Dette indlæg giver vejledning i, hvordan man bygger skalerbare analytiske løsninger til brugscases i spilindustrien Amazon Redshift Serverløs. Det dækker, hvordan man bruger en begrebsmæssig, logisk arkitektur til nogle af de mest populære spilindustriens anvendelsessager som begivenhedsanalyse, købsanbefalinger i spillet, måling af spillertilfredshed, telemetridataanalyse og mere. Dette indlæg diskuterer også kunsten af det mulige med nyere innovationer i AWS-tjenester omkring streaming, machine learning (ML), datadeling og serverløse muligheder.
Vores spilkunder fortæller os, at deres vigtigste forretningsmål omfatter følgende:
- Øget omsætning fra køb i appen
- Høj gennemsnitlig omsætning pr. bruger og livstidsværdi
- Forbedret klæbrighed med bedre spiloplevelse
- Forbedret begivenhedsproduktivitet og høj ROI
Vores spilkunder fortæller os også, at mens de bygger analyseløsninger, ønsker de følgende:
- Lav- eller kodefri model – Out-of-the-box løsninger foretrækkes frem for at bygge skræddersyede løsninger.
- Afkoblet og skalerbar – Serverløse, automatisk skalerede og fuldt administrerede tjenester foretrækkes frem for manuelt administrerede tjenester. Hver tjeneste skal være let udskiftelig, forbedret med ringe eller ingen afhængighed. Løsningerne skal være fleksible, så de kan skaleres op og ned.
- Overførsel til flere kanaler – Løsninger bør være kompatible med de fleste endpoint-kanaler som pc, mobil og spilplatforme.
- Fleksibel og let at bruge – Løsningerne skal give mindre restriktive, let tilgængelige og klar til brug data. De skal også give optimal ydeevne med lav eller ingen tuning.
Analysereferencearkitektur for spilorganisationer
I dette afsnit diskuterer vi, hvordan spilorganisationer kan bruge en datahub-arkitektur til at imødekomme en virksomheds analytiske behov, som kræver de samme data på flere niveauer af granularitet og forskellige formater og er standardiseret til hurtigere forbrug. EN datahub er et center for dataudveksling, der udgør et knudepunkt for datalagre og understøttes af datateknik, datastyring, sikkerhed og overvågningstjenester.
En datahub indeholder data på flere niveauer af granularitet og er ofte ikke integreret. Det adskiller sig fra en datasø ved at tilbyde data, der er prævalideret og standardiseret, hvilket giver mulighed for enklere forbrug for brugerne. Datahubs og datasøer kan eksistere side om side i en organisation og supplerer hinanden. Datahubs er mere fokuseret på at gøre det muligt for virksomheder at forbruge standardiserede data hurtigt og nemt. Datasøer er mere fokuseret på at opbevare og vedligeholde alle data i en organisation ét sted. Og i modsætning til datavarehuse, som primært er analytiske lagre, er en datahub en kombination af alle typer repositories – analytiske, transaktionsmæssige, operationelle, reference- og data-I/O-tjenester sammen med styringsprocesser. Et datavarehus er en af komponenterne i en datahub.
Følgende diagram er en konceptuel analysedatahub-referencearkitektur. Denne arkitektur ligner en hub-and-spoke tilgang. Datalagre repræsenterer hub'en. Eksterne processer er egerne, der fører data til og fra navet. Denne referencearkitektur kombinerer delvist en datahub og datasø for at muliggøre omfattende analysetjenester.
