Jeg har allerede demonstreret hvordan lav en vidensgraf ud af en Wikipedia-side. Men da indlægget fik meget opmærksomhed, har jeg besluttet at udforske andre domæner, hvor det giver mening at bruge NLP-teknikker til at konstruere en vidensgraf. Efter min mening er det biomedicinske område et godt eksempel, hvor det giver mening at repræsentere dataene som en graf, da du ofte analyserer interaktioner og relationer mellem gener, sygdomme, lægemidler, proteiner og mere.
Eksempel på undergrafik, der viser ascorbinsyrerelationer til andre biomedicinske koncepter. Billede af forfatteren.
I ovenstående visualisering har vi ascorbinsyre, også kendt som C-vitamin, og nogle af dens relationer til andre begreber. For eksempel viser det, at C-vitamin kunne bruges til at behandle kronisk gastritis.
Nu kan du få et team af domæneeksperter til at kortlægge alle disse forbindelser mellem lægemidler, sygdomme og andre biomedicinske koncepter for dig. Men desværre er der ikke mange af os, der har råd til at hyre et team af læger til at udføre arbejdet for os. I så fald kan vi ty til at bruge NLP-teknikker til at udtrække disse relationer automatisk. Den gode del er, at vi kan bruge en NLP-pipeline til at læse alle forskningsartiklerne derude, og den dårlige del er, at ikke alle opnåede resultater vil være perfekte. Men da jeg ikke har et team af videnskabsmænd klar ved min side til at udtrække relationer manuelt, vil jeg ty til at bruge NLP-teknikker til at konstruere en egen biomedicinsk vidensgraf.
Jeg vil bruge et enkelt forskningspapir i dette blogindlæg til at lede dig gennem alle de nødvendige trin for at konstruere en biomedicinsk vidensgraf – Tissue Engineering af hudregenerering og hårvækst.
Opgaven er skrevet af Mohammadreza Ahmadi. PDF-versionen af artiklen er tilgængelig under CC0 1.0-licensen. Vi vil gennemgå følgende trin for at konstruere en vidensgraf:
Læsning af et PDF-dokument med OCR
Tekstforbehandling
Biomedicinsk begrebsgenkendelse og kobling
Relationsudvinding
Ekstern databaseberigelse
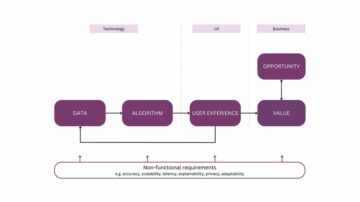
Ved slutningen af dette indlæg vil du konstruere en graf med følgende skema.
Biomedicinsk grafskema. Billede af forfatteren.
Vi vil bruge Neo4j, en grafdatabase, der indeholder den mærkede egenskabsgrafmodel, til at gemme vores graf. Hver artikel kan have en eller flere forfattere. Vi vil opdele artiklens indhold i sætninger og bruge NLP til at udtrække både medicinske enheder og deres relationer. Det er måske lidt kontraintuitivt, at vi vil gemme relationerne mellem entiteter som mellemliggende knudepunkter i stedet for relationer. Den kritiske faktor bag denne beslutning er, at vi ønsker at have et revisionsspor af kildeteksten, som relationen er udtrukket fra. Med den mærkede egenskabsgrafmodel kan du ikke have en relation, der peger på en anden relation. Af denne grund refaktorerer vi forbindelsen mellem medicinske begreber til en mellemknude. Dette vil også give en domæneekspert mulighed for at vurdere, om en relation var korrekt udtrukket eller ej.
Undervejs vil jeg også demonstrere anvendelser af at bruge den konstruerede graf til at søge og analysere lagret information.
