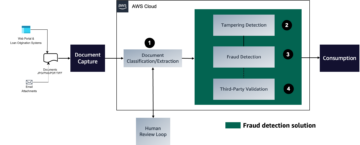
Amazon SageMaker giver en suite af indbyggede algoritmer, fortrænede modellerog forudbyggede løsningsskabeloner at hjælpe dataforskere og maskinlæringsudøvere (ML) med at komme i gang med at træne og implementere ML-modeller hurtigt. Du kan bruge disse algoritmer og modeller til både superviseret og uovervåget læring. De kan behandle forskellige typer inputdata, herunder tabel, billede og tekst.
Fra og med i dag tilbyder SageMaker fire nye indbyggede tabelformede datamodelleringsalgoritmer: LightGBM, CatBoost, AutoGluon-Tabular og TabTransformer. Du kan bruge disse populære, state-of-the-art algoritmer til både tabelklassificering og regressionsopgaver. De er tilgængelige via indbyggede algoritmer på SageMaker-konsollen såvel som gennem Amazon SageMaker JumpStart UI inde Amazon SageMaker Studio.
Det følgende er listen over de fire nye indbyggede algoritmer med links til deres dokumentation, eksempel på notesbøger og kilde.
| Dokumentation | Eksempel på notesbøger | Kilde |
| LightGBM-algoritme | Regression, Klassifikation | LightGBM |
| CatBoost-algoritme | Regression, Klassifikation | CatBoost |
| AutoGluon-tabelalgoritme | Regression, Klassifikation | AutoGluon-tabel |
| TabTransformer-algoritme | Regression, Klassifikation | TabTransformer |
I de følgende afsnit giver vi en kort teknisk beskrivelse af hver algoritme og eksempler på, hvordan man træner en model via SageMaker SDK eller SageMaker Jumpstart.
LightGBM
LightGBM er en populær og effektiv open source-implementering af algoritmen Gradient Boosting Decision Tree (GBDT). GBDT er en overvåget læringsalgoritme, der forsøger præcist at forudsige en målvariabel ved at kombinere et ensemble af estimater fra et sæt enklere og svagere modeller. LightGBM bruger yderligere teknikker til markant at forbedre effektiviteten og skalerbarheden af konventionel GBDT.
CatBoost
CatBoost er en populær og højtydende open source-implementering af GBDT-algoritmen. To kritiske algoritmiske fremskridt introduceres i CatBoost: Implementeringen af ordnet boosting, et permutationsdrevet alternativ til den klassiske algoritme og en innovativ algoritme til behandling af kategoriske funktioner. Begge teknikker blev skabt for at bekæmpe et forudsigelsesskift forårsaget af en særlig form for mållækage, der er til stede i alle eksisterende implementeringer af gradientforstærkende algoritmer.
AutoGluon-tabel
AutoGluon-tabel er et open source AutoML-projekt udviklet og vedligeholdt af Amazon, der udfører avanceret databehandling, deep learning og flerlags stak-ensembling. Den genkender automatisk datatypen i hver kolonne for robust dataforbehandling, herunder særlig håndtering af tekstfelter. AutoGluon passer til forskellige modeller lige fra hyldeforstærkede træer til tilpassede neurale netværksmodeller. Disse modeller er sammensat på en ny måde: modeller stables i flere lag og trænes på en lagvis måde, der garanterer, at rådata kan oversættes til forudsigelser af høj kvalitet inden for en given tidsbegrænsning. Overtilpasning afbødes gennem hele denne proces ved at opdele dataene på forskellige måder med omhyggelig sporing af eksempler, der ikke er synlige. AutoGluon er optimeret til ydeevne, og dens direkte brug har opnået adskillige top-3 og top-10 placeringer i datavidenskabskonkurrencer.
