Denne artikel blev offentliggjort som en del af Data Science Blogathon

Indtil nu har vi lært om lineær regression, logistisk regression, og de var ret svære at forstå. Lad os nu starte med beslutningstræet, og jeg forsikrer dig om, at dette sandsynligvis er den nemmeste algoritme inden for Machine Learning. Der er ikke meget matematik involveret her. Da det er meget nemt at bruge og fortolke, er det en af de mest udbredte og praktiske metoder, der bruges i Machine Learning.
Indhold
1. Hvad er et beslutningstræ?
2. Eksempel på et beslutningstræ
3. Entropi
4. Informationsgevinst
5. Hvornår skal man stoppe med at splitte?
6. Hvordan stopper man overfitting?
- max_depth
- min_samples_split
- min_samples_leaf
- max_features
7. Beskæring
- Efterbeskæring
- Forbeskæring
8. Slutnoter
Hvad er et beslutningstræ?
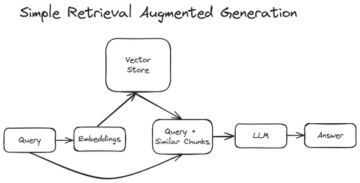
Det er et værktøj, der har applikationer, der spænder over flere forskellige områder. Beslutningstræer kan bruges til klassificering såvel som regressionsproblemer. Selve navnet antyder, at det bruger et rutediagram som en træstruktur til at vise forudsigelserne, der er resultatet af en række funktionsbaserede opdelinger. Det starter med en rodknude og slutter med en beslutning truffet af blade.

Billede 1
Før vi lærer mere om beslutningstræer, lad os blive fortrolige med nogle af terminologierne.
Rodnoder – Det er den knude, der er til stede i begyndelsen af et beslutningstræ fra denne knude, populationen begynder at opdele efter forskellige funktioner.
Beslutningsknudepunkter – de noder vi får efter at have splittet rodknuderne kaldes Decision Node
Bladknuder – de knudepunkter, hvor yderligere opdeling ikke er mulig, kaldes bladknuder eller terminalknuder
Undertræ – ligesom en lille del af en graf kaldes undergraf, på samme måde kaldes en undersektion af dette beslutningstræ undertræ.
Beskæring – er ikke andet end at skære nogle noder ned for at stoppe overfitting.

Billede 2
Eksempel på et beslutningstræ
Lad os forstå beslutningstræer ved hjælp af et eksempel.

Billede 3
Beslutningstræer er på hovedet, hvilket betyder, at roden er øverst, og så er denne rod opdelt i flere forskellige noder. Beslutningstræer er intet andet end en flok hvis-else-udsagn i lægmandssprog. Den kontrollerer, om betingelsen er sand, og hvis den er den, går den til den næste knude, der er knyttet til den beslutning.
I nedenstående diagram vil træet først spørge, hvad vejret er? Er det solrigt, overskyet eller regnfuldt? Hvis ja, så går den til næste funktion, som er fugt og vind. Den vil igen tjekke om der er en stærk eller svag vind, hvis det er en svag vind og det regner så kan personen gå og lege.

Billede 4
Har du bemærket noget i ovenstående flowchart? Vi ser, at hvis vejret er overskyet så skal vi ud og lege. Hvorfor delte den sig ikke mere? Hvorfor stoppede det der?
For at besvare dette spørgsmål skal vi vide om nogle få flere begreber som entropi, informationsgevinst og Gini-indeks. Men forenklet kan jeg sige her, at output for træningsdatasættet altid er ja for overskyet vejr, da der ikke er uorden her, behøver vi ikke at opdele noden yderligere.
Målet med maskinlæring er at mindske usikkerhed eller forstyrrelser fra datasættet, og til dette bruger vi beslutningstræer.
Nu tænker du sikkert, hvordan ved jeg, hvad der skal være rodnoden? hvad skal beslutningsknuden være? hvornår skal jeg stoppe med at dele? For at afgøre dette er der en metrik kaldet "Entropi", som er mængden af usikkerhed i datasættet.
Entropi
Entropi er intet andet end usikkerheden i vores datasæt eller mål for uorden. Lad mig prøve at forklare dette ved hjælp af et eksempel.
Antag, at du har en gruppe venner, der bestemmer, hvilken film de kan se sammen på søndag. Der er 2 valg for film, det ene er "Lucy" og den anden er "Titanic" og nu skal alle fortælle deres valg. Når alle har givet deres svar, ser vi det "Lucy" får 4 stemmer , "Titanic" får 5 stemmer. Hvilken film ser vi nu? Er det ikke svært at vælge 1 film nu, fordi stemmerne for begge film er nogenlunde lige store.
Det er netop det, vi kalder uorden, der er lige mange stemmer til begge film, og vi kan ikke rigtig beslutte os for, hvilken film vi skal se. Det ville have været meget nemmere, hvis stemmerne for "Lucy" var 8 og for "Titanic" var det 2. Her kunne vi sagtens sige, at flertallet af stemmerne er for "Lucy", og derfor vil alle se denne film.
I et beslutningstræ er output for det meste "ja" eller "nej"
Formlen for entropi er vist nedenfor:

Her s+ er sandsynligheden for positiv klasse
p- er sandsynligheden for negativ klasse
S er delmængden af træningseksemplet
Hvordan bruger beslutningstræer entropi?
Nu ved vi, hvad entropi er, og hvad er dens formel. Dernæst skal vi vide, hvordan præcist fungerer det i denne algoritme.
Entropi måler grundlæggende urenheden af en knude. Urenhed er graden af tilfældighed; det fortæller, hvor tilfældige vores data er. EN ren sub-split betyder, at enten skal du få "ja", eller også skal du få "nej".
Antag en funktion har 8 "ja" og 4 "nej" til at begynde med, efter den første opdeling af venstre knude får 5 'ja' og 2 'nej' hvorimod højre node får 3 'ja' og 2 'nej'.
Vi ser her, at splittelsen ikke er ren, hvorfor? Fordi vi stadig kan se nogle negative klasser i begge noder. For at lave et beslutningstræ skal vi beregne urenheden af hver spaltning, og når renheden er 100 %, laver vi den som en bladknude.
For at kontrollere urenheden af funktion 2 og funktion 3 vil vi tage hjælp til Entropi-formlen.

Billedkilde: Forfatter

For funktion 3,

Vi kan tydeligt se fra selve træet, at venstre knude har lav entropi eller mere renhed end højre knude, da venstre knude har et større antal "ja", og det er nemt at afgøre her.
Husk altid, at jo højere entropi, jo lavere vil renheden være, og jo højere vil urenheden være.
Som tidligere nævnt er målet med maskinlæring at mindske usikkerheden eller urenheden i datasættet, her ved at bruge entropien får vi urenheden af en bestemt node, vi ved ikke om forældreentropien eller entropien af en bestemt node er faldet eller ej.
Til dette bringer vi en ny metrik kaldet "Informationsgevinst", som fortæller os, hvor meget forældreentropien er faldet efter at have opdelt den med en eller anden funktion.
Informationsgevinst
Informationsgevinst måler reduktionen af usikkerhed givet en eller anden funktion, og det er også en afgørende faktor for, hvilken attribut der skal vælges som en beslutningsknude eller rodknude.

Det er blot entropi af det fulde datasæt - entropi af datasættet givet en eller anden funktion.
For at forstå dette bedre, lad os overveje et eksempel:
Antag, at hele vores befolkning har i alt 30 tilfælde. Datasættet skal forudsige, om personen vil gå i fitnesscenter eller ej. Lad os sige, at 16 personer går i fitnesscenteret og 14 personer ikke
Nu har vi to funktioner til at forudsige, om han/hun vil gå i fitnesscenter eller ej.
Funktion 1 er "Energi" som tager to værdier "højt og lavt"
Funktion 2 er "Motivering" som tager 3 værdier "Ingen motivation", "Neutral" og "Stærkt motiveret".
Lad os se, hvordan vores beslutningstræ vil blive lavet ved hjælp af disse 2 funktioner. Vi vil bruge informationsgevinst til at bestemme, hvilken funktion der skal være rodnoden, og hvilken funktion der skal placeres efter opdelingen.

Billedkilde: Forfatter
Lad os beregne entropien:

For at se det vægtede gennemsnit af entropi af hver knude vil vi gøre som følger:

Nu har vi værdien af E(Parent) og E(Parent|Energy), informationsgevinst vil være:

Vores moderentropi var tæt på 0.99, og efter at have set på denne værdi af informationsgevinst, kan vi sige, at entropien af datasættet vil falde med 0.37, hvis vi laver "Energy" som vores rodknude.
På samme måde vil vi gøre dette med den anden funktion "Motivation" og beregne dens informationsgevinst.

Billedkilde: Forfatter
Lad os beregne entropien her:

For at se det vægtede gennemsnit af entropi af hver knude vil vi gøre som følger:

Nu har vi værdien af E(Forælder) og E(Forældre|Motivation), informationsgevinst vil være:

Vi ser nu, at "Energi"-funktionen giver mere reduktion, hvilket er 0.37 end "Motivation"-funktionen. Derfor vil vi vælge den funktion, der har den højeste informationsforstærkning, og derefter opdele noden baseret på den funktion.

