Organisationer bruger agile projektstyringsplatforme såsom Atlassian Jira for at gøre det muligt for teams at samarbejde om at planlægge, spore og sende leverancer. Jira fanger organisatorisk viden om, hvordan leverancerne fungerer, i de problemer og kommentarer, der logges under projektimplementeringen. Men at gøre denne viden let og sikkert tilgængelig for brugerne er udfordrende, fordi den er fragmenteret på tværs af problemstillinger, der hører til forskellige projekter og sprints. Derudover, fordi forskellige interessenter såsom udviklere, testingeniører og projektledere bidrager til det samme problem ved at logge det og derefter tilføje vedhæftede filer og kommentarer, bliver traditionel søgeordsbaseret søgning ineffektiv, når der søges efter information i Jira-projekter.
Du kan nu bruge Amazon Kendra Jira cloud-forbindelse til at indeksere problemer, kommentarer og vedhæftede filer i dine Jira-projekter og søge efter dette indhold ved hjælp af Amazon Kendra intelligent søgning, drevet af maskinlæring (ML).
Dette indlæg viser, hvordan man bruger Amazon Kendra Jira-skyforbindelsen til at konfigurere en Jira-skyforekomst som en datakilde for et Amazon Kendra-indeks og intelligent søger i indholdet af projekterne i det. Vi bruger et eksempel på Jira-projekter, hvor teammedlemmer samarbejder ved at skabe problemer og tilføje oplysninger til dem i form af beskrivelser, kommentarer og vedhæftede filer gennem hele problematikkens livscyklus.
Løsningsoversigt
En Jira-instans har et eller flere projekter, hvor hvert projekt har teammedlemmer, der arbejder med problemer i det pågældende projekt. Hvert teammedlem har et sæt tilladelser om de operationer, de kan udføre med hensyn til forskellige problemer i det projekt, de tilhører. Teammedlemmer kan oprette nye problemer eller tilføje flere oplysninger til problemerne i form af vedhæftede filer og kommentarer, samt ændre status for et problem fra dets åbning til lukning i hele problematikkens livscyklus defineret for det pågældende projekt. En projektleder opretter sprints, tildeler problemer til specifikke sprints og tildeler ejere til problemer. I løbet af projektet fortsætter den viden, der er fanget i disse problemstillinger, med at udvikle sig.
I vores løsning konfigurerer vi en Jira cloud-instans som en datakilde til et Amazon Kendra-søgeindeks ved hjælp af Amazon Kendra Jira-stikket. Baseret på konfigurationen, når datakilden er synkroniseret, gennemgår og indekserer connectoren indholdet fra projekterne i Jira-forekomsten. Du kan eventuelt konfigurere den til at indeksere indholdet baseret på ændringsloggen. Connectoren indsamler og indtager også adgangskontrollisteoplysninger (ACL) for hvert problem, kommentar og vedhæftet fil. ACL-oplysningerne bruges til brugerkontekstfiltrering, hvor søgeresultater for en forespørgsel filtreres efter, hvad en bruger har autoriseret adgang til.
Forudsætninger
For at prøve Amazon Kendra-stikket til Jira ved at bruge dette indlæg som reference, har du brug for følgende:
- An AWS-konto med privilegier til at skabe AWS identitets- og adgangsstyring (IAM) roller og politikker. For mere information, se Oversigt over adgangsstyring: Tilladelser og politikker , politikker for Jira-datakilder.
- Grundlæggende viden om AWS og praktisk viden om Jira administration.
- Administratoradgang til en Jira cloud-instans.
Jira-instanskonfiguration
Dette afsnit beskriver Jira-konfigurationen, der bruges til at demonstrere, hvordan man konfigurerer en Amazon Kendra-datakilde ved hjælp af Jira-stikket, indtager data fra Jira-projekterne i Amazon Kendra-indekset og foretager søgeforespørgsler. Du kan bruge din egen Jira-instans, som du har administratoradgang til, eller oprette et nyt projekt og udføre trinene for at prøve Amazon Kendra-stikket til Jira.
