Introduktion
En verden af revisionsdata kan være kompleks, med mange udfordringer, der skal overvindes. En af de største udfordringer er at håndtere kategoriske attributter, mens man håndterer datasæt. I denne artikel vil vi dykke ned i verden af revisionsdata, anomalidetektion og indvirkningen af kodning af kategoriske attributter på modeller.
En af hovedudfordringerne forbundet med anomalidetektion til revision af data er håndtering af kategoriske attributter. Indkodning af kategoriske attributter er obligatorisk, fordi modellerne ikke kan fortolke tekstinput. Normalt gøres dette ved hjælp af Label-kodning eller One Hot-kodning. I et stort datasæt kan One-hot-kodning dog føre til dårlig modelydeevne på grund af dimensionalitetens forbandelse.
Læringsmål
-
At forstå konceptet med revision af data og udfordringen
- For at evaluere forskellige metoder til dyb uovervåget anomalidetektion.
- For at forstå virkningen af indkodning af kategoriske attributter på modeller, der bruges til afsløring af anomalier i revisionsdata.
Denne artikel blev offentliggjort som en del af Data Science Blogathon.
Indholdsfortegnelse
- Hvad er Auata?
- Hvad er anomalidetektion?
- Store udfordringer under revision af data
- Revision af datasæt til registrering af anomalier
- Kodning af kategoriattributter
- Kategoriske kodninger
- Uovervågede anomalidetektionsmodeller
- Hvordan påvirker kodning af kategoriske attributter modellerne?
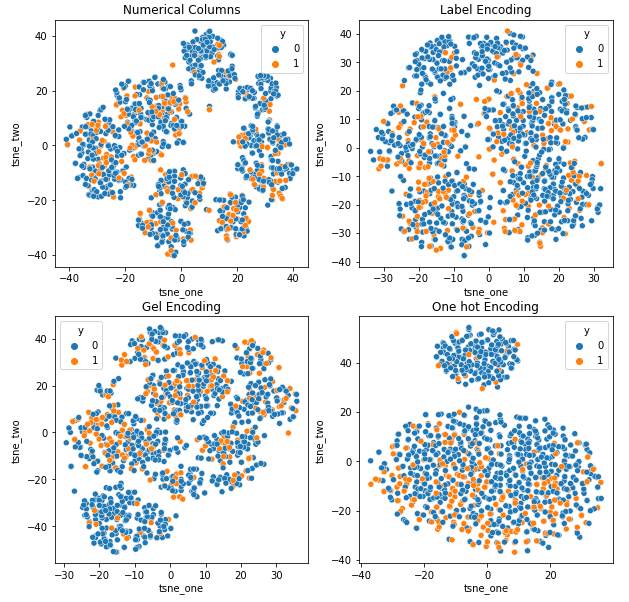
8.1 t-SNE-repræsentation af datasættet for bilforsikring
8.2 t-SNE-repræsentation af datasættet for køretøjsforsikring
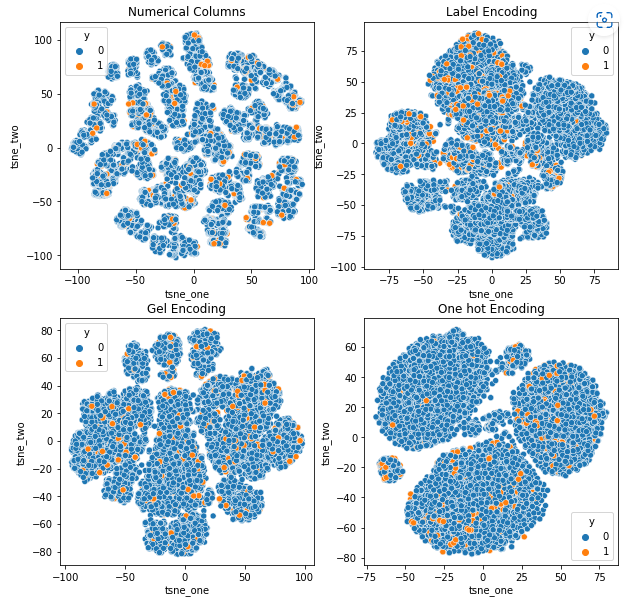
8.3 t-SNE-repræsentation af datasættet for køretøjskrav - Konklusion
på er Revisionsdata?
