Datastyring er en samling af politikker, processer og systemer, som organisationer bruger til at sikre kvaliteten og passende håndtering af deres data gennem hele deres livscyklus med det formål at skabe forretningsværdi. Datastyring er i stigende grad top-of-mind for kunder, da de anerkender data som et af deres vigtigste aktiver. Effektiv datastyring muliggør bedre beslutningstagning ved at forbedre datakvaliteten, reducere omkostningerne til dataadministration og sikre sikker adgang til data for interessenter. Derudover er dataforvaltning påkrævet for at overholde et stadig mere komplekst reguleringsmiljø med databeskyttelse (såsom GDPR og CCPA) og regler om dataophold (såsom i EU, Rusland og Kina).
For AWS-kunder forbedrer effektiv datastyring beslutningstagning, øger virksomhedens smidighed, giver en konkurrencefordel og reducerer risikoen for bøder på grund af manglende overholdelse af lovpligtige forpligtelser. Vi forstår den unikke mulighed for at give vores kunder en omfattende end-to-end datastyringsløsning, der er problemfrit integreret i vores portefølje af tjenester, og AWS søformation og AWS Glue Data Katalog er nøglen til at løse disse udfordringer.
I dette indlæg er vi glade for at opsummere de funktioner, som AWS Glue Data Catalog, AWS Glue crawler- og Lake Formation-teamene leverede i 2022. Vi har samlet nogle af nøgletalkerne og løsningerne om datastyring, datamesh og moderne data arkitektur udgivet og præsenteret i AWS re:Invent 2022, og et par datasøløsninger bygget af kunder og AWS-partnere til nem reference. Uanset om du er en dataplatformbygger, dataingeniør, dataforsker eller en hvilken som helst teknologileder, der er interesseret i data lake-løsninger, er dette indlæg for dig.
For at lære mere om, hvordan kunder sikrer og deler data med Lake Formation, anbefaler vi at gå dybere ind i GoDaddy's decentraliseret datanet, Novo Nordisks moderne dataarkitektur, og JPMorgans forbedringer af deres Federated Data Lake, en styret data mesh-implementering ved hjælp af Lake Formation. Du kan også lære, hvordan AWS Partners integrerede med Lake Formation for at hjælpe kunder med at bygge unikke datasøer i Starburst's data mesh-løsning, Informatica's automatiseret datadelingsløsning, Ahanas Presto integration med Lake Formation, Stigende skik datastyringssystem, hvordan PBS bruges maskinlæring på deres datasøer, og hvordan hc1 giver personlig sundhedsindsigt for kunder.
Du kan gennemgå, hvordan Lake Formation bruges af kunder til at bygge moderne dataarkitekturer i følgende re:Invent 2022 talks:
Lake Formation-teamet lyttede til kundernes feedback og lavede forbedringer inden for datastyring på tværs af konti, udvidelse af kilden til datasøer, muliggør ensartet datastyring af et virksomhedsdatakatalog, hvilket gør sikker business-to-business datadeling mulig, og udvidelse af dækningsområdet for finmasket adgangskontrol til Amazon rødforskydning. I resten af dette indlæg deler vi gerne de fremskridt, vi gjorde i 2022.
