amazontekst er en maskinlæringstjeneste (ML), der automatisk udtrækker tekst, håndskrift og data fra ethvert dokument eller billede. For at gøre det nemmere at evaluere mulighederne i Amazon Textract, har vi lanceret en ny Bulk Document Uploader-funktion på Amazon Textract-konsollen, der gør det muligt for dig hurtigt at behandle dit eget sæt dokumenter uden at skrive nogen kode.
I dette indlæg gennemgår vi, hvornår og hvordan du bruger Amazon Textract Bulk Document Uploader til at evaluere, hvordan Amazon Textract klarer sig på dine dokumenter.
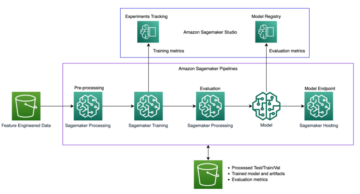
Oversigt over løsning
Bulk Document Uploader skal bruges til hurtig evaluering af Amazon Textract for forudbestemte brugstilfælde. Ved at uploade flere dokumenter samtidigt gennem en intuitiv brugergrænseflade kan du nemt måle, hvor godt Amazon Textract klarer sig på dine dokumenter.
Du kan uploade og behandle op til 150 dokumenter på én gang. I modsætning til de eksisterende Amazon Textract-konsoldemoer, som pålægger kunstige begrænsninger for antallet af dokumenter, dokumentstørrelse og maksimalt tilladte antal sider, understøtter Bulk Document Uploader behandling af op til 150 dokumenter pr. anmodning og har samme dokumentstørrelse og sidegrænser som Amazon Textract API'erne. Dette gør det mere effektivt for dig at evaluere et større sæt dokumenter.
Bulk Document Uploader udsender et standard Amazon Textract JSON-svar og en CSV-fil. Resultaterne leveres i JSON-format til nem programmatisk analyse. Derudover leveres en CSV-fil, der kan læses af mennesker, med konfidensresultater til enkel sammenligning og evaluering af den udtrukne information.
Når du bruger denne funktion, skal du huske følgende:
- Bulk Document Uploader behandler dokumenter via asynkrone operationer. Du kan spore status for behandlingen på Amazon Textract-konsollen. Kun DetectDocumentText (OCR), AnalyserDokument (Tabeller, forespørgsler, formularer og signaturer), og Analyser Udgift API'er understøttes i øjeblikket.
- Bulk Document Uploader giver JSON-resultater af API-handlinger og formaterede CSV-rapporter. Du skal muligvis stole på eksterne værktøjer til visualisering af dataene, såsom visning af markeringsrammehøjdepunkter på dokumentet ved hjælp af JSON-resultaterne.
- Brug af denne funktion til at behandle dokumenter medfører de samme gebyrer som almindelig Amazon Textract-brug (afhængigt af hvilken funktion der bruges), og er underlagt TPS-grænserne (transaktioner pr. sekund) for API'er, der er angivet for kontoen og regionen. For mere information om priser, se Amazon Textract-priser. For at lære mere om Amazon Textract-grænser, se Kvoter i Amazon Textract.
- Accepterede filformater til masseuploader er JPEG, PNG, TIF og PDF. JPEG 2000-kodede billeder i PDF'er understøttes også. JPEG- og PNG-filer har en størrelsesgrænse på 10 MB, mens PDF- og TIF-filer har en størrelsesgrænse på 500 MB. Flersidede PDF- og TIF-filer har en grænse på 3,000 sider.
Brug Bulk Document Uploader
Bulk Document Uploader er beregnet til at hjælpe dig med hurtigt at evaluere, hvordan Amazon Textract klarer sig på et sæt af dine egne dokumenter uden at skulle skrive nogen kode. Du kan bruge Bulk Document Uploader til at behandle så mange som 150 dokumenter i stedet for at uploade og behandle dokumenter individuelt. Du kan masseuploade dokumenter direkte fra din computer eller importere dokumenter fra en eksisterende Amazon Simple Storage Service (Amazon S3) spand.
