Vi har for nylig annonceret den generelle tilgængelighed af Amazon OpenSearch Serverløs , en ny mulighed for Amazon OpenSearch Service der gør det nemt at køre store søge- og analysearbejdsbelastninger uden at skulle konfigurere, administrere eller skalere OpenSearch-klynger. Med OpenSearch Serverless får du de samme interaktive millisekunders svartider som OpenSearch Service med enkelheden i et serverløst miljø.
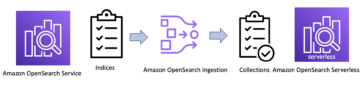
I dette indlæg lærer du, hvordan du migrerer dine eksisterende indekser fra et OpenSearch Service-administreret klyngedomæne til en serverløs samling ved hjælp af Logstash.
Med OpenSearch-domæner får du dedikerede, sikre klynger konfigureret og optimeret til dine arbejdsbelastninger på få minutter. Du har fuld kontrol over konfigurationen af computer-, hukommelses- og lagerressourcer i klynger for at optimere omkostninger og ydeevne for dine applikationer. OpenSearch Serverless giver en endnu enklere måde at køre søge- og analysearbejdsbelastninger på – uden nogensinde at skulle tænke på klynger. Du opretter blot en samling og en gruppe af indekser og kan begynde at indtage og forespørge dataene.
Løsningsoversigt
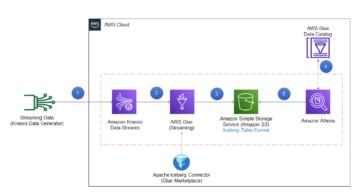
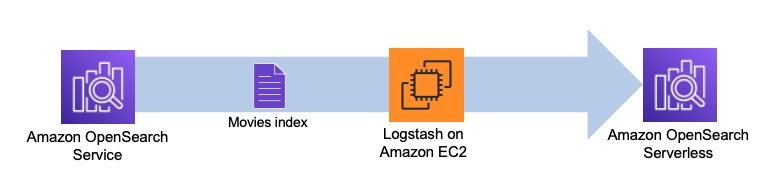
Logstash er open source-software, der giver ETL (ekstrahere, transformere og indlæse) til dine data. Du kan konfigurere Logstash til at oprette forbindelse til en kilde og en destination via input- og output-plugins. Ind imellem konfigurerer du filtre, der kan transformere dine data. Dette indlæg leder dig gennem de trin, du skal bruge for at konfigurere Logstash til at forbinde et OpenSearch Service-domæne (input) til en OpenSearch Serverless-samling (output).
Du indstiller kilde- og destinations-plugins i Logstash's konfigurationsfil. Konfigurationsfilen har sektioner til Input, Filterog Output. Når den er konfigureret, sender Logstash en anmodning til OpenSearch Service-domænet og læser dataene i henhold til den forespørgsel, du har lagt i input afsnit. Når data er læst fra OpenSearch Service, kan du eventuelt sende dem til næste trin Filter til transformationer såsom tilføjelse eller fjernelse af et felt fra inputdata eller opdatering af et felt med forskellige værdier. I dette eksempel vil du ikke bruge Filter plugin. Næste er Output plugin. Open source-versionen af Logstash (Logstash OSS) giver en bekvem måde at bruge bulk API til at uploade data til dine samlinger. OpenSearch Serverless understøtter logstash-output-opensearch output plugin, som understøtter AWS identitets- og adgangsstyring (IAM) legitimationsoplysninger til dataadgangskontrol.
Følgende diagram illustrerer vores løsningsarbejdsgang.
Forudsætninger
Før du går i gang, skal du sikre dig, at du har opfyldt følgende forudsætninger:
- Notér dit OpenSearch Service-domænes ARN, brugernavn og adgangskode.
- Opret en OpenSearch Serverless-samling. Hvis du er ny til OpenSearch Serverless, se Loganalyse på den nemme måde med Amazon OpenSearch Serverless for detaljer om, hvordan du opsætter din samling.
Konfigurer Logstash og input- og output-plugins til OpenSearch
Udfør følgende trin for at konfigurere Logstash og dine plugins:
- Hent
logstash-oss-with-opensearch-output-plugin. (Dette eksempel bruger distroen til macos-x64. For andre distros, se artefakter.) - Udpak den downloadede tarball:
- Opdatér
logstash-output-opensearchplugin til den nyeste version: - Installer
logstash-input-opensearchplugin:
Test plugin'et
Lad os gå i gang og se, hvordan plugin'et virker. Følgende konfigurationsfil henter data fra movies indekserer i dit OpenSearch Service-domæne og indekserer disse data i din OpenSearch Serverless-samling med samme indeksnavn, movies.