Som nævnt er PDF-versionen af forskningspapiret tilgængelig for offentligheden under CC0 1.0-licensen, hvilket betyder, at vi nemt kan downloade det med Python. Vi vil bruge pytesseract bibliotek for at udtrække tekst fra PDF'en. Så vidt jeg ved, er pytesseract-biblioteket et af de mere populære biblioteker til OCR. Hvis du vil følge med i kodeeksempler, har jeg udarbejdet en Google Colab notesbog, så du ikke selv skal kopiere og indsætte koden.
import requests
import pdf2image
import pytesseract pdf = requests.get('https://arxiv.org/pdf/2110.03526.pdf')
doc = pdf2image.convert_from_bytes(pdf.content) # Get the article text
article = []
for page_number, page_data in enumerate(doc): txt = pytesseract.image_to_string(page_data).encode("utf-8") # Sixth page are only references if page_number < 6: article.append(txt.decode("utf-8"))
article_txt = " ".join(article)
Tekstforbehandling
Nu hvor vi har artiklens indhold tilgængeligt, vil vi gå videre og fjerne afsnitstitler og figurbeskrivelser fra teksten. Dernæst vil vi dele teksten op i sætninger.
import nltk
nltk.download('punkt') def clean_text(text): """Remove section titles and figure descriptions from text""" clean = "n".join([row for row in text.split("n") if (len(row.split(" "))) > 3 and not (row.startswith("(a)")) and not row.startswith("Figure")]) return clean text = article_txt.split("INTRODUCTION")[1]
ctext = clean_text(text)
sentences = nltk.tokenize.sent_tokenize(ctext)
Biomedicinsk navngiven enhedsforbindelse
Nu kommer den spændende del. For dem, der er nye til NLP og navngivne enhedsgenkendelse og linkning, lad os starte med nogle grundlæggende ting. Navngivne entitetsgenkendelsesteknikker bruges til at opdage relevante enheder eller begreber i teksten. For eksempel inden for det biomedicinske domæne ønsker vi at identificere forskellige gener, lægemidler, sygdomme og andre begreber i teksten.
Udvinding af biomedicinske begreber. Billede af forfatteren.
I dette eksempel identificerede NLP-modellen gener, sygdomme, lægemidler, arter, mutationer og veje i teksten. Som nævnt kaldes denne proces for navngivet enhedsgenkendelse. En opgradering til den navngivne enhedsgenkendelse er den såkaldte navngivne enhedskobling. Den navngivne entity linking-teknik detekterer relevante begreber i teksten og forsøger at kortlægge dem til målvidensbasen. På det biomedicinske domæne er nogle af målvidenbaserne:
Hvorfor vil vi gerne forbinde medicinske enheder til en målvidenbase? Den primære årsag er, at det hjælper os med at håndtere entitetsdisambiguation. For eksempel ønsker vi ikke separate enheder i grafen, der repræsenterer ascorbinsyre og C-vitamin, da domæneeksperter kan fortælle dig, at det er det samme. Den sekundære årsag er, at vi ved at kortlægge koncepter til en målvidensbase kan berige vores grafmodel ved at hente information om de kortlagte koncepter fra målvidensbasen. Hvis vi bruger ascorbinsyreeksemplet igen, kunne vi nemt hente yderligere information fra CHEBI-databasen, hvis vi allerede kender det CHEBI id.
Berigelsesdata tilgængelige om ascorbinsyre på CHEBIs hjemmeside. Alt indhold på hjemmesiden er tilgængeligt under CC BY 4.0-licens. Billede af forfatteren.
Jeg har ledt efter en anstændig open source-foruddannet biomedicinsk navngiven enhedsforbindelse i nogen tid. Masser af NLP-modeller fokuserer på kun at udvinde en specifik undergruppe af medicinske begreber som gener eller sygdomme. Det er endnu sjældnere at finde en model, der opdager de fleste medicinske begreber og forbinder dem med en målvidensbase. Heldigvis er jeg faldet over BERN[1], et neural biomedicinsk enhedsgenkendelse og multi-type normaliseringsværktøj. Hvis jeg forstår det rigtigt, er det en finjusteret BioBert-model med forskellige navngivne entity-linking-modeller integreret til kortlægning af koncepter til biomedicinske målvidensbaser. Ikke nok med det, men de giver også et gratis REST-endepunkt, så vi ikke skal håndtere hovedpinen med at få afhængighederne og modellen til at fungere. Den biomedicinske navngivne enhedsgenkendelsesvisualisering, jeg har brugt ovenfor, blev skabt ved hjælp af BERN-modellen, så vi ved, at den detekterer gener, sygdomme, lægemidler, arter, mutationer og veje i teksten.
