Denne artikel blev offentliggjort som en del af Data Science Blogathon
Introduktion

Konvolutionelle neurale netværk, også kaldet ConvNets, blev først introduceret i 1980'erne af Yann LeCun, en datalogiforsker, der arbejdede i baggrunden. LeCun byggede på arbejdet fra Kunihiko Fukushima, en japansk videnskabsmand, et grundlæggende netværk for billedgenkendelse.
Den gamle version af CNN, kaldet LeNet (efter LeCun), kan se håndskrevne cifre. CNN hjælper med at finde pinkoder fra post. Men på trods af deres ekspertise forblev ConvNets tæt på computersyn og kunstig intelligens, fordi de stod over for et stort problem: De kunne ikke skalere meget. CNN'er kræver en masse data og integrerer ressourcer for at fungere godt til store billeder.
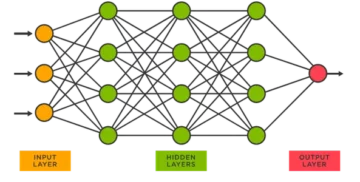
På det tidspunkt var denne metode kun anvendelig til billeder i lav opløsning. Pytorch er et bibliotek, der kan udføre deep learning operationer. Vi kan bruge dette til at udføre konvolutionelle neurale netværk. Konvolutionelle neurale netværk indeholder mange lag af kunstige neuroner. Syntetiske neuroner, komplekse simuleringer af biologiske modstykker, er matematiske funktioner, der beregner den vægtede masse af flere input og produktværdiaktivering.

Ovenstående billede viser os en CNN-model, der tager et cifferlignende billede af 2 og giver os resultatet af, hvilket ciffer der blev vist på billedet som et tal. Vi vil diskutere i detaljer, hvordan vi får dette i denne artikel.
CIFAR-10 er et datasæt, der har en samling af billeder af 10 forskellige klasser. Dette datasæt bruges i vid udstrækning til forskningsformål til at teste forskellige maskinlæringsmodeller og især til problemer med computersyn. I denne artikel vil vi forsøge at bygge en neural netværksmodel ved hjælp af Pytorch og teste den på CIFAR-10-datasættet for at kontrollere, hvilken nøjagtighed af forudsigelse der kan opnås.
Import af PyTorch-biblioteket
import numpy som np import pandaer som pd
import fakkel import torch.nn.functional as F fra torchvision import datasæt, transformerer fra fakkel import nn import matplotlib.pyplot som plt import numpy som np import seaborn som sns #from tqdm.notebook import tqdm fra tqdm import tqdm
I dette trin importerer vi de nødvendige biblioteker. Vi kan se, at vi bruger NumPy til numeriske operationer og pandaer til datarammeoperationer. Fakkelbiblioteket bruges til at importere Pytorch.
Pytorch har en nn-komponent, der bruges til abstraktion af maskinlæringsoperationer og -funktioner. Dette importeres som F. Torchvision-biblioteket bruges, så vi kan importere CIFAR-10-datasættet. Dette bibliotek har mange billeddatasæt og er meget brugt til forskning. Transformationerne kan importeres, så vi kan ændre størrelsen på billedet til samme størrelse for alle billederne. tqdm'en bruges til at vi kan holde styr på fremskridtene under træningen og bruges til visualisering.
Læs det nødvendige datasæt
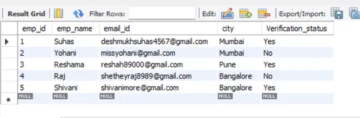
trainData = pd.read_csv('cifar-10/trainLabels.csv') trainData.head()
Når vi har læst datasættet, kan vi se forskellige etiketter som frøen, lastbilen, hjorten, bilen osv.
