Denne serie i tre dele demonstrerer, hvordan man bruger grafiske neurale netværk (GNN'er) og Amazon Neptun at generere filmanbefalinger ved hjælp af IMDb og Box Office Mojo Movies/TV/OTT licenserbar datapakke, som giver en bred vifte af underholdningsmetadata, inklusive over 1 milliard brugervurderinger; kreditter til mere end 11 millioner medvirkende og besætningsmedlemmer; 9 millioner film-, tv- og underholdningstitler; og globale box office-rapporteringsdata fra mere end 60 lande. Mange AWS medie- og underholdningskunder licenserer IMDb-data igennem AWS dataudveksling at forbedre indholdsopdagelsen og øge kundernes engagement og fastholdelse.
In del 1, vi diskuterede anvendelserne af GNN'er, og hvordan man transformerer og forbereder vores IMDb-data til forespørgsel. I dette indlæg diskuterer vi processen med at bruge Neptun til at generere indlejringer, der bruges til at udføre vores søgning uden for kataloget i del 3. Vi går også over Amazon Neptune ML, maskinlæringsfunktionen (ML) i Neptune og den kode, vi bruger i vores udviklingsproces. I del 3 gennemgår vi, hvordan vi anvender vores vidensgrafindlejringer på en søgning uden for kataloget.
Løsningsoversigt
Store forbundne datasæt indeholder ofte værdifuld information, som kan være svær at udtrække ved hjælp af forespørgsler baseret på menneskelig intuition alene. ML-teknikker kan hjælpe med at finde skjulte sammenhænge i grafer med milliarder af relationer. Disse korrelationer kan være nyttige til at anbefale produkter, forudsige kreditværdighed, identificere svindel og mange andre brugssager.
Neptune ML gør det muligt at bygge og træne nyttige ML-modeller på store grafer i timer i stedet for uger. For at opnå dette bruger Neptune ML GNN-teknologi drevet af Amazon SageMaker og Deep Graph Library (DGL) (som er open source). GNN'er er et spirende felt inden for kunstig intelligens (se for eksempel En omfattende undersøgelse af grafiske neurale netværk). For en praktisk vejledning om brug af GNN'er med DGL, se Lær grafiske neurale netværk med Deep Graph Library.
I dette indlæg viser vi, hvordan man bruger Neptun i vores pipeline til at generere indlejringer.
Følgende diagram viser det overordnede flow af IMDb-data fra download til indlejringsgenerering.
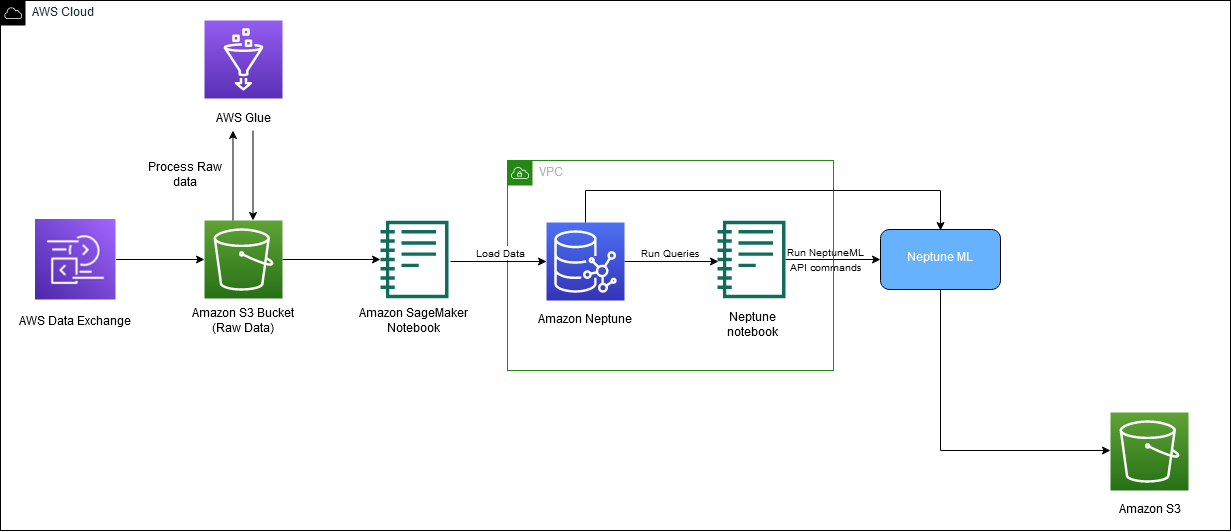
Vi bruger følgende AWS-tjenester til at implementere løsningen:
I dette indlæg leder vi dig gennem følgende trin på højt niveau:
- Opsæt miljøvariabler
- Opret et eksportjob.
