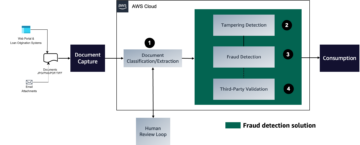
Dette blogindlæg er skrevet sammen med Chaoyang He og Salman Avestimehr fra FedML.
Analyse af data fra den virkelige verden af sundheds- og biovidenskab (HCLS) udgør adskillige praktiske udfordringer, såsom distribuerede datasiloer, mangel på tilstrækkelige data på et enkelt sted til sjældne hændelser, lovgivningsmæssige retningslinjer, der forbyder datadeling, infrastrukturkrav og omkostninger forbundet med at skabe et centraliseret datalager. Fordi de er i et stærkt reguleret domæne, søger HCLS-partnere og kunder mekanismer, der beskytter privatlivets fred, til at administrere og analysere store, distribuerede og følsomme data.
For at afbøde disse udfordringer foreslår vi en fødereret læringsramme (FL) baseret på open source FedML på AWS, som gør det muligt at analysere følsomme HCLS-data. Det involverer træning af en global maskinlæringsmodel (ML) ud fra distribuerede sundhedsdata, der opbevares lokalt på forskellige steder. Det kræver ikke flytning eller deling af data på tværs af websteder eller med en centraliseret server under modeltræningsprocessen.
Implementering af en FL-ramme i skyen har flere udfordringer. Automatisering af klient-server-infrastrukturen for at understøtte flere konti eller virtuelle private skyer (VPC'er) kræver VPC-peering og effektiv kommunikation på tværs af VPC'er og instanser. I en produktionsarbejdsbelastning er en stabil implementeringspipeline nødvendig for problemfrit at tilføje og fjerne klienter og opdatere deres konfigurationer uden meget overhead. Desuden kan klienter i en heterogen opsætning have forskellige krav til beregning, netværk og lagring. I denne decentraliserede arkitektur kan det være vanskeligt at logge og fejlfinde fejl på tværs af klienter. Endelig er det en besværlig opgave at bestemme den optimale tilgang til aggregerede modelparametre, vedligeholde modellens ydeevne, sikre databeskyttelse og forbedre kommunikationseffektiviteten. I dette indlæg adresserer vi disse udfordringer ved at levere en federated learning operations (FLOps) skabelon, der er vært for en HCLS-løsning. Løsningen er agnostisk at bruge cases, hvilket betyder at du kan tilpasse den til dine use cases ved at ændre model og data.
I denne todelte serie demonstrerer vi, hvordan du kan implementere en cloud-baseret FL-ramme på AWS. I den første indlæg, beskrev vi FL-koncepter og FedML-rammerne. I denne anden del præsenterer vi et proof-of-concept brugscase for sundhedspleje og biovidenskab fra et datasæt fra den virkelige verden eICU. Dette datasæt omfatter en multi-center kritisk plejedatabase indsamlet fra over 200 hospitaler, hvilket gør det ideelt at teste vores FL-eksperimenter.
HCLS use case
Med henblik på demonstration byggede vi en FL-model på et offentligt tilgængeligt datasæt til at håndtere kritisk syge patienter. Vi brugte eICU Collaborative Research Database, en multi-center intensive care unit (ICU) database, der omfatter 200,859 patientenhedsmøder for 139,367 unikke patienter. De blev indlagt på en af 335 enheder på 208 hospitaler i hele USA mellem 2014-2015. På grund af den underliggende heterogenitet og distribuerede karakter af dataene giver det et ideelt eksempel fra den virkelige verden til at teste denne FL-ramme. Datasættet omfatter laboratoriemålinger, vitale tegn, plejeplanoplysninger, medicin, patienthistorie, indlæggelsesdiagnose, tidsstemplede diagnoser fra en struktureret problemliste og lignende valgte behandlinger. Den er tilgængelig som et sæt CSV-filer, som kan indlæses i ethvert relationelt databasesystem. Tabellerne er afidentificeret for at opfylde de regulatoriske krav US Health Insurance Portability and Accountability Act (HIPAA). Dataene kan tilgås via et PhysioNet-depot, og detaljer om dataadgangsprocessen kan findes her [1].
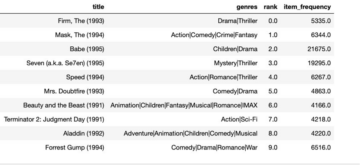
eICU-dataene er ideelle til at udvikle ML-algoritmer, beslutningsstøtteværktøjer og fremme klinisk forskning. Til benchmarkanalyse overvejede vi opgaven med at forudsige patienters dødelighed på hospitalet [2]. Vi definerede det som en binær klassifikationsopgave, hvor hver dataprøve strækker sig over et 1-times vindue. For at skabe en kohorte til denne opgave udvalgte vi patienter med sygehusudskrivningsstatus i patientjournalen og en liggetid på mindst 48 timer, fordi vi fokuserer på forudsigelse af dødelighed i de første 24 og 48 timer. Dette skabte en kohorte på 30,680 patienter indeholdende 1,164,966 journaler. Vi har vedtaget domænespecifik dataforbehandling og metoder beskrevet i [3] til forudsigelse af dødelighed. Dette resulterede i et aggregeret datasæt bestående af flere kolonner pr. patient pr. journal, som vist i følgende figur. Følgende tabel giver en patientjournal i en tabelformet grænseflade med tid i kolonner (5 intervaller over 48 timer) og vitale tegn observationer i rækker. Hver række repræsenterer en fysiologisk variabel, og hver kolonne repræsenterer dens værdi registreret over et tidsvindue på 48 timer for en patient.
