I dataanalyseområdet beskæftiger organisationer sig ofte med mange tabeller i forskellige databaser og filformater for at opbevare data for forskellige forretningsfunktioner. Forretningsbehov driver ofte tabelstruktur, såsom skemaudvikling (tilføjelse af nye kolonner, fjernelse af eksisterende kolonner, opdatering af kolonnenavne og så videre) for nogle af disse tabeller i en forretningsfunktion, der kræver, at andre forretningsfunktioner replikerer det samme . Dette indlæg fokuserer på sådanne skemaændringer i filbaserede tabeller og viser, hvordan man automatisk replikerer skemaudviklingen af strukturerede data fra tabelformater i databaser til tabellerne gemt som filer på en omkostningseffektiv måde.
AWS Lim er en serverløs dataintegrationstjeneste, der gør det nemt at opdage, forberede og kombinere data til analyse, maskinlæring (ML) og applikationsudvikling. I dette indlæg viser vi, hvordan du bruger Apache Hudi, et selvadministrerende databaselag på filbaserede datasøer, i AWS Glue til automatisk at repræsentere data i relationel form og styre deres skemaudvikling i skala ved hjælp af Amazon Simple Storage Service (Amazon S3), AWS Database Migration Service (AWS DMS), AWS Lambda, AWS Lim, Amazon DynamoDB, Amazon Auroraog Amazonas Athena til automatisk at identificere skemaudvikling og anvende den til at styre databelastning i petabyte-skala.
Apache Hudi understøtter ACID-transaktioner og CRUD-operationer på en datasø. Dette lægger grundlaget for en datasø-arkitektur ved at muliggøre transaktionsunderstøttelse og skemaudvikling og -styring, afkoble lagring fra computer og sikre understøttelse af tilgængelighed gennem Business Intelligence (BI) værktøjer. I dette indlæg implementerer vi en arkitektur til at bygge en transaktionsdatasø bygget på de førnævnte Hudi-funktioner.
Løsningsoversigt
Dette indlæg antager et scenario, hvor flere tabeller er til stede i en kildedatabase, og vi ønsker at replikere eventuelle skemaændringer i nogen af disse tabeller i Apache Hudi-tabeller i datasøen. Den bruger indbygget support til Apache Hudi på AWS Glue for Apache Spark.
I dette indlæg er skemaudviklingen af kildetabeller i Aurora-databasen fanget via AWS DMS inkrementel indlæsning eller ændring af datafangst (CDC) mekanisme, og den samme skemaudvikling er replikeret i Apache Hudi-tabeller gemt i Amazon S3. Apache Hudi-tabeller opdages af AWS Glue Data Catalog og forespørges af Athena. Et AWS Glue-job, understøttet af en orkestreringspipeline ved hjælp af Lambda og en DynamoDB-tabel, tager sig af den automatiserede replikering af skemaudvikling i Apache Hudi-tabellerne.
Vi bruger Aurora som en eksempeldatakilde, men enhver datakilde, der understøtter CRUD-operationer (Opret, Læs, Opdater og Slet) kan erstatte Aurora i dit tilfælde.
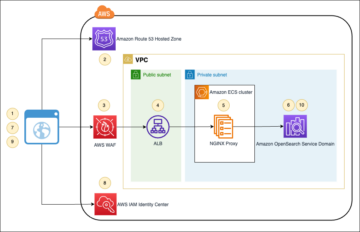
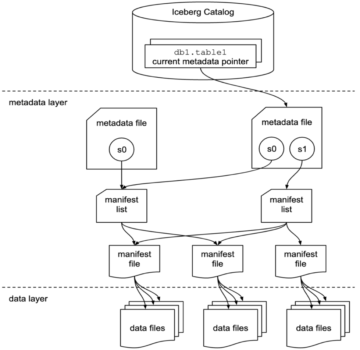
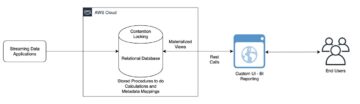
Følgende diagram illustrerer vores løsningsarkitektur.