- Opret et databehandlingsjob.
- Indsend et træningsjob.
- Download indlejringer.
Kode til Neptune ML-kommandoer
Vi bruger følgende kommandoer som en del af implementeringen af denne løsning:
Vi anvender neptune_ml export for at kontrollere status eller starte en Neptune ML eksportproces, og neptune_ml training for at starte og kontrollere status for et Neptune ML model træningsjob.
For mere information om disse og andre kommandoer, se Brug af Neptune workbench magics i dine notesbøger.
Forudsætninger
For at følge med i dette indlæg skal du have følgende:
- An AWS-konto
- Kendskab til SageMaker, Amazon S3 og AWS CloudFormation
- Grafdata indlæst i Neptun-klyngen (se del 1 for mere information)
Opsæt miljøvariabler
Før vi begynder, skal du konfigurere dit miljø ved at indstille følgende variabler: s3_bucket_uri , processed_folder. s3_bucket_uri er navnet på den spand, der blev brugt i del 1 og processed_folder er Amazon S3-lokationen for output fra eksportjobbet.
Opret et eksportjob
I del 1 oprettede vi en SageMaker notesbog og eksporttjeneste til at eksportere vores data fra Neptune DB-klyngen til Amazon S3 i det krævede format.
Nu hvor vores data er indlæst, og eksporttjenesten er oprettet, skal vi oprette et eksportjob og starte det. For at gøre dette bruger vi NeptuneExportApiUri og oprette parametre for eksportjobbet. I den følgende kode bruger vi variablerne expo , export_params. Sæt expo til din NeptuneExportApiUri værdi, som du kan finde på Udgange fanen på din CloudFormation-stak. Til export_params, bruger vi endepunktet for din Neptun-klynge og angiver værdien for outputS3path, som er Amazon S3-lokationen for output fra eksportjobbet.
Brug følgende kommando for at indsende eksportjobbet:
Brug følgende kommando for at kontrollere status for eksportjobbet:
Når dit job er fuldført, skal du indstille processed_folder variabel for at angive Amazon S3-placeringen af de behandlede resultater:
Opret et databehandlingsjob
Nu hvor eksporten er færdig, opretter vi et databehandlingsjob for at forberede dataene til Neptune ML træningsprocessen. Dette kan gøres på et par forskellige måder. For dette trin kan du ændre job_name , modelType variabler, men alle andre parametre skal forblive de samme. Hoveddelen af denne kode er modelType parameter, som enten kan være heterogene grafmodeller (heterogeneous) eller vidensgrafer (kge).
Eksportjobbet omfatter også training-data-configuration.json. Brug denne fil til at tilføje eller fjerne eventuelle noder eller kanter, som du ikke ønsker at give til træning (hvis du f.eks. vil forudsige linket mellem to noder, kan du fjerne det link i denne konfigurationsfil). Til dette blogindlæg bruger vi den originale konfigurationsfil. For yderligere information, se Redigering af en træningskonfigurationsfil.
Opret dit databehandlingsjob med følgende kode:
Brug følgende kommando for at kontrollere status for eksportjobbet:
Indsend et træningsjob
Når forarbejdningsjobbet er afsluttet, kan vi begynde vores træningsjob, hvor vi skaber vores indlejringer. Vi anbefaler en instanstype på ml.m5.24xlarge, men du kan ændre dette, så det passer til dine computerbehov. Se følgende kode:
Vi udskriver variablen training_results for at få ID'et for træningsjobbet. Brug følgende kommando til at kontrollere status for dit job:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Download indlejringer
Når dit træningsjob er fuldført, er det sidste trin at downloade dine rå indlejringer. De følgende trin viser dig, hvordan du downloader indlejringer oprettet ved hjælp af KGE (du kan bruge den samme proces til RGCN).
I den følgende kode bruger vi neptune_ml.get_mapping() , get_embeddings() for at downloade kortfilen (mapping.info) og den rå indlejringsfil (entity.npy). Så skal vi kortlægge de relevante indlejringer til deres tilsvarende ID'er.
For at downloade RGCN'er skal du følge den samme proces med et nyt træningsjobnavn ved at behandle dataene med modelType-parameteren indstillet til heterogeneous, og derefter træne din model med parameteren modelName indstillet til rgcn se link. for flere detaljer. Når det er færdigt, ring til get_mapping , get_embeddings funktioner til at downloade din nye mapping.info , entity.npy filer. Når du har entitets- og tilknytningsfilerne, er processen til at oprette CSV-filen identisk.
