Amazon SageMaker er en fuldt administreret maskinlæringstjeneste (ML). Med SageMaker kan dataforskere og udviklere hurtigt og nemt bygge og træne ML-modeller og derefter implementere dem direkte i et produktionsklart hostet miljø. Det giver en integreret Jupyter-forfatternotebook-instans for nem adgang til dine datakilder til udforskning og analyse, så du ikke behøver at administrere servere. Det giver også fælles ML algoritmer der er optimeret til at køre effektivt mod ekstremt store data i et distribueret miljø.
SageMaker real-time inference er ideel til arbejdsbelastninger, der har real-time, interaktive krav med lav latens. Med SageMaker real-time inferens kan du implementere REST-slutpunkter, der understøttes af en specifik instanstype med en vis mængde beregning og hukommelse. Implementering af et SageMaker-endepunkt i realtid er kun det første skridt på vejen til produktion for mange kunder. Vi ønsker at være i stand til at maksimere ydeevnen af slutpunktet for at opnå et mål for transaktioner pr. sekund (TPS), mens vi overholder latenskravene. En stor del af ydeevneoptimering til slutninger er at sørge for, at du vælger den korrekte forekomsttype og tæller for at gå tilbage til et slutpunkt.
Dette indlæg beskriver bedste praksis for belastningsteste et SageMaker-slutpunkt for at finde den rigtige konfiguration til antallet af forekomster og størrelse. Dette kan hjælpe os med at forstå minimumskravene til klargjorte forekomster for at opfylde vores latenstid og TPS-krav. Derfra dykker vi ned i, hvordan du kan spore og forstå metrik og ydeevne for SageMaker-slutpunktet ved at bruge amazoncloudwatch målinger.
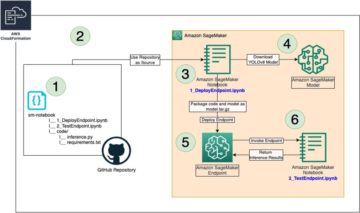
Vi benchmarker først vores models ydeevne på en enkelt instans for at identificere den TPS, den kan håndtere i henhold til vores acceptable latencykrav. Derefter ekstrapolerer vi resultaterne for at beslutte, hvor mange instanser vi skal bruge for at håndtere vores produktionstrafik. Til sidst simulerer vi trafik på produktionsniveau og opsætter belastningstests for et SageMaker-slutpunkt i realtid for at bekræfte, at vores endepunkt kan håndtere belastningen på produktionsniveau. Hele kodesættet for eksemplet er tilgængeligt i det følgende GitHub repository.
Oversigt over løsning
Til denne stilling indsætter vi en foruddannet Hugging Face DistilBERT model fra Krammer Face Hub. Denne model kan udføre en række opgaver, men vi sender en nyttelast specifikt til sentimentanalyse og tekstklassificering. Med denne prøve nyttelast stræber vi efter at opnå 1000 TPS.
Implementer et slutpunkt i realtid
Dette indlæg forudsætter, at du er bekendt med, hvordan man implementerer en model. Henvise til Opret dit slutpunkt og implementer din model at forstå det interne bag at hoste et slutpunkt. Indtil videre kan vi hurtigt pege på denne model i Hugging Face Hub og implementere et slutpunkt i realtid med følgende kodestykke:
Lad os hurtigt teste vores endepunkt med prøvens nyttelast, som vi vil bruge til belastningstest:

Bemærk, at vi bakker slutpunktet ved hjælp af en enkelt Amazon Elastic Compute Cloud (Amazon EC2) instans af typen ml.m5.12xlarge, som indeholder 48 vCPU og 192 GiB hukommelse. Antallet af vCPU'er er en god indikation af den samtidighed, instansen kan håndtere. Generelt anbefales det at teste forskellige forekomsttyper for at sikre, at vi har en forekomst, der har ressourcer, der bruges korrekt. For at se en komplet liste over SageMaker-forekomster og deres tilsvarende regnekraft til inferens i realtid, se Amazon SageMaker-priser.
Metrics at spore
Før vi kan komme ind i belastningstestning, er det vigtigt at forstå, hvilke metrics der skal spores for at forstå ydelsesnedbrydningen af dit SageMaker-endepunkt. CloudWatch er det primære logningsværktøj, som SageMaker bruger til at hjælpe dig med at forstå de forskellige målinger, der beskriver dit endepunkts ydeevne. Du kan bruge CloudWatch-logfiler til at fejlsøge dine slutpunktskald; alle log- og printudsagn, du har i din slutningskode, er fanget her. For mere information, se Sådan fungerer Amazon CloudWatch.
