I denne artikel finder du ud af forskellige metoder til at konvertere PDF til Google Sheets.
Du vil også lære, hvordan Nanonets kan automatisere hele arbejdsgangen med at konvertere PDF til Google Sheets online.
Før vi ser på, hvordan man konverterer PDF til Google Sheets, lad os tage et kig på, hvorfor det er vigtigt at gøre dette.
Hvorfor konvertere PDF-filer til Google Sheets?
Ifølge denne google-blog indlæg fra den officielle Google-blogside, bruger mere end 5 millioner virksomheder deres G Suite-løsning. Samtidig er en lang række virksomheder også begyndt at bruge Google Sheets-integrationer til at automatisere opgaver.
Lad os overveje en typisk use case. Dit Kreditorteam modtager en faktura i standard PDF-format. Nogen går manuelt igennem fakturaen og indtaster de nødvendige oplysninger i et Google Sheets-dokument, før de videresender det til finanssektionen. Økonomisektionen betaler din leverandør og laver en indtastning i virksomhedens hovedbog.
Ud over at være en langvarig proces, er dette fejludsat, og det ville give meget mere mening blot at automatisere det.
Nu hvor behovet for at konvertere PDF-filer til en Google-arkformular er klart, lad os tage et kig på, hvordan PDF-dokumenter er struktureret, og hvad udfordringerne er ved at parse dem.
Ønsker at konvertere PDF filer til Google Sheets ? Check ud Nanonetter' gratis PDF til CSV konverter. Eller find ud af hvordan automatiser hele din PDF til Google Sheets workflow med Nanonets.
Udfordringer med at parse et PDF-dokument
Det bærbare dokumentformat var et filformat oprindeligt udviklet af Adobe og blev senere udgivet som en åben standard. Det er siden blevet bredt vedtaget, da det er agnostisk over for det underliggende operativsystem.
Så hvorfor er det så udfordrende at parse en PDF og konvertere dens indhold til et andet format? De følgende billeder siger mere end tusind ord og vil føre pointen hjem.
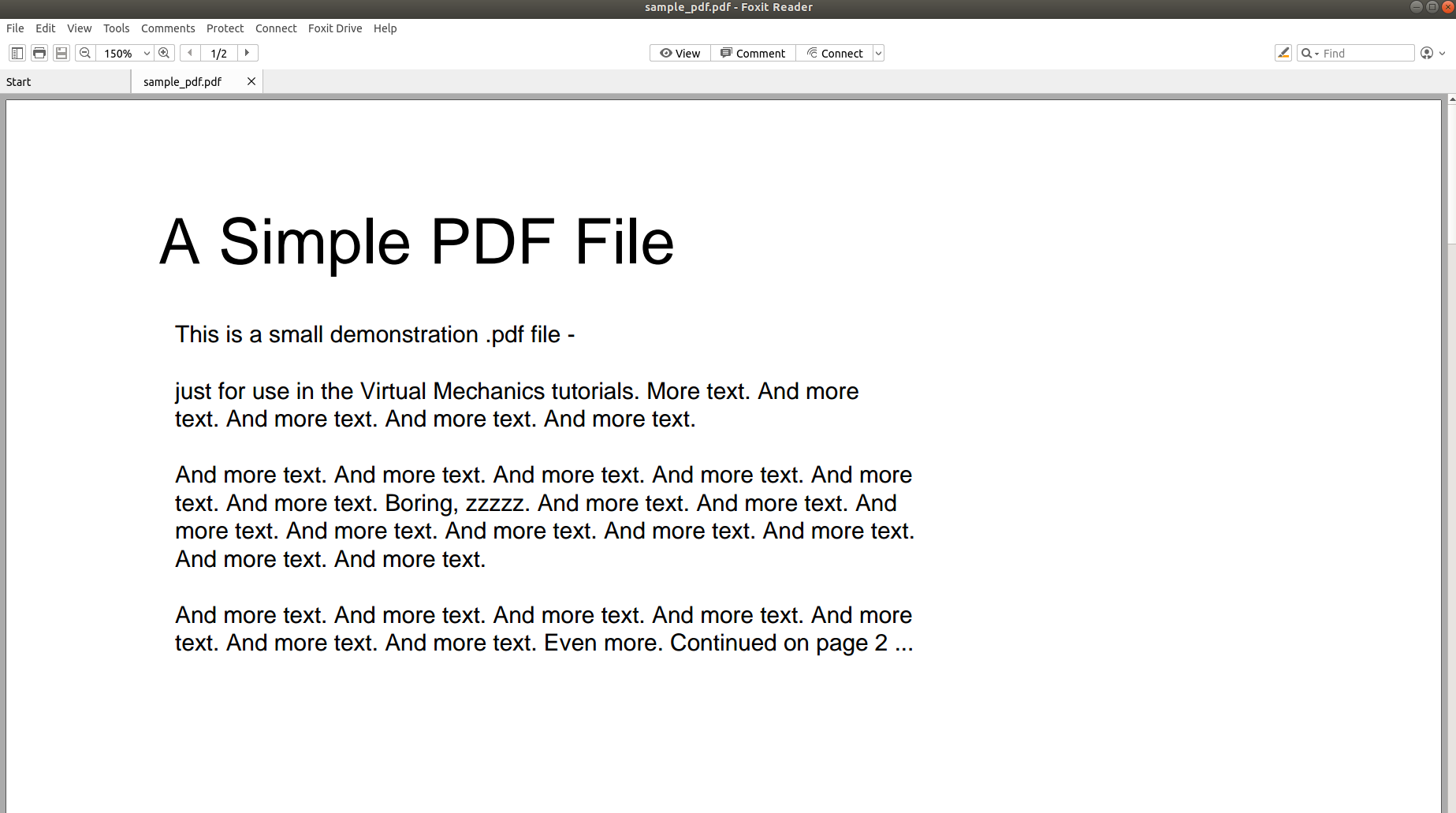
Ovenstående billede viser skærmbilledet af et PDF-dokument, som åbnes ved hjælp af en PDF-læser. Lad os prøve at åbne det samme PDF-dokument ved hjælp af en teksteditor.
