Dette indlæg er skrevet sammen med Mahima Agarwal, Machine Learning Engineer, og Deepak Mettem, Senior Engineering Manager, hos VMware Carbon Black
VMware Carbon Black er en kendt sikkerhedsløsning, der tilbyder beskyttelse mod hele spektret af moderne cyberangreb. Med terabytes af data genereret af produktet fokuserer sikkerhedsanalyseteamet på at bygge maskinlæringsløsninger (ML) for at synliggøre kritiske angreb og sætte fokus på nye trusler fra støj.
Det er afgørende for VMware Carbon Black-teamet at designe og bygge en brugerdefineret end-to-end MLOps-pipeline, der orkestrerer og automatiserer arbejdsgange i ML-livscyklussen og muliggør modeltræning, -evalueringer og -implementeringer.
Der er to hovedformål med at opbygge denne pipeline: at støtte dataforskerne til modeludvikling på sent stadium og forudsigelser af overflademodeller i produktet ved at betjene modeller i høj volumen og i realtidsproduktionstrafik. Derfor valgte VMware Carbon Black og AWS at bygge en tilpasset MLOps-pipeline vha Amazon SageMaker for dens brugervenlighed, alsidighed og fuldt administrerede infrastruktur. Vi orkestrerer vores ML-trænings- og implementeringspipelines vha Amazon administrerede arbejdsgange til Apache Airflow (Amazon MWAA), som gør det muligt for os at fokusere mere på programmatisk oprettelse af arbejdsgange og pipelines uden at skulle bekymre os om automatisk skalering eller vedligeholdelse af infrastrukturen.
Med denne pipeline er det, der engang var Jupyter notebook-drevet ML-forskning, nu en automatiseret proces, der implementerer modeller til produktion med lidt manuel indgriben fra dataforskere. Tidligere kunne processen med at træne, evaluere og implementere en model tage over en dag; med denne implementering er alt kun en trigger væk og har reduceret den samlede tid til få minutter.
I dette indlæg diskuterer VMware Carbon Black- og AWS-arkitekter, hvordan vi byggede og administrerede brugerdefinerede ML-arbejdsgange ved hjælp af Gitlab, Amazon MWAA og SageMaker. Vi diskuterer, hvad vi har opnået indtil nu, yderligere forbedringer af pipelinen og erfaringer undervejs.
Løsningsoversigt
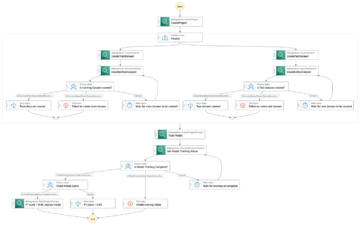
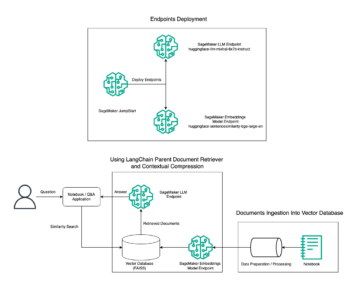
Følgende diagram illustrerer ML-platformens arkitektur.

Løsningsdesign på højt niveau
Denne ML-platform blev tænkt og designet til at blive brugt af forskellige modeller på tværs af forskellige kodelagre. Vores team bruger GitLab som et kildekodestyringsværktøj til at vedligeholde alle kodelagrene. Eventuelle ændringer i modellagerets kildekode integreres løbende ved hjælp af Gitlab CI, som påberåber sig de efterfølgende arbejdsgange i pipelinen (modeltræning, evaluering og implementering).
Følgende arkitekturdiagram illustrerer end-to-end-arbejdsgangen og de komponenter, der er involveret i vores MLOps-pipeline.

End-to-end workflow
ML-modellens trænings-, evaluerings- og implementeringspipelines er orkestreret ved hjælp af Amazon MWAA, kaldet en Retning Acyclic Graph (DAG). En DAG er en samling af opgaver sammen, organiseret med afhængigheder og relationer for at sige, hvordan de skal køre.