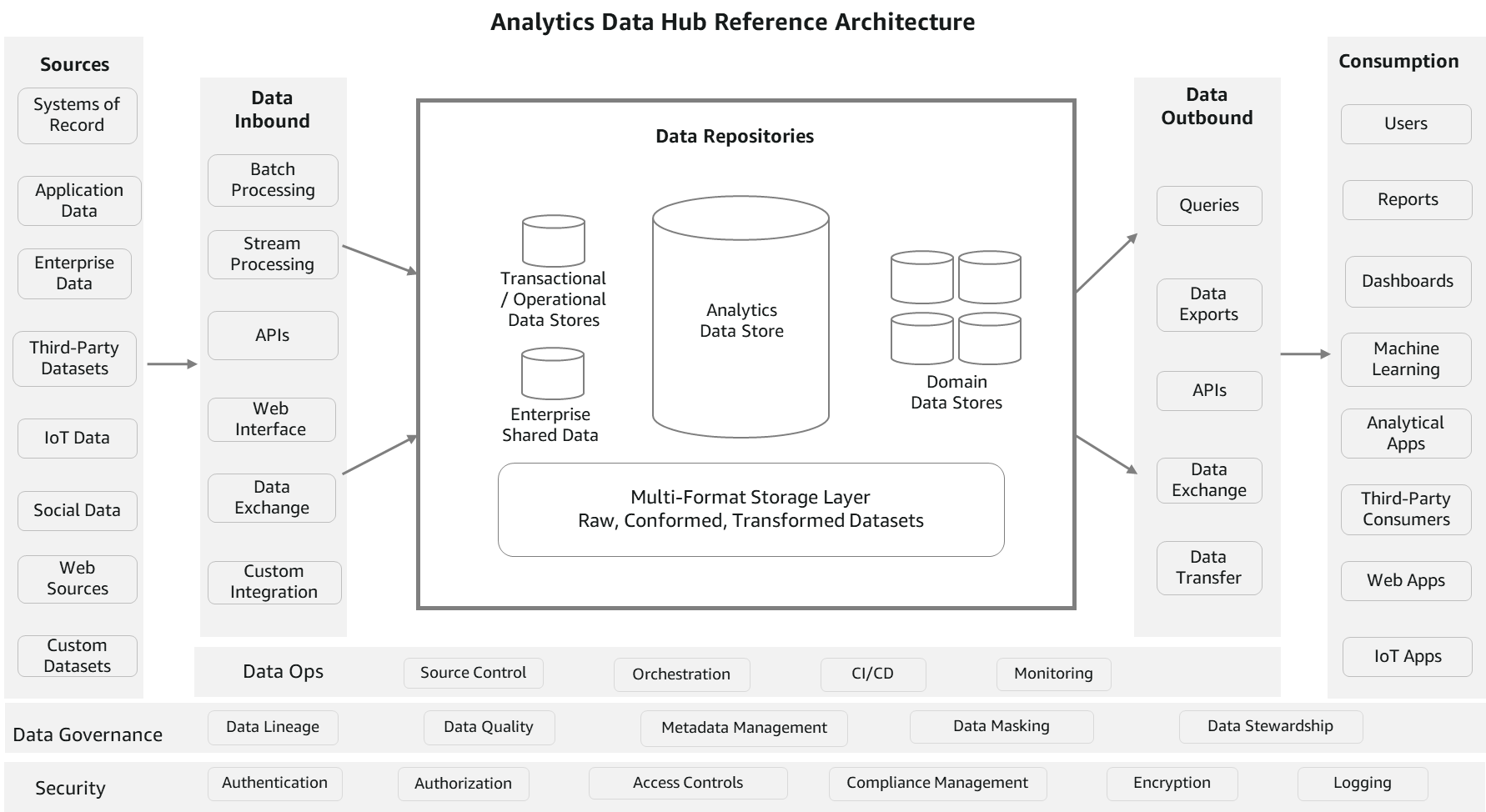
Lad os se mere detaljeret på komponenterne i arkitekturen.
Kilder
Data kan indlæses fra flere kilder, såsom registreringssystemer, data genereret fra applikationer, driftsdatalagre, referencedata og metadata for hele virksomheden, data fra leverandører og partnere, maskingenererede data, sociale kilder og webkilder. Kildedataene er normalt i enten strukturerede eller semi-strukturerede formater, som er henholdsvis højt og løst formateret.
Data indgående
Dette afsnit består af komponenter til at behandle og indlæse data fra flere kilder til datalagre. Det kan være i batch-tilstand, kontinuerlig, pub/sub eller en hvilken som helst anden
tilpasset integration. ETL-teknologier (ekstrahere, transformere og indlæse), streamingtjenester, API'er og dataudvekslingsgrænseflader er kernekomponenterne i denne søjle. I modsætning til indtagelsesprocesser kan data transformeres i henhold til forretningsregler før indlæsning. Du kan anvende tekniske eller forretningsmæssige datakvalitetsregler og også indlæse rådata. Grundlæggende giver det fleksibiliteten til at få dataene ind i depoter i dens mest brugbare form.
Dataarepoter
Denne sektion består af en gruppe af datalagre, som omfatter datavarehuse, transaktions- eller operationelle datalagre, referencedatalagre, domænedatalagre med specialbyggede forretningsvisninger og virksomhedsdatasæt (fillagring). Fillagringskomponenten er normalt en fælles komponent mellem en datahub og en datasø for at undgå dataduplikering og give en helhed. Data kan også deles mellem alle disse lagre uden fysisk at flytte med funktioner, såsom datadeling og fødererede forespørgsler. Datakopiering og duplikering er dog tilladt under hensyntagen til forskellige forbrugsbehov med hensyn til formater og latens.
Data udgående
Data forbruges ofte ved hjælp af strukturerede forespørgsler til analytiske behov. Der er også adgang til datasæt til ML, dataeksport og publiceringsbehov. Denne sektion består af komponenter til at forespørge data, eksport, udveksling og API'er. Med hensyn til implementering kan de samme teknologier bruges til både indgående og udgående, men funktionerne er forskellige. Det er dog ikke obligatorisk at bruge de samme teknologier. Disse processer er ikke transformationstunge, fordi dataene allerede er standardiserede og næsten klar til at blive brugt. Fokus er på let forbrug og integration med forbrugende tjenester.
Forbrug
Denne søjle består af forskellige forbrugskanaler til virksomhedens analytiske behov. Det inkluderer business intelligence (BI)-brugere, konserverede og interaktive rapporter, dashboards, datavidenskabelige arbejdsbelastninger, Internet of Things (IoT), webapps og tredjepartsdataforbrugere. Populære forbrugsenheder i mange organisationer er forespørgsler, rapporter og datavidenskabelige arbejdsbelastninger. Fordi der er flere datalagre, der vedligeholder data i forskellig granularitet og formater for at servicere forbrugernes behov, er disse forbrugskomponenter afhængige af datakataloger for at finde den rigtige kilde.
