Introduktion
Vi har set nogle fancy termer for AI og deep learning, såsom præ-trænede modeller, transfer learning osv. Lad mig uddanne dig med en meget brugt teknologi og en af de vigtigste og mest effektive: Transfer learning med YOLOv5.
You Only Look Once, eller YOLO er en af de mest brugte deep learning-baserede objektidentifikationsmetoder. Ved at bruge et brugerdefineret datasæt vil denne artikel vise dig, hvordan du træner en af dens seneste variationer, YOLOv5.
Læringsmål
- Denne artikel vil hovedsageligt fokusere på træning af YOLOv5-modellen i en brugerdefineret datasætimplementering.
- Vi vil se, hvad præ-trænede modeller er, og se, hvad transfer learning er.
- Vi vil forstå, hvad YOLOv5 er, og hvorfor vi bruger version 5 af YOLO.
Så lad os komme i gang med processen uden at spilde tid
Indholdsfortegnelse
- Foruddannede modeller
- Overfør læring
- Hvad og hvorfor YOLOv5?
- Trin involveret i overførselslæring
- Implementering
- Nogle udfordringer, du kan møde
- Konklusion
Foruddannede modeller
Du har måske hørt dataforskere bruge udtrykket "foruddannet model" bredt. Efter at have forklaret, hvad en deep learning model/netværk gør, vil jeg forklare begrebet. En deep learning-model er en model, der indeholder forskellige lag stablet sammen for at tjene et ensomt formål, såsom klassificering, detektion osv. Deep learning-netværk lærer ved at opdage komplicerede strukturer i de data, der sendes til dem og gemme vægtene i en fil, som bruges senere til at udføre lignende opgaver. Foruddannede modeller er allerede trænede Deep Learning-modeller. Hvad det betyder er, at de allerede er trænet i et enormt datasæt, der indeholder millioner af billeder.
Her er, hvordan TensorFlow webstedet definerer præ-trænede modeller: En præ-trænet model er et gemt netværk, der tidligere blev trænet på et stort datasæt, typisk på en storstilet billedklassificeringsopgave.
Nogle meget optimerede og ekstraordinært effektive fortrænede modeller er tilgængelige på internettet. Forskellige modeller bruges til at udføre forskellige opgaver. Nogle af de fortrænede modeller er VGG-16, VGG-19, YOLOv5, YOLOv3 og ResNet 50.
Hvilken model du skal bruge afhænger af den opgave du vil udføre. Hvis jeg f.eks. vil udføre en objektdetektion opgave, vil jeg bruge YOLOv5-modellen.
Overfør læring
Overfør læring er den vigtigste teknik, der letter opgaven for en dataforsker. At træne en model er en heftig og tidskrævende opgave; hvis en model trænes fra bunden, giver det normalt ikke særlig gode resultater. Selvom vi træner en model, der ligner en fortrænet model, vil den ikke præstere så effektivt, og det kan tage uger for en model at træne. I stedet kan vi bruge de fortrænede modeller og bruge de allerede lærte vægte ved at træne dem på et brugerdefineret datasæt til at udføre en lignende opgave. Disse modeller er yderst effektive og raffinerede med hensyn til arkitektur og ydeevne, og de har nået deres vej til toppen ved at præstere bedre i forskellige konkurrencer. Disse modeller er trænet på meget store mængder data, hvilket gør dem mere forskelligartede i viden.
Så transfer learning betyder grundlæggende at overføre viden opnået ved at træne modellen på tidligere data for at hjælpe modellen med at lære bedre og hurtigere at udføre en anden, men lignende opgave.
For eksempel ved at bruge en YOLOv5 til objektdetektion, men objektet er noget andet end objektets tidligere brugte data.
Hvad og hvorfor YOLOv5?
YOLOv5 er en præ-trænet model, som står for, at du kun ser, når version 5 er brugt til objektdetektering i realtid og har vist sig at være yderst effektiv med hensyn til nøjagtighed og slutningstid. Der er andre versioner af YOLO, men som man ville forudsige, klarer YOLOv5 sig bedre end andre versioner. YOLOv5 er hurtig og nem at bruge. Det er baseret på PyTorch frameworket, som har et større community end Yolo v4 Darknet.
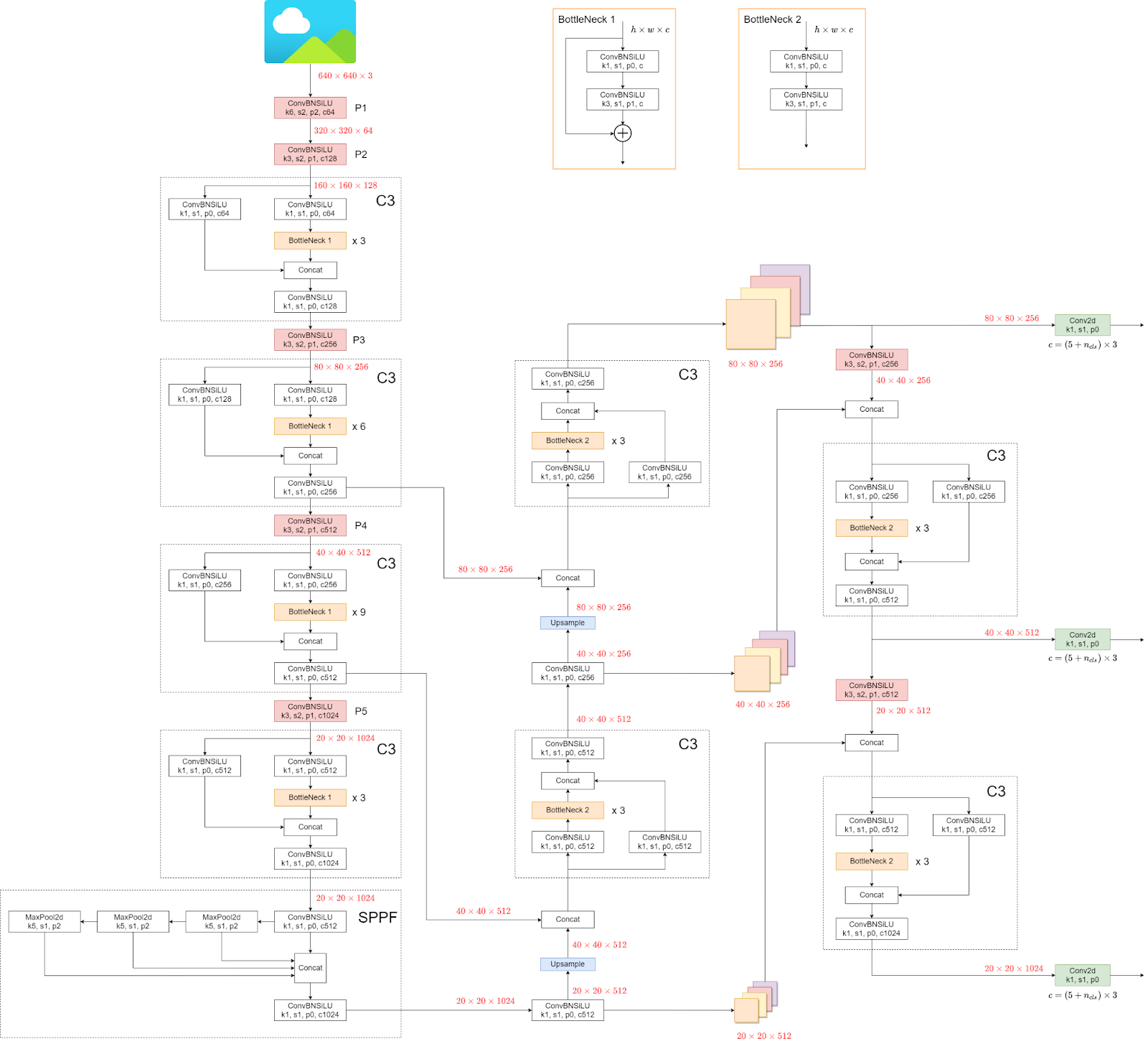
Vi vil nu se på arkitekturen af YOLOv5.