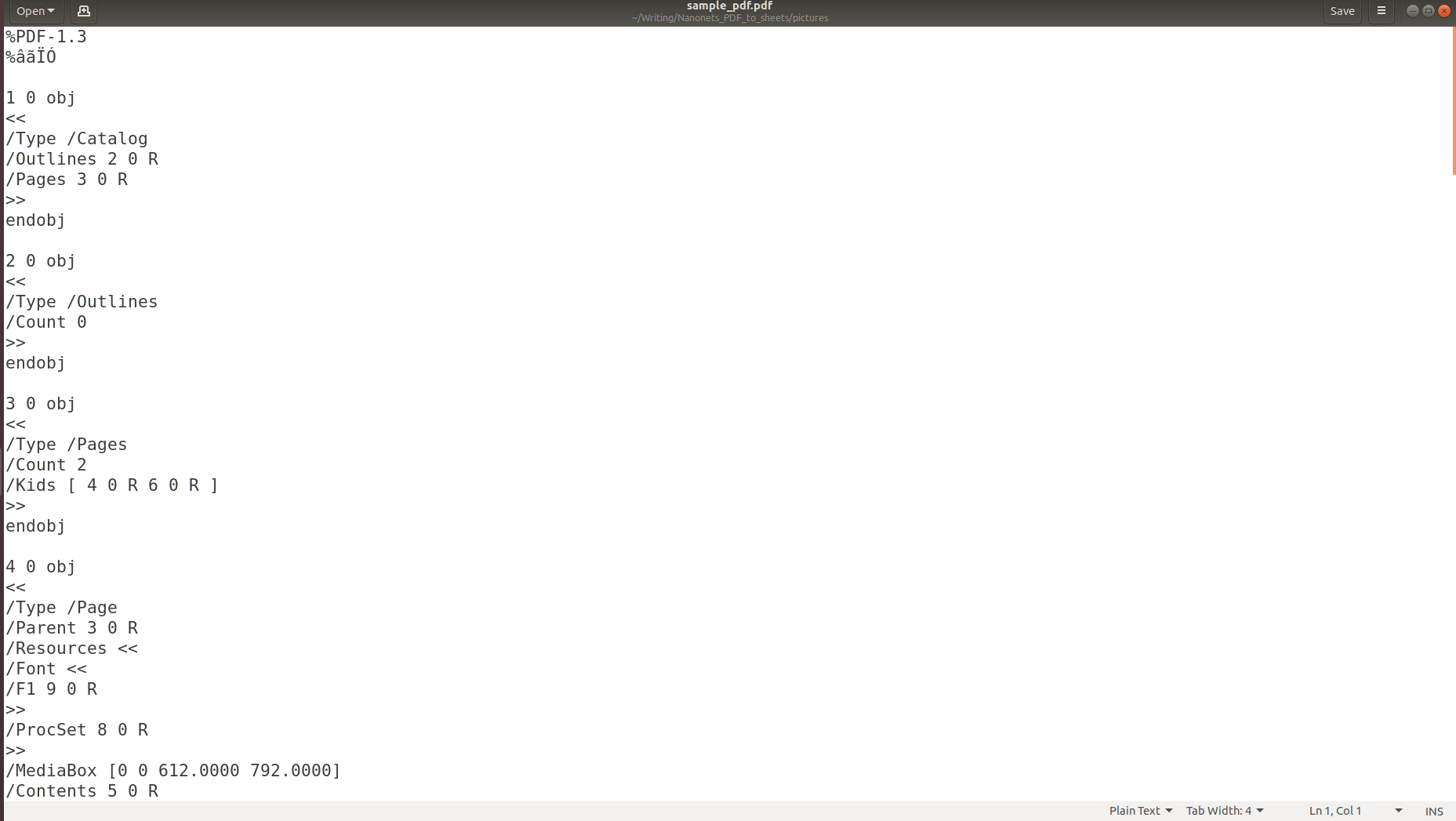
Ovenstående billeder gør det klart, at når information gemmes i en PDF, går dens oprindelige struktur fuldstændig tabt. Det skyldes, at PDF-formatet blot består af instruktioner til, hvordan man udskriver/tegner en sekvens af tegn på en side.
Hvis du synes, at tekstudvinding er vanskelig, er det endnu mere udfordrende at udtrække dataene i tabeller på grund af vidt forskellige tabelformater, der bruges.
Forhåbentlig er du overbevist om, at det ikke er en gåtur i parken at konvertere et PDF-dokument til en Google Sheets-formular. Det næste afsnit fortæller om den tilgang, som de fleste moderne PDF-parsere anvender til at genkende/parse information fra et PDF-dokument.
Den moderne tilgang til at analysere PDF-dokumenter
De fleste moderne PDF-parsere gør brug af flowet beskrevet nedenfor til at parse ustrukturerede data fra PDF-dokumenter.
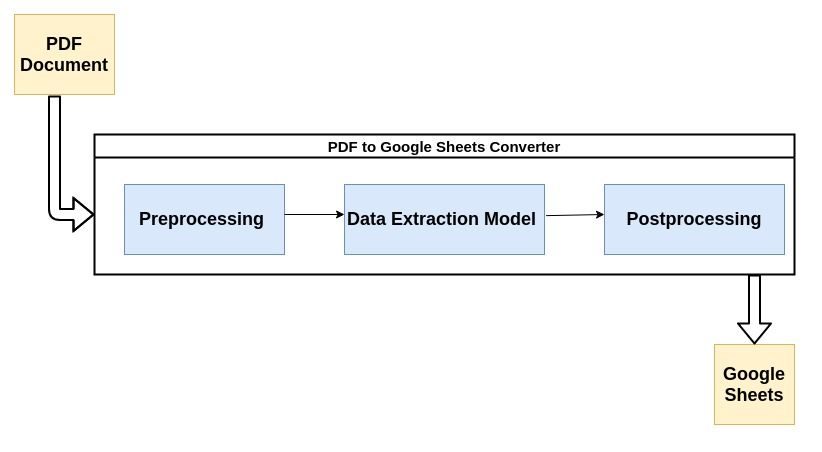
Lad os kort tage et kig på hvert trin i processen:
1. Forbehandling eller datarensning:
Jo bedre din PDF ser ud, jo lettere vil det være for din Machine Learning-model at udtrække eller indsamle data fra det. For eksempel, hvis PDF-dokumentet er blevet scannet, er det bundet til at indeholde nogle scanningsartefakter, som kan påvirke konverterens ydeevne.
