Har du nogensinde ventet på den ene dyre pakke, der viser "afsendt", men du har ingen anelse om, hvor den er? Sporingshistorikken stoppede med at opdatere for fem dage siden, og du har næsten mistet håbet. Men vent, 11 dage senere har du den lige ved døren. Du ville ønske, at sporbarheden kunne have været bedre for at befri dig fra al den ængstelige venten. Det er her "observabilitet" kommer i spil.
I et teknisk landskab vil du gerne undgå, at dette sker med din software eller datasystemer. Og derved anvender du overvågningsværktøjer, som indsamler logfiler og metrics for dine systemer og informerer dig om deres interne tilstand. Overvågning fungerer bedst, når du ønsker, at dine systemer skal informere dig om, hvad fejlen er, hvor og hvornår den skete, men den fortæller dig ikke, hvordan du skal løse fejlen.
For mere end et årti siden manglede overvågningsværktøjer konteksten og forudseenheden af underliggende systemproblemer, og teams ville være begrænset til fejlretning af daglige driftsfejl. I dag arbejder og lever vi i en distribueret verden af mikrotjenester og datapipelines; selv at bruge flere overvågningsværktøjer hjælper dig ikke med at besvare dine forretningsspørgsmål som "Hvorfor er min ansøgning altid langsom?" eller "På hvilket stadium opstod problemet, og hvor dybt er det i stakken?" eller "Hvordan kan jeg forbedre miljøets overordnede ydeevne?" Det bliver nødvendigt at være proaktiv i at træffe disse beslutninger og have en overordnet synlighed af dine systemer, applikationer og data.
Denne blogindlæg af Etsy blev udgivet for et årti siden, og det fastslår selve faktum i andet afsnit:
"Anvendelsesmålinger er normalt de sværeste, men dog vigtigste, af de tre. De er meget specifikke for din virksomhed, og de ændrer sig, efterhånden som dine applikationer ændrer sig (og Etsy ændrer sig meget)."
Så hvordan måler vi alt og noget? Vi starter med observerbarhed.
Hvad er observerbarhed?
Udtrykket "observerbarhed" var opfundet af Rudolf Emil Kálmán i 1960 i hans ingeniørpapir for at beskrive matematiske kontrolsystemer. Han definerede det som et mål for, hvor godt interne tilstande i et system kan udledes af viden om dets eksterne output. Men lyder det ikke som overvågning? Grundlæggende, ja, det er overvågning.
I disse dage er observerbarhed blevet et ret varmt emne. Ifølge flere markedsundersøgelser er det en milliardplatform. Mange organisationer har taget konceptet til sig og brugt det som en ramme for ende-til-ende synlighed af deres distribuerede systemer og pipelines. Observerbarhed forveksles dog med overvågning. Indtil videre kan jeg sige, at overvågning er en delmængde af observerbarhed, hvor observerbarhed er ét stort paraplybegreb.
Observerbarhed giver mulighed for distribueret sporing gennem indsamling og aggregering af spor, logfiler og metrikker. Lad os se, hvad disse udleder:
- Spor: Når et system modtager en forespørgsel, fortæller spor dig, hvordan den forespørgsel flyder gennem hele dets livscyklus fra kilden til destinationen. Spor er repræsenteret ved "spænd". Et spor er et træ af spænd, og et spænd er en enkelt operation i et spor. De hjælper dig med at lokalisere fejl, latenstid eller flaskehalse i systemet.
- Logs: Disse er maskingenererede tidsstemplede hændelser, der fortæller dig om de operationer eller ændringer, der skete i systemet. Logfiler bruges ofte til at forespørge om disse fejl eller ændringer i systemet.
- Metrics: Disse giver kvantitativ indsigt i CPU, hukommelse, diskbrug og hvordan systemet præsterer over en tidsperiode.
Disse attributter forbedrer overvågningsrammen med sporbarhed. Sporbarhed giver dig linserne til at spore en anmodning, der foretager et opkald til dit system, hvor lang tid det tager at gå fra en komponent til en anden, hvilke andre tjenester den påkalder, kaster den nogen fejl, hvilke logfiler det producerer, hvilken tilstand den er i, hvornår startede og sluttede det, hvad er tidslinjen det forblev i dit system osv. Når du indsamler, aggregerer og analyserer disse spor, er du i stand til at træffe værdifulde informerede beslutninger som kundetidslinje på et e-handelswebsted , hvor lang tid det tog dem at søge efter et produkt, hvor lang tid de så produktet, indlæste HTML-siden de komplette detaljer som billeder eller indlejrede videoer, hvor lang tid det tog systemet at godkende og behandle betalingen osv.
Hvad opnår vi med observerbarhed i et distribueret miljø?
Udviklingen af distribuerede systemer begyndte, da organisationer begyndte at bevæge sig væk fra deres centraliserede monolitarkitektur til en distribueret og decentraliseret mikroservicearkitektur. Og dette er stadig et igangværende arbejde, hvor mange organisationer omfavner systemers og applikationers mikroservicekarakter. Og alt dette kan tilskrives big data og skalering. Håndtering af et distribueret miljø kræver kontinuerlig læring, yderligere arbejdsstyrke, ændringer i rammer og politikker, it-styring og så videre. Det er i sandhed en stor forandring.