Bulk Document Uploader giver resultater, som du kan downloade senere til offlinegennemgang. Hver ZIP-fil, der kan downloades, indeholder Amazon Textract API-svaret i JSON-filformat og en human-læsbar CSV-fil af outputtet, der indeholder de udtrukne data og konfidensresultater. Outputresultaterne er tilgængelige til download i 7 dage efter behandling. Efter 14 dage slettes dokumenter fra Indsendte dokumenter afsnit. For at bruge Bulk Document Uploader skal du udføre følgende trin:
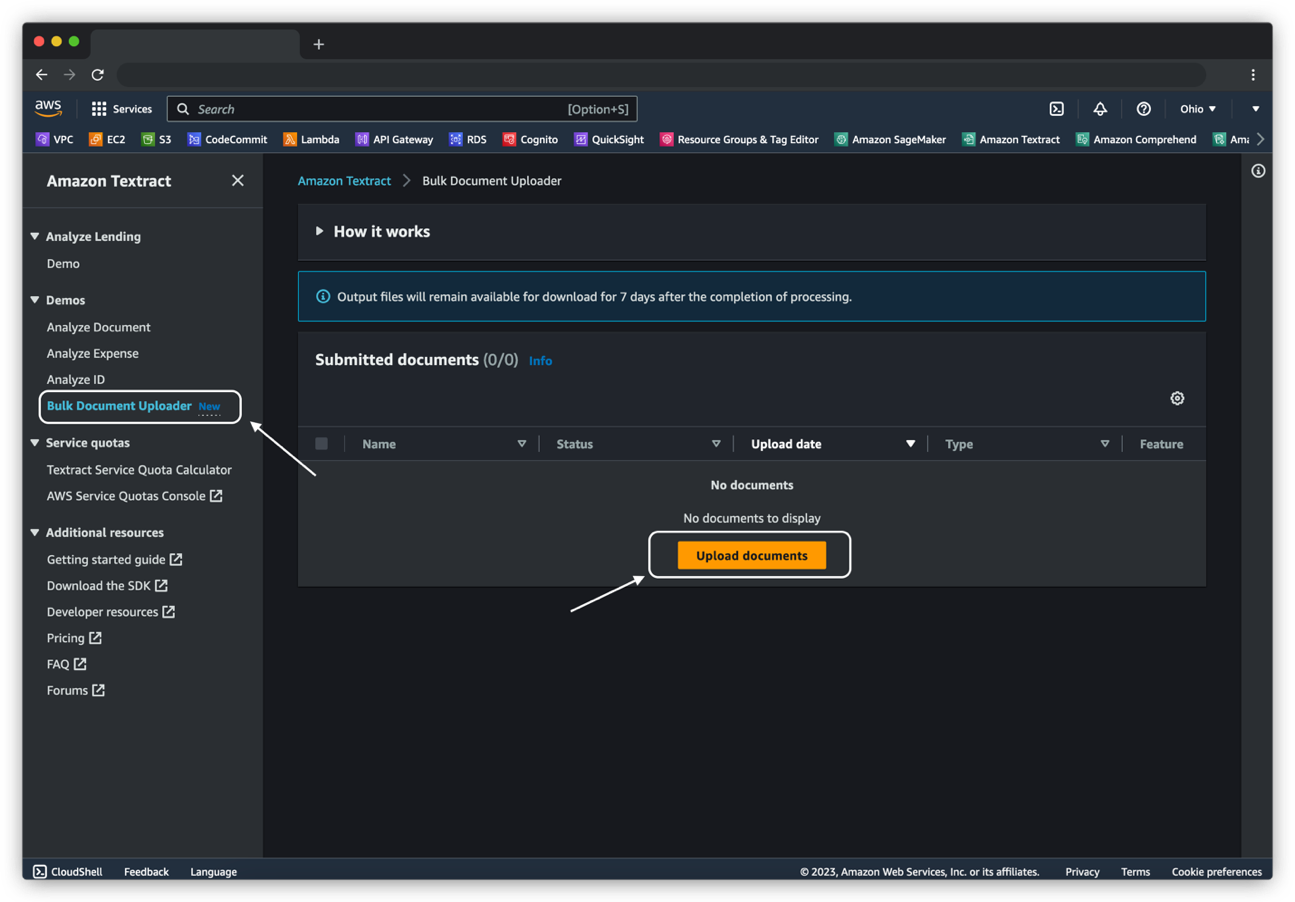
- På Amazon Textract-konsollen, under Demoer i navigationsruden skal du vælge Bulk Document Uploader.
- Vælg Upload dokumenter.
- Angiv kilden til dine dokumenter.