På et højt niveau omfatter løsningsarkitekturen tre hovedkomponenter:
- ML pipeline kodelager
- ML model træning og evaluering pipeline
- ML-modelimplementeringspipeline
Lad os diskutere, hvordan disse forskellige komponenter administreres, og hvordan de interagerer med hinanden.
ML pipeline kodelager
Efter at model-repoen har integreret MLOps-repoen som deres downstream-pipeline, og en dataforsker begår kode i deres model-repo, udfører en GitLab-løber standardkodevalidering og -testning defineret i den repo og udløser MLOps-pipeline baseret på kodeændringerne. Vi bruger Gitlabs multi-projekt pipeline til at aktivere denne trigger på tværs af forskellige reposer.
MLOps GitLab-pipeline kører et bestemt sæt trin. Den udfører grundlæggende kodevalidering ved hjælp af pylint, pakker modellens trænings- og inferenskode i Docker-billedet og udgiver containerbilledet til Amazon Elastic Container Registry (Amazon ECR). Amazon ECR er et fuldt administreret containerregister, der tilbyder højtydende hosting, så du pålideligt kan implementere applikationsbilleder og artefakter hvor som helst.
ML model træning og evaluering pipeline
Efter at billedet er offentliggjort, udløser det træningen og evalueringen Apache luftstrøm rørledning gennem AWS Lambda fungere. Lambda er en serverløs, hændelsesdrevet beregningstjeneste, der lader dig køre kode til stort set enhver type applikation eller backend-tjeneste uden at klargøre eller administrere servere.
Efter at pipelinen er succesfuldt udløst, kører den Training and Evaluation DAG, som igen starter modeltræningen i SageMaker. I slutningen af denne træningspipeline modtager den identificerede brugergruppe en meddelelse med trænings- og modelevalueringsresultaterne via e-mail via Amazon Simple Notification Service (Amazon SNS) og Slack. Amazon SNS er fuldt administreret pub/underservice til A2A- og A2P-meddelelser.
Efter omhyggelig analyse af evalueringsresultaterne kan dataforskeren eller ML-ingeniøren implementere den nye model, hvis ydeevnen af den nyuddannede model er bedre sammenlignet med den tidligere version. Modellernes ydeevne evalueres ud fra de modelspecifikke metrics (såsom F1-score, MSE eller forvirringsmatrix).
ML-modelimplementeringspipeline
For at starte implementeringen starter brugeren GitLab-jobbet, der udløser Deployment DAG'en gennem den samme Lambda-funktion. Når pipelinen kører med succes, opretter eller opdaterer den SageMaker-slutpunktet med den nye model. Dette sender også en meddelelse med slutpunktsdetaljerne via e-mail ved hjælp af Amazon SNS og Slack.
I tilfælde af fejl i en af rørledningerne underrettes brugerne via de samme kommunikationskanaler.
SageMaker tilbyder inferens i realtid, der er ideel til inferensarbejdsbelastninger med lav latenstid og høje gennemløbskrav. Disse endepunkter er fuldt administrerede, belastningsbalancerede og automatisk skaleret og kan implementeres på tværs af flere tilgængelighedszoner for høj tilgængelighed. Vores pipeline opretter et sådant slutpunkt for en model, efter at den er kørt med succes.
I de følgende afsnit udvider vi de forskellige komponenter og dykker ned i detaljerne.
GitLab: Pakke modeller og trigger pipelines
Vi bruger GitLab som vores kodelager og til pipelinen til at pakke modelkoden og udløse downstream Airflow DAG'er.
Multi-projekt pipeline
Multi-projekt GitLab pipeline-funktionen bruges, hvor den overordnede pipeline (opstrøms) er en model-repo, og den underordnede pipeline (nedstrøms) er MLOps-repoen. Hver repo vedligeholder en .gitlab-ci.yml, og den følgende kodeblok aktiveret i upstream-pipelinen udløser downstream MLOps-pipeline.