Datastyring
Datastyring er nøglen til succes for en datahub-referencearkitektur. Det udgør komponenter som metadatastyring, datakvalitet, afstamning, maskering og forvaltning, som er nødvendige for organiseret vedligeholdelse af datahubben. Metadatastyring hjælper med at organisere det tekniske og forretningsmæssige metadatakatalog, og forbrugere kan referere til dette katalog for at vide, hvilke data der er tilgængelige i hvilket lager og med hvilken granularitet, format, ejere, opdateringsfrekvens og så videre. Sammen med metadatastyring er datakvalitet vigtig for at øge tilliden for forbrugerne. Dette omfatter datarensning, validering, overensstemmelse og datakontrol.
Sikkerhed og overvågning
Brugere og applikationsadgang bør kontrolleres på flere niveauer. Det starter med godkendelse, derefter godkendelse af, hvem og hvad der skal tilgås, politikstyring, kryptering og anvendelse af regler for dataoverholdelse. Det inkluderer også overvågningskomponenter til at logge aktiviteten til revision og analyse.
Analyse datahub løsningsarkitektur på AWS
Følgende referencearkitektur giver en AWS-stak til løsningskomponenterne.
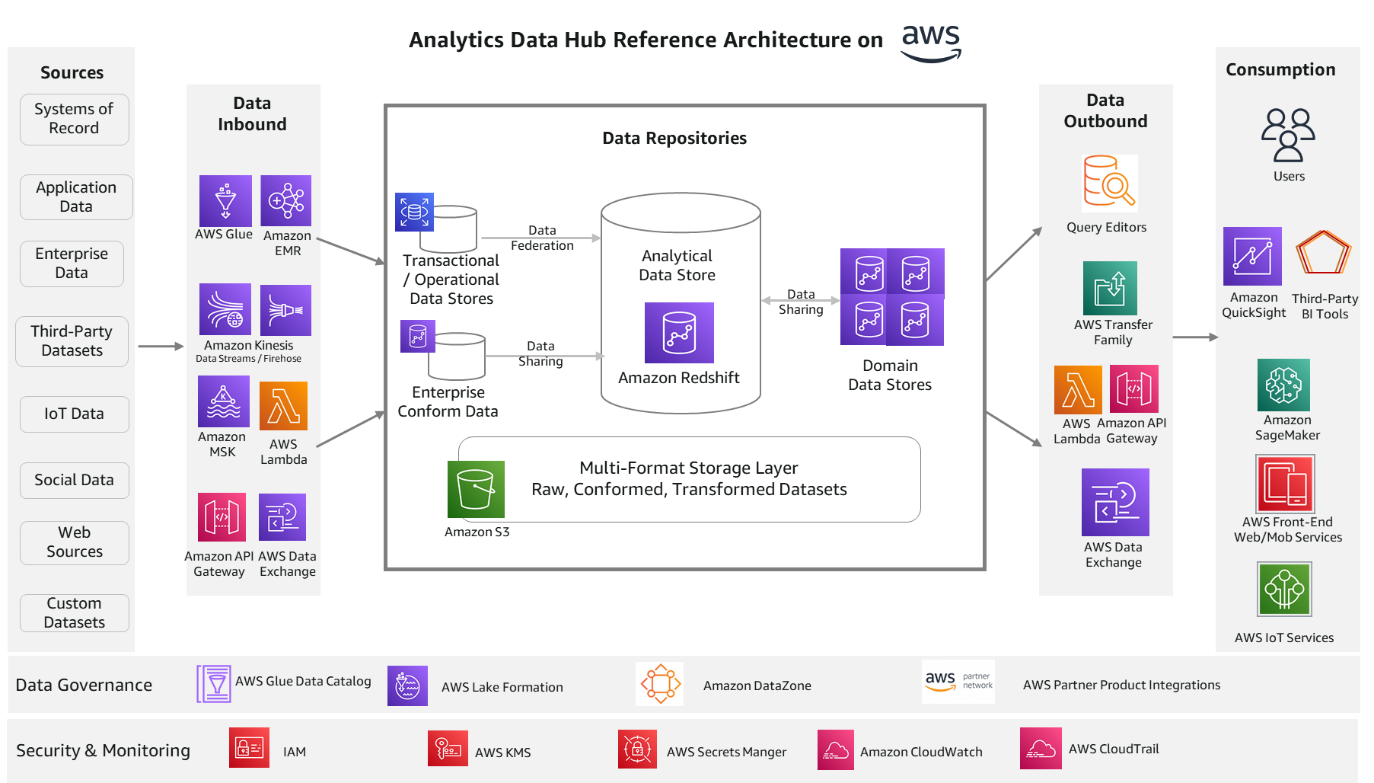
Lad os se på hver komponent igen og de relevante AWS-tjenester.
Dataindgående tjenester
AWS Lim , Amazon EMR tjenester er ideelle til batchbehandling. De skaleres automatisk og er i stand til at behandle de fleste industristandarddataformater. Amazon Kinesis datastrømme, Amazon Kinesis Data Firehoseog Amazon administrerede streaming til Apache Kafka (Amazon MSK) giver dig mulighed for at bygge streamingprocesapplikationer. Disse streamingtjenester integreres godt med Amazon Redshift streaming funktion. Dette hjælper dig med at behandle kilder i realtid, IoT-data og data fra onlinekanaler. Du kan også indtage data med tredjepartsværktøjer som Informatica, dbt og Matallion.