| Fysiologisk parameter | Diagram_Tid_0 | Diagram_Tid_1 | Diagram_Tid_2 | Diagram_Tid_3 | Diagram_Tid_4 |
| Glasgow Coma Score Eyes | 4 | 4 | 4 | 4 | 4 |
| FiO2 | 15 | 15 | 15 | 15 | 15 |
| Glasgow Coma Score Eyes | 15 | 15 | 15 | 15 | 15 |
| Heart Rate | 101 | 100 | 98 | 99 | 94 |
| Invasiv BP diastolisk | 73 | 68 | 60 | 64 | 61 |
| Invasiv BP systolisk | 124 | 122 | 111 | 105 | 116 |
| Gennemsnitligt arterielt tryk (mmHg) | 77 | 77 | 77 | 77 | 77 |
| Glasgow Coma Score Motor | 6 | 6 | 6 | 6 | 6 |
| 02 Mætning | 97 | 97 | 97 | 97 | 97 |
| Åndedrætsfrekvens | 19 | 19 | 19 | 19 | 19 |
| Temperatur (C) | 36 | 36 | 36 | 36 | 36 |
| Glasgow Coma Score Verbal | 5 | 5 | 5 | 5 | 5 |
| optagelseshøjde | 162 | 162 | 162 | 162 | 162 |
| optagelsesvægt | 96 | 96 | 96 | 96 | 96 |
| alder | 72 | 72 | 72 | 72 | 72 |
| apacheadmissiondx | 143 | 143 | 143 | 143 | 143 |
| etnicitet | 3 | 3 | 3 | 3 | 3 |
| køn | 1 | 1 | 1 | 1 | 1 |
| glucose | 128 | 128 | 128 | 128 | 128 |
| modregning på hospitalsindlæggelse | -436 | -436 | -436 | -436 | -436 |
| sygehusudskrivningsstatus | 0 | 0 | 0 | 0 | 0 |
| vareforskydning | -6 | -1 | 0 | 1 | 2 |
| pH | 7 | 7 | 7 | 7 | 7 |
| patientenhed forbliver | 2918620 | 2918620 | 2918620 | 2918620 | 2918620 |
| unitdischarge offset | 1466 | 1466 | 1466 | 1466 | 1466 |
| enhedsudladningsstatus | 0 | 0 | 0 | 0 | 0 |
Vi brugte både numeriske og kategoriske træk og grupperede alle journaler for hver patient for at udflade dem i en enkelt-record tidsserie. De syv kategoriske træk (indlæggelsesdiagnose, etnicitet, køn, Glasgow Coma Score Total, Glasgow Coma Score Eyes, Glasgow Coma Score Motor og Glasgow Coma Score Verbal blev konverteret til one-hot encoding vektorer) indeholdt 429 unikke værdier og blev konverteret til én -varme indstøbninger. For at forhindre datalækage på tværs af træningsknudeservere opdelte vi dataene efter hospitals-id'er og opbevarede alle optegnelser for et hospital på en enkelt node.
Løsningsoversigt
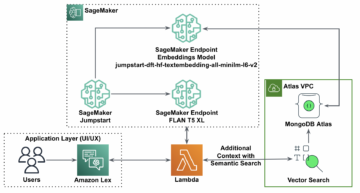
Følgende diagram viser arkitekturen for implementering af flere konti af FedML på AWS. Dette inkluderer to klienter (deltager A og deltager B) og en modelaggregator.