Strukturen kan se forvirrende ud, men det gør ikke noget, da vi ikke skal se på arkitekturen i stedet for direkte at bruge model og vægte.
I transfer learning bruger vi det brugerdefinerede datasæt, dvs. de data som modellen aldrig har set før ELLER de data som modellen ikke er trænet på. Da modellen allerede er trænet på et stort datasæt, har vi allerede vægtene. Vi kan nu træne modellen til en række epoker på de data, vi ønsker at arbejde videre med. Træning er påkrævet, da modellen har set dataene for første gang og vil kræve en vis viden for at kunne udføre opgaven.
Trin involveret i overførselslæring
Overførselslæring er en simpel proces, og vi kan gøre det med et par enkle trin:
- Forberedelse af data
- Det rigtige format til annoteringerne
- Skift et par lag, hvis du vil
- Gentræn modellen i et par gentagelser
- Valider/test
Dataforberedelse
Dataforberedelse kan være tidskrævende, hvis dine valgte data er lidt store. Dataforberedelse betyder at kommentere billederne, hvilket er en proces, hvor man mærker billederne ved at lave en boks rundt om objektet på billedet. Ved at gøre dette vil koordinaterne for det markerede objekt blive gemt i en fil, som derefter vil blive ført til modellen til træning. Der er et par hjemmesider, som f.eks makesense.ai , roboflow.com, som kan hjælpe dig med at mærke dataene.
Her er, hvordan du kan kommentere dataene for YOLOv5-modellen på makesense.ai.