TabTransformer
TabTransformer er en ny dyb tabelformet datamodelleringsarkitektur til overvåget læring. TabTransformeren er bygget på selvopmærksomhedsbaserede transformere. Transformer-lagene transformerer indlejringer af kategoriske funktioner til robuste kontekstuelle indlejringer for at opnå højere forudsigelsesnøjagtighed. Desuden er de kontekstuelle indlejringer lært fra TabTransformer meget robuste over for både manglende og støjende datafunktioner og giver bedre fortolkning. Denne model er et produkt af nyere Amazon Videnskab forskning (papir og officiel blogindlæg her) og er blevet bredt vedtaget af ML-samfundet med forskellige tredjepartsimplementeringer (Keras, AutoGluon,) og sociale mediefunktioner som f.eks tweets, mod datavidenskab, medium og Kaggle.
Fordele ved SageMaker indbyggede algoritmer
Når du vælger en algoritme til din særlige type problem og data, er brugen af en SageMaker indbygget algoritme den nemmeste mulighed, fordi det kommer med følgende store fordele:
- De indbyggede algoritmer kræver ingen kodning for at begynde at køre eksperimenter. De eneste input, du skal angive, er data, hyperparametre og computerressourcer. Dette giver dig mulighed for at køre eksperimenter hurtigere med mindre overhead til sporing af resultater og kodeændringer.
- De indbyggede algoritmer kommer med parallelisering på tværs af flere computerforekomster og GPU-understøttelse lige fra kassen for alle anvendelige algoritmer (nogle algoritmer er muligvis ikke inkluderet på grund af iboende begrænsninger). Hvis du har mange data til at træne din model med, kan de fleste indbyggede algoritmer nemt skaleres for at imødekomme efterspørgslen. Selvom du allerede har en fortrænet model, kan det stadig være lettere at bruge dens følge i SageMaker og indtaste de hyperparametre, du allerede kender, i stedet for at overføre den og selv skrive et træningsscript.
- Du er ejer af de resulterende modelartefakter. Du kan tage den model og implementere den på SageMaker for flere forskellige slutningsmønstre (tjek alle tilgængelige implementeringstyper) og nem slutpunktsskalering og -administration, eller du kan implementere det, hvor du ellers har brug for det.
Lad os nu se, hvordan man træner en af disse indbyggede algoritmer.
Træn en indbygget algoritme ved hjælp af SageMaker SDK
For at træne en udvalgt model skal vi have denne models URI, såvel som for træningsscriptet og containerbilledet, der bruges til træning. Heldigvis afhænger disse tre input udelukkende af modelnavnet, versionen (for en liste over de tilgængelige modeller, se JumpStart tilgængelig model tabel), og den type instans, du vil træne på. Dette er demonstreret i følgende kodestykke:
train_model_id ændres til lightgbm-regression-model hvis vi har at gøre med et regressionsproblem. ID'erne for alle de andre modeller introduceret i dette indlæg er angivet i følgende tabel.
| Model | Problemtype | Model ID |
| LightGBM | Klassifikation | lightgbm-classification-model |
| . | Regression | lightgbm-regression-model |
| CatBoost | Klassifikation | catboost-classification-model |
| . | Regression | catboost-regression-model |
| AutoGluon-tabel | Klassifikation | autogluon-classification-ensemble |
| . | Regression | autogluon-regression-ensemble |
| TabTransformer | Klassifikation | pytorch-tabtransformerclassification-model |
| . | Regression | pytorch-tabtransformerregression-model |
Vi definerer derefter, hvor vores input er på Amazon Simple Storage Service (Amazon S3). Vi bruger et offentligt eksempeldatasæt til dette eksempel. Vi definerer også, hvor vi vil have vores output til at gå, og henter standardlisten over hyperparametre, der er nødvendige for at træne den valgte model. Du kan ændre deres værdi efter din smag.