I vores eksempel på Jira oprettede vi to projekter for at demonstrere, at brugernes søgeforespørgsler kun returnerer resultater fra de projekter, som de har adgang til. Vi brugte data fra følgende offentlige domæne-projekter til at simulere brugen af virkelige softwareudviklingsprojekter:
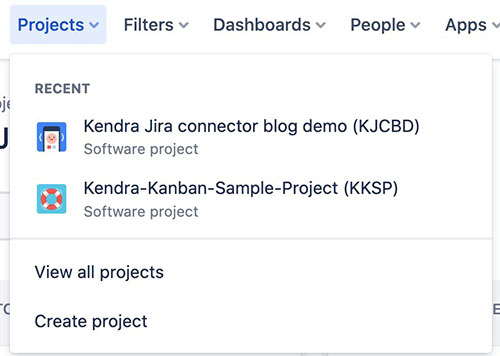
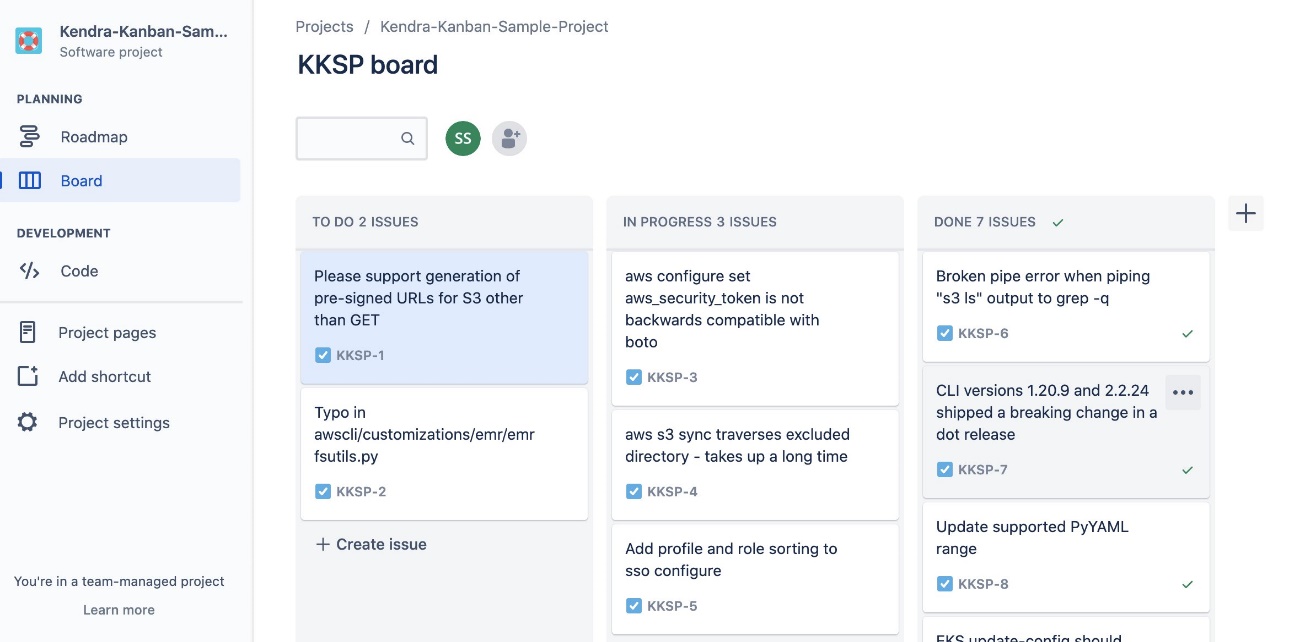
Følgende er et skærmbillede af vores Kanban-stil bord til projekt 1.
Opret et API-token til Jira-forekomsten
For at få det API-token, der er nødvendigt for at konfigurere Amazon Kendra Jira-stikket, skal du udføre følgende trin:
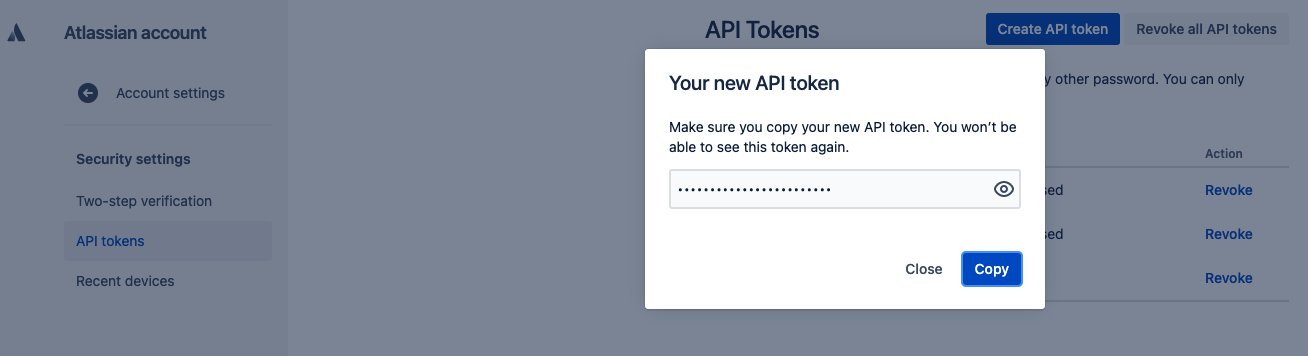
- Log ind på https://id.atlassian.com/manage/api-tokens.
- Vælg Opret API-token.
- Indtast en etiket for dit token i dialogboksen, der vises, og vælg Opret.
- Vælg Kopi og indtast tokenet på en midlertidig notesblok.
Du kan ikke kopiere dette token igen, og du skal bruge det til at konfigurere Amazon Kendra Jira-stikket.
Konfigurer datakilden ved hjælp af Amazon Kendra-stikket til Jira
For at tilføje en datakilde til dit Amazon Kendra-indeks ved hjælp af Jira-stikket, kan du bruge et eksisterende indeks eller oprette et nyt indeks. Udfør derefter følgende trin. For mere information om dette emne, se Amazon Kendra Developer Guide.
- På Amazon Kendra-konsollen skal du åbne dit indeks og vælge Data kilder i navigationsruden.
- Vælg Tilføj datakilde.
- Under Jira, vælg Tilføj stik.