Upstream-pipelinen sender over modelkoden til downstream-pipelinen, hvor pakke- og udgivelses-CI-jobbene udløses. Kode til at containerisere modelkoden og udgive den til Amazon ECR vedligeholdes og administreres af MLOps pipeline. Den sender variabler som ACCESS_TOKEN (kan oprettes under Indstillinger, Adgang), JOB_ID (for at få adgang til opstrøms artefakter) og $CI_PROJECT_ID (projekt-id'et for model repo) variabler, så MLOps-pipelinen kan få adgang til modelkodefilerne. Med job artefakter funktion fra Gitlab, downstream-repoen får adgang til de eksterne artefakter ved hjælp af følgende kommando:
Model-repoen kan forbruge downstream-rørledninger for flere modeller fra den samme repo ved at udvide den fase, der udløser den ved hjælp af udvider nøgleord fra GitLab, som giver dig mulighed for at genbruge den samme konfiguration på tværs af forskellige stadier.
Efter at have offentliggjort modelbilledet til Amazon ECR, udløser MLOps-pipelinen Amazon MWAA-træningspipeline ved hjælp af Lambda. Efter brugerens godkendelse udløser den modelimplementeringen Amazon MWAA-pipeline ved hjælp af den samme Lambda-funktion.
Semantisk versionering og videregivelse af versioner nedstrøms
Vi udviklede tilpasset kode til version ECR-billeder og SageMaker-modeller. MLOps-pipelinen styrer den semantiske versionslogik for billeder og modeller som en del af den fase, hvor modelkoden bliver containeriseret, og videregiver versionerne til senere stadier som artefakter.
Omskoling
Fordi omskoling er et afgørende aspekt af en ML-livscyklus, har vi implementeret genoptræningsfunktioner som en del af vores pipeline. Vi bruger SageMaker list-models API til at identificere, om det er genoptræning baseret på modeloplæringens versionsnummer og tidsstempel.
Vi styrer den daglige tidsplan for omskolingspipeline vha GitLabs tidsplan pipelines.
Terraform: Opsætning af infrastruktur
Ud over en Amazon MWAA-klynge, ECR-lagre, Lambda-funktioner og SNS-emne, bruger denne løsning også AWS identitets- og adgangsstyring (IAM) roller, brugere og politikker; Amazon Simple Storage Service (Amazon S3) spande, og en amazoncloudwatch log forwarder.
For at strømline infrastrukturopsætningen og vedligeholdelsen af de involverede tjenester i hele vores pipeline, bruger vi terraform at implementere infrastrukturen som kode. Når der kræves infra-opdateringer, udløser kodeændringerne en GitLab CI-pipeline, som vi sætter op, som validerer og implementerer ændringerne i forskellige miljøer (for eksempel tilføjelse af en tilladelse til en IAM-politik i dev-, stage- og prod-konti).
Amazon ECR, Amazon S3 og Lambda: Pipeline facilitation
Vi bruger følgende nøgletjenester til at lette vores pipeline:
- Amazon ECR – For at vedligeholde og tillade bekvemme hentning af modelbeholderbillederne, tagger vi dem med semantiske versioner og uploader dem til ECR-lagre opsat pr.
${project_name}/${model_name}gennem Terraform. Dette muliggør et godt lag af isolation mellem forskellige modeller og giver os mulighed for at bruge brugerdefinerede algoritmer og formatere slutningsanmodninger og svar til at inkludere ønskede modelmanifestoplysninger (modelnavn, version, træningsdatasti og så videre). - Amazon S3 – Vi bruger S3-spande til at bevare modeltræningsdata, trænede modelartefakter pr. model, Airflow DAG'er og andre yderligere oplysninger, der kræves af rørledningerne.
