IMDb og Box Office Mojo Movies/TV/OTT licenserbar datapakke giver en bred vifte af underholdningsmetadata, inklusive over 1 milliard brugervurderinger; kreditter til mere end 11 millioner medvirkende og besætningsmedlemmer; 9 millioner film-, tv- og underholdningstitler; og globale box office-rapporteringsdata fra mere end 60 lande. Mange AWS medie- og underholdningskunder licenserer IMDb-data igennem AWS dataudveksling at forbedre indholdsopdagelsen og øge kundernes engagement og fastholdelse.
I denne tredelte serie demonstrerer vi, hvordan man transformerer og forbereder IMDb-data til at drive søgning uden for kataloget efter dine medie- og underholdningsbrug. I dette indlæg diskuterer vi, hvordan man forbereder IMDb-data og indlæser dataene i Amazon Neptun til forespørgsel. I del 2, diskuterer vi, hvordan man bruger Amazon Neptune ML at træne grafneuralt netværk (GNN) indlejringer fra IMDb-grafen. I del 3 gennemgår vi en demoapplikation uden for kataloget søgning, der er drevet af GNN-indlejringer.
Løsningsoversigt
I denne serie bruger vi IMDb og Box Office Mojo Movies/TV/OTT licenseret datapakke for at vise, hvordan du kan bygge dine egne applikationer ved hjælp af grafer.
Denne licenserbare datapakke består af JSON-filer med IMDb-metadata for mere end 9 millioner titler (inklusive film, tv- og OTT-shows og videospil) og kreditter til mere end 11 millioner cast-, crew- og underholdningsprofessionelle. IMDbs metadatapakke inkluderer også over 1 milliard brugervurderinger, såvel som plots, genrer, kategoriserede søgeord, plakater, kreditter og mere.
IMDb leverer data gennem AWS Data Exchange, hvilket gør det utroligt nemt for dig at få adgang til data for at drive dine underholdningsoplevelser og problemfrit integrere med andre AWS-tjenester. IMDb licenserer data til en bred vifte af medie- og underholdningskunder, herunder betalings-tv, direkte til forbrugere og streamingoperatører, for at forbedre indholdsgenkendelse og øge kundeengagement og fastholdelse. Licenserende kunder bruger også IMDb-data til at forbedre titelsøgning i kataloget og uden for kataloget og levere relevante anbefalinger.
Vi bruger følgende tjenester som en del af denne løsning:
Følgende diagram viser arbejdsgangen for del 1 af 3-delt blogserie.
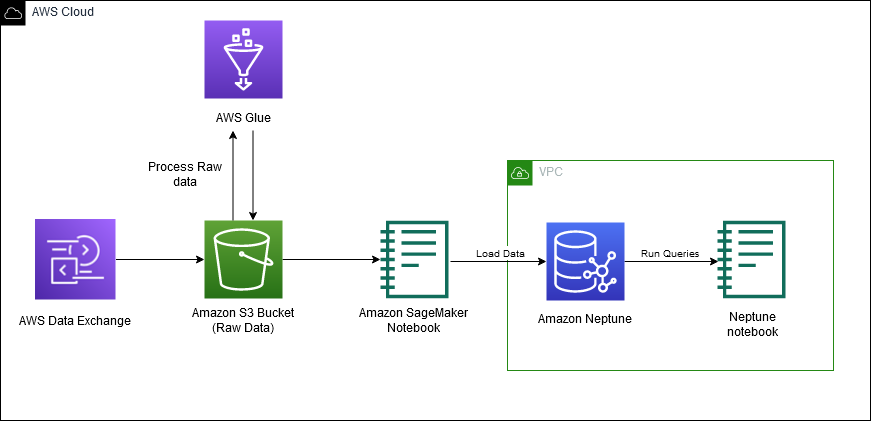
I dette indlæg gennemgår vi følgende trin på højt niveau:
- Forsyn Neptune ressourcer med AWS CloudFormation.
- Få adgang til IMDb-dataene fra AWS Data Exchange.
- Klon GitHub repo.
- Behandl dataene i Neptune Gremlin-format.
- Indlæs dataene i en Neptun-klynge.
- Forespørg dataene ved hjælp af Gremlin Query Language.
