Amazon rødforskydning er et hurtigt, skalerbart, sikkert og fuldt administreret datavarehus, der gør det muligt for dig at analysere alle dine data ved hjælp af standard SQL nemt og omkostningseffektivt. Amazon rødforskydning Datadeling giver kunderne mulighed for sikkert at dele live, transaktionelt konsistente data i én Amazon Redshift-klynge med en anden Amazon Redshift-klynge på tværs af konti og regioner uden at skulle kopiere eller flytte data fra én klynge til en anden.
Amazon Redshift Data Sharing blev oprindeligt lanceret i Marts 2021, og tilføjet understøttelse af datadeling på tværs af konti blev tilføjet August 2021. Den tværregionale støtte blev generelt tilgængelig i februar 2022. Dette giver fuld fleksibilitet og smidighed til at dele data på tværs af Redshift-klynger i den samme AWS-konto, forskellige konti eller forskellige regioner.
Amazon Redshift Data Sharing bruges til grundlæggende at omdefinere Amazon Redshift-implementeringsarkitekturer til en hub-eger, data mesh-model for bedre at imødekomme ydeevne SLA'er, give arbejdsbelastningsisolering, udføre analyser på tværs af grupper, nemt integrere nye use cases og vigtigst af alt gøre alt dette uden kompleksiteten af dataflytning og datakopier. Nogle af de mest almindelige spørgsmål, der stilles under implementering af datadeling, er "Hvor store skal mine forbrugerklynger og producentklynger være?", og "Hvordan får jeg den bedste prisydeevne for isolering af arbejdsbyrder?". Da arbejdsbyrdekarakteristika som datastørrelse, indlæsningshastighed, forespørgselsmønster og vedligeholdelsesaktiviteter kan påvirke datadelingsydelsen, bør der implementeres en kontinuerlig strategi for at dimensionere både forbruger- og producentklynger for at maksimere ydeevnen og minimere omkostningerne. I dette indlæg giver vi en trin-for-trin tilgang til at hjælpe dig med at bestemme størrelsen på dine producent- og forbrugerklynger for den bedste prisydelse baseret på din specifikke arbejdsbyrde.