Der er to forskellige typer metrics, CloudWatch dækker for SageMaker: instansniveau og invocation-metrics.
Metrics på instansniveau
Det første sæt parametre, der skal overvejes, er metrics på forekomstniveau: CPUUtilization , MemoryUtilization (for GPU-baserede forekomster, GPUUtilization). Til CPUUtilization, kan du først se procenter over 100 % i CloudWatch. Det er vigtigt at indse for CPUUtilization, vises summen af alle CPU-kernerne. For eksempel, hvis instansen bag dit endepunkt indeholder 4 vCPU'er, betyder det, at anvendelsesområdet er op til 400 %. MemoryUtilization, på den anden side er i intervallet 0-100%.
Konkret kan du bruge CPUUtilization for at få en dybere forståelse af, om du har tilstrækkelig eller endda en overskydende mængde hardware. Hvis du har en underudnyttet instans (mindre end 30 %), kan du potentielt nedskalere din instanstype. Omvendt, hvis du er omkring 80-90 % udnyttelse, ville det være en fordel at vælge en instans med større beregning/hukommelse. Ud fra vores test foreslår vi omkring 60-70 % udnyttelse af din hardware.
Invokationsmålinger
Som antydet af navnet, er invokationsmetrics, hvor vi kan spore ende-til-ende-forsinkelsen af enhver påkaldelse til dit slutpunkt. Du kan bruge opkaldsmetrikkene til at registrere fejlantal og hvilken type fejl (5xx, 4xx og så videre), som dit slutpunkt muligvis oplever. Endnu vigtigere er det, at du kan forstå latenstidsfordelingen af dine slutpunktopkald. Meget af dette kan fanges med ModelLatency , OverheadLatency metrikker, som illustreret i følgende diagram.

ModelLatency metrisk fanger den tid, som inferens tager inden for modelbeholderen bag et SageMaker-slutpunkt. Bemærk, at modelbeholderen også indeholder enhver tilpasset slutningskode eller scripts, som du har videregivet til slutning. Denne enhed fanges i mikrosekunder som en invokationsmetrik, og generelt kan du tegne en percentil på tværs af CloudWatch (s.99, p90, og så videre) for at se, om du opfylder din målforsinkelse. Bemærk, at flere faktorer kan påvirke model- og containerforsinkelse, såsom følgende:
- Brugerdefineret inferensscript – Uanset om du har implementeret din egen container eller brugt en SageMaker-baseret container med brugerdefinerede slutningsbehandlere, er det bedste praksis at profilere dit script for at fange eventuelle operationer, der specifikt tilføjer en masse tid til din latency.
- Kommunikationsprotokol – Overvej REST vs. gRPC-forbindelser til modelserveren i modelbeholderen.
- Modelrammeoptimeringer – Det er rammespecifikt, for eksempel med TensorFlow, er der en række miljøvariabler, du kan indstille, og som er TF-serveringsspecifikke. Sørg for at tjekke, hvilken container du bruger, og hvis der er nogen rammespecifikke optimeringer, du kan tilføje i scriptet eller som miljøvariabler til at injicere i containeren.
OverheadLatency måles fra det tidspunkt, hvor SageMaker modtager anmodningen, indtil den returnerer et svar til klienten, minus modelforsinkelsen. Denne del er stort set uden for din kontrol og falder ind under den tid, det tager SageMaker overhead.
End-to-end latency som helhed afhænger af en række faktorer og er ikke nødvendigvis summen af ModelLatency plus OverheadLatency. For eksempel, hvis din klient laver InvokeEndpoint API-kald over internettet, fra klientens perspektiv, ville ende-til-ende-forsinkelsen være internet + ModelLatency + OverheadLatency. Som sådan, når du belastningstester dit endepunkt for nøjagtigt at benchmarke selve endepunktet, anbefales det at fokusere på endepunktets metrics (ModelLatency, OverheadLatencyog InvocationsPerInstance) for nøjagtigt at benchmarke SageMaker-endepunktet. Eventuelle problemer relateret til end-to-end latency kan derefter isoleres separat.
