I dag bruger hundredtusindvis af kunder datasøer til analyser og maskinlæring. Dataingeniører skal dog rense og forberede disse data, før de kan bruges. De underliggende data skal være nøjagtige og nye, for at kunden kan træffe sikre forretningsbeslutninger. Ellers mister dataforbrugerne tilliden til dataene og træffer suboptimale eller forkerte beslutninger. Det er en almindelig opgave for dataingeniører at vurdere, om dataene er nøjagtige og nyere eller ej. I dag findes der forskellige datakvalitetsværktøjer. Almindelige datakvalitetsværktøjer kræver dog normalt manuelle processer for at overvåge datakvaliteten.
AWS Glue Data Quality er en forhåndsvisningsfunktion af AWS Lim der måler og overvåger datakvaliteten vedr Amazon Simple Storage Service (Amazon S3) datasøer og i AWS Glue extract, transform and load (ETL) jobs. Dette er en åben preview-funktion, så den er allerede aktiveret på din konto i tilgængelige regioner. Du kan nemt definere og måle datakvalitetskontrollen i AWS Glue Studio-konsollen uden at skrive koder. Det forenkler din oplevelse af styring af datakvalitet.
Dette indlæg er del 2 af en fire-post-serie for at forklare, hvordan AWS Glue Data Quality fungerer. Tjek det forrige indlæg i denne serie:
I dette indlæg viser vi, hvordan du opretter et AWS Glue-job, der måler og overvåger datakvaliteten af en datapipeline. Vi viser også, hvordan du kan handle baseret på datakvalitetsresultaterne.
Løsningsoversigt
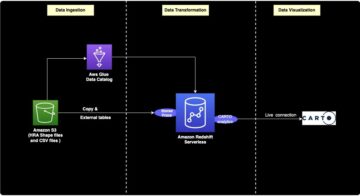
Lad os overveje et eksempel på en brugssituation, hvor en dataingeniør skal bygge en datapipeline for at indtage data fra en rå zone til en kureret zone i en datasø. Som dataingeniør er et af dine vigtigste ansvarsområder – sammen med at udtrække, transformere og indlæse data – at validere datakvaliteten. Identifikation af datakvalitetsproblemer på forhånd hjælper dig med at forhindre at placere dårlige data i den kurerede zone og undgå besværlige datakorruptionshændelser.
I dette indlæg lærer du, hvordan du nemt opsætter indbygget , skik datavalideringstjek i dit AWS Glue-job for at forhindre dårlige data i at ødelægge downstream-data af høj kvalitet.
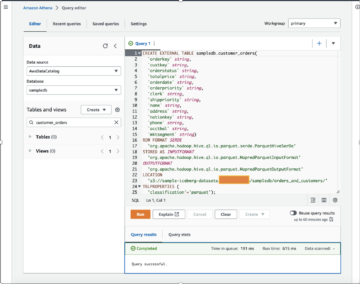
Datasættet brugt til dette indlæg er syntetisk genereret; følgende skærmbillede viser et eksempel på dataene.

Konfigurer ressourcer med AWS CloudFormation
Dette indlæg indeholder en AWS CloudFormation skabelon til hurtig opsætning. Du kan gennemgå og tilpasse den, så den passer til dine behov.
CloudFormation-skabelonen genererer følgende ressourcer:
- En Amazon Simple Storage Service (Amazon S3) spand (
gluedataqualitystudio-*). - Følgende præfikser og objekter i S3-bøtten:
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- AWS identitets- og adgangsstyring (IAM) brugere, roller og politikker. IAM-rollen (
GlueDataQualityStudio-*) har tilladelse til at læse og skrive fra S3-bøtten. - AWS Lambda funktioner og IAM-politikker, der kræves af disse funktioner for at oprette og slette denne stak.
For at oprette dine ressourcer skal du udføre følgende trin:
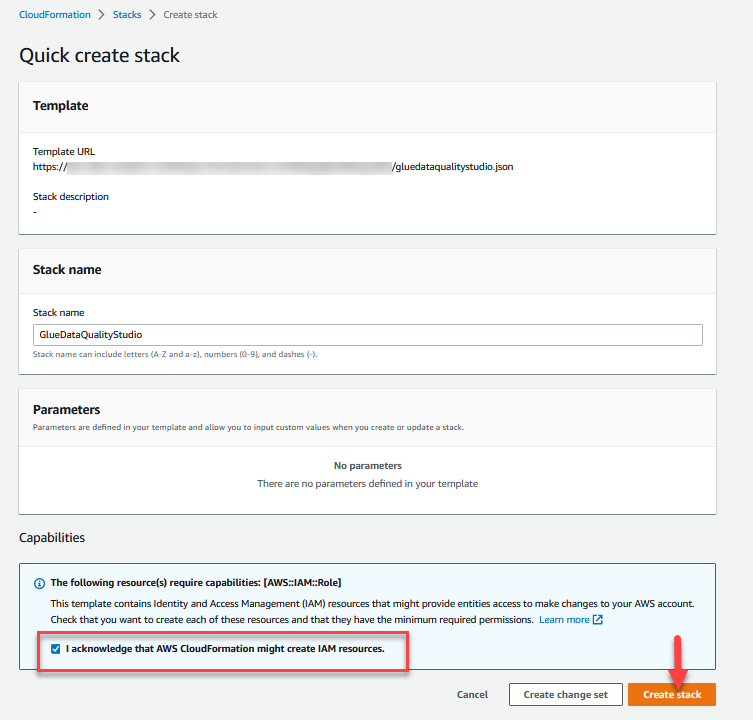
- Log ind på AWS CloudFormation konsol i
us-east-1Område. - Vælg Start Stack:

- Type Jeg anerkender, at AWS CloudFormation kan skabe IAM-ressourcer.