- Lambda – Fordi vores Airflow-klynge er implementeret i en separat VPC af sikkerhedshensyn, kan DAG'erne ikke tilgås direkte. Derfor bruger vi en Lambda-funktion, der også vedligeholdes med Terraform, til at udløse eventuelle DAG'er angivet af DAG-navnet. Med korrekt IAM-opsætning udløser GitLab CI-jobbet Lambda-funktionen, som passerer gennem konfigurationerne ned til de anmodede trænings- eller implementerings-DAG'er.
Amazon MWAA: Trænings- og implementeringspipelines
Som tidligere nævnt bruger vi Amazon MWAA til at orkestrere trænings- og implementeringspipelines. Vi bruger SageMaker-operatører, der er tilgængelige i Amazon-udbyderpakke til Airflow at integrere med SageMaker (for at undgå jinja-skabeloner).
Vi bruger følgende operatører i denne træningspipeline (vist i følgende workflowdiagram):

MWAA Træningsrørledning
Vi bruger følgende operatører i implementeringspipelinen (vist i følgende workflowdiagram):

Model Deployment Pipeline
Vi bruger Slack og Amazon SNS til at offentliggøre fejl-/succesmeddelelserne og evalueringsresultaterne i begge pipelines. Slack giver en bred vifte af muligheder for at tilpasse beskeder, herunder følgende:
- SnsPublishOperator - Vi bruger SnsPublishOperator at sende meddelelser om succes/fejl til brugere-e-mails
- Slack API – Vi skabte indgående webhook-URL for at få pipeline-meddelelserne til den ønskede kanal
CloudWatch og VMware Wavefront: Overvågning og logning
Vi bruger et CloudWatch-dashboard til at konfigurere slutpunktsovervågning og logning. Det hjælper med at visualisere og holde styr på forskellige operationelle og modelpræstationsmålinger, der er specifikke for hvert projekt. Ud over de automatiske skaleringspolitikker, der er sat op til at spore nogle af dem, overvåger vi løbende ændringerne i CPU- og hukommelsesforbrug, anmodninger pr. sekund, svarforsinkelser og modelmålinger.
CloudWatch er endda integreret med et VMware Tanzu Wavefront-dashboard, så det kan visualisere metrikken for model-endepunkter samt andre tjenester på projektniveau.
Forretningsmæssige fordele og det næste
ML-pipelines er meget afgørende for ML-tjenester og -funktioner. I dette indlæg diskuterede vi en end-to-end ML use case ved hjælp af funktioner fra AWS. Vi byggede en tilpasset pipeline ved hjælp af SageMaker og Amazon MWAA, som vi kan genbruge på tværs af projekter og modeller, og automatiserede ML-livscyklussen, hvilket reducerede tiden fra modeltræning til produktionsimplementering til så lidt som 10 minutter.
Med skiftet af ML-livscyklusbyrden til SageMaker gav det optimeret og skalerbar infrastruktur til modeltræning og implementering. Modelvisning med SageMaker hjalp os med at lave forudsigelser i realtid med millisekunders forsinkelser og overvågningsmuligheder. Vi brugte Terraform for at lette opsætningen og til at administrere infrastruktur.
De næste trin for denne pipeline ville være at forbedre modeltræningspipelinen med genoptræningsfunktioner, uanset om den er planlagt eller baseret på modeldriftdetektion, understøttelse af skyggeimplementering eller A/B-test for hurtigere og kvalificeret modelimplementering og ML-afstamningssporing. Vi planlægger også at evaluere Amazon SageMaker Pipelines fordi GitLab-integration nu er understøttet.
Erfaringer
Som en del af opbygningen af denne løsning lærte vi, at du bør generalisere tidligt, men ikke overgeneralisere. Da vi først var færdige med arkitekturdesignet, forsøgte vi at skabe og håndhæve kodeskabeloner til modelkoden som en bedste praksis. Det var dog så tidligt i udviklingsprocessen, at skabelonerne enten var for generaliserede eller for detaljerede til at kunne genbruges til fremtidige modeller.
