Gartner, Inc. anslår det dårlige dataomkostninger organisationer et gennemsnit på 12.9 millioner USD årligt.
Vi håndterer Petabytes af data dagligt, og datakvalitetsproblemer er almindelige med så store datamængder. Dårlige data koster organisationer penge, omdømme og tid. Derfor er det meget vigtigt at overvåge og validere datakvaliteten løbende.
Dårlige data omfatter unøjagtige oplysninger, manglende data, forkerte oplysninger, ikke-overensstemmende data og duplikerede data. Dårlige data vil resultere i forkert dataanalyse, hvilket resulterer i dårlige beslutninger og ineffektive strategier.
Experian datakvalitet fandt ud af, at den gennemsnitlige virksomhed mister 12 % af sin omsætning på grund af utilstrækkelige data. Udover penge lider virksomhederne også tab af spildtid.
Identifikation af uregelmæssigheder i data før behandling vil hjælpe organisationer med at få mere værdifuld indsigt i deres kundeadfærd og hjælper med at reducere omkostninger.
Store forventningsbibliotek hjælper organisationer med at verificere og hævde sådanne uregelmæssigheder i dataene med mere end 200+ out-of-the-box regler, der er let tilgængelige.
Great Expectations er et open source Python-bibliotek, der hjælper os med at validere data. Store forventninger give et sæt metoder eller funktioner til hjælpe dataingeniørerne hurtigt validere et givet datasæt.
I denne artikel vil vi se på de trin, der er involveret i at validere dataene ved Great Expectations-biblioteket.
GE er som enhedstest for data. GE giver påstande kaldet Forventninger for at anvende nogle regler på de data, der testes. For eksempel må police-id/-nummer ikke være tomt for et forsikringsdokument. For at konfigurere og udføre GE skal du følge nedenstående trin. Selvom der er flere måder at arbejde med GE på (ved at bruge dets CLI), vil jeg forklare den programmatiske måde at sætte ting op i denne artikel. Al kildekoden forklaret i denne artikel er tilgængelig i denne GitHub repo.
Trin 1: Konfigurer Data Config
GE har et koncept med butikker. Butikker er intet andet end den fysiske placering på disken, hvor den kan gemme forventningerne (regler/påstande), kørselsdetaljer, checkpointdetaljer, valideringsresultater og datadokumenter (statiske HTML-versioner af valideringsresultaterne). Klik her for at lære mere om butikker.
GE understøtter forskellige butiksbackends. I denne artikel bruger vi fillagerbackend og standardindstillinger. GE understøtter andre butiksbackends som AWS (Amazon Web Services) S3, Azure Blobs, PostgreSQL osv. Se dette til vide mere om backends. Kodestykket nedenfor viser en meget simpel datakonfiguration:
STORE_FOLDER = "/Users/saisyam/work/github/great-expectations-sample/ge_data"
#Setup data config
data_context_config = DataContextConfig( datasources = {}, store_backend_defaults = FilesystemStoreBackendDefaults(root_directory=STORE_FOLDER)
) context = BaseDataContext(project_config = data_context_config)
Ovenstående konfiguration bruger File Store-backend med standardindstillinger. GE vil automatisk oprette de nødvendige mapper, der er nødvendige for at leve op til forventningerne. Vi tilføjer datakilder i vores næste trin.
Trin 2: Konfigurer datakildekonfiguration
GE understøtter tre typer datakilder:
- pandas
- Spark
- SQLAlchemy
Datakildekonfiguration fortæller GE at bruge en specifik eksekveringsmotor til at behandle det leverede datasæt. Hvis du f.eks. konfigurerer din datakilde til at bruge Pandas-udførelsesmotoren, skal du levere en Pandas-dataramme med data til GE for at leve op til dine forventninger. Nedenfor er et eksempel på brug af Pandas som datakilde:
datasource_config = { "name": "sales_datasource", "class_name": "Datasource", "module_name": "great_expectations.datasource", "execution_engine": { "module_name": "great_expectations.execution_engine", "class_name": "PandasExecutionEngine", }, "data_connectors": { "default_runtime_data_connector_name": { "class_name": "RuntimeDataConnector", "module_name": "great_expectations.datasource.data_connector", "batch_identifiers": ["default_identifier_name"], }, },
}
context.add_datasource(**datasource_config)
Vær sød at henvise til denne dokumentation for mere information om datakilder.
Trin 3: Opret en forventningspakke og tilføj forventninger
Dette trin er den afgørende del. I dette trin vil vi skabe en suite og tilføje forventninger til suiten. Du kan betragte en suite som en gruppe af forventninger, der vil køre som en batch. De forventninger, vi skaber her, er at validere en eksempelsalgsrapport. Du kan downloade salg.csv fil.
Kodestykket nedenfor viser, hvordan du opretter en suite og tilføjer forventninger. Vi vil tilføje to forventninger til vores suite.