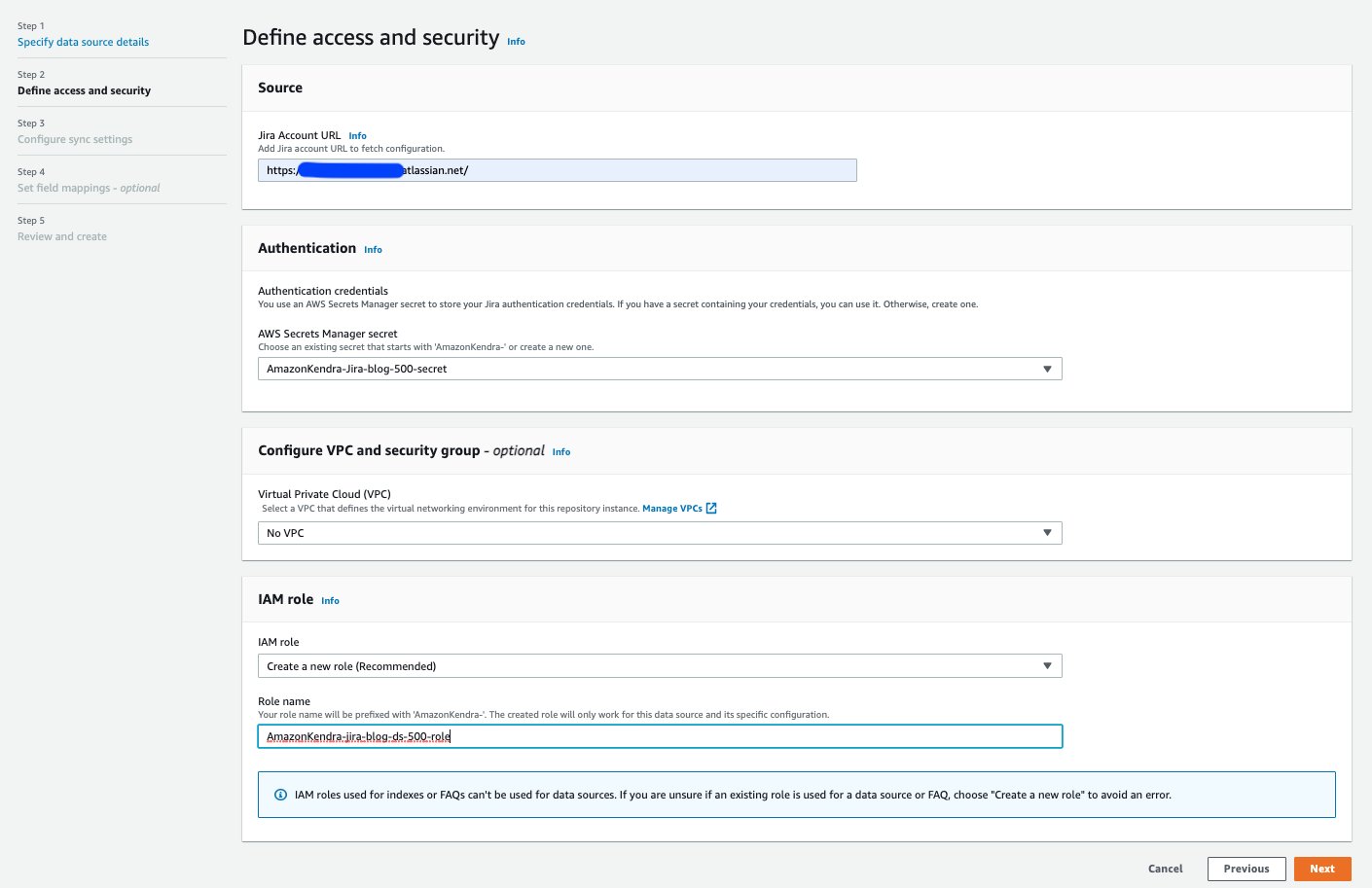
- I Angiv datakildedetaljer sektion, indtast detaljerne for din datakilde og vælg Næste.
- I Definer adgang og sikkerhed afsnit, for Jira-konto-URL, skal du indtaste URL'en på din Jira cloud-instans.
- Under Godkendelse, har du to muligheder:
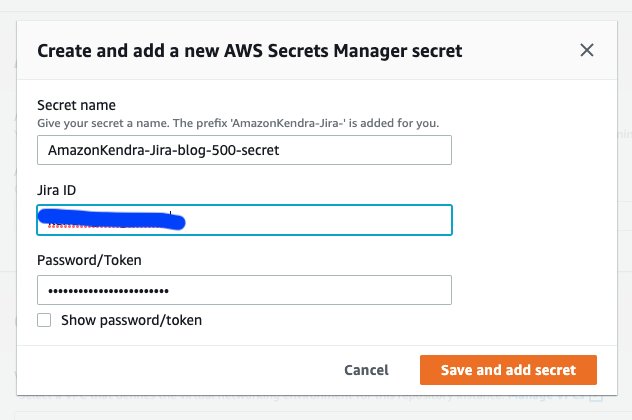
- Vælg Opret at tilføje en ny hemmelighed ved hjælp af Jira API-tokenet, du kopierede fra din Jira-instans, og bruge den e-mail-adresse, der blev brugt til at logge ind på Jira som Jira ID. (Dette er den mulighed, vi vælger for dette indlæg.)
- Brug en eksisterende AWS Secrets Manager hemmelighed, der har API-tokenet for den Jira-forekomst, du ønsker, at connectoren skal have adgang til.
- Til IAM rolle, vælg Lav en ny rolle eller vælg en eksisterende IAM-rolle konfigureret med passende IAM-politikker for at få adgang til Secrets Manager-hemmeligheden, Amazon Kendra-indekset og datakilden.
- Vælg Næste.
- I Konfigurer synkroniseringsindstillinger sektion, giv oplysninger om dit synkroniseringsområde og køreplan.
- Vælg Næste.