Løsningens flow er som følger:
- Aurora, som en eksempeldatakilde, indeholder en RDBMS-tabel med flere rækker, og AWS DMS udfører den fulde indlæsning af disse data til en S3-bucket (som vi kalder den rå bucket). Vi forventer, at du kan have flere kildetabeller, men til demonstrationsformål bruger vi kun én kildetabel i dette indlæg.
- Vi udløser en Lambda-funktion med kildetabelnavnet som en hændelse, så de tilsvarende parametre for kildetabellen læses fra DynamoDB. For at planlægge denne operation til bestemte tidsintervaller, vi planlægge Amazon Eventbridge for at udløse Lambdaen med tabelnavnet som parameter.
- Der er mange tabeller i kildedatabasen, og vi ønsker at køre et AWS Glue-job for hver kildetabel for enkelhedens skyld. Fordi vi bruger hvert AWS Glue-job til at opdatere hver Apache Hudi-tabel, bruger dette indlæg en DynamoDB-tabel til at indeholde de konfigurationsparametre, der bruges af hvert AWS Glue-job for hver Apache Hudi-tabel. DynamoDB-tabellen indeholder hvert Apache Hudi-tabelnavn, tilsvarende AWS-limjobnavn, AWS-limjobstatus, indlæsningsstatus (fuld eller delta), partitionsnøgle, registreringsnøgle og skema, der skal overføres til den tilsvarende tabels AWS-limjob. Værdierne i DynamoDB-tabellen er statiske værdier.
- For at udløse hvert AWS Glue-job (10 G.1X DPU'er) parallelt for at køre en Apache Hudi-specifik kode for at indsætte data i de tilsvarende Hudi-tabeller, sender Lambda hver Apache Hudi-tabelspecifikke parametre læst fra DynamoDB til hvert AWS Glue-job. Kildedataene kommer fra tabeller i Aurora-kildedatabasen via AWS DMS med fuld belastning og inkrementel belastning eller CDC.
Opret ressourcer med AWS CloudFormation
Vi leverer en AWS CloudFormation skabelon til at oprette følgende ressourcer:
- Lambda og DynamoDB som orkestratorer for databelastningsstyring
- S3-spande til den rå, raffinerede zone og aktiver til at holde kode til skemaudvikling
- Et AWS Glue-job til at opdatere Hudi-tabellerne og udføre skemaudvikling, både fremad- og bagudkompatibel
Aurora-tabellen og AWS DMS-replikeringsinstansen leveres ikke via denne stak. For instruktioner til opsætning af Aurora, se Oprettelse af en Amazon Aurora DB-klynge.
Start den følgende stak og angiv dit staknavn.
eu-west-1 |
Skema udvikling
For at få adgang til din Aurora-database, se Hvordan opretter jeg forbindelse til min Amazon RDS for MySQL-instans ved at bruge MySQL Workbench. Udfør derefter følgende trin:
- Opret en tabel med navnet objekt efter forespørgslerne i Aurora-databasen og skift dets skema, så vi kan se skemaudviklingen afspejles på datasø-niveau:
Når du har oprettet stakkene, er nogle manuelle trin nødvendige for at forberede løsningen fra ende til anden.
- Opret et AWS DMS instans, AWS DMS endpointsog AWS DMS opgave med følgende konfigurationer:
- Tilføj dataFormat som parket i målendepunktet.
- Peg målendepunktet for AWS DMS til den rå bucket, som er formateret som
raw-bucket-<account_number>-<region_name>, og mappenavnet skal være POC.
- Start AWS DMS-opgaven.
- Opret en testbegivenhed i
HudiLambdaLambda-funktion med indholdet af begivenheden JSON somPOC.dbog gem det. - Kør Lambda-funktionen.
I dette indlæg reflekteres skemaudviklingen igennem Hudi Hive synkronisering i AWS Lim. Du ændrer ikke forespørgsler separat i datasøen.
Nu fuldfører vi følgende trin for at ændre skemaet ved kilden. Udløs Lambda-funktionen efter hvert trin for at generere en fil i POC/db/object mappe i råbøtten. AWS DMS opfanger næsten øjeblikkeligt skemaændringerne og rapporterer til råbøtten.