Generisk vejledning til forbrugerstørrelser
De følgende trin viser den generiske strategi for størrelsen på dine producent- og forbrugerklynger. Du kan bruge det som udgangspunkt og ændre i overensstemmelse hermed for at imødekomme dit specifikke brugsscenarie.
Dimensionér din producentklynge
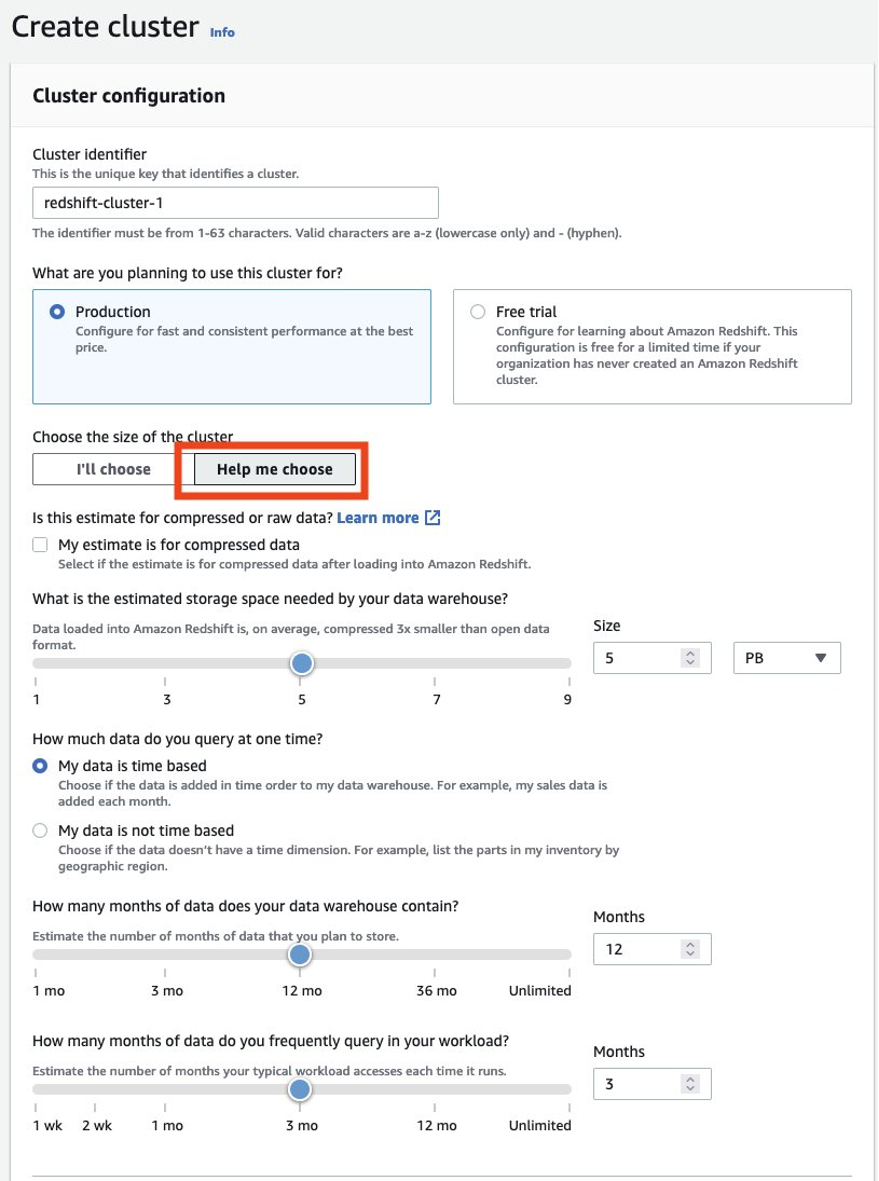
Du bør altid sikre dig, at du har den rigtige størrelse på din producentklynge for at få den ydeevne, du har brug for for at opfylde din SLA. Du kan udnytte størrelsesberegneren fra Amazon Redshift-konsollen for at få en anbefaling til producentklyngen baseret på størrelsen af dine data og forespørgselsegenskaber. Lede efter Hjælp mig med at vælge på konsollen i AWS-regioner, der understøtter RA3-nodetyper for at bruge denne størrelsesberegner. Bemærk, at dette kun er en indledende anbefaling for at komme i gang, og du bør teste at køre hele din arbejdsbyrde på den oprindelige størrelsesklynge og elastisk tilpasse klyngens størrelse op og ned i overensstemmelse hermed for at få den bedste prisydelse.
Størrelse og opsætning af indledende forbrugerklynge
Du bør altid dimensionere din forbrugerklynge baseret på dine computerbehov. En måde at komme i gang på er at følge den generiske klyngestørrelsesguide svarende til producentklyngen ovenfor.
Konfigurer Amazon Redshift-datadeling
Opsæt datadeling fra producent til forbruger, når du har både producent- og forbrugerklyngeopsætningen. Henvis til dette indlæg for vejledning i, hvordan du opsætter datadeling.
Test kun arbejdsbyrde for forbrugere på den oprindelige forbrugerklynge
Test kun arbejdsbelastning for forbrugere på den nye indledende forbrugerklynge. Dette kan gøres ved at pege forbrugerapplikationer, for eksempel ETL-værktøjer, BI-applikationer og SQL-klienter, til den nye forbrugerklynge og køre arbejdsbyrden igen for at evaluere ydeevnen i forhold til dine krav.