- Vælg Opret stak og vent på, at stakoprettelsestrinnet er fuldført.
Implementer løsningen
Udfør følgende trin for at begynde at konfigurere din løsning:
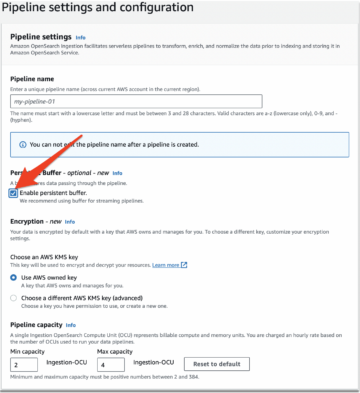
- På AWS Glue Studio konsol, vælg Karriere i navigationsruden.
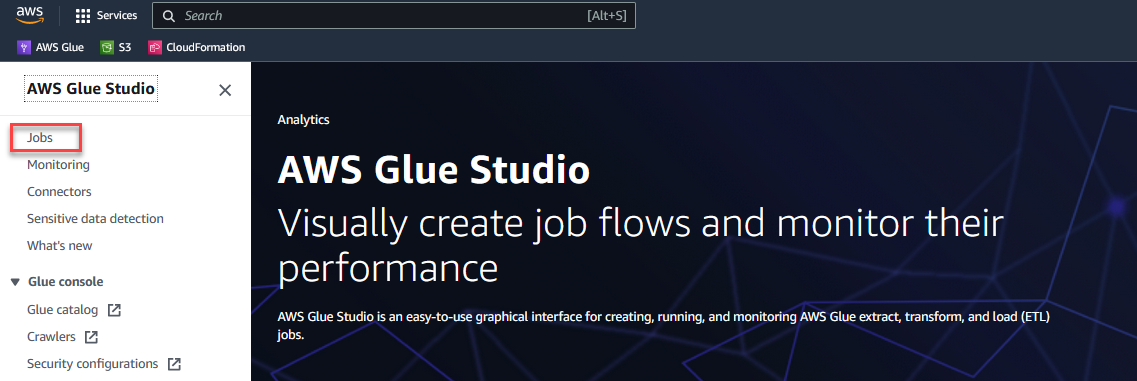
- Type Visuel med et tomt lærred Og vælg Opret.
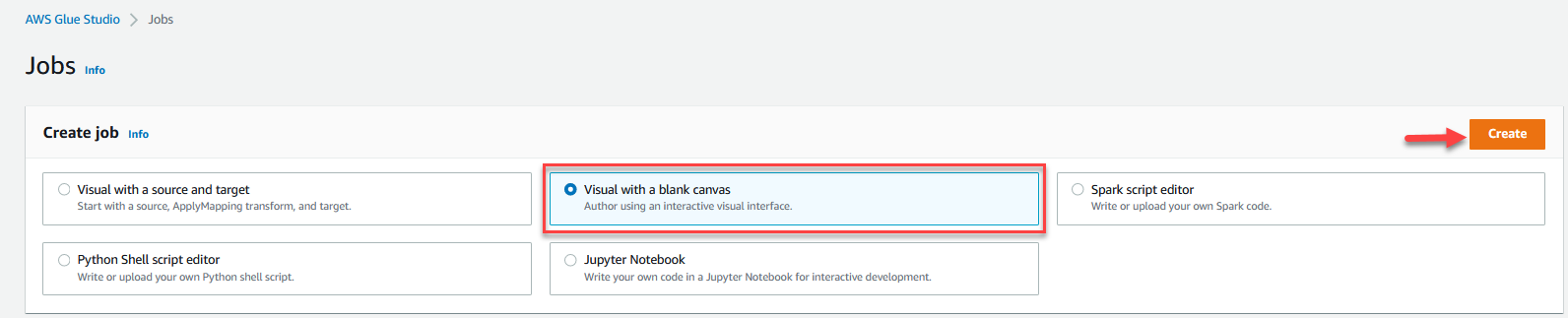
- Vælg den Job Detaljer fanen for at konfigurere jobbet.
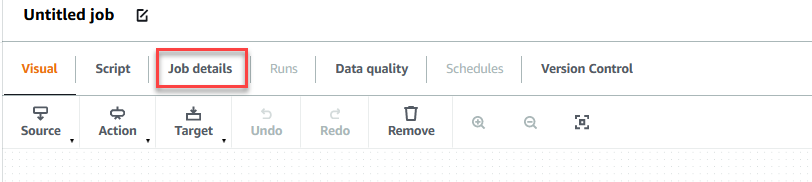
- Til Navn, gå ind
GlueDataQualityStudio. - Til IAM rolle, vælg den rolle, der starter med
GlueDataQualityStudio-*. - Til Lim version, vælg Lim 3.0.