# Create expectations suite and add expectations
suite = context.create_expectation_suite(expectation_suite_name="sales_suite", overwrite_existing=True) expectation_config_1 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_in_set", kwargs={ "column": "product_group", "value_set": ["PG1", "PG2", "PG3", "PG4", "PG5", "PG6"] }
) suite.add_expectation(expectation_configuration=expectation_config_1) expectation_config_2 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_unique", kwargs={ "column": "id" }
) suite.add_expectation(expectation_configuration=expectation_config_2)
context.save_expectation_suite(suite, "sales_suite")
Den første forventning, "expect_column_values_to_be_in_set" kontrollerer, om kolonnens (product_group) værdier er lig med nogen af værdierne i det givne værdisæt. Den anden forventning kontrollerer, om "id" kolonneværdierne er unikke.
Når forventningerne er tilføjet og gemt, kan vi nu køre disse forventninger på et datasæt, som vi vil se i trin 4.
Trin 4: Indlæs og valider dataene
I dette trin indlæser vi vores CSV-fil i pandas.DataFrame og opretter et kontrolpunkt for at køre de forventninger, vi oprettede ovenfor.
# load and validate data
df = pd.read_csv("./sales.csv") batch_request = RuntimeBatchRequest( datasource_name="sales_datasource", data_connector_name="default_runtime_data_connector_name", data_asset_name="product_sales", runtime_parameters={"batch_data":df}, batch_identifiers={"default_identifier_name":"default_identifier"}
) checkpoint_config = { "name": "product_sales_checkpoint", "config_version": 1, "class_name":"SimpleCheckpoint", "expectation_suite_name": "sales_suite"