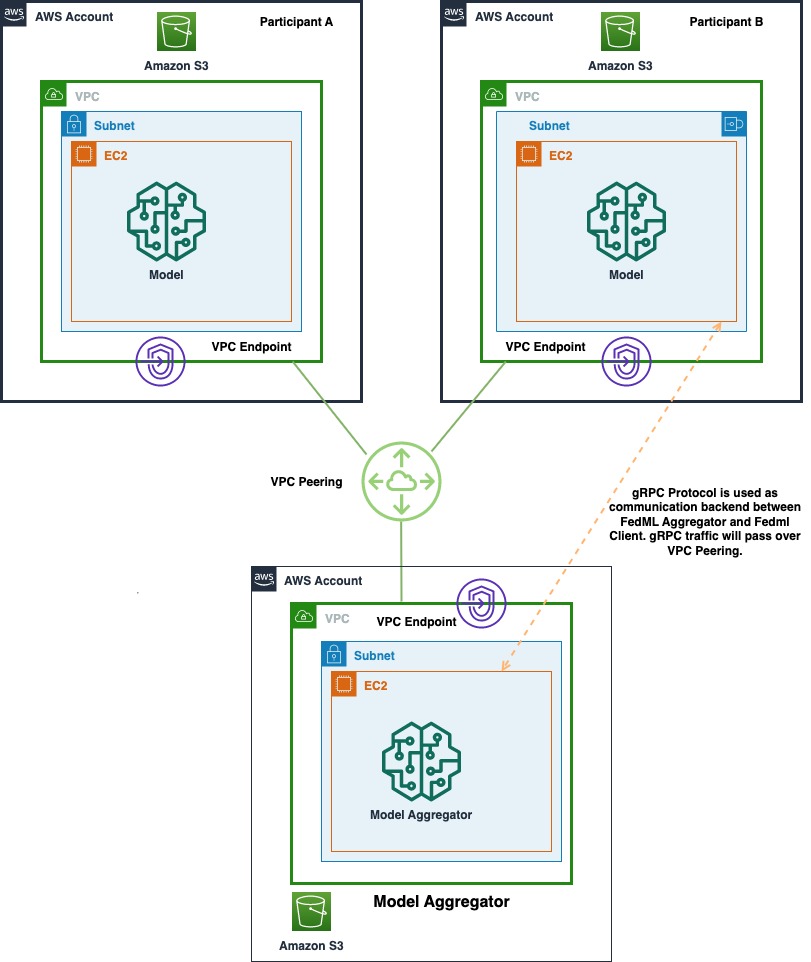
Arkitekturen består af tre separate Amazon Elastic Compute Cloud (Amazon EC2) forekomster, der kører på sin egen AWS-konto. Hver af de to første instanser ejes af en klient, og den tredje instans ejes af modelaggregatoren. Konti er forbundet via VPC-peering, så ML-modeller og vægte kan udveksles mellem kunder og aggregator. gRPC bruges som kommunikations-backend til kommunikation mellem modelaggregator og klienter. Vi testede en enkelt kontobaseret distribueret computeropsætning med en server og to klientnoder. Hver af disse forekomster blev oprettet ved hjælp af en tilpasset Amazon EC2 AMI med FedML-afhængigheder installeret i henhold til FedML.ai installationsvejledning.
Opsæt VPC-peering
Når du har startet de tre forekomster i deres respektive AWS-konti, etablerer du VPC-peering mellem konti via Amazon Virtual Private Cloud (Amazon VPC). For at oprette en VPC-peering-forbindelse skal du først oprette en anmodning om at peere med en anden VPC. Du kan anmode om en VPC-peering-forbindelse med en anden VPC på din konto eller med en VPC på en anden AWS-konto. For at aktivere anmodningen skal ejeren af VPC'et acceptere anmodningen. Med henblik på denne demonstration har vi oprettet peering-forbindelsen mellem VPC'er på forskellige konti, men den samme region. For andre konfigurationer af VPC-peering, se Opret en VPC-peering-forbindelse.
Før du begynder, skal du sørge for, at du har AWS-kontonummeret og VPC-id'et på VPC'en at peer med.
Anmod om en VPC-peering-forbindelse
For at oprette VPC-peering-forbindelsen skal du udføre følgende trin:
- På Amazon VPC-konsollen skal du i navigationsruden vælge Peering-forbindelser.
- Vælg Opret peering-forbindelse.
- Til Peering-forbindelses navnemærke, kan du valgfrit navngive din VPC-peering-forbindelse. Hvis du gør det, oprettes et tag med en nøgle af navnet og en værdi, som du angiver. Dette tag er kun synligt for dig; ejeren af peer-VPC'en kan oprette deres egne tags til VPC-peering-forbindelsen.
- Til VPC (anmoder), vælg VPC'en på din konto for at oprette peering-forbindelsen.
- Til Konto, vælg En anden konto.
- Til Konto-id, skal du indtaste AWS-konto-id'et for ejeren af den accepterende VPC.
- Til VPC (Accepter), skal du indtaste det VPC-id, som du vil oprette VPC-peering-forbindelsen med.
- Vælg i bekræftelsesdialogboksen OK.
- Vælg Opret peering-forbindelse.
Accepter en VPC-peering-forbindelse
Som tidligere nævnt skal VPC-peering-forbindelsen accepteres af ejeren af den VPC, som forbindelsesanmodningen er sendt til. Udfør følgende trin for at acceptere anmodningen om peering-forbindelse:
- På Amazon VPC-konsollen skal du bruge regionsvælgeren til at vælge regionen for den accepterende VPC.
- Vælg i navigationsruden Peering-forbindelser.
- Vælg den afventende VPC-peering-forbindelse (statussen er
pending-acceptance), og på handlinger menu, vælg Accepter anmodning. - Vælg i bekræftelsesdialogboksen Ja, Accepter.
- I den anden bekræftelsesdialog skal du vælge Rediger mine rutetabeller nu for at gå direkte til rutetabeller-siden, eller vælg Luk at gøre dette senere.