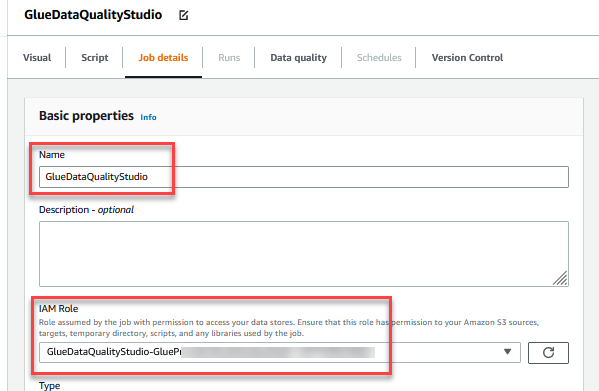
- Til Jobbogmærke, vælg Deaktiver. Dette giver dig mulighed for at køre dette job flere gange med det samme inputdatasæt.
- Til Antal genforsøg, gå ind
0.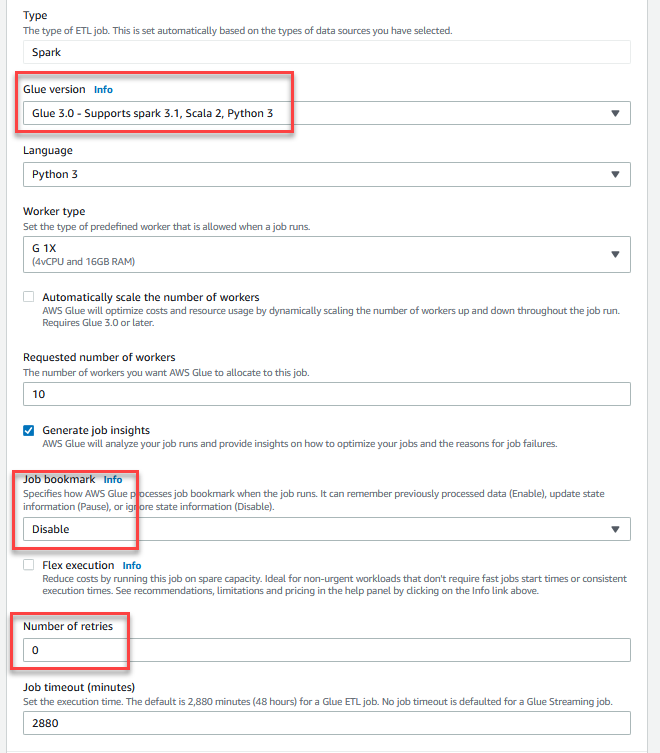
- I Avancerede egenskaber sektionen, skal du give S3-bøtten oprettet af CloudFormation-skabelonen (startende med
gluedataqualitystudio-*).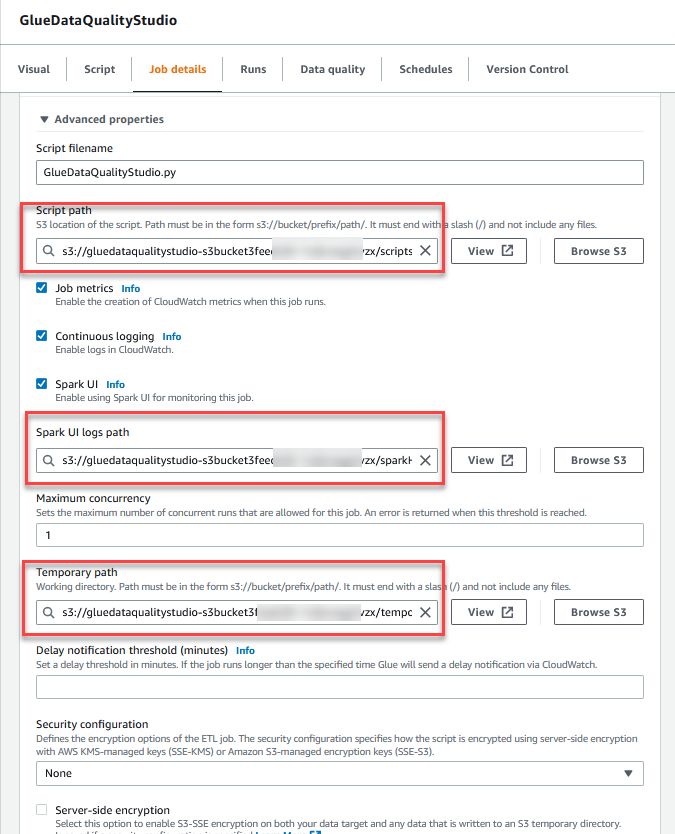
- Vælg Gem.
- Når jobbet er gemt, skal du vælge Visuel fanen og på Kilde menu, vælg Amazon S3.