1. Besøg https://www.makesense.ai/.
2. Klik på kom i gang nederst til højre på skærmen.
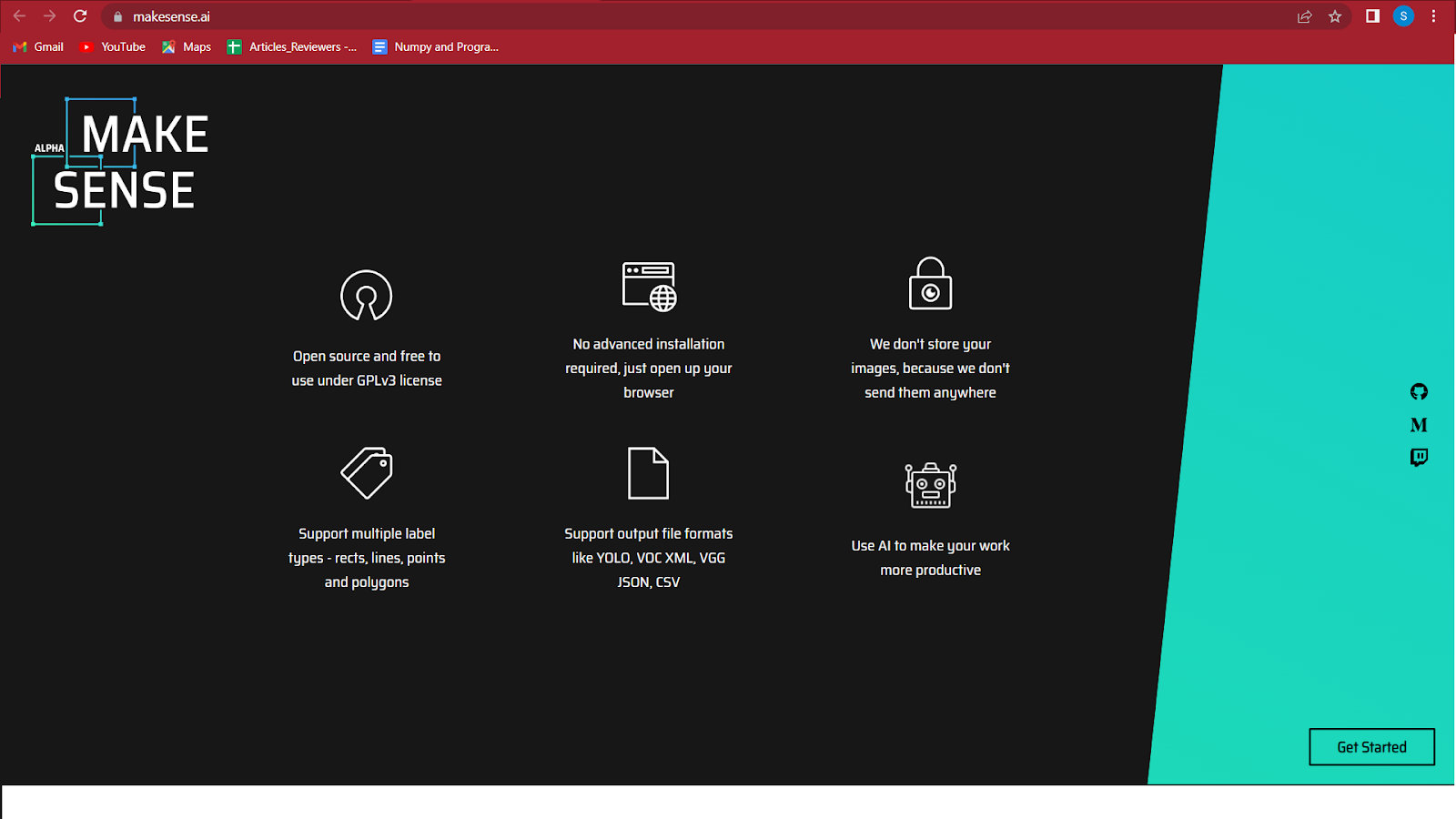
3. Vælg de billeder, du vil mærke ved at klikke på boksen, der er fremhævet i midten.
Indlæs de billeder, du vil kommentere, og klik på objektgenkendelse.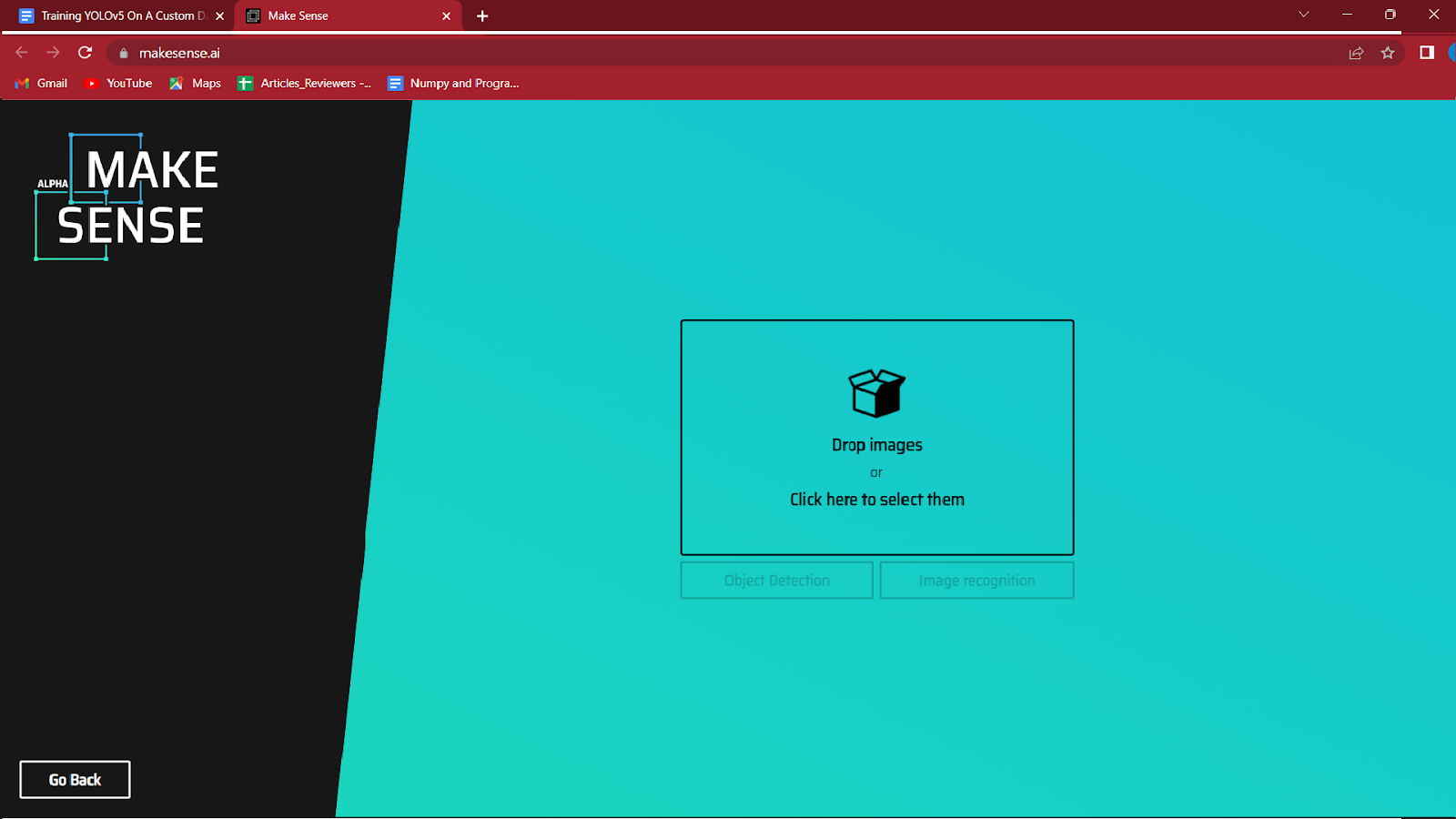
4. Efter indlæsning af billederne bliver du bedt om at oprette etiketter til dit datasæts forskellige klasser.
Jeg registrerer nummerplader på et køretøj, så den eneste etiket, jeg vil bruge, er "License Plate". Du kan lave flere etiketter ved blot at trykke på Enter ved at klikke på knappen '+' i venstre side af dialogboksen.
Når du har oprettet alle etiketterne, skal du klikke på start projekt.
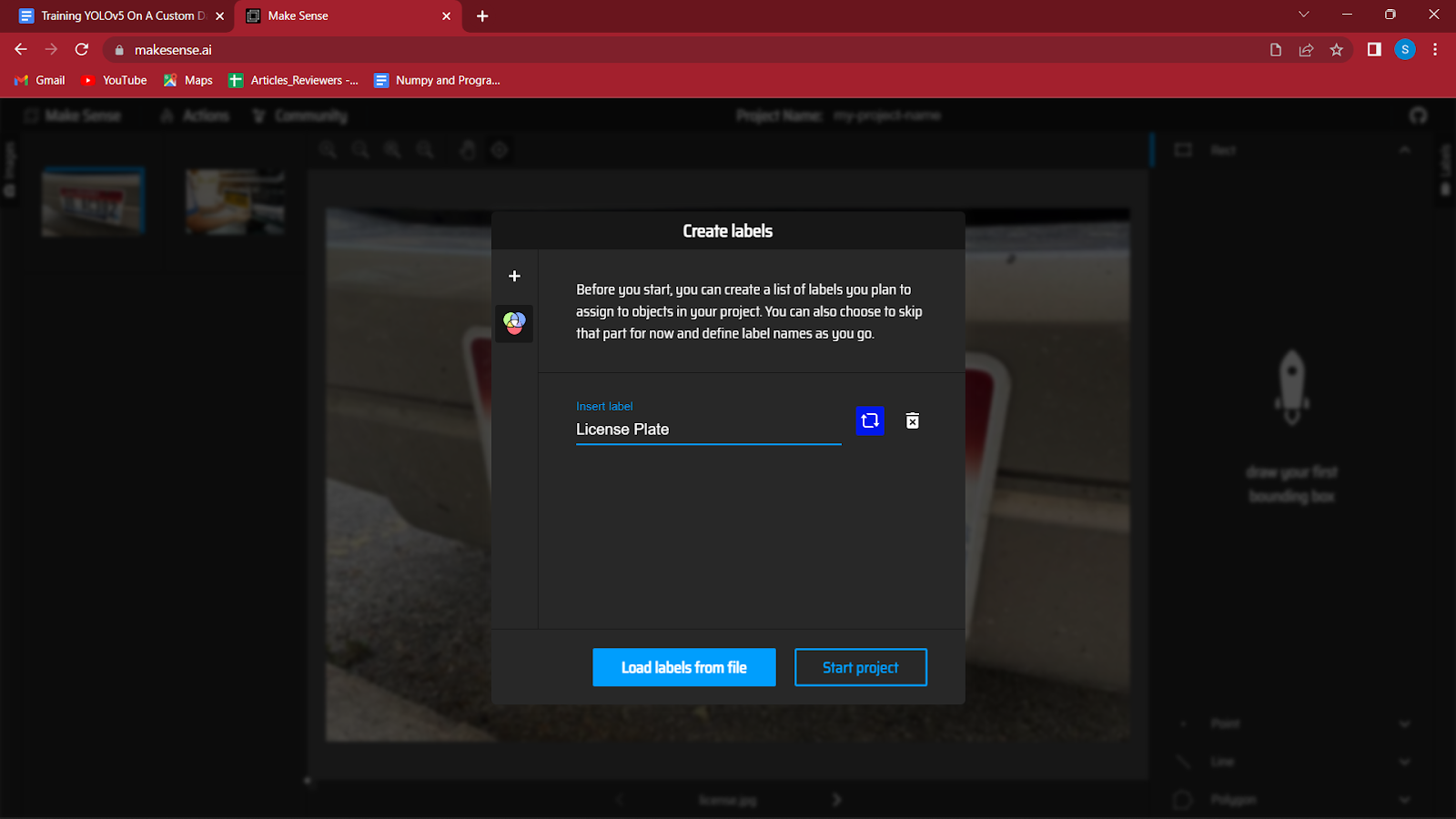
Hvis du er gået glip af nogen etiketter, kan du redigere dem senere ved at klikke på handlinger og derefter redigere etiketter.
5. Begynd at oprette en afgrænsningsramme omkring objektet i billedet. Denne øvelse kan være lidt sjov i starten, men med meget store data kan det være trættende.