Tidligere, i det begrænsede monolitiske miljø, boede hardware, software, data og databaser alle under ét enkelt tag. Med fremkomsten af big data i 2000'erne begyndte overvågnings- og skaleringssystemer at blive en stor bekymring. Ofte brugte organisationer forskellige overvågningsværktøjer til at imødekomme behovene for deres forskellige applikationer. Som et resultat blev det hurtigt en operationel overhead med dårlig modstandskraft, synlighed og pålidelighed.
Alle disse spørgsmål gav anledning til vedtagelsen af observerbarhed. I dag findes der flere observerbarhedsværktøjer til sikkerhed, netværk, applikationer og datapipelines til distribueret sporing i et komplekst miljø. De eksisterer side om side med deres fætter, overvågningsværktøjerne, og udnytter løftestangen ved at indsamle oplysningerne fra deres fætter og samle yderligere oplysninger fra deres egne sporingsdata.
Der er en masse bevægelige komponenter i alle disse systemer, hvis spor, når de fanges, kan illustrere historien om de 5 W'er: hvornår, hvor, hvorfor, hvad og hvordan. For eksempel går du ind på DATAVERSITYs hjemmeside klokken 1:43 for at læse nogle blogindlæg. Når du rammer dataversity.net, bliver HTTP-anmodningen logget ind i systemet. Du begynder at søge efter et blogindlæg og går til et Data Governance-indlæg, hvor du bruger 17 minutter på at læse det indlæg, og derefter lukker du din fane klokken 2
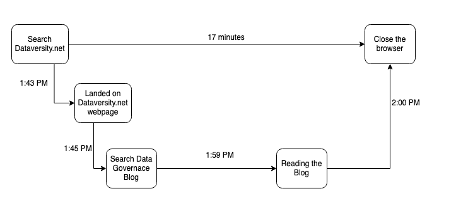
Der vil også blive foretaget andre opkald til netværkssystemet til netværkspakkefangst. Observerbarhedsværktøjer samler alle spændene og forener dem i et spor eller spor, så du kan se den sti, den dannede i løbet af sin livscyklus. Hvis du har et problem som netværksforsinkelse eller en systemdefekt, er det nu nemmere at dissekere (skrælle løget) og fejlfinde problemet (fejl i hvilket lag).
Nu i et stort distribueret miljø, når dine applikationer modtager millioner af anmodninger, vokser sporingsdataene i enorm mængde. Indsamling og analyse af disse spor er dyrt for lagerforbrug og dataoverførsel. Så for at spare omkostninger bliver sporingsdataene samplet, for i de fleste tilfælde har ingeniørhold kun brug for nogle af brikkerne for at undersøge, hvad der gik galt, eller hvad er fejlmønsteret.
Med det lille eksempel forstår vi, at vi får meget dybere indsigt i vores systemer. Så i betragtning af en større skala af systemer, kan ingeniørteams fange og arbejde på de samplede data for at forbedre den nuværende struktur af systemet, anvende eller trække nye komponenter tilbage, tilføje endnu et sikkerhedslag, fjerne flaskehalse og så videre.
Skal organisationer vælge observerbarhed?
Vi bør alle forstå, at slutmålene er bedre brugeroplevelse og større brugertilfredshed. Og vejen til at nå disse mål kan gøres lettere med en automatiseret og proaktiv observerbarhedsramme. Etablering af en kultur for kontinuerlig forbedring og optimering betragtes som den optimale forretnings- og ledelsestilgang.
I denne tidsalder med digital transformation er observerbarhed blevet et must-have, for at en virksomhed kan få succes på sin digitale rejse. Observerbarheden giver dig indsigtsfulde spor og manøvrerer dig også til at være datainformeret i stedet for blot datadrevet.
Konklusion
Selvom vi har brugt termerne overvågning og observerbarhed i flæng, har vi set, at mens overvågning hjælper dig med information om systemets helbred og hændelser, der sker på det, gør observerbarhed det lettere for dig at drage slutninger baseret på beviser indsamlet fra dybere lag af en ende- to-end miljø.