Et par spørgsmål at overveje for end-to-end latency:
- Hvor er den klient, der påkalder dit slutpunkt?
- Er der nogen mellemliggende lag mellem din klient og SageMaker runtime?
Automatisk skalering
Vi dækker ikke automatisk skalering specifikt i dette indlæg, men det er en vigtig overvejelse for at levere det korrekte antal forekomster baseret på arbejdsbyrden. Afhængigt af dine trafikmønstre kan du vedhæfte en politik for automatisk skalering til dit SageMaker-slutpunkt. Der er forskellige skaleringsmuligheder, som f.eks TargetTrackingScaling, SimpleScalingog StepScaling. Dette gør det muligt for dit endepunkt at skalere ind og ud automatisk baseret på dit trafikmønster.
En almindelig mulighed er målsporing, hvor du kan specificere en CloudWatch-metrik eller brugerdefineret metrik, som du har defineret og skalere ud baseret på det. En hyppig brug af automatisk skalering er sporing af InvocationsPerInstance metrisk. Efter at du har identificeret en flaskehals ved en bestemt TPS, kan du ofte bruge den som en metrik til at skalere ud til et større antal instanser for at kunne håndtere spidsbelastninger af trafik. For at få en dybere opdeling af automatisk skalering af SageMaker-endepunkter, se Konfiguration af autoskalering af inferensslutpunkter i Amazon SageMaker.
Belastningstest
Selvom vi bruger Locust til at vise, hvordan vi kan indlæse test i skala, hvis du prøver at rette størrelsen på forekomsten bag dit slutpunkt, SageMaker Inference Recommend er en mere effektiv mulighed. Med tredjeparts belastningstestværktøjer skal du manuelt implementere slutpunkter på tværs af forskellige instanser. Med Inference Recommender kan du blot bestå en række af de instanstyper, du vil indlæse test imod, og SageMaker vil spinne op job for hvert af disse tilfælde.
Locust
Til dette eksempel bruger vi Locust, et open source-belastningstestværktøj, som du kan implementere ved hjælp af Python. Locust ligner mange andre open source-belastningstestværktøjer, men har et par specifikke fordele:
- Nemt at sætte op – Som vi demonstrerer i dette indlæg, sender vi et simpelt Python-script, der nemt kan omstruktureres til dit specifikke slutpunkt og nyttelast.
- Distribueret og skalerbar – Locust er begivenhedsbaseret og bruger gavt under kølerhjelmen. Dette er meget nyttigt til at teste meget samtidige arbejdsbelastninger og simulere tusindvis af samtidige brugere. Du kan opnå høj TPS med en enkelt proces, der kører Locust, men den har også en distribueret belastningsgenerering funktion, der giver dig mulighed for at skalere ud til flere processer og klientmaskiner, som vi vil udforske i dette indlæg.
- Locust-metrics og UI – Locust fanger også ende-til-ende latency som en metrisk. Dette kan hjælpe med at supplere dine CloudWatch-metrics for at tegne et fuldstændigt billede af dine tests. Dette er alt sammen fanget i Locust UI, hvor du kan spore samtidige brugere, arbejdere og mere.
For yderligere at forstå Locust, tjek deres dokumentation.
Amazon EC2 opsætning
Du kan opsætte Locust i et hvilket som helst miljø, der passer til dig. Til dette indlæg opsætter vi en EC2-instans og installerer Locust der for at udføre vores tests. Vi bruger en c5.18xlarge EC2-instans. Beregningskraften på klientsiden er også noget at overveje. På tidspunkter, hvor du løber tør for computerkraft på klientsiden, bliver dette ofte ikke fanget og forveksles som en SageMaker-slutpunktsfejl. Det er vigtigt at placere din klient et sted med tilstrækkelig computerkraft, der kan håndtere den belastning, du tester ved. Til vores EC2-forekomst bruger vi en Ubuntu Deep Learning AMI, men du kan bruge enhver AMI, så længe du kan konfigurere Locust korrekt på maskinen. For at forstå, hvordan du starter og opretter forbindelse til din EC2-instans, se selvstudiet Kom godt i gang med Amazon EC2 Linux-instanser.
Locust UI er tilgængelig via port 8089. Vi kan åbne dette ved at justere vores indgående sikkerhedsgrupperegler for EC2-instansen. Vi åbner også port 22, så vi kan SSH ind i EC2-instansen. Overvej at afgrænse kilden til den specifikke IP-adresse, du får adgang til EC2-instansen fra.