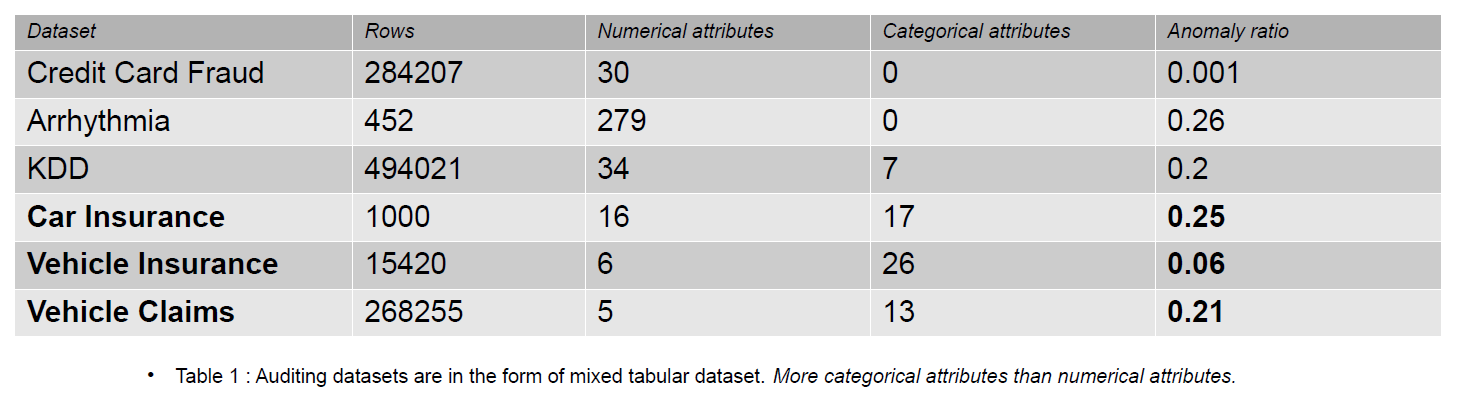
Revisionsdata kan omfatte journaler, forsikringskrav og indtrængningsdata til informationssystemer; i denne artikel er eksemplerne forsikringskrav på køretøjer. Forsikringskrav kan skelnes fra datasæt til registrering af anomalier, f.eks. KDD, ved et større antal kategoriske træk.
Kategoriske træk er diskute i vores data, som enten kan være af typen heltal eller karakter. Numeriske funktioner er kontinuerlige attributter i vores data, som altid er reelt værdsat. Datasæt med numeriske funktioner er populære i anomalidetektionssamfundet som f.eks. kreditkortsvindeldata. De fleste af de offentligt tilgængelige datasæt indeholder færre kategoriske træk end data om forsikringsskader. Kategoriske træk er flere i antal end numeriske træk i datasættene for forsikringsskader.
Et forsikringskrav inkluderer funktioner som Model, Brand, Indkomst, Omkostning, Udstedelse, Farve osv. Antallet af kategoriske funktioner er højere i revisionsdata end i kreditkort- og KDD-datasættene. Disse datasæt er benchmarks i uovervågede anomalidetektionsmetoder. Som det ses i nedenstående tabel, har datasæt for forsikringskrav mere kategoriske funktioner, som er vigtige for at forstå adfærden af svigagtige data.
De revisionsdatasæt, der bruges til at evaluere virkningen af kategoriske kodninger, er bilforsikring, køretøjsforsikring og køretøjskrav.
Hvad er anomalidetektion?
En anomali er en observation placeret langt væk fra normale data i et datasæt med en bestemt afstand (Tærskel). Med hensyn til revisionsdata foretrækker vi udtrykket svigagtige data. Anomalidetektion skelner mellem normale og svigagtige data ved hjælp af machine learning eller deep learning model. Forskellige metoder kan bruges til anomalidetektion, såsom tæthedsestimering, rekonstruktionsfejl og klassificeringsmetoder.