- Tilføj en kolonne kaldet
test_columntil kildetabellenobjecti din Aurora-database:
- Omdøb kolonnen
new_field_1tilnew_field_2i kildetabelobjektet:
Kolonnen new_field_1 forventes at forblive i Hudi-tabellen, men uden at der længere er tilføjet nogen nye værdier til den.
- Slet kolonnen
new_field_2fra kildetabelobjektet:
Svarende til den forrige operation, kolonnen new_field_2 forventes at forblive i Hudi-tabellen, men uden at der længere er tilføjet nogen nye værdier til den.
Hvis du allerede har AWS søformation datatilladelser opsat på din konto, kan du støde på tilladelsesproblemer. I så fald skal du give fuld tilladelse (Super) til standarddatabasen (før udløsning af Lambda-funktionen) og alle tabeller i POC.db database (efter at belastningen er fuldført).
Gennemgå resultaterne
Når den førnævnte kørsel sker efter skemaændringer, genereres følgende resultater i den raffinerede bucket. Vi kan se Apache Hudi-tabellerne med dets indhold i Athena. For at konfigurere Athena, se Kom godt i gang.
Tabellen og databasen er tilgængelige i AWS Glue Data Catalog og klar til at gennemse skemaet.
Før skemaændringen ser Athena-resultaterne ud som følgende skærmbillede.
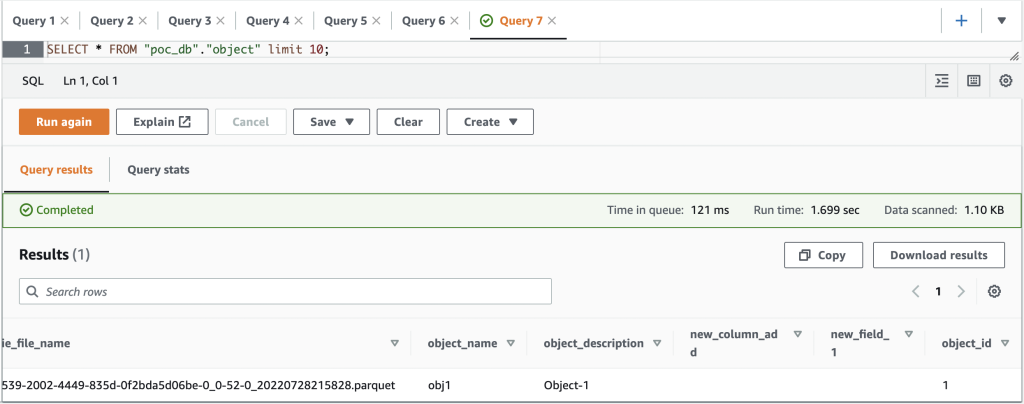
Når du har tilføjet kolonnen test_column og indsæt en værdi i test_column felt i objekttabellen i Aurora-databasen, den nye kolonne (test_column) afspejles i dens tilsvarende Apache Hudi-tabel i datasøen.
Følgende skærmbillede viser resultaterne i Athena.

Når du har omdøbt kolonnen new_field_1 til new_field_2 og indsæt en værdi i new_field_2 felt i objekttabellen, den omdøbte kolonne (new_field_2) afspejles i dens tilsvarende Apache Hudi-tabel i datasøen, og new_field_1 forbliver i skemaet og har ingen ny værdi udfyldt i kolonnen.
Følgende skærmbillede viser resultaterne i Athena.