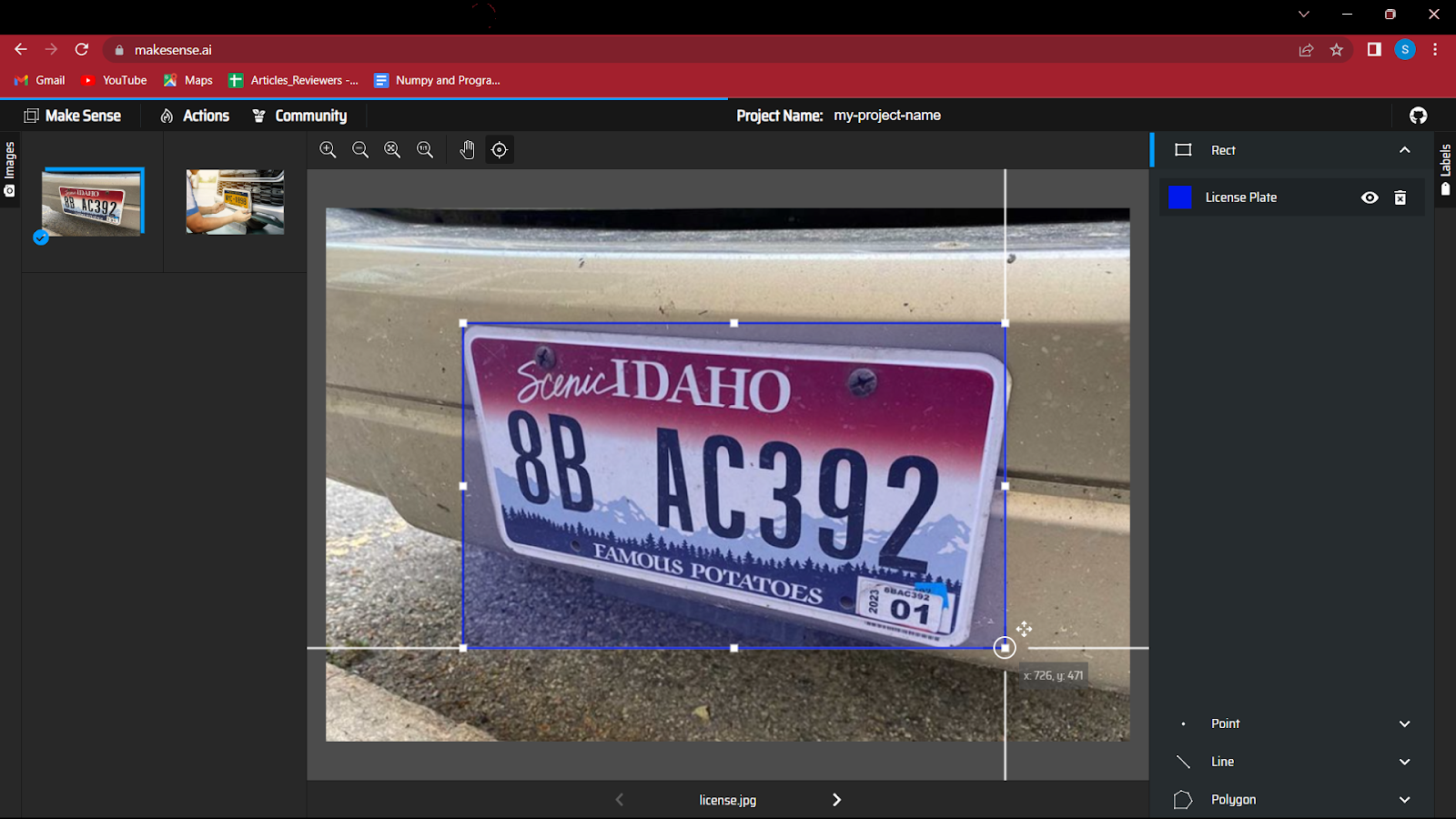
6. Efter at have annoteret alle billederne, skal du gemme filen, som vil indeholde koordinaterne for afgrænsningsfelter sammen med klassen.
Så du skal gå til handlingsknappen og klikke på eksport annoteringer, glem ikke at markere muligheden 'En zip-pakke, der indeholder filer i YOLO-format', da dette vil gemme filerne i det korrekte format som krævet i YOLO-modellen.
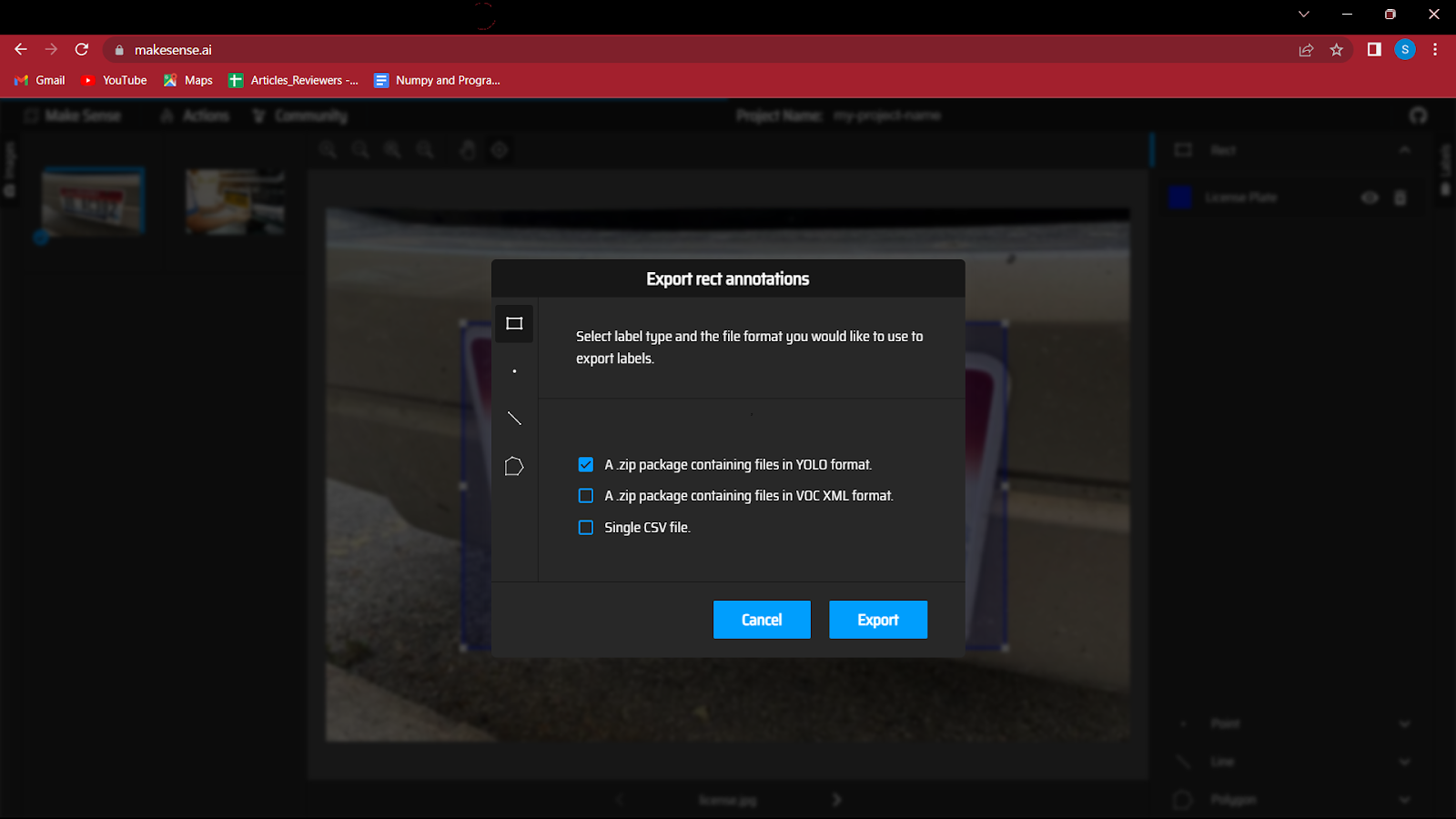
7. Dette er et vigtigt skridt, så følg det omhyggeligt.
Når du har alle filerne og billederne, skal du lave en mappe med et hvilket som helst navn. Klik på mappen og lav yderligere to mapper med navnebilleder og etiketter inde i mappen. Glem ikke at navngive mappen det samme som ovenfor, da modellen automatisk søger efter etiketter, efter du har fodret træningsstien i kommandoen.