- Densitetsvurdering – Disse metoder estimerer normal datafordeling og klassificerer unormale data, hvis de ikke er blevet samplet fra den indlærte fordeling.
- Rekonstruktionsfejl – Rekonstruktionsfejlbaserede metoder er baseret på princippet om, at normale data kan rekonstrueres med mindre tab end unormale data. Jo højere rekonstruktionstabet er, øger chancerne for, at dataene er en anomali.
- Klassificeringsmetoder - Klassificeringsmetoder som Tilfældig Skov, Isolation Forest, One Class – Support Vector Machines og Local Outlier Factors kan bruges til afsløring af anomalier. Klassificering i anomalidetektion involverer at identificere en af klasserne som anomalien. Alligevel er klasserne opdelt i to grupper (0 og 1) i multi-class scenariet, og klassen med færre data er den unormale klasse.
Outputtet af ovenstående metoder er anomali-score eller rekonstruktionsfejl. Så skal vi beslutte os for en tærskel, som vi klassificerer de unormale data efter.
Store udfordringer under revision af data
- Håndtering af kategoriske attributter: Indkodning af kategoriske attributter er obligatorisk, fordi modellen ikke kan fortolke tekstinput. Så værdierne er kodet med Label-kodning eller One Hot-kodning. Men i et stort datasæt transformerer One hot encoding dataene til et højdimensionelt rum ved at øge antallet af attributter. Modellen klarer sig dårligt pga dimensionalitetens forbandelse.
- Valg af tærskel for klassificering: Hvis dataene ikke er mærket, er det svært at evaluere modellens ydeevne, fordi vi ikke kender antallet af anomalier i datasættet. Den forudgående viden om datasættet gør det lettere at bestemme tærsklen. Lad os sige, at vi har 5 ud af 10 unormale prøver i vores data. Så vi kan vælge tærsklen ved 50 percentilen.
- Offentlige datasæt: De fleste revisionsdatasæt er fortrolige, fordi de tilhører virksomhedsvirksomheder og indeholder følsomme og personlige oplysninger. En mulig måde at afbøde problemer med fortrolighed på er at træne ved hjælp af syntetiske datasæt (Vehicle Claims).
Revision af datasæt til registrering af anomalier
Forsikringskrav for køretøjer omfatter oplysninger om køretøjets egenskaber, såsom model, mærke, pris, årgang og brændstoftype. Den indeholder oplysninger om føreren, fødselsdato, køn og erhverv. Derudover kan kravet indeholde oplysninger om de samlede omkostninger ved reparation. De datasæt, der bruges i denne artikel, er alle fra et enkelt domæne, men de varierer i antallet af attributter og antallet af forekomster.
-
Datasættet for køretøjskrav er stort og indeholder over 250,000 rækker, og dets kategoriske attributter har en kardinalitet på 1171. På grund af dets store størrelse lider dette datasæt af dimensionalitetens forbandelse.
- Køretøjsforsikringsdatasættet er mellemstort med 15,420 rækker og 151 unikke kategoriske værdier. Dette gør den mindre tilbøjelig til at lide af dimensionalitetens forbandelse.
- Bilforsikringsdatasættet er lille med etiketter og 25 % unormale prøver, og det indeholder et tilsvarende antal numeriske og kategoriske funktioner. Med 169 unikke kategorier lider den ikke af dimensionalitetens forbandelse.