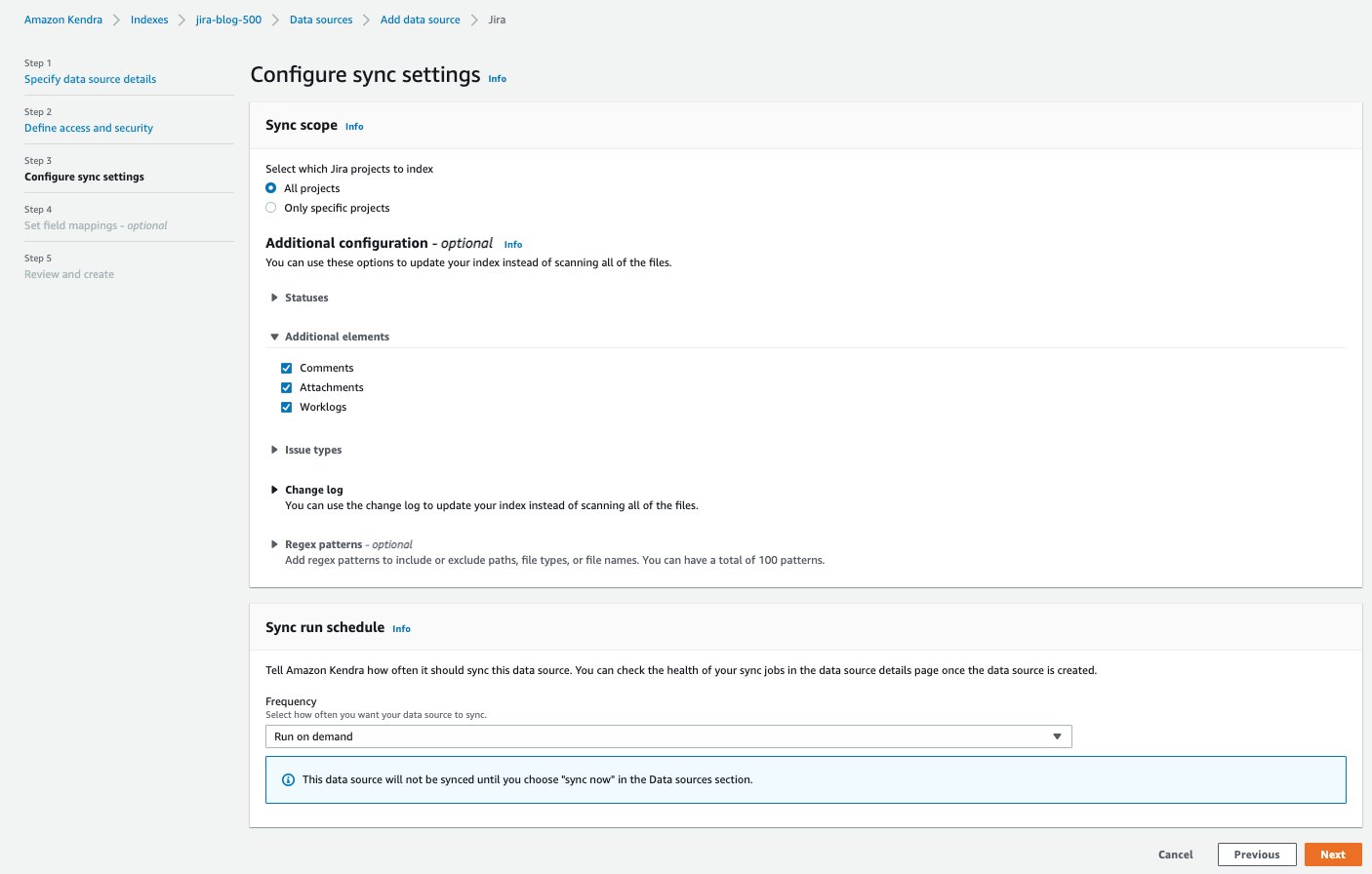
- I Indstil markkortlægninger sektionen, kan du valgfrit konfigurere felttilknytningerne, eller hvordan Jira-feltnavnene kortlægges til Amazon Kendra-attributter eller facetter.
- Vælg Næste.
- Gennemgå dine indstillinger, og bekræft at tilføje datakilden.
- Når datakilden er tilføjet, skal du vælge Data kilder i navigationsruden, vælg den nyligt tilføjede datakilde, og vælg Synkroniser nu for at starte datakildesynkronisering med Amazon Kendra-indekset.