Du har to muligheder for at uploade dokumenter:
- Importer dokumenter fra S3 bucket – Hvis du bruger en S3-bøtte til dine dokumenter, skal du angive bucket-URL'en og (valgfrit) præfikset, hvor dine dokumenter ligger, i
s3://your-bucket/prefix/format. Alternativt, vælg Gennemse S3 for at gennemse og vælge den ønskede placering af dine dokumenter. Hvis den Amazon S3-placering, du har angivet, indeholder mere end 150 dokumenter, vil kun de første 150 dokumenter blive sendt til Amazon Textract til behandling.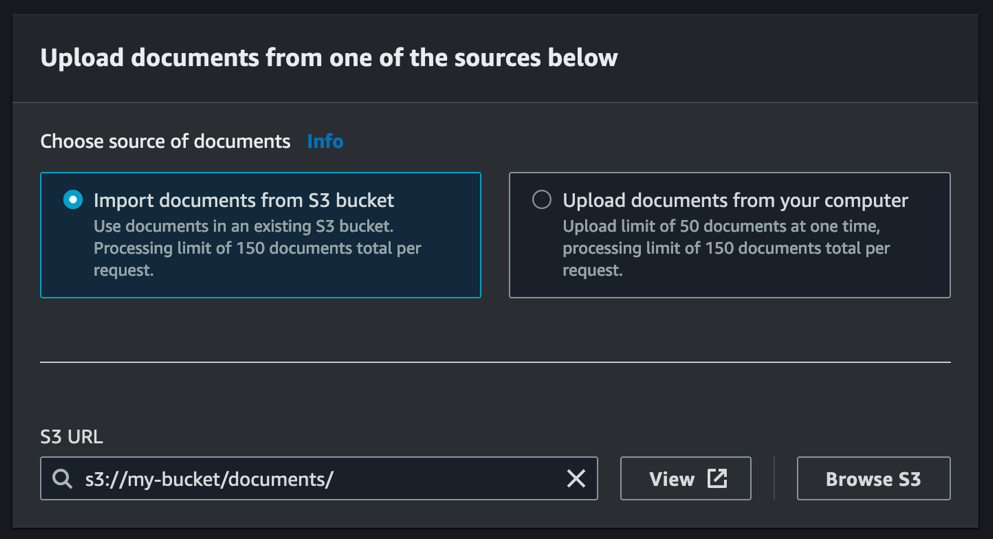
- Upload dokumenter fra din computer – Hvis du uploader dokumenter fra din computer, kan du uploade op til 50 dokumenter ad gangen ved at vælge Upload dokumenter. For at uploade yderligere dokumenter (op til maksimalt 150), skal du vælge Tilføj dokumenter efter dine første dokumenter er uploadet.
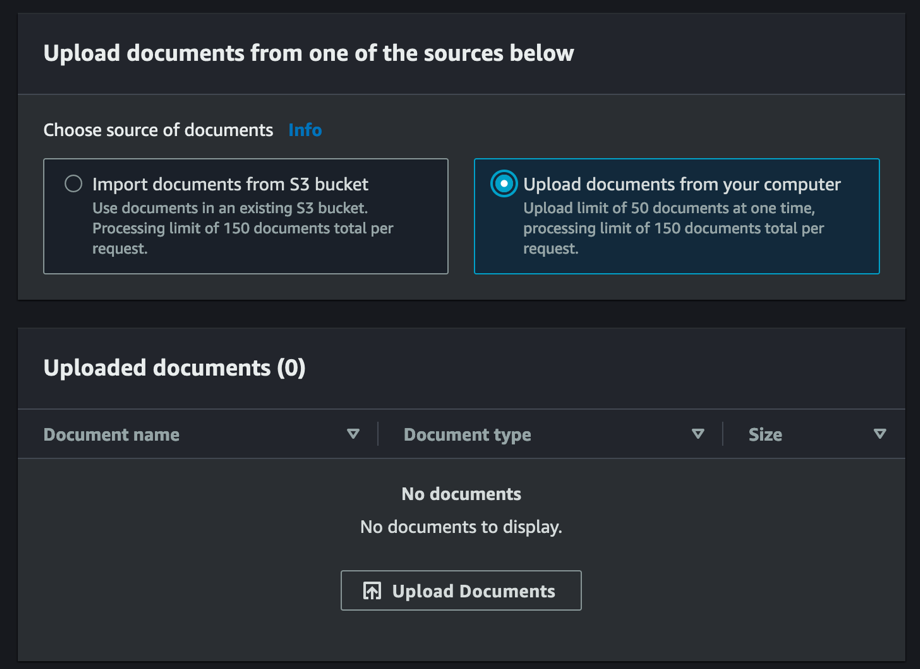
I dette tilfælde uploades dine dokumenter først til en S3-bucket på din konto, der er oprettet på dine vegne, derfor er det vigtigt at sikre, at du har tilladelser til at få adgang til og uploade dokumenter til Amazon S3. Dette er en engangshandling, og den samme bucket vil blive brugt til alle efterfølgende uploads fra din computer. Hvis du vil uploade og behandle det samme sæt dokumenter, kan du bruge stien til denne S3-bøtte ved hjælp af Importer dokumenter fra S3 bucket mulighed. S3-spanden, der er oprettet på dine vegne, vil være synlig, efter at spanden er oprettet.