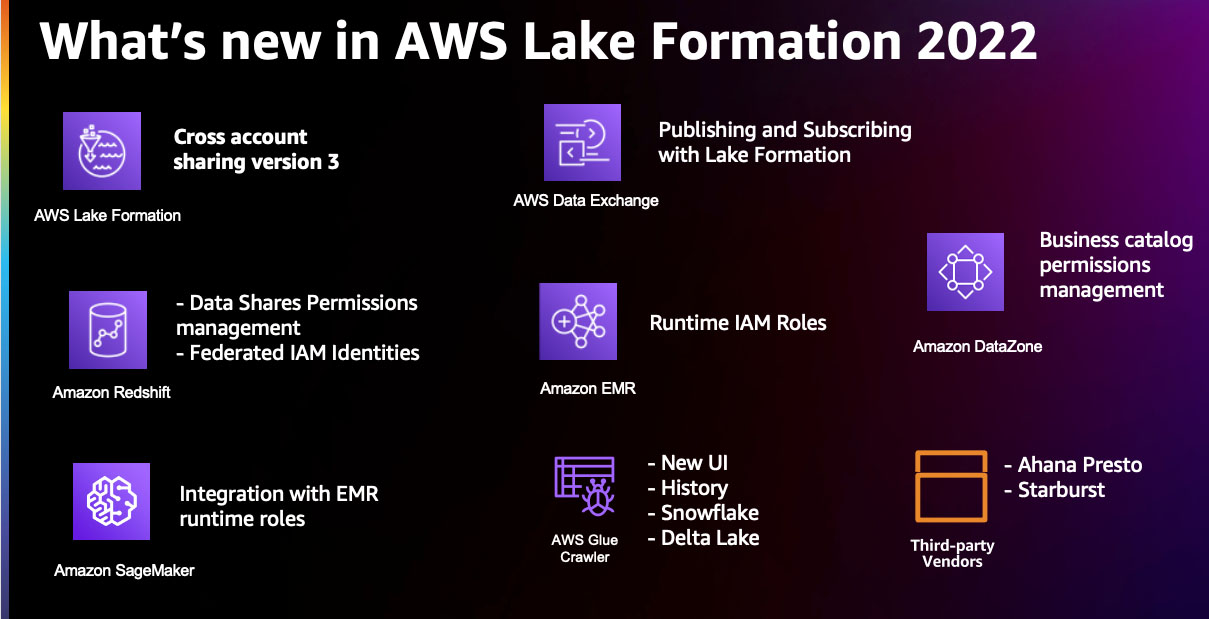
Forbedring af styring på tværs af konti
Lake Formation danner grundlaget for, at kunder kan dele data på tværs af konti i deres organisation. Du kan dele AWS Glue Data Catalog-ressourcer til AWS identitets- og adgangsstyring (IAM) principaler inden for en konto såvel som andre AWS-konti ved hjælp af to metoder. Den første kaldes named-resource-metoden, hvor brugere kan vælge navnene på databaser og tabeller og vælge den type tilladelser, der skal deles. Den anden metode bruger LF-tags, hvor brugere kan oprette og knytte LF-tags til databaser og tabeller og give tilladelse til IAM principaler ved hjælp af LF-Tag politikker og udtryk.
I november 2022 introducerede Lake Formation version 3 af sin funktion til deling på tværs af konti. Med denne nye version kan Lake Formation-brugere dele katalogressourcer ved hjælp af LF-tags på AWS-organisationer niveau. Deling af data ved hjælp af LF-tags hjælper med at skalere tilladelser og reducerer administrationsarbejdet for datasøbyggere. Deling på tværs af konti version 3 giver dig også mulighed for at dele ressourcer til specifikke IAM-princippere på andre konti, hvilket giver dataejere kontrol over, hvem der kan få adgang til deres data på andre konti. Endelig har vi fjernet overheaden med at skrive og vedligeholde ressourcepolitikker for datakatalog ved at introducere AWS Resource Access Manager (AWS RAM)-invitationer med LF-Tags-baserede politikker i version 3 til deling på tværs af konti. Vi opfordrer dig til at udforske yderligere deling på tværs af konti i Lake Formation.
Udvidelse af Lake Formation-tilladelser til nye data
Indtil re:Invent 2022 leverede Lake Formation tilladelsesstyring til IAM-princippere på datakatalogressourcer med underliggende data primært på Amazon Simple Storage Service (Amazon S3). På re:Invent 2022 introducerede vi Administration af Lake Formation-tilladelser for Amazon Redshift-datadelinger i preview-tilstand. Amazon Redshift er en fuldt administreret, petabyte-skala datavarehustjeneste i AWS Cloud. Det datadelingsfunktion giver dataejere mulighed for at gruppere databaser, tabeller og visninger i en Amazon Redshift-klynge og dele dem med andre Amazon Redshift-klynger inden for eller på tværs af AWS-konti. Datadeling reducerer behovet for at opbevare flere kopier af de samme data i forskellige datavarehuse for at fremskynde forretningsbeslutninger på tværs af en organisation. Lake Formation forbedrer yderligere deling af data inden for Amazon Redshift-datadelinger ved at give finmasket adgangskontrol på tabeller og visninger.