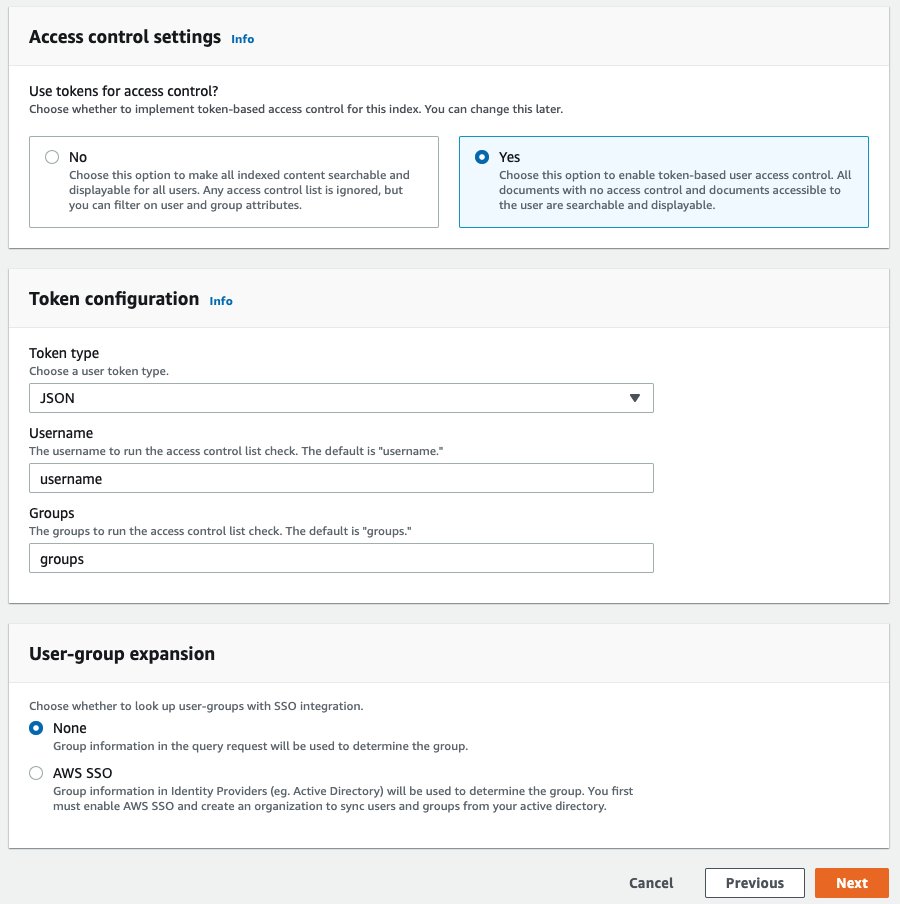
Synkroniseringsprocessen kan tage omkring 10-15 minutter. Lad os nu aktivere adgangskontrol til Amazon Kendra-indekset. - Vælg dit indeks i navigationsruden.
- I den midterste rude skal du vælge Brugeradgangskontrol fane.
- Vælg Rediger indstillinger og ændre indstillingerne, så de ligner følgende skærmbillede.
- Vælg Næste og vælg derefter Opdatering.
Udfør intelligent søgning med Amazon Kendra
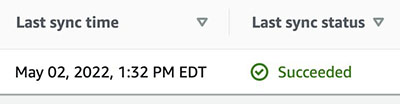
Før du prøver at søge på Amazon Kendra-konsollen eller bruge API'et, skal du sørge for, at datakildesynkroniseringen er fuldført. For at kontrollere, se datakilderne og kontroller, om den sidste synkronisering lykkedes.
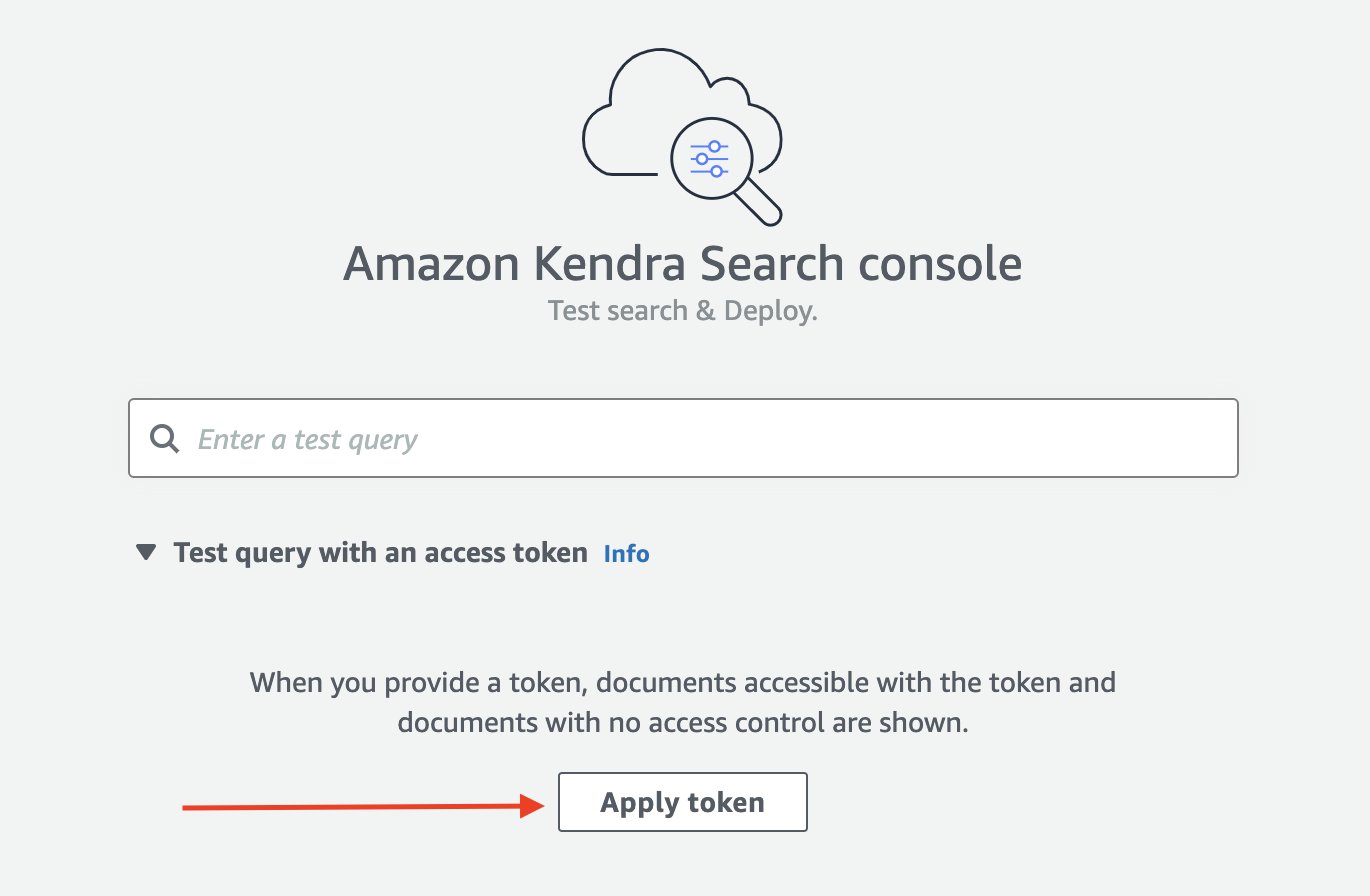
- For at starte din søgning skal du på Amazon Kendra-konsollen vælge Søg efter indekseret indhold i navigationsruden.