Desværre tildeler BERN-modellen ikke målvidenbase-id'er til alle koncepter. Så jeg har forberedt et script, der først ser efter, om der er givet et særskilt id for et koncept, og hvis det ikke er det, vil det bruge entitetsnavnet som id. Vi vil også beregne sha256 af teksten af sætninger for at identificere specifikke sætninger lettere senere, når vi skal lave relationsekstraktion.
import hashlib def query_raw(text, url="https://bern.korea.ac.kr/plain"): """Biomedical entity linking API""" return requests.post(url, data={'sample_text': text}).json() entity_list = []
# The last sentence is invalid
for s in sentences[:-1]: entity_list.append(query_raw(s)) parsed_entities = []
for entities in entity_list: e = [] # If there are not entities in the text if not entities.get('denotations'): parsed_entities.append({'text':entities['text'], 'text_sha256': hashlib.sha256(entities['text'].encode('utf-8')).hexdigest()}) continue for entity in entities['denotations']: other_ids = [id for id in entity['id'] if not id.startswith("BERN")] entity_type = entity['obj'] entity_name = entities['text'][entity['span']['begin']:entity['span']['end']] try: entity_id = [id for id in entity['id'] if id.startswith("BERN")][0] except IndexError: entity_id = entity_name e.append({'entity_id': entity_id, 'other_ids': other_ids, 'entity_type': entity_type, 'entity': entity_name}) parsed_entities.append({'entities':e, 'text':entities['text'], 'text_sha256': hashlib.sha256(entities['text'].encode('utf-8')).hexdigest()})
Jeg har inspiceret resultaterne af den navngivne enhedslinkning, og som forventet er den ikke perfekt. For eksempel identificerer den ikke stamceller som et medicinsk begreb. På den anden side opdagede den en enkelt enhed ved navn "hjerte, hjerne, nerver og nyre". BERN er dog stadig den bedste open source biomedicinske model, jeg kunne finde under min undersøgelse.
Konstruer en vidensgraf
Før vi ser på relationsekstraktionsteknikker, vil vi konstruere en biomedicinsk vidensgraf ved kun at bruge entiteter og undersøge de mulige anvendelser. Som nævnt har jeg udarbejdet en Google Colab notesbog som du kan bruge til at følge kodeeksemplerne i dette indlæg. For at gemme vores graf vil vi bruge Neo4j. Du behøver ikke at beskæftige dig med at forberede et lokalt Neo4j-miljø. I stedet kan du bruge en gratis Neo4j Sandbox-instans.
Neo4j Sandbox-forbindelsesdetaljer. Billede af forfatteren.
Nu kan du gå videre og forberede Neo4j-forbindelsen i notesbogen.
from neo4j import GraphDatabase
import pandas as pd host = 'bolt://3.236.182.55:7687'
user = 'neo4j'
password = 'hydrometer-ditches-windings'
driver = GraphDatabase.driver(host,auth=(user, password)) def neo4j_query(query, params=None): with driver.session() as session: result = session.run(query, params) return pd.DataFrame([r.values() for r in result], columns=result.keys())
Vi starter med at importere forfatteren og artiklen til grafen. Artiklens node vil kun indeholde titlen.
Hvis du åbner Neo4j Browser, bør du se følgende graf.
Billede af forfatteren.
Du kan importere sætningerne og nævnte enheder ved at udføre følgende Cypher-forespørgsel:
neo4j_query("""
MATCH (a:Article)
UNWIND $data as row
MERGE (s:Sentence{id:row.text_sha256})
SET s.text = row.text
MERGE (a)-[:HAS_SENTENCE]->(s)
WITH s, row.entities as entities
UNWIND entities as entity
MERGE (e:Entity{id:entity.entity_id})
ON CREATE SET e.other_ids = entity.other_ids, e.name = entity.entity, e.type = entity.entity_type
MERGE (s)-[m:MENTIONS]->(e)
ON CREATE SET m.count = 1
ON MATCH SET m.count = m.count + 1
""", {'data': parsed_entities})
Du kan udføre følgende Cypher-forespørgsel for at inspicere den konstruerede graf:
MATCH p=(a:Article)-[:HAS_SENTENCE]->()-[:MENTIONS]->(e:Entity)
RETURN p LIMIT 25
Hvis du har importeret dataene korrekt, bør du se en lignende visualisering.