Test kun arbejdsbelastning for forbrugere på forskellige forbrugerklyngekonfigurationer
Hvis den oprindelige størrelse forbrugerklynge opfylder eller overstiger dine arbejdsbyrdes ydeevnekrav, så kan du enten fortsætte med at bruge denne klyngekonfiguration, eller du kan teste på mindre konfigurationer for at se, om du kan reducere omkostningerne yderligere og stadig få den ydeevne, du har brug for.
På den anden side, hvis den oprindelige størrelse forbrugerklynge ikke opfylder dine arbejdsbyrdes ydeevnekrav, så kan du yderligere teste større konfigurationer for at få den konfiguration, der opfylder din SLA.
Som en tommelfingerregel skal du øge forbrugerklyngen med 2x den oprindelige klyngekonfiguration trinvist, indtil den opfylder dine arbejdsbelastningskrav.
Når du har planlagt, hvilken konfiguration du vil teste, skal du bruge elastisk størrelse til at ændre størrelsen på den oprindelige klynge til målklyngekonfigurationen. Når den elastiske størrelsesændring er gennemført, skal du udføre den samme arbejdsbelastningstest og evaluere ydeevnen i forhold til din SLA. Vælg den konfiguration, der opfylder dit priseffektivitetsmål.
Test kun arbejdsbyrde for producent på forskellige producentklyngekonfigurationer
Når du flytter din forbrugerarbejdsbyrde til forbrugerklyngen med den optimale prisydelse, kan der være mulighed for at reducere computerressourcen hos producenten for at spare på omkostningerne.
For at opnå dette kan du kun køre producentens arbejdsbyrde igen på 1/2x af den oprindelige producentstørrelse og evaluere arbejdsbelastningens ydeevne. Ændring af klyngens størrelse op og ned i overensstemmelse hermed afhænger af resultatet, og derefter vælger du den mindste producentkonfiguration, der opfylder dine arbejdsbyrdes ydeevnekrav.
Reevaluer efter en fuld arbejdsbyrde over tid
Efterhånden som Amazon Redshift fortsætter med at udvikle sig, og der er løbende udgivelser til forbedring af ydeevne og skalerbarhed, vil ydeevnen for datadeling fortsætte med at blive bedre. Desuden kan adskillige variabler påvirke ydeevnen af datadelingsforespørgsler. Følgende er blot nogle eksempler:
- Indtagelseshastighed og mængden af data ændres
- Forespørgselsmønster og karakteristik
- Ændringer i arbejdsbyrden
- samtidighed
- Vedligeholdelsesaktiviteter, for eksempel vakuum, analyser og ATO
Dette er grunden til, at du lejlighedsvis skal revurdere producent- og forbrugerklyngestørrelsen ved hjælp af strategien ovenfor, især efter en fuld arbejdsbelastningsimplementering, for at opnå den nye bedste prisydeevne fra din klynges konfiguration.
Automatiserede dimensioneringsløsninger
Hvis dit miljø involverede mere kompleks arkitektur, for eksempel med flere værktøjer eller applikationer (BI, indtagelse eller streaming, ETL, datavidenskab), så er det muligvis ikke muligt at bruge den manuelle metode fra den generiske vejledning ovenfor. I stedet kan du udnytte løsningerne i dette afsnit til automatisk at afspille arbejdsbyrden fra din produktionsklynge på testforbruger- og producentklyngerne for at evaluere ydeevnen.
Simpelt Replay-værktøj vil blive udnyttet som den automatiserede løsning til at guide dig gennem processen med at få den rigtige producent- og forbrugerklyngerstørrelse til den bedste prisydelse.
Simple Replay er et værktøj til at udføre en what-if-analyse og evaluere, hvordan din arbejdsbyrde klarer sig i forskellige scenarier. For eksempel kan du bruge værktøjet til at benchmarke din faktiske arbejdsbyrde på en ny instanstype som RA3, evaluere en ny funktion eller vurdere forskellige klyngekonfigurationer. Det inkluderer også forbedret understøttelse af genafspilning af dataindtagelse og eksport af pipelines med COPY- og UNLOAD-sætninger. For at komme i gang og afspille dine arbejdsbelastninger skal du downloade værktøjet fra Amazon Redshift GitHub-depot.