Kodning af kategoriske attributter
Forskellige indkodninger af kategoriske værdier
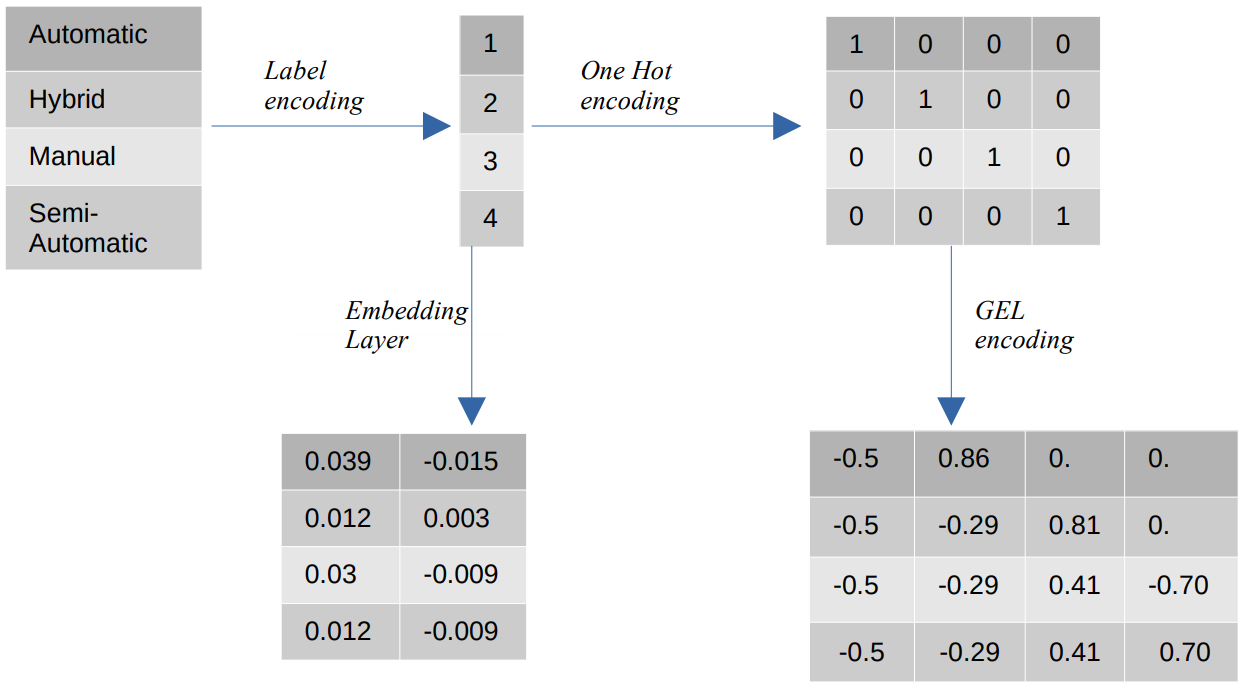
- Etiketkodning – Ved etiketkodning erstattes de kategoriske værdier med numeriske heltalsværdier mellem 1 og antallet af kategorier. Etiketkodning repræsenterer kategorierne på den tilsigtede måde for ordensværdier. Alligevel, når funktionerne er nominelle, er repræsentationen forkert, da de kategoriske værdier ikke stemmer overens med en bestemt rækkefølge.
Hvis vi f.eks. har kategorier som Automatic, Hybrid, Manual og Semi-Automatic i en funktion, omdanner etiketkodning disse værdier til {1: Automatic, 2: Hybrid, 3: Manual, 4:Semi-Automatic}. Denne repræsentation giver ingen information om de kategoriske værdier, men en repræsentation som {0: Lav, 1: Medium, 2: Høj} giver en klar repræsentation, fordi featurevariablen Lav er tildelt en lavere numerisk værdi. Derfor er etiketkodning bedre for ordinalværdier, men ufordelagtig for nominelle værdier. - En varm kodning – One Hot-encoding bruges til at løse problemet med nominelle kodningsværdier, som transformerer hver kategorisk værdi til en særskilt funktion i datasættet bestående af binære værdier. For eksempel, i tilfælde af fire forskellige kategorier kodet som {1, 2, 3, 4}, vil One Hot-kodning skabe nye funktioner såsom {Automatisk: [1,0,0,0], Hybrid: [0,1,0,0 ,0,0,1,0], Manuel: [0,0,0,1], Semi-automatisk: [XNUMX]}.
Datasættets dimension afhænger så direkte af antallet af kategorier, der findes i datasættet. Som et resultat kan One Hot-kodning føre til dimensionalitetens forbandelse, hvilket er en ulempe ved denne kodningsmetode. - GEL-kodning – GEL-kodning er en indlejringsteknik, der kan bruges i overvågede og uovervågede læringsmetoder. Det er baseret på princippet om One Hot-kodning og kan bruges til at reducere dimensionaliteten af kategoriske funktioner, der er blevet kodet ved hjælp af One Hot-kodning.