For at give dig en idé om mappen, har jeg lavet en mappe ved navn 'CarsData' og i den mappe lavet to mapper - 'billeder' og 'etiketter'.
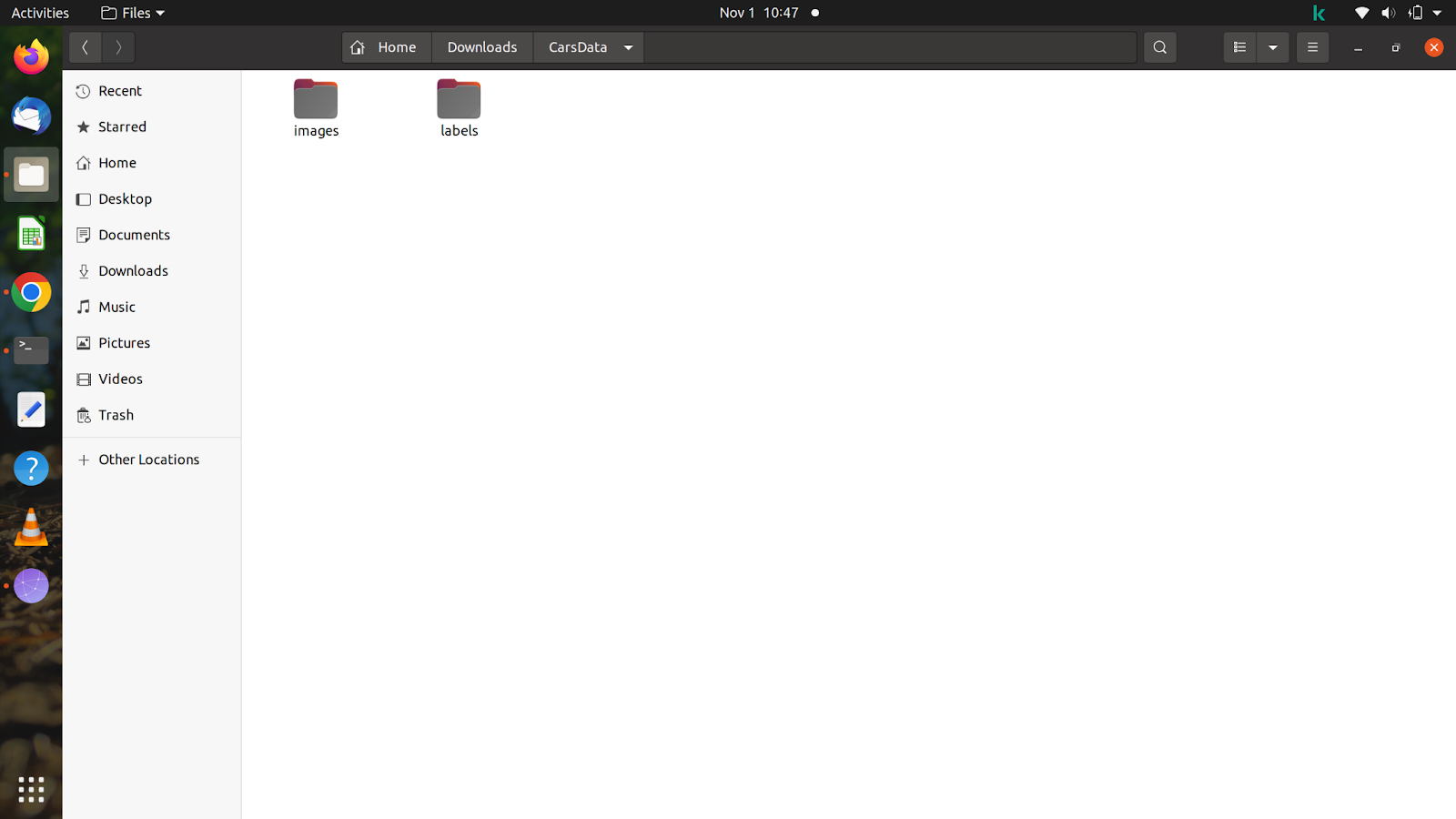
Inde i de to mapper skal du lave yderligere to mapper med navnet 'train' og 'val'. I billedmappen kan du opdele billederne efter din vilje, men du skal være forsigtig med at opdele etiketten, da etiketterne skal matche de billeder, du har opdelt
8. Lav nu en zip-fil af mappen og upload den til drevet, så vi kan bruge den i colab.
Implementering
Vi kommer nu til implementeringsdelen, som er meget enkel, men vanskelig. Hvis du ikke ved, hvilke filer der præcist skal ændres, vil du ikke være i stand til at træne modellen på det brugerdefinerede datasæt.
Så her er de koder, du bør følge for at træne YOLOv5-modellen på et brugerdefineret datasæt
Jeg anbefaler, at du bruger google colab til denne tutorial, da den også giver GPU, som giver hurtigere beregninger.
1. !git klon https://github.com/ultralytics/yolov5
Dette vil lave en kopi af YOLOv5-depotet, som er et GitHub-depot oprettet af ultralytics.
2. cd yolov5
Dette er en kommandolinje-shell-kommando, der bruges til at ændre den aktuelle arbejdsmappe til YOLOv5-mappen.
3. !pip install -r requirements.txt
Denne kommando vil installere alle de pakker og biblioteker, der bruges til at træne modellen.
4. !unzip '/content/drive/MyDrive/CarsData.zip'
Udpakning af mappen, der indeholder billeder og etiketter i google colab
Her kommer det vigtigste skridt...
Du har nu udført næsten alle trinene og skal skrive endnu en linje kode, der træner modellen, men før det skal du udføre et par trin mere og ændre nogle mapper for at give stien til dit brugerdefinerede datasæt og træne din model på disse data.
Her er, hvad du skal gøre.
Efter at have udført de 4 trin ovenfor, vil du have mappen yolov5 i din google colab. Gå til yolov5-mappen, og klik på 'data'-mappen. Nu vil du se en mappe med navnet 'coco128.yaml'.
Gå videre og download denne mappe.
Når mappen er downloadet, skal du foretage et par ændringer i den og uploade den tilbage til den samme mappe, som du downloadede den fra.
Lad os nu se på indholdet af den fil, vi har downloadet, og den vil se nogenlunde sådan ud.