Når du er forbundet til din EC2-instans, opsætter vi et virtuelt Python-miljø og installerer open source Locust API'en via CLI:
Vi er nu klar til at arbejde med Locust til belastningsteste vores slutpunkt.
Græshopper test
Alle Locust-belastningstest udføres baseret på en Locust fil som du giver. Denne Locust-fil definerer en opgave for belastningstesten; det er her, vi definerer vores Boto3 invoke_endpoint API-kald. Se følgende kode:
I den foregående kode skal du justere dine påkaldende slutpunktkaldsparametre, så de passer til din specifikke modelkald. Vi bruger InvokeEndpoint API ved hjælp af følgende stykke kode i Locust-filen; dette er vores belastningstestkørselspunkt. Locust-filen vi bruger er locust_script.py.
Nu hvor vi har vores Locust-script klar, ønsker vi at køre distribuerede Locust-tests for at stressteste vores enkelte instans for at finde ud af, hvor meget trafik vores instans kan håndtere.
Locust distribueret tilstand er lidt mere nuanceret end en enkelt-proces Locust test. I distribueret tilstand har vi én primær og flere arbejdere. Den primære arbejder instruerer arbejderne om, hvordan de skal afføde og kontrollere de samtidige brugere, der sender en anmodning. I vores distributed.sh script, ser vi som standard, at 240 brugere vil blive fordelt på de 60 arbejdere. Bemærk, at --headless flag i Locust CLI fjerner UI-funktionen i Locust.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Vi kører først den distribuerede test på en enkelt instans, der understøtter slutpunktet. Ideen her er, at vi ønsker at maksimere en enkelt forekomst fuldt ud for at forstå antallet af forekomster, vi har brug for for at nå vores mål-TPS, mens vi holder os inden for vores latenskrav. Bemærk, at hvis du vil have adgang til brugergrænsefladen, skal du ændre Locust_UI miljøvariablen til True, og tag den offentlige IP for din EC2-instans og tilknyt port 8089 til URL'en.
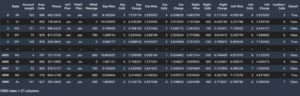
Følgende skærmbillede viser vores CloudWatch-metrics.

Til sidst bemærker vi, at selvom vi oprindeligt opnår en TPS på 200, begynder vi at bemærke 5xx-fejl i vores EC2-klientsidelogfiler, som vist på det følgende skærmbillede.
Vi kan også bekræfte dette ved at se specifikt på vores metrics på instansniveau CPUUtilization.
 Her bemærker vi
Her bemærker vi CPUUtilization på næsten 4,800 %. Vores ml.m5.12x.large-instans har 48 vCPU'er (48 * 100 = 4800~). Dette mætter hele forekomsten, hvilket også hjælper med at forklare vores 5xx-fejl. Vi ser også en stigning i ModelLatency.
Det ser ud til, at vores enkelte instans er ved at blive væltet og ikke har computeren til at opretholde en belastning forbi de 200 TPS, som vi observerer. Vores mål-TPS er 1000, så lad os prøve at øge vores forekomstantal til 5. Dette skal muligvis være endnu mere i en produktionsindstilling, fordi vi observerede fejl ved 200 TPS efter et vist tidspunkt.

Vi ser i både Locust UI- og CloudWatch-loggene, at vi har en TPS på næsten 1000 med fem forekomster, der understøtter slutpunktet.

 Hvis du begynder at opleve fejl, selv med denne hardwareopsætning, skal du sørge for at overvåge
Hvis du begynder at opleve fejl, selv med denne hardwareopsætning, skal du sørge for at overvåge CPUUtilization for at forstå det fulde billede bag din endpoint-hosting. Det er afgørende at forstå din hardwareudnyttelse for at se, om du skal skalere op eller endda ned. Nogle gange fører problemer på containerniveau til 5xx-fejl, men hvis CPUUtilization er lav, indikerer det, at det ikke er din hardware, men noget på container- eller modelniveau, der kan føre til disse problemer (f.eks. den korrekte miljøvariabel for antallet af arbejdere, der ikke er indstillet). På den anden side, hvis du bemærker, at din instans er ved at blive fuldt mættet, er det et tegn på, at du enten skal øge den nuværende instansflåde eller prøve en større instans med en mindre flåde.