Du kan bygge RESTful API'er og WebSocket API'er ved hjælp af Amazon API Gateway , AWS Lambda, som vil muliggøre tovejskommunikation i realtid med webkilder, sociale kilder og IoT-kilder. AWS dataudveksling hjælper med at abonnere på tredjepartsdata i AWS Marketplace. Dataabonnement og adgang administreres fuldt ud med denne tjeneste. Se den respektive servicedokumentation for yderligere detaljer.
Datalagertjenester
Amazon rødforskydning er den anbefalede datalagringstjeneste til OLAP (Online Analytical Processing) arbejdsbelastninger såsom cloud data warehouses, data marts og andre analytiske datalagre. Denne service er kernen i denne referencearkitektur på AWS og kan imødekomme de fleste analytiske behov ud af boksen. Du kan bruge simpel SQL til at analysere strukturerede og semistrukturerede data på tværs af datavarehuse, datamarts, operationelle databaser og datasøer for at levere den bedste prisydelse i enhver skala. Det Amazon Redshift datadeling funktion giver øjeblikkelig, detaljeret og højtydende adgang uden datakopier og databevægelse på tværs af flere Amazon Redshift-datavarehuse i samme eller forskellige AWS-konti og på tværs af regioner.
For at lette brugen tilbyder Amazon Redshift en serverløs mulighed. Amazon Redshift Serverløs klargør og skalerer automatisk datavarehuskapaciteten for at levere hurtig ydeevne til selv de mest krævende og uforudsigelige arbejdsbelastninger, og du betaler kun for det, du bruger. Du skal bare indlæse dine data, og begynde at forespørge med det samme i Amazon Redshift Query Editor eller i dit foretrukne BI-værktøj, og fortsæt med at nyde den bedste prisydelse og velkendte SQL-funktioner i et brugervenligt, nul administrationsmiljø.
Amazon Relationel Database Service (Amazon RDS) er en fuldt administreret tjeneste til opbygning af transaktions- og operationelle datalagre. Du kan vælge mellem mange populære motorer såsom MySQL, PostgreSQL, MariaDB, Oracle og SQL Server. Med Amazon Redshift fødereret forespørgsel funktion, kan du forespørge transaktions- og driftsdata på plads uden at flytte dataene. Den fødererede forespørgselsfunktion understøtter i øjeblikket Amazon RDS til PostgreSQL, Amazon Aurora PostgreSQL-kompatibel udgave, Amazon RDS til MySQLog Amazon Aurora MySQL-kompatibel udgave.
Amazon Simple Storage Service (Amazon S3) er den anbefalede service til lagringslag i flere formater i arkitekturen. Det tilbyder brancheførende skalerbarhed, datatilgængelighed, sikkerhed og ydeevne. Organisationer gemmer typisk data i Amazon S3 ved hjælp af åbne filformater. Åbne filformater muliggør analyse af de samme Amazon S3-data ved hjælp af flere behandlings- og forbrugslagskomponenter. Data i Amazon S3 kan nemt forespørges på plads ved hjælp af SQL med Amazon Redshift Spectrum. Det hjælper dig med at forespørge og hente strukturerede og semi-strukturerede data fra filer i Amazon S3 uden at skulle indlæse dataene. Flere Amazon Redshift-datavarehuse kan samtidigt forespørge på de samme datasæt i Amazon S3 uden behov for at lave kopier af dataene for hvert datavarehus.
Dataudgående tjenester
Amazon Redshift kommer med det webbaserede analysearbejdsbord Forespørgselseditor V2.0, som hjælper dig med at køre forespørgsler, udforske data, oprette SQL-notesbøger og samarbejde om data med dine teams i SQL via en fælles grænseflade. AWS Transfer Familie hjælper med sikker overførsel af filer ved hjælp af SFTP-, FTPS-, FTP- og AS2-protokoller. Den understøtter tusindvis af samtidige brugere og er en fuldt administreret, lav-kode-tjeneste. I lighed med indgående processer, kan du bruge Amazon API Gateway , AWS Lambda til datatræk ved hjælp af Amazon Redshift Data API. Og AWS dataudveksling hjælper med at offentliggøre dine data til tredjeparter til forbrug gennem AWS Marketplace.
Forbrugstjenester
Amazon QuickSight er den anbefalede service til oprettelse af rapporter og dashboards. Det giver dig mulighed for at skabe interaktive dashboards, visualiseringer og avancerede analyser med ML-indsigt. Amazon SageMaker er ML-platformen til alle dine behov for datavidenskab. Det hjælper dig med at opbygge, træne og implementere modeller, der forbruger data fra lagre i datahubben. Du kan bruge Amazon front-end web og mobil tjenester og AWS IoT tjenester til at bygge web-, mobil- og IoT-slutpunktsapplikationer til at forbruge data ud af datahubben.