Analyse af data med PyTorch
print("Antal point:",trainData.shape[0]) print("Antal funktioner:",trainData.shape[1]) print("Features:",trainData.columns.values) print("Antal af Unikke værdier") for col in trainData: print(col,":",len(trainData[col].unique())) plt.figure(figsize=(12,8))
Output:
Antal point: 50000 Antal funktioner: 2 Funktioner: ['id' 'label'] Antal unikke værdier id : 50000 label : 10
I dette trin analyserer vi datasættet og ser, at vores togdata har omkring 50000 rækker med deres id og tilhørende etiket. Der er i alt 10 klasser som i navnet CIFAR-10.
Få valideringssæt ved hjælp af PyTorch
fra torch.utils.data import random_split val_size = 5000 train_size = len(datasæt) - val_size train_ds, val_ds = random_split(datasæt, [train_size, val_size]) len(train_ds), len(val_ds)
Dette trin er det samme som træningstrinnet, men vi ønsker at opdele dataene i tog- og valideringssæt.
(45000, 5000)
fra torch.utils.data.dataloader import DataLoader batch_size=64 train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True) val_dl = DataLoader(val_ds, batch_meersmor=4,Tru_meersmory)
Torch.utils har en dataindlæser, der kan hjælpe os med at indlæse de påkrævede data ved at omgå forskellige parametre som arbejdernummer eller batchstørrelse.
Definition af de nødvendige funktioner
@torch.no_grad() def nøjagtighed(output, labels): _, preds = torch.max(outputs, dim=1) return torch.tensor(torch.sum(preds == labels).item() / len(preds) )) klasse ImageClassificationBase(nn.Module): def training_step(self, batch): billeder, labels = batch out = self(images) # Generer forudsigelser tab = F.cross_entropy(out, labels) # Beregn tab accu = nøjagtighed(out) ,labels) return loss,accu def validation_step(self, batch): billeder, labels = batch out = self(images) # Generer forudsigelser tab = F.cross_entropy(out, labels) # Beregn tab acc = nøjagtighed(out, labels) # Beregn nøjagtighedsretur {'Loss': loss.detach(), 'Accuracy': acc} def validation_epoch_end(self, outputs): batch_losses = [x['Loss'] for x in outputs] epoch_loss = torch.stack(batch_losses) ).mean() # Kombiner tab batch_accs = [x['Nøjagtighed'] for x i output] epoch_acc = torch.stack(batch_accs).mean() # Kombiner nøjagtigheder returner {'Tab': epoch_loss.item(), ' Nøjagtighed': epoch_acc.item()} def epoch_end(selv, epoke, resultat): pr int("Epoke :",epoch + 1) print(f'Train Accuracy:{result["train_accuracy"]*100:.2f}% Valideringsnøjagtighed:{result["Accuracy"]*100:.2f}%' ) print(f'Train Loss:{result["train_loss"]:.4f} Valideringstab:{result["Loss"]:.4f}')
Som vi kan se her, har vi brugt klasseimplementering af ImageClassification, og det kræver en parameter, der er nn.Module. Inden for denne klasse kan vi implementere de forskellige funktioner eller forskellige trin som træning, validering osv. Funktionerne her er simple python-implementeringer.
Træningstrinnet tager billeder og etiketter i batches. vi bruger krydsentropi til tabsfunktion og beregner tabet og returnerer tabet. Dette svarer til valideringstrinnet, som vi kan se i funktionen. Epokens afslutning kombinerer tab og nøjagtigheder, og til sidst udskriver vi nøjagtighederne og tabene.