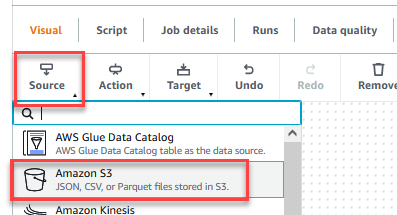
- På Datakildeegenskaber – S3 fane, for S3 kildetype, Vælg S3 placering.
- Vælg Gennemse S3 og naviger til præfiks
/datalake/raw/customer/i S3-spanden startende medgluedataqualitystudio-*. - Vælg Udled skema.
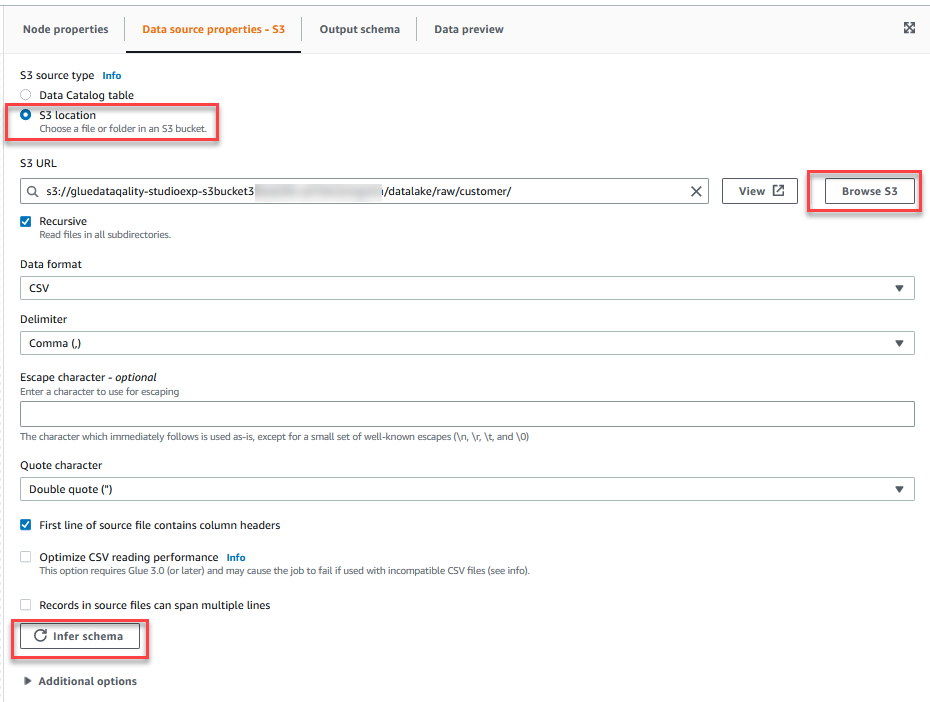
- På Handling menu, vælg Evaluer datakvalitet.
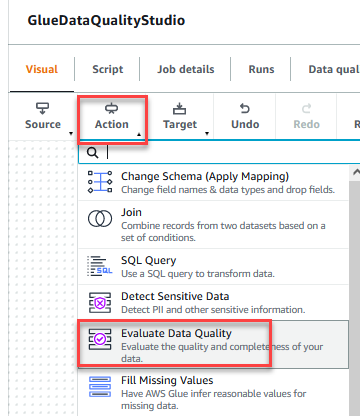
- Vælg den Evaluer datakvalitet node.
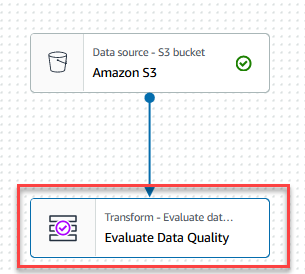
På Transform fanen, kan du nu begynde at opbygge regler for datakvalitet. Den første regel, du opretter, er at kontrollere, omCustomer_IDer unik og ikke null ved hjælp afisPrimaryKeyHerske. - På Regeltyper fanebladet af DQDL-regelbygger, søge efter
isprimarykeyog vælg plustegnet.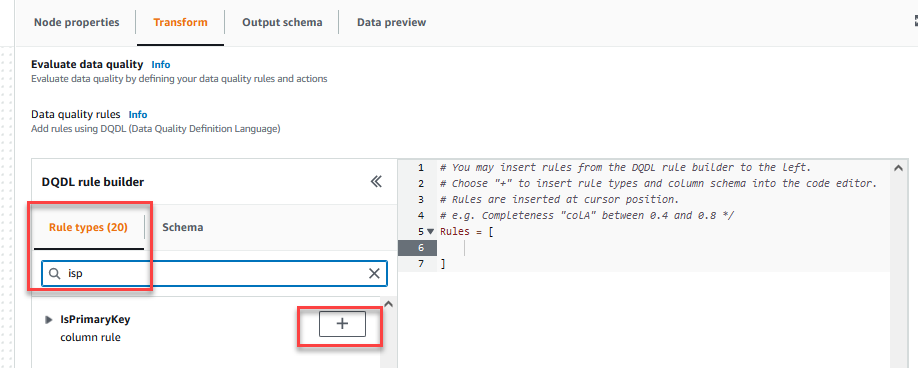
- På Planlæg fanebladet af DQDL-regelbygger, skal du vælge plustegnet ved siden af
Customer_ID. - Slet i regeleditoren
id.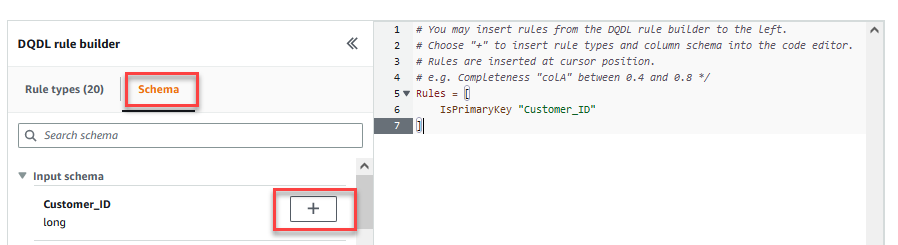
Den næste regel, vi tilføjer kontrollerer, atFirst_Namekolonneværdi er til stede for alle rækkerne. - Du kan også indtaste datakvalitetsreglerne direkte i regeleditoren. Tilføj et komma (,) og indtast
IsComplete "First_Name",efter den første regel.