For yderligere detaljer om denne funktion, se AWS Lake Formation-administrerede Redshift-datadelinger (forhåndsvisning) , Hvordan Redshift-dataandel kan administreres af Lake Formation.
Amazon EMR er en administreret klyngeplatform til at køre big data-applikationer ved hjælp af Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi og Presto i stor skala. Du kan bruge Amazon EMR til at køre batch- og streambehandlingsanalysejob på dine S3-datasøer. Startende med Amazon EMR release 6.7.0 introducerede vi Administration af Lake Formation-tilladelser på en runtime IAM-rolle bruges sammen med EMR Steps API. Denne funktion giver dig mulighed for at indsende Apache Spark- og Apache Hive-applikationer til en EMR-klynge gennem EMR Steps API, der håndhæver tilladelser på tabelniveau og kolonneniveau ved hjælp af Lake Formation til den IAM-rolle, der indsender ansøgningen. Denne Lake Formation-integration med Amazon EMR giver dig mulighed for at dele en EMR-klynge på tværs af flere brugere i en organisation med forskellige tilladelser ved at isolere dine applikationer gennem en runtime IAM-rolle. Vi opfordrer dig til at tjekke denne funktion i Lake Formation-værkstedet Integration med Amazon EMR ved hjælp af Runtime-roller. For at udforske en use case, se Introduktion af runtime-roller til Amazon EMR-trin: Brug IAM-roller og AWS Lake Formation til adgangskontrol med Amazon EMR.
Amazon SageMaker Studio er et fuldt integreret udviklingsmiljø (IDE) til maskinlæring (ML), der gør det muligt for datavidenskabsfolk og udviklere at forberede data til opbygning, træning, tuning og implementering af modeller. Studio tilbyder en indbygget integration med Amazon EMR, så dataforskere og dataingeniører interaktivt kan forberede data i petabyte-skala ved hjælp af open source-frameworks såsom Apache Spark, Presto og Hive ved hjælp af Studio-notebooks. Med udgivelsen af Administration af Lake Formation-tilladelser på en runtime IAM-rolle, Studio understøtter nu adgang på tabelniveau og kolonneniveau med Lake Formation. Når brugere opretter forbindelse til EMR-klynger fra Studio-notebooks, kan de vælge IAM-rollen (kaldet runtime IAM-rolle), som de ønsker at forbinde med. Hvis dataadgang administreres af Lake Formation, kan brugere håndhæve tilladelser på tabelniveau og kolonneniveau ved hjælp af politikker knyttet til runtime-rollen. For flere detaljer, se Anvend finkornede dataadgangskontroller med AWS Lake Formation og Amazon EMR fra Amazon SageMaker Studio.
Indtag og katalogiserer forskellige data
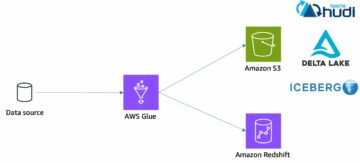
En robust datastyringsmodel inkluderer data fra en organisations mange datakilder og metoder til at opdage og katalogisere disse forskellige dataaktiver. AWS Glue-crawlere giver mulighed for at opdage data fra kilder, herunder Amazon S3, Amazon Redshift og NoSQL-databaser, og udfylde AWS Glue Data Catalog.
I 2022 lancerede vi AWS Glue crawler støtte til Snowflake , AWS Glue crawler støtte til Delta Lake borde. Disse integrationer giver AWS Glue-crawlere mulighed for at oprette og opdatere datakatalogtabeller baseret på disse populære datakilder. Dette gør det endnu nemmere at oprette udtrække, transformere og indlæse (ETL) jobs med AWS Glue baseret på disse datakatalogtabeller som kilder og mål.
I 2022 blev AWS Glue crawlers UI redesignet for at tilbyde en bedre brugeroplevelse. En af de vigtigste forbedringer leveret som en del af denne revision er den større indsigt i AWS Glue-crawler-historien. Webcrawlerhistorik-brugergrænsefladen giver en nem visning af crawler-kørsler, tidsplaner, datakilder og tags. For hver gennemgang tilbyder crawlerhistorikken en oversigt over ændringer i databaseskemaet eller Amazon S3-partitionsændringer. Crawler-historik giver også detaljerede oplysninger om DPU-timer og reducerer den tid, der bruges på at analysere og fejlfinde crawlerens operationer og omkostninger. For at udforske de nye funktioner, der er tilføjet til crawlerens brugergrænseflade, se Konfigurer og overvåg AWS Glue-crawlere ved hjælp af den forbedrede AWS Glue UI og crawlerhistorik.