Støjfjernelse ved at bruge passende filtre, binarisering, skævhedskorrektion osv. er nogle af de mest almindelige forbehandlingstrin. Følgende Nanonets indlæg Nanonets Tesseract Post indeholder nogle gode eksempler på, hvordan dokumenter kan forbehandles før Optical Character Recognition(OCR) køres på dem.
Det er her det meste af magien sker. Dataudtræk udføres normalt af en Machine Learning (ML) model. De fleste ML-modeller, der bruges til dataudtræk fra PDF'er, indeholder en kombination af optiske tegngenkendelsesværktøjer, tekst- og mønstergenkendelsesværktøjer osv.
Til formålet med dette indlæg kan vi behandle modellen som en sort boks, der tager dit PDF-dokument som input og spytter den parsede information ud. Da den anvender ML i sin kerne, kan den også omskoles med tilpassede data, så de passer til din virksomheds brugssituation.
3. Efterbehandling:
I dette trin konverteres de udpakkede data til det påkrævede format såsom CSV, XML, JSON osv. Derudover tilføjes yderligere brugerdefinerede regler oven i forudsigelserne lavet af AI. Dette kan omfatte regler for formatering af output, yderligere begrænsninger på information, der udvindes osv.
Det følgende afsnit ser på nogle målinger, som vi kunne bruge til at måle ydeevnen af en PDF-parser.
Ønsker at konvertere PDF filer til Google Sheets ? Check ud Nanonetter' gratis PDF til CSV konverter. Find ud af, hvordan du automatiserer hele din PDF til Google Sheets-arbejdsgang med Nanonets.

Metrik til at måle ydeevnen af en PDF-konverter