Her gennemgår vi trinene til at udtrække dine arbejdsbelastningslogfiler fra kildeproduktionsklyngen og afspille dem i et isoleret miljø. Dette lader dig udføre en direkte sammenligning mellem disse Amazon Redshift-klynger problemfrit og vælge den klyngekonfiguration, der bedst opfylder dit prispræstationsmål.
Følgende diagram viser løsningsarkitekturen.
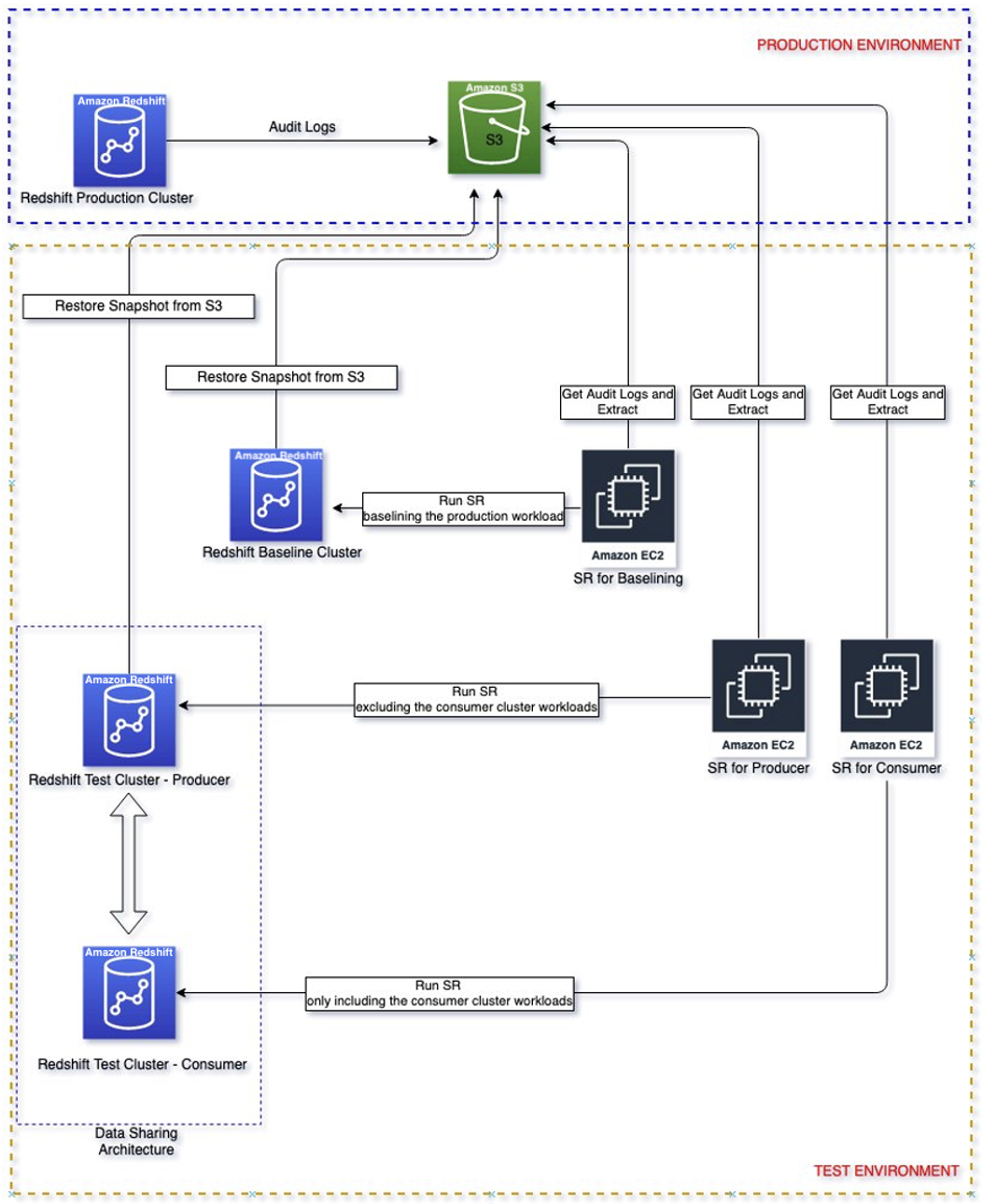
Gennemgang af løsning
Følg disse trin for at gennemgå løsningen for at tilpasse dine forbruger- og producentklynger.