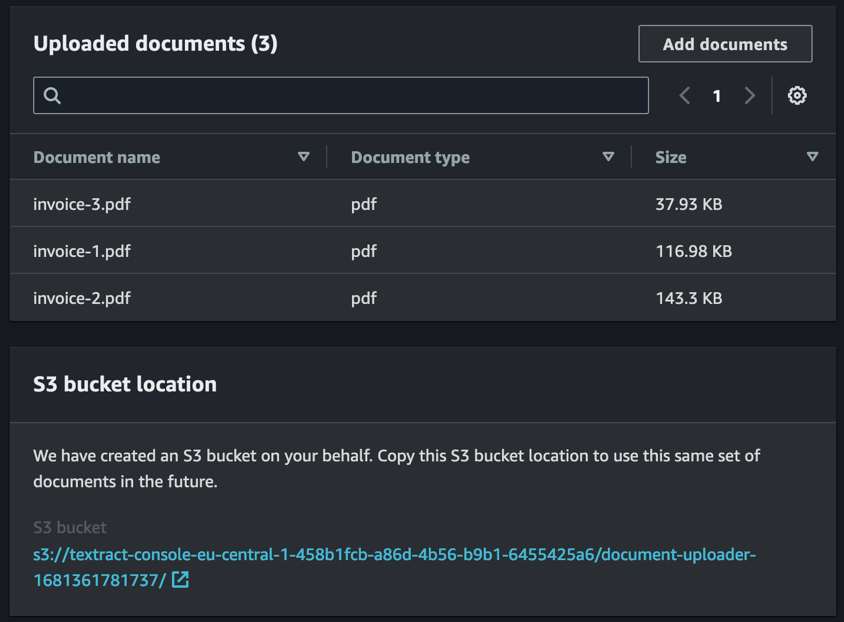
- Angiv derefter den Amazon Textract-funktion, du vil bruge til at behandle dine dokumenter.
Du kan kun vælge én funktion ad gangen for at behandle dine dokumenter. Hvis du har brug for at vurdere yderligere funktioner, skal du oprette en separat anmodning ved at vælge den ønskede funktion og uploade dokumenterne igen. Hvis AnalyseDokument – Forespørgsler funktionen er valgt, skal du angive de forespørgsler, du vil teste mod dine dokumenter. Du kan angive op til 30 forespørgsler ad gangen. Hvis de uploadede dokumenter indeholder filer med flere sider (PDF eller TIF), anvendes forespørgsler kun på den første side af hvert dokument. Henvise til Bedste praksis for forespørgsler at lære om, hvordan man konstruerer forespørgsler.