Opdater rutetabeller
For at aktivere privat IPv4-trafik mellem forekomster i peerede VPC'er skal du tilføje en rute til rutetabellerne, der er knyttet til undernettene for begge forekomster. Rutedestinationen er CIDR-blokken (eller en del af CIDR-blokken) af peer-VPC'en, og målet er ID'et for VPC-peeringforbindelsen. For mere information, se Konfigurer rutetabeller.
Opdater dine sikkerhedsgrupper til at referere til peer VPC-grupper
Opdater de indgående eller udgående regler for dine VPC-sikkerhedsgrupper for at referere til sikkerhedsgrupper i den peerede VPC. Dette tillader trafik at flyde på tværs af forekomster, der er knyttet til den refererede sikkerhedsgruppe i den peerede VPC. For flere detaljer om opsætning af sikkerhedsgrupper, se Opdater dine sikkerhedsgrupper til at referere til peer-sikkerhedsgrupper.
Konfigurer FedML
Når du har kørt de tre EC2-forekomster, skal du oprette forbindelse til hver af dem og udføre følgende trin:
- Klon FedML-depot.
- Angiv topologidata om dit netværk i konfigurationsfilen
grpc_ipconfig.csv.
Denne fil kan findes på FedML/fedml_experiments/distributed/fedavg i FedML-depotet. Filen indeholder data om serveren og klienterne og deres udpegede nodemapping, såsom FL Server – Node 0, FL Client 1 – Node 1 og FL Client 2 – Node2.
- Definer GPU-tilknytningskonfigurationsfilen.
Denne fil kan findes på FedML/fedml_experiments/distributed/fedavg i FedML-depotet. Filen gpu_mapping.yaml består af konfigurationsdata til klientserver-mapping til den tilsvarende GPU, som vist i det følgende uddrag.
Når du har defineret disse konfigurationer, er du klar til at køre klienterne. Bemærk at klienterne skal køres før serveren startes. Inden vi gør det, lad os konfigurere dataindlæserne til eksperimenterne.
Tilpas FedML til eICU
For at tilpasse FedML-lageret til eICU-datasættet skal du foretage følgende ændringer i data- og dataindlæseren.
data
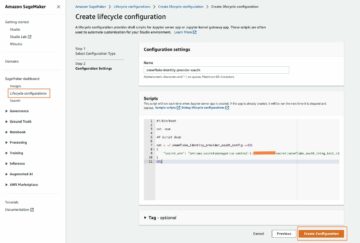
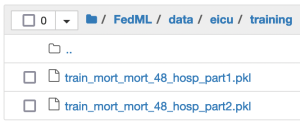
Tilføj data til den forudtildelte datamappe, som vist på det følgende skærmbillede. Du kan placere dataene i enhver mappe efter eget valg, så længe stien er konsekvent refereret til i træningsscriptet og har adgang aktiveret. For at følge et HCLS-scenarie i den virkelige verden, hvor lokale data ikke deles på tværs af websteder, skal du opdele og prøve dataene, så der ikke er nogen overlapning af hospitals-id'er på tværs af de to klienter. Dette sikrer, at et hospitals data er hostet på dets egen server. Vi håndhævede også den samme begrænsning for at opdele dataene i tog-/testsæt inden for hver klient. Hvert af tog-/testsættene på tværs af klienterne havde et forhold på 1:10 af positive til negative etiketter, med omkring 27,000 prøver under træning og 3,000 prøver i test. Vi håndterer dataubalancen i modeltræning med en vægtet tabsfunktion.
Dataindlæser
Hver af FedML-klienterne indlæser dataene og konverterer dem til PyTorch-tensorer for effektiv træning på GPU. Udvid den eksisterende FedML-nomenklatur for at tilføje en mappe til eICU-data i data_processing mappe.

Følgende kodestykke indlæser dataene fra datakilden. Den forbehandler dataene og returnerer én vare ad gangen gennem __getitem__ funktion.
Træning af ML-modeller med et enkelt datapunkt ad gangen er kedeligt og tidskrævende. Modeltræning udføres typisk på en batch af datapunkter hos hver klient. For at implementere dette skal dataindlæseren i data_loader.py script konverterer NumPy-arrays til Torch-tensorer, som vist i følgende kodestykke. Bemærk, at FedML leverer dataset.py , data_loader.py scripts til både strukturerede og ustrukturerede data, som du kan bruge til dataspecifikke ændringer, som i ethvert PyTorch-projekt.
Importer dataindlæseren til træningsscriptet
Når du har oprettet dataindlæseren, skal du importere den til FedML-koden til ML-modeltræning. Som ethvert andet datasæt (for eksempel CIFAR-10 og CIFAR-100), indlæs eICU-dataene til main_fedavg.py script i stien FedML/fedml_experiments/distributed/fedavg/. Her brugte vi det fødererede gennemsnit (fedavg) aggregeringsfunktion. Du kan følge en lignende metode til at konfigurere main fil til enhver anden aggregeringsfunktion.