Forudsætninger
De IMDb-data, der bruges i dette indlæg, kræver en IMDb-indholdslicens og betalt abonnement på IMDb og Box Office Mojo Movies/TV/OTT-licenspakken i AWS Data Exchange. For at forespørge om en licens og få adgang til eksempeldata, besøg developer.imdb.com.
Derudover, for at følge med i dette indlæg, bør du have en AWS-konto og kendskab til Neptun, forespørgselssproget Gremlin og SageMaker.
Lever Neptune-ressourcer med AWS CloudFormation
Nu hvor du har set strukturen af løsningen, kan du implementere den på din konto for at køre et eksempel på en arbejdsgang.
Du kan starte stakken i AWS-regionen us-east-1 på AWS CloudFormation-konsollen ved at vælge Start Stack:
![]()
For at starte stakken i en anden region, se Brug af Neptune ML AWS CloudFormation-skabelonen til at komme hurtigt i gang i en ny DB-klynge.
Følgende skærmbillede viser de stakparametre, der skal angives.

Oprettelse af stakke tager cirka 20 minutter. Du kan overvåge fremskridtene på AWS CloudFormation-konsollen.
Når stakken er færdig, er du nu klar til at behandle IMDb-dataene. På den Udgange fanen for stakken, bemærk værdierne for NeptuneExportApiUri , NeptuneLoadFromS3IAMRoleArn. Fortsæt derefter til følgende trin for at få adgang til IMDb-datasættet.
Få adgang til IMDb-data
IMDb udgiver sit datasæt én gang om dagen på AWS Data Exchange. For at bruge IMDb-dataene abonnerer du først på dataene i AWS Data Exchange, derefter kan du eksportere dataene til Amazon Simple Storage Service (Amazon S3). Udfør følgende trin:
- På AWS Data Exchange-konsollen skal du vælge Gennemse kataloget i navigationsruden.
- Indtast i søgefeltet
IMDb. - Abonner på enten IMDb og Box Office Mojo Movie/TV/OTT-data (EKSEMPEL) or IMDb og Box Office Mojo Movie/TV/OTT-data.
- Udfør trinene i det følgende værksted at eksportere IMDb-data fra AWS Data Exchange til Amazon S3.
Klon GitHub-depotet
Udfør følgende trin:
- Åbn den SageMaker-instans, som du oprettede fra CloudFormation-skabelonen.
- Klon GitHub-depotet.
Behandl IMDb-data i Neptune Gremlin-format
For at tilføje data til Amazon Neptune behandler vi dataene i Neptune gremlin-format. Fra GitHub-lageret kører vi process_imdb_data.py at behandle filerne. Scriptet opretter CSV'erne for at indlæse dataene i Neptun. Upload dataene til en S3-bøtte, og noter S3 URI-placeringen.
Bemærk, at for dette indlæg filtrerer vi datasættet til kun at inkludere film. Du har brug for enten en AWS Lim job eller Amazon EMR at behandle de fulde data.
For at behandle IMDb-dataene ved hjælp af AWS Glue skal du udføre følgende trin:
- På AWS Glue-konsollen skal du i navigationsruden vælge Karriere.
- På Karriere side, vælg Spark script editor.
- Under Indstillinger, vælg Upload og rediger eksisterende script og upload
1_process_imdb_data.pyfil. - Vælg Opret.
- Vælg på editorsiden Job Detaljer.
- På Job Detaljer side, skal du tilføje følgende muligheder:
- Til Navn, gå ind
imdb-graph-processor. - Til Beskrivelse, gå ind
processing IMDb dataset and convert to Neptune Gremlin Format. - Til IAM rolle, brug en eksisterende AWS Glue-rolle eller oprette en IAM-rolle til AWS Glue. Sørg for, at du giver tilladelse til din Amazon S3-placering for rådata og outputdatasti.
- Til Arbejdertype, vælg G 2X.
- Til Ønsket antal arbejdere, indtast 20.
- Til Navn, gå ind
- Udvid Avancerede egenskaber.
- Under Jobparametre, vælg Tilføj ny parameter og indtast følgende nøgleværdipar:
- Indtast for nøglen
--output_bucket_path. - For værdien skal du indtaste S3-stien, hvor du vil gemme filerne. Denne sti bruges også til at indlæse dataene i Neptun-klyngen.
- Indtast for nøglen
- For at tilføje en anden parameter, vælg Tilføj ny parameter og indtast følgende nøgleværdipar:
- Indtast for nøglen
--raw_data_path. - For værdien skal du indtaste S3-stien, hvor de rå data er gemt.