Efter at have leveret den første model gennem pipelinen, kom skabelonerne ud naturligt baseret på indsigten fra vores tidligere arbejde. En pipeline kan ikke alt fra dag ét.
Modeleksperimentering og produktion har ofte meget forskellige (eller nogle gange endda modstridende) krav. Det er afgørende at balancere disse krav fra begyndelsen som et team og prioritere derefter.
Derudover har du muligvis ikke brug for alle funktioner i en tjeneste. At bruge væsentlige funktioner fra en tjeneste og have et modulært design er nøglerne til mere effektiv udvikling og en fleksibel pipeline.
Konklusion
I dette indlæg viste vi, hvordan vi byggede en MLOps-løsning ved hjælp af SageMaker og Amazon MWAA, der automatiserede processen med at implementere modeller til produktion, med lidt manuel indgriben fra dataforskere. Vi opfordrer dig til at evaluere forskellige AWS-tjenester som SageMaker, Amazon MWAA, Amazon S3 og Amazon ECR for at bygge en komplet MLOps-løsning.
*Apache, Apache Airflow og Airflow er enten registrerede varemærker eller varemærker tilhørende Apache Software Foundation i USA og/eller andre lande.
Om forfatterne
 Deepak Mettem er Senior Engineering Manager i VMware, Carbon Black Unit. Han og hans team arbejder på at bygge de streamingbaserede applikationer og tjenester, der er yderst tilgængelige, skalerbare og modstandsdygtige for at bringe kunderne maskinlæringsbaserede løsninger i realtid. Han og hans team er også ansvarlige for at skabe værktøjer, der er nødvendige for datavidenskabsfolk til at bygge, træne, implementere og validere deres ML-modeller i produktionen.
Deepak Mettem er Senior Engineering Manager i VMware, Carbon Black Unit. Han og hans team arbejder på at bygge de streamingbaserede applikationer og tjenester, der er yderst tilgængelige, skalerbare og modstandsdygtige for at bringe kunderne maskinlæringsbaserede løsninger i realtid. Han og hans team er også ansvarlige for at skabe værktøjer, der er nødvendige for datavidenskabsfolk til at bygge, træne, implementere og validere deres ML-modeller i produktionen.
 Mahima Agarwal er en maskinlæringsingeniør i VMware, Carbon Black Unit.
Mahima Agarwal er en maskinlæringsingeniør i VMware, Carbon Black Unit.
Hun arbejder med at designe, bygge og udvikle kernekomponenterne og arkitekturen i maskinlæringsplatformen til VMware CB SBU.
 Vamshi Krishna Enabothala er Sr. Applied AI Specialist Architect hos AWS. Han arbejder med kunder fra forskellige sektorer for at fremskynde effektive data, analyser og maskinlæringsinitiativer. Han brænder for anbefalingssystemer, NLP og computervisionsområder inden for AI og ML. Uden for arbejdet er Vamshi en RC-entusiast, der bygger RC-udstyr (fly, biler og droner) og nyder også havearbejde.
Vamshi Krishna Enabothala er Sr. Applied AI Specialist Architect hos AWS. Han arbejder med kunder fra forskellige sektorer for at fremskynde effektive data, analyser og maskinlæringsinitiativer. Han brænder for anbefalingssystemer, NLP og computervisionsområder inden for AI og ML. Uden for arbejdet er Vamshi en RC-entusiast, der bygger RC-udstyr (fly, biler og droner) og nyder også havearbejde.
 Sahil Thapar er en Enterprise Solutions Architect. Han arbejder med kunder for at hjælpe dem med at bygge højst tilgængelige, skalerbare og modstandsdygtige applikationer på AWS Cloud. Han er i øjeblikket fokuseret på containere og maskinlæringsløsninger.