Vi kalder dataindlæsningsfunktionen for eICU-data med følgende kode:
Definer modellen
FedML understøtter adskillige klare deep learning-algoritmer til forskellige datatyper, såsom tabel-, tekst-, billed-, grafer og Internet of Things-data (IoT). Indlæs modellen, der er specifik for eICU, med input- og outputdimensioner defineret baseret på datasættet. Til denne proof of concept-udvikling brugte vi en logistisk regressionsmodel til at træne og forudsige dødeligheden for patienter med standardkonfigurationer. Følgende kodestykke viser de opdateringer, vi har lavet til main_fedavg.py manuskript. Bemærk, at du også kan bruge brugerdefinerede PyTorch-modeller med FedML og importere det til main_fedavg.py scripts.
Kør og overvåg FedML-træning på AWS
Den følgende video viser træningsprocessen, der initialiseres hos hver af klienterne. Efter at begge klienter er angivet for serveren, skal du oprette servertræningsprocessen, der udfører fødereret aggregering af modeller.
For at konfigurere FL-serveren og klienterne skal du udføre følgende trin:
- Kør klient 1 og klient 2.
For at køre en klient skal du indtaste følgende kommando med dens tilsvarende node-id. For at køre klient 1 med node ID 1, skal du køre fra kommandolinjen:
- Når begge klientforekomster er startet, skal du starte serverforekomsten med den samme kommando og det relevante node-id i henhold til din konfiguration i
grpc_ipconfig.csv file. Du kan se modelvægtene blive sendt til serveren fra klientforekomsterne.
- Vi træner FL model i 50 epoker. Som du kan se i videoen nedenfor, overføres vægtene mellem knudepunkter 0, 1 og 2, hvilket indikerer, at træningen skrider frem som forventet på en fødereret måde.
- Til sidst skal du overvåge og spore FL-modellens træningsprogression på tværs af forskellige noder i klyngen ved hjælp af vægte og skævheder (wandb) værktøj, som vist på det følgende skærmbillede. Følg venligst de angivne trin link. at installere wandb og opsætningsovervågning for denne løsning.
Følgende video fanger alle disse trin for at give en ende-til-ende demonstration af FL på AWS ved hjælp af FedML:
Konklusion
I dette indlæg viste vi, hvordan du kan implementere en FL-ramme, baseret på open source FedML, på AWS. Det giver dig mulighed for at træne en ML-model på distribuerede data, uden at du behøver at dele eller flytte den. Vi opretter en multi-konto arkitektur, hvor hospitaler eller sundhedsorganisationer i et scenarie i den virkelige verden kan slutte sig til økosystemet for at drage fordel af kollaborativ læring og samtidig opretholde datastyring. Vi brugte multihospitals eICU-datasættet til at teste denne implementering. Denne ramme kan også anvendes på andre use cases og domæner. Vi vil fortsætte med at udvide dette arbejde ved at automatisere implementeringen gennem infrastruktur som kode (ved hjælp af AWS CloudFormation), yderligere inkorporering af privatlivsbevarende mekanismer og forbedring af FL-modellernes fortolkning og retfærdighed.
Gennemgå venligst præsentationen på re:MARS 2022 med fokus på "Managed Federated Learning på AWS: Et casestudie for sundhedspleje” for en detaljeret gennemgang af denne løsning.
Henvisning
[1] Pollard, Tom J., et al. "eICU Collaborative Research Database, en frit tilgængelig multicenterdatabase for intensiv-forskning." Videnskabelige data 5.1 (2018): 1-13.
[2] Yin, X., Zhu, Y. og Hu, J., 2021. En omfattende undersøgelse af privatlivsbevarende fødereret læring: En taksonomi, gennemgang og fremtidige retninger. ACM Computing Surveys (CSUR), 54(6), pp.1-36.
[3] Sheikhalishahi, Seyedmostafa, Vevake Balaraman og Venet Osmani. "Benchmarking af maskinlæringsmodeller på multi-center eICU kritisk pleje datasæt." Plos en 15.7 (2020): e0235424.
Om forfatterne
 Vidya Sagar Ravipati er leder på Amazon ML Solutions Lab, hvor han udnytter sin store erfaring med distribuerede systemer i stor skala og sin passion for maskinlæring til at hjælpe AWS-kunder på tværs af forskellige brancher med at accelerere deres AI og cloud-adoption. Tidligere var han Machine Learning Engineer i Connectivity Services hos Amazon, som hjalp med at bygge personalisering og forudsigende vedligeholdelsesplatforme.
Vidya Sagar Ravipati er leder på Amazon ML Solutions Lab, hvor han udnytter sin store erfaring med distribuerede systemer i stor skala og sin passion for maskinlæring til at hjælpe AWS-kunder på tværs af forskellige brancher med at accelerere deres AI og cloud-adoption. Tidligere var han Machine Learning Engineer i Connectivity Services hos Amazon, som hjalp med at bygge personalisering og forudsigende vedligeholdelsesplatforme.