Da de fleste PDF-konvertere vil blive brugt til fakturabehandling eller relaterede opgaver, er nøjagtigheden og hastigheden af tabeludtræk fra et PDF-dokument en kritisk faktor i bedømmelsen af PDF-konverterens ydeevne.
2. Flersproget evne:
De fleste store virksomheder er forpligtet til at modtage fakturaer på en række forskellige sprog. PDF-parseren skal enten understøtte flersproget parsing ud af boksen, eller den skal give en mulighed, hvorved brugere kan træne modellen ved hjælp af brugerdefinerede data.
3. Integration med regnskabssoftware:
Den ideelle PDF-konverter bør være et plug and play-modul, der nemt kan føjes til dit eksisterende dokument arbejdsgang. Det skal understøtte integration med populær regnskabssoftware som QuickBooks, Xero, Wave osv.
4. Nemt og intuitivt:
Værktøjet vil højst sandsynligt blive betjent af ikke-tekniske brugere. Det vil være en fordel, hvis det kan betjenes med minimal teknisk viden.
Forskellige metoder til at konvertere PDF-filer til Google Sheets
1.Brug af Google Docs til at konvertere PDF til Google Sheets
Google Drev har indbygget mulighed for at genkende tabeller og tekst i simple PDF-dokumenter. Du skal blot:
-
Upload din PDF-fil til Google Drev
-
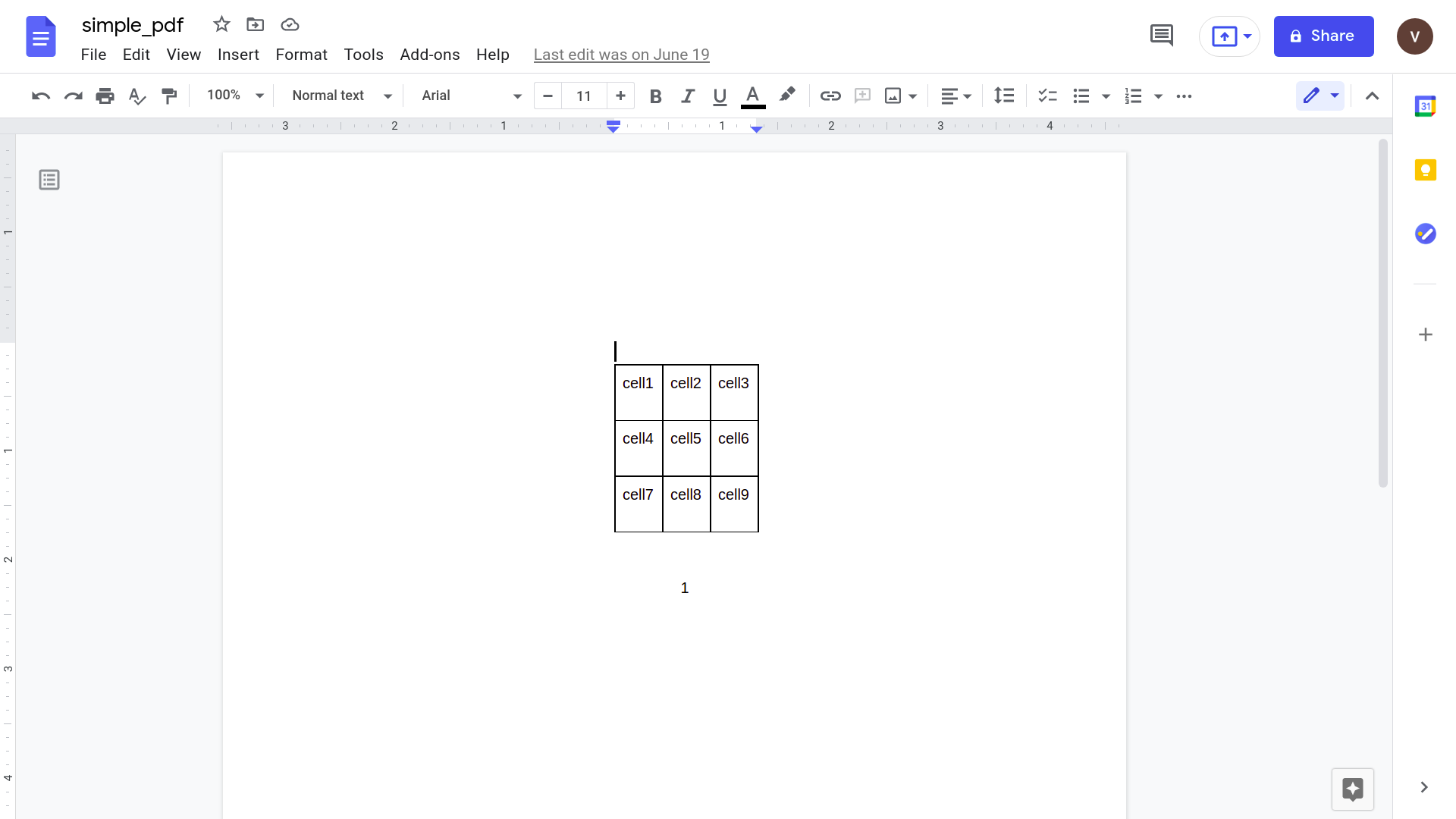
Klik på "Åbn med Google Docs"
-
Kopiér de data, du ønsker, og indsæt dem i Google Sheets
Selvom det ser ud til at fungere godt, lad os prøve noget lidt mere praktisk. Overvej denne enkle faktura.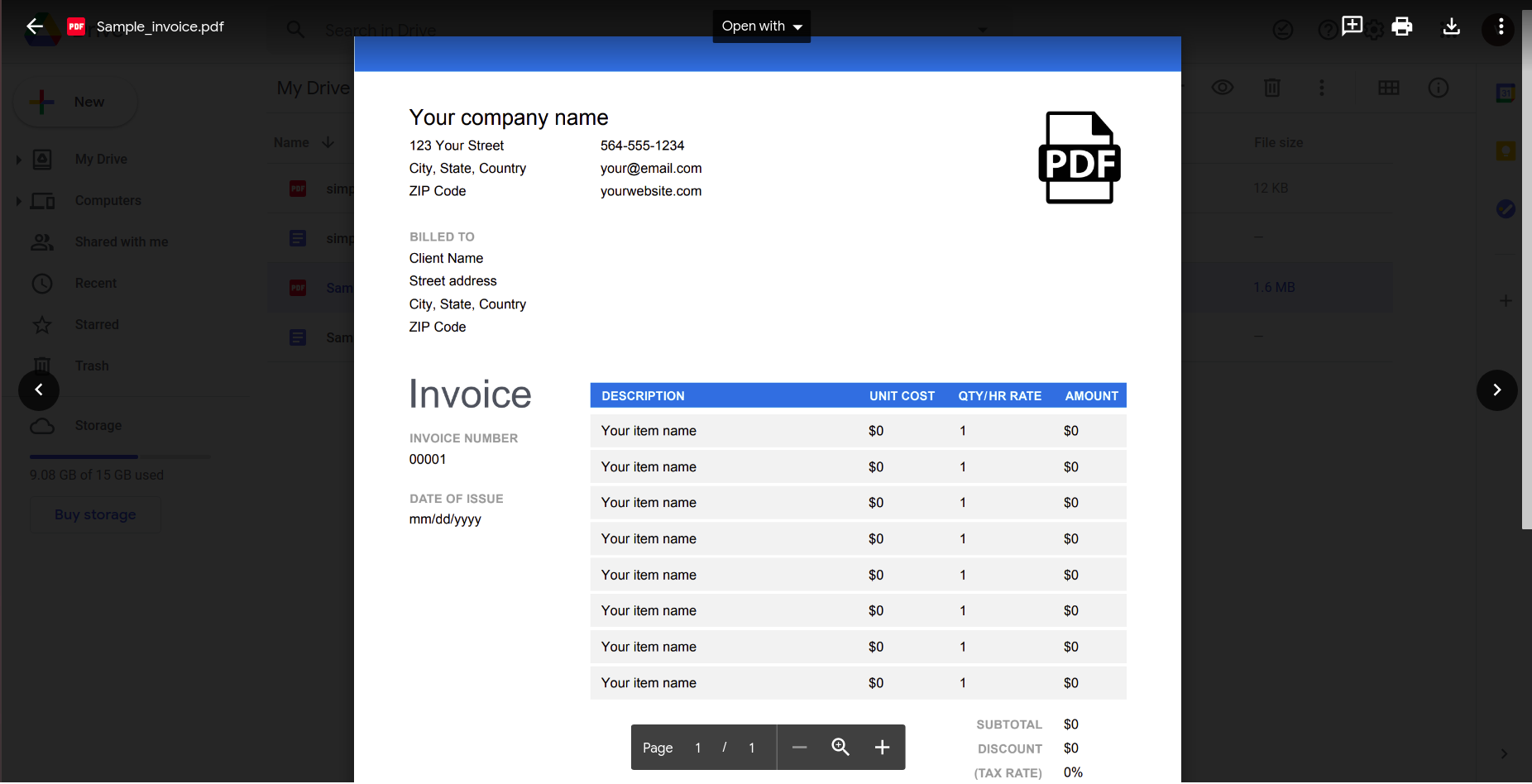
Åbning af dette ved hjælp af Google docs-applikationen giver følgende resultat.
