denne logik. I stedet vil tabellen blive tilføjet til en matrix, der udskrives, når jobbet er fuldført. I et sådant scenarie vil jobbet blive markeret som mislykket, efter at det forsøger at behandle resten af de tabeller, der er fundet på den rå datakilde. På denne måde behøver tabeller uden fejl ikke at vente, indtil brugeren identificerer og løser problemet på de modstridende tabeller. Brugeren kan hurtigt opdage jobkørsler, der havde problemer ved hjælp af AWS Glue-jobkørselsstatus, og identificere, hvilke specifikke tabeller der forårsager problemet ved hjælp af CloudWatch-logfilerne for jobkørslen.
- Jobscriptet implementerer denne funktion med følgende Python-kode:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')Følgende skærmbillede viser, hvordan CloudWatch-logfilerne ser ud efter tabeller, der forårsager fejl under behandlingen.

Afstemt med AWS Well-Architected Framework Data Analytics Lens praksis, kan du tilpasse mere sofistikerede kontrolmekanismer for at identificere og underrette interessenter, når der opstår fejl på datapipelines. Du kan f.eks. bruge en Amazon DynamoDB kontroltabel til at gemme alle tabeller og jobkørsler med fejl, eller vha Amazon Simple Notification Service (Amazon SNS) til sende alarmer til operatører når visse kriterier er opfyldt.
Planlæg trinvis batchdataindlæsning
CloudFormation-stakken implementerer en Amazon Eventbridge regel (deaktiveret som standard), der kan udløse AWS Glue-jobbet til at køre efter en tidsplan. For at angive din egen tidsplan og aktivere reglen skal du udføre følgende trin:
- Vælg på EventBridge-konsollen Regler i navigationsruden.
- Søg efter reglen foran med navnet på din CloudFormation-stak efterfulgt af
JobTrigger(for eksempel,transactionaldl-postgresql-JobTrigger-randomvalue). - Vælg reglen.
- Under Arrangementsplan, vælg Redigere.
Standardplanen er konfigureret til at udløse hver time.
- Angiv den tidsplan, du vil udføre jobbet.
- Derudover kan du bruge en EventBridge cron udtryk ved at vælge En finmasket tidsplan.

- Når du er færdig med at opsætte cron-udtrykket, skal du vælge Næste tre gange, og til sidst vælge Opdater regel for at gemme ændringer.
Reglen oprettes deaktiveret som standard for at give dig mulighed for at køre den indledende dataindlæsning først.
- Aktiver reglen ved at vælge Aktiver.
Du kan bruge Overvågning fanen for at se regelpåkaldelser eller direkte på AWS-limen Job Run detaljer.
Konklusion
Efter at have implementeret denne løsning, har du automatiseret indlæsningen af dine tabeller på en enkelt relationel datakilde. Organisationer, der bruger en datasø som deres centrale dataplatform, skal normalt håndtere flere, nogle gange endda snesevis af datakilder. Også flere og flere use cases kræver, at organisationer implementerer transaktionsevner til datasøen. Du kan bruge denne løsning til at fremskynde overtagelsen af sådanne muligheder på tværs af alle dine relationelle datakilder for at muliggøre nye business use cases, automatisere implementeringsprocessen for at få mere værdi ud af dine data.
Om forfatterne
 Luis Gerardo Baeza er en Big Data Architect i Amazon Web Services (AWS) Data Lab. Han har 12 års erfaring med at hjælpe organisationer inden for sundheds-, finans- og uddannelsessektoren med at indføre virksomhedsarkitekturprogrammer, cloud computing og dataanalysefunktioner. Luis hjælper i øjeblikket organisationer på tværs af Latinamerika med at accelerere strategiske datainitiativer.
Luis Gerardo Baeza er en Big Data Architect i Amazon Web Services (AWS) Data Lab. Han har 12 års erfaring med at hjælpe organisationer inden for sundheds-, finans- og uddannelsessektoren med at indføre virksomhedsarkitekturprogrammer, cloud computing og dataanalysefunktioner. Luis hjælper i øjeblikket organisationer på tværs af Latinamerika med at accelerere strategiske datainitiativer.