- Indtast for nøglen
- Vælg Gem og vælg derefter Kør.
Dette job tager omkring 2.5 timer at udføre.
Følgende tabel giver detaljer om knudepunkterne for grafdatamodellen.
| Beskrivelse | etiket |
| Hovedbesætningsmedlemmer | Person |
| Film i langt format | film |
| Genre af film | Genre |
| Nøgleordsbeskrivelser af film | Søgeord |
| Optagelsessteder for film | Place |
| Bedømmelser for film | bedømmelse |
| Prisbegivenhed, hvor filmen modtog en pris | Præmier |
På samme måde viser den følgende tabel nogle af de kanter, der er inkluderet i grafen. Der vil i alt være 24 kanttyper.
| Beskrivelse | etiket | Fra | Til |
| Film en skuespillerinde har medvirket i | castet af skuespillerinde | film | Person |
| Film en skuespiller har medvirket i | castet af skuespiller | film | Person |
| Nøgleord i en film efter karakter | beskrevet-for-tegn-søgeord | film | søgeord |
| Genre af en film | er-genre | film | Genre |
| Stedet, hvor filmen blev optaget | Filmet-kl | film | Place |
| Komponist af en film | Besætning af komponist | film | Person |
| nominering af prisen | Nomineret_til | film | Priser han har vundet |
| prisvinder | Har vundet | film | Priser han har vundet |
Indlæs dataene i en Neptun-klynge
I repoen skal du navigere til graph_creation mappe og kør 2_load.ipynb. For at indlæse dataene til Neptun skal du bruge kommandoen %load i notesbogen og angive din AWS identitets- og adgangsstyring (IAM) rolle ARN og Amazon S3 placering af dine behandlede data.
Følgende skærmbillede viser outputtet af kommandoen.

Bemærk, at dataindlæsningen tager omkring 1.5 time at fuldføre. For at kontrollere status for belastningen skal du bruge følgende kommando:
Når belastningen er færdig, vises status LOAD_COMPLETED, som vist i følgende skærmbillede.

Alle data er nu indlæst i grafer, og du kan begynde at forespørge på grafen.

Fig.: Eksempel på vidensgrafrepræsentation af film i IMDb-datasæt. Filmene "Saving Private Ryan" og "Bridge of Spies" har fælles forbindelser som skuespiller og instruktør såvel som indirekte forbindelser gennem film som "The Catcher was a Spy" i grafnetværket.
Spørg dataene ved hjælp af Gremlin
For at få adgang til grafen i Neptun bruger vi forespørgselssproget Gremlin. For mere information, se Forespørgsel på en Neptun-graf.
Grafen består af et rigt sæt information, der kan forespørges direkte ved hjælp af Gremlin. I dette afsnit viser vi nogle få eksempler på spørgsmål, som du kan besvare med grafdataene. I repoen skal du navigere til graph_creation mappe og kør 3_queries.ipynb notesbog. Det følgende afsnit gennemgår alle forespørgslerne fra notesbogen.
Verdensomspændende brutto af film, der er optaget i New Zealand, med minimum 7.5 rating
Følgende forespørgsel returnerer det globale brutto af film optaget i New Zealand med en minimumsvurdering på 7.5:
Følgende skærmbillede viser forespørgselsresultaterne.

Top 50 film, der tilhører action- og dramagenrer og har Oscar-vindende skuespillere
I det følgende eksempel ønsker vi at finde de 50 bedste film i to forskellige genrer (action og drama) med Oscar-vindende skuespillere. Vi kan gøre dette ved at bruge tre forskellige forespørgsler og flette oplysningerne ved hjælp af Pandas:
Følgende skærmbillede viser vores resultater.

Topfilm, der har fælles søgeord "tatovering" og "morder"
Følgende forespørgsel returnerer film med søgeordene "tattoo" og "assassin":
Følgende skærmbillede viser vores resultater.

Film, der har fælles skuespillere
I den følgende forespørgsel finder vi film, der har Leonardo DiCaprio og Tom Hanks:
Vi får følgende resultater.

Konklusion
I dette indlæg viste vi dig kraften i IMDb og Box Office Mojo Movies/TV/OTT-datasættet, og hvordan du kan bruge det i forskellige brugssager ved at konvertere dataene til en graf ved hjælp af Gremlin-forespørgsler. I del 2 i denne serie viser vi dig, hvordan du opretter grafiske neurale netværksmodeller på disse data, som kan bruges til downstream-opgaver.