Dimensionér din produktionsklynge
Du bør altid sørge for at dimensionere din eksisterende produktionsklynge korrekt for at få den ydeevne, du har brug for for at opfylde dine arbejdsbyrdekrav. Du kan udnytte størrelsesberegneren fra Amazon Redshift-konsollen til at få en anbefaling om produktionsklyngen baseret på størrelsen af dine data og forespørgselsegenskaber. Lede efter Hjælp mig med at vælge på konsollen i AWS-regioner, der understøtter RA3-nodetyper for at bruge denne størrelsesberegner. Bemærk, at dette kun er en indledende anbefaling for at komme i gang. Du bør teste at køre hele din arbejdsbyrde på den oprindelige størrelse klynge og elastisk tilpasse klyngen op og ned i overensstemmelse hermed for at få den bedste prisydelse.
Identificer den arbejdsbyrde, der skal isoleres
Du kan have forskellige arbejdsbelastninger kørende på din oprindelige klynge, men det første skridt er at identificere den mest kritiske arbejdsbyrde for virksomheden, som vi ønsker at isolere. Det skyldes, at vi vil sikre os, at den nye arkitektur kan opfylde dine krav til arbejdsbelastning. Det her indlæg er en god reference til en brugssag til isolering af datadeling, der kan hjælpe dig med at beslutte, hvilken arbejdsbyrde der kan isoleres.
Opsætning af simpel genafspilning
Når du kender din kritiske arbejdsbyrde, skal du aktivere revisionslogning i din produktionsklynge, hvor den kritiske arbejdsbyrde, der er identificeret ovenfor, kører for at fange forespørgselsaktiviteter og gemme dem Amazon Simple Storage Service (Amazon S3). Bemærk, at det kan tage op til tre timer for revisionsloggene at blive leveret til Amazon S3. Når revisionsloggen er tilgængelig, fortsæt til opsætning Simple Replay og så ekstrakt den kritiske arbejdsbyrde fra revisionsloggen. Bemærk, at start_time og end_time kunne bruges som parametre til at filtrere den kritiske arbejdsbyrde fra, hvis disse arbejdsbelastninger kører i bestemte tidsperioder, for eksempel 9 til 11. Ellers vil det udtrække alle de loggede aktiviteter.
Grundlæggende arbejdsbyrde
Opret en basislinjeklynge med samme konfiguration som producentklyngen ved at gendanne fra produktionsøjebliksbilledet. Formålet med at starte med den samme konfiguration er at baseline ydeevnen med et isoleret miljø.
Når basislinjeklyngen er tilgængelig, replay den udtrukne arbejdsbyrde i basisklyngen. Outputtet fra denne replay vil være den baseline, der bruges til at sammenligne med efterfølgende replays på forskellige forbrugerkonfigurationer.
Opsæt indledende producent- og forbrugertestklynger
Opret en producentklynge med den samme produktionsklyngekonfiguration ved at gendanne fra produktionsøjebliksbilledet. Opret en forbrugerklynge med den anbefalede initiale forbrugerstørrelse fra den tidligere vejledning. Ydermere opsætte datadeling mellem producent og forbruger.