 Olivia Choudhury, PhD, er Senior Partner Solutions Architect hos AWS. Hun hjælper partnere inden for Healthcare and Life Sciences-domænet med at designe, udvikle og skalere state-of-the-art løsninger, der udnytter AWS. Hun har en baggrund inden for genomik, sundhedsanalyse, fødereret læring og maskinlæring, der beskytter privatlivets fred. Uden for arbejdet spiller hun brætspil, maler landskaber og samler på manga.
Olivia Choudhury, PhD, er Senior Partner Solutions Architect hos AWS. Hun hjælper partnere inden for Healthcare and Life Sciences-domænet med at designe, udvikle og skalere state-of-the-art løsninger, der udnytter AWS. Hun har en baggrund inden for genomik, sundhedsanalyse, fødereret læring og maskinlæring, der beskytter privatlivets fred. Uden for arbejdet spiller hun brætspil, maler landskaber og samler på manga.
 Wajahat Aziz er Principal Machine Learning og HPC Solutions Architect hos AWS, hvor han fokuserer på at hjælpe sundheds- og biovidenskabskunder med at udnytte AWS-teknologier til at udvikle avancerede ML- og HPC-løsninger til en bred vifte af anvendelsessager såsom Drug Development, Kliniske forsøg og maskinlæring, der bevarer privatlivets fred. Uden for arbejdet kan Wajahat lide at udforske naturen, vandre og læse.
Wajahat Aziz er Principal Machine Learning og HPC Solutions Architect hos AWS, hvor han fokuserer på at hjælpe sundheds- og biovidenskabskunder med at udnytte AWS-teknologier til at udvikle avancerede ML- og HPC-løsninger til en bred vifte af anvendelsessager såsom Drug Development, Kliniske forsøg og maskinlæring, der bevarer privatlivets fred. Uden for arbejdet kan Wajahat lide at udforske naturen, vandre og læse.
 Divya Bhargavi er Data Scientist og Media and Entertainment Vertical Lead ved Amazon ML Solutions Lab, hvor hun løser forretningsproblemer af høj værdi for AWS-kunder ved hjælp af Machine Learning. Hun arbejder med billed-/videoforståelse, vidensgrafanbefalingssystemer, prædiktiv annonceringsbrug.
Divya Bhargavi er Data Scientist og Media and Entertainment Vertical Lead ved Amazon ML Solutions Lab, hvor hun løser forretningsproblemer af høj værdi for AWS-kunder ved hjælp af Machine Learning. Hun arbejder med billed-/videoforståelse, vidensgrafanbefalingssystemer, prædiktiv annonceringsbrug.
 Ujjwal Ratan er leder for AI/ML og Data Science i AWS Healthcare and Life Science Business Unit og er også Principal AI/ML Solutions Architect. I årenes løb har Ujjwal været en tankeleder inden for sundheds- og biovidenskabsindustrien og har hjulpet flere Global Fortune 500-organisationer med at nå deres innovationsmål ved at indføre maskinlæring. Hans arbejde, der involverer analyse af medicinsk billeddannelse, ustruktureret klinisk tekst og genomik, har hjulpet AWS med at bygge produkter og tjenester, der giver meget personlig og præcist målrettet diagnostik og terapi. I sin fritid nyder han at lytte til (og spille) musik og tage på uplanlagte roadtrips med sin familie.
Ujjwal Ratan er leder for AI/ML og Data Science i AWS Healthcare and Life Science Business Unit og er også Principal AI/ML Solutions Architect. I årenes løb har Ujjwal været en tankeleder inden for sundheds- og biovidenskabsindustrien og har hjulpet flere Global Fortune 500-organisationer med at nå deres innovationsmål ved at indføre maskinlæring. Hans arbejde, der involverer analyse af medicinsk billeddannelse, ustruktureret klinisk tekst og genomik, har hjulpet AWS med at bygge produkter og tjenester, der giver meget personlig og præcist målrettet diagnostik og terapi. I sin fritid nyder han at lytte til (og spille) musik og tage på uplanlagte roadtrips med sin familie.
 Chaoyang He er medstifter og CTO af FedML, Inc., en startup, der kører for et samfund, der bygger åben og kollaborativ AI fra hvor som helst i enhver skala. Hans forskning fokuserer på distribuerede/fødererede maskinlæringsalgoritmer, systemer og applikationer. Han fik sin ph.d. i datalogi fra University of Southern California, Los Angeles, USA.
Chaoyang He er medstifter og CTO af FedML, Inc., en startup, der kører for et samfund, der bygger åben og kollaborativ AI fra hvor som helst i enhver skala. Hans forskning fokuserer på distribuerede/fødererede maskinlæringsalgoritmer, systemer og applikationer. Han fik sin ph.d. i datalogi fra University of Southern California, Los Angeles, USA.
 Salman Avestimehr er medstifter og administrerende direktør for FedML, Inc., en startup, der kører for et samfund, der bygger åben og kollaborativ AI fra hvor som helst i enhver skala. Salman Avestimehr er en verdenskendt ekspert i fødereret læring med over 20 års F&U-lederskab i både den akademiske verden og industrien. Han er dekanprofessor og åbningsleder for USC-Amazon Center for Trustworthy Machine Learning ved University of Southern California. Han har også været Amazon Scholar i Amazon. Han er en amerikansk præsidentprisvinder for sine dybtgående bidrag inden for informationsteknologi og en Fellow of IEEE.