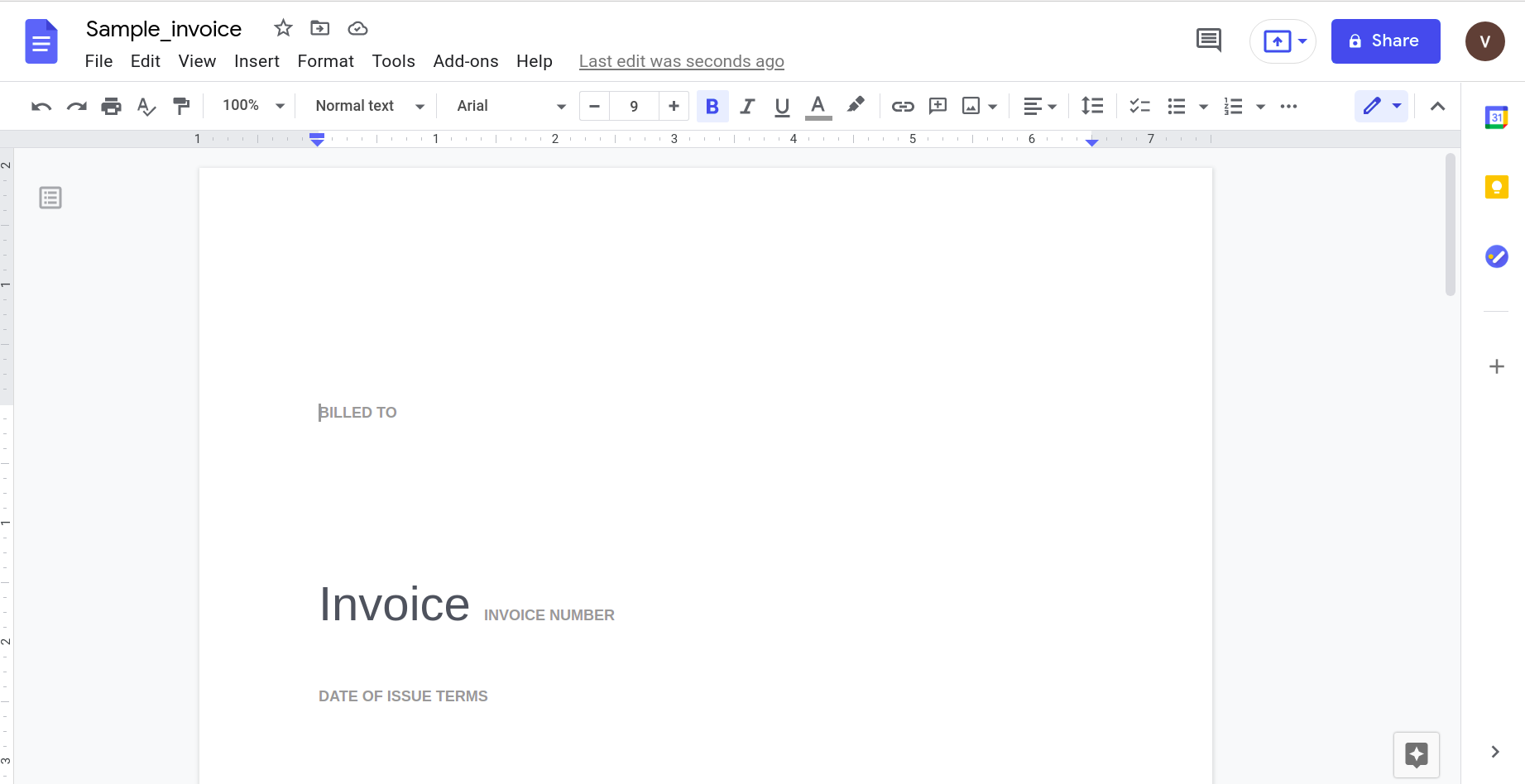
Det er klart, at efterhånden som dokumentets kompleksitet øges, er vi nødt til at stole på mere sofistikerede værktøjer til at genkende data.
2. Brug af onlineværktøjer:
Adskillige onlineværktøjer såsom PDF-tabeludtrækker, Online2PDF osv., integreres direkte med Google Drev og giver mulighed for at konvertere PDF-dokumenter til Google Sheets.
Men da disse værktøjer blev testet ved hjælp af eksemplet på faktura-PDF vist ovenfor, blev tabellerne ikke fundet i de fleste tilfælde.
Ønsker at konvertere PDF filer til Google Sheets ? Check ud Nanonetter' gratis PDF til CSV konverter. Find ud af, hvordan du automatiserer hele din PDF til Google Sheets-workflow med Nanonets som vist nedenfor.
Automatisering af PDF til Google Sheets-konverteringsprocessen
Vi kan fuldstændig automatisere processen med at parse PDF'en og udtrække dataene til en Google Sheets-formular ved at bruge følgende værktøjer.
1. Brug af Webhooks:
Webhooks er brugerdefinerede HTTP-anmodninger. De udløses normalt på en hændelse, dvs. når en hændelse indtræffer, sender applikationen information til en foruddefineret URL.
Hvordan kan du bruge dette til at automatisere din arbejdsgang? Lad os overveje den typiske brugssag af fakturabehandling. Du modtager en række fakturaer fra dine leverandører og fører dem ind i din PDF til Google Sheets-konverter, som ligger i skyen. Hvordan ved man, hvornår modellen er færdig med at behandle dokumenterne?
I stedet for manuelt at tjekke, om konverteringen er gennemført, kan du blot gøre brug af en webhook, der giver dig besked, når dataene i PDF'en er blevet udtrukket til et Google Sheets-dokument.
2. Brug af API'er
API står for Application Programming Interface. Ved at bruge de relevante API-kald kan konvertering af PDF-dokumenter til Google Sheets vise sig at være lige så let som at skrive følgende kodelinjer:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Hvis din virksomhed allerede har opsat integrationen med Webhooks, vil du modtage en meddelelse, når dine PDF-dokumenter er blevet konverteret. Du kan derefter downloade Google Sheets-formularen ved hjælp af API'et vist nedenfor.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF til Google Sheets med Nanonets
Nanonets PDF-parser gør parsing og konvertering nem og nøjagtig. PDF-parseren blev brugt til at parse en eksempelfaktura. Dette afsnit demonstrerer værktøjets lette brug og nøjagtighed. I stedet for at tale om, hvor fantastisk det er, illustrerer de følgende billeder på passende vis pointen.
Billedet vist nedenfor er et skærmbillede af eksempelfakturaen, som blev ført til Nanonets PDF-parseren.