Gentag arbejdsbyrden på den oprindelige producent og forbruger
Replay kun producentens arbejdsbyrde på den oprindelige størrelse producentklynge. Dette kan opnås ved at bruge filterparameteren "Ekskluder" for at ekskludere forbrugerforespørgsler, for eksempel den bruger, der kører forbrugerforespørgsler.
Replay arbejdsbyrden kun for forbrugeren på forbrugerklyngen i den oprindelige størrelse. Dette kan opnås ved at bruge filterparameteren "Inkluder" for at ekskludere forbrugerforespørgsler, for eksempel den bruger, der kører forbrugerforespørgsler.
Evaluer ydeevnen af disse gentagelser i forhold til basislinje- og arbejdsbelastningens ydeevnekrav.
Gentag forbrugerens arbejdsbyrde på forskellige konfigurationer
Hvis den oprindelige størrelse forbrugerklynge opfylder eller overstiger dine arbejdsbyrdes ydeevnekrav, kan du enten bruge denne klyngekonfiguration, eller du kan følge disse trin for at teste på mindre konfigurationer for at se, om du kan reducere omkostningerne yderligere og stadig få den ydeevne, du har brug for.
Sammenlign de første resultater for forbrugernes ydeevne med dine krav til arbejdsbelastning:
- Hvis resultatet overstiger dine arbejdsbyrdes ydeevnekrav, kan du reducere størrelsen på forbrugerklyngen trinvist, begyndende med 1/2x, prøve gentagelsen og evaluere ydeevnen, og derefter ændre størrelsen op eller ned i overensstemmelse hermed baseret på resultatet, indtil den opfylder din arbejdsbyrde krav. Formålet er at få et sødt sted, hvor du er komfortabel med ydelseskravene og får den lavest mulige pris.
- Hvis resultatet ikke opfylder dine krav til arbejdsbelastning, kan du øge klyngens størrelse trinvist, begyndende med 2x den oprindelige størrelse, prøve afspilningen igen og evaluere ydeevnen, indtil den opfylder dine arbejdsbyrdes ydeevnekrav.
Afspil producentens arbejdsbyrde på forskellige konfigurationer
Når du deler dine arbejdsbyrder ud til forbrugerklynger, bør belastningen på producentklyngen reduceres, og du bør evaluere din producentklynges arbejdsbyrdeydelse for at søge muligheden for at reducere for at spare på omkostningerne.
Trinene ligner forbrugerreplay. Elastisk tilpas størrelsen på producentklyngen trinvist, startende med 1/2x den oprindelige størrelse, afspil kun producentens arbejdsbyrde og evaluer ydeevnen, og tilpas derefter størrelsen yderligere op eller ned, indtil den opfylder dine arbejdsbyrdes ydeevnekrav. Formålet er at få et godt sted, hvor du er fortrolig med arbejdsbyrdens ydeevnekrav og få den lavest mulige pris. Når du har den ønskede producentklyngekonfiguration, skal du prøve at afspille forbrugerarbejdsbelastninger på forbrugerklyngen igen for at sikre, at ydeevnen ikke blev påvirket af ændringer i producentklyngekonfigurationen. Endelig bør du afspille både producent- og forbrugerarbejdsbelastninger samtidigt for at sikre, at ydeevnen opnås i et scenarie med fuld arbejdsbelastning.
Reevaluer efter en fuld arbejdsbyrde over tid
I lighed med den generiske vejledning bør du lejlighedsvis revurdere producent- og forbrugerklyngernes størrelse ved hjælp af den tidligere strategi, især efter fuld implementering af arbejdsbyrden for at opnå den nye bedste prisydelse fra din klynges konfiguration.
Ryd op
Kørsel af disse størrelsestests på din AWS-konto kan have nogle omkostningsimplikationer, fordi det leverer nye Amazon Redshift-klynger, som kan blive opkrævet som on-demand-forekomster, hvis du ikke har reserverede forekomster. Når du er færdig med dine evalueringer, anbefaler vi at slette Amazon Redshift-klyngerne for at spare på omkostningerne. Vi anbefaler også at sætte dine klynger på pause, når de ikke er i brug.