- Indlejring af lag - Ordindlejringer giver mulighed for at bruge en kompakt og tæt repræsentation, hvor lignende ord har lignende kodninger. En indlejring er en tæt vektor af flydende kommaværdier, der er parametre, der kan trænes. Ordindlejringer kan variere fra 8-dimensionelle (for små datasæt) til 1024-dimensionelle (for store datasæt).
En højere dimensionel indlejring kan fange mere detaljerede forhold mellem ord, men det kræver flere data at lære. Indlejringslaget er en opslagstabel, der konverterer hvert ord, der findes i matrixen, til en vektor af en bestemt størrelse.
Uovervågede anomalidetektionsmodeller
I den virkelige verden er data ikke mærket i de fleste tilfælde, og mærkning af data er dyrt og tidskrævende. Derfor vil vi bruge uovervågede modeller til vores evalueringer.
- SOM - The Self-Organizing Map (SOM) er en kompetitiv læringsmetode, hvor neuronernes vægte opdateres konkurrencedygtigt frem for at bruge backpropagation learning. SOM består af et kort over neuroner, hver med en vægtvektor af samme størrelse som inputvektoren. Vægtvektoren initialiseres med tilfældige vægte før træningen starter. Under træningen sammenlignes hvert input med neuronerne på kortet baseret på en afstandsmetrik (f.eks. Euklidisk afstand) og kortlægges til Best Matching Unit (BMU), som er neuronen med den mindste afstand til inputvektoren.
Vægtene af BMU'en opdateres med vægtene af inputvektoren, og de tilstødende neuroner opdateres baseret på nabolagets radius (sigma). Da neuronerne konkurrerer med hinanden om at være den bedst matchende enhed, er denne proces kendt som konkurrencedygtig læring. I sidste ende er neuronerne for normale prøver tættere på end de unormale. Anomaliscorer er defineret af kvantiseringsfejlen, som er forskellen mellem inputprøven og vægtene af den bedst matchende enhed. En højere kvantiseringsfejl indikerer en højere sandsynlighed for, at prøven er en anomali. - DAGMM – Deep Autoencoding Gaussian Mixture Model (DAGMM) er en tæthedsestimeringsmetode, der antager, at anomalier ligger i et område med lav sandsynlighed. Netværket er opdelt i to dele: et kompressionsnetværk, som bruges til at projicere data i lavere dimensioner ved hjælp af en autoencoder, og et estimeringsnetværk, som bruges til at estimere parametrene for den Gaussiske blandingsmodel. DAGMM estimerer k antal Gaussiske blandinger, hvor k kan være et hvilket som helst tal fra 1 til N (antallet af datapunkter), og det antages, at normale punkter ligger i et område med høj tæthed, hvilket betyder, at sandsynligheden for at blive samplet fra en Gaussisk blanding er højere for normale punkter end for unormale prøver. Anomali-score er defineret af prøvens estimerede energi.
- RSRAE – The Robust Surface Recovery Layer for Unsupervised Anomaly Detection er en rekonstruktionsfejlmetode, der først projicerer dataene til en lavere dimension ved hjælp af en autoencoder. Den latente repræsentation udsættes derefter for en ortogonal projektion på et lineært underrum, der er robust over for outliers. Dekoderen rekonstruerer derefter outputtet fra det lineære underrum. I denne metode indikerer en højere rekonstruktionsfejl en højere sandsynlighed for, at prøven er en anomali.
- SOM-DAGMM- Et selvorganiserende kort (SOM) – Deep Autoencoding Gaussian Mixture Model (DAGMM) er også en tæthedsestimeringsmodel. Ligesom DAGMM estimerer den også sandsynlighedsfordelingen af normale datapunkter og klassificerer et datapunkt som en anomali, hvis det har en lav sandsynlighed for at blive samplet fra den indlærte fordeling. Den største forskel mellem SOM-DAGMM og DAGMM er, at SOM-DAGMM inkluderer de normaliserede koordinater for SOM for inputprøven, som giver den manglende topologiske information i tilfælde af DAGMM til estimeringsnetværket. Målet ligner også DAGMM, idet anomali-score er defineret af prøvens estimerede energi, og lav energi indikerer en højere sandsynlighed for prøven som en anomali.