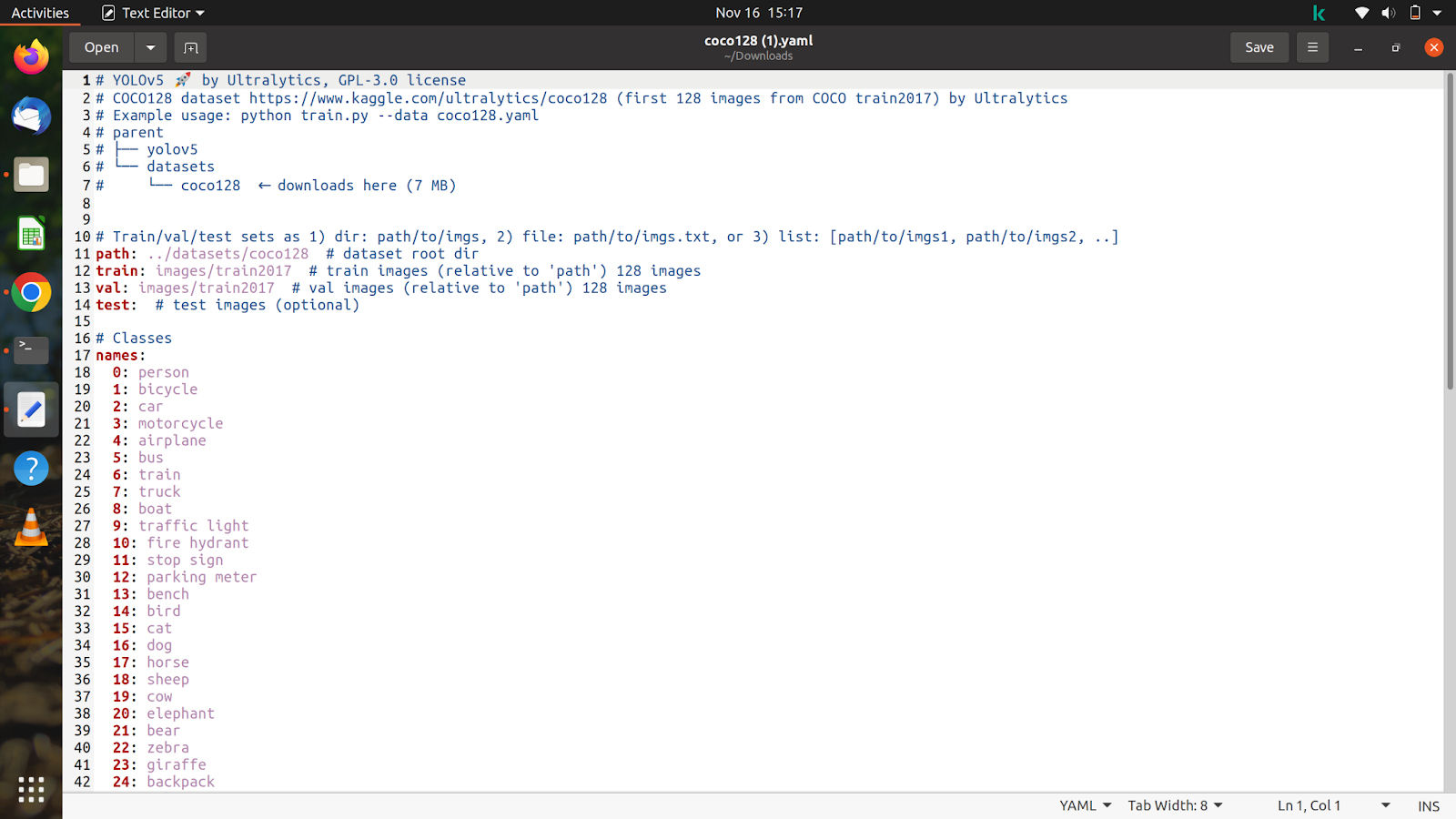
Vi vil tilpasse denne fil i henhold til vores datasæt og annoteringer.
Vi har allerede pakket datasættet ud på colab, så vi vil kopiere stien til vores tog og valideringsbilleder. Efter at have kopieret stien til togbillederne, som vil være i datasætmappen og ser sådan ud som denne '/content/yolov5/CarsData/images/train', indsæt den i filen coco128.yaml, som vi lige har downloadet.
Gør det samme med test- og valideringsbillederne.
Nu efter vi er færdige med dette, vil vi nævne antallet af klasser som 'nc: 1'. Antallet af klasser er i dette tilfælde kun 1. Vi vil så nævne navnet som vist på billedet nedenfor. Fjern alle de andre klasser og den kommenterede del, som ikke er nødvendig, hvorefter vores fil skulle se sådan ud.
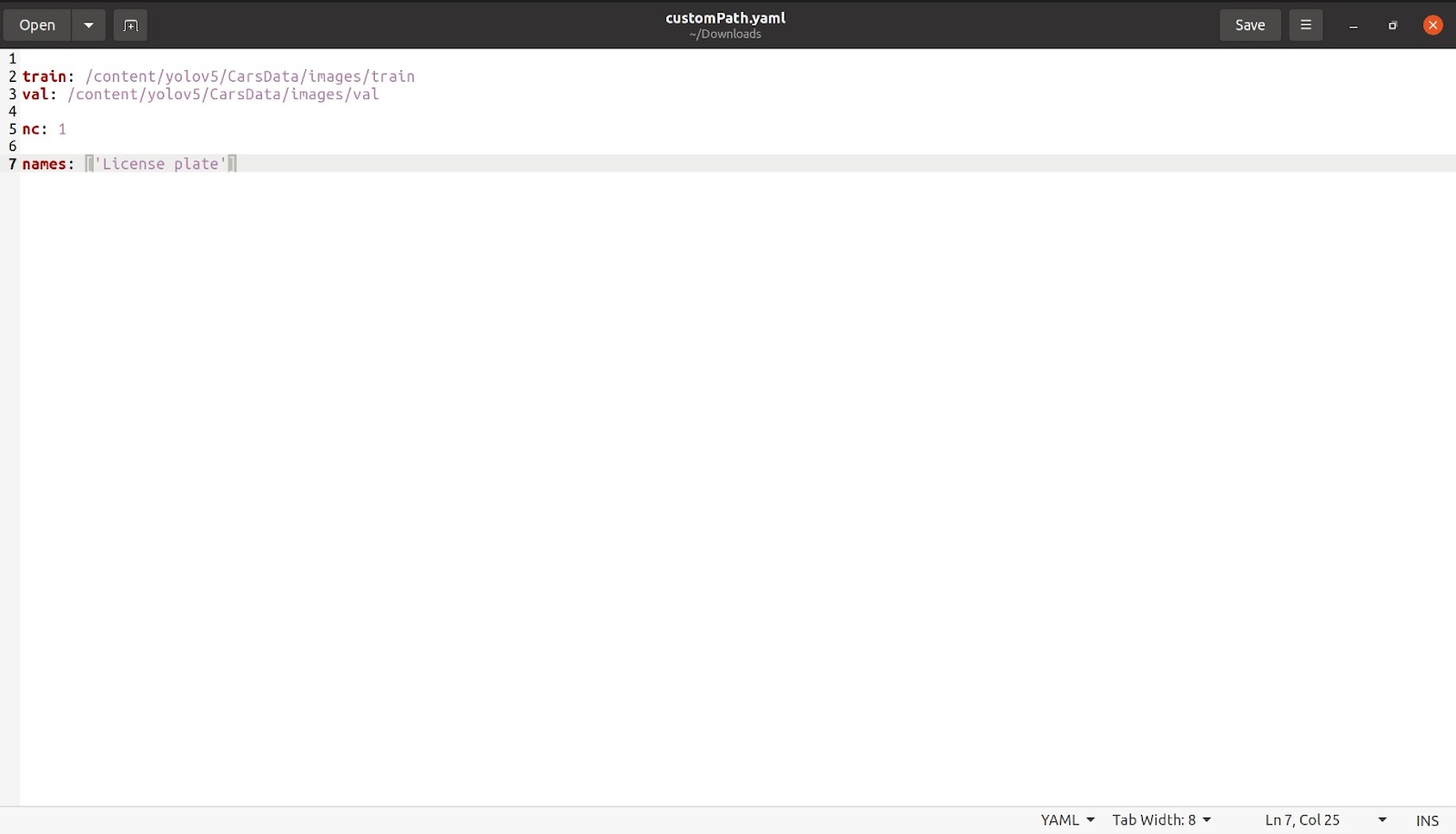
Gem denne fil med et hvilket som helst navn, du ønsker. Jeg har gemt filen med navnet customPath.yaml og uploader nu denne fil tilbage til colab samme sted, hvor coco128.yaml var.
Nu er vi færdige med redigeringsdelen og klar til at træne modellen.
Kør følgende kommando for at træne din model til nogle få interaktioner på dit brugerdefinerede datasæt.