Du bliver omdirigeret til Amazon Kendra Search-konsollen. - Udvid Testforespørgsel med et adgangstoken Og vælg Anvend token.
- Til Brugernavn, skal du indtaste den e-mailadresse, der er knyttet til din Jira-konto.
- Vælg Indløs.
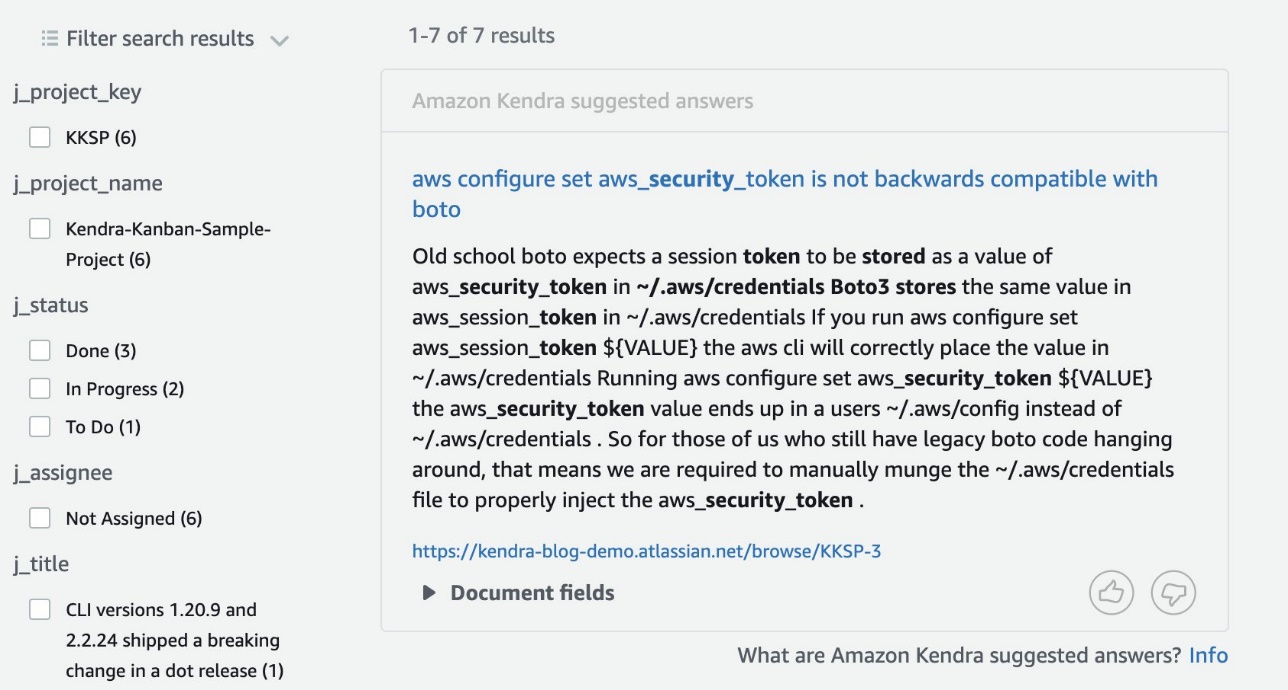
Nu er vi klar til at søge i vores indeks. Lad os bruge forespørgslen "hvor gemmer boto3 sikkerhedstokens?"

I dette tilfælde giver Kendra et foreslået svar fra et af kortene i vores Kanban-projekt om Jira.