Implementering af konvolutionelt neuralt netværksmodul
klasse Cifar10CnnModel(ImageClassificationBase): def __init__(selv): super().__init__() self.network = nn.Sequential( nn.Conv2d(3, 32, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(2, 2), # output: 64 x 16 x 16 nn.BatchNorm2d(64) , nn.Conv2d(64, 128, kernel_size=3, skridt=1, polstring=1), nn.ReLU(), nn.Conv2d(128, 128, kernel_size=3, skridt=1, polstring=1), nn .ReLU(), nn.MaxPool2d(2, 2), # output: 128 x 8 x 8 nn.BatchNorm2d(128), nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.Conv2d(256, 256, kernel_size=3, stride=1, polstring=1), nn.ReLU(), nn.MaxPool2d(2, 2), # output: 256 x 4 x 4 nn.BatchNorm2d(256), nn.Flatten(), nn.Lineær(256*4*4, 1024), nn.ReLU(), nn.Lineær(1024, 512), nn.ReLU(), nn.Lineær (512, 10)) def forward(self, xb): return self.network(xb)
Dette er den vigtigste del af implementering af neurale netværk. Gennemgående bruger vi nn-modulet, vi importerede fra fakkel. Som vi kan se i den første linje, er Conv2d et modul, der hjælper med at implementere et foldet neuralt netværk. Den første parameter 3 repræsenterer her, at billedet er farvet og i RGB-format. Hvis det var et gråtonebillede, ville vi være gået efter 1.
32 er størrelsen på den indledende outputkanal, og når vi går efter det næste conv2d-lag, vil vi have denne 32 som inputkanal og 64 som outputkanal.
Den 3. parameter i den første linje kaldes kernestørrelse, og den hjælper os med at passe på de anvendte filtre. Padding operation er den sidste parameter.
Konvolutionsoperationen er forbundet til et aktiveringslag og Relu her. Efter to Conv2d-lag har vi en max-pooling-operation på størrelse 2 * 2. Den værdi, der kommer ud fra dette, er batch-normaliseret for stabilitet og for at undgå intern kovariatforskydning. Disse operationer gentages med flere lag for at dybere netværket og reducere størrelsen. Til sidst flader vi laget ud, så vi kan bygge et lineært lag for at kortlægge værdierne til 10 værdier. Sandsynligheden for hver neuron af disse 10 neuroner vil bestemme, hvilken klasse et bestemt billede tilhører baseret på den maksimale sandsynlighed.
Træn modellen
@torch.no_grad() def evaluate(model, data_loader): model.eval() outputs = [model.validation_step(batch) for batch i data_loader] returner model.validation_epoch_end(outputs) def fit(model, train_loader, val_loader,epoker =10,learning_rate=0.001): best_valid = Ingen historie = [] optimizer = torch.optim.Adam(model.parameters(), learning_rate,weight_decay=0.0005) for epoke i rækkevidde(epoker): # Træningsfase model.train( ) train_losses = [] train_accuracy = [] for batch i tqdm(train_loader): loss,accu = model.training_step(batch) train_losses.append(loss) train_accuracy.append(accu) loss.backward() optimizer.step() optimizer .zero_grad() # Valideringsfaseresultat = evaluate(model, val_loader) resultat['train_loss'] = torch.stack(train_losses).mean().item() result['train_accuracy'] = torch.stack(train_accuracy). mean().item() model.epoch_end(epoke, resultat) if(best_valid == Ingen eller best_valid
historie = fit(model, train_dl, val_dl)
Dette er et grundlæggende trin for at træne vores model for at få det ønskede resultat. Tilpasningsfunktionen her vil passe til tog- og Val-dataene med den model, vi har oprettet. Tilpasningsfunktionen tager til at begynde med en liste kaldet historie, der tager sig af iterationsdataene for hver epoke. Vi kører en for-løkke, så vi kan iterere over hver epoke. For hver batch sørger vi for, at vi viser fremskridtene ved hjælp af tqdm. Vi kalder det træningstrin, vi implementerede før, og beregner nøjagtighed og tab. Gå til baglæns udbredelse og kørselsoptimering, som vi definerede tidligere. Når vi gør dette, holder vi styr på vores liste, og funktionerne hjælper os med at udskrive detaljer og fremskridt.
Evalueringsfunktionen bruger derimod evalfunktionen, og for hvert trin tager vi den batch, der er indlæst fra dataindlæseren, og output beregnes. Værdien sendes derefter til den valideringsepoke, vi definerede tidligere, og den respektive værdi returneres.