Datastyringstjenester
AWS Glue Data Katalog , AWS søformation er de centrale datastyringstjenester, AWS tilbyder i øjeblikket. Disse tjenester hjælper med at administrere metadata centralt for alle datalagre og administrere adgangskontrol. De hjælper også med dataklassificering og kan automatisk håndtere skemaændringer. Du kan bruge Amazon DataZone at opdage og dele data i stor skala på tværs af organisationsgrænser med indbygget styring og adgangskontrol. AWS investerer i dette rum for at give mere en samlet oplevelse for AWS-tjenester. Der er mange partnerprodukter såsom Collibra, Alation, Amorphic, Informatica og flere, som du også kan bruge til datastyringsfunktioner med AWS-tjenester.
Sikkerheds- og overvågningstjenester
AWS identitets- og adgangsstyring (AWS IAM) administrerer identiteter for AWS-tjenester og -ressourcer. Du kan definere brugere, grupper, roller og politikker til finmasket adgangsstyring af din arbejdsstyrke og arbejdsbelastninger. AWS Key Management Service (AWS KMS) administrerer AWS-nøgler eller kundeadministrerede nøgler til dine applikationer. amazoncloudwatch , AWS CloudTrail hjælpe med at levere overvågnings- og revisionskapaciteter. Du kan indsamle metrics og hændelser og analysere dem for operationel effektivitet.
I dette indlæg har vi diskuteret de mest almindelige AWS-tjenester for de respektive løsningskomponenter. Du er dog ikke begrænset til kun disse tjenester. Der er mange andre AWS-tjenester til specifikke brugstilfælde, der kan være mere passende til dine behov end det, vi diskuterede her. Du kan kontakte AWS Analytics Solutions Architects for at få passende vejledning.
Eksempler på arkitekturer til spilbrug
I dette afsnit diskuterer vi eksempler på arkitekturer for to gaming use cases.
Analyse af spilbegivenheder
Begivenheder i spillet (også kaldet tidsbestemte eller live-begivenheder) tilskynder spillerengagement gennem spænding og forventning. Begivenheder lokker spillere til at interagere med spillet, hvilket øger spillernes tilfredshed og indtjening med køb i spillet. Begivenheder er blevet mere og mere vigtige, især efterhånden som spil skifter fra at være statiske stykker underholdning, der skal spilles, til at tilbyde dynamisk og skiftende indhold gennem brug af tjenester, der bruger information til at træffe beslutninger om spil, mens spillet spilles. Dette gør det muligt for spil at ændre sig, efterhånden som spillerne spiller og påvirker, hvad der virker og hvad der ikke gør, og giver ethvert spil en potentielt uendelig levetid.
Denne mulighed for begivenheder i spillet til at tilbyde nyt indhold og aktiviteter inden for en velkendt ramme er, hvordan du holder spillere engageret og spiller i måneder til år. Spillere kan nyde nye oplevelser og udfordringer inden for de velkendte rammer eller verden, som de er vokset til at elske.
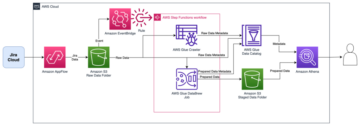
Følgende eksempel viser, hvordan en sådan arkitektur kan se ud, herunder ændringer for at understøtte forskellige dele af processen, som f.eks. at opdele dataene i separate beholdere for at imødekomme skalerbarhed, tilbageførsel og ejerskab.
For fuldt ud at forstå, hvordan begivenheder ses af spillerne og for at træffe beslutninger om fremtidige begivenheder, kræver det information om, hvordan den seneste begivenhed faktisk blev udført. Det betyder, at der indsamles en masse data, mens spillerne spiller for at opbygge key performance indicators (KPI'er), der måler effektiviteten og spillernes tilfredshed med hver begivenhed. Dette kræver analyser, der specifikt måler hver begivenhed og fanger, analyserer, rapporterer om og måler spilleroplevelsen for hver begivenhed. Disse KPI'er omfatter følgende:
- Indledende brugerflow-interaktioner – Hvilke handlinger brugere foretager sig, efter de første gang har modtaget eller downloadet en begivenhedsopdatering i et spil. Er der nogle klare afleveringssteder eller flaskehalse, der slår folk fra begivenheden?
- monetarisering – Hvornår, hvad og hvor brugere bruger penge på i begivenheden, uanset om det er at købe valutaer i spillet, besvare annoncer, tilbud og så videre.
- Spiløkonomi – Hvordan kan brugere tjene og bruge virtuelle valutaer eller varer under en begivenhed, ved at bruge penge i spillet, handler eller byttehandel.
- Aktivitet i spillet – Spillerens sejre, tab, level-up, konkurrencesejre eller spillerpræstationer inden for begivenheden.
- Bruger til bruger interaktioner – Invitationer, gaver, chats (private og gruppe), udfordringer og så videre under et arrangement.
Dette er blot nogle af de KPI'er og målinger, der er nøglen til forudsigelig modellering af begivenheder, da spillet anskaffer nye spillere, samtidig med at eksisterende brugere holdes involveret, engageret og spiller.