 SaiKiran Reddy Aenugu er en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 10 års erfaring med implementering af dataindlæsning, transformation og visualiseringsprocesser. SaiKiran hjælper i øjeblikket organisationer i Nordamerika med at indføre moderne dataarkitekturer såsom datasøer og datamesh. Han har erfaring i detail-, fly- og finanssektoren.
SaiKiran Reddy Aenugu er en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 10 års erfaring med implementering af dataindlæsning, transformation og visualiseringsprocesser. SaiKiran hjælper i øjeblikket organisationer i Nordamerika med at indføre moderne dataarkitekturer såsom datasøer og datamesh. Han har erfaring i detail-, fly- og finanssektoren.
 Narendra Merla er en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 12 års erfaring med at designe og produktionsalisere både realtids- og batch-orienterede datapipelines og bygge datasøer i både cloud- og lokale miljøer. Narendra hjælper i øjeblikket organisationer i Nordamerika med at bygge og designe robuste dataarkitekturer og har erfaring inden for telekom- og finanssektoren.
Narendra Merla er en dataarkitekt i Amazon Web Services (AWS) Data Lab. Han har 12 års erfaring med at designe og produktionsalisere både realtids- og batch-orienterede datapipelines og bygge datasøer i både cloud- og lokale miljøer. Narendra hjælper i øjeblikket organisationer i Nordamerika med at bygge og designe robuste dataarkitekturer og har erfaring inden for telekom- og finanssektoren.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Om
- fremskynde
- adgang
- Ifølge
- anerkende
- tværs
- tilpasse
- tilføjet
- Yderligere
- Derudover
- Tilføjer
- admin
- administration
- vedtage
- Vedtagelse
- Efter
- flyselskab
- Alle
- allerede
- Amazon
- Amazonas Athena
- Amazon RDS
- Amazon Web Services
- Amazon Web Services (AWS)
- amerika
- analyse
- analytics
- ,
- Angeles
- Apache
- vises
- Anvendelse
- anvendt
- Anvendelse
- tilgang
- cirka
- arkitektur
- Array
- forbundet
- autentificeret
- automatisere
- Automatiseret
- automatisk
- Automatisering
- gennemsnit
- undgå
- AWS
- AWS CloudFormation
- AWS Lim
- baseret
- flagermus
- fordi
- bliver
- før
- Begyndelse
- Big
- Big data
- bygge
- Builder
- Bygning
- virksomhed
- Kan få
- kapaciteter
- caps
- fange
- Optagelse
- tilfælde
- tilfælde
- katalog
- brydning
- Årsag
- årsager
- forårsager
- CDC
- central
- vis
- lave om
- Ændringer
- valg
- Vælg
- vælge
- valgt
- Cloud
- cloud computing
- kode
- Kolonne
- Kolonner
- selskab
- fuldføre
- computing
- Konfiguration
- konfigurationer
- Bekræfte
- Modstridende
- Tilslut
- tilslutning
- overvejelser
- Konsol
- Forbrugere
- forbrug
- indeholder
- fortsæt
- kontinuerlig
- kontrol
- kunne
- skabe
- oprettet
- skaber
- Oprettelse af
- skabelse
- kriterier
- For øjeblikket
- skik
- kunde
- tilpasse
- data
- Dataanalyse
- Data Lake
- Dataplatform
- Database
- databaser
- Dato
- Standard
- definerede
- indsætte
- indsat
- implementering
- implementering
- udruller
- Design
- konstrueret
- designe
- detaljer
- opdaget
- Udvikling
- forskellige
- direkte
- deaktiveret
- Divided
- Er ikke
- domæne
- Domæner
- Dont
- i løbet af
- hver
- tidligere
- nemt
- Uddannelse
- indsats
- enten
- muliggøre
- aktiveret
- krypteret
- kryptering
- Endpoint
- Engine (Motor)
- Indtast
- Enterprise
- miljøer
- fejl
- Ether (ETH)
- Endog
- Hver
- eksempel
- overstiger
- Undtagen
- undtagelse
- eksisterende
- eksisterer
- forventet
- forventer
- erfaring
- udforske
- udvidelser
- ekstrakt