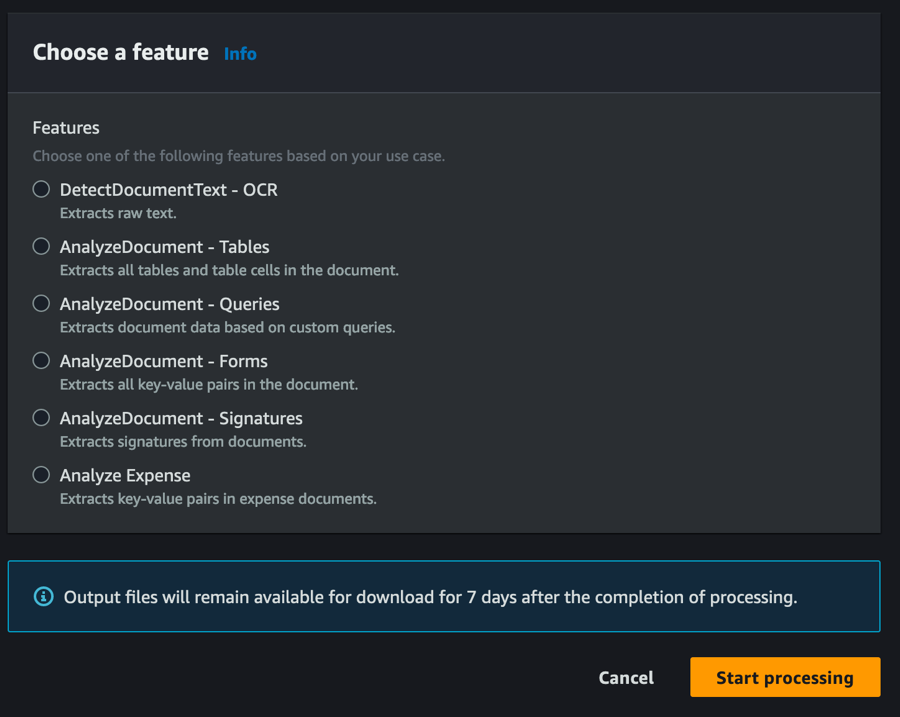
- Vælg Begynd at behandle at indsende dokumenterne til Amazon Textract til behandling.
Du kan spore dokumentstatus og downloade outputresultater af behandlede dokumenter i Indsendte dokumenter afsnit. Dette afsnit opdateres med jævne mellemrum, og du kan manuelt opdatere det for at se, om behandlingen er fuldført. Hvert dokument behandles individuelt, så du kan enten vælge dokumentet med Klar til at downloade status eller vent på, at alle dokumenter er færdigbehandlet for at downloade resultaterne. Outputtet af de behandlede dokumenter vil forblive tilgængeligt i op til 7 dage til download, hvorefter de udløber. Udløbne dokumenter vil blive slettet fra Indsendte dokumenter afsnit efter yderligere 7 dage (14 dage fra behandlet dato). Vi foreslår, at du downloader og bevarer output inden for 7-dages perioden.
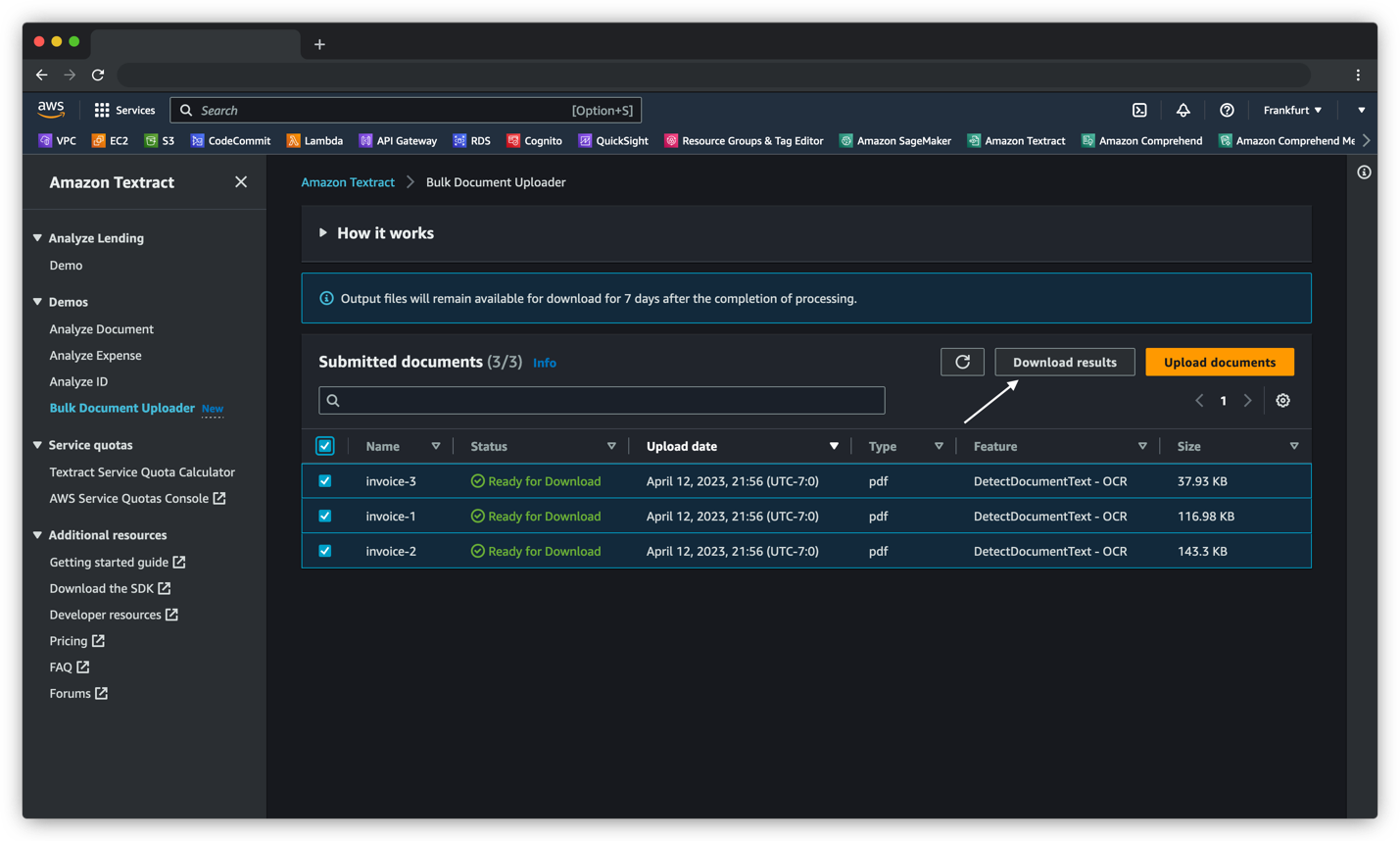
Konklusion
I dette indlæg annoncerede vi den nye Amazon Textract Bulk Document Uploader-funktion, som giver dig mulighed for hurtigt at behandle et stort antal dokumenter til evalueringsformål. Du kan bruge denne funktion til at evaluere Amazon Textract for en forudbestemt use case med dine dokumenter. For at lære mere om, hvordan du kan bruge Amazon Textract i din intelligente dokumentbehandlingsarbejdsbyrde, besøg Amazon Textract-funktioner , Kom godt i gang med Amazon Textract.
Om forfatterne