Til sidst skal du uploade dine indlejringer til din ønskede Amazon S3-placering:
Sørg for at huske denne S3-placering, du skal bruge den i del 3.
Ryd op
Når du er færdig med at bruge løsningen, skal du sørge for at rydde op i eventuelle ressourcer for at undgå løbende opkrævninger.
Konklusion
I dette indlæg diskuterede vi, hvordan man bruger Neptune ML til at træne GNN-indlejringer fra IMDb-data.
Nogle relaterede anvendelser af videngrafindlejringer er begreber som søgning uden for kataloget, indholdsanbefalinger, målrettet annoncering, forudsigelse af manglende links, generel søgning og kohorteanalyse. Søgning uden for katalog er processen med at søge efter indhold, som du ikke ejer, og finde eller anbefale indhold, der er i dit katalog, som er så tæt på det, som brugeren søgte efter som muligt. Vi dykker dybere ned i søgning uden for kataloget i del 3.
Om forfatterne
 Matthew Rhodes er dataforsker, jeg arbejder i Amazon ML Solutions Lab. Han har specialiseret sig i at bygge Machine Learning pipelines, der involverer begreber som Natural Language Processing og Computer Vision.
Matthew Rhodes er dataforsker, jeg arbejder i Amazon ML Solutions Lab. Han har specialiseret sig i at bygge Machine Learning pipelines, der involverer begreber som Natural Language Processing og Computer Vision.
 Divya Bhargavi er Data Scientist og Media and Entertainment Vertical Lead hos Amazon ML Solutions Lab, hvor hun løser forretningsproblemer af høj værdi for AWS-kunder ved hjælp af Machine Learning. Hun arbejder med billed-/videoforståelse, vidensgrafanbefalingssystemer, prædiktiv annonceringsbrug.
Divya Bhargavi er Data Scientist og Media and Entertainment Vertical Lead hos Amazon ML Solutions Lab, hvor hun løser forretningsproblemer af høj værdi for AWS-kunder ved hjælp af Machine Learning. Hun arbejder med billed-/videoforståelse, vidensgrafanbefalingssystemer, prædiktiv annonceringsbrug.
 Gaurav Rele er dataforsker ved Amazon ML Solution Lab, hvor han arbejder med AWS-kunder på tværs af forskellige vertikaler for at accelerere deres brug af machine learning og AWS Cloud-tjenester til at løse deres forretningsmæssige udfordringer.
Gaurav Rele er dataforsker ved Amazon ML Solution Lab, hvor han arbejder med AWS-kunder på tværs af forskellige vertikaler for at accelerere deres brug af machine learning og AWS Cloud-tjenester til at løse deres forretningsmæssige udfordringer.
 Karan Sindwani er Data Scientist hos Amazon ML Solutions Lab, hvor han bygger og implementerer deep learning-modeller. Han har specialiseret sig inden for computersyn. I sin fritid nyder han at vandre.
Karan Sindwani er Data Scientist hos Amazon ML Solutions Lab, hvor han bygger og implementerer deep learning-modeller. Han har specialiseret sig inden for computersyn. I sin fritid nyder han at vandre.
 Soji Adeshina er en Applied Scientist hos AWS, hvor han udvikler grafiske neurale netværksbaserede modeller til maskinlæring på grafopgaver med applikationer til bedrageri og misbrug, vidensgrafer, anbefalingssystemer og biovidenskab. I sin fritid nyder han at læse og lave mad.
Soji Adeshina er en Applied Scientist hos AWS, hvor han udvikler grafiske neurale netværksbaserede modeller til maskinlæring på grafopgaver med applikationer til bedrageri og misbrug, vidensgrafer, anbefalingssystemer og biovidenskab. I sin fritid nyder han at læse og lave mad.
 Vidya Sagar Ravipati er leder hos Amazon ML Solutions Lab, hvor han udnytter sin store erfaring med distribuerede systemer i stor skala og sin passion for maskinlæring til at hjælpe AWS-kunder på tværs af forskellige brancher med at accelerere deres AI og cloud-adoption.