Dernæst tilføjer du en tilpasset regel for at validere, at der ikke eksisterer nogen række udenTelephoneorEmail. - Indtast følgende tilpassede regel i regeleditoren:

Funktionen Evaluer datakvalitet giver handlinger til at styre resultatet af et job baseret på jobkvalitetsresultaterne. - For dette indlæg skal du vælge Mislykket job, når datakvaliteten svigter Og vælg Mislykket job uden at indlæse mål data handlinger. I den Indstilling for output af datakvalitet sektion, skal du vælge Gennemse S3 og naviger til præfiks
dqresultsi S3-spanden startende medgluedataqualitystudio-*.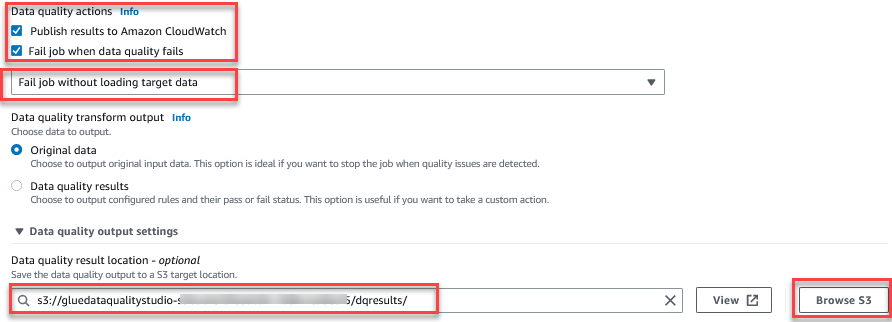
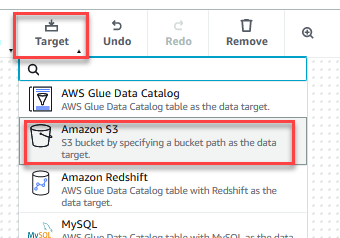
- På mål menu, vælg Amazon S3.
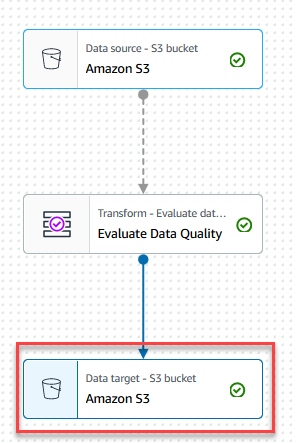
- Vælg den Datamål – S3-spand node.
- På Datamålegenskaber – S3 fane, for dannet, vælg parket, Og Komprimeringstype, vælg Snappy.
- Til S3 Målplacering, vælg Gennemse S3 og naviger til præfikset
/datalake/curated/customer/i S3-spanden startende medgluedataqualitystudio-*.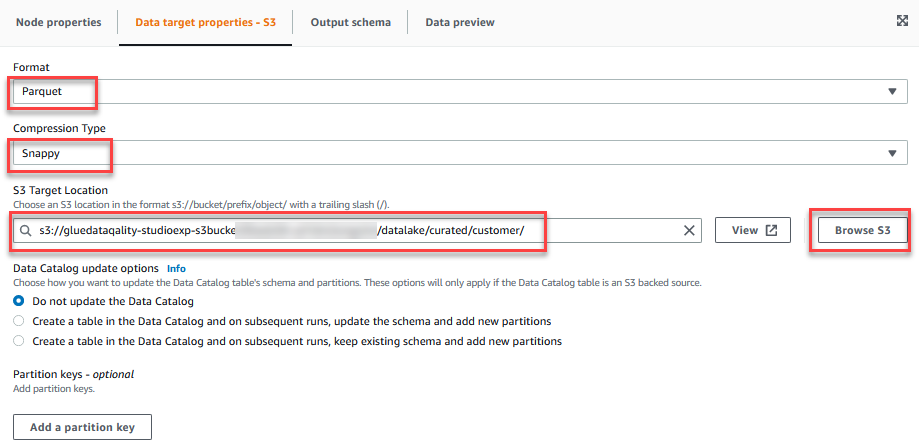
- Vælg Gem, Og vælg derefter Kør.