Dernæst vil vi tage fat på udfordringen med at håndtere kategoriske attributter.
Hvordan påvirker kodning af kategoriske attributter modellerne?
For at forstå virkningen af forskellige kodninger på datasæt, vil vi bruge t-SNE til at visualisere de lavdimensionelle repræsentationer af dataene for forskellige kodninger. t-SNE projicerer højdimensionelle data ind i et rum med lavere dimensioner, hvilket gør det nemmere at visualisere. Ved at sammenligne t-SNE-visualiseringer og numeriske resultater af forskellige kodninger af det samme datasæt, observeres forskellen i de resulterende repræsentationer og forståelse af kodningens indvirkning på datasættet.
t-SNE-repræsentation af datasættet for bilforsikring
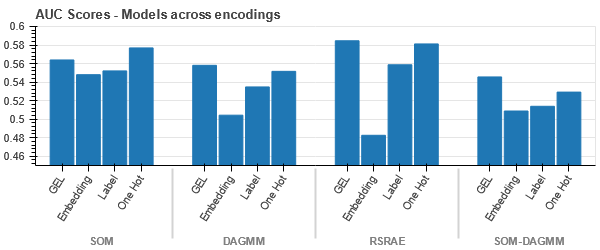
t-SNE-repræsentation af køretøjsforsikringsdatasættet
-
Dataene er tættere på hinanden, fordi antallet af rækker er højere end i datasættet for bilforsikring. Det bliver svært at adskille med øget dimensionalitet i One Hot-kodning.
-
GEL-kodning er bedre end One Hot-kodning i alle tilfælde undtagen DAGMM.
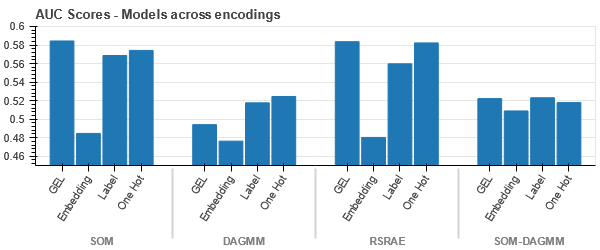
t-SNE-repræsentation af datasættet for køretøjskrav
-
Dataene er i alle tilfælde tæt bundet, hvilket gør det vanskeligt at adskille med øget dimensionalitet. Dette er en af grundene til modellernes dårlige ydeevne på grund af øget dimensionalitet.
- SOM overgår alle andre modeller for dette datasæt. Alligevel er indlejringslaget mere velegnet i de fleste tilfælde, hvilket giver os et alternativ til kodning kategoriske egenskaber til afsløring af anomalier.
Konklusion
Denne artikel præsenterer en kort oversigt over revisionsdata, anomalidetektion og kategoriske kodninger. Det er vigtigt at forstå, at håndtering af kategoriske attributter i revisionsdata er udfordrende. Ved at forstå virkningen af kodning af attributterne på modeller kan vi forbedre nøjagtigheden af afsløring af anomalier i datasættene. De vigtigste ting fra denne artikel er:
- Efterhånden som datastørrelsen øges, er det vigtigt at bruge alternative kodningstilgange til kategoriske attributter, såsom GEL-kodning og Embedding-lag, fordi One Hot-kodning er uegnet.
- Én model virker ikke for alle datasæt. For datasæt i tabelform er domæneviden ekstremt vigtig.
- Valget af indkodningsmetode afhænger af valget af model.
Koden til evaluering af modeller er tilgængelig på GitHub.
Mediet vist i denne artikel ejes ikke af Analytics Vidhya og bruges efter forfatterens skøn.