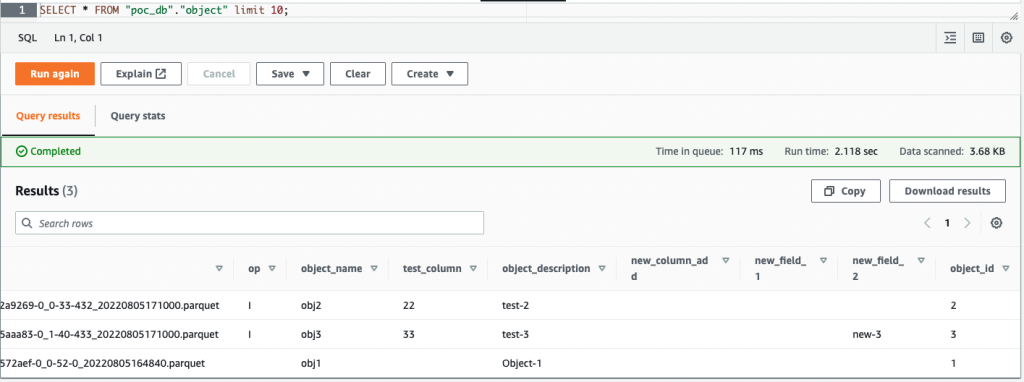
Når du har slettet kolonnen new_field_2 i objekttabellen og indsæt eller opdater eventuelle værdier under alle kolonner i objekttabellen, den slettede kolonne (new_field_2) forbliver i det tilsvarende Apache Hudi-tabelskema og har ingen ny værdi udfyldt i kolonnen.
Følgende skærmbillede viser resultaterne i Athena.

Ryd op
Når du er færdig med denne løsning, skal du slette prøvedataene i de rå og raffinerede S3-bøtter og slette buckets.
Slet også CloudFormation-stakken for at fjerne alle de serviceressourcer, der bruges i denne løsning.
Konklusion
Dette indlæg viste, hvordan man implementerer skemaudvikling med en open source-løsning ved hjælp af Apache Hudi i et AWS-miljø med en orkestreringspipeline.
Du kan udforske de forskellige konfigurationer af AWS Glue for at ændre AWS Glue-jobstrukturerne og implementere det til dine dataanalyser og andre use cases.
Om forfatterne
 Subhro Bose er en Senior Data Architect i Emergent Technologies og Intelligence Platform i Amazon. Han elsker at løse videnskabelige problemer med nye teknologier såsom AI/ML, big data, quantum og mere for at hjælpe virksomheder på tværs af forskellige brancher med succes med deres innovationsrejse. I sin fritid nyder han at spille bordtennis, lære teorier om miljøøkonomi og udforske de bedste muffins i hele byen.
Subhro Bose er en Senior Data Architect i Emergent Technologies og Intelligence Platform i Amazon. Han elsker at løse videnskabelige problemer med nye teknologier såsom AI/ML, big data, quantum og mere for at hjælpe virksomheder på tværs af forskellige brancher med succes med deres innovationsrejse. I sin fritid nyder han at spille bordtennis, lære teorier om miljøøkonomi og udforske de bedste muffins i hele byen.
 Ketan Karalkar er Big Data Solutions Consultant hos AWS. Han har næsten 2 årtiers erfaring med at hjælpe kunder med at designe og bygge dataanalyse og databaseløsninger. Han tror på at bruge teknologi som en muliggører til at løse virkelige forretningsproblemer.
Ketan Karalkar er Big Data Solutions Consultant hos AWS. Han har næsten 2 årtiers erfaring med at hjælpe kunder med at designe og bygge dataanalyse og databaseløsninger. Han tror på at bruge teknologi som en muliggører til at løse virkelige forretningsproblemer.
 Eva Fang er Data Scientist indenfor Professional Services i AWS. Hun brænder for at bruge teknologien til at give værdi til kunderne og opnå forretningsresultater. Hun er baseret i London, i sin fritid kan hun lide at se film og musicals.