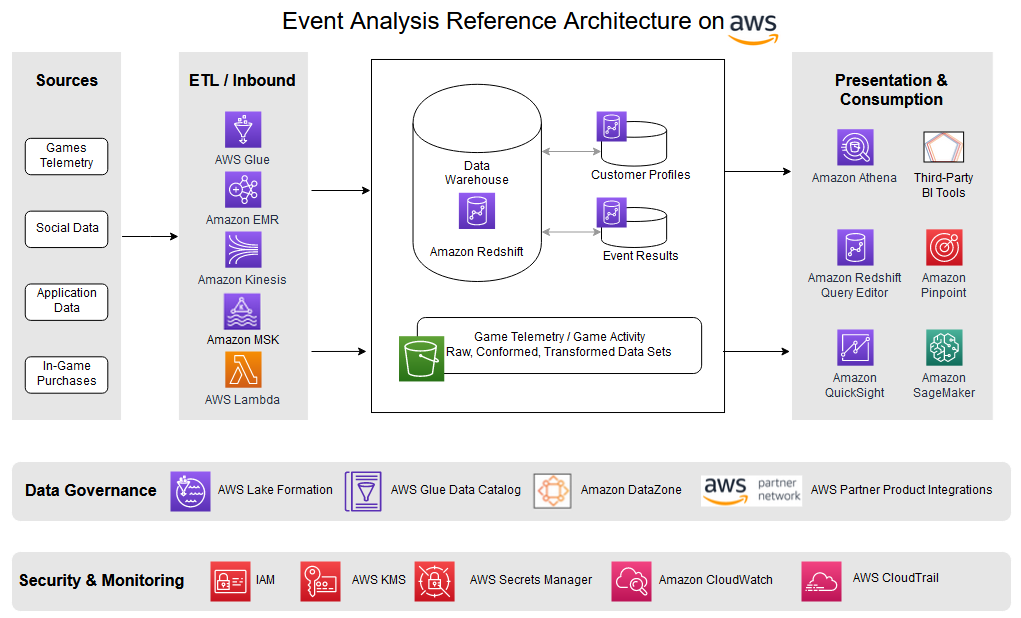
Aktivitetsanalyse i spillet
Aktivitetsanalyse i spillet ser i det væsentlige på enhver meningsfuld, målrettet aktivitet, som spilleren kan vise, med det formål at forsøge at forstå, hvilke handlinger der udføres, deres timing og resultater. Dette inkluderer situationsbestemt information om spillerne, herunder hvor de spiller (både geografisk og kulturelt), hvor ofte, hvor længe, hvad de foretager sig ved hvert login og andre aktiviteter.
Følgende eksempel viser, hvordan en sådan arkitektur kan se ud, herunder ændringer for at understøtte forskellige dele af processen, som f.eks. opdeling af data i separate varehuse. Multi-cluster warehouse-tilgangen hjælper med at skalere arbejdsbyrden uafhængigt, giver fleksibilitet til den implementerede charge-back-model og understøtter decentraliseret dataejerskab.

Løsningen logger i det væsentlige information for at hjælpe med at forstå dine spilleres adfærd, hvilket kan føre til indsigt, der øger fastholdelsen af eksisterende spillere og erhvervelse af nye. Dette kan give mulighed for at gøre følgende:
- Giv købsanbefalinger i spillet
- Mål spillertendenser på kort sigt og over tid
- Planlæg begivenheder, som spillerne skal deltage i
- Forstå hvilke dele af dit spil der er mest succesrige, og hvilke der er mindre
Du kan bruge denne forståelse til at træffe beslutninger om fremtidige spilopdateringer, komme med købsanbefalinger i spillet, bestemme, hvornår og hvordan din spiløkonomi skal balanceres, og endda tillade spillere at ændre deres karakter eller spille efterhånden som spillet skrider frem ved at injicere dette information og medfølgende beslutninger tilbage i spillet.
Konklusion
Selvom denne referencearkitektur kun viser eksempler på nogle få analysetyper, giver den en hurtigere teknologisk vej til at aktivere spilanalyseapplikationer. Den afkoblede hub/spoke-tilgang giver fleksibilitet og fleksibilitet til at implementere forskellige tilgange til analyse og forståelse af spilapplikationers ydeevne. De specialbyggede AWS-tjenester, der er beskrevet i denne arkitektur, giver omfattende muligheder for nemt at indsamle, gemme, måle, analysere og rapportere spil- og hændelsesmålinger. Dette hjælper dig med effektivt at udføre analyser i spillet, hændelsesanalyse, måle spillertilfredshed og give skræddersyede anbefalinger til spillere, effektivt organisere begivenheder og øge fastholdelsesraterne.
Tak fordi du læste indlægget. Hvis du har feedback eller spørgsmål, bedes du efterlade dem i kommentarerne.
Om forfatterne
 Satesh Sonti er en Sr. Analytics Specialist Solutions Architect baseret i Atlanta, specialiseret i at bygge virksomhedsdataplatforme, data warehousing og analyseløsninger. Han har over 16 års erfaring med at bygge dataaktiver og lede komplekse dataplatformsprogrammer til bank- og forsikringskunder over hele kloden.
Satesh Sonti er en Sr. Analytics Specialist Solutions Architect baseret i Atlanta, specialiseret i at bygge virksomhedsdataplatforme, data warehousing og analyseløsninger. Han har over 16 års erfaring med at bygge dataaktiver og lede komplekse dataplatformsprogrammer til bank- og forsikringskunder over hele kloden.