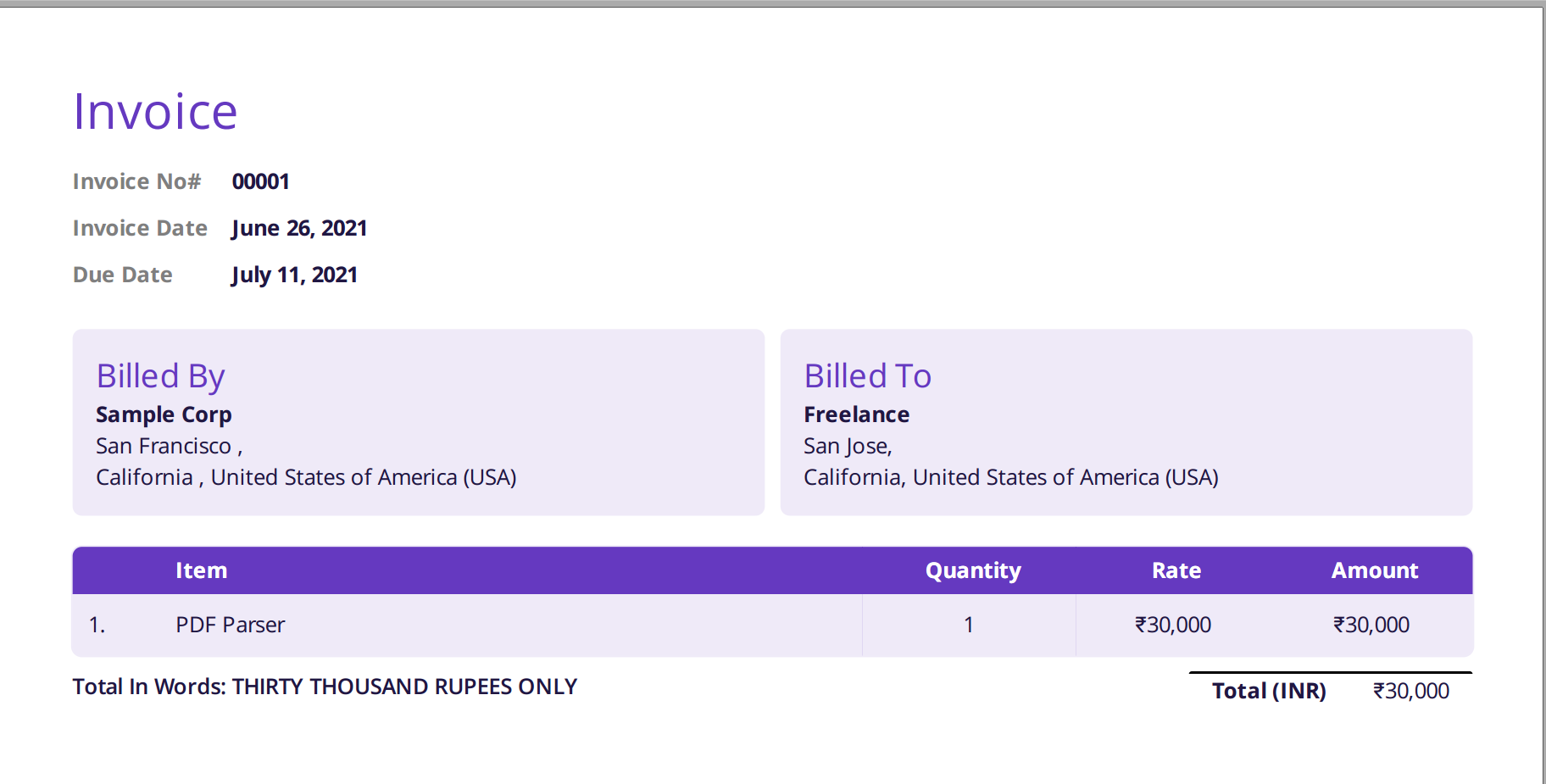
Du skal blot navigere til Nanonets hjemmeside og uploade fakturaen. Konvertering tager kun et par sekunder, hvorefter de parsede data kan downloades i en række forskellige formater som f.eks CSV, XLSX osv. (tjek Nanonets' PDF til CSV konverter)
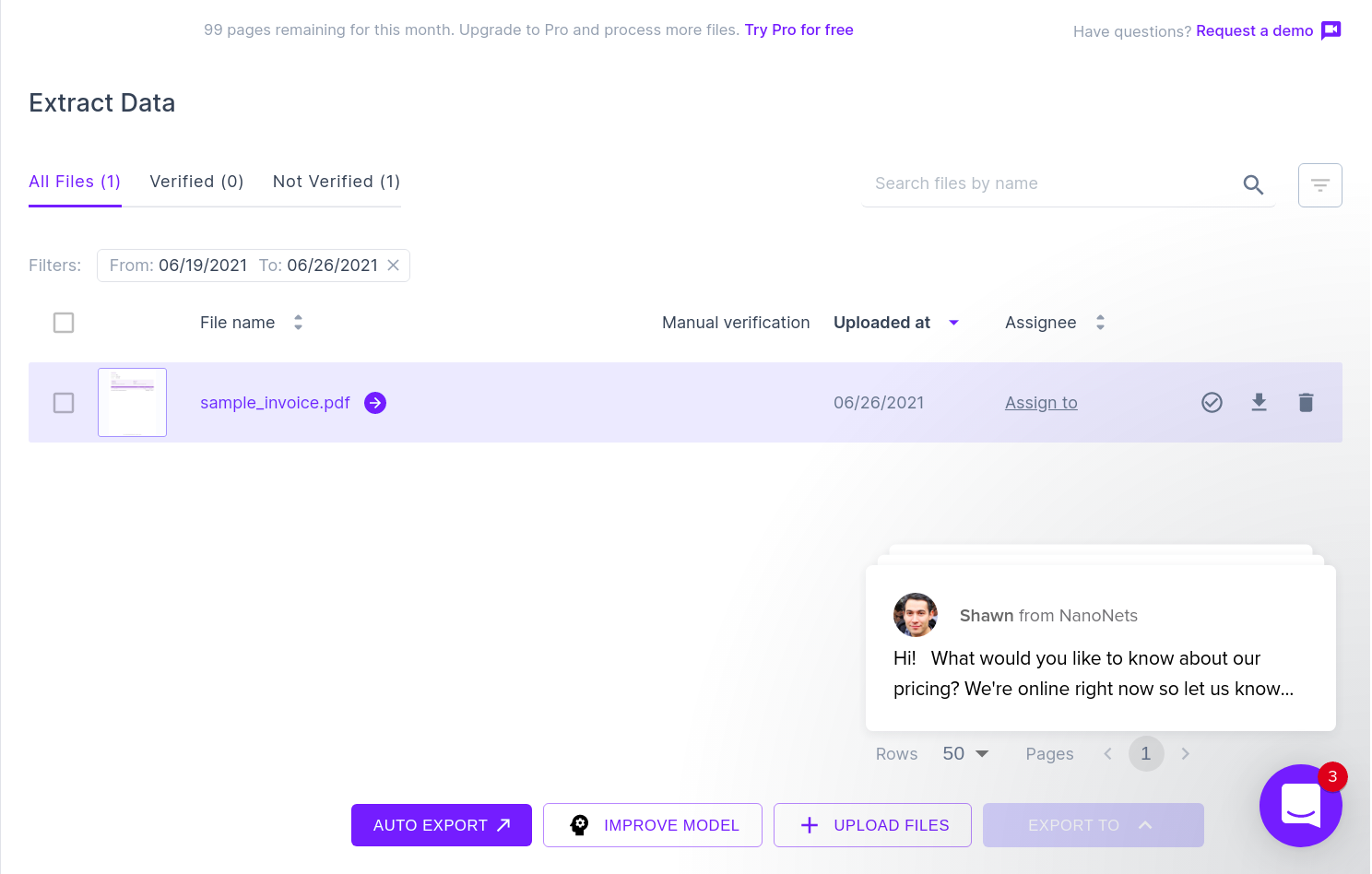
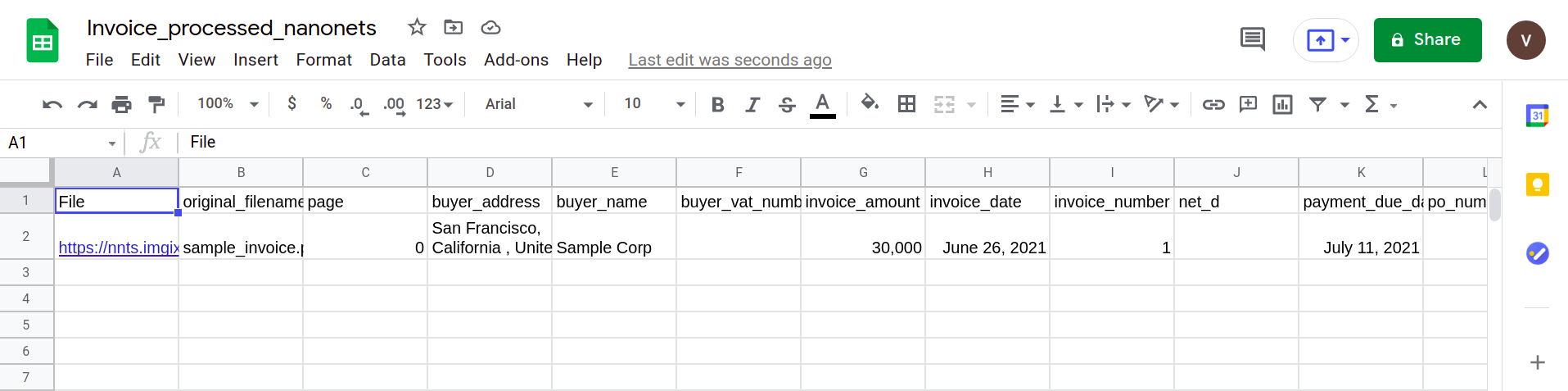
Det næste billede viser et skærmbillede af CSV-filen, der indeholder de analyserede data fra PDF-dokumentet.

Til sidst, for at konvertere CSV-filen til en google sheets-formular, er det blot et spørgsmål om at uploade XLSX/CSV-filen til dit Google-drev. Dette trin kan automatiseres ved at bruge Google Drive API'er.
Det følgende afsnit viser, hvordan en simpel pipeline kan oprettes ved at gøre brug af Nanonets PDF-parser.