Relaterede
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- Om
- over
- Ifølge
- nøjagtighed
- Derudover
- adresse
- Alle
- tillader
- alternativ
- altid
- analytics
- Analyse Vidhya
- ,
- afsløring af anomalier
- tilgange
- artikel
- tildelt
- forbundet
- antaget
- attributter
- revision
- Automatisk Ur
- til rådighed
- baseret
- fordi
- bliver
- før
- være
- jf. nedenstående
- Benchmarks
- BEDSTE
- Bedre
- mellem
- Største
- bundet
- brand
- kan ikke
- fange
- bil
- bilforsikring
- kort
- tilfælde
- tilfælde
- kategorier
- udfordre
- udfordringer
- udfordrende
- odds
- karakter
- valg
- krav
- fordringer
- klasse
- klasser
- klassificering
- Klassificere
- klar
- tættere
- kode
- farve
- almindeligt
- samfund
- Virksomheder
- sammenlignet
- sammenligne
- konkurrere
- konkurrencedygtig
- komplekse
- Konceptet
- fortrolighed
- Bestående
- indeholder
- kontinuerlig
- Corporate
- Koste
- skabe
- kredit
- kreditkort
- data
- datapunkter
- datasæt
- Dato
- beskæftiger
- falde
- dyb
- dyb læring
- afhænger
- detaljeret
- Detektion
- Bestem
- forskel
- forskellige
- svært
- Dimension
- størrelse
- direkte
- diskretion
- afstand
- distinkt
- fordeling
- Divided
- domæne
- driver
- i løbet af
- hver
- lettere
- enten
- energi
- fejl
- fejl
- skøn
- anslået
- skøn
- etc.
- evaluere
- evaluering
- evalueringer
- eksempel
- eksempler
- Undtagen
- dyrt
- ekstremt
- konfronteret
- faktorer
- Feature
- Funktionalitet
- Fornavn
- skov
- bedrageri
- svigagtig
- fra
- Brændstof
- Køn
- Gruppens
- Håndtering
- Høj
- højere
- HOT
- Men
- HTTPS
- Hybrid
- identificere
- KIMOs Succeshistorier
- vigtigt
- Forbedre
- in
- omfatter
- omfatter
- Indkomst
- øget
- Stigninger
- stigende
- angiver
- oplysninger
- Informationssystemer
- indgang
- forsikring
- isolation
- spørgsmål
- spørgsmål
- IT
- Nøgle
- Kend
- viden
- kendt
- etiket
- mærkning
- Etiketter
- stor
- større
- lag
- lag
- føre
- LÆR
- lærte
- læring
- lokale
- placeret
- kig op
- off
- tab
- Lav
- maskine
- machine learning
- Maskiner
- Main
- maerker
- Making
- obligatorisk
- manuel
- mange
- kort
- matchende
- Matrix
- betyder
- Medier
- medium
- metode
- metoder
- metrisk
- minimum
- mangler
- afbøde
- blanding
- model
- modeller
- mere
- mest
- netværk
- Neuroner
- Ny
- Nye funktioner
- normal
- nummer
- objektiv
- ONE
- ordrer
- Andet
- udkonkurrerer
- Overvind
- oversigt
- ejede
- parametre
- del
- dele
- ydeevne
- udfører
- personale
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- punkter
- fattige
- Populær
- mulig
- foretrække
- præsentere
- gaver
- pris
- princippet
- Forud
- sandsynlighed
- Problem
- behandle
- erhverv
- projekt
- projektdata
- Fremskrivning
- projekter
- egenskaber
- give
- forudsat
- giver
- offentliggjort
- tilfældig
- rækkevidde
- ægte
- virkelige verden
- årsager
- opsving
- region
- Relationer
- reparation
- udskiftes
- repræsentation
- repræsenterer
- Kræver
- resultere
- resulterer
- Resultater
- robust
- samme
- Videnskab
- følsom
- adskille
- vist
- Sigma
- lignende
- siden
- enkelt
- Størrelse
- lille
- mindre
- So
- Space
- specifikke
- starter
- Stadig
- sådan
- lider
- egnede
- support
- overflade
- syntetisk
- Systemer
- bord
- Takeaways
- vilkår
- verdenen
- derfor
- tærskel
- stramt
- tidskrævende
- til
- I alt
- Tog
- Kurser
- forstå
- forståelse
- enestående
- enhed
- uovervåget læring
- opdateret
- us
- brug
- værdi
- Værdier
- køretøj
- Køretøjer
- vægt
- Hvad
- Hvad er
- som
- mens
- vilje
- ord
- ord
- Arbejde
- world
- ville
- år
- zephyrnet