I 2022 udvidede vi også understøttelsen af crawlere baseret på Amazon S3-begivenhedsmeddelelser til at understøtte katalogtabeller. Med denne funktion kan trinvis crawl aflastes fra datapipelines til den planlagte AWS Glue-crawler, hvilket reducerer crawl til trinvise S3-hændelser. For mere information, se Byg trinvise gennemgange af datasøer med eksisterende Glue-katalogtabeller.
Flere måder at dele data på ud over datasøen
Under re:Invent 2022 annoncerede vi en forhåndsvisning af AWS Data Exchange for AWS Lake Formation, en ny funktion, der gør det muligt for dataabonnenter at finde og abonnere på tredjepartsdatasæt, der administreres direkte gennem Lake Formation. Indtil nu, AWS dataudveksling abonnenter kunne få adgang til tredjeparts datasæt ved at eksportere udbyderes filer til deres egne S3 buckets, kalde udbyderes API'er gennem Amazon API Gateway, eller forespørgsel på producenters Amazon Redshift-dataandele fra deres Amazon Redshift-klynge. Med den nye Lake Formation-integration kuraterer dataudbydere AWS Data Exchange-datasæt ved hjælp af Lake Formation-tags. Dataabonnenter er i stand til at forespørge og udforske de databaser og tabeller, der er knyttet til disse tags, ligesom enhver anden AWS Glue Data Catalog-ressource. Organisationer kan anvende ressourcebaserede Lake Formation-tilladelser til at dele de licenserede datasæt inden for den samme konto eller på tværs af konti ved hjælp af AWS Licens Manager. AWS Data Exchange for Lake Formation strømliner datalicenser og -delingsoperationer ved at accelerere data onboarding, reducere mængden af ETL, der kræves for slutbrugere for at få adgang til tredjepartsdata, og centralisere styring og adgangskontrol for tredjepartsdata.
På re:Invent 2022 annoncerede vi også Amazon DataZone, en ny dataadministrationstjeneste, der gør det hurtigere og nemmere for dig at katalogisere, opdage, dele og styre data, der er lagret på tværs af AWS, lokale og tredjepartskilder. Amazon DataZone er en virksomhedsdatakatalogtjeneste, der supplerer de tekniske metadata i AWS Glue Data Catalog. Amazon DataZone er integreret med Lake Formation tilladelsesstyring, så du effektivt kan administrere og styre adgangen til dine data og kontrollere, hvem der har adgang til hvilke data og til hvilket formål. Med Amazon DataZone-udgiver-abonnentmodellen kan dataaktiver deles og tilgås på tværs af regioner. For yderligere detaljer om tjenesten og dens muligheder henvises til Ofte stillede spørgsmål om Amazon DataZone , re: Invent launch.
Konklusion
Data transformerer hvert felt og enhver virksomhed. Men da data vokser hurtigere end de fleste virksomheder kan holde styr på, er det en udfordrende ting at indsamle, sikre og få værdi ud af disse data. En moderne datastrategi kan hjælpe dig med at skabe bedre forretningsresultater med data. AWS leverer det mest komplette sæt af tjenester til end-to-end datarejsen for at hjælpe dig med at låse op for værdi fra dine data og omdanne dem til indsigt.
Hos AWS arbejder vi bagud fra kundernes krav. Fra Lake Formation-teamet arbejdede vi hårdt på at levere de funktioner, der er beskrevet i dette indlæg, og vi inviterer dig til at tjekke dem ud. Med vores fortsatte fokus på at opfinde håber vi at spille en nøglerolle i at give organisationer mulighed for at bygge nye datastyringsmodeller, der hjælper dig med at opnå mere forretningsværdi med lynets hast.
Du kan komme i gang med Lake Formation ved at udforske vores praktisk værksted moduler og Kom godt i gang tutorials. Vi ser frem til at høre fra jer, vores kunder, om jeres datasø og datagovernance-brugssager. Kontakt venligst via dit AWS-kontoteam og del dine kommentarer.