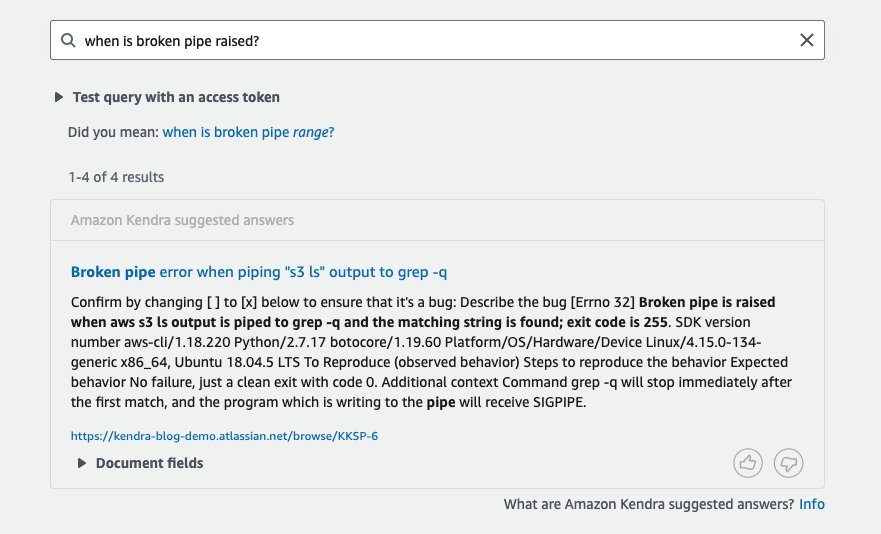
Bemærk, at dette også er et foreslået svar, der peger på et problem, der diskuterer AWS-sikkerhedstokens og Boto3. Du kan også opbygge søgeoplevelse med flere datakilder, herunder SDK-dokumentation og wikier med Amazon Kendra, og præsentere resultater og relaterede links i overensstemmelse hermed. Følgende skærmbillede viser en anden søgeforespørgsel lavet mod det samme indeks.
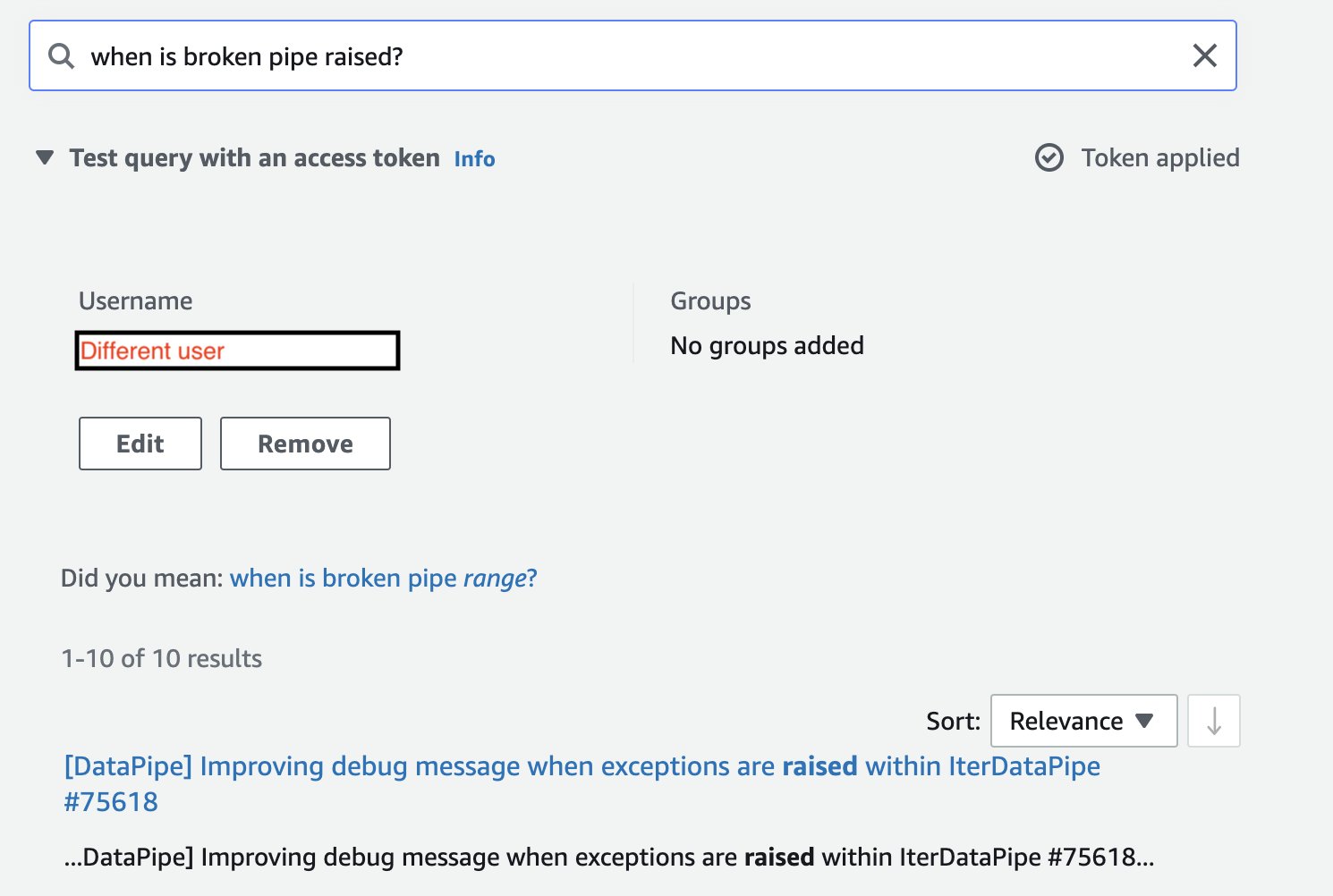
Bemærk, at når vi anvender et andet adgangstoken (knytter søgningen til en anden bruger), er søgeresultaterne begrænset til projekter, som denne bruger har adgang til.