For mere information om Neptun og Gremlin, se Amazon Neptune Ressourcer for yderligere blogindlæg og videoer.
Om forfatterne
 Gaurav Rele er dataforsker ved Amazon ML Solution Lab, hvor han arbejder med AWS-kunder på tværs af forskellige vertikaler for at accelerere deres brug af machine learning og AWS Cloud-tjenester til at løse deres forretningsmæssige udfordringer.
Gaurav Rele er dataforsker ved Amazon ML Solution Lab, hvor han arbejder med AWS-kunder på tværs af forskellige vertikaler for at accelerere deres brug af machine learning og AWS Cloud-tjenester til at løse deres forretningsmæssige udfordringer.
 Matthew Rhodes er dataforsker, jeg arbejder i Amazon ML Solutions Lab. Han har specialiseret sig i at bygge Machine Learning pipelines, der involverer begreber som Natural Language Processing og Computer Vision.
Matthew Rhodes er dataforsker, jeg arbejder i Amazon ML Solutions Lab. Han har specialiseret sig i at bygge Machine Learning pipelines, der involverer begreber som Natural Language Processing og Computer Vision.
 Divya Bhargavi er Data Scientist og Media and Entertainment Vertical Lead hos Amazon ML Solutions Lab, hvor hun løser forretningsproblemer af høj værdi for AWS-kunder ved hjælp af Machine Learning. Hun arbejder med billed-/videoforståelse, vidensgrafanbefalingssystemer, prædiktiv annonceringsbrug.
Divya Bhargavi er Data Scientist og Media and Entertainment Vertical Lead hos Amazon ML Solutions Lab, hvor hun løser forretningsproblemer af høj værdi for AWS-kunder ved hjælp af Machine Learning. Hun arbejder med billed-/videoforståelse, vidensgrafanbefalingssystemer, prædiktiv annonceringsbrug.
 Karan Sindwani er Data Scientist hos Amazon ML Solutions Lab, hvor han bygger og implementerer deep learning-modeller. Han har specialiseret sig inden for computersyn. I sin fritid nyder han at vandre.
Karan Sindwani er Data Scientist hos Amazon ML Solutions Lab, hvor han bygger og implementerer deep learning-modeller. Han har specialiseret sig inden for computersyn. I sin fritid nyder han at vandre.
 Soji Adeshina er en Applied Scientist hos AWS, hvor han udvikler grafiske neurale netværksbaserede modeller til maskinlæring på grafopgaver med applikationer til bedrageri og misbrug, vidensgrafer, anbefalingssystemer og biovidenskab. I sin fritid nyder han at læse og lave mad.
Soji Adeshina er en Applied Scientist hos AWS, hvor han udvikler grafiske neurale netværksbaserede modeller til maskinlæring på grafopgaver med applikationer til bedrageri og misbrug, vidensgrafer, anbefalingssystemer og biovidenskab. I sin fritid nyder han at læse og lave mad.
 Vidya Sagar Ravipati er leder hos Amazon ML Solutions Lab, hvor han udnytter sin store erfaring med distribuerede systemer i stor skala og sin passion for maskinlæring til at hjælpe AWS-kunder på tværs af forskellige brancher med at accelerere deres AI og cloud-adoption.
Vidya Sagar Ravipati er leder hos Amazon ML Solutions Lab, hvor han udnytter sin store erfaring med distribuerede systemer i stor skala og sin passion for maskinlæring til at hjælpe AWS-kunder på tværs af forskellige brancher med at accelerere deres AI og cloud-adoption.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/part-1-power-recommendation-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Om
- misbrug
- fremskynde
- adgang
- Konto
- tværs
- Handling
- Yderligere
- Vedtagelse
- Reklame
- AI
- Alle
- Amazon
- Amazon ML Solutions Lab
- Amazon Neptun
- ,
- En anden
- besvare
- Anvendelse
- applikationer
- anvendt
- cirka
- OMRÅDE
- snigmorder
- AWS
- AWS CloudFormation
- AWS Lim
- Billion
- Blog
- Blogindlæg
- Boks
- box office
- Bygning
- bygger
- bygget
- virksomhed
- .