Eva Fang er Data Scientist indenfor Professional Services i AWS. Hun brænder for at bruge teknologien til at give værdi til kunderne og opnå forretningsresultater. Hun er baseret i London, i sin fritid kan hun lide at se film og musicals.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/automate-schema-evolution-at-scale-with-apache-hudi-in-aws-glue/
- 1
- 10
- 100
- 107
- 11
- 7
- a
- Om
- adgang
- tilgængelighed
- Konto
- opnå
- tværs
- Desuden
- Efter
- AI / ML
- Alle
- allerede
- Amazon
- Amazon RDS
- amp
- analytics
- ,
- Apache
- Anvendelse
- Application Development
- Indløs
- arkitektur
- Aktiver
- Aurora
- automatisere
- Automatiseret
- automatisk
- til rådighed
- AWS
- AWS Lim
- baseret
- fordi
- før
- være
- mener
- BEDSTE
- Big
- Big data
- Browsing
- bygge
- bygget
- virksomhed
- forretningsfunktioner
- business intelligence
- virksomheder
- ringe
- kaldet
- fange
- hvilken
- tilfælde
- tilfælde
- katalog
- CDC
- lave om
- Ændringer
- By
- kode
- Kolonne
- Kolonner
- kombinerer
- fuldføre
- Compute
- Konfiguration
- konfigurationer
- Tilslut
- konsulent
- indeholder
- indhold
- indhold
- Tilsvarende
- omkostningseffektiv
- skabe
- Oprettelse af
- Kunder
- data
- Dataanalyse
- dataintegration
- Data Lake
- dataforsker
- Database
- databaser
- deal
- årtier
- Standard
- Delta
- Design
- Udvikling
- forskellige
- opdage
- opdaget
- Dont
- køre
- Drop
- hver
- Økonomi
- muliggør
- møde
- Endpoint
- sikring
- Miljø
- miljømæssige
- Ether (ETH)
- begivenhed
- evolution
- eksisterende
- forvente
- forventet
- erfaring
- udforske
- Funktionalitet
- felt
- File (Felt)
- Filer
- flow
- fokuserer
- efter
- følger
- formular
- Foundation
- fra
- fuld
- funktion
- funktioner
- generere
- genereret
- indrømme
- sker
- have
- hjælpe
- hjælpe
- Hive
- hold
- bedrift
- Hvordan
- How To
- HTML
- HTTPS
- identificere
- gennemføre
- in
- industrien
- Innovation
- instans
- anvisninger
- integration
- Intelligens
- spørgsmål
- IT
- Job
- rejse
- json
- Nøgle
- sø
- lag
- Lays
- LÆR
- læring
- Niveau
- Livet
- belastning
- London
- Se
- ligner
- maskine
- machine learning
- maerker
- administrere
- ledelse
- manuel
- mange
- mekanisme
- migration
- ML
- mere
- Film
- flere
- MySQL
- navn
- Som hedder
- navne
- næsten
- behov
- behov
- Ny
- objekt
- ONE
- open source
- drift
- Produktion
- orkestrering
- organisationer
- Andet
- Parallel
- parameter
- parametre
- gennemløb
- lidenskabelige
- udføre
- tilladelse
- Tilladelser
- petabytes
- picks
- pipeline
- perron
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- PoC
- befolkede
- Indlæg
- Forbered
- præsentere
- tidligere
- problemer
- professionel
- give
- formål
- Quantum
- Raw
- Læs
- klar
- ægte
- I virkeligheden
- optage
- raffinerede
- afspejles
- resterne
- fjernelse
- Fjern
- erstatte
- replikeres
- replikation
- Rapporter
- repræsentere
- Kræver
- Ressourcer
- Resultater
- Kør
- samme
- Gem
- Scale
- scenarie
- planlægge
- Videnskab
- Videnskabsmand
- senior
- Serverless
- tjeneste
- Tjenester
- sæt
- bør
- Vis
- Shows
- Simpelt
- enkelhed
- So
- løsninger
- Løsninger
- SOLVE
- Løsning
- nogle
- Kilde
- Space
- specifikke
- stable
- Stakke
- Status
- forblive
- Trin
- Steps
- opbevaring
- opbevaret
- struktur
- struktureret
- lykkes
- sådan
- Super
- support
- Understøttet
- Understøtter
- bord
- tager
- mål
- Opgaver
- Teknologier
- Teknologier
- skabelon
- tennis
- prøve
- The Source
- deres
- Gennem
- tid
- til
- værktøjer
- transaktion
- transaktionsbeslutning
- Transaktioner
- udløse
- udløsning
- under
- Opdatering
- brug
- brug tilfælde
- værdi
- Værdier
- vertikaler
- via
- Specifikation
- Ur
- som
- inden for
- uden
- Din
- zephyrnet