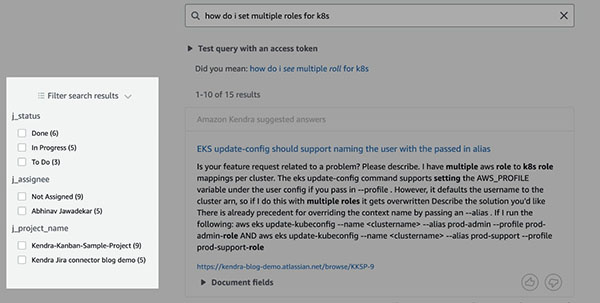
Endelig kan vi også bruge filtre, der er relevante for Jira i vores søgning. Først navigerer vi til vores indeks Facet definition side og tjek Facetable forum j_status, j_assigneeog j_project_name. For hver søgning kan vi derefter filtrere efter disse felter, som vist på det følgende skærmbillede.
Ryd op
For at undgå fremtidige omkostninger skal du rydde op i de ressourcer, du har oprettet som en del af denne løsning. Hvis du oprettede et nyt Amazon Kendra-indeks, mens du testede denne løsning, skal du slette det. Hvis du kun tilføjede en ny datakilde ved hjælp af Amazon Kendra-stikket til Jira, skal du slette denne datakilde.
Konklusion
Med Amazon Kendra Jira-stikket kan din organisation gøre uvurderlig viden i dine Jira-projekter tilgængelig for dine brugere sikkert ved hjælp af intelligent søgning drevet af Amazon Kendra.
For at lære mere om Amazon Kendra Jira-stikket, se Amazon Kendra Jira stik afsnittet i Amazon Kendra Developer Guide.
For mere information om andre Amazon Kendra indbyggede stik til populære datakilder, se Optrævl viden i Slack-arbejdsområder med intelligent søgning ved hjælp af Amazon Kendra Slack-stikket , Søg efter viden i Quip-dokumenter med intelligent søgning ved hjælp af Quip-stikket til Amazon Kendra.
Om forfatterne
 Shreyas Subramanian er en AI/ML specialist Solutions Architect, og hjælper kunder ved at bruge Machine Learning til at løse deres forretningsudfordringer på AWS Cloud.
Shreyas Subramanian er en AI/ML specialist Solutions Architect, og hjælper kunder ved at bruge Machine Learning til at løse deres forretningsudfordringer på AWS Cloud.
 Abhinav Jawadekar er en Principal Solutions Architect med fokus på Amazon Kendra i AI/ML sprogserviceteamet hos AWS. Abhinav arbejder med AWS-kunder og -partnere for at hjælpe dem med at bygge intelligente søgeløsninger på AWS.
Abhinav Jawadekar er en Principal Solutions Architect med fokus på Amazon Kendra i AI/ML sprogserviceteamet hos AWS. Abhinav arbejder med AWS-kunder og -partnere for at hjælpe dem med at bygge intelligente søgeløsninger på AWS.
- Coinsmart. Europas bedste Bitcoin og Crypto Exchange.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. FRI ADGANG.
- CryptoHawk. Altcoin radar. Gratis prøveversion.
- Kilde: https://aws.amazon.com/blogs/machine-learning/intelligently-search-your-jira-projects-with-amazon-kendra-jira-cloud-connector/
- "
- 100
- 420
- Om
- adgang
- derfor
- Konto
- tværs
- adresse
- admin
- administration
- adræt
- Amazon
- En anden
- besvare
- api
- passende
- Associate
- attributter
- til rådighed
- AWS
- være
- board
- grænse
- Boks
- bygge
- indbygget
- virksomhed
- fanger
- Kort
- bære
- udfordringer
- udfordrende
- lave om
- Vælg
- lukning
- Cloud
- samarbejde
- kommentarer
- samfund
- Konfiguration
- Konsol
- indhold
- indhold
- bidrage
- kontrol
- Omkostninger
- skabe
- oprettet
- skaber
- Oprettelse af
- Kunder
- data
- demonstrere
- detaljer
- Udvikler
- udviklere
- Udvikling
- forskellige
- dokumenter
- domæne
- i løbet af
- nemt
- muliggøre
- Ingeniører
- Indtast
- udviklende
- eksempel
- eksisterende
- erfaring
- Fields
- filtrering
- Filtre
- Fornavn
- fokuserede
- efter
- formular
- fremtiden
- GitHub
- hjælpe
- hjælper
- Hvordan
- How To
- Men
- HTTPS
- Identity
- implementering
- Herunder
- indeks
- oplysninger
- Intelligent
- spørgsmål
- spørgsmål
- IT
- viden
- Sprog
- LÆR
- læring
- Bibliotek
- links
- Liste
- maskine
- machine learning
- lavet
- Making
- ledelse
- leder
- Ledere
- medlem
- Medlemmer
- ML
- mere
- flere
- navne
- Navigation
- åbent
- åbning
- Produktion
- Option
- Indstillinger
- organisation
- organisatorisk
- Andet
- egen
- ejere
- del
- partnere
- Platforme
- politikker
- Populær
- præsentere
- Main
- behandle
- projekt
- projektledelse
- projekter
- give
- giver
- offentlige
- relevant
- Ressourcer
- Resultater
- afkast
- Kør
- SDK
- Søg
- sikkert
- sikkerhed
- Security Tokens
- Tjenester
- sæt
- vist
- slæk
- Software
- softwareudvikling
- solid
- løsninger
- Løsninger
- SOLVE
- specialist
- starte
- Status
- butik
- vellykket
- hold
- midlertidig
- prøve
- Test
- hele
- token
- Tokens
- spor
- traditionelle
- brug
- brugere
- verificere
- Specifikation
- Hvad
- mens
- arbejder
- virker