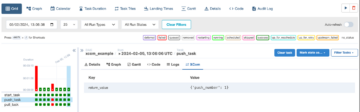
 Du kan se jobkørselsdetaljerne på fanen Kørsler. I vores eksempel mislykkes jobbet med fejlmeddelelsen "AssertionError: Jobbet mislykkedes på grund af fejlagtige DQ-regler for node: ."
Du kan se jobkørselsdetaljerne på fanen Kørsler. I vores eksempel mislykkes jobbet med fejlmeddelelsen "AssertionError: Jobbet mislykkedes på grund af fejlagtige DQ-regler for node: ."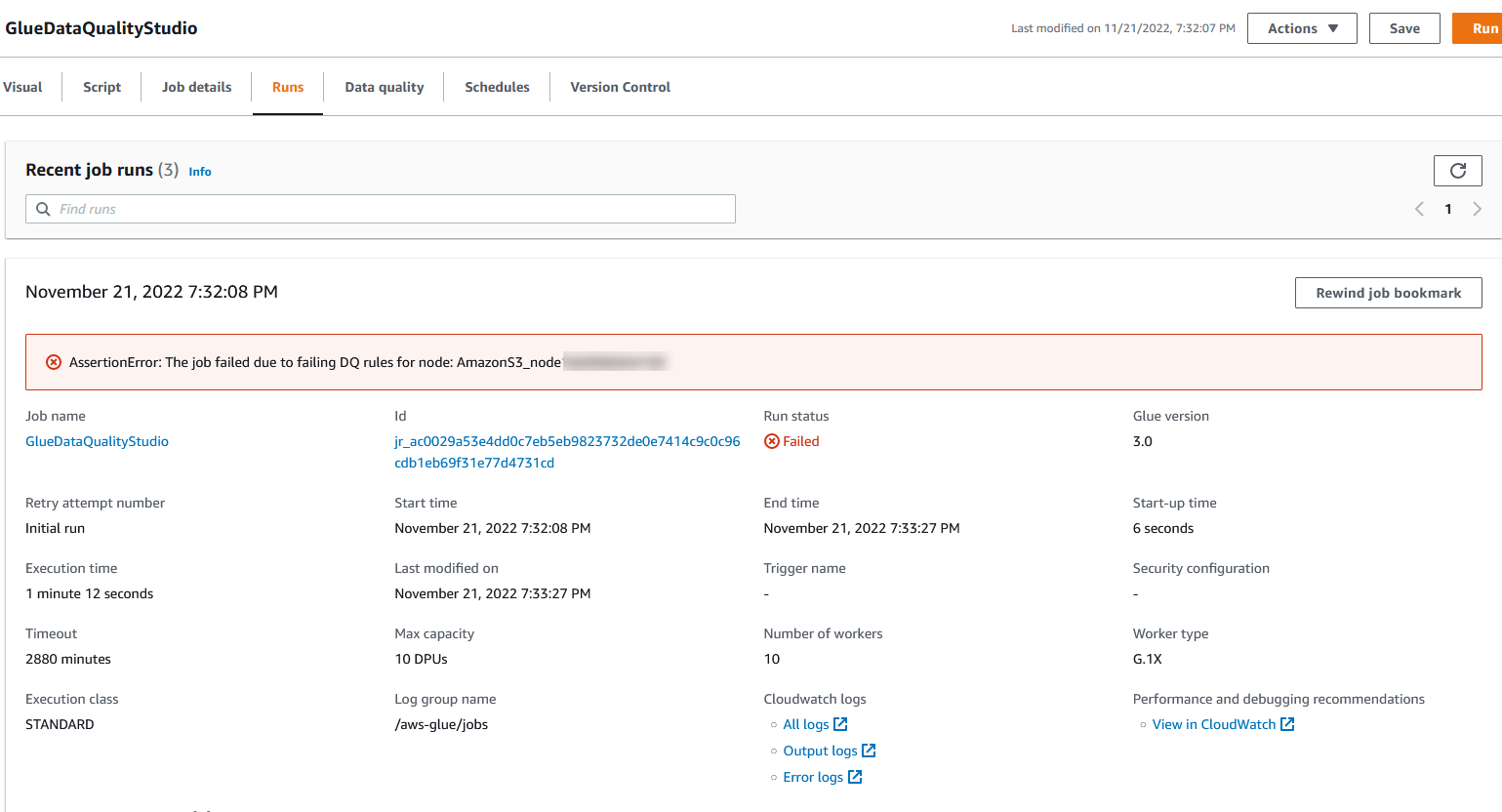 Du kan gennemgå datakvalitetsresultatet på fanen Datakvalitet. I vores eksempel mislykkedes den tilpassede datakvalitetsvalidering, fordi en af rækkerne i datasættet havde nr
Du kan gennemgå datakvalitetsresultatet på fanen Datakvalitet. I vores eksempel mislykkedes den tilpassede datakvalitetsvalidering, fordi en af rækkerne i datasættet havde nr TelephoneorEmailværdi. Evaluer datakvalitetsresultater skrives også til S3-bøtten i JSON-format baseret på datakvalitetsresultatplaceringsparameteren for noden.