Opret en ny fil og tilføj følgende indhold, og gem derefter filen som opensearch-serverless-migration.conf. Angiv værdierne for OpenSearch Service-domæneslutpunktet under HOST, USERNAMEog PASSWORD i input sektionen og OpenSearch Serverless-indsamlingens slutpunktdetaljer under HOST sammen med REGION, AWS_ACCESS_KEY_IDog AWS_SECRET_ACCESS_KEY i output sektion.
Du kan angive en forespørgsel i input sektion af den foregående konfiguration. Det match_all forespørgsel matcher alle data i movies indeks. Du kan ændre forespørgslen, hvis du vil vælge en delmængde af dataene. Du kan også bruge forespørgslen til at parallelisere dataoverførslen ved at køre flere Logstash-processer med konfigurationer, der angiver forskellige dataudsnit. Du kan også parallelisere ved at køre Logstash-processer mod flere indekser, hvis du har dem.
Start Logstash
Brug følgende kommando til at starte Logstash:
Når du har kørt kommandoen, henter Logstash dataene fra kildeindekset fra dit OpenSearch Service-domæne og skriver til destinationsindekset i din OpenSearch Serverless-samling. Når dataoverførslen er fuldført, lukker Logstash ned. Se følgende kode:
Bekræft dataene i OpenSearch Serverless
Du kan bekræfte, at Logstash har kopieret alle dine data ved at sammenligne antallet af dokumenter i dit domæne og din samling. Kør følgende forespørgsel enten fra Dev værktøjer fanen eller med curl, postman, eller en lignende HTTP-klient. Følgende forespørgsel hjælper dig med at søge i alle dokumenter fra movies indeks og returnerer de øverste dokumenter sammen med optællingen. Som standard returnerer OpenSearch dokumentantallet op til et maksimum på 10,000. Tilføjelse af track_total_hits flag hjælper dig med at få det nøjagtige antal dokumenter, hvis dokumentantallet overstiger 10,000.
Konklusion
I dette indlæg migrerede du data fra dit OpenSearch Service-domæne til din OpenSearch Serverless-samling ved hjælp af Logstash's OpenSearch input- og output-plugins.
Hold øje med en række indlæg, der fokuserer på de forskellige muligheder, der er tilgængelige for dig til at opbygge effektive loganalyse- og søgeløsninger ved hjælp af OpenSearch Serverless. Du kan også henvise til Kom godt i gang med Amazon OpenSearch Serverless workshop for at vide mere om OpenSearch Serverless.
Hvis du har feedback om dette indlæg, så send det i kommentarfeltet. Hvis du har spørgsmål til dette indlæg, så start en ny tråd på Amazon OpenSearch Service-forum or kontakt AWS Support.
Om forfatterne
 Prashant Agrawal er en Sr. Search Specialist Solutions Architect med Amazon OpenSearch Service. Han arbejder tæt sammen med kunderne for at hjælpe dem med at migrere deres arbejdsbelastninger til skyen og hjælper eksisterende kunder med at finjustere deres klynger for at opnå bedre ydeevne og spare på omkostningerne. Før han kom til AWS, hjalp han forskellige kunder med at bruge OpenSearch og Elasticsearch til deres søge- og loganalysebrug. Når du ikke arbejder, kan du finde ham på rejse og udforske nye steder. Kort sagt, han kan lide at lave Spis → Rejser → Gentag.
Prashant Agrawal er en Sr. Search Specialist Solutions Architect med Amazon OpenSearch Service. Han arbejder tæt sammen med kunderne for at hjælpe dem med at migrere deres arbejdsbelastninger til skyen og hjælper eksisterende kunder med at finjustere deres klynger for at opnå bedre ydeevne og spare på omkostningerne. Før han kom til AWS, hjalp han forskellige kunder med at bruge OpenSearch og Elasticsearch til deres søge- og loganalysebrug. Når du ikke arbejder, kan du finde ham på rejse og udforske nye steder. Kort sagt, han kan lide at lave Spis → Rejser → Gentag.
 Jon Handler (@_searchgeek) er Sr. Principal Solutions Architect hos Amazon Web Services baseret i Palo Alto, CA. Jon arbejder tæt sammen med CloudSearch- og Elasticsearch-teamene og yder hjælp og vejledning til en bred vifte af kunder, som har søgearbejdsbelastninger, som de ønsker at flytte til AWS Cloud. Før han kom til AWS, omfattede Jons karriere som softwareudvikler fire års kodning af en storstilet e-handelssøgemaskine.