Glem ikke at ændre navnet på den fil, du har uploadet ('customPath.yaml). Du kan også ændre antallet af epoker, du ønsker at træne modellen. I dette tilfælde vil jeg kun træne modellen i 3 epoker.
5. !python train.py –img 640 –batch 16 –epoker 10 –data /content/yolov5/customPath.yaml –weights yolov5s.pt
Husk stien, hvor du uploader mappen. Hvis stien ændres, vil kommandoerne slet ikke virke.
Når du har kørt denne kommando, bør din model begynde at træne, og du vil se noget lignende på din skærm.
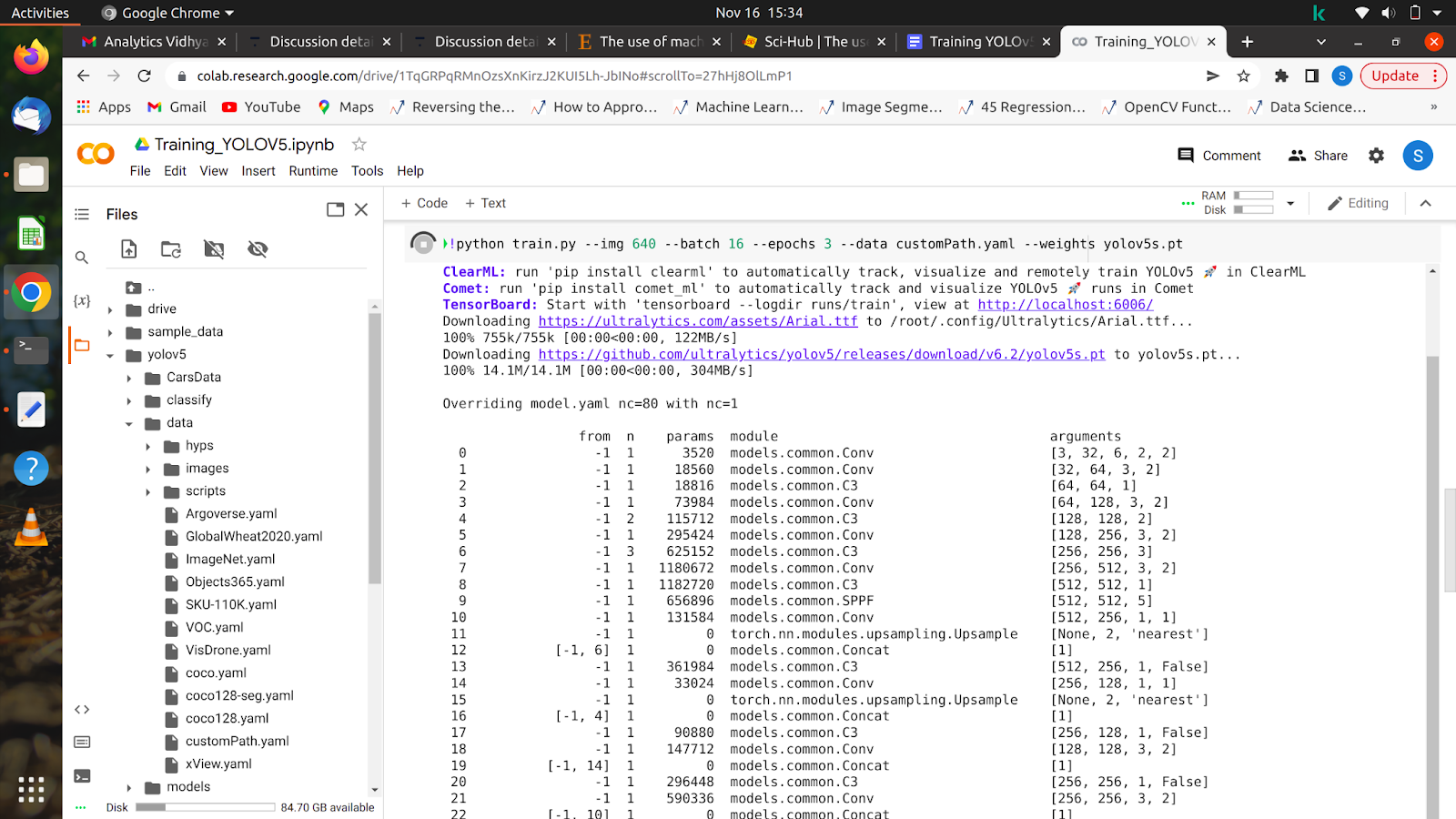
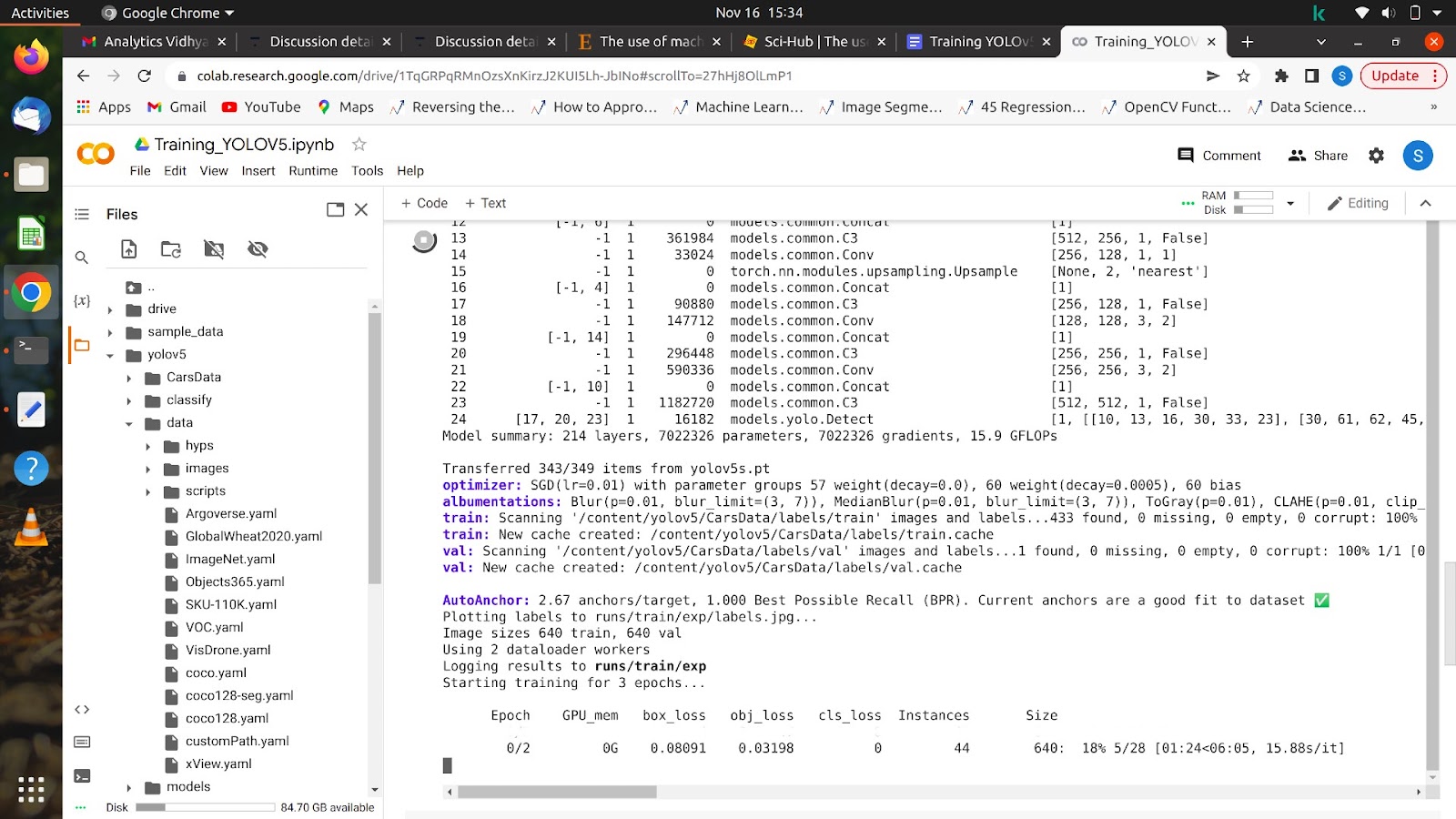
Når alle epoker er afsluttet, kan din model testes på ethvert billede.