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint( checkpoint_name="product_sales_checkpoint", validations=[ {"batch_request": batch_request} ]
)
Vi opretter en batch-anmodning for vores data, der giver datakildenavnet, som vil fortælle GE om at bruge en specifik eksekveringsmotor, i vores tilfælde, Pandas. Vi opretter en kontrolpunktkonfiguration og validerer derefter vores batchanmodning mod kontrolpunktet. Du kan tilføje flere batch-anmodninger, hvis forventningerne gælder for dataene i batchen i et enkelt kontrolpunkt. `run_checkpoint`-metoden returnerer resultatet i JSON-format og kan bruges til yderligere behandling eller analyser.
Resultater
Når vi har kørt forventningerne til vores datasæt, opretter GE et statisk HTML-dashboard med resultaterne for vores kontrolpunkt. Resultaterne indeholder antallet af evaluerede forventninger, succesfulde forventninger, mislykkede forventninger og succesprocenter. Alle poster, der ikke matcher de givne forventninger, vil blive fremhævet på siden. Nedenfor er et eksempel på vellykket udførelse:
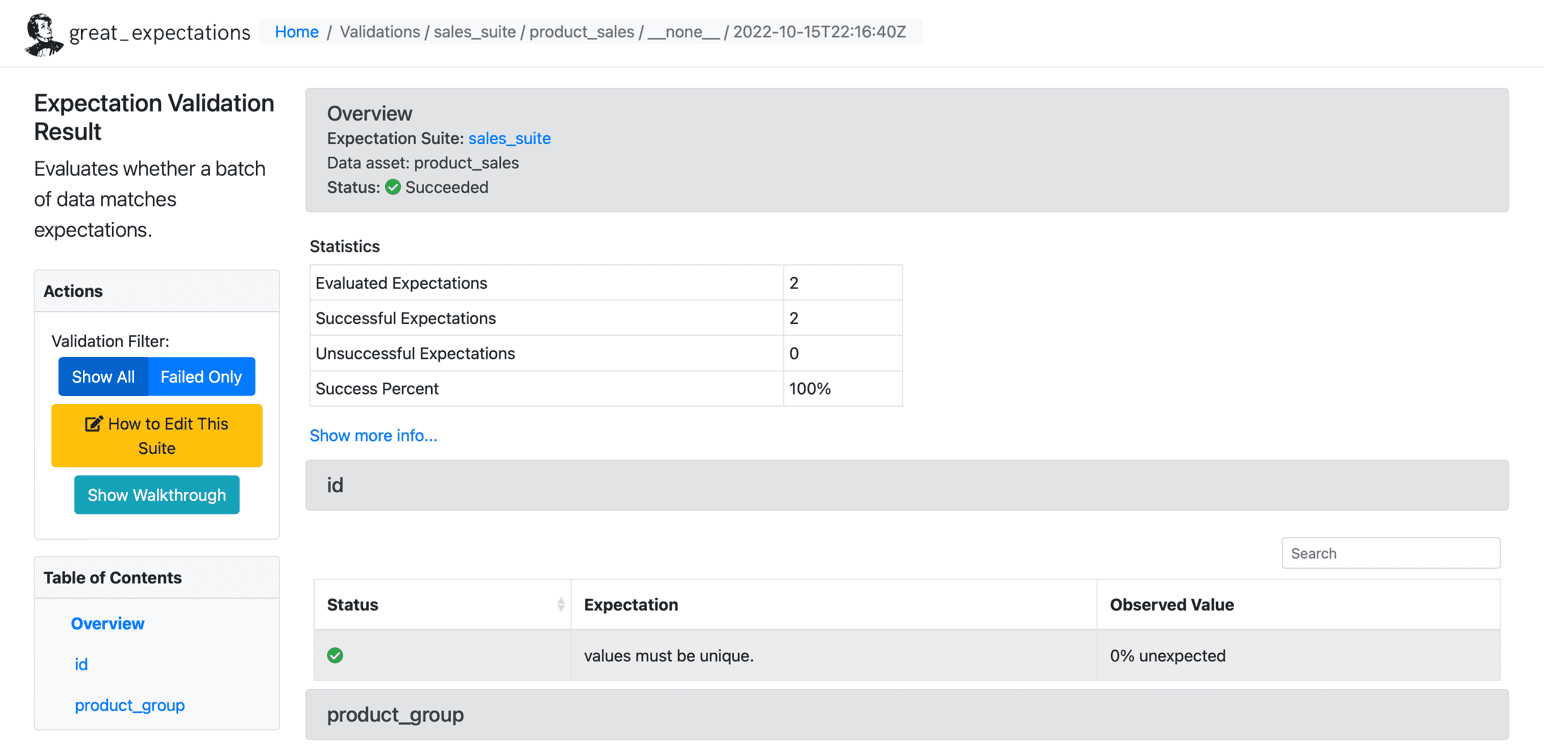
Kilde: Store forventninger
Nedenfor er et eksempel på den mislykkede forventning:
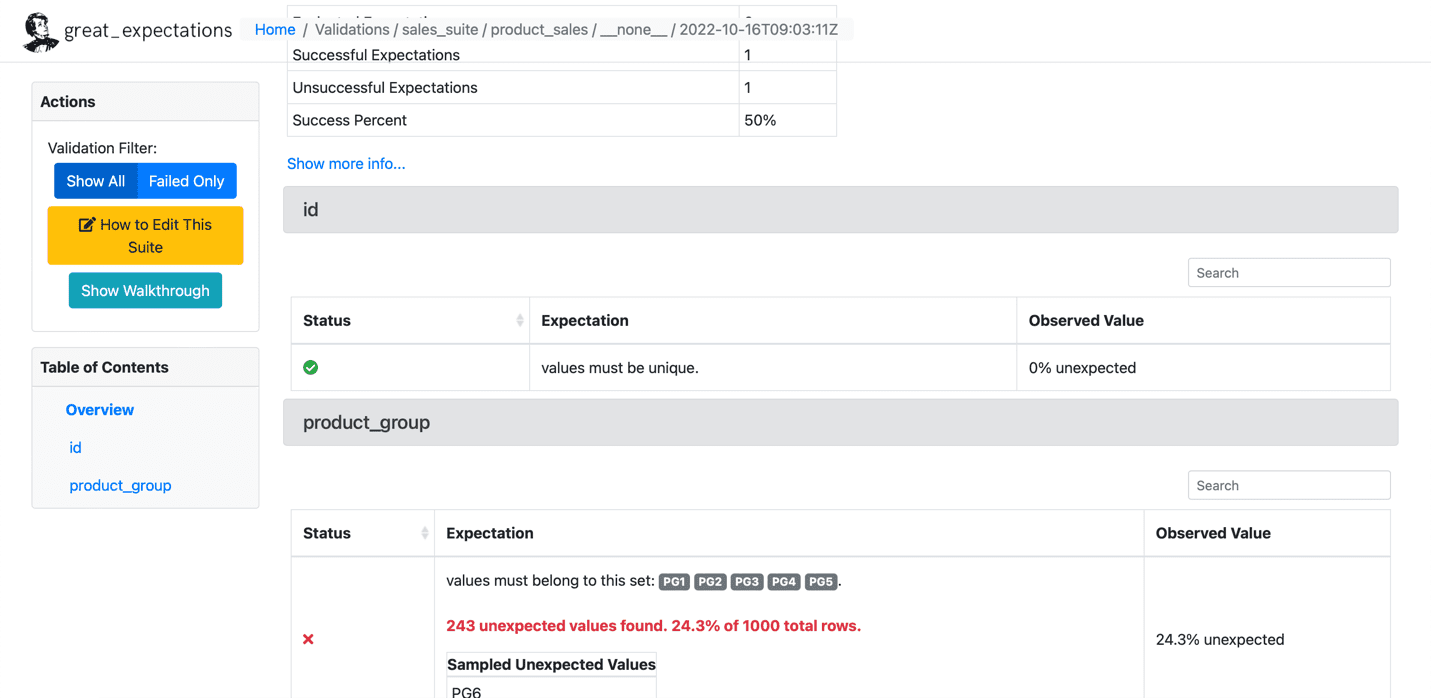
Kilde: Store forventninger
Vi har opsat GE i fire trin og har med succes kørt forventninger på et givet datasæt. GE har mere avancerede funktioner som at skrive dine tilpassede forventninger, som vi vil dække i fremtidige artikler. Mange organisationer bruger GE i vid udstrækning til at tilpasse deres kunders krav og skrive tilpassede forventninger.