Selvom vi øgede antallet af forekomster til 5 for at håndtere 100 TPS, kan vi se, at ModelLatency metrikken er stadig høj. Dette skyldes, at forekomsterne er mættede. Generelt foreslår vi, at man tilstræber at udnytte instansens ressourcer mellem 60-70 %.
Ryd op
Efter belastningstest skal du sørge for at rydde op i alle ressourcer, du ikke vil bruge via SageMaker-konsollen eller via delete_endpoint Boto3 API-kald. Derudover skal du sørge for at stoppe din EC2-instans eller hvilken som helst klientopsætning du har for ikke at pådrage dig yderligere gebyrer der også.
Resumé
I dette indlæg beskrev vi, hvordan du kan indlæse teste dit SageMaker-endepunkt i realtid. Vi diskuterede også, hvilke metrics du bør evaluere, når du belastningstester dit slutpunkt for at forstå din ydeevnenedbrydning. Sørg for at tjekke ud SageMaker Inference Recommend for yderligere at forstå instansernes rigtige størrelse og flere ydelsesoptimeringsteknikker.
Om forfatterne
 Marc Karp er ML-arkitekt hos SageMaker Service-teamet. Han fokuserer på at hjælpe kunder med at designe, implementere og administrere ML-arbejdsbelastninger i stor skala. I sin fritid nyder han at rejse og udforske nye steder.
Marc Karp er ML-arkitekt hos SageMaker Service-teamet. Han fokuserer på at hjælpe kunder med at designe, implementere og administrere ML-arbejdsbelastninger i stor skala. I sin fritid nyder han at rejse og udforske nye steder.
 Ram Vegiraju er ML-arkitekt hos SageMaker Service-teamet. Han fokuserer på at hjælpe kunder med at bygge og optimere deres AI/ML-løsninger på Amazon SageMaker. I sin fritid elsker han at rejse og skrive.
Ram Vegiraju er ML-arkitekt hos SageMaker Service-teamet. Han fokuserer på at hjælpe kunder med at bygge og optimere deres AI/ML-løsninger på Amazon SageMaker. I sin fritid elsker han at rejse og skrive.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- I stand
- over
- acceptabel
- adgang
- tilgængelig
- Adgang
- præcist
- opnå
- tværs
- Desuden
- adresse
- Efter
- mod
- AI / ML
- sigter
- Alle
- tillader
- Skønt
- Amazon
- Amazon EC2
- Amazon SageMaker
- beløb
- analyse
- ,
- api
- omkring
- Array
- vedhæfte
- forfatter
- auto
- automatisk
- til rådighed
- AWS
- tilbage
- Backed
- opbakning
- baseret
- fordi
- bag
- være
- benchmark
- gavner det dig
- fordele
- BEDSTE
- bedste praksis
- mellem
- krop
- Fordeling
- bygge
- C + +
- ringe
- Opkald
- Kan få
- fange
- fanger
- brydning
- vis
- lave om
- afgifter
- kontrollere
- klasse
- klassificering
- kunde
- kode
- Fælles
- kompatibel
- Compute
- konkurrent
- Adfærd
- Konfiguration
- Bekræfte
- Tilslut
- tilsluttet
- Tilslutninger
- Overvej
- overvejelse
- Konsol
- Container
- indeholder
- sammenhæng
- kontrol
- Tilsvarende
- kunne
- dæksel
- dækker
- CPU
- skabe
- afgørende
- Nuværende
- skik
- Kunder
- data
- dyb
- dyb læring
- dybere
- Standard
- definerer
- demonstrere
- Afhængigt
- afhænger
- indsætte
- implementering
- beskrive
- beskrevet
- Design
- udviklere
- forskellige
- direkte
- drøftet
- Skærm
- distribueret
- Er ikke
- Dont
- ned
- hver
- nemt
- effektiv
- effektivt
- enten
- muliggør
- ende til ende
- Endpoint
- Hele
- Miljø
- fejl
- fejl
- væsentlig
- Ether (ETH)
- Endog
- eksempel
- undtagelse
- udføre
- oplever
- Forklar
- udforskning
- udforske
- Udforskning
- eksport
- ekstremt
- Ansigtet
- faktorer
- Falls
- bekendt
- Feature
- få
- File (Felt)
- Endelig
- Finde
- Fornavn
- FLÅDE
- Fokus
- fokuserer
- efter
- format
- Framework
- hyppig
- fra
- fuld
- fuldt ud
- yderligere
- Generelt
- generelt
- få
- få
- godt
- graf
- større
- gruppe
- Gruppens
- håndtere
- Gem
- Hardware
- hjælpe
- hjælpe
- hjælper
- link.