Du kan gøre noget mere tilpasning i detect.py-filen om, hvad du vil gemme, og hvad du ikke kan lide, detekteringerne, hvor nummerpladerne er opdaget osv.
6. !python detect.py –weight /content/yolov5/runs/train/exp/weights/best.pt –source path_of_the_image
Du kan bruge denne kommando til at teste modellens forudsigelse på nogle af billederne.
Nogle udfordringer, du kan møde
Selvom ovenstående trin er korrekte, er der nogle problemer, du kan stå over for, hvis du ikke følger dem nøjagtigt.
- Forkert vej: Dette kan være hovedpine eller et problem. Hvis du er kommet ind på den forkerte vej et sted i træningen af billedet, kan det ikke være nemt at identificere, og du vil ikke være i stand til at træne modellen.
- Forkert format af etiketter: Dette er et udbredt problem, som folk står over for, mens de træner en YOLOv5. Modellen accepterer kun et format, hvor hvert billede har sin egen tekstfil med det ønskede format indeni. Ofte føres en XLS-formatfil eller en enkelt CSV-fil til netværket, hvilket resulterer i en fejl. Hvis du downloader dataene fra et sted, i stedet for at kommentere hvert eneste billede, kan der være et andet filformat, som etiketterne gemmes i. Her er en artikel til at konvertere XLS-formatet til YOLO-formatet. (link efter færdiggørelsen af artiklen).
- Ikke navngivning af filerne korrekt: Hvis filen ikke navngives korrekt, vil det igen føre til en fejl. Vær opmærksom på trinene, mens du navngiver mapperne, og undgå denne fejl.
Konklusion
I denne artikel lærte vi, hvad transferlæring er, og den fortrænede model. Vi lærte, hvornår og hvorfor man skal bruge YOLOv5-modellen, og hvordan man træner modellen på et brugerdefineret datasæt. Vi gennemgik hvert eneste trin, fra at forberede datasættet til at ændre stierne og til sidst at føre dem til netværket i implementeringen af teknikken, og vi forstod grundigt trinene. Vi kiggede også på almindelige problemer, som man møder, mens man træner en YOLOv5 og deres løsning. Jeg håber, at denne artikel hjalp dig med at træne din første YOLOv5 på et brugerdefineret datasæt, og at du kan lide artiklen.
Relaterede
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.analyticsvidhya.com/blog/2023/02/how-to-train-a-custom-dataset-with-yolov5/
- 1
- 10
- a
- I stand
- over
- accepterer
- Ifølge
- nøjagtighed
- aktioner
- Efter
- forude
- AI
- Alle
- allerede
- beløb
- ,
- arkitektur
- omkring
- artikel
- opmærksomhed
- automatisk
- til rådighed
- undgå
- tilbage
- baseret
- I bund og grund
- før
- jf. nedenstående
- Bedre
- Bit
- Bund
- Boks
- kasser
- .
- forsigtig
- omhyggeligt
- tilfælde
- CD
- center
- udfordringer
- lave om
- Ændringer
- skiftende
- kontrollere
- valgt
- klasse
- klasser
- klassificering
- kode
- Kom
- kommenteret
- Fælles
- samfund
- Afsluttet
- færdiggørelse
- kompliceret
- beregninger
- forvirrende
- indeholder
- indhold
- konvertere
- kopiering
- korrekt
- skabe
- oprettet
- Oprettelse af
- Nuværende
- skik
- tilpasning
- tilpasse
- Darknet
- data
- Dataforberedelse
- dataforsker
- dyb
- dyb læring
- definerer
- afhænger
- opdaget
- Detektion
- Dialog
- forskellige
- direkte
- mapper
- opdage
- forskelligartede
- gør
- Dont
- downloade
- køre
- hver
- Letter
- uddanne
- Effektiv
- effektivt
- effektiv
- Indtast
- indtastet
- epoker
- fejl
- etc.
- Endog
- Hver
- præcist nok
- eksempel
- Dyrke motion
- Forklar
- forklarede
- forklarer
- eksport
- ekstraordinært
- Ansigtet
- konfronteret
- FAST
- hurtigere
- Fed
- fodring
- få
- File (Felt)
- Filer
- Endelig
- Fornavn
- første gang
- Fokus
- følger
- efter
- format
- Framework
- fra
- sjovt
- få
- GitHub
- Giv
- Go
- gå
- godt
- GPU
- hoved
- hørt
- hjælpe
- hjulpet
- link.
- Fremhævet
- stærkt
- rammer
- håber
- Hvordan
- How To
- HTTPS
- kæmpe
- idé
- Identifikation
- identificere
- billede
- billeder
- implementering
- vigtigt
- in
- i første omgang
- installere
- i stedet
- interaktioner
- Internet
- involverede
- IT
- Kend
- viden
- etiket
- Etiketter
- stor
- storstilet
- større
- lag
- føre
- LÆR
- lærte
- læring
- biblioteker
- Licens
- Line (linje)
- LINK
- lastning
- Se
- kiggede
- UDSEENDE
- lavet
- lave
- Making
- markeret
- Match
- Matter
- max-bredde
- midler
- metoder
- måske
- millioner
- tankerne
- model
- modeller
- mere
- mest
- navn
- Som hedder
- navngivning
- Behov
- behov
- netværk
- net
- nummer
- objekt
- Objektdetektion
- ONE
- optimeret
- Option
- ordrer
- Andet
- egen
- pakke
- pakker
- del
- sti
- Betal
- Mennesker
- udføre
- ydeevne
- udfører
- udfører
- Place
- plato
- Platon Data Intelligence
- PlatoData
- forudsige
- forudsigelse
- forberede
- tidligere
- tidligere
- Problem
- problemer
- behandle
- projekt
- gennemprøvet
- giver
- formål
- pytorch
- klar
- realtid
- nylige
- anbefaler
- raffinerede
- Fjern
- Repository
- kræver
- påkrævet
- Krav
- resulterer
- Resultater
- Kør
- samme
- Gem
- besparelse
- Videnskabsmand
- forskere
- Skærm
- tjener
- Shell
- bør
- Vis
- vist
- signifikant
- lignende
- Simpelt
- ganske enkelt
- siden
- enkelt
- So
- løsninger
- nogle
- noget
- et eller andet sted
- delt
- stablet
- står
- starte
- påbegyndt
- Trin
- Steps
- struktur
- sådan
- Tag
- Opgaver
- opgaver
- Teknologier
- vilkår
- prøve
- deres
- grundigt
- Gennem
- tid
- tidskrævende
- til
- sammen
- top
- Tog
- uddannet
- Kurser
- overførsel
- Overførsel
- tutorial
- typisk
- forstå
- forstået
- brug
- sædvanligvis
- validering
- forskellige
- køretøj
- udgave
- Hjemmeside
- websites
- uger
- Hvad
- som
- mens
- bredt
- udbredt
- vilje
- uden
- Arbejde
- arbejder
- ville
- skriver
- Forkert
- yaml
- YOLO
- Din
- zephyrnet
- Zip