Jon Handler (@_searchgeek) er Sr. Principal Solutions Architect hos Amazon Web Services baseret i Palo Alto, CA. Jon arbejder tæt sammen med CloudSearch- og Elasticsearch-teamene og yder hjælp og vejledning til en bred vifte af kunder, som har søgearbejdsbelastninger, som de ønsker at flytte til AWS Cloud. Før han kom til AWS, omfattede Jons karriere som softwareudvikler fire års kodning af en storstilet e-handelssøgemaskine.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/migrate-your-indexes-to-amazon-opensearch-serverless-with-logstash/
- 000
- 10
- 100
- 28
- 39
- 7
- a
- Om
- adgang
- Ifølge
- opnå
- Handling
- Efter
- mod
- Agent
- Alle
- Amazon
- Amazon Web Services
- analytics
- ,
- annoncerede
- api
- applikationer
- tilgængelighed
- til rådighed
- AWS
- baseret
- før
- Bedre
- mellem
- bred
- bygge
- CA
- Karriere
- tilfælde
- CD
- lave om
- kunde
- nøje
- Cloud
- Cluster
- kode
- Kodning
- samling
- samlinger
- kommentarer
- sammenligne
- fuldføre
- Afsluttet
- Compute
- Konfiguration
- Tilslut
- indhold
- kontrol
- Praktisk
- Koste
- skabe
- Legitimationsoplysninger
- Kunder
- data
- dataadgang
- dedikeret
- Standard
- destination
- detaljer
- Udvikler
- forskellige
- deaktiveret
- dokumentet
- dokumenter
- gør
- domæne
- Domæner
- ned
- spiser
- ecommerce
- Effektiv
- enten
- Elasticsearch
- Endpoint
- Engine (Motor)
- Miljø
- Ether (ETH)
- Endog
- NOGENSINDE
- eksempel
- overstiger
- eksisterende
- Udforskning
- ekstrakt
- tilbagemeldinger
- felt
- File (Felt)
- Filtre
- Finde
- fokusering
- efter
- fra
- fuld
- Generelt
- få
- få
- gruppe
- have
- hjælpe
- hjulpet
- hjælper
- Hvordan
- How To
- HTTPS
- IAM
- Identity
- in
- medtaget
- indeks
- indekser
- Indeks
- info
- indgang
- installere
- interaktiv
- IT
- sammenføjning
- Kend
- storstilet
- seneste
- LÆR
- belastning
- Main
- lave
- maerker
- administrere
- lykkedes
- maksimal
- Hukommelse
- migrere
- millisekund
- minutter
- mere
- bevæge sig
- Film
- flere
- navn
- Behov
- Ny
- næste
- open source
- Open source software
- Optimer
- optimeret
- Option
- Indstillinger
- Os
- Andet
- Palo Alto
- Adgangskode
- ydeevne
- pipeline
- Steder
- plato
- Platon Data Intelligence
- PlatoData
- plugin
- Plugins
- Indlæg
- Indlæg
- forudsætninger
- Main
- Forud
- Processer
- give
- giver
- leverer
- sætte
- Spørgsmål
- rækkevidde
- Læs
- for nylig
- region
- register
- fjernet
- fjernelse
- gentag
- anmode
- Ressourcer
- svar
- afkast
- afkast
- Kør
- runner
- kører
- samme
- Gem
- Scale
- Søg
- søgemaskine
- Sektion
- sektioner
- sikker
- Series
- Serverless
- tjeneste
- Tjenester
- sæt
- Kort
- Luk ned
- lukker
- lignende
- enkelhed
- ganske enkelt
- Software
- løsninger
- Løsninger
- Kilde
- specialist
- Stage
- starte
- påbegyndt
- Steps
- opbevaring
- indsende
- Succesfuld
- sådan
- Understøtter
- hold
- The Source
- deres
- Gennem
- gange
- til
- top
- overførsel
- Transform
- transformationer
- rejse
- Traveling
- sand
- under
- Opdatering
- opdatering
- brug
- Bruger
- Værdier
- forskellige
- verificere
- udgave
- via
- web
- webservices
- som
- WHO
- vilje
- uden
- workflow
- arbejder
- virker
- værksted
- workshops
- skriver
- år
- Din
- zephyrnet