 Tanya Rhodes er en Senior Solutions Architect baseret i San Francisco, fokuseret på spilkunder med vægt på analyse, skalering og ydeevneforbedring af spil og understøttende systemer. Hun har over 25 års erfaring i virksomheds- og løsningsarkitektur med speciale i meget store virksomhedsorganisationer på tværs af flere brancher, herunder spil, bankvæsen, sundhedsvæsen, videregående uddannelser og statslige regeringer.
Tanya Rhodes er en Senior Solutions Architect baseret i San Francisco, fokuseret på spilkunder med vægt på analyse, skalering og ydeevneforbedring af spil og understøttende systemer. Hun har over 25 års erfaring i virksomheds- og løsningsarkitektur med speciale i meget store virksomhedsorganisationer på tværs af flere brancher, herunder spil, bankvæsen, sundhedsvæsen, videregående uddannelser og statslige regeringer.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/how-gaming-companies-can-use-amazon-redshift-serverless-to-build-scalable-analytical-applications-faster-and-easier/
- :er
- $OP
- 100
- a
- evne
- I stand
- Om
- adgang
- adgangsstyring
- af udleverede
- imødekomme
- Konti
- resultater
- Overtager
- erhvervelse
- tværs
- aktioner
- aktiviteter
- aktivitet
- faktisk
- adresse
- administration
- annoncer
- fremskreden
- Efter
- Alle
- tillade
- allerede
- Amazon
- Amazon RDS
- blandt
- analyse
- Analytisk
- analytics
- analysere
- ,
- forventning
- Apache
- api
- API'er
- vises
- Anvendelse
- applikationer
- Indløs
- Anvendelse
- tilgang
- tilgange
- passende
- apps
- arkitektur
- ER
- omkring
- Kunst
- AS
- Aktiver
- At
- Atlanta
- revision
- Aurora
- Godkendelse
- auto
- automatisk
- tilgængelighed
- til rådighed
- gennemsnit
- undgå
- AWS
- AWS Marketplace
- tilbage
- Bank
- baseret
- BE
- fordi
- bliver
- før
- være
- BEDSTE
- Bedre
- mellem
- flaskehalse
- grænser
- Boks
- Breaking
- Bringer
- bygge
- Bygning
- indbygget
- virksomhed
- business intelligence
- virksomheder
- Købe
- by
- kaldet
- CAN
- kapaciteter
- Kapacitet
- fange
- tilfælde
- katalog
- kataloger
- center
- udfordringer
- lave om
- Ændringer
- skiftende
- kanaler
- karakter
- Vælg
- klassificering
- klar
- kunder
- Cloud
- samarbejde
- indsamler
- kombination
- kombinerer
- kommentarer
- Fælles
- Kommunikation
- Virksomheder
- kompatibel
- konkurrence
- komplekse
- Compliance
- komponent
- komponenter
- omfattende
- konceptuelle
- konkurrent
- tillid
- Overvejer
- forbruge
- forbruges
- forbruger
- Forbrugere
- forbrug
- Beholdere
- indeholder
- indhold
- fortsæt
- kontinuerlig
- kontrolleret
- kontrol
- Core
- dækker
- skabe
- Oprettelse af
- kulturelle
- valutaer
- For øjeblikket
- kunde
- Kunder
- tilpassede
- data
- dataanalyse
- Dataudveksling
- Data Lake
- Dataplatform
- datakvalitet
- datalogi
- datadeling
- data opbevaring
- datalager
- datavarehuse
- Database
- databaser
- datasæt
- decentral
- afgørelser
- levere
- krævende
- Afhængighed
- indsætte
- beskrevet
- detail
- detaljer
- Bestem
- forskellige
- opdage
- diskutere
- drøftet
- dokumentation
- Er ikke
- domæne
- ned
- downloade
- i løbet af
- dynamisk
- hver
- tjene
- brugervenlighed
- lettere
- nemt
- let
- nem at bruge
- økonomi
- editor
- Uddannelse
- effektivitet
- effektivitet
- effektivt
- enten
- vægt
- muliggøre
- muliggør
- muliggør
- tilskynde
- kryptering
- Endpoint
- engagere
- beskæftiget
- engagement
- Engineering
- Motorer
- forbedret
- nyde
- Enterprise
- Underholdning
- enheder
- Miljø
- især
- væsentlige
- Ether (ETH)
- Endog
- begivenhed
- begivenheder
- eksempel
- eksempler
- udveksling
- Spænding
- eksisterende
- erfaring
- Oplevelser
- udforske
- eksport
- ekstern
- ekstrakt
- bekendt
- FAST
- hurtigere
- Favorit
- Feature
- Funktionalitet
- tilbagemeldinger
- fodring
- få
- File (Felt)
- Filer
- finde
- Fornavn
- Fleksibilitet
- fleksibel
- flow
- Fokus
- fokuserede
- efter
- Til
- For forbrugere
- formular
- format
- Framework
- Francisco
- Frekvens
- frisk
- fra
- fuldt ud
- funktioner
- yderligere
- fremtiden
- fremtidigt spil
- spil
- Spil
- spil
- Spillebranchen
- indsamling
- genereret
- geografisk
- få
- giver
- kloden
- mål
- varer
- regeringsførelse
- regeringer
- gruppe
- Gruppens
- voksen
- vejledning
- håndtere
- Have
- have
- sundhedspleje
- tunge
- hjælpe
- hjælper
- link.