Evaluer datakvalitetsresultater skrives også til S3-bøtten i JSON-format baseret på datakvalitetsresultatplaceringsparameteren for noden. - Naviger til
dqresultspræfiks under S3 skovlen startergluedataqualitystudio-*. Du vil se, at datakvalitetsresultatet er opdelt efter dato.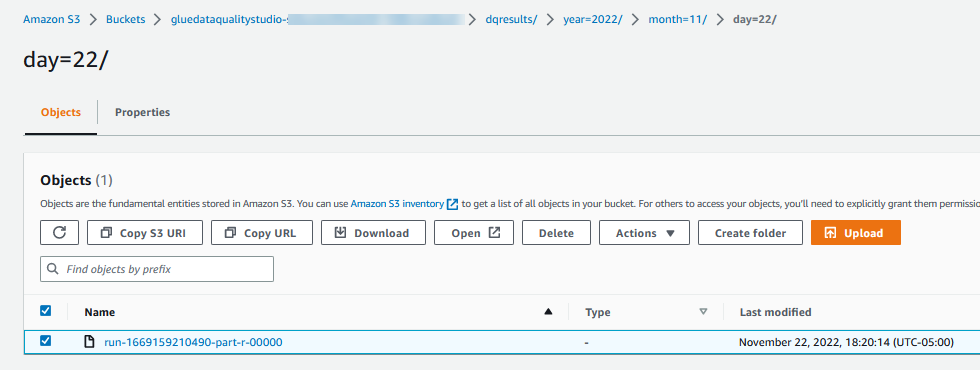
Følgende er output fra JSON-filen. Du kan bruge dette filoutput til at bygge brugerdefinerede dashboards til visualisering af datakvalitet.

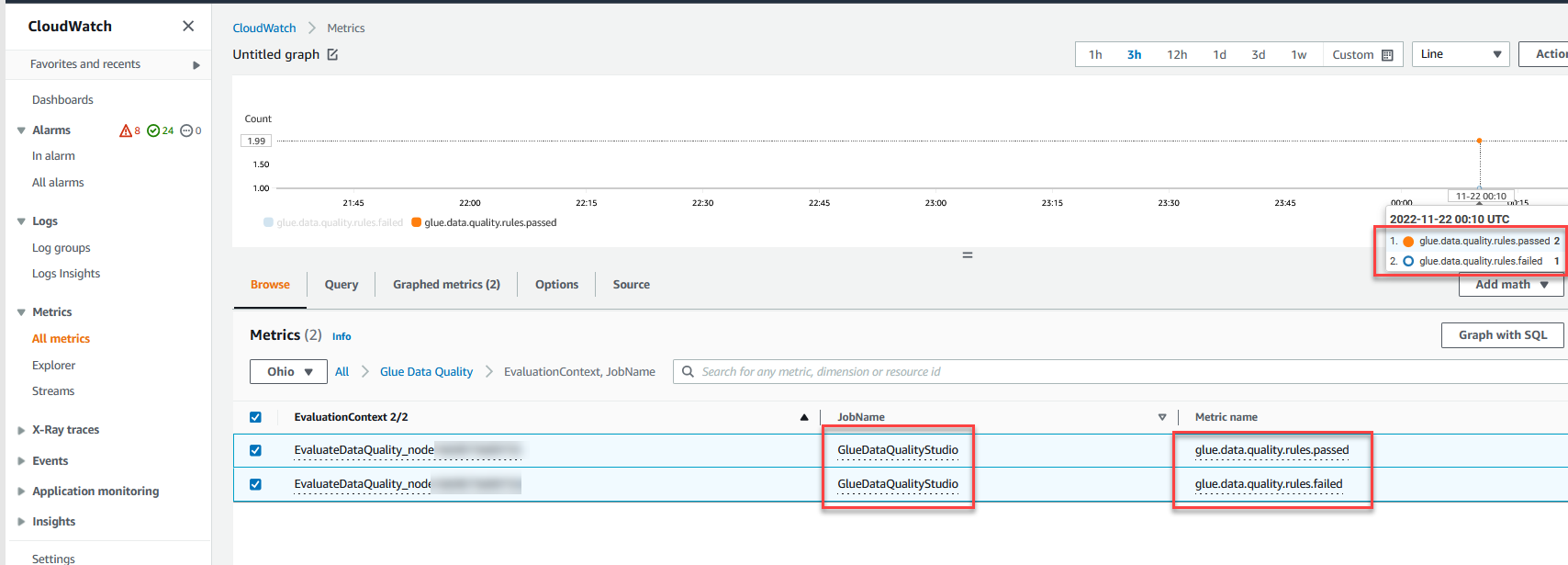
Du kan også overvåge Evaluer datakvalitet node igennem amazoncloudwatch målinger og indstil alarmer til at sende meddelelser om datakvalitetsresultater. For at lære mere om, hvordan du opsætter CloudWatch-alarmer, se Brug af Amazon CloudWatch-alarmer.
Ryd op
For at undgå fremtidige gebyrer og for at rydde op i ubrugte roller og politikker skal du slette de ressourcer, du har oprettet:
- Slette
GlueDataQualityStudiojob, du har oprettet som en del af dette indlæg. - På AWS CloudFormation-konsollen skal du slette
GlueDataQualityStudiostak.