Enhedsudtræk gemt som en graf. Billede af forfatteren.
Viden graf applikationer
Selv uden relationsekstraktionsflowet er der allerede et par use-cases for vores graf.
Søgemaskine
Vi kunne bruge vores graf som søgemaskine. For eksempel kan du bruge følgende Cypher-forespørgsel til at finde sætninger eller artikler, der nævner en specifik medicinsk enhed.
MATCH (e:Entity)<-[:MENTIONS]-(s:Sentence)
WHERE e.name = "autoimmune diseases"
RETURN s.text as result
Resultater
Billede af forfatteren.
Samtidsanalyse
Den anden mulighed er analyse af samtidig forekomst. Du kan definere samtidig forekomst mellem medicinske enheder, hvis de optræder i samme sætning eller artikel. Jeg har fundet en artikel[2], der bruger det medicinske co-occurrence-netværk til at forudsige nye mulige forbindelser mellem medicinske enheder.
Du kan bruge følgende Cypher-forespørgsel til at finde enheder, der ofte forekommer sammen i samme sætning.
MATCH (e1:Entity)<-[:MENTIONS]-()-[:MENTIONS]->(e2:Entity)
MATCH (e1:Entity)<-[:MENTIONS]-()-[:MENTIONS]->(e2:Entity)
WHERE id(e1) < id(e2)
RETURN e1.name as entity1, e2.name as entity2, count(*) as cooccurrence
ORDER BY cooccurrence
DESC LIMIT 3
Resultater
enhed 1
enhed 2
samtidighed
hudsygdomme
diabetiske mavesår
2
kroniske sår
diabetiske mavesår
2
hudsygdomme
kroniske sår
2
Naturligvis ville resultaterne være bedre, hvis vi analyserede tusindvis eller flere artikler.
Undersøg forfatterens ekspertise
Du kan også bruge denne graf til at finde forfatterens ekspertise ved at undersøge de medicinske enheder, de oftest skriver om. Med disse oplysninger kan du også foreslå fremtidige samarbejder.
Udfør følgende Cypher-forespørgsel for at inspicere, hvilke medicinske enheder vores enkelte forfatter nævnte i forskningspapiret.
MATCH (a:Author)-[:WROTE]->()-[:HAS_SENTENCE]->()-[:MENTIONS]->(e:Entity)
RETURN a.name as author, e.name as entity,
MATCH (a:Author)-[:WROTE]->()-[:HAS_SENTENCE]->()-[:MENTIONS]->(e:Entity)
RETURN a.name as author, e.name as entity, count(*) as count
ORDER BY count DESC
LIMIT 5
Resultater
forfatter
enhed
tælle
Mohammadreza Ahmadi
collagen
9
Mohammadreza Ahmadi
forbrændinger
4
Mohammadreza Ahmadi
hudsygdomme
4
Mohammadreza Ahmadi
collagenase enzymer
2
Mohammadreza Ahmadi
Epidermolyse bullosa
2
Relationsudvinding
Nu vil vi forsøge at uddrage relationer mellem medicinske begreber. Fra min erfaring er relationsekstraktion i det mindste en størrelsesorden sværere end navngivet enhedsekstraktion. Hvis du ikke skulle forvente perfekte resultater med navngivne entitetslinkning, så kan du helt sikkert forvente nogle fejl med relationsekstraktionsteknikken.