 Shashwat Sapre er Senior Technical Product Manager hos Amazon Textract-teamet. Han er fokuseret på at bygge maskinlæringsbaserede tjenester til AWS-kunder. I sin fritid kan han godt lide at læse om nye teknologier, rejse og udforske forskellige køkkener.
Shashwat Sapre er Senior Technical Product Manager hos Amazon Textract-teamet. Han er fokuseret på at bygge maskinlæringsbaserede tjenester til AWS-kunder. I sin fritid kan han godt lide at læse om nye teknologier, rejse og udforske forskellige køkkener.
 Anjan Biswas er Senior AI Services Solutions Architect med fokus på AI/ML og Data Analytics. Anjan er en del af det verdensomspændende AI-serviceteam og arbejder med kunder for at hjælpe dem med at forstå og udvikle løsninger på forretningsproblemer med AI og ML. Anjan har over 14 års erfaring med at arbejde med globale forsyningskæder, fremstillings- og detailorganisationer og hjælper aktivt kunder med at komme i gang og skalere på AWS AI-tjenester.
Anjan Biswas er Senior AI Services Solutions Architect med fokus på AI/ML og Data Analytics. Anjan er en del af det verdensomspændende AI-serviceteam og arbejder med kunder for at hjælpe dem med at forstå og udvikle løsninger på forretningsproblemer med AI og ML. Anjan har over 14 års erfaring med at arbejde med globale forsyningskæder, fremstillings- og detailorganisationer og hjælper aktivt kunder med at komme i gang og skalere på AWS AI-tjenester.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Udmøntning af fremtiden med Adryenn Ashley. Adgang her.