Om forfatterne
 Jason Berkowitz er Senior Product Manager hos AWS Lake Formation. Han kommer fra en baggrund inden for maskinlæring og data sø-arkitekturer. Han hjælper kunder med at blive datadrevne.
Jason Berkowitz er Senior Product Manager hos AWS Lake Formation. Han kommer fra en baggrund inden for maskinlæring og data sø-arkitekturer. Han hjælper kunder med at blive datadrevne.
 Aarthi Srinivasan er Senior Big Data Architect med AWS Lake Formation. Hun nyder at bygge data sø-løsninger til AWS kunder og partnere. Når hun ikke er på tastaturet, udforsker hun de seneste videnskabelige og teknologiske tendenser og tilbringer tid med sin familie.
Aarthi Srinivasan er Senior Big Data Architect med AWS Lake Formation. Hun nyder at bygge data sø-løsninger til AWS kunder og partnere. Når hun ikke er på tastaturet, udforsker hun de seneste videnskabelige og teknologiske tendenser og tilbringer tid med sin familie.
 Leonardo Gomez er Senior Analytics Specialist Solutions Architect hos AWS. Baseret i Toronto, Canada, har han mere end ti års erfaring med datastyring, der hjælper kunder over hele verden med at løse deres forretningsmæssige og tekniske behov.
Leonardo Gomez er Senior Analytics Specialist Solutions Architect hos AWS. Baseret i Toronto, Canada, har han mere end ti års erfaring med datastyring, der hjælper kunder over hele verden med at løse deres forretningsmæssige og tekniske behov.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/aws-lake-formation-2022-year-in-review/
- 100
- 116
- 2022
- 7
- a
- evne
- I stand
- Om
- fremskynde
- accelererende
- adgang
- Adgang til data
- af udleverede
- Adgang
- Konto
- Konti
- tværs
- tilføjet
- Desuden
- Yderligere
- adresse
- admin
- Fordel
- tillader
- Amazon
- Amazon EMR
- Amazon SageMaker
- beløb
- analytics
- analysere
- ,
- annoncerede
- Apache
- Apache Spark
- api
- API'er
- Anvendelse
- applikationer
- Indløs
- passende
- arkitektur
- OMRÅDE
- områder
- omkring
- Aktiver
- Associate
- forbundet
- revision
- AWS
- AWS Lim
- AWS søformation
- AWS re: Invent
- baggrund
- baseret
- bliver
- Bedre
- Beyond
- Big
- Big data
- bygge
- Builder
- bygherrer
- Bygning
- bygget
- virksomhed
- forretning til forretning
- kaldet
- ringer
- Kan få
- Canada
- kapaciteter
- tilfælde
- tilfælde
- katalog
- CCPA
- udfordringer
- udfordrende
- Ændringer
- kontrollere
- Kina
- Vælg
- Cloud
- Cluster
- Indsamling
- samling
- kommentarer
- Virksomheder
- konkurrencedygtig
- fuldføre
- komplekse
- omfattende
- Tilslut
- fortsatte
- kontrol
- kontrol
- Omkostninger
- kunne
- dækning
- crawler
- skabe
- skik
- kunde
- Kunder
- data
- dataadgang
- dataingeniør
- Dataudveksling
- Data Lake
- datastyring
- Dataplatform
- databeskyttelse
- datakvalitet
- dataforsker
- datadeling
- datastrategi
- datalager
- datavarehuse
- datastyret
- Database
- databaser
- datasæt
- årti
- Beslutningstagning
- dybere
- levere
- leveret
- Delta
- implementering
- beskrevet
- detaljeret
- detaljer
- udviklere
- Udvikling
- forskellige
- direkte
- opdage
- hver
- lettere
- Effektiv
- effektivt
- bemyndigelse
- muliggør
- muliggør
- tilskynde
- ende til ende
- ingeniør
- Ingeniører
- forbedret
- Forbedrer
- sikre
- sikring
- Miljø
- Ether (ETH)
- EU
- Endog
- begivenhed
- begivenheder