Til sidst instansierer vi en SageMaker Estimator med alle de hentede inputs og igangsætte træningsjobbet med .fit, og giver det vores træningsdatasæt URI. Det entry_point det angivne script er navngivet transfer_learning.py (det samme for andre opgaver og algoritmer), og inputdatakanalen videregivet til .fit skal navngives training.
Bemærk at du kan træne indbyggede algoritmer med SageMaker automatisk model tuning at vælge de optimale hyperparametre og yderligere forbedre modellens ydeevne.
Træn en indbygget algoritme ved hjælp af SageMaker JumpStart
Du kan også træne alle disse indbyggede algoritmer med nogle få klik via SageMaker JumpStart UI. JumpStart er en SageMaker-funktion, der giver dig mulighed for at træne og implementere indbyggede algoritmer og præ-trænede modeller fra forskellige ML-frameworks og modelhubs gennem en grafisk grænseflade. Det giver dig også mulighed for at implementere fuldt udbyggede ML-løsninger, der samler ML-modeller og forskellige andre AWS-tjenester for at løse en målrettet use case.
For mere information henvises til Kør tekstklassificering med Amazon SageMaker JumpStart ved hjælp af TensorFlow Hub og Hugging Face-modeller.
Konklusion
I dette indlæg annoncerede vi lanceringen af fire kraftfulde nye indbyggede algoritmer til ML på tabeldatasæt, der nu er tilgængelige på SageMaker. Vi gav en teknisk beskrivelse af, hvad disse algoritmer er, samt et eksempel på et træningsjob for LightGBM ved hjælp af SageMaker SDK.
Medbring dit eget datasæt og prøv disse nye algoritmer på SageMaker, og tjek eksemplerne på notebooks for at bruge indbyggede algoritmer, der er tilgængelige på GitHub.
Om forfatterne
![]() Dr. Xin Huang er en Applied Scientist for Amazon SageMaker JumpStart og Amazon SageMaker indbyggede algoritmer. Han fokuserer på at udvikle skalerbare maskinlæringsalgoritmer. Hans forskningsinteresser er inden for området naturlig sprogbehandling, forklarlig dyb læring på tabeldata og robust analyse af ikke-parametrisk rum-tid-klynger. Han har publiceret mange artikler i ACL, ICDM, KDD-konferencer og Royal Statistical Society: Series A journal.
Dr. Xin Huang er en Applied Scientist for Amazon SageMaker JumpStart og Amazon SageMaker indbyggede algoritmer. Han fokuserer på at udvikle skalerbare maskinlæringsalgoritmer. Hans forskningsinteresser er inden for området naturlig sprogbehandling, forklarlig dyb læring på tabeldata og robust analyse af ikke-parametrisk rum-tid-klynger. Han har publiceret mange artikler i ACL, ICDM, KDD-konferencer og Royal Statistical Society: Series A journal.
![]() Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker JumpStart og Amazon SageMaker indbyggede algoritmer og hjælper med at udvikle machine learning algoritmer. Han er en aktiv forsker i maskinlæring og statistisk inferens og har publiceret mange artikler i NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP konferencer.
Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker JumpStart og Amazon SageMaker indbyggede algoritmer og hjælper med at udvikle machine learning algoritmer. Han er en aktiv forsker i maskinlæring og statistisk inferens og har publiceret mange artikler i NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP konferencer.
 João Moura er AI/ML Specialist Solutions Architect hos Amazon Web Services. Han er mest fokuseret på NLP use-cases og hjælper kunder med at optimere Deep Learning modeltræning og implementering. Han er også en aktiv fortaler for lavkode ML-løsninger og ML-specialiseret hardware.
João Moura er AI/ML Specialist Solutions Architect hos Amazon Web Services. Han er mest fokuseret på NLP use-cases og hjælper kunder med at optimere Deep Learning modeltræning og implementering. Han er også en aktiv fortaler for lavkode ML-løsninger og ML-specialiseret hardware.
- Coinsmart. Europas bedste Bitcoin og Crypto Exchange.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. FRI ADGANG.