Observerbarhed er og kan også opfattes som en komponent i Data Governance-rammen. I denne generation, hvor den stadigt stigende datamængde ligger på et netværk af råvarehardware, er det afgørende at holde arkitekturerne så enkle som muligt. Og åbenbart bliver det en umulig opgave at styre miljøet ned ad linjen. Implementering af passende og automatiserede styringspolitikker og regler for at holde dit store netværk af systemer, pipelines og data ryddet opfordrer derved til handling før end senere.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- I stand
- Om
- Ifølge
- opnå
- opnå
- Handling
- Yderligere
- yderligere information
- vedtage
- vedtaget
- Vedtagelse
- advent
- Alle
- tillader
- altid
- analysere
- analysere
- ,
- En anden
- besvare
- Anvendelse
- applikationer
- Indløs
- tilgang
- passende
- arkitektur
- attributter
- autentificere
- Automatiseret
- undgå
- baseret
- I bund og grund
- fordi
- bliver
- bliver
- begyndte
- BEDSTE
- Bedre
- Big
- Big data
- Blog
- Blogindlæg
- flaskehalse
- virksomhed
- ringe
- Opkald
- fange
- tilfælde
- centraliseret
- lave om
- Ændringer
- Vælg
- Luk
- indsamler
- Indsamling
- råvare
- fuldføre
- komplekse
- komponent
- komponenter
- Konceptet
- Bekymring
- forvirret
- betragtes
- Overvejer
- forbrug
- sammenhæng
- kontinuerlig
- kontrol
- Omkostninger
- kunne
- CPU
- Medarbejder kultur
- Nuværende
- kunde
- data
- datastyret
- databaser
- DATAVERSITET
- dag til dag
- Dage
- årti
- decentral
- afgørelser
- dyb
- dybere
- definerede
- beskrive
- destination
- detaljer
- DID
- forskellige
- digital
- Digital Transformation
- distribueret
- distribuerede systemer
- Er ikke
- ned
- i løbet af
- e-handel
- lettere
- indlejret
- omfavne
- muliggør
- ende til ende
- Engineering
- Miljø
- fejl
- fejl
- oprettelse
- etc.
- Endog
- begivenheder
- NOGENSINDE
- stadigt stigende
- at alt
- bevismateriale
- evolution
- eksempel
- dyrt
- erfaring
- ekstern
- letter
- strømme
- dannet
- Framework
- rammer
- fra
- generation
- få
- Go
- Mål
- regeringsførelse
- større
- Vokser
- skete
- Happening
- Hardware
- Helse
- hjælpe
- hjælper
- historie
- Hit
- håber
- HOT
- Hvordan
- How To
- Men
- HTML
- HTTPS
- kæmpe
- billeder
- gennemføre
- vigtigt
- umuligt
- Forbedre
- in
- oplysninger
- informeret
- indsigt
- interne
- undersøge
- påberåber sig
- spørgsmål
- spørgsmål
- IT
- It-forvaltning
- rejse
- Holde
- viden
- landskab
- stor
- større
- Latency
- lag
- lag
- Leadership" (virkelig menneskelig ledelse)
- læring
- linser
- Leverage
- livscyklus
- Limited
- Line (linje)
- leve
- belastning
- Lang
- Lot
- lavet
- lave
- maerker
- Making
- administrere
- ledelse
- styring
- mange
- Marked
- matematiske
- max-bredde
- måle
- Hukommelse
- Metrics
- microservices
- millioner
- minutter
- overvågning
- Monolithic
- mest
- bevæge sig
- flytning
- flere
- Must-have
- Natur
- nødvendig
- Behov
- behov
- netto
- netværk
- netværkssystem
- Ny
- ONE
- drift
- operationelle
- Produktion
- optimal
- optimering
- organisationer
- Andet
- samlet
- egen
- Papir
- sti
- Mønster
- betaling
- opfattet
- ydeevne
- udfører
- periode
- stykker
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Leg
- politikker
- fattige
- mulig
- Indlæg
- Indlæg
- Proaktiv
- Problem
- behandle
- Produkt
- Progress
- give
- giver
- leverer
- offentliggjort
- kvantitativ
- Spørgsmål
- hellere
- Læs
- Læsning
- modtage
- modtager
- pålidelighed
- Fjern
- repræsenteret
- anmode
- anmodninger
- Kræver
- modstandskraft
- begrænset
- resultere
- Rise
- tag
- regler
- tilfredshed
- Gem
- Scale
- skalering
- Søg
- søgning
- Anden
- sikkerhed
- Tjenester
- flere
- bør
- Shows
- Simpelt
- enkelt
- langsom
- lille
- So
- Software
- SOLVE
- nogle
- Snart
- Lyd
- Kilde
- spændvidder
- specifikke
- tilbringe
- stable
- Stage
- starte
- påbegyndt
- Tilstand
- Stater
- opholdt sig
- Stadig
- stoppet
- opbevaring
- Story
- struktur
- vellykket
- systemet
- Systemer
- Tag
- tager
- Opgaver
- hold
- Teknisk
- vilkår
- oplysninger
- The Source
- deres
- derved
- tre
- Gennem
- hele
- tid
- tidslinje
- til
- i dag
- værktøjer
- emne
- spore
- Sporbarhed
- Sporing
- Sporing
- overførsel
- Transformation
- paraply
- under
- underliggende
- forstå
- opdatering
- Brug
- Bruger
- Brugererfaring
- sædvanligvis
- Værdifuld
- forskellige
- Videoer
- synlighed
- afgørende
- bind
- vente
- Venter
- Hjemmeside
- Hvad
- Hvad er
- som
- mens
- vilje
- inden for
- Arbejde
- Workforce
- virker
- world
- ville
- Forkert
- Din
- zephyrnet