Konklusion
AWS Glue Data Quality tilbyder en nem måde at måle og overvåge datakvaliteten af din ETL-pipeline. I dette indlæg lærte du, hvordan du tager nødvendige handlinger baseret på datakvalitetsresultaterne, hvilket hjælper dig med at opretholde høje datastandarder og træffe sikre forretningsbeslutninger.
For at lære mere om AWS Glue Data Quality, tjek dokumentationen:
Om forfatterne
 Deenbandhu Prasad er Senior Analytics Specialist hos AWS, med speciale i big data-tjenester. Han brænder for at hjælpe kunder med at bygge moderne dataarkitektur på AWS Cloud. Han har hjulpet kunder i alle størrelser med at implementere datastyring, data warehouse og data lake løsninger.
Deenbandhu Prasad er Senior Analytics Specialist hos AWS, med speciale i big data-tjenester. Han brænder for at hjælpe kunder med at bygge moderne dataarkitektur på AWS Cloud. Han har hjulpet kunder i alle størrelser med at implementere datastyring, data warehouse og data lake løsninger.
 Yannis Mentekidis er Senior Software Development Engineer på AWS Glue-teamet.
Yannis Mentekidis er Senior Software Development Engineer på AWS Glue-teamet.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/getting-started-with-aws-glue-data-quality-for-etl-pipelines/
- 1
- 100
- 7
- a
- Om
- adgang
- Konto
- præcis
- anerkende
- Handling
- aktioner
- Efter
- Alle
- tillader
- allerede
- Amazon
- analytics
- ,
- arkitektur
- AWS
- AWS CloudFormation
- AWS Lim
- Bad
- dårlige data
- baseret
- fordi
- før
- Big
- Big data
- bygge
- Bygning
- virksomhed
- tilfælde
- afgifter
- kontrollere
- Kontrol
- Vælg
- Cloud
- Kolonne
- Fælles
- fuldføre
- sikker
- Overvej
- Konsol
- Forbrugere
- Korruption
- skabe
- oprettet
- skabelse
- kurateret
- skik
- kunde
- Kunder
- tilpasse
- data
- Data Lake
- datastyring
- Dato
- afgørelser
- detaljer
- Udvikling
- direkte
- dokumentation
- nemt
- editor
- ingeniør
- Ingeniører
- Indtast
- fejl
- Ether (ETH)
- evaluere
- eksempel
- eksisterer
- erfaring
- Forklar
- ekstrakt
- mislykkedes
- mislykkes
- Feature
- File (Felt)
- Fornavn
- efter
- format
- fra
- funktioner
- fremtiden
- genereret
- genererer
- få
- hjulpet
- hjælpe
- hjælper
- Høj
- høj kvalitet
- Hvordan
- How To
- Men
- HTML
- HTTPS
- Hundreder
- identificere
- Identity
- gennemføre
- in
- omfatter
- indgang
- spørgsmål
- IT
- Job
- Karriere
- json
- Nøgle
- sø
- LÆR
- lærte
- læring
- belastning
- lastning
- placering
- taber
- maskine
- machine learning
- vedligeholde
- lave
- administrere
- ledelse
- styring
- manuel
- måle
- foranstaltninger
- Menu
- besked
- Metrics
- måske
- Moderne
- Overvåg
- skærme
- mere
- flere
- Naviger
- Navigation
- nødvendig
- behov
- næste
- node
- meddelelser
- objekter
- Tilbud
- ONE
- åbent
- Ellers
- brød
- parameter
- del
- lidenskabelige
- tilladelse
- pipeline
- anbringelse
- plato
- Platon Data Intelligence
- PlatoData
- plus
- politikker
- Indlæg
- Forbered
- præsentere
- forhindre
- Eksempel
- tidligere
- primære
- Processer
- egenskaber
- give
- giver
- kvalitet
- Hurtig
- Raw
- Læs
- nylige
- region
- kræver
- påkrævet
- Ressourcer
- resultere
- Resultater
- gennemgå
- roller
- roller
- RÆKKE
- Herske
- regler
- Kør
- samme
- Søg
- Sektion
- Series
- tjeneste
- Tjenester
- sæt
- indstilling
- setup
- Vis
- Shows
- underskrive
- Simpelt
- størrelser
- So
- Software
- softwareudvikling
- løsninger
- Løsninger
- Kilde
- specialist
- speciale
- stable
- standarder
- starte
- påbegyndt
- Starter
- Trin
- Steps
- opbevaring
- Studio
- Dragt
- syntetisk
- Tag
- mål
- Opgaver
- hold
- skabelon
- tusinder
- Gennem
- gange
- til
- i dag
- værktøjer
- Transform
- omdanne
- Stol
- under
- underliggende
- enestående
- ubrugt
- brug
- brug tilfælde
- brugere
- sædvanligvis
- VALIDATE
- validering
- værdi
- forskellige
- Specifikation
- visualisering
- vente
- hvorvidt
- som
- vilje
- uden
- virker
- skriver
- skrivning
- skriftlig
- Din
- zephyrnet