I dette eksempel vil "Energi" være vores rodknude, og vi vil gøre det samme for undernoder. Her kan vi se, at når energien er "høj", er entropien lav, og derfor kan vi sige, at en person helt sikkert vil gå i fitnesscenter, hvis han har høj energi, men hvad hvis energien er lav? Vi vil igen opdele noden baseret på den nye funktion, som er "Motivation".
Hvornår skal man stoppe med at splitte?
Du må stille dette spørgsmål til dig selv, at hvornår stopper vi med at dyrke vores træ? Normalt har virkelige datasæt et stort antal funktioner, hvilket vil resultere i et stort antal opdelinger, hvilket igen giver et kæmpe træ. Sådanne træer tager tid at bygge og kan føre til overfitting. Det betyder, at træet vil give meget god nøjagtighed på træningsdatasættet, men vil give dårlig nøjagtighed i testdata.
Der er mange måder at tackle dette problem på ved hjælp af hyperparameterjustering. Vi kan indstille den maksimale dybde af vores beslutningstræ ved hjælp af max_depth parameter. Jo mere værdien af max_depth, jo mere komplekst vil dit træ være. Træningsfejlen vil uden for kurset falde, hvis vi øger max_depth værdi, men når vores testdata kommer ind i billedet, vil vi få en meget dårlig nøjagtighed. Derfor har du brug for en værdi, der ikke vil over- eller underpasse vores data, og til dette kan du bruge GridSearchCV.
En anden måde er at indstille minimumsantallet af prøver for hvert spild. Det er betegnet med min_samples_split. Her specificerer vi det mindste antal prøver, der kræves for at udføre et spild. For eksempel kan vi bruge minimum 10 prøver til at nå frem til en beslutning. Det betyder, at hvis en node har mindre end 10 samples, kan vi ved at bruge denne parameter stoppe den yderligere opdeling af denne node og gøre den til en bladknude.
Der er flere hyperparametre såsom:
min_samples_leaf – repræsenterer det mindste antal prøver, der kræves for at være i bladknuden. Jo mere du øger antallet, jo større er muligheden for overfitting.
max_features – det hjælper os med at beslutte, hvilket antal funktioner vi skal overveje, når vi leder efter den bedste opdeling.
For at læse mere om disse hyperparametre kan du læse den link..
Beskæring
Det er en anden metode, der kan hjælpe os med at undgå overfitting. Det hjælper med at forbedre træets ydeevne ved at skære de noder eller underknuder, som ikke er signifikante. Det fjerner de grene, som har meget lav betydning.
Der er hovedsageligt 2 måder at beskære på:
(I) Forbeskæring – vi kan stoppe med at dyrke træet tidligere, hvilket betyder, at vi kan beskære/fjerne/klippe en knude, hvis den har lav betydning mens den vokser træet.
(Ii) Efterbeskæring – engang vores træet er bygget til dets dybde, kan vi begynde at beskære noderne baseret på deres betydning.
slutnoter
For at opsummere lærte vi i denne artikel om beslutningstræer. På hvilket grundlag træet splitter knuderne og hvordan man kan stoppe overfitting. hvorfor lineær regression ikke virker i tilfælde af klassifikationsproblemer.
I den næste artikel vil jeg forklare Random forests, som igen er en ny teknik til at undgå overfitting.
For at tjekke den fulde implementering af beslutningstræer henvises til min Github repository.
Lad mig vide, hvis du har spørgsmål i kommentarerne nedenfor.
Om forfatteren
Jeg er en bachelorstuderende i øjeblikket i mit sidste år med hovedfag i statistik (bachelor i statistik) og har en stærk interesse inden for datavidenskab, maskinlæring og kunstig intelligens. Jeg nyder at dykke ned i data for at opdage trends og anden værdifuld indsigt om dataene. Jeg lærer hele tiden og motiveres til at prøve nye ting.
Jeg er åben for samarbejde og arbejde.
For enhver tvivl og spørgsmål, kontakt mig gerne på E-mail
Medierne vist i denne artikel ejes ikke af Analytics Vidhya og bruges efter forfatterens skøn.
Billedkilder
- Billede 1 – https://wiki.pathmind.com/decision-tree
- Billede 2 – https://wiki.pathmind.com/decision-tree
- Billede 3 – www.hackerearth.com
- Billede 4 – www.hackerearth.com
Relaterede
Kilde: https://www.analyticsvidhya.com/blog/2021/08/decision-tree-algorithm/
- "
- 77
- algoritme
- analytics
- applikationer
- artikel
- kunstig intelligens
- BEDSTE
- grene
- bygge
- Bunch
- ringe
- Kontrol
- klassificering
- samarbejde
- kommentarer
- data
- datalogi
- beslutning træ
- DID
- sygdom
- ender
- energi
- Feature
- Funktionalitet
- Fornavn
- Gratis
- fuld
- sådan her
- godt
- gruppe
- Dyrkning
- vejlede
- gym
- link.
- Høj
- Hvordan
- How To
- HTTPS
- kæmpe
- Forøg
- indeks
- oplysninger
- indsigt
- Intelligens
- interesse
- involverede
- IT
- stor
- føre
- lærte
- læring
- machine learning
- Flertal
- matematik
- måle
- Medier
- film
- Film
- I nærheden af
- ny funktion
- noder
- åbent
- ordrer
- Andet
- Mennesker
- ydeevne
- billede
- befolkning
- Forudsigelser
- præsentere
- regression
- Videnskab
- valgt
- Series
- sæt
- Simpelt
- lille
- delt
- starte
- statistik
- studerende
- fortæller
- prøve
- Tænker
- tid
- top
- Kurser
- Tendenser
- us
- værdi
- Ur
- Hvad er
- WHO
- blæst
- Arbejde
- år
- youtube