Jeg har ledt efter tilgængelige biomedicinske relationsekstraktionsmodeller, men fandt intet, der fungerer ud af boksen eller ikke kræver finjustering. Det ser ud til, at feltet for udvinding af relationer er på forkant, og forhåbentlig vil vi se mere opmærksomhed om det i fremtiden. Jeg er desværre ikke NLP-ekspert, så jeg undgik at finjustere min egen model. I stedet vil vi bruge nul-skuds-relationsekstraktoren baseret på papiret Udforsker nul-skudsgrænsen for FewRel[3]. Selvom jeg ikke vil anbefale at sætte denne model i produktion, er den god nok til en simpel demonstration. Modellen fås på KrammerFace, så vi ikke skal beskæftige os med træning eller opsætning af modellen.
from transformers import AutoTokenizer
from zero_shot_re import RelTaggerModel, RelationExtractor model = RelTaggerModel.from_pretrained("fractalego/fewrel-zero-shot")
tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
relations = ['associated', 'interacts']
extractor = RelationExtractor(model, tokenizer, relations)
Med nul-skuds relationsudtrækkeren kan du definere, hvilke relationer du vil detektere. I dette eksempel har jeg brugt forbundet , interagerer relationer. Jeg har også prøvet mere specifikke forholdstyper såsom godbidder, årsager og andre, men resultaterne var ikke gode.
Med denne model skal du definere, mellem hvilke par af entiteter du gerne vil detektere relationer. Vi vil bruge resultaterne af den navngivne enhedslinkning som input til relationsekstraktionsprocessen. Først finder vi alle de sætninger, hvor to eller flere entiteter er nævnt, og kører dem derefter gennem relationsekstraktionsmodellen for at udtrække eventuelle forbindelser. Jeg har også defineret en tærskelværdi på 0.85, hvilket betyder, at hvis en model forudsiger en forbindelse mellem enheder med en sandsynlighed lavere end 0.85, ignorerer vi forudsigelsen.
import itertools
# Candidate sentence where there is more than a single entity present
candidates = [s for s in parsed_entities if (s.get('entities')) and (len(s['entities']) > 1)]
predicted_rels = []
for c in candidates: combinations = itertools.combinations([{'name':x['entity'], 'id':x['entity_id']} for x in c['entities']], 2) for combination in list(combinations): try: ranked_rels = extractor.rank(text=c['text'].replace(",", " "), head=combination[0]['name'], tail=combination[1]['name']) # Define threshold for the most probable relation if ranked_rels[0][1] > 0.85: predicted_rels.append({'head': combination[0]['id'], 'tail': combination[1]['id'], 'type':ranked_rels[0][0], 'source': c['text_sha256']}) except: pass # Store relations to Neo4j
neo4j_query("""
UNWIND $data as row
MATCH (source:Entity {id: row.head})
MATCH (target:Entity {id: row.tail})
MATCH (text:Sentence {id: row.source})
MERGE (source)-[:REL]->(r:Relation {type: row.type})-[:REL]->(target)
MERGE (text)-[:MENTIONS]->(r)
""", {'data': predicted_rels})
Vi gemmer relationerne såvel som kildeteksten, der er brugt til at udtrække dette forhold i grafen.
Udtrukne relationer gemt i en graf. Billede af forfatteren.
Du kan undersøge de udtrukne relationer mellem enheder og kildeteksten med følgende Cypher-forespørgsel:
MATCH (s:Entity)-[:REL]->(r:Relation)-[:REL]->(t:Entity), (r)<-[:MENTIONS]-(st:Sentence)
RETURN s.name as source_entity, t.name as target_entity, r.type as type, st.text as source_text
Resultater
Billede af forfatteren.
Som nævnt er NLP-modellen, jeg har brugt til at udtrække relationer, ikke perfekt, og da jeg ikke er læge, ved jeg ikke, hvor mange forbindelser den gik glip af. Men dem, den opdagede, virker rimelige.
Ekstern databaseberigelse
Som jeg nævnte før, kan vi stadig bruge de eksterne databaser som CHEBI eller MESH til at berige vores graf. For eksempel indeholder vores graf en medicinsk enhed Epidermolyse bullosa og vi kender også dens MeSH-id.