Vil du udtrække oplysninger fra PDF-dokumenter og konvertere/føje dem til et Google Sheets-dokument? Tjek Nanonets™ at automatisere eksport af enhver information fra et PDF-dokument til Google Sheets!
Oprettelse af en simpel rørledning
1. Upload automatisk dine PDF-dokumenter ved hjælp af Nanonets API
Nanonets API giver dig mulighed for automatisk at uploade dine dokumenter, som skal parses. Følgende kodestykke viser, hvordan dette kan gøres ved hjælp af python.
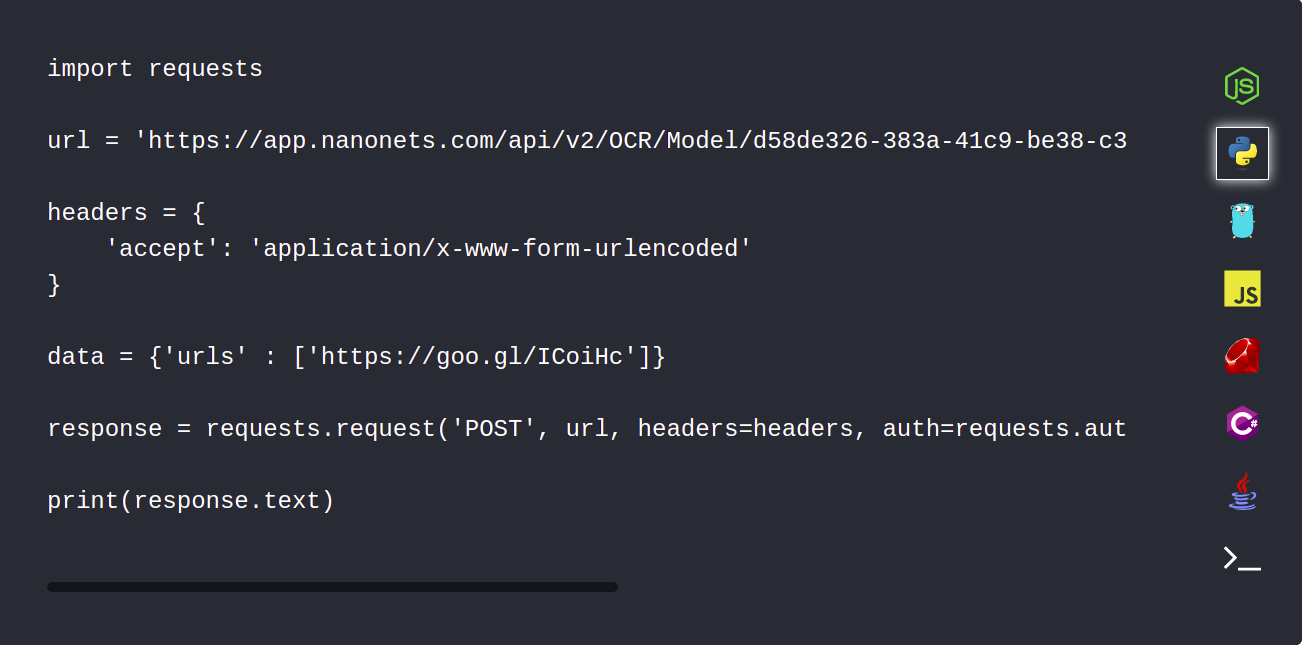
2. Brug webhooks-integration til at modtage en meddelelse efter færdiggørelse af parsing
Webhooks kan konfigureres til automatisk at give dig besked, når dokumenterne er blevet parset.