- CryptoHawk. Altcoin radar. Gratis prøveversion.
- Kilde: https://aws.amazon.com/blogs/machine-learning/new-built-in-amazon-sagemaker-algorithms-for-tabular-data-modeling-lightgbm-catboost-autogluon-tabular-and-tabtransformer/
- "
- 100
- a
- opnå
- opnået
- tværs
- aktiv
- Yderligere
- fremskreden
- fremskridt
- mod
- algoritme
- algoritmisk
- algoritmer
- Alle
- tillader
- allerede
- alternativ
- Amazon
- Amazon Web Services
- analyse
- annoncerede
- anvendelig
- anvendt
- arkitektur
- OMRÅDE
- Automatisk Ur
- automatisk
- til rådighed
- AWS
- fordi
- fordele
- Bedre
- Hjulpet
- fremme
- Boks
- indbygget
- forsigtig
- tilfælde
- forårsagede
- lave om
- Classic
- klassificering
- kode
- Kodning
- Kolonne
- Kom
- samfund
- Konkurrencer
- Compute
- konferencer
- Konsol
- Container
- skabe
- oprettet
- kritisk
- For øjeblikket
- skik
- Kunder
- data
- databehandling
- datalogi
- beskæftiger
- beslutning
- dyb
- Efterspørgsel
- demonstreret
- indsætte
- implementering
- implementering
- beskrivelse
- udvikle
- udviklet
- udvikling
- forskellige
- Docker
- hver
- nemt
- effektivitet
- effektiv
- Endpoint
- skøn
- eksempel
- eksempler
- eksisterende
- Ansigtet
- Feature
- Funktionalitet
- Fields
- fokuserede
- fokuserer
- efter
- rammer
- fra
- yderligere
- Endvidere
- GPU
- Håndtering
- Hardware
- højde
- hjælpe
- hjælpe
- hjælper
- link.
- høj kvalitet
- højere
- stærkt
- Hvordan
- How To
- HTTPS
- Hub
- billede
- implementering
- Forbedre
- medtaget
- Herunder
- oplysninger
- iboende
- innovativ
- indgang
- instans
- interesser
- grænseflade
- IT
- Job
- tidsskrift
- Kend
- Sprog
- lancere
- lærte
- læring
- links
- Liste
- Børsnoterede
- maskine
- machine learning
- større
- ledelse
- måde
- Medier
- medium
- ML
- model
- modeller
- mere
- mest
- flere
- Natural
- netværk
- Optimer
- optimeret
- Option
- Andet
- egen
- ejer
- særlig
- Passing
- ydeevne
- Populær
- vigtigste
- forudsige
- forudsigelse
- Forudsigelser
- præsentere
- Problem
- behandle
- forarbejdning
- Produkt
- projekt
- give
- forudsat
- giver
- offentlige
- offentliggjort
- hurtigt
- spænder
- Raw
- anerkender
- region
- kræver
- forskning
- Ressourcer
- resulterer
- Resultater
- Kør
- kører
- samme
- Skalerbarhed
- skalerbar
- Scale
- skalering
- Videnskab
- Videnskabsmand
- forskere
- SDK
- valgt
- Series
- Serie A
- Tjenester
- sæt
- flere
- skifte
- Simpelt
- So
- Social
- sociale medier
- Samfund
- løsninger
- Løsninger
- SOLVE
- nogle
- særligt
- specialist
- stable
- starte
- påbegyndt
- state-of-the-art
- statistiske
- Stadig
- opbevaring
- support
- mål
- målrettet
- opgaver
- Teknisk
- teknikker
- tredjepart
- tre
- Gennem
- hele
- tid
- i dag
- sammen
- Sporing
- Tog
- Kurser
- Transform
- typer
- ui
- enestående
- brug
- brugssager
- værdi
- forskellige
- udgave
- måder
- web
- webservices
- Hvad
- inden for
- Din