Du kan hente MeSH-id'et for Epidermolysis bullosa med følgende forespørgsel:
MATCH (e:Entity)
WHERE e.name = "Epidermolysis bullosa"
RETURN e.name as entity, e.other_ids as other_ids
Du kan gå videre og inspicere MeSH for at finde tilgængelig information:
Skærmbillede af forfatter. Data er udlånt af US National Library of Medicine.
Her er et skærmbillede af den tilgængelige information på MeSH-webstedet for Epidermolysis bullosa. Som nævnt er jeg ikke læge, så jeg ved ikke præcis, hvad der ville være den bedste måde at modellere denne information i en graf. Jeg vil dog vise dig, hvordan du henter disse oplysninger i Neo4j ved hjælp af apoc.load.json-proceduren for at hente oplysningerne fra MeSH REST-slutpunktet. Og så kan du bede en domæneekspert om at hjælpe dig med at modellere disse oplysninger.
Cypher-forespørgslen til at hente oplysningerne fra MeSH REST-slutpunktet er:
MATCH (e:Entity)
WHERE e.name = "Epidermolysis bullosa"
WITH e, [id in e.other_ids WHERE id contains "MESH" | split(id,":")[1]][0] as meshId
CALL apoc.load.json("https://id.nlm.nih.gov/mesh/lookup/details?descriptor=" + meshId) YIELD value
RETURN value
Vidensgraf som maskinlæringsdatainput
Som en sidste tanke vil jeg hurtigt lede dig igennem, hvordan du kunne bruge den biomedicinske vidensgraf som input til en maskinlærings-workflow. I de seneste år har der været en masse forskning og fremskridt inden for node-indlejring. Node-indlejringsmodeller oversætter netværkstopologien til indlejringsrum.
Antag, at du har konstrueret en biomedicinsk vidensgraf, der indeholder medicinske enheder og begreber, deres relationer og berigelse fra forskellige medicinske databaser. Du kan bruge teknikker til indlejring af noder til at lære noderepræsentationerne, som er vektorer med fast længde, og indlæse dem i dit maskinlærings-workflow. Forskellige applikationer bruger denne tilgang lige fra genbrug af lægemidler til forudsigelser af lægemiddelbivirkninger eller bivirkninger. Jeg har fundet et forskningspapir, der bruger link forudsigelse for potentielle behandlinger af nye sygdomme[4].
Konklusion
Det biomedicinske domæne er et godt eksempel, hvor vidensgrafer er anvendelige. Der er mange applikationer lige fra simple søgemaskiner til mere komplicerede maskinlæringsarbejdsgange. Forhåbentlig, ved at læse dette blogindlæg, kom du med nogle ideer til, hvordan du kunne bruge biomedicinske vidensgrafer til at understøtte dine applikationer. Du kan starte en gratis Neo4j Sandbox og begynde at udforske i dag.
[1] D. Kim et al., "Et neuralt navngivet enhedsgenkendelse og multi-type normaliseringsværktøj til biomedicinsk tekstminedrift," i IEEE-adgang, bind. 7, s. 73729–73740, 2019, doi: 10.1109/ACCESS.2019.2920708.
[2] Kastrin A, Rindflesch TC, Hristovski D. Link-forudsigelse i et MeSH co-forekomst netværk: foreløbige resultater. Stud Health Technol Inform. 2014;205:579-83. PMID: 25160252.
[3] Cetoli, A. (2020). Udforsker nul-skudsgrænsen for FewRel. I Proceedings of the 28th International Conference on Computational Linguistics (s. 1447–1451). International Komité for Computerlingvistik.
[4] Zhang, R., Hristovski, D., Schutte, D., Kastrin, A., Fiszman, M., & Kilicoglu, H. (2021). Genbrug af lægemidler til COVID-19 via færdiggørelse af vidensgraf. Journal of Biomedical Informatics, 115, 103696.
Denne artikel blev oprindeligt offentliggjort den Mod datalogi og genudgivet til TOPBOTS med tilladelse fra forfatteren.
Nyder du denne artikel? Tilmeld dig for flere AI-opdateringer.
Vi giver dig besked, når vi frigiver mere teknisk uddannelse.