- mislykkedes
- bekendt
- Mode
- Feature
- få
- File (Felt)
- Filer
- Endelig
- finansiere
- finansielle
- Finde
- slut
- Fornavn
- efterfulgt
- efter
- For forbrugere
- formular
- formation
- Framework
- fra
- fuld
- funktion
- genereret
- generation
- få
- indrømme
- tilskud
- Dyrkning
- håndtere
- sundhedspleje
- hjælpe
- hjælper
- hierarki
- historie
- bedrift
- Hvordan
- How To
- HTML
- HTTPS
- kæmpe
- IAM
- identificeret
- identifikator
- identificerer
- identificere
- gennemføre
- implementering
- implementeret
- gennemføre
- redskaber
- in
- omfatter
- omfatter
- Herunder
- Indgående
- angiver
- individuel
- oplysninger
- initial
- initiativer
- Indsætter
- indsigt
- instans
- i stedet
- anvisninger
- Mellem
- spørgsmål
- spørgsmål
- IT
- iteration
- Job
- Karriere
- json
- Holde
- Nøgle
- nøgler
- Kend
- lab
- sø
- latin
- latin Amerika
- lag
- lag
- føre
- LÆR
- biblioteker
- GRÆNSE
- Line (linje)
- Liste
- belastning
- lastning
- belastninger
- placering
- Se
- UDSEENDE
- den
- Los Angeles
- Lot
- Main
- fastholder
- lave
- lykkedes
- ledelse
- leder
- styring
- manuelt
- mange
- kortlægning
- markeret
- Menu
- Flet
- besked
- måske
- migration
- minimum
- minut
- minutter
- Moderne
- ændre
- Overvåg
- overvågning
- mere
- mest
- Mest Populære
- flere
- navn
- Som hedder
- navne
- Naviger
- Navigation
- Behov
- behov
- behov
- Ny
- næste
- Nord
- nordamerika
- underretning
- nummer
- objekt
- objekter
- ONE
- igangværende
- OP
- drift
- optimeret
- Indstillinger
- organisatorisk
- organisationer
- Organiseret
- original
- Ellers
- uden for
- egen
- ejer
- brød
- parameter
- parametre
- del
- dele
- sti
- Mønster
- udføre
- udfører
- udfører
- periode
- Tilladelser
- fase
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Populær
- Indlæg
- postgresql
- praksis
- foretrækkes
- forudsætninger
- præsentere
- primære
- Problem
- behandle
- Processer
- forarbejdning
- produceret
- Programmer
- give
- forudsat
- giver
- Python
- hurtigt
- rejse
- Sats
- Raw
- rådata
- Læs
- realtid
- optage
- optegnelser
- erstatte
- replikeres
- replikation
- kræver
- påkrævet
- ressource
- Ressourcer
- REST
- Resultater
- detail
- afkast
- afkast
- gennemgå
- robust
- roller
- Herske
- regler
- Kør
- kører
- samme
- Gem
- scenarie
- planlægge
- rækkevidde
- scripts
- Søg
- Anden
- Sektorer
- se
- valgt
- udvælgelse
- valg
- adskille
- Tjenester
- sæt
- indstilling
- indstillinger
- bør
- Vis
- Shows
- lignende
- Simpelt
- siden
- enkelt
- So
- løsninger
- Løser
- nogle
- sofistikeret
- Kilde
- Kilder
- rum
- Spark
- specifikke
- specifikation
- specificeret
- Sport
- SQL
- stable
- Stakke
- Stage
- interessenter
- starte
- påbegyndt
- Starter
- starter
- Stater
- statistik
- Status
- Trin
- Steps
- stoppet
- opbevaring
- butik
- opbevaret
- forhandler
- Strategisk
- struktur
- struktureret
- Studio
- Succesfuld
- sådan
- Super
- support
- Systemer
- bord
- mål
- Opgaver
- opgaver
- hold
- hold
- telecom
- skabelon
- terminal
- The Source
- deres
- tusinder
- tre
- Gennem
- tid
- tidslinje
- gange
- tidsstempel
- til
- værktøj
- top
- I alt
- Sporing
- traditionelle
- transaktionsbeslutning
- Transform
- Transformation
- udløse
- tutorial
- typer
- under
- forstå
- enestående
- Opdatering
- opdateringer
- brug
- brug tilfælde
- Bruger
- brugere
- sædvanligvis
- værdi
- verificere
- Specifikation
- visualisering
- bind
- vente
- Warehouse
- web
- webservices
- som
- vilje
- inden for
- uden
- virker
- skriver
- skriftlig
- yaml
- år
- år
- Din
- zephyrnet