Salman Avestimehr er medstifter og administrerende direktør for FedML, Inc., en startup, der kører for et samfund, der bygger åben og kollaborativ AI fra hvor som helst i enhver skala. Salman Avestimehr er en verdenskendt ekspert i fødereret læring med over 20 års F&U-lederskab i både den akademiske verden og industrien. Han er dekanprofessor og åbningsleder for USC-Amazon Center for Trustworthy Machine Learning ved University of Southern California. Han har også været Amazon Scholar i Amazon. Han er en amerikansk præsidentprisvinder for sine dybtgående bidrag inden for informationsteknologi og en Fellow of IEEE.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/part-2-federated-learning-on-aws-with-fedml-health-analytics-without-sharing-sensitive-data/
- 000
- 1
- 10
- 100
- 20 år
- 2018
- 2020
- 2021
- 2022
- 28
- 7
- 9
- a
- Om
- over
- Academy
- fremskynde
- Acceptere
- adgang
- af udleverede
- Konto
- ansvarlighed
- Konti
- opnå
- tværs
- Lov
- tilpasse
- adresse
- indrømmede
- vedtaget
- Vedtagelsen
- Vedtagelse
- Reklame
- Efter
- aggregering
- aggregator
- AI
- AI / ML
- algoritmer
- Alle
- tillader
- Amazon
- Amazon EC2
- analyse
- analytics
- analysere
- analysere
- ,
- Angeles
- En anden
- overalt
- applikationer
- anvendt
- tilgang
- passende
- arkitektur
- forbundet
- Automatisering
- til rådighed
- tildeling
- AWS
- Bagende
- baggrund
- baseret
- fordi
- før
- være
- jf. nedenstående
- benchmark
- gavner det dig
- mellem
- Bloker
- Blog
- board
- Brætspil
- Boks
- BP
- bygge
- Bygning
- bygget
- virksomhed
- california
- ringe
- fanger
- hvilken
- tilfælde
- casestudie
- tilfælde
- center
- centraliseret
- Direktør
- udfordringer
- Ændringer
- skiftende
- valg
- Vælg
- valgt
- klasse
- klassificering
- kunde
- kunder
- Klinisk
- kliniske forsøg
- Cloud
- cloud adoption
- Cluster
- Medstifter
- kode
- kohorte
- kollaborativ
- indsamler
- Kolonne
- Kolonner
- Coma
- Kommunikation
- samfund
- samfund bygning
- fuldføre
- omfattende
- Compute
- computer
- Datalogi
- computing
- Konceptet
- begreber
- Konfiguration
- Tilslut
- tilsluttet
- tilslutning
- Connectivity
- betragtes
- Konsol
- fortsæt
- bidrag
- konverteret
- Tilsvarende
- Koste
- skabe
- oprettet
- skaber
- Oprettelse af
- kritisk
- CTO
- skik
- Kunder
- tilpasse
- data
- dataadgang
- datalækage
- datapunkter
- databeskyttelse
- datalogi
- dataforsker
- datadeling
- Database
- decentral
- beslutning
- dyb
- dyb læring
- Standard
- demonstrere
- indsætte
- implementering
- beskrevet
- Design
- destination
- detaljeret
- detaljer
- bestemmelse
- udvikle
- udvikling
- Udvikling
- dialog
- forskellige
- svært
- størrelse
- direkte
- Direktør
- distribueret
- distribueret computing
- distribuerede systemer
- fordeling
- Er ikke
- gør
- domæne
- Domæner
- medicin
- lægemiddeludvikling
- i løbet af
- hver
- tidligere
- økosystem
- effektivitet
- effektiv
- muliggøre
- aktiveret
- muliggør
- ende til ende
- ingeniør
- sikre
- sikrer
- Indtast
- Underholdning
- epoker
- fejl
- etablere
- Ether (ETH)
- begivenheder
- eksempel
- eksisterende
- forventet
- erfaring
- ekspert
- udforske
- udvide
- Øjne
- fairness
- familie
- Funktionalitet
- fyr
- Figur
- File (Felt)
- Filer
- Endelig
- Fornavn
- flow
- Fokus
- fokuserede
- fokuserer
- følger
- efter
- rigdom
- fundet
- Framework
- Gratis
- fra
- funktion
- funktioner
- yderligere
- Endvidere
- fremtiden
- Spil
- Køn
- genomforskning
- gif
- Global
- Go
- Mål
- regeringsførelse
- GPU
- graf
- grafer
- gruppe
- Gruppens
- retningslinjer
- håndtere
- Helse
- sygesikring
- sundhedspleje
- Held
- hjælpe
- hjulpet
- hjælpe
- hjælper
- link.
- stærkt
- hiking
- historie
- Hospital
- sygehuse
- hostede
- HOURS
- Hvordan
- HPC
- HTML
- HTTPS
- ideal
- IEEE
- billede
- Imaging
- ubalance
- gennemføre
- importere
- Forbedre
- forbedring
- in
- tiltrædelsesforelæsning
- Inc.