Plot resultaterne
I dette trin vil vi visualisere nøjagtigheden i forhold til hver epoke. Vi kan observere, at når epoken øges, bliver systemets nøjagtighed ved med at stige, og tabet bliver på samme måde ved med at falde. Den røde linje her angiver træningsdatafremskridt og blå for valideringen. Vi kan se, at der har været en god del overfitting i vores resultater, da træningsdataene overgår valideringsresultatet og tilsvarende i tilfælde af tab. Efter 10 epoker ser togdataene ud til at omgå 90 % nøjagtighed, men har et tab på omkring 0.5. Testdataene kommer omkring 81%, og tabene er tæt på 0.2.
def plot_accuracies(historie): Validation_accuracies = [x['Accuracies'] for x i historik] Training_Accuracies = [x['train_accuracies'] for x in history] plt.plot(Training_Accuracies, '-rx') plt.plot(Validation_accuracies , '-bx') plt.xlabel('epoch') plt.ylabel('accuracy') plt.legend(['Training', 'Validation']) plt.title('Nøjagtighed vs. antal epoker') ; plot_accuracies(historie)

def plot_losses(history): train_losses = [x.get('train_loss') for x in history] val_losses = [x['Loss'] for x in history] plt.plot(train_losses, '-bx') plt.plot (val_losses, '-rx') plt.xlabel('epoch') plt.ylabel('tab') plt.legend(['Training', 'Validation']) plt.title('Tab vs. antal epoker '); plot_tabs(historie)
test_dataset = ImageFolder(data_dir+'/test', transform=ToTensor()) test_loader = DeviceDataLoader(DataLoader(test_dataset, batch_size), device) result = evaluate(final_model, test_loader) print(f'Test nøjagtighed:{result["Nøjagtighed" ]*100:.2f} %')
Testnøjagtighed: 81.07 %
Vi kan se, at vi ender med en nøjagtighed på 81.07%.
konklusion:
Billede:https://unsplash.com/photos/5L0R8ZqPZHk
Om mig: Jeg er en forskningsstuderende, der er interesseret i området Deep Learning og Natural Language Processing og forfølger i øjeblikket postgraduering i kunstig intelligens.
Image Source
- Image 1: https://becominghuman.ai/cifar-10-image-classification-fd2ace47c5e8
- Billede 2: https://www.analyticsvidhya.com/blog/2021/05/convolutional-neural-networks-cnn/
Du er velkommen til at kontakte mig på:
- Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
- Github: https://github.com/Siddharth1698
Medierne vist i denne artikel ejes ikke af Analytics Vidhya og bruges efter forfatterens skøn.
Relaterede
- "
- Alle
- analytics
- omkring
- artikel
- kunstig intelligens
- bygge
- ringe
- hvilken
- CNN
- kommer
- komponent
- Datalogi
- Computer Vision
- indviklet neuralt netværk
- data
- dyb læring
- Deer
- detail
- Digit
- cifre
- ender
- etc.
- Funktionalitet
- Filtre
- Endelig
- Fornavn
- passer
- format
- Gratis
- funktion
- GitHub
- godt
- Gråskala
- link.
- historie
- Hvordan
- HTTPS
- billede
- Billedgenkendelse
- Forøg
- Intelligens
- IT
- Etiketter
- Sprog
- stor
- læring
- Bibliotek
- Line (linje)
- Liste
- belastning
- machine learning
- større
- kort
- Medier
- model
- Naturligt sprog
- Natural Language Processing
- I nærheden af
- netværk
- net
- Neural
- neurale netværk
- neurale netværk
- Produktion
- Andet
- forudsigelse
- Forudsigelser
- Produkt
- Python
- pytorch
- reducere
- forskning
- Ressourcer
- Resultater
- Kør
- Scale
- Videnskab
- sæt
- skifte
- Simpelt
- Størrelse
- So
- delt
- Stabilitet
- studerende
- systemet
- prøve
- tid
- fakkel
- spor
- Kurser
- lastbil
- us
- værdi
- vision
- visualisering
- WHO
- inden for
- Arbejde
- X