- tilfælde
- udfordringer
- kontrollere
- Vælg
- vælge
- Cloud
- cloud adoption
- cloud-tjenester
- Cluster
- Fælles
- fuldføre
- computer
- Computer Vision
- begreber
- Tilslutninger
- Konsol
- indhold
- konvertere
- lande
- skabe
- oprettet
- skaber
- skabelse
- Medvirkende
- kunde
- Kundeforlovelse
- Kunder
- data
- Dataudveksling
- dataforsker
- dag
- dyb
- dyb læring
- leverer
- demonstrere
- indsætte
- udruller
- detaljer
- udvikler
- forskellige
- direkte
- Direktør
- opdagelse
- diskutere
- displays
- distribueret
- distribuerede systemer
- Drama
- Edge
- editor
- enten
- engagement
- Indtast
- Underholdning
- Ether (ETH)
- begivenhed
- eksempel
- eksempler
- udveksling
- eksisterende
- erfaring
- Oplevelser
- eksport
- Kendskab
- få
- felt
- File (Felt)
- Filer
- filtrere
- Finde
- Fornavn
- følger
- efter
- format
- bedrageri
- fra
- fuld
- Gevinst
- Spil
- få
- GitHub
- Giv
- Global
- Goes
- graf
- Graf neuralt netværk
- grafer
- brutto
- hjælpe
- højt niveau
- HOURS
- Hvordan
- How To
- HTML
- HTTPS
- Identity
- Forbedre
- in
- omfatter
- medtaget
- omfatter
- Herunder
- Forøg
- utroligt
- industrien
- oplysninger
- instans
- integrere
- involvere
- IT
- Job
- json
- Nøgle
- viden
- lab
- Sprog
- storstilet
- lancere
- føre
- læring
- Udnytter
- Licens
- Licenseret
- licenser
- Licenser
- Livet
- Life Sciences
- belastning
- placering
- placeringer
- maskine
- machine learning
- lave
- maerker
- leder
- mange
- Medier
- Medlemmer
- sammenlægning
- Metadata
- million
- minimum
- minutter
- ML
- model
- modeller
- Overvåg
- mere
- film
- Film
- navn
- Natural
- Natural Language Processing
- Naviger
- Navigation
- Behov
- Neptune
- netværk
- netværksbaseret
- neurale netværk
- Ny
- New Zealand
- noder
- notesbog
- nummer
- Office
- Operatører
- Indstillinger
- Andet
- egen
- pakke
- betalt
- pandaer
- brød
- parameter
- parametre
- del
- lidenskab
- sti
- Betal
- tilladelse
- person,
- Place
- plato
- Platon Data Intelligence
- PlatoData
- Indlæg
- Indlæg
- magt
- strøm
- Forbered
- private
- problemer
- behandle
- forarbejdning
- professionelle partnere
- Progress
- give
- giver
- Spørgsmål
- hurtigt
- rækkevidde
- bedømmelse
- ratings
- Raw
- Læsning
- klar
- modtaget
- Anbefaling
- anbefalinger
- region
- relevant
- Rapportering
- Repository
- repræsentation
- Kræver
- Ressourcer
- resultere
- Resultater
- tilbageholdelse
- afkast
- Rich
- roller
- Kør
- sagemaker
- Gem
- VIDENSKABER
- Videnskabsmand
- Skærm
- problemfrit
- Søg
- Sektion
- Series
- Tjenester
- sæt
- bør
- Vis
- vist
- Shows
- Simpelt
- løsninger
- Løsninger
- SOLVE
- Løser
- nogle
- specialiseret
- stable
- starte
- påbegyndt
- Status
- Steps
- opbevaring
- opbevaret
- streaming
- struktur
- Studio
- Hold mig opdateret
- abonnement
- sådan
- Systemer
- bord
- tager
- opgaver
- skabelon
- Området
- Grafen
- Graph Network
- oplysninger
- deres
- tre
- Gennem
- tid
- Titel
- titler
- til
- top
- I alt
- Tog
- Transform
- sand
- tv
- typer
- forståelse
- brug
- Bruger
- værdi
- Værdier
- forskellige
- Vast
- vertikaler
- video
- videospil
- Videoer
- vision
- som
- bred
- Bred rækkevidde
- vilje
- arbejder
- virker
- workshops
- verdensplan
- år
- Din
- Sjælland
- zephyrnet