Sahil Thapar er en Enterprise Solutions Architect. Han arbejder med kunder for at hjælpe dem med at bygge højst tilgængelige, skalerbare og modstandsdygtige applikationer på AWS Cloud. Han er i øjeblikket fokuseret på containere og maskinlæringsløsninger.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :er
- $OP
- 1
- 10
- 100
- 7
- 8
- a
- Om
- fremskynde
- adgang
- af udleverede
- derfor
- Konti
- opnået
- tværs
- acykliske
- Desuden
- Yderligere
- yderligere information
- Efter
- mod
- AI
- algoritmer
- Alle
- tillader
- Amazon
- Amazon SageMaker
- analyse
- analytics
- ,
- overalt
- Apache
- api
- Anvendelse
- applikationer
- anvendt
- Anvendt AI
- godkendelse
- arkitektur
- ER
- områder
- AS
- udseende
- At
- Angreb
- forfatter
- auto
- Automatiseret
- automater
- tilgængelighed
- til rådighed
- undgå
- AWS
- Bagende
- Balance
- baseret
- grundlæggende
- BE
- fordi
- Begyndelse
- fordele
- BEDSTE
- Bedre
- mellem
- Sort
- Bloker
- Branch
- bringe
- bygge
- Bygning
- bygget
- byrde
- by
- CAN
- kan ikke
- kapaciteter
- kulstof
- biler
- tilfælde
- CB
- vis
- Ændringer
- kanaler
- barn
- valgte
- Cloud
- Cluster
- kode
- samling
- Kommunikation
- sammenlignet
- fuldføre
- komponenter
- Compute
- computer
- Computer Vision
- adfærd
- Konfiguration
- konfigurationer
- Modstridende
- forvirring
- overvejelser
- forbruge
- forbruges
- Container
- Beholdere
- kontinuerligt
- Praktisk
- Core
- kunne
- lande
- CPU
- skabe
- oprettet
- skaber
- Oprettelse af
- kritisk
- afgørende
- For øjeblikket
- skik
- Kunder
- tilpasse
- cyberangreb
- DAG
- dagligt
- instrumentbræt
- data
- dataforsker
- dag
- definerede
- leverer
- indsætte
- indsat
- implementering
- implementering
- implementeringer
- udruller
- Design
- konstrueret
- designe
- detaljeret
- detaljer
- Detektion
- dev
- udviklet
- udvikling
- Udvikling
- forskellige
- direkte
- diskutere
- drøftet
- Docker
- Dont
- ned
- Drones
- hver
- tidligere
- Tidligt
- brugervenlighed
- effektiv
- enten
- smergel
- muliggøre
- aktiveret
- muliggør
- tilskynde
- ende til ende
- Endpoint
- ingeniør
- Engineering
- Enterprise
- Enterprise Solutions
- entusiast
- miljøer
- udstyr
- væsentlig
- Ether (ETH)
- evaluere
- evalueret
- evaluere
- evaluering
- evalueringer
- Endog
- begivenhed
- Hver
- at alt
- eksempel
- Udvid
- strækker
- f1
- lette
- Manglende
- langt
- hurtigere
- Feature
- Funktionalitet
- få
- Filer
- Fornavn
- fleksibel
- Fokus
- fokuserede
- fokuserer
- efter
- Til
- format
- fra
- fuld
- fuldt spektrum
- fuldt ud
- funktion
- funktioner
- yderligere
- fremtiden
- genereret
- få
- godt
- gruppe
- Have
- have
- hjælpe
- hjulpet
- hjælper
- Høj
- Høj ydeevne
- stærkt
- Hosting
- Hvordan
- Men
- HTML
- http
- HTTPS
- IAM
- ID
- ideal
- identificeret
- identificere
- Identity
- billede
- billeder
- gennemføre
- implementering
- implementeret
- in
- omfatter
- omfatter
- Herunder
- oplysninger
- Infrastruktur
- initiativer
- indsigt
- integrere