- omfatter
- inkorporering
- indeks
- industrien
- oplysninger
- Infrastruktur
- Innovation
- indgang
- installere
- instans
- forsikring
- grænseflade
- Internet
- tingenes internet
- tingenes internet
- IT
- deltage
- Nøgle
- viden
- Etiketter
- laboratorium
- Mangel
- storstilet
- lancere
- føre
- leder
- Leadership" (virkelig menneskelig ledelse)
- læring
- Længde
- Leverage
- Udnytter
- løftestang
- Livet
- Life Science
- Life Sciences
- Line (linje)
- Liste
- Børsnoterede
- Lytte
- belastning
- loader
- belastninger
- lokale
- lokalt
- placeret
- Lang
- den
- Los Angeles
- off
- maskine
- machine learning
- lavet
- vedligeholde
- vedligeholdelse
- lave
- maerker
- administrere
- leder
- måde
- kortlægning
- mars
- midler
- målinger
- Medier
- medicinsk
- medicinsk billeddannelse
- Mød
- nævnte
- metode
- metoder
- MIT
- afbøde
- ML
- ML algoritmer
- model
- modeller
- Overvåg
- overvågning
- mere
- Motor
- bevæge sig
- flytning
- flere
- Musik
- navn
- Natur
- Navigation
- Behov
- behov
- behov
- negativ
- netværk
- node
- noder
- nummer
- bedøvet
- ONE
- åbent
- open source
- Produktion
- optimal
- organisationer
- Andet
- uden for
- egen
- ejede
- ejer
- brød
- parametre
- del
- partner
- partnere
- Bestået
- lidenskab
- sti
- patient
- patienter
- peer
- udføre
- ydeevne
- udfører
- Personalisering
- Personlig
- pipeline
- Place
- fly
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- Vær venlig
- Punkt
- punkter
- udgør
- positiv
- Indlæg
- Praktisk
- præcist
- forudsige
- forudsige
- forudsigelse
- præsentere
- præsentation
- præsidentkandidat
- tryk
- forhindre
- tidligere
- Main
- Beskyttelse af personlige oplysninger
- private
- Problem
- problemer
- behandle
- produktion
- Produkter
- Produkter og services
- Professor
- skrider frem
- progression
- forbyde
- projekt
- bevis
- Bevis for koncept
- foreslå
- give
- giver
- leverer
- offentligt
- formål
- pytorch
- F & U
- tilfældig
- SJÆLDEN
- Sats
- forholdet
- RE
- Læsning
- klar
- virkelige verden
- modtaget
- Anbefaling
- optage
- registreres
- optegnelser
- region
- regression
- reguleret
- lovgivningsmæssige
- Fjern
- Repository
- repræsenterer
- anmode
- kræver
- krav
- Krav
- Kræver
- forskning
- dem
- afkast
- afkast
- gennemgå
- vej
- groft
- R
- RÆKKE
- regler
- Kør
- kører
- samme
- Scale
- Videnskab
- VIDENSKABER
- Videnskabsmand
- scripts
- problemfrit
- Anden
- sikkerhed
- Søg
- valgt
- SELV
- senior
- følsom
- Series
- Tjenester
- sæt
- sæt
- indstilling
- setup
- syv
- flere
- Del
- delt
- deling
- vist
- Shows
- underskrive
- Skilte
- lignende
- Tilsvarende
- enkelt
- websted
- Websteder
- So
- løsninger
- Løsninger
- Løser
- Kilde
- Syd
- spændvidder
- specifikke
- delt
- stabil
- standard
- starte
- påbegyndt
- opstart
- state-of-the-art
- Stater
- Status
- forblive
- Steps
- opbevaring
- struktureret
- strukturerede og ustrukturerede data
- Studere
- stil
- undernet
- sådan
- tilstrækkeligt
- support
- Understøtter
- Kortlægge
- systemet
- Systemer
- bord
- TAG
- tager
- mål
- målrettet
- Opgaver
- taksonomi
- Teknologier
- Teknologier
- skabelon
- prøve
- deres
- terapi
- ting
- Tredje
- tænkte
- tre
- Gennem
- hele
- tid
- Tidsserier
- tidskrævende
- til
- værktøj
- værktøjer
- fakkel
- Torchvision
- I alt
- spor
- Trafik
- Tog
- Kurser
- overført
- forsøg
- troværdig
- typer
- typisk
- underliggende
- forståelse
- enestående
- enhed
- Forenet
- Forenede Stater
- enheder
- universitet
- University of Southern California
- Opdatering
- opdateringer
- us
- USA
- brug
- brug tilfælde
- værdi
- Værdier
- række
- forskellige
- Vast
- vertikaler
- via
- video
- Virtual
- synlig
- afgørende
- går igennem
- som
- mens
- WHO
- bred
- vilje
- inden for
- uden
- Arbejde
- virker
- verdenskendte
- X
- år
- Din
- zephyrnet