- Hver
- udveksling
- ophidset
- eksisterende
- ekspanderende
- erfaring
- udforske
- Udforskning
- udtryk
- ekstrakt
- familie
- hurtigere
- Feature
- Funktionalitet
- tilbagemeldinger
- få
- felt
- Filer
- Finde
- bøder
- Fornavn
- Fokus
- efter
- formation
- Videresend
- Foundation
- rammer
- fra
- fuldt ud
- funktionaliteter
- yderligere
- GDPR
- generere
- få
- få
- kloden
- gå
- regeringsførelse
- indrømme
- større
- gruppe
- Dyrkning
- Håndtering
- Gem
- Hård Ost
- Helse
- høre
- hjælpe
- hjælpe
- hjælper
- historie
- Hive
- håber
- HOURS
- Hvordan
- Men
- HTML
- HTTPS
- IAM
- Identity
- implementering
- vigtigt
- forbedringer
- forbedrer
- forbedring
- in
- I andre
- omfatter
- Herunder
- Stigninger
- stigende
- info
- oplysninger
- indsigt
- indsigt
- integreret
- integration
- integrationer
- interesseret
- introduceret
- indføre
- invitere
- IT
- Karriere
- rejse
- Holde
- Nøgle
- sø
- seneste
- lanceret
- leder
- LÆR
- læring
- Niveau
- Licens
- Licenseret
- Licenser
- lyn
- Lynhastighed
- belastning
- Se
- maskine
- machine learning
- lavet
- Main
- maerker
- Making
- administrere
- lykkedes
- ledelse
- leder
- mange
- Metadata
- metode
- metoder
- ML
- tilstand
- model
- modeller
- Moderne
- Moduler
- Overvåg
- mere
- mest
- flere
- navne
- indfødte
- Behov
- behov
- Ny
- ny funktion
- notesbøger
- meddelelser
- november
- Nyheder
- forpligtelser
- tilbyde
- Tilbud
- onboarding
- ONE
- open source
- Produktion
- Opportunity
- organisation
- organisationer
- Andet
- egen
- ejere
- del
- partnere
- PBS
- tilladelse
- Tilladelser
- petabytes
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Leg
- Vær venlig
- politikker
- Populær
- portefølje
- mulig
- Indlæg
- Forbered
- forelagt
- Eksempel
- primært
- Beskyttelse af personlige oplysninger
- Processer
- forarbejdning
- Produkt
- produktchef
- Progress
- give
- forudsat
- udbydere
- giver
- leverer
- offentliggjort
- formål
- kvalitet
- RAM
- RE
- genkende
- anbefaler
- reducerer
- reducere
- regioner
- regler
- lovgivningsmæssige
- frigive
- fjernet
- påkrævet
- Krav
- ressource
- Ressourcer
- REST
- gennemgå
- Risiko
- robust
- roller
- roller
- Kør
- Rusland
- sagemaker
- samme
- Scale
- planlagt
- Videnskab
- Videnskab og Teknologi
- Videnskabsmand
- forskere
- problemfrit
- Anden
- sikker
- fastgørelse
- senior
- tjeneste
- Tjenester
- sæt
- Del
- delt
- Aktier
- deling
- Simpelt
- So
- løsninger
- Løsninger
- Løsning
- nogle
- Kilde
- Kilder
- Spark
- specialist
- specifikke
- hastighed
- brugt
- interessenter
- starburst
- påbegyndt
- Starter
- Steps
- opbevaring
- opbevaret
- Strategi
- strøm
- Studio
- indsende
- Hold mig opdateret
- abonnenter
- sådan
- opsummere
- RESUMÉ
- support
- Understøtter
- Systemer
- Talks
- mål
- hold
- hold
- Teknisk
- Teknologier
- The Source
- deres
- ting
- tredjepart
- Gennem
- hele
- tid
- til
- toronto
- spor
- Kurser
- Transform
- omdanne
- Tendenser
- TUR
- ui
- underliggende
- forstå
- forenet
- enestående
- låse
- Opdatering
- brug
- brug tilfælde
- Bruger
- Brugererfaring
- brugere
- værdi
- udgave
- Specifikation
- visninger
- Warehouse
- måder
- Hvad
- hvorvidt
- WHO
- inden for
- Arbejde
- arbejdede
- værksted
- workshops
- skrivning
- år
- Din
- youtube
- zephyrnet