- integreret
- Integrerer
- integration
- interagere
- indgriben
- påberåber sig
- involverede
- isolation
- IT
- ITS
- Job
- Karriere
- jpg
- Holde
- Nøgle
- nøgler
- Latency
- lag
- lærte
- læring
- Lessons
- Erfaringer
- Lets
- Niveau
- livscyklus
- ligesom
- lidt
- belastning
- Lav
- maskine
- machine learning
- Main
- vedligeholde
- fastholder
- vedligeholdelse
- lave
- administrere
- lykkedes
- ledelse
- leder
- administrerer
- styring
- manuel
- Matrix
- Hukommelse
- nævnte
- beskeder
- messaging
- Metrics
- måske
- millisekund
- minutter
- ML
- MLOps
- model
- modeller
- Moderne
- Overvåg
- overvågning
- mere
- mere effektiv
- flere
- navn
- naturligt
- nødvendig
- Behov
- Ny
- næste
- NLP
- Støj
- underretning
- meddelelser
- nummer
- of
- tilbyde
- Tilbud
- on
- ONE
- operationelle
- Operatører
- optimeret
- Indstillinger
- orkestreret
- Organiseret
- Andet
- uden for
- samlet
- pakke
- pakker
- emballage
- del
- gennemløb
- Passing
- lidenskabelige
- sti
- ydeevne
- tilladelse
- pipeline
- fly
- Planes
- perron
- plato
- Platon Data Intelligence
- PlatoData
- politikker
- politik
- Indlæg
- praksis
- Forudsigelser
- tidligere
- Prioriter
- behandle
- Produkt
- produktion
- projekt
- projekter
- passende
- beskyttelse
- forudsat
- udbyder
- giver
- offentliggøre
- offentliggjort
- Udgiver
- Publicering
- formål
- kvalificeret
- rækkevidde
- realtid
- Anbefaling
- Reduceret
- benævnt
- registreret
- register
- Relationer
- fjern
- Kendt
- Repository
- anmodet
- anmodninger
- påkrævet
- Krav
- forskning
- elastisk
- svar
- ansvarlige
- Resultater
- omskoling
- genanvendelige
- roller
- Kør
- runner
- sagemaker
- samme
- skalerbar
- skalering
- planlægge
- planlagt
- Videnskabsmand
- forskere
- Anden
- sektioner
- Sektorer
- sikkerhed
- senior
- adskille
- Serverless
- Servere
- tjeneste
- Tjenester
- servering
- sæt
- setup
- Shadow
- SKIFT
- bør
- vist
- Simpelt
- slæk
- So
- indtil nu
- Software
- løsninger
- Løsninger
- nogle
- Kilde
- kildekode
- specialist
- specifikke
- specificeret
- Spectrum
- Spotlight
- Stage
- etaper
- standard
- starte
- starter
- Stater
- Steps
- opbevaring
- Strategi
- streaming
- strømline
- efterfølgende
- Succesfuld
- sådan
- support
- Understøttet
- overflade
- Systemer
- TAG
- Tag
- opgaver
- hold
- skabeloner
- terraform
- Test
- at
- deres
- Them
- derfor
- Disse
- trusler
- tre
- Gennem
- hele
- kapacitet
- tid
- tidsstempel
- til
- sammen
- også
- værktøj
- værktøjer
- top
- emne
- spor
- Sporing
- varemærker
- Trafik
- Tog
- uddannet
- Kurser
- udløse
- udløst
- TUR
- under
- enhed
- Forenet
- Forenede Stater
- opdateringer
- us
- Brug
- brug
- brug tilfælde
- Bruger
- brugere
- VALIDATE
- validering
- variabler
- forskellige
- udgave
- næsten
- vision
- Visualiser
- vmware
- bind
- Vej..
- GODT
- Hvad
- hvorvidt
- som
- bred
- Bred rækkevidde
- med
- inden for
- uden
- Arbejde
- workflow
- arbejdsgange
- virker
- ville
- zephyrnet
- Zip
- zoner