- Høj
- stærkt
- hætte
- host
- hostede
- Hosting
- Hvordan
- How To
- HTML
- HTTPS
- Hub
- idé
- ideal
- identificeret
- identificere
- KIMOs Succeshistorier
- gennemføre
- implementeret
- importere
- vigtigt
- in
- omfatter
- Forøg
- øget
- angiver
- tegn
- oplysninger
- i første omgang
- installere
- instans
- integreret
- interaktiv
- Internet
- påberåber sig
- IP
- IP-adresse
- isolerede
- spørgsmål
- IT
- selv
- json
- stor
- vid udstrækning
- større
- Latency
- lancere
- lag
- føre
- førende
- læring
- Niveau
- linux
- Liste
- lidt
- belastning
- belastninger
- placering
- Lang
- leder
- Lot
- Lav
- maskine
- machine learning
- Maskiner
- lave
- Making
- administrere
- lykkedes
- manuelt
- mange
- kort
- Maksimer
- midler
- Mød
- møde
- Hukommelse
- metrisk
- Metrics
- måske
- minimum
- ML
- tilstand
- model
- modeller
- Overvåg
- mere
- mere effektiv
- flere
- navn
- næsten
- nødvendigvis
- Behov
- Ny
- notesbog
- nummer
- ONE
- åbent
- open source
- Produktion
- optimering
- Optimer
- optimeret
- Option
- Indstillinger
- ordrer
- Andet
- uden for
- egen
- male
- parametre
- del
- Bestået
- forbi
- sti
- Mønster
- mønstre
- Peak
- udføre
- ydeevne
- perspektiv
- pick
- billede
- stykke
- Place
- Steder
- plato
- Platon Data Intelligence
- PlatoData
- plus
- Punkt
- Indlæg
- potentielt
- magt
- praksis
- praksis
- Predictor
- primære
- problemer
- behandle
- Processer
- produktion
- Profil
- passende
- korrekt
- give
- giver
- bestemmelse
- offentlige
- Python
- Spørgsmål
- hurtigt
- rækkevidde
- klar
- realtid
- indse
- modtager
- anbefales
- region
- relaterede
- anmode
- Krav
- Ressourcer
- svar
- REST
- resultere
- Resultater
- afkast
- regler
- Kør
- kører
- sagemaker
- SageMaker Inference
- Scale
- skalering
- forskere
- Anvendelsesområde
- scripts
- Anden
- sikkerhed
- synes
- SELV
- afsendelse
- stemningen
- tjeneste
- servering
- sæt
- indstilling
- indstillinger
- setup
- flere
- bør
- vist
- Shows
- underskrive
- lignende
- Simpelt
- ganske enkelt
- enkelt
- Størrelse
- mindre
- So
- Løsninger
- noget
- Kilde
- Kilder
- Spawn
- specifikke
- specifikt
- Spin
- standard
- starte
- påbegyndt
- udsagn
- Trin
- Stadig
- Stands
- stress
- stræbe
- sådan
- tilstrækkeligt
- Dragt
- Super
- supplere
- Tag
- tager
- mål
- Opgaver
- opgaver
- hold
- teknikker
- prøve
- Test løb
- Test
- tests
- Tekstklassificering
- The Source
- deres
- tredjepart
- tusinder
- Gennem
- tid
- gange
- til
- værktøj
- værktøjer
- TPS
- spor
- Sporing
- Trafik
- Tog
- Transaktioner
- Traveling
- sand
- tutorial
- typer
- Ubuntu
- ui
- under
- forstå
- forståelse
- enhed
- URL
- us
- brug
- brugere
- udnytte
- udnyttet
- udnytter
- Ved hjælp af
- række
- verificere
- via
- Virtual
- Hvad
- hvorvidt
- som
- mens
- vilje
- inden for
- Arbejde
- arbejdstager
- arbejdere
- ville
- skrivning
- Din
- zephyrnet