Saisyam Dampuri kommer med 18+ års erfaring med softwareudvikling og brænder for at udforske nye teknologier og værktøjer. Han arbejder i øjeblikket som Sr. Cloud Architect hos Anblicks, TX, USA. Selvom han ikke koder, vil han have travlt med fotografering, madlavning og rejser.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.kdnuggets.com/2023/01/overcome-data-quality-issues-great-expectations.html?utm_source=rss&utm_medium=rss&utm_campaign=overcome-your-data-quality-issues-with-great-expectations
- 1
- 11
- 18 +
- 9
- a
- Om
- over
- tilføjet
- fremskreden
- mod
- Alle
- Amazon
- Amazon Web Services
- analyse
- analytics
- ,
- fra hinanden
- Indløs
- artikel
- artikler
- automatisk
- til rådighed
- gennemsnit
- AWS
- Azure
- Bagende
- Bad
- dårlige data
- før
- jf. nedenstående
- kaldet
- tilfælde
- Kontrol
- kunder
- Cloud
- kode
- Kodning
- Kolonne
- Fælles
- Virksomheder
- selskab
- Konceptet
- Konfiguration
- Overvej
- sammenhæng
- madlavning
- Omkostninger
- dæksel
- skabe
- oprettet
- skaber
- afgørende
- For øjeblikket
- skik
- kunde
- kundeadfærd
- tilpasse
- dagligt
- instrumentbræt
- data
- dataanalyse
- datakvalitet
- datasæt
- deal
- afgørelser
- defaults
- detaljer
- Udvikling
- dokumentet
- downloade
- Engine (Motor)
- skøn
- etc.
- Ether (ETH)
- evalueret
- eksempel
- udføre
- udførelse
- forventning
- forventninger
- erfaring
- Forklar
- forklarede
- Udforskning
- mislykkedes
- Funktionalitet
- File (Felt)
- Fornavn
- følger
- Forbes
- format
- fundet
- FRAME
- fra
- funktioner
- yderligere
- fremtiden
- Gevinst
- ge
- given
- stor
- gruppe
- hjælpe
- hjælper
- link.
- Fremhævet
- Hvordan
- How To
- HTML
- HTTPS
- kæmpe
- vigtigt
- in
- forkert
- Inc.
- omfatter
- oplysninger
- indsigt
- forsikring
- involverede
- spørgsmål
- IT
- json
- KDnuggets
- LÆR
- Bibliotek
- belastning
- placering
- Se
- taber
- off
- mange
- Match
- metode
- metoder
- million
- mangler
- penge
- Overvåg
- mere
- flere
- navn
- nødvendig
- Behov
- behov
- Ny
- Nye teknologier
- næste
- nummer
- open source
- organisationer
- Andet
- Overvind
- pandaer
- del
- lidenskabelige
- fotografering
- fysisk
- plato
- Platon Data Intelligence
- PlatoData
- politik
- postgresql
- behandle
- forarbejdning
- programmatisk
- give
- forudsat
- giver
- leverer
- Python
- kvalitet
- hurtigt
- optegnelser
- Reduceret
- indberette
- omdømme
- anmode
- anmodninger
- Krav
- resultere
- resulterer
- Resultater
- afkast
- indtægter
- regler
- Kør
- salg
- Anden
- Tjenester
- sæt
- indstilling
- bør
- Shows
- Simpelt
- enkelt
- Software
- softwareudvikling
- nogle
- Kilde
- kildekode
- Kilder
- specifikke
- Trin
- Steps
- butik
- forhandler
- strategier
- succes
- vellykket
- Succesfuld
- sådan
- suite
- Understøtter
- Teknologier
- fortæller
- prøve
- tests
- The Source
- deres
- ting
- tre
- tid
- til
- værktøjer
- Traveling
- TX
- typer
- under
- enestående
- enhed
- us
- USD
- brug
- VALIDATE
- validering
- Værdifuld
- Værdier
- forskellige
- verificere
- mængder
- måder
- web
- webservices
- hvorvidt
- som
- mens
- vilje
- Arbejde
- arbejder
- skriver
- skrivning
- år
- Din
- zephyrnet