- Høj
- Høj ydeevne
- højere
- Videregående uddannelse
- stærkt
- boliger
- Hvordan
- How To
- Men
- HTML
- HTTPS
- Hub
- IAM
- ideal
- identiteter
- Identity
- gennemføre
- implementering
- implementeret
- vigtigt
- in
- in-game
- omfatter
- omfatter
- Herunder
- Forøg
- stigende
- uafhængigt
- Indikatorer
- industrien
- brancheførende
- indflydelse
- oplysninger
- innovationer
- indsigt
- øjeblikkelig
- forsikring
- integrere
- integreret
- integration
- Intelligens
- interagere
- interaktiv
- grænseflade
- grænseflader
- Internet
- tingenes internet
- investere
- involverede
- tingenes internet
- IT
- ITS
- jpg
- Holde
- holde
- Nøgle
- nøgler
- Kend
- sø
- stor
- Latency
- seneste
- lag
- lag
- føre
- førende
- læring
- Forlade
- niveauer
- levetid
- levetid
- ligesom
- Limited
- linjer
- lidt
- leve
- Live Events
- belastning
- lastning
- logisk
- Lang
- Se
- UDSEENDE
- tab
- Lot
- kærlighed
- Lav
- maskine
- machine learning
- vedligeholdelse
- lave
- administrere
- lykkedes
- ledelse
- administrerer
- obligatorisk
- manuelt
- mange
- markedsplads
- meningsfuld
- midler
- måle
- måling
- Metadata
- Metrics
- måske
- ML
- Mobil
- tilstand
- model
- modellering
- modeller
- penge
- overvågning
- måned
- mere
- mest
- Mest Populære
- bevægelse
- flytning
- flere
- MySQL
- Behov
- behov
- Ny
- notesbøger
- målsætninger
- of
- tilbyde
- tilbyde
- Tilbud
- on
- ONE
- online
- åbent
- operationelle
- optimal
- Option
- oracle
- organisation
- organisatorisk
- organisationer
- Organiseret
- Andet
- ejere
- ejerskab
- parter
- partner
- partnere
- dele
- sti
- Betal
- PC
- Mennesker
- udføre
- ydeevne
- Fysisk
- stykker
- Søjle
- Place
- perron
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- Leg
- spillet
- spiller
- spillere
- spiller
- Vær venlig
- punkter
- politikker
- politik
- Populær
- mulig
- Indlæg
- postgresql
- potentielt
- foretrækkes
- pris
- primært
- private
- behandle
- Processer
- forarbejdning
- produktivitet
- Produkter
- Programmer
- protokoller
- give
- giver
- offentliggøre
- Publicering
- køb
- indkøb
- kvalitet
- Spørgsmål
- hurtigt
- priser
- Raw
- rådata
- nå
- Læsning
- klar
- realtid
- modtage
- anbefalinger
- anbefales
- optage
- regioner
- relevant
- indberette
- Rapporter
- Repository
- repræsentere
- påkrævet
- Kræver
- Ligner
- Ressourcer
- dem
- restriktiv
- tilbageholdelse
- indtægter
- roller
- regler
- Kør
- samme
- San
- San Francisco
- tilfredshed
- Skalerbarhed
- skalerbar
- Scale
- skalaer
- skalering
- Videnskab
- Sektion
- sektioner
- sikkert
- sikkerhed
- senior
- adskille
- Serverless
- tjeneste
- Tjenester
- Del
- delt
- deling
- skifte
- Kort
- bør
- Vis
- Shows
- lignende
- Simpelt
- So
- Social
- løsninger
- Løsninger
- nogle
- Kilde
- Kilder
- Space
- specialist
- specialiserede
- speciale
- specifikke
- specifikt
- tilbringe
- udgifterne
- bruge penge
- SQL
- stable
- standard
- starte
- starter
- Tilstand
- Stewardship
- opbevaring
- butik
- forhandler
- streaming
- streaming tjenester
- struktureret
- abonnement
- succes
- vellykket
- sådan
- support
- Understøttet
- Støtte
- Understøtter
- Systemer
- tager
- hold
- Teknisk
- Teknologier
- Teknologier
- vilkår
- at
- navet
- The Source
- deres
- Them
- Disse
- ting
- Tredje
- tredje partier
- tredjepart
- tusinder
- Gennem
- Tidsindstillet
- timing
- til
- værktøj
- værktøjer
- handler
- Tog
- transaktionsbeslutning
- overførsel
- Transform
- Transformation
- omdannet
- Tendenser
- Drejning
- typer
- typisk
- forstå
- forståelse
- forenet
- uforudsigelige
- Opdatering
- opdateringer
- us
- brug
- Bruger
- brugere
- sædvanligvis
- udnytte
- validering
- forskellige
- leverandører
- visninger
- Virtual
- virtuelle valutaer
- Warehouse
- Warehousing
- web
- web-baseret
- websockets
- GODT
- Hvad
- hvorvidt
- som
- mens
- WHO
- vilje
- Vinder
- med
- inden for
- uden
- Workforce
- virker
- world
- år
- Din
- zephyrnet
- nul