Anvendelse af Amazon Redshift og bedste praksis for datadeling
Korrekt dimensionering af både dine producent- og forbrugerklynger vil give dig en god start for at få den bedste prisydelse fra din Amazon Redshift-implementering. Størrelse er dog ikke den eneste faktor, der kan maksimere din ydeevne. I dette tilfælde er det lige så vigtigt at forstå og følge bedste praksis.
Generel Amazon Redshift-ydeevneindstilling bedste praksis gælder for implementering af datadeling. Sørg for, at din implementering følger disse bedste praksis.
Der er adskillige datadelingsspecifikke bedste praksisser, som du bør følge for at sikre, at du maksimerer ydeevnen. Henvis til dette indlæg for flere detaljer.
Resumé
Der er ingen ensartet anbefaling om producent- og forbrugerklyngestørrelser. Det varierer efter arbejdsbelastninger og din præstations-SLA. Formålet med dette indlæg er at give dig vejledning til, hvordan du kan evaluere din specifikke datadelings arbejdsbelastningsydelse for at bestemme både forbruger- og producentklyngestørrelser for at få den bedste prisydelse. Overvej at teste dine arbejdsbelastninger på producent og forbruger ved hjælp af simpel genafspilning, før du tager det i produktion for at få den bedste prisydelse.
Om forfatterne
 BP Yau er Sr Product Manager hos AWS. Han brænder for at hjælpe kunder med at udvikle big data-løsninger til at behandle data i stor skala. Før AWS hjalp han Amazon.com Supply Chain Optimization Technologies med at migrere sit Oracle-datavarehus til Amazon Redshift og bygge sin næste generation af big data-analyseplatform ved hjælp af AWS-teknologier.
BP Yau er Sr Product Manager hos AWS. Han brænder for at hjælpe kunder med at udvikle big data-løsninger til at behandle data i stor skala. Før AWS hjalp han Amazon.com Supply Chain Optimization Technologies med at migrere sit Oracle-datavarehus til Amazon Redshift og bygge sin næste generation af big data-analyseplatform ved hjælp af AWS-teknologier.
 Sidhanth Muralidhar er Principal Technical Account Manager hos AWS. Han arbejder med store virksomhedskunder, der kører deres arbejdsopgaver på AWS. Han brænder for at arbejde med kunder og hjælpe dem med at udarbejde arbejdsbyrder for omkostninger, pålidelighed, ydeevne og operationel ekspertise i stor skala i deres cloud-rejse. Han har også en stor interesse for Data Analytics.
Sidhanth Muralidhar er Principal Technical Account Manager hos AWS. Han arbejder med store virksomhedskunder, der kører deres arbejdsopgaver på AWS. Han brænder for at arbejde med kunder og hjælpe dem med at udarbejde arbejdsbyrder for omkostninger, pålidelighed, ydeevne og operationel ekspertise i stor skala i deres cloud-rejse. Han har også en stor interesse for Data Analytics.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- Om
- over
- derfor
- Konto
- Konti
- opnå
- opnået
- tværs
- aktiviteter
- tilføjet
- Vedtagelsen
- Efter
- mod
- Alle
- tillader
- altid
- Amazon
- Amazon.com
- beløb
- analyse
- analytics
- analysere
- ,
- En anden
- anvendelig
- applikationer
- tilgang
- arkitektur
- revision
- Automatiseret
- automatisk
- til rådighed
- AWS
- baseret
- Baseline
- fordi
- før
- benchmark