Vidya Sagar Ravipati er leder hos Amazon ML Solutions Lab, hvor han udnytter sin store erfaring med distribuerede systemer i stor skala og sin passion for maskinlæring til at hjælpe AWS-kunder på tværs af forskellige brancher med at accelerere deres AI og cloud-adoption.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Om
- misbrug
- fremskynde
- tværs
- Yderligere
- yderligere information
- Vedtagelse
- Reklame
- Efter
- AI
- Alle
- alene
- Amazon
- Amazon ML Solutions Lab
- analyse
- ,
- applikationer
- anvendt
- Indløs
- passende
- OMRÅDE
- kunstig
- kunstig intelligens
- AWS
- baseret
- mellem
- Billion
- milliarder
- Blog
- Boks
- box office
- bygge
- Bygning
- bygger
- virksomhed
- ringe
- tilfælde
- tilfælde
- katalog
- udfordringer
- lave om
- afgifter
- kontrollere
- Luk
- Cloud
- cloud adoption
- cloud-tjenester
- Cluster
- kode
- kohorte
- fuldføre
- omfattende
- computer
- Computer Vision
- computing
- begreber
- Adfærd
- Konfiguration
- tilsluttet
- indhold
- Tilsvarende
- lande
- skabe
- oprettet
- kredit
- Medvirkende
- kunde
- Kundeforlovelse
- Kunder
- data
- databehandling
- dataforsker
- datasæt
- dyb
- dyb læring
- dybere
- udruller
- detaljer
- Udvikling
- udvikler
- dgl
- forskellige
- opdagelse
- diskutere
- drøftet
- distribueret
- distribuerede systemer
- Dont
- downloade
- enten
- smergel
- Endpoint
- engagement
- Underholdning
- enhed
- Miljø
- Ether (ETH)
- eksempel
- erfaring
- eksport
- ekstrakt
- Feature
- få
- felt
- File (Felt)
- Filer
- Finde
- finde
- flow
- følger
- efter
- format
- bedrageri
- fra
- fuld
- funktioner
- Generelt
- generere
- generation
- få
- Global
- Go
- graf
- grafer
- hands-on
- Hård Ost
- hjælpe
- hjælpsom
- Skjult
- højt niveau
- HOURS
- Hvordan
- How To
- HTML
- HTTPS
- menneskelig
- identisk
- identificere
- gennemføre
- gennemføre
- Forbedre
- in
- omfatter
- Herunder
- Forøg
- indeks
- industrien
- info
- oplysninger
- instans
- i stedet
- Intelligens
- involvere
- IT
- Job
- json
- Nøgle
- viden
- lab
- Sprog
- stor
- storstilet
- Efternavn
- føre
- læring
- Udnytter
- Bibliotek
- Licens
- Livet
- Life Sciences
- LINK
- links
- placering
- maskine
- machine learning
- Main
- maerker
- leder
- mange
- kort
- kortlægning
- Medier
- medium
- Medlemmer
- Metadata
- million
- mangler
- ML
- model
- modeller
- mere
- film
- navn
- Natural
- Natural Language Processing
- Behov
- behov
- Neptune
- netværksbaseret
- net
- neurale netværk
- Ny
- noder
- notesbog
- Office
- igangværende
- original
- Andet
- samlet
- egen
- pakke
- parameter
- parametre
- del
- lidenskab
- pipeline
- plato
- Platon Data Intelligence
- PlatoData
- mulig
- Indlæg
- magt
- strøm
- forudsige
- forudsige
- Forbered
- problemer
- behandle
- forarbejdning
- Produkter
- Profil
- give
- giver
- rækkevidde
- ratings
- Raw
- Læsning
- anbefaler
- Anbefaling
- anbefalinger
- anbefale
- relaterede
- Relationer
- forblive
- huske
- Fjern
- Rapportering
- påkrævet
- Ressourcer
- Resultater
- tilbageholdelse
- sagemaker
- samme
- VIDENSKABER
- Videnskabsmand
- Søg
- søgning
- Series
- tjeneste
- Tjenester
- sæt
- indstilling
- bør
- Vis
- løsninger
- Løsninger
- SOLVE
- Løser
- specialiseret
- stable
- starte
- Status
- Trin
- Steps
- butik
- indsende
- sådan
- Dragt
- Kortlægge
- Systemer
- målrettet
- opgaver
- teknikker
- Teknologier
- Området
- deres
- Gennem
- tid
- titler
- til
- Tog
- Kurser
- Transform
- sand
- tutorial
- tv
- forståelse
- brug
- brug tilfælde
- Bruger
- Værdifuld
- værdi
- Vast
- udgave
- vertikaler
- vision
- måder
- uger
- Hvad
- som
- bred
- Bred rækkevidde
- vilje
- arbejder
- virker
- Din
- zephyrnet