3. Gennemgå og upload til Google Sheets
Download og gennemse CSV-filerne for at sikre dig, at alt er i orden, og upload dataene til Google Sheets ved hjælp af Google Drive API.
Nanonets Edge
Her er nogle funktioner i Nanonets PDF Parser, der gør den til det ideelle værktøj til din virksomhed.
1. Eksterne integrationer:
Nanonetmodellen kan nemt integreres med MySql, Quickbooks, Salesforce etc. Det betyder, at din nuværende arbejdsgang forbliver uforstyrret, og nanonetkonverteren kan blot tilsluttes som et ekstra modul.
2. Høj nøjagtighed og lave behandlingstider:
Nanonets PDF-parserværktøjet har en nøjagtighed på over 95%+, hvilket er meget højere sammenlignet med dets konkurrenter.
3. Seje efterbehandlingsfunktioner:
Antag, at din database er blevet integreret med nanonets-modellen. Modellen udfylder automatisk nogle felter (med data fra din database) baseret på de data, der er udtrukket fra dokumentet. For eksempel:
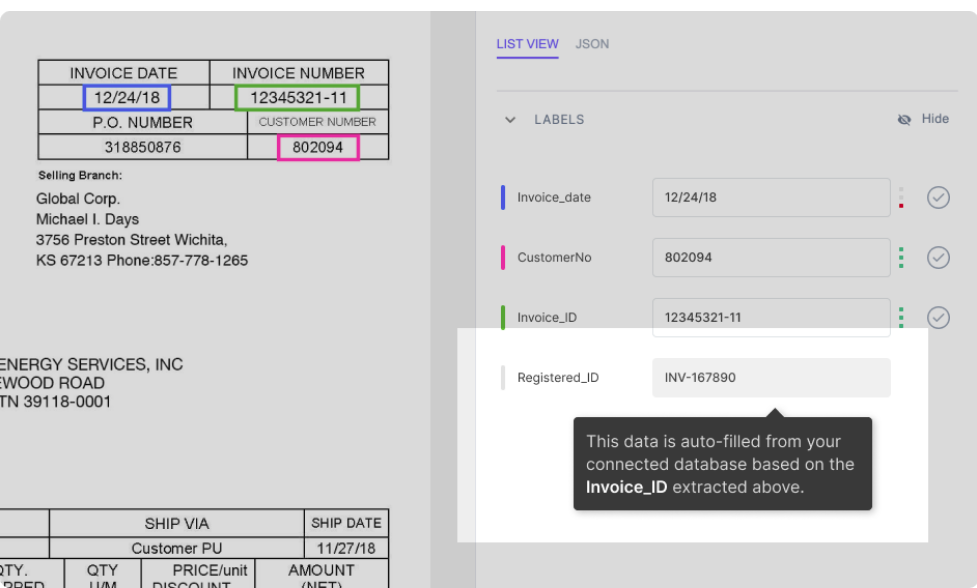
Som vist på figuren udfyldes feltet Registered_ID automatisk (ved et databaseopslag) baseret på det Invoice_ID, der er udtrukket fra PDF'en.
4. Enkel og intuitiv grænseflade
Selvom denne funktion er undervurderet, fandt jeg, at brugergrænsefladen og UX var spot on. Hele processen med at tilmelde sig, uploade dokumentet og analysere dataene tog mindre end 5 minutter. Det svarer næsten til den tid, det tager min bærbare computer at starte op!
5. Kæmpe kundebase
Hvis du stadig har forbehold for at bruge Nanonets til at automatisere din arbejdsgang, skal du bare tage et kig på nogle af de virksomheder, der bruger deres tjenester.
- Deloitte
- Sherwin Williams
- DoorDash
- P&G
Vil du udtrække oplysninger fra PDF-dokumenter og konvertere/føje dem til et Google Sheets-dokument? Tjek Nanonets™ at automatisere eksport af enhver information fra et PDF-dokument til Google Sheets!
Konklusion
I dette indlæg tog vi et kig på, hvordan du kan automatisere din arbejdsgang ved at bruge en PDF til Google Sheets-konverter. Til at begynde med lærte vi om behovet for at konvertere PDF-dokumenter til Google Sheets efterfulgt af de udfordringer, som denne proces står over for. Vi dykkede derefter ned i de tilgange, som moderne parsere anvender til at parse PDF-dokumenter, og implementerede også nogle af de almindelige fremgangsmåder. Vi lærte også, hvordan vi fuldstændig kan automatisere konverteringen ved hjælp af eksterne integrationer såsom webhooks og API'er. Til sidst brugte vi Nanonets-værktøjet til at analysere en eksempelfaktura, udtrække dataene i en Google Sheets-formular og også udforske nogle af dets fede efterbehandlingsfunktioner.
Har du givet Nanonets-modellen et skud? Hvis ja, bedes du efterlade en kommentar nedenfor om din oplevelse med værktøjet. Hvis ikke, så gå videre og prøv det. Det kan måske bare gøre din dag!
- AI
- AI og maskinindlæring
- ai kunst
- ai kunst generator
- en robot
- kunstig intelligens
- certificering af kunstig intelligens
- kunstig intelligens i banksektoren
- kunstig intelligens robot
- kunstig intelligens robotter
- software til kunstig intelligens
- blockchain
- blockchain konference ai
- coingenius
- samtale kunstig intelligens
- kryptokonference ai
- dalls
- dyb læring
- du har google
- machine learning
- Pdf til google sheets
- plato
- platon ai
- Platon Data Intelligence
- Platon spil
- PlatoData
- platogaming
- skala ai
- syntaks
- zephyrnet