- BEDSTE
- bedste praksis
- Bedre
- mellem
- Big
- Big data
- bygge
- virksomhed
- fange
- tilfælde
- tilfælde
- vis
- kæde
- Ændringer
- karakteristisk
- karakteristika
- opladet
- kunder
- Cloud
- Cluster
- KOM
- behagelig
- Fælles
- sammenligne
- sammenligning
- fuldføre
- Afsluttet
- komplekse
- kompleksitet
- Compute
- udførelse
- Konfiguration
- Overvej
- konsekvent
- Konsol
- forbruger
- fortsæt
- fortsætter
- kontinuerlig
- Koste
- Omkostninger
- kunne
- skabe
- kritisk
- Kunder
- data
- Dataanalyse
- datalogi
- datadeling
- leveret
- afhænger
- implementering
- detaljer
- Bestem
- forskellige
- direkte
- Dont
- ned
- downloade
- i løbet af
- nemt
- enten
- muliggør
- forbedret
- Enterprise
- Miljø
- lige
- især
- Ether (ETH)
- evaluere
- evalueringer
- udviklende
- eksempel
- eksempler
- overstiger
- Excellence
- eksisterende
- eksport
- ekstrakt
- mislykkes
- FAST
- gennemførlig
- Feature
- filtrere
- Endelig
- Fornavn
- Fleksibilitet
- følger
- efter
- følger
- fra
- fuld
- fundamentalt
- yderligere
- Endvidere
- Gevinst
- generelt
- generation
- få
- få
- GitHub
- Giv
- Go
- godt
- vejlede
- hjælpe
- hjulpet
- hjælpe
- HOURS
- Hvordan
- How To
- Men
- HTTPS
- identificeret
- identificere
- KIMOs Succeshistorier
- påvirket
- implementeret
- implikationer
- vigtigt
- forbedring
- in
- omfatter
- Forøg
- initial
- i første omgang
- instans
- i stedet
- interesse
- involverede
- isolerede
- isolation
- IT
- rejse
- Keen
- Kend
- stor
- større
- lanceret
- Lets
- Leverage
- leve
- belastning
- Se
- vedligeholdelse
- lave
- leder
- manuel
- Maksimer
- Mød
- opfylder
- metode
- måske
- migrere
- minimum
- model
- mere
- mest
- bevæge sig
- bevægelse
- flere
- Behov
- behøve
- behov
- Ny
- næste
- node
- talrige
- lejlighed
- Ombord
- ONE
- operationelle
- Opportunity
- optimering
- optimal
- oracle
- original
- Andet
- Ellers
- parameter
- parametre
- lidenskabelige
- Mønster
- udføre
- ydeevne
- udfører
- perioder
- fly
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- mulig
- Indlæg
- praksis
- tidligere
- pris
- Main
- behandle
- producent
- Produkt
- produktchef
- produktion
- korrekt
- give
- giver
- formål
- Spørgsmål
- Sats
- anbefaler
- Anbefaling
- anbefales
- reducere
- Reduceret
- regioner
- Udgivelser
- pålidelighed
- Krav
- forbeholdes
- ressource
- genoprette
- resultere
- Resultater
- Herske
- Kør
- kører
- samme
- Gem
- Skalerbarhed
- skalerbar
- Scale
- scenarier
- Videnskab
- problemfrit
- Sektion
- sikker
- sikkert
- Søg
- tjeneste
- setup
- Del
- deling
- bør
- Vis
- Shows
- lignende
- Simpelt
- Størrelse
- størrelser
- mindre
- Snapshot
- løsninger
- Løsninger
- nogle
- Kilde
- specifikke
- delt
- Spot
- standard
- starte
- påbegyndt
- Starter
- udsagn
- Trin
- Steps
- Stadig
- opbevaring
- butik
- Strategi
- streaming
- efterfølgende
- forsyne
- forsyningskæde
- Supply Chain Optimering
- support
- sød
- Tag
- mål
- Teknisk
- Teknologier
- prøve
- Test
- tests
- The Source
- deres
- tre
- Gennem
- tid
- til
- værktøj
- værktøjer
- typer
- forståelse
- brug
- brug tilfælde
- Bruger
- Vacuum
- Hvad
- som
- WHO
- vilje
- uden
- arbejder
- virker
- Din
- zephyrnet