- Køb og sælg aktier i PRE-IPO-virksomheder med PREIPO®. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/introducing-amazon-textract-bulk-document-uploader-for-enhanced-evaluation-and-analysis/
- :har
- :er
- :hvor
- $OP
- 000
- 10
- 100
- 102
- 14
- 30
- 50
- 500
- 7
- a
- Om
- adgang
- Konto
- Handling
- aktivt
- Yderligere
- Derudover
- Efter
- igen
- mod
- AI
- AI-tjenester
- AI / ML
- Alle
- tillader
- også
- Amazon
- amazontekst
- Amazon Web Services
- an
- analyse
- analytics
- ,
- annoncerede
- enhver
- api
- API'er
- anvendt
- ER
- kunstig
- AS
- At
- automatisk
- til rådighed
- AWS
- BE
- Boks
- Bygning
- virksomhed
- by
- CAN
- kapaciteter
- tilfælde
- tilfælde
- kæde
- afgifter
- Vælg
- vælge
- kode
- sammenligning
- fuldføre
- computer
- tillid
- Konsol
- konstruere
- indeholder
- skabe
- oprettet
- For øjeblikket
- Kunder
- data
- Dataanalyse
- Dato
- Dage
- Demoer
- Afhængigt
- ønskes
- udvikle
- forskellige
- direkte
- visning
- dokumentet
- dokumenter
- downloade
- hver
- nemt
- let
- effektiv
- enten
- muliggør
- forbedret
- sikre
- Ether (ETH)
- evaluere
- evaluering
- eksisterende
- erfaring
- Udforskning
- ekstern
- Uddrag
- Feature
- Funktionalitet
- File (Felt)
- Filer
- Fornavn
- Fokus
- fokuserede
- efter
- Til
- format
- formularer
- fra
- få
- Global
- Have
- he
- hjælpe
- hjælpe
- højdepunkter
- hans
- Hvordan
- How To
- HTML
- http
- HTTPS
- læsbar
- if
- billede
- billeder
- importere
- vigtigt
- pålægge
- in
- Individuelt
- oplysninger
- initial
- i stedet
- Intelligent
- Intelligent dokumentbehandling
- beregnet
- indføre
- intuitiv
- IT
- jpg
- json
- Holde
- stor
- større
- senere
- lanceret
- LÆR
- læring
- GRÆNSE
- grænser
- placering
- maskine
- machine learning
- lave
- maerker
- leder
- manuelt
- Produktion
- mange
- maksimal
- Kan..
- tankerne
- ML
- mere
- mere effektiv
- flere
- skal
- Navigation
- Behov
- behøve
- Ny
- Nye teknologier
- nummer
- OCR
- of
- offline
- on
- engang
- ONE
- kun
- Produktion
- Option
- Indstillinger
- or
- organisationer
- output
- i løbet af
- egen
- side
- brød
- del
- sti
- udfører
- periode
- Tilladelser
- plato
- Platon Data Intelligence
- PlatoData
- Indlæg
- praksis
- bevare
- prissætning
- problemer
- behandle
- Processer
- forarbejdning
- Produkt
- produktchef
- programmatisk
- give
- forudsat
- giver
- formål
- forespørgsler
- Hurtig
- hurtigt
- Læsning
- region
- fast
- stole
- forblive
- Rapporter
- anmode
- svar
- Resultater
- detail
- gennemgå
- samme
- Scale
- Anden
- Sektion
- se
- valgt
- udvælgelse
- senior
- sendt
- adskille
- tjeneste
- Tjenester
- sæt
- bør
- Underskrifter
- Simpelt
- samtidigt
- Størrelse
- So
- Løsninger
- Kilde
- specificeret
- standard
- påbegyndt
- Status
- Steps
- opbevaring
- emne
- indsende
- efterfølgende
- sådan
- tyder
- forsyne
- forsyningskæde
- Understøttet
- Understøtter
- hold
- Teknisk
- Teknologier
- prøve
- end
- at
- The Source
- Them
- derefter
- derfor
- de
- denne
- Gennem
- tid
- til
- værktøjer
- TPS
- spor
- Transaktioner
- Traveling
- to
- ui
- under
- forstå
- I modsætning til
- opdateringer
- uploadet
- Uploading
- URL
- Brug
- brug
- brug tilfælde
- anvendte
- ved brug af
- via
- synlig
- Besøg
- visualisering
- vente
- ønsker
- we
- web
- webservices
- GODT
- hvornår
- som
- vilje
- med
- inden for
- uden
- arbejder
- virker
- skriver
- skrivning
- år